
Im Oktober steht GPT-3 traditionell wieder im Rampenlicht. Es gibt verschiedene Neuigkeiten zum Modell von OpenAI - gut und nicht so gut.
OpenAI und Microsoft handeln
Wir müssen mit einem weniger angenehmen beginnen - Microsoft hat die exklusiven Rechte an GPT-3 übernommen. Der Deal löste vorhersehbar Empörung aus - Elon Musk, Gründer von OpenAI und jetzt ehemaliges Mitglied des Board of Directors des Unternehmens, sagte, Microsoft habe OpenAI im Wesentlichen übernommen.
Tatsache ist, dass OpenAI ursprünglich als gemeinnützige Organisation mit einer hohen Mission gegründet wurde - künstliche Intelligenz nicht in die Hände eines separaten Staates oder Unternehmens zu bringen. Die Gründer der Organisation forderten die Offenheit der Forschung in diesem Bereich, damit die Technologie zum Nutzen der gesamten Menschheit funktioniert.
Microsoft sagt zu ihrer Verteidigung, dass sie den Zugriff auf die Modell-API nicht einschränken werden. Tatsächlich hat sich also nichts geändert - zuvor hat OpenAI den Code auch nicht veröffentlicht, aber wenn früher sogar Partnerunternehmen nur über die API mit GPT-3 arbeiten durften, hat Microsoft jetzt die exklusiven Nutzungsrechte.
ruGPT3 von der Sberbank
Nun zu angenehmeren Neuigkeiten: Forscher der Sberbank haben ein Open-Access-Modell veröffentlicht , das die GPT-3-Architektur wiederholt, auf dem GPT-2-Code basiert und vor allem im russischsprachigen Korpus geschult ist.
Eine Sammlung russischer Literatur, Wikipedia-Daten, Schnappschüsse von Nachrichten und Frage-und-Antwort-Sites sowie Materialien aus den Portalen Pikabu, 22century.ru banki.ru, Omnia Russica wurden als Datensatz für Schulungen verwendet. Die Entwickler haben auch Daten von GitHub und StackOverflow hinzugefügt, um zu lernen, wie Code generiert und programmiert wird. Die Gesamtmenge der bereinigten Daten beträgt mehr als 600 GB.
Die Nachrichten sind definitiv gut, aber es gibt ein paar Einschränkungen. Dieses Modell ähnelt GPT-3, jedoch nicht. Die Autoren selbst geben zudass es 230-mal kleiner ist als die größte Version von GPT-3 mit 175 Milliarden Gewichten, was bedeutet, dass es die Benchmark-Ergebnisse nicht genau wiederholen kann. Erwarten Sie also nicht, dass dieses Modell Texte schreibt, die nicht von journalistischen Texten zu unterscheiden sind.
Es ist auch zu berücksichtigen, dass die beschriebene GPT-3-Architektur von der tatsächlichen Implementierung abweichen kann. Sie können sicher erst sagen, nachdem Sie sich mit den Trainingsparametern vertraut gemacht haben, und wenn die Gewichte vor der Veröffentlichung mit Verzögerung veröffentlicht wurden, können sie angesichts der jüngsten Ereignisse nicht erwartet werden.
Tatsache ist, dass das Projektbudget von der Anzahl der Schulungsparameter abhängt und Experten zufolge die GPT-3-Schulung mindestens 10 Millionen US-Dollar kostet. Daher können nur große Unternehmen mit starken ML-Spezialisten und leistungsstarken Computerressourcen die Arbeit von OpenAI reproduzieren.
Stand des AI-Berichts 2020
All dies bestätigt die Schlussfolgerungen des dritten Jahresberichts zum aktuellen Stand der Dinge im Bereich des maschinellen Lernens. Nathan Benaich und Ian Hogarth, Investoren, die sich auf AI-Startups spezialisiert haben, haben eine detaillierte Präsentation veröffentlicht, die sich mit Technologie, Humanressourcen, industriellen Anwendungen und rechtlichen Komplikationen befasst.
Seltsamerweise werden 85% der Forschung ohne Quellcode veröffentlicht. Wenn kommerzielle Organisationen durch die Tatsache gerechtfertigt werden können, dass Code häufig in die Infrastruktur von Projekten eingebunden ist, was ist dann mit Forschungseinrichtungen und gemeinnützigen Unternehmen wie DeepMind und OpenAI?
Es wird auch gesagt, dass eine Zunahme von Datensätzen und Modellen zu einer Zunahme von Budgets führt, und da der Bereich des maschinellen Lernens stagniert, erfordert jeder neue Durchbruch unverhältnismäßig große Budgets (vergleiche die Größe von GPT-2 und GPT-3), was bedeutet, dass sie es sich leisten können nur große Unternehmen.
Wir empfehlen Ihnen, sich mit diesem Dokument vertraut zu machen, da es präzise und klar geschrieben und gut illustriert ist. Außerdem haben sich bereits vier Prognosen für 2020 aus dem letzten Bericht bewahrheitet.
Wir werden nicht weiter übertreiben, es gibt immer noch gute Geschichten, sonst würde diese Sammlung nicht existieren.
Öffnen Sie mehrsprachige Modelle von Google und Facebook
mT5
Google hat den Quellcode und den Datensatz der T5-Familie mehrsprachiger Modelle veröffentlicht. Aufgrund des mit OpenAI verbundenen Hype blieben diese Nachrichten trotz der beeindruckenden Größenordnung fast unbemerkt - das größte Modell hat 13 Milliarden Parameter.
Für das Training wurde ein Datensatz von 101 Sprachen verwendet, von denen Russisch an zweiter Stelle steht. Dies kann durch die Tatsache erklärt werden, dass unser großer und mächtiger Ort der zweitbeliebteste Ort im Internet ist.
M2M-100
Facebook ist auch nicht weit dahinter und hat ein mehrsprachiges Modell entwickelt , das nach ihren Aussagen die direkte Übersetzung von 100x100 Sprachpaaren ohne Zwischensprache ermöglicht.
Im Bereich der maschinellen Übersetzung ist es üblich, Modelle für jede einzelne Sprache und Aufgabe zu erstellen und zu trainieren. Bei Facebook ist dieser Ansatz jedoch nicht effektiv skalierbar, da Benutzer des sozialen Netzwerks Inhalte in mehr als 160 Sprachen veröffentlichen.
In der Regel sind mehrsprachige Systeme, die mehrere Sprachen gleichzeitig verarbeiten, auf Englisch angewiesen. Die Übersetzung ist vermittelt und ungenau. Die Überbrückung der Lücke zwischen Quell- und Zielsprache ist aufgrund unzureichender Daten schwierig, da es sehr schwierig sein kann, eine Übersetzung vom Chinesischen ins Französische und umgekehrt zu finden. Dazu mussten die Ersteller synthetische Daten durch umgekehrte Übersetzung generieren.
Der Artikel bietet Benchmarks, das Modell kommt besser mit Übersetzungen zurecht als Analoga, die auf Englisch basieren, sowie einen Link zum Datensatz .

Fortschritte bei Videokonferenzen
Im Oktober erschienen sofort einige interessante Neuigkeiten aus Nvidia.
StyleGAN2
Zuerst haben wir Updates für StyleGAN2 veröffentlicht . Die ressourcenarme Modellarchitektur bietet jetzt eine verbesserte Leistung für Datensätze mit weniger als 30.000 Bildern. Die neue Version bietet Unterstützung für gemischte Präzision: Training ~ 1,6-fach beschleunigt, Inferenz ~ 1,3-fach, GPU-Verbrauch ~ 1,5-fach gesunken. Wir haben auch eine automatische Auswahl von Modellhyperparametern hinzugefügt: vorgefertigte Lösungen für Datensätze mit unterschiedlichen Auflösungen und eine unterschiedliche Anzahl verfügbarer Grafikprozessoren.
NeMo
Neural Modules ist ein Open Source-Toolkit , mit dem Sie schnell Konversationsmodelle erstellen, trainieren und optimieren können. NeMo besteht aus einem Kern, der ein einheitliches Erscheinungsbild für alle Modelle und Kollektionen bietet und aus Modulen besteht, die nach Umfang gruppiert sind.
Maxine
Ein anderes angekündigtes Produkt wird wahrscheinlich beide oben genannten Technologien intern verwenden. Die Maxine-Videoanrufplattform kombiniert einen ganzen Zoo von ML-Algorithmen. Dies beinhaltet die bereits bekannte Verbesserung der Auflösung, die Beseitigung von Rauschen, das Entfernen des Hintergrunds, aber auch die Korrektur von Blick und Schatten, die Wiederherstellung des Bildes durch wichtige Gesichtsmerkmale (dh Deepfakes), die Erzeugung von Untertiteln und die Übersetzung von Sprache in andere Sprachen in Echtzeit. Das heißt, fast alles, was zuvor separat angetroffen wurde, hat Nvidia zu einem digitalen Produkt zusammengefasst. Sie können jetzt Early Access beantragen.
Neue Entwicklungen von Google
Aufgrund der Quarantäne gibt es in diesem Jahr einen echten Wettlauf um die Führung im Bereich Videokonferenzen. Google Meet hat eine Fallstudie zur Erstellung eines Algorithmus zur hochwertigen Hintergrundentfernung auf der Grundlage des Mediapipe-Frameworks (das die Bewegung von Augen, Kopf und Händen verfolgen kann) veröffentlicht.
Google hat außerdem eine neue Funktion für den YouTube Stories-Dienst unter iOS eingeführt, die die Sprachqualität verbessert. Dies ist ein interessanter Fall , da für Video viel mehr Enhancer verfügbar sind als für Audio. Dieser Algorithmus verfolgt und zeichnet Korrelationen zwischen Sprache und visuellen Markierungen wie Gesichtsausdrücken und Lippenbewegungen auf, die dann verwendet werden, um Sprache von Hintergrundgeräuschen zu trennen, einschließlich Stimmen von anderen Sprechern.
Das Unternehmen präsentierte auch einen neuen Versuchim Bereich der Gebärdenspracherkennung.
In Bezug auf Videokonferenzsoftware sind auch die neuen Deepfake-Algorithmen zu erwähnen.
MakeItTalk
Kürzlich wurde der Code des Algorithmus , der das Foto animiert und sich ausschließlich auf den Audiostream stützt, im Open Access veröffentlicht . Dies ist bemerkenswert, da normalerweise Deepfake-Algorithmen Video als Eingabe verwenden.

Unglaublich
Die neue Generation von Deepfake-Algorithmen stellt sich die Aufgabe, nicht nur das Gesicht, sondern den gesamten Körper zu ersetzen, einschließlich Haarfarbe, Hautton und Figur. Diese Technologie wird vor allem im Bereich des Online-Shoppings eingesetzt, so dass Produktfotos der Marke selbst verwendet werden können, ohne dass einzelne Modelle angeheuert werden müssen. Weitere Anwendungen finden Sie in der Videodemo . Bisher sieht es nicht überzeugend aus, aber bald kann sich alles ändern.
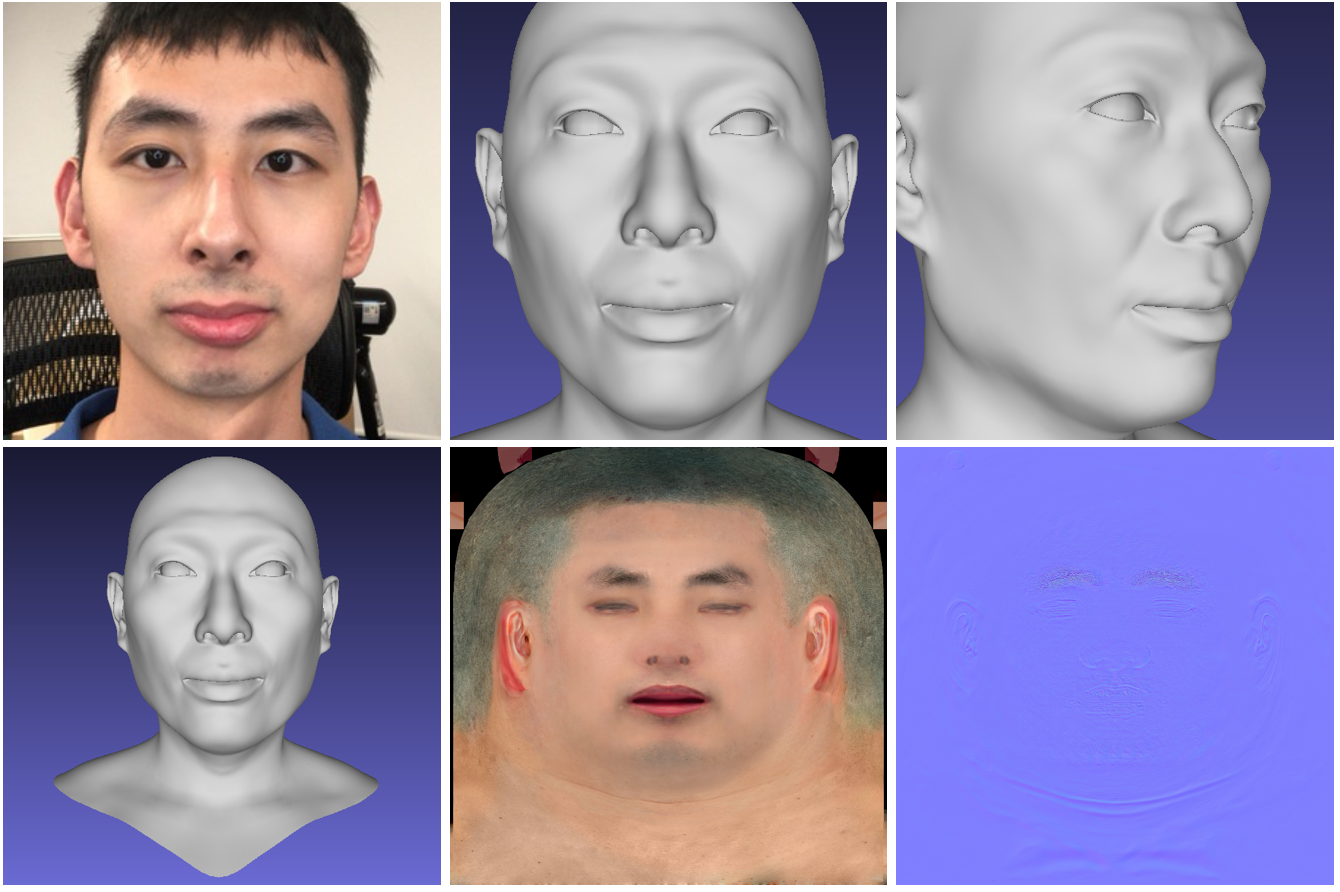
Hi-Fi 3D-Gesicht
Das neuronale Netzwerk generiert aus Fotos ein hochwertiges 3D-Modell des Gesichts einer Person. Das Modell empfängt als Eingabe ein kurzes Video von einer normalen RGB-D-Kamera und am Ausgang ein generiertes 3D-Modell des Gesichts. Der Projektcode und das 3DMM-Modell sind öffentlich verfügbar .

SkyAR
Die Autoren präsentierten eine Open-Source-Technologie , um den Himmel in Echtzeit durch Video zu ersetzen, mit der Sie auch die Stile steuern können. Auf dem Zielvideo können Wettereffekte wie Blitze erzeugt werden.
Das Pipeline-Modell löst eine Reihe von Aufgaben schrittweise: Das Raster verfilzt den Himmel, verfolgt sich bewegende Objekte, umhüllt das Bild und malt es neu, damit es dem Skybox-Farbschema entspricht.

Sea-thru
Das Tool löst die ungewöhnliche Aufgabe, echte Farben in Unterwasserfotos wiederherzustellen. Das heißt, der Algorithmus berücksichtigt die Tiefe und Entfernung zu Objekten, um die Beleuchtung wiederherzustellen und Wasser aus den Bildern zu entfernen. Bisher sind nur Datensätze verfügbar.
MIT-Modell zur Diagnose von Covid-19
Abschließend werden wir einen interessanten Fall zu einem relevanten Thema vorstellen - MIT-Forscher haben ein Modell entwickelt, das asymptomatische Patienten mit Coronavirus-Infektion von gesunden Menschen anhand von Zwangs-Husten-Aufzeichnungen unterscheidet.
Das Modell wurde auf Zehntausenden von Tonbändern mit Hustenproben trainiert. Laut MIT identifiziert der Algorithmus Personen, bei denen Covid-19 bestätigt wurde, mit einer Genauigkeit von 98,5%.
Die Regierungsbehörden haben die Erstellung des Antrags bereits genehmigt. Der Benutzer kann eine Audioaufnahme seines Hustens herunterladen und anhand des Ergebnisses feststellen, ob eine vollständige Analyse im Labor erforderlich ist.
Das ist alles, danke für Ihre Aufmerksamkeit!