Bob Steagall hielt kürzlich auf der CppCon 2020 einen Vortrag mit dem Titel " Abenteuer im SIMD-Denken ", in dem er unter anderem über seine Erfahrungen mit der Verwendung von AVX512 für die Medianfilterung mit Fenster 7 sprach. Dieser Vortrag verursachte zwei Gefühle: Einerseits ist es cool und behauptete fast 20x Geschwindigkeit im Vergleich zur "dümmsten" STL-Implementierung; Andererseits stellte sich in einem Durchgang des Algorithmus aus 16 Eingabebeispielen nur 2 Ausgaben heraus, obwohl die Eingabedaten für 10 ausreichten, und einige Implementierungsdetails veranlassten mich, zu versuchen, sie zu verbessern. Ich dachte, dachte und kam auf eine Idee, dann auf eine andere, probierte sie dann "in Software" aus und erkannte, dass ich etwas zu teilen hatte :) Und so stellte sich dieser Artikel heraus.
Grundlegende Implementierung
Ich werde kurz beschreiben, wie es von Bob gemacht wurde (in der Tat eine kurze Nacherzählung des entsprechenden Teils seiner Geschichte, zusammen mit seinen eigenen Bildern). Er hat die folgenden Grundelemente mit AVX512 erstellt (ich werde diejenigen der von ihm beschriebenen Grundelemente weglassen, die direkt der einzigen AVX512-Operation entsprechen):
drehen: Drehen Sie die Elemente im AVX-512-Register in einem Kreis

Shift with Carry : Verschiebt Elemente aus einem Register und ersetzt Elemente aus einem zweiten Register
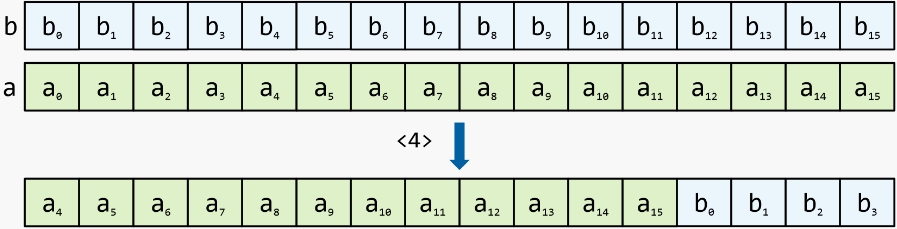
In-Place-Shift mit Carry : Wie Shift mit Carry, aber die Eingangsregister werden als Referenz übergeben und das Ergebnis der Shift bleibt in ihnen
Vergleiche mit Austausch : Parallele Sortierung von bis zu 8 Elementpaaren in einem Register

, , : perm 0..15, ; mask 1 «» . : , perm. vmin , vmax ́ . , .
, , . :
1) shift with carry, «» , «» (.. 0 0..6, 1 — 1..7 . .)
2) , 0 , 1 —
3) 7 , — 6 compare and exchange, . — — .
0
- , . , , ( , L2). , . AVX-512…
1
, — . 7 ; 6 !

, 6 r1-r6 , r0 r7? S[0..5], X, , S[3] .
X >= S[3], S[3] ,X <= S[2], S[2] S[3], S[2]S[2] < X < S[3], X S[3], , X. ,clamp(X, S[2], S[3])=>min(max(X, S[2]), S[3])!
:
«» 4 7- ( 0, 7, 2, 9) – X 4
6- 1..6 3..8 ( 0..7 8..15, )
6-
clamp 2 3 X[0] X[1], 2 3 X[2] X[3]
2x — 2 ( 6 5 , 7 — 6), clamp . : 1,86x . . ?
2
«» X . 6- ; 5 , 2 ( 3 ). — : S[0] <=> S[1], S[2] <=> S[3], S[4] <=> S[5]
2, . . , , !

— 2 , 2 . , : 1.06x. , .
3
- , 1, 6- .

, 4 ( ), 6; , 4- ?
2 , 4- . 6- : 2- Y 4- S, 2 3 ( Z). , min(Y[0], S[0]) => Z[0], ; max(Y[0], S[0]) Z[1]..Z[5] – . max(Y[1], S[3]) , min(Y[1], S[3]).
4- S[1], S[2], min/max. , 4 , 1 2 — 2 3 6- . , «» 4- S[1] S[2], — . , 2 , Y.
:
r1-r2 . .
— Y, r1-2, r5-6, r7-8, r11-12; permute 4 , Y r0-1, r4-5 . .
( ) «» ; r3-r6 r7-r10
max min Y[0]/S[0], Y[1]/S[3]
mask_permute Y S, S[1] S[2] ,
4
1 2, min/max X 8
, , , 2. — 1.64x , 2, 3 , .
; ( - permute; , - ), .
, :)
benchmark:
512 : 3.1-3.2 ; 7.3 , memcpy avx-512
50 : 2.8-2.9 ; 1.8 , memcpy (!)
.
5? , (disclaimer: — ).
16- 12 .
- 3 ( …)
1 , 4 ( 6 ) 4- — , . . 4 , 5 ; 8 .
2 , — 2 ; , .
3 , . , — , 12 . , «» — 24 , 12 .
9? 8 .
—
1 — 2 8- 4 , 4 ( 7 6 )
2 — , -
3 — , — 6- 2, 6- ( , ) , 8-.
, - . , https://github.com/tea/avx-median/. « », , -. , .
- , — . .
UPDATE
AVX2 . , , , , ( , 16 , ). , : 1.64x , .
Es stellte sich heraus, dass nicht alles verloren geht - der erste Optimierungsschritt kann auch auf diese Variante angewendet werden! Es ist notwendig, 32 Kanten von X zu sammeln, es ist notwendig, die Daten zum Sortieren durcheinander zu bringen, die sortierten Daten müssen auch permutiert sein usw., aber trotz all dieser Gesten beträgt die Beschleunigung das 1,27-fache.
Ich habe nicht versucht, die Schritte 2 und 3 auszuführen, da dies offensichtlich langsamer sein wird. Es ist durchaus möglich, dass sie für den Fall mit beispielsweise Fenster 11 in einem Plus arbeiten (aber ich weiß nicht, ob jemand einen schnellen 1D-Medianfilter mit großen Fenstern benötigt).