Verwenden der CUDA Runtime API für Computing. Vergleich von CPU- und GPU-Computing
In diesem Artikel habe ich beschlossen, die Ausführung eines in C ++ auf einer CPU und einer GPU geschriebenen Algorithmus zu vergleichen (Berechnungen mit der Nvidia CUDA Runtime API auf einer unterstützten Nvidia GPU durchzuführen). Mit der CUDA-API können einige Berechnungen auf der GPU durchgeführt werden. Eine c ++ - Datei mit cuda hat die Erweiterung .cu .
Der Algorithmus ist unten gezeigt.
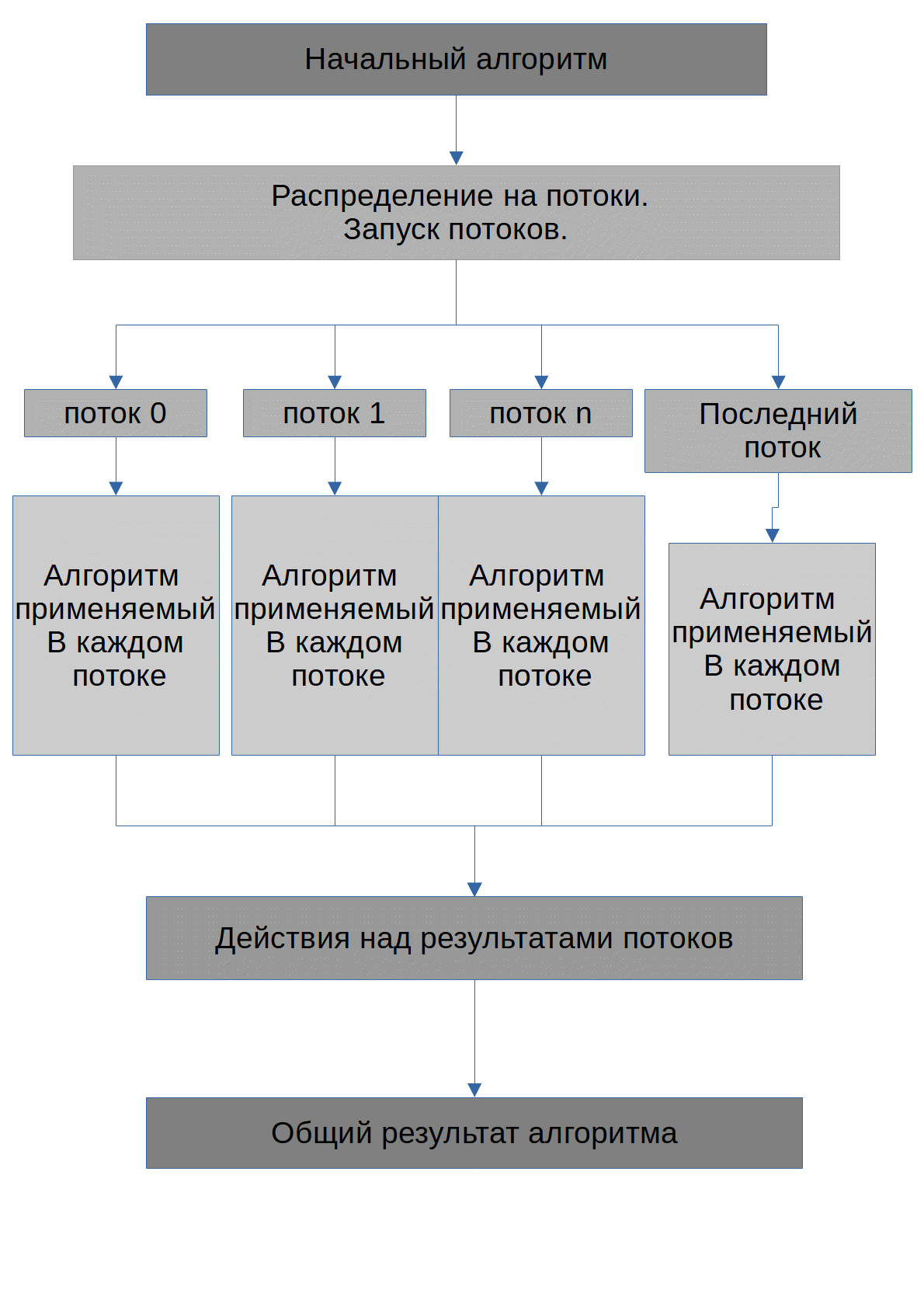
Die Aufgabe des Algorithmus besteht darin, die möglichen Zahlen X zu finden, wenn sie auf den Grad grad_of angehoben werden, wird die Anfangszahl max_number erhalten. Ich stelle sofort fest, dass alle Nummern, die an die GPU übertragen werden, in Arrays gespeichert werden. Der von jedem Thread ausgeführte Algorithmus sieht folgendermaßen aus:
int degree_of=2;
int degree_of_max=Number_degree_of_max[0];//
int x=thread;//
int max_number=INPUT[0];// ,
int Number=1;
int Degree;
bool BREAK=false;// while
while(degree_of<=degree_of_max&&!BREAK){
Number=1;
for(int i=0;i<degree_of;i++){
Number*=x;
Degree=degree_of;
}
if(Number==max_number){
OUT_NUMBER[thread]=X;//OUT_NUMBER Degree
OUT_DEGREE[thread]=Degree;// OUT_DEGREE X
}
degree_of++;
// :
if(degree_of>degree_of_max||Number>max_number){
BREAK=true;
}
}
Code, der auf CPU C ++ ausgeführt werden soll. Cpp
#include <iostream>
#include<vector>
#include<string>// getline
#include<thread>
#include<fstream>
using namespace std;
int Running_thread_counter = 0;
void Upload_to_CPU(unsigned long long *Number, unsigned long long *Stepn, bool *Stop,unsigned long long *INPUT, unsigned long long *max, int THREAD);
void Upload_to_CPU(unsigned long long *Number, unsigned long long *Stepn, bool *Stop,unsigned long long *INPUT, unsigned long long *max, int THREAD) {
int thread = THREAD;
Running_thread_counter++;
unsigned long long MAX_DEGREE_OF = max[0];
int X = thread;
unsigned long long Calculated_number = 1;
unsigned long long DEGREE_OF = 2;
unsigned long long INP = INPUT[0];
Stop[thread] = false;
bool BREAK = false;
if (X != 0 && X != 1) {
while (!BREAK) {
if (DEGREE_OF <= MAX_DEGREE_OF) {
Calculated_number = 1;
for (int counter = 0; counter < DEGREE_OF; counter++) {
Calculated_number *= X;
}
if (Calculated_number == INP) {
Stepn[thread] = DEGREE_OF;
Number[thread] = X;
Stop[thread] = true;
BREAK = true;
}
DEGREE_OF++;
}
else { BREAK = true; }
}
}
}
void Parallelize_to_threads(unsigned long long *Number, unsigned long long *Stepn, bool *Stop,unsigned long long *INPUT, unsigned long long *max, int size);
int main()
{
int size = 1000;
unsigned long long *Number = new unsigned long long[size], *Degree_of = new unsigned long long[size];
unsigned long long *Max_Degree_of = new unsigned long long[1];
unsigned long long *INPUT_NUMBER = new unsigned long long[1];
Max_Degree_of[0] = 7900;
INPUT_NUMBER[0] = 216 * 216 * 216;
ifstream inp("input.txt");
if (inp.is_open()) {
string t;
vector<unsigned long long>IN;
while (getline(inp, t)) {
IN.push_back(stol(t));
}
INPUT_NUMBER[0] = IN[0];//
Max_Degree_of[0] = IN[1];//
}
else {
ofstream error("error.txt");
if (error.is_open()) {
error << "No file " << '"' << "input.txt" << '"' << endl;
error << "Please , create a file" << '"' << "input.txt" << '"' << endl;
error << "One read:input number" << endl;
error << "Two read:input max stepen" << endl;
error << "." << endl;
error.close();
INPUT_NUMBER[0] = 1;
Max_Degree_of[0] = 1;
}
}
// ,
//cout << INPUT[0] << endl;
bool *Elements_that_need_to_stop = new bool[size];
Parallelize_to_threads(Number, Degree_of, Elements_that_need_to_stop, INPUT_NUMBER, Max_Degree_of, size);
vector<unsigned long long>NUMBER, DEGREEOF;
for (int i = 0; i < size; i++) {
if (Elements_that_need_to_stop[i]) {
if (Degree_of[i] < INPUT_NUMBER[0] && Number[i] < INPUT_NUMBER[0]) {//
NUMBER.push_back(Number[i]);
DEGREEOF.push_back(Degree_of[i]);
}
}
}
// ,
//
/*
for (int f = 0; f < NUMBER.size(); f++) {
cout << NUMBER[f] << "^" << DEGREEOF[f] << "=" << INPUT_NUMBER[0] << endl;
}
*/
ofstream out("out.txt");
if (out.is_open()) {
for (int f = 0; f < NUMBER.size(); f++) {
out << NUMBER[f] << "^" << DEGREEOF[f] << "=" << INPUT_NUMBER[0] << endl;
}
out.close();
}
}
void Parallelize_to_threads(unsigned long long *Number, unsigned long long *Stepn, bool *Stop,unsigned long long *INPUT, unsigned long long *max, int size) {
thread *T = new thread[size];
Running_thread_counter = 0;
for (int i = 0; i < size; i++) {
T[i] = thread(Upload_to_CPU, Number, Stepn, Stop, INPUT, max, i);
T[i].detach();
}
while (Running_thread_counter < size - 1);//
}
Damit der Algorithmus funktioniert, ist eine Textdatei mit einer Anfangsnummer und einem maximalen Grad erforderlich.
Code für die GPU-Berechnung C ++. Cu
// cuda_runtime.h device_launch_parameters.h
// cyda
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include<vector>
#include<string>// getline
#include <stdio.h>
#include<fstream>
using namespace std;
__global__ void Upload_to_GPU(unsigned long long *Number,unsigned long long *Stepn, bool *Stop,unsigned long long *INPUT,unsigned long long *max) {
int thread = threadIdx.x;
unsigned long long MAX_DEGREE_OF = max[0];
int X = thread;
unsigned long long Calculated_number = 1;
unsigned long long Current_degree_of_number = 2;
unsigned long long Original_numberP = INPUT[0];
Stop[thread] = false;
bool BREAK = false;
if (X!=0&&X!=1) {
while (!BREAK) {
if (Current_degree_of_number <= MAX_DEGREE_OF) {
Calculated_number = 1;
for (int counter = 0; counter < Current_degree_of_number; counter++) {
Calculated_number *=X;
}
if (Calculated_number == Original_numberP) {
Stepn[thread] = Current_degree_of_number;
Number[thread] = X;
Stop[thread] = true;
BREAK = true;
}
Current_degree_of_number++;
}
else { BREAK = true; }
}
}
}
cudaError_t Configure_cuda(unsigned long long *Number, unsigned long long *Stepn, bool *Stop,unsigned long long *INPUT, unsigned long long *max,unsigned int size);
int main()
{
int size = 1000;
unsigned long long *Number=new unsigned long long [size], *Degree_of=new unsigned long long [size];
unsigned long long *Max_degree_of = new unsigned long long [1];
unsigned long long *INPUT_NUMBER = new unsigned long long [1];
Max_degree_of[0] = 7900;
ifstream inp("input.txt");
if (inp.is_open()) {
string text;
vector<unsigned long long>IN;
while (getline(inp, text)) {
IN.push_back( stol(text));
}
INPUT_NUMBER[0] = IN[0];
Max_degree_of[0] = IN[1];
}
else {
ofstream error("error.txt");
if (error.is_open()) {
error<<"No file "<<'"'<<"input.txt"<<'"'<<endl;
error<<"Please , create a file" << '"' << "input.txt" << '"' << endl;
error << "One read:input number" << endl;
error << "Two read:input max stepen" << endl;
error << "." << endl;
error.close();
INPUT_NUMBER[0] = 1;
Max_degree_of[0] = 1;
}
}
bool *Elements_that_need_to_stop = new bool[size];
// cuda
cudaError_t cudaStatus = Configure_cuda(Number, Degree_of, Elements_that_need_to_stop, INPUT_NUMBER, Max_degree_of, size);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addWithCuda failed!");
return 1;
}
vector<unsigned long long>NUMBER, DEGREEOF;
for (int i = 0; i < size; i++) {
if (Elements_that_need_to_stop[i]) {
NUMBER.push_back(Number[i]);//
DEGREEOF.push_back(Degree_of[i]);//
}
}
// ,
/*
for (int f = 0; f < NUMBER.size(); f++) {
cout << NUMBER[f] << "^" << DEGREEOF[f] << "=" << INPUT_NUMBER[0] << endl;
}*/
ofstream out("out.txt");
if (out.is_open()) {
for (int f = 0; f < NUMBER.size(); f++) {
out << NUMBER[f] << "^" << DEGREEOF[f] << "=" << INPUT_NUMBER[0] << endl;
}
out.close();
}
//
cudaStatus = cudaDeviceReset();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceReset failed!");
return 1;
}
return 0;
}
cudaError_t Configure_cuda(unsigned long long *Number, unsigned long long *Degree_of, bool *Stop,unsigned long long *INPUT, unsigned long long *max,unsigned int size) {
unsigned long long *dev_Number = 0;
unsigned long long *dev_Degree_of = 0;
unsigned long long *dev_INPUT = 0;
unsigned long long *dev_Max = 0;
bool *dev_Elements_that_need_to_stop;
cudaError_t cudaStatus;
// GPU
cudaStatus = cudaSetDevice(0);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");
goto Error;
}
//
cudaStatus = cudaMalloc((void**)&dev_Number, size * sizeof(unsigned long long));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!dev_Number");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_Degree_of, size * sizeof(unsigned long long));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!dev_Degree_of");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_Max, size * sizeof(unsigned long long int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!dev_Max");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_INPUT, size * sizeof(unsigned long long));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!dev_INPUT");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_Elements_that_need_to_stop, size * sizeof(bool));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!dev_Stop");
goto Error;
}
// GPU
cudaStatus = cudaMemcpy(dev_Max, max, size * sizeof(unsigned long long), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
cudaStatus = cudaMemcpy(dev_INPUT, INPUT, size * sizeof(unsigned long long), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
Upload_to_GPU<<<1, size>>>(dev_Number, dev_Degree_of, dev_Elements_that_need_to_stop, dev_INPUT, dev_Max);
//
cudaStatus = cudaGetLastError();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addKernel launch failed: %s\n", cudaGetErrorString(cudaStatus));
goto Error;
}
// ,
cudaStatus = cudaDeviceSynchronize();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceSynchronize returned error code %d after launching addKernel!\n", cudaStatus);
goto Error;
}
// GPU
cudaStatus = cudaMemcpy(Number, dev_Number, size * sizeof(unsigned long long), cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
cudaStatus = cudaMemcpy(Degree_of, dev_Degree_of, size * sizeof(unsigned long long), cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
cudaStatus = cudaMemcpy(Stop, dev_Elements_that_need_to_stop, size * sizeof(bool), cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
Error:// GPU
cudaFree(dev_INPUT);
cudaFree(dev_Degree_of);
cudaFree(dev_Max);
cudaFree(dev_Elements_that_need_to_stop);
cudaFree(dev_Number);
return cudaStatus;
}
Kennung
__global__ Um mit der CUDA-API arbeiten zu können, müssen Sie vor dem Aufrufen der Funktion Speicher für das Array reservieren und die Elemente in den GPU-Speicher übertragen. Dies erhöht die Codemenge, ermöglicht jedoch das Auslagern der CPU, da die Berechnungen auf der GPU ausgeführt werden. Daher bietet cuda zumindest die Möglichkeit, den Prozessor für andere Workloads auszulagern, die cuda nicht verwenden.
Im Fall des cuda-Beispiels besteht die Aufgabe des Prozessors nur darin, Anweisungen auf die GPU zu laden und die von der GPU stammenden Ergebnisse zu verarbeiten. Im Code für die CPU verarbeitet der Prozessor jeden Thread. Es ist erwähnenswert, dass cyda Einschränkungen hinsichtlich der Anzahl der Threads hat, die gestartet werden können. Daher habe ich in beiden Algorithmen die gleiche Anzahl von Threads gleich 1000 verwendet. Auch im Fall der CPU habe ich die Variable verwendet
int Running_thread_counter = 0;um die Anzahl der bereits ausgeführten Threads zu zählen und zu warten, bis alle Threads ausgeführt wurden.
Testkonfiguration
CUDA GPU-Z
- CPU :amd ryzen 5 1400(4core,8thread)
- :8DDR4 2666
- GPU:Nvidia rtx 2060
- OS:windows 10 version 2004
- Cuda:
- Compute Capability 7.5
- Threads per Multiprocessor 1024
- CUDA 11.1.70
- GPU-Z:version 2.35.0
- Visual Studio 2017
CUDA GPU-Z
Um den Algorithmus zu testen, habe ich verwendet
den folgenden C # -Code
, die eine Datei mit Anfangsdaten erstellte, dann nacheinander exe-Dateien von Algorithmen unter Verwendung von CPU oder GPU startete und die Zeit ihres Betriebs maß, dann diese Zeit und die Ergebnisse der Algorithmen in die Datei result.txt eingab . Der Windows Task Manager wurde verwendet, um die Prozessorlast zu messen .
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Diagnostics;
using System.IO;
namespace ConsoleAppTESTSTEPEN_CPU_AND_GPU_
{
class Program
{
static string Upload(Int64 number,Int64 degree_of)
{
string OUT = "";
string[] Chord_values = new string[2];
Int64 Degree_of = degree_of;
Int64 Number = number;
Chord_values[0] = Number.ToString();
Chord_values[1] = Degree_of.ToString();
File.WriteAllLines("input.txt", Chord_values);//
OUT+="input number:" + Number.ToString()+"\n";
OUT+="input degree of number:" + Degree_of.ToString()+"\n";
DateTime running_CPU_application = DateTime.Now;//
Process proc= Process.Start("ConsoleApplication29.exe");//exe c++ x64 CPU
while (!proc.HasExited) ;//
DateTime stop_CPU_application = DateTime.Now;//
string[]outs = File.ReadAllLines("out.txt");//
File.Delete("out.txt");
OUT+="CPU:"+"\n";
if (outs.Length>0)
{
for (int j = 0; j < outs.Length; j++)
{
OUT+=outs[j]+"\n";
}
}
else { OUT+="no values"+"\n"; }
OUT+="running_CPU_application:" + running_CPU_application.ToString()+"\n";
OUT+="stop_CPU_application:" + stop_CPU_application.ToString()+"\n";
OUT+="GPU:"+"\n";
// korenXN.exe x64 GPU
DateTime running_GPU_application = DateTime.Now;
Process procGPU = Process.Start("korenXN.exe");
while (!procGPU.HasExited) ;
DateTime stop_GPU_application = DateTime.Now;
string[] outs2 = File.ReadAllLines("out.txt");
File.Delete("out.txt");
if (outs2.Length > 0)
{
for (int j = 0; j < outs2.Length; j++)
{
OUT+=outs2[j]+"\n";
}
}
else { OUT+="no values"+"\n"; }
OUT+="running_GPU_application:" + running_GPU_application.ToString()+"\n";
OUT+="stop_GPU_application:" + stop_GPU_application.ToString()+"\n";
return OUT;//
}
static void Main()
{
Int64 start = 36*36;//
Int64 degree_of_strat = 500;//
int size = 20-5;//
Int64[] Number = new Int64[size];//
Int64[] Degree_of = new Int64[size];//
string[]outs= new string[size];//
for (int n = 0; n < size; n++)
{
if (n % 2 == 0)
{
Number[n] = start * start;
}
else
{
Number[n] = start * degree_of_strat;
Number[n] -= n + n;
}
start += 36*36;
Degree_of[n] = degree_of_strat;
degree_of_strat +=1000;
}
for (int n = 0; n < size; n++)
{
outs[n] = Upload(Number[n], Degree_of[n]);
Console.WriteLine(outs[n]);
}
System.IO.File.WriteAllLines("result.txt", outs);// result.txt
}
}
}
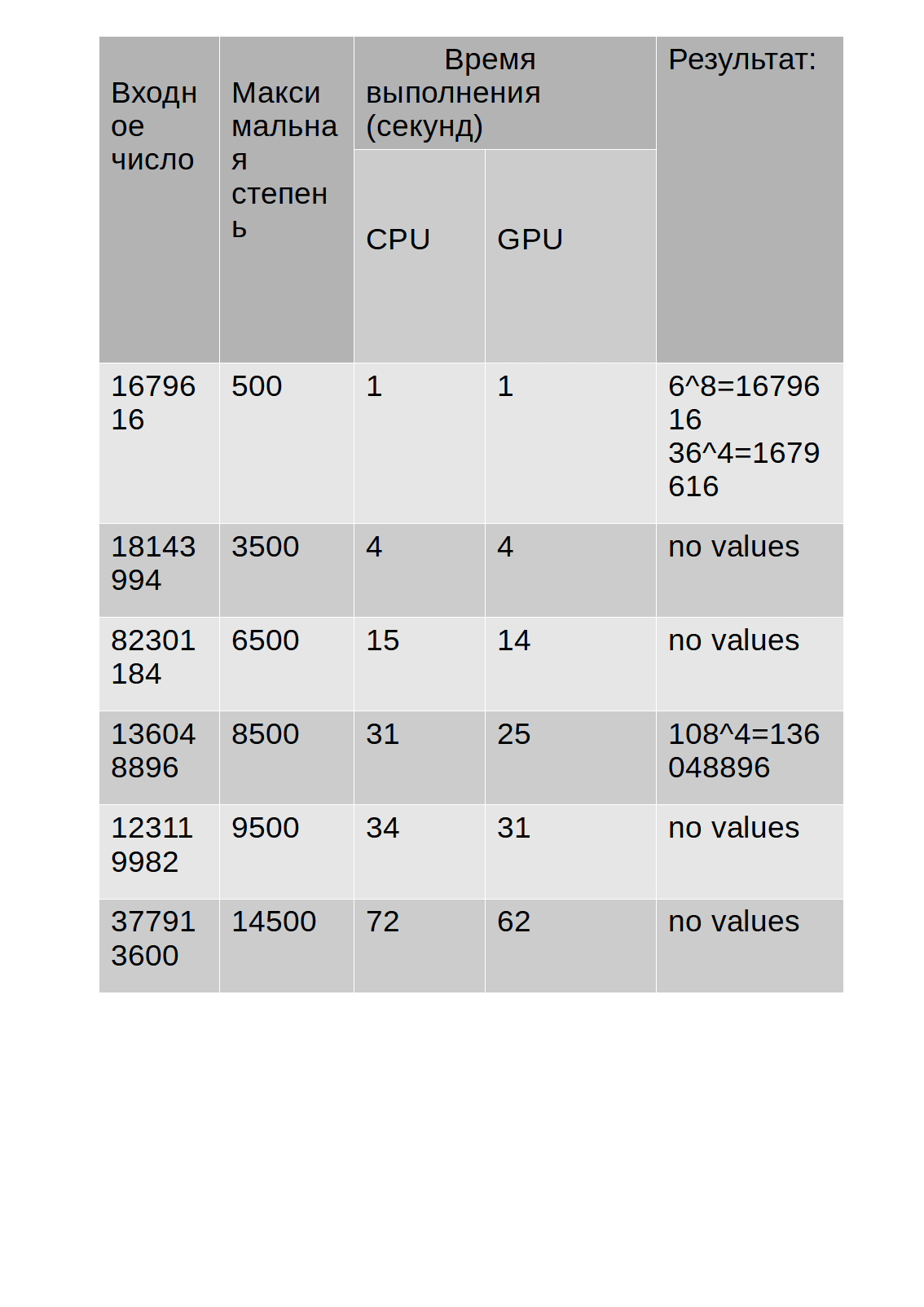
Die Testergebnisse sind in der Tabelle aufgeführt:

Wie Sie der Tabelle entnehmen können, ist die Ausführungszeit des Algorithmus auf der GPU etwas länger als auf der CPU.
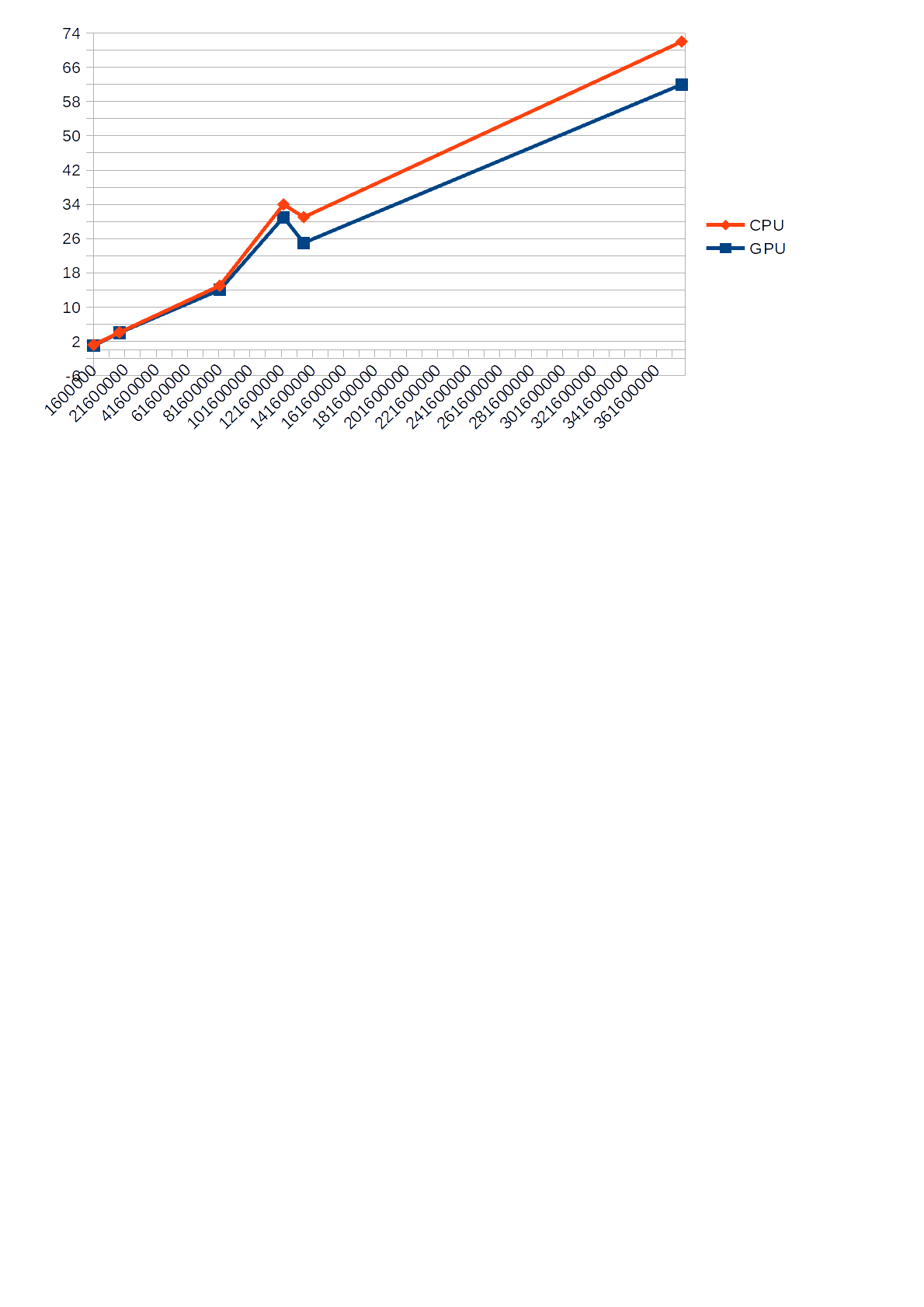
Ich stelle jedoch fest, dass während des Betriebs des Algorithmus, der die GPU für Berechnungen verwendet, die im Task-Manager angezeigte CPU-Auslastung 30% nicht überstieg, während der Algorithmus, der die CPU für Berechnungen verwendet, sie um 68-85% belastetewas wiederum manchmal andere Anwendungen verlangsamte. Unten sehen Sie ein Diagramm, das den Unterschied in der
Ausführungszeit (Y-Achse) der CPU und der GPU gegenüber der Eingangsnummer (X-Achse) zeigt.
Zeitplan

Dann habe ich beschlossen, mit dem Prozessor zu testen, der mit anderen Anwendungen geladen ist. Der Prozessor wurde geladen, sodass der in der Anwendung gestartete Test nicht mehr als 55% der Ressourcen des Prozessors beanspruchte. Die Testergebnisse sind unten gezeigt:
Zeitplan
Wie im Falle eines beladenen CPU aus der Tabelle ersichtlich ist, gibt, eine Leistungssteigerung auf einer GPU Berechnungen , da eine Prozessorauslastung von 30% in der 55% -Grenze liegt, und im Falle einer CPU für die Berechnungen verwendet wird , dessen Last ist 68-85% , was verlangsamt den Betrieb des Algorithmus, wenn die CPU mit anderen Anwendungen geladen ist.
Der Grund, warum die GPU meiner Meinung nach hinter der CPU zurückbleibt, kann sein, dass die CPU eine höhere Kernleistung aufweist (3400-MHz-CPU, 1680-MHz-GPU). Wenn die Prozessorkerne mit anderen Prozessen geladen werden, hängt die Leistung von der Anzahl der in einem bestimmten Zeitintervall verarbeiteten Threads ab. In diesem Fall ist die GPU schneller, da mehr Threads gleichzeitig verarbeitet werden können (1024 GPU, 8 CPU).
Wir können daher den Schluss ziehen, dass die Verwendung der GPU für Berechnungen nicht unbedingt zu einem schnelleren Betrieb des Algorithmus führen muss, sondern die CPU entladen kann, was eine Rolle spielen kann, wenn sie mit anderen Anwendungen geladen wird.
Ressourcen: