EXPLAIN (ANALYZE, BUFFERS) ...Ihr bevorzugtes Werkzeug sind, um die Besonderheiten dieses DBMS kennenzulernen , sind neue nützliche "Chips" unseres Dienstes zur Visualisierung und Analyse von Plänen EXPLAIN.tensor.ru bei dieser schwierigen Aufgabe sicherlich hilfreich .
Aber ich möchte Sie sofort daran erinnern, dass ohne eine umfassende Überwachung der PostgreSQL-Datenbank nur die Plananalyse von der Position des Weisen Nr. 5 aus erfolgt!

[ Quelle KDPV , "Die Blinden und der Elefant" ]
, 1940
, ,
.
,
,
, .
, —
.
,
:
—
!
,
,
, ,
.
,
,
,
.
Streit entstand unter den Blinden
und dauerte ein ganzes Jahr.
Dann
bewegten die Blinden endlich ihre Hände.
Und da der fünfte stark war,
- schloss er den Mund aller.
Und jetzt besteht der Elefant aus
einem Schwanz!
Also, heute im Programm:
- Ändern Sie "Chevrons" in "Schultergurte"
- Wir bringen "Mega" -Pläne zusammen
- Wir führen ein persönliches Archiv
- Studium der Genealogie von Plänen
- Blick in die "Fenster"
Keine einzige Farbe!
In der Vergangenheit haben wir beim Anzeigen des Plans die "heißesten" Knoten mit einem vertikalen "Chevron" links vom Wert markiert - je höher der Wert, desto gesättigter die Farbe.

In einem solchen Modell wird das Werteverhältnis jedoch schlecht wahrgenommen - beispielsweise kann eine Abweichung des Farbunterschieds von 30% nur von einem geschulten Auge festgestellt werden. Aus diesem Grund haben wir ein Histogramm aus horizontalen "Schultergurten" erstellt.

Nützliche Statistiken für "Mega" -Pläne
Viele Leute bemerken die Registerkarte „Statistik“ des Plans nicht, hier ist sie rechts:

Und wer es bemerkt hat - hat sie kaum aktiv genutzt. Wir haben uns entschlossen, dieses Versäumnis zu korrigieren und es für die Analyse "großer" Pläne (über 100 Knoten) wirklich nützlich zu machen .
Knoten gruppieren
Alle "identischen" Planknoten (dh solche mit demselben Knotentyp, derselben verwendeten Tabelle und demselben Index) werden in einer Tabellenzeile zusammengefasst. In diesem Fall werden alle ihre Indikatoren (Ausführungszeit, Anzahl der gelesenen und verworfenen Datensätze, Gesamtzahl der Durchgänge und Menge der gelesenen Daten) zusammengefasst.
Aus Gründen der Übersichtlichkeit trägt jeder Knotentyp eine Farbetikette:
- rot - Lesen von Daten
KnotenSeq Scan,Index Scan,CTE Scanund verschiedene andere... Scan - Gelb -
DatenverarbeitungsknotenSort,Unique,Aggregate,Group,Materialize, ... - grün -
AnschlussknotenNested Loop,Merge Join,Hash Join, ...

Sortieren nach einem beliebigen Indikator
Wenn Sie plötzlich eine Analyse benötigen, nicht nach der Gesamtzeit, sondern nach dem Knotentyp - klicken Sie einfach auf die Spaltenüberschrift - und alles wird sein:

Kontextknotenhinweis
Um den Beitrag eines bestimmten Knotens in einer Gruppe im Detail zu verstehen, bewegen Sie den Mauszeiger über die Anzahl der Knoten - und Sie sehen den traditionellen Hinweis darauf, was genau dort passiert ist:
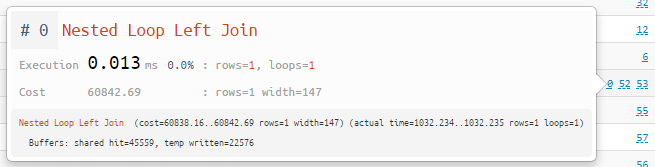
Persönliches Archiv der Pläne
"Ohne Registrierung und SMS!"Wenn Sie unseren Service aktiv nutzen, ist es jetzt viel einfacher, Ihre zuvor analysierten Pläne zu finden. Wechseln Sie einfach zur Registerkarte "Mine" im Archiv . Pläne fallen hier unabhängig von der Veröffentlichung im allgemeinen Archiv und sind nur für Sie sichtbar.

Genealogie der Pläne
Früher war es ziemlich schwierig, einen bestimmten Ihrer Pläne im Archiv zu finden, jetzt ist es einfach. Sie können benannt und in einem Optimierungs-Stammbaum zusammengefasst werden!
Geben Sie einfach einen Namen an, wenn Sie einen Plan hinzufügen:

... oder in einem vorhandenen Plan können Sie ihn festlegen, bearbeiten oder einen verknüpften Plan hinzufügen:

Anschließend können Sie schnell durch den Optionsbaum wechseln, um die Auswirkungen bestimmter Optimierungen zu bewerten:

Und wenn plötzlich ein Link zu einem bestimmten Plan erstellt wird verloren, kann er leicht anhand seines Namens in seinem persönlichen Archiv identifiziert werden:

Wir schauen in die "Fenster"
Eine kleine, aber nützliche Erweiterung von Query Profiler , über die ich bereits geschrieben habe. Wir haben ihm beigebracht, "in Fenster zu schauen" und Knoten richtig zuzuordnen:
-> WindowAgg ==> WINDOW / OVER
-> Sort ==> PARTITION BY / ORDER BY... als mehrere unabhängige Definitionen von "window" (
WINDOW) innerhalb einer einzigen Abfrage:
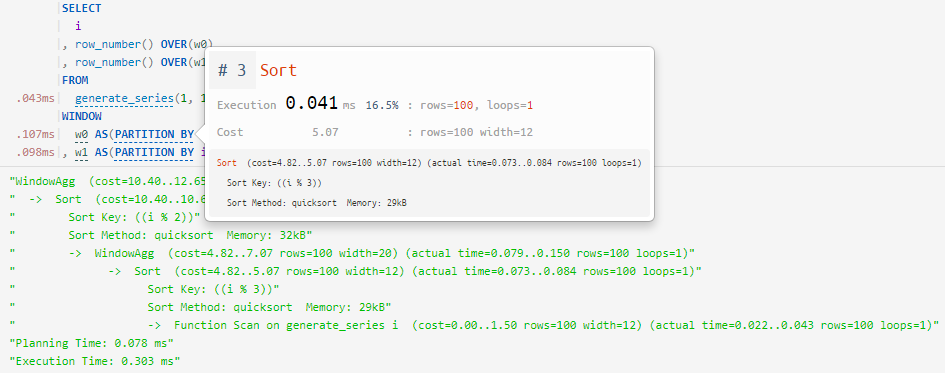
... und Sortieren in Fensterfunktionen ohne explizite Definition:

Viel Spaß beim Suchen nach verschiedenen Ineffizienzen!