Um den erforderlichen Bericht mit einer bestimmten Häufigkeit zu generieren, reicht es aus, eine entsprechende benutzerdefinierte Berichtsressource zu schreiben.
Nutzungsszenarien
Benutzerdefinierte Messberichte werden beispielsweise in folgenden Fällen benötigt:
- OpenShift, , (worker nodes) . . CPU , , -, , .
- OpenShift. Metering, , , , . , , , .
- In einer Situation mit öffentlichen Clustern wäre die Betriebsabteilung außerdem nützlich, um Aufzeichnungen im Kontext von Teams und Abteilungen über die Gesamtlaufzeit ihrer Pods (oder darüber, wie viel CPU- oder Speicherressourcen dafür aufgewendet wurden) zu führen. Mit anderen Worten, wir sind wieder an Informationen darüber interessiert, wem dieses oder jenes Sub gehört.
Um diese Probleme im Cluster zu lösen, reicht es aus, bestimmte benutzerdefinierte Ressourcen zu erstellen, die wir als Nächstes ausführen werden. Die Installation des Messoperators geht über den Rahmen dieses Artikels hinaus. Lesen Sie daher gegebenenfalls die Installationsdokumentation . Weitere Informationen zur Verwendung der Standardmessberichte finden Sie in der zugehörigen Dokumentation .
So funktioniert die Messung
Bevor wir benutzerdefinierte Assets erstellen, werfen wir einen Blick auf die Messung. Nach der Installation werden sechs Arten von benutzerdefinierten Ressourcen erstellt, von denen wir uns auf Folgendes konzentrieren werden:
- ReportDataSources (RDS) - Mit diesem Mechanismus können Sie angeben, welche Daten verfügbar sind und in ReportQuery oder benutzerdefinierten Berichtsressourcen verwendet werden können. Mit RDS können Sie auch Daten aus mehreren Quellen extrahieren. In OpenShift werden Daten aus Prometheus sowie aus benutzerdefinierten ReportQuery-Ressourcen (RQ) abgerufen.
- ReportQuery (rq) – SQL- , RDS. RQ- Report, RQ- , . RQ- RDS-, RQ- Metering view Presto ( Metering) .
- Report – , , ReportQuery. , , , Metering. Report .
Viele RDS und RQ sind sofort verfügbar. Da wir hauptsächlich an Berichten auf Knotenebene interessiert sind, werden wir diejenigen berücksichtigen, die Ihnen beim Schreiben Ihrer benutzerdefinierten Abfragen helfen. Führen Sie im Projekt "openshift-metering" den folgenden Befehl aus:
$ oc project openshift-metering
$ oc get reportdatasources | grep node
node-allocatable-cpu-cores
node-allocatable-memory-bytes
node-capacity-cpu-cores
node-capacity-memory-bytes
node-cpu-allocatable-raw
node-cpu-capacity-raw
node-memory-allocatable-raw
node-memory-capacity-raw
Hier interessieren uns zwei RDS: Node-Capacity-CPU-Core und Node-Capput-Capacity - Capacity-Raw, da wir einen Bericht über den CPU-Verbrauch erhalten möchten. Beginnen wir mit Node-Capacity-CPU-Core und führen Sie den folgenden Befehl aus, um zu sehen, wie Daten von Prometheus erfasst werden:
$ oc get reportdatasource/node-capacity-cpu-cores -o yaml
<showing only relevant snippet below>
spec:
prometheusMetricsImporter:
query: |
kube_node_status_capacity_cpu_cores * on(node) group_left(provider_id) max(kube_node_info) by (node, provider_id)
Hier sehen wir eine Prometheus-Anfrage, die Daten von Prometheus abruft und in Presto speichert. Lassen Sie uns dieselbe Anforderung in der OpenShift-Metrikkonsole ausführen und das Ergebnis anzeigen. Wir haben einen OpenShift-Cluster mit zwei Worker-Knoten (jeweils mit 16 Kernen) und drei Master-Knoten (jeweils mit 8 Kernen). Die letzte Spalte, Wert, enthält die Anzahl der dem Knoten zugewiesenen Kerne.

Die Daten werden also empfangen und in den Presto-Tabellen gespeichert. Sehen wir uns nun die RQ-Ressourcen (Custom Reportquery) an:
$ oc project openshift-metering
$ oc get reportqueries | grep node-cpu
node-cpu-allocatable
node-cpu-allocatable-raw
node-cpu-capacity
node-cpu-capacity-raw
node-cpu-utilization
Hier interessieren uns folgende RQS: Node-CPU-Kapazität und Node-CPU-Kapazität-Raw. Wie der Name schon sagt, enthalten diese Metriken sowohl beschreibende Daten (wie lange ein Knoten ausgeführt wird, wie viele Prozessoren er zugewiesen hat usw.) als auch aggregierte Daten.
Die zwei RDS und zwei RQS, an denen wir interessiert sind, sind durch die folgende Kette miteinander verbunden:
node-cpu-capacity (rq) <b>uses</b> node-cpu-capacity-raw (rds) <b>uses</b> node-cpu-capacity-raw (rq) <b>uses</b> node-capacity-cpu-cores (rds)
Anpassbare Berichte
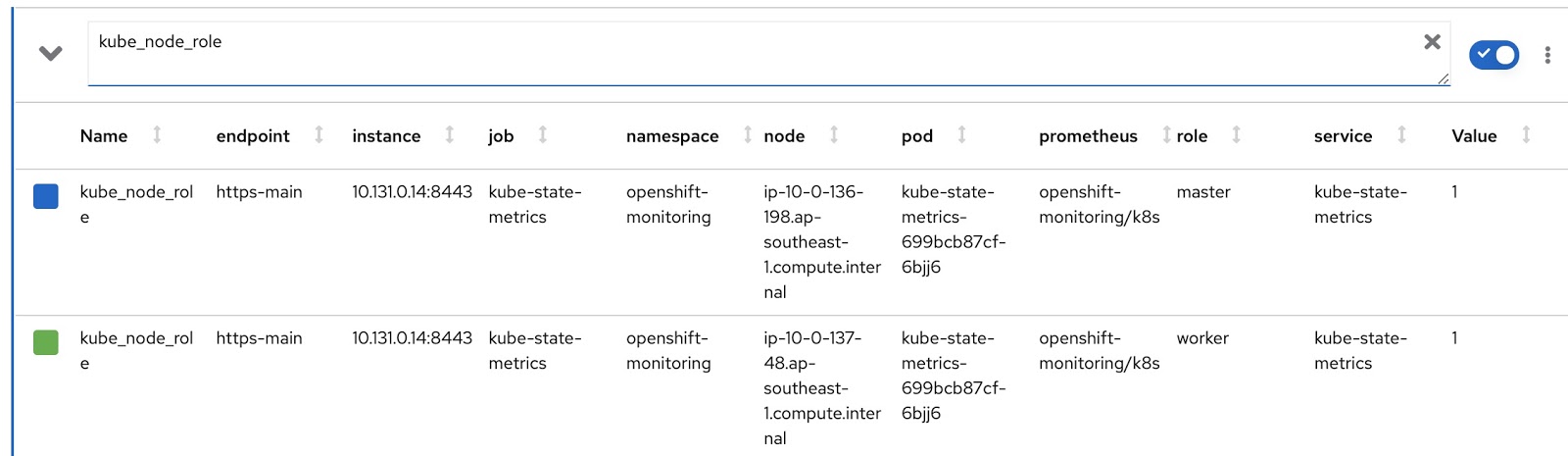
Schreiben wir nun unsere eigenen angepassten Versionen von RDS und RQ. Wir müssen die Prometheus-Anforderung so ändern, dass sie den Modus des Knotens (Master / Worker) und die entsprechende Knotenbezeichnung anzeigt, die angibt, zu welchem Team dieser Knoten gehört. Der Knotenbetriebsmodus ist in der Prometheus-Metrik kube_node_role enthalten, siehe Rollenspalte:
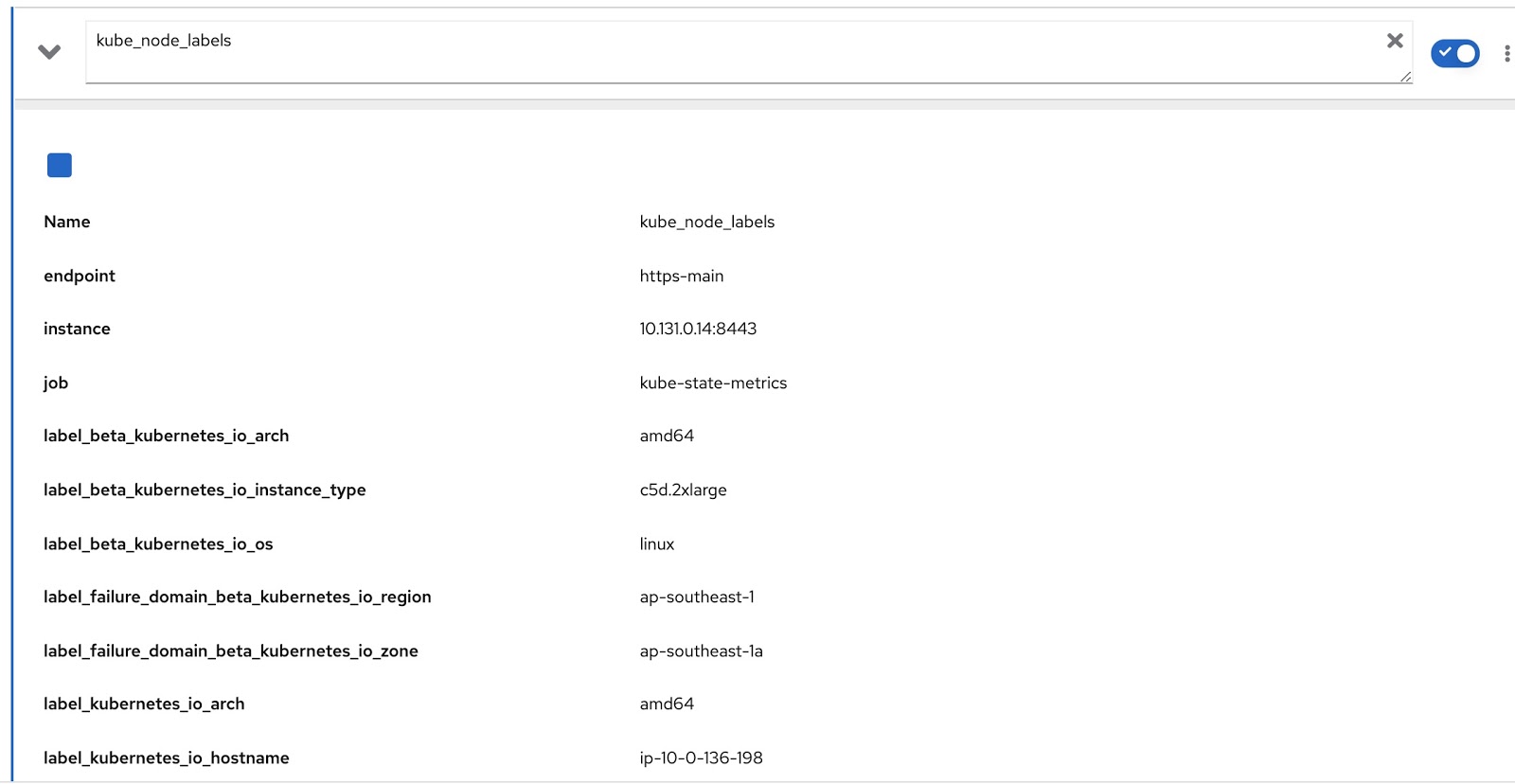
Alle dem Knoten zugewiesenen Beschriftungen sind in der Prometheus-Metrik kube_node_labels enthalten, wo sie mithilfe der label_-Vorlage gebildet werden. Wenn ein Knoten beispielsweise eine Bezeichnung node_lob hat, wird diese in der Prometheus-Metrik als label_node_lob angezeigt.
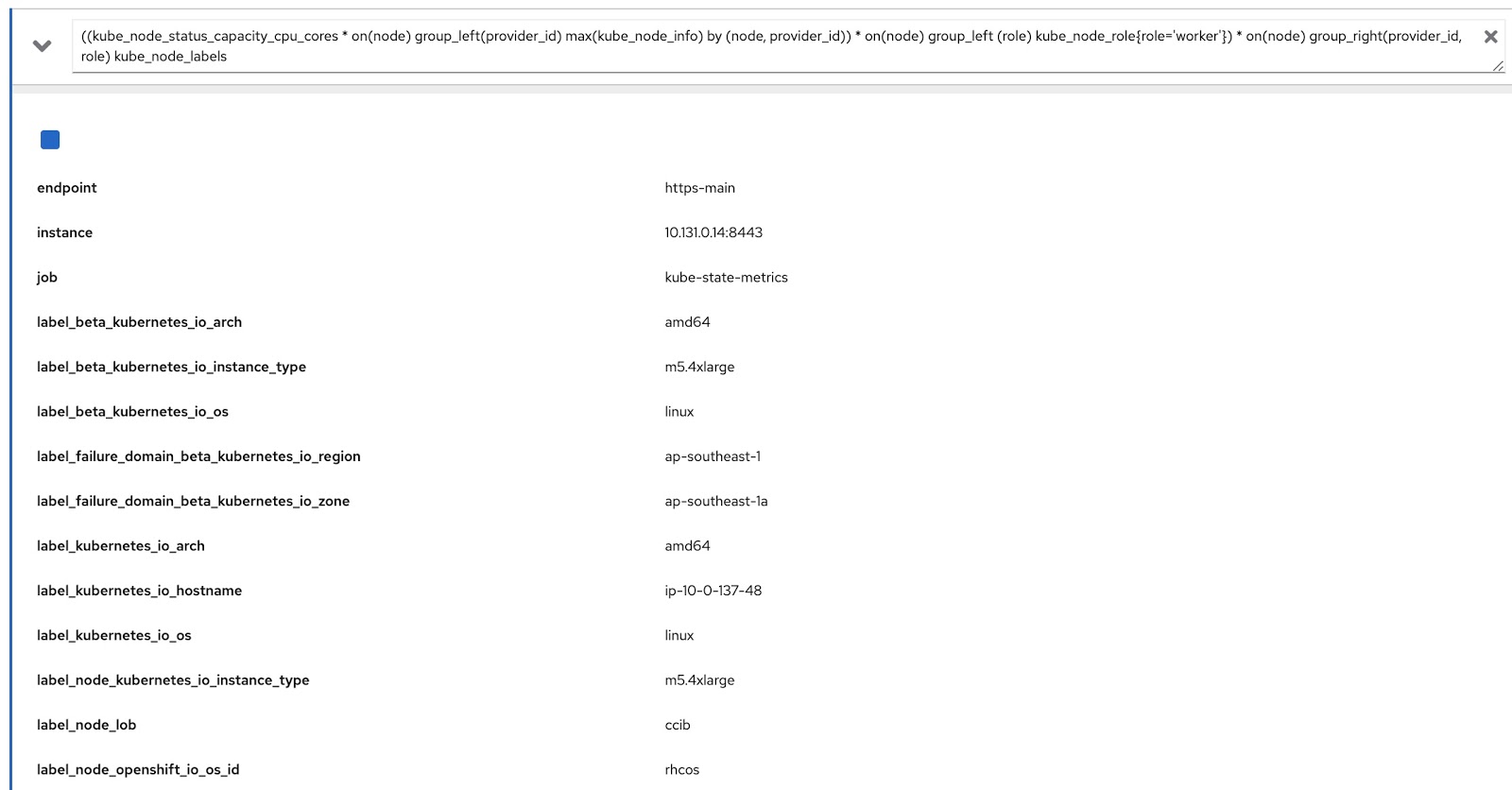
Jetzt müssen wir nur noch die ursprüngliche Abfrage mithilfe dieser beiden Prometheus-Abfragen ändern, um die benötigten Daten zu erhalten:
((kube_node_status_capacity_cpu_cores * on(node) group_left(provider_id) max(kube_node_info) by (node, provider_id)) * on(node) group_left (role) kube_node_role{role='worker'}) * on(node) group_right(provider_id, role) kube_node_labels
Führen Sie diese Abfrage nun in der OpenShift-Metrikkonsole aus und stellen Sie sicher, dass Daten sowohl nach Labels (node_lob) als auch nach Rollen zurückgegeben werden. Im Bild unten ist dies zunächst label_node_lob sowie die Rolle (es ist da, es ist einfach nicht auf dem Screenshot erschienen):
Wir müssen also vier benutzerdefinierte Ressourcen schreiben (Sie können sie aus der folgenden Liste herunterladen):
- rds-custom-node-Capacity-CPU-Cores.yaml - Gibt eine Prometheus-Anforderung an.
- rq-custom-node-cpu-Capacity-raw.yaml - bezieht sich auf die Anforderung aus Schritt 1 und gibt Rohdaten aus.
- rds-custom-node-cpu-Capacity-raw.yaml - verweist auf RQ aus Schritt 2 und erstellt ein Ansichtsobjekt in Presto.
- rq-custom-node-cpu-Kapazität-mit-CPU-Labels.yaml - bezieht sich auf RDS aus Abschnitt 3 und gibt Daten unter Berücksichtigung der eingegebenen Start- und Enddaten des Berichts aus. Außerdem werden die Rollen- und Beschriftungsspalten in dieselbe Datei extrahiert.
Nachdem Sie diese vier Yaml-Dateien erstellt haben, rufen Sie das OpenShift-Metering-Projekt auf und führen Sie die folgenden Befehle aus:
$ oc project openshift-metering
$ oc create -f rds-custom-node-capacity-cpu-cores.yaml
$ oc create -f rq-custom-node-cpu-capacity-raw.yaml
$ oc create -f rds-custom-node-cpu-capacity-raw.yaml
$ oc create -f rq-custom-node-cpu-capacity-with-cpus-labels.yaml
Jetzt muss nur noch ein benutzerdefiniertes Berichtsobjekt geschrieben werden, das auf das RQ-Objekt aus Schritt 4 verweist. Sie können dies beispielsweise wie unten gezeigt tun, damit der Bericht sofort ausgeführt wird und vom 15. bis 30. September Daten zurückgibt.
$ cat report_immediate.yaml
apiVersion: metering.openshift.io/v1
kind: Report
metadata:
name: custom-role-node-cpu-capacity-lables-immediate
namespace: openshift-metering
spec:
query: custom-role-node-cpu-capacity-labels
reportingStart: "2020-09-15T00:00:00Z"
reportingEnd: "2020-09-30T00:00:00Z"
runImmediately: true
$ oc create -f report-immediate.yaml
Nach dem Ausführen dieses Berichts kann die Ergebnisdatei (csv oder json) von der folgenden URL heruntergeladen werden (ersetzen Sie einfach DOMAIN_NAME durch Ihre eigene):
metering-openshift-metering.DOMAIN_NAME / api / v1 / reports / get? Name = benutzerdefinierte-rollen-knoten-cpu- Kapazität pro Stunde & Namespace = OpenShift-Metering & Format =
CSV Wie Sie im Screenshot der CSV-Datei sehen können, enthält sie sowohl Rolle als auch Node_Lob. Teilen Sie node_capacity_cpu_core_seconds durch node_capacity_cpu_cores, um die Betriebszeit des Knotens in Sekunden zu erhalten:

Fazit
Der Metering-Operator ist eine coole Sache für OpenShift-Cluster, die überall eingesetzt werden. Durch die Bereitstellung eines erweiterbaren Frameworks können Sie benutzerdefinierte Ressourcen erstellen, um die gewünschten Berichte zu generieren. Alle in diesem Artikel verwendeten Quellcodes können hier heruntergeladen werden .