
Wir implementieren und vergleichen 4 beliebte Trainingsoptimierer für neuronale Netze: Impulsoptimierer, Effektivausbreitung, Mini-Batch-Gradientenabstieg und adaptive Drehmomentschätzung. Das Repository, viel Python-Code und seine Ausgabe, Visualisierungen und Formeln sind alle unter dem Schnitt.
Einführung
Ein Modell ist das Ergebnis eines Algorithmus für maschinelles Lernen, der auf einigen Daten ausgeführt wird. Das Modell repräsentiert, was der Algorithmus gelernt hat. Dies ist das "Ding", das nach dem Ausführen des Algorithmus für die Trainingsdaten bestehen bleibt und Regeln, Zahlen und andere Datenstrukturen darstellt, die für den Algorithmus spezifisch und für die Vorhersage erforderlich sind.
Was ist ein Optimierer?
Bevor wir fortfahren, müssen wir wissen, was eine Verlustfunktion ist. Die Verlustfunktion ist ein Maß dafür, wie gut Ihr Vorhersagemodell das erwartete Ergebnis (oder den erwarteten Wert) vorhersagt. Die Verlustfunktion wird auch als Kostenfunktion bezeichnet (weitere Informationen hier ).
Während des Trainings versuchen wir, Funktionsverlust zu minimieren und Parameter zu aktualisieren, um die Genauigkeit zu verbessern. Die neuronalen Netzwerkparameter sind normalerweise die Verbindungsgewichte. In diesem Fall werden die Parameter in der Trainingsphase untersucht. Der Algorithmus selbst (und die Eingabedaten) passen diese Parameter an. Weitere Informationen finden Sie hier .
Somit ist der Optimierer eine Methode, um bessere Ergebnisse zu erzielen und das Lernen zu beschleunigen. Mit anderen Worten, es handelt sich um einen Algorithmus, mit dem geringfügige Anpassungen an Parametern wie Gewichten und Lernraten vorgenommen werden, damit das Modell korrekt und schnell ausgeführt wird. Hier finden Sie eine grundlegende Übersicht über die verschiedenen Optimierer, die beim Deep Learning verwendet werden, sowie ein einfaches Modell, um die Implementierung dieses Modells zu verstehen. Ich empfehle dringend, dieses Repository zu klonen und Änderungen vorzunehmen, indem Sie die Verhaltensmuster beobachten.
Einige häufig verwendete Begriffe:
- Rückausbreitung
Die Ziele der Backpropagation sind einfach: Passen Sie jedes Gewicht im Netzwerk an, je nachdem, wie viel es zum Gesamtfehler beiträgt. Wenn Sie den Fehler jedes Gewichts iterativ reduzieren, erhalten Sie eine Reihe von Gewichten, die gute Vorhersagen liefern. Wir finden die Steigung jedes Parameters für die Verlustfunktion und aktualisieren die Parameter durch Subtrahieren der Steigung (weitere Informationen hier ).

- Gradientenabstieg
Der Gradientenabstieg ist ein Optimierungsalgorithmus, der verwendet wird, um eine Funktion zu minimieren, indem iterativ zum steilsten Abstieg übergegangen wird, der durch einen negativen Gradientenwert definiert ist. Beim Deep Learning verwenden wir den Gradientenabstieg, um die Modellparameter zu aktualisieren (weitere Informationen hier ).
- Hyperparameter
Ein Modellhyperparameter ist eine Konfiguration außerhalb des Modells, deren Wert aus den Daten nicht geschätzt werden kann. Zum Beispiel die Anzahl der versteckten Neuronen, die Lernrate usw. Wir können die Lernrate nicht aus den Daten abschätzen (weitere Informationen hier ).
- Lernrate
Die Lernrate (α) ist ein Abstimmungsparameter im Optimierungsalgorithmus, der die Schrittgröße bei jeder Iteration bestimmt, während er sich dem Minimum der Verlustfunktion nähert (weitere Informationen hier).
Beliebte Optimierer

Im Folgenden sind einige der beliebtesten SEOs aufgeführt:
- Stochastischer Gradientenabstieg (SGD).
- Momentum Optimizer.
- Root Mean Square Propagation (RMSProp).
- Adaptive Drehmomentschätzung (Adam).
Betrachten wir jeden von ihnen im Detail.
1. Stochastischer Gradientenabstieg (insbesondere Mini-Batch)
Wir verwenden jeweils ein Beispiel, wenn wir das Modell trainieren (in reinem SGD) und den Parameter aktualisieren. Aber wir müssen einen anderen für die Schleife verwenden. Es wird viel Zeit in Anspruch nehmen. Daher verwenden wir Mini-Batch-SGD.
Der Mini-Batch-Gradientenabstieg versucht, die Robustheit des stochastischen Gradientenabstiegs und die Effizienz des Batch-Gradientenabstiegs auszugleichen. Dies ist die häufigste Implementierung des Gradientenabstiegs beim Deep Learning. Bei der Mini-Batch-SGD nehmen wir beim Training des Modells eine Gruppe von Beispielen (z. B. 32, 64 Beispiele usw.). Dieser Ansatz funktioniert besser, da nur eine einzige Schleife für das Minibatch benötigt wird, nicht jedes Beispiel. Mini-Pakete werden für jede Iteration zufällig ausgewählt, aber warum? Wenn Minipakete zufällig ausgewählt werden und dann in lokalen Minima stecken bleiben, können einige verrauschte Schritte zum Verlassen dieser Minima führen. Warum brauchen wir diesen Optimierer?
- Die Parameteraktualisierungsrate ist höher als beim einfachen Batch-Gradientenabstieg, was eine zuverlässigere Konvergenz ermöglicht, indem lokale Minima vermieden werden.
- Stapelaktualisierungen bieten einen rechnerisch effizienteren Prozess als der stochastische Gradientenabstieg.
- Wenn Sie wenig RAM haben, sind Mini-Pakete die beste Option. Das Stapeln ist effizient, da alle Trainingsdaten in Speicher- und Algorithmusimplementierungen fehlen.
Wie erstelle ich zufällige Mini-Pakete?
def RandomMiniBatches(X, Y, MiniBatchSize):
m = X.shape[0]
miniBatches = []
permutation = list(np.random.permutation(m))
shuffled_X = X[permutation, :]
shuffled_Y = Y[permutation, :].reshape((m,1)) #sure for uptpur shape
num_minibatches = m // MiniBatchSize
for k in range(0, num_minibatches):
miniBatch_X = shuffled_X[k * MiniBatchSize:(k + 1) * MiniBatchSize,:]
miniBatch_Y = shuffled_Y[k * MiniBatchSize:(k + 1) * MiniBatchSize,:]
miniBatch = (miniBatch_X, miniBatch_Y)
miniBatches.append(miniBatch)
#handeling last batch
if m % MiniBatchSize != 0:
# end = m - MiniBatchSize * m // MiniBatchSize
miniBatch_X = shuffled_X[num_minibatches * MiniBatchSize:, :]
miniBatch_Y = shuffled_Y[num_minibatches * MiniBatchSize:, :]
miniBatch = (miniBatch_X, miniBatch_Y)
miniBatches.append(miniBatch)
return miniBatches
Wie wird das Modell formatiert?
Ich gebe einen Überblick über das Modell, falls Sie neu im Deep Learning sind. Es sieht ungefähr so aus:
def model(X,Y,learning_rate,num_iter,hidden_size,keep_prob,optimizer):
L = len(hidden_size)
params = initilization(X.shape[1], hidden_size)
for i in range(1,num_iter):
MiniBatches = RandomMiniBatches(X, Y, 64) # GET RAMDOMLY MINIBATCHES
p , q = MiniBatches[2]
for MiniBatch in MiniBatches: #LOOP FOR MINIBATCHES
(MiniBatch_X, MiniBatch_Y) = MiniBatch
cache, A = model_forward(MiniBatch_X, params, L,keep_prob) #FORWARD PROPOGATIONS
cost = cost_f(A, MiniBatch_Y) #COST FUNCTION
grad = backward(MiniBatch_X, MiniBatch_Y, params, cache, L,keep_prob) #BACKWARD PROPAGATION
params = update_params(params, grad, beta=0.9,learning_rate=learning_rate)
return params
In der folgenden Abbildung sehen Sie, dass SGD stark schwankt. Vertikale Bewegung ist nicht notwendig: Wir wollen nur horizontale Bewegung. Wenn Sie die vertikale Bewegung verringern und die horizontale Bewegung erhöhen, lernt das Modell schneller, stimmen Sie nicht zu?

Wie minimiere ich unerwünschte Vibrationen? Die folgenden Optimierer minimieren sie und beschleunigen das Lernen.
2. Impulsoptimierer
Es gibt viel Zögern bei SGD oder Gefälle. Sie müssen sich vorwärts bewegen, nicht auf und ab. Wir müssen die Lernrate des Modells in die richtige Richtung erhöhen, und das werden wir mit dem Momentum-Optimierer tun.

Wie Sie im obigen Bild sehen können, ist die grüne Linie des Pulsoptimierers schneller als andere. Die Wichtigkeit des schnellen Lernens zeigt sich bei großen Datenmengen und vielen Iterationen. Wie implementiere ich diesen Optimierer?

Der Normalwert für β liegt bei etwa 0,9. Sie
können sehen, dass wir zwei Parameter - vdW und vdb - aus den Backpropagation- Parametern erstellt haben. Betrachten Sie den Wert β = 0,9, dann hat die Gleichung die Form:
vdw= 0.9 * vdw + 0.1 * dw
vdb = 0.9 * vdb + 0.1 * dbWie Sie sehen können, ist vdw eher vom vorherigen Wert von vdw als von dw abhängig . Wenn das Rendern ein Diagramm ist, können Sie sehen, dass der Momentum-Optimierer vergangene Verläufe berücksichtigt, um die Aktualisierung zu glätten. Deshalb ist es möglich, Schwankungen zu minimieren. Bei Verwendung von SGD schwankte der Pfad des Mini-Batch-Gradientenabfalls in Richtung Konvergenz. Der Momentum Optimizer hilft, diese Schwankungen zu reduzieren.
def update_params_with_momentum(params, grads, v, beta, learning_rate):
# grads has the dw and db parameters from backprop
# params has the W and b parameters which we have to update
for l in range(len(params) // 2 ):
# HERE WE COMPUTING THE VELOCITIES
v["dW" + str(l + 1)] = beta * v["dW" + str(l + 1)] + (1 - beta) * grads['dW' + str(l + 1)]
v["db" + str(l + 1)] = beta * v["db" + str(l + 1)] + (1 - beta) * grads['db' + str(l + 1)]
#updating parameters W and b
params["W" + str(l + 1)] = params["W" + str(l + 1)] - learning_rate * v["dW" + str(l + 1)]
params["b" + str(l + 1)] = params["b" + str(l + 1)] - learning_rate * v["db" + str(l + 1)]
return params
Das Repository ist hier
3. Root Mean Square Spread
Root Root Mean Square (RMSprop) ist ein exponentiell abfallender Mittelwert. Die wesentliche Eigenschaft von RMSprop ist, dass Sie nicht nur auf die Summe vergangener Farbverläufe beschränkt sind, sondern eher auf die Farbverläufe der letzten Zeitschritte. RMSprop trägt zum exponentiell abfallenden Mittelwert vergangener "Quadratgesetz-Gradienten" bei. In RMSProp versuchen wir, die vertikale Bewegung mithilfe des Mittelwerts zu reduzieren, da sie sich mit dem Mittelwert zu etwa 0 addieren. RMSprop liefert den Durchschnitt für das Update.

Eine Quelle

Schauen Sie sich den folgenden Code an. Auf diese Weise erhalten Sie ein grundlegendes Verständnis für die Implementierung dieses Optimierers. Alles ist das gleiche wie bei SGD, wir müssen die Update-Funktion ändern.
def initilization_RMS(params):
s = {}
for i in range(len(params)//2 ):
s["dW" + str(i)] = np.zeros(params["W" + str(i)].shape)
s["db" + str(i)] = np.zeros(params["b" + str(i)].shape)
return s
def update_params_with_RMS(params, grads,s, beta, learning_rate):
# grads has the dw and db parameters from backprop
# params has the W and b parameters which we have to update
for l in range(len(params) // 2 ):
# HERE WE COMPUTING THE VELOCITIES
s["dW" + str(l)]= beta * s["dW" + str(l)] + (1 - beta) * np.square(grads['dW' + str(l)])
s["db" + str(l)] = beta * s["db" + str(l)] + (1 - beta) * np.square(grads['db' + str(l)])
#updating parameters W and b
params["W" + str(l)] = params["W" + str(l)] - learning_rate * grads['dW' + str(l)] / (np.sqrt( s["dW" + str(l)] )+ pow(10,-4))
params["b" + str(l)] = params["b" + str(l)] - learning_rate * grads['db' + str(l)] / (np.sqrt( s["db" + str(l)]) + pow(10,-4))
return params
4. Adam Optimizer
Adam ist einer der effizientesten Optimierungsalgorithmen im neuronalen Netzwerktraining. Es kombiniert die Ideen von RMSProp und Pulse Optimizer. Anstatt die Lernrate der Parameter basierend auf dem Mittelwert des ersten Moments (Mittelwert) wie in RMSProp anzupassen, verwendet Adam auch den Mittelwert der zweiten Momente der Gradienten. Insbesondere berechnet der Algorithmus den exponentiellen gleitenden Durchschnitt des Gradienten und des quadratischen Gradienten sowie die Parameter
beta1und beta2steuert die Abklingrate dieser gleitenden Mittelwerte. Auf welche Weise?
def initilization_Adam(params):
s = {}
v = {}
for i in range(len(params)//2 ):
v["dW" + str(i)] = np.zeros(params["W" + str(i)].shape)
v["db" + str(i)] = np.zeros(params["b" + str(i)].shape)
s["dW" + str(i)] = np.zeros(params["W" + str(i)].shape)
s["db" + str(i)] = np.zeros(params["b" + str(i)].shape)
return v, s
def update_params_with_Adam(params, grads,v, s, beta1,beta2, learning_rate,t):
epsilon = pow(10,-8)
v_corrected = {}
s_corrected = {}
# grads has the dw and db parameters from backprop
# params has the W and b parameters which we have to update
for l in range(len(params) // 2 ):
# HERE WE COMPUTING THE VELOCITIES
v["dW" + str(l)] = beta1 * v["dW" + str(l)] + (1 - beta1) * grads['dW' + str(l)]
v["db" + str(l)] = beta1 * v["db" + str(l)] + (1 - beta1) * grads['db' + str(l)]
v_corrected["dW" + str(l)] = v["dW" + str(l)] / (1 - np.power(beta1, t))
v_corrected["db" + str(l)] = v["db" + str(l)] / (1 - np.power(beta1, t))
s["dW" + str(l)] = beta2 * s["dW" + str(l)] + (1 - beta2) * np.power(grads['dW' + str(l)], 2)
s["db" + str(l)] = beta2 * s["db" + str(l)] + (1 - beta2) * np.power(grads['db' + str(l)], 2)
s_corrected["dW" + str(l)] = s["dW" + str(l)] / (1 - np.power(beta2, t))
s_corrected["db" + str(l)] = s["db" + str(l)] / (1 - np.power(beta2, t))
params["W" + str(l)] = params["W" + str(l)] - learning_rate * v_corrected["dW" + str(l)] / np.sqrt(s_corrected["dW" + str(l)] + epsilon)
params["b" + str(l)] = params["b" + str(l)] - learning_rate * v_corrected["db" + str(l)] / np.sqrt(s_corrected["db" + str(l)] + epsilon)
return params
Hyperparameter
- β1 (beta1) Wert fast 0,9
- β2 (beta2) - fast 0,999
- ε - Verhinderung der Division durch Null (10 ^ -8) (wirkt sich nicht zu stark auf das Lernen aus)
Warum dieser Optimierer?
Seine Vorteile:
- Einfache Implementierung.
- Recheneffizienz.
- Geringer Speicherbedarf.
- Invariante zur diagonalen Skalierung von Gradienten.
- Gut geeignet für große Aufgaben in Bezug auf Daten und Parameter.
- Geeignet für instationäre Zwecke.
- Geeignet für Aufgaben mit sehr lauten oder spärlichen Verläufen.
- Hyperparameter sind unkompliziert und erfordern normalerweise wenig Abstimmung.
Lassen Sie uns ein Modell erstellen und sehen, wie Hyperparameter das Lernen beschleunigen
Lassen Sie uns eine praktische Demonstration machen, wie Sie das Lernen beschleunigen können. In diesem Artikel werden wir die anderen Dinge nicht erklären (Initialisierung, Screenings,
forward_prop, back_prop, Gradientenabfallsaktualisierung, und so weiter. D.). Die für das Training erforderlichen Funktionen sind bereits in NumPy integriert. Wenn Sie es sich ansehen möchten, hier ist der Link !
Lasst uns beginnen!
Ich erstelle eine generische Modellfunktion, die für alle hier diskutierten Optimierer funktioniert.
1. Initialisierung:
Wir initialisieren die Parameter mithilfe einer Initialisierungsfunktion, die Eingaben wie
features_size (in unserem Fall 12288) und ein verstecktes Array von Größen (wir haben [100,1] verwendet) und diese Ausgabe als Initialisierungsparameter verwendet. Es gibt eine andere Initialisierungsmethode. Ich ermutige Sie, diesen Artikel zu lesen .
def initilization(input_size,layer_size):
params = {}
np.random.seed(0)
params['W' + str(0)] = np.random.randn(layer_size[0], input_size) * np.sqrt(2 / input_size)
params['b' + str(0)] = np.zeros((layer_size[0], 1))
for l in range(1,len(layer_size)):
params['W' + str(l)] = np.random.randn(layer_size[l],layer_size[l-1]) * np.sqrt(2/layer_size[l])
params['b' + str(l)] = np.zeros((layer_size[l],1))
return params
2. Vorwärtsausbreitung:
In dieser Funktion ist die Eingabe X sowie die Parameter, die Ausdehnung der verborgenen Ebenen und das Dropout, die in der Dropout-Technik verwendet werden.
Ich habe den Wert auf 1 gesetzt, damit das Training nicht beeinträchtigt wird. Wenn Ihr Modell überpasst ist, können Sie einen anderen Wert festlegen. Ich wende den Ausfall nur auf die geraden Schichten an .
Wir berechnen den Aktivierungswert für jede Schicht mithilfe einer Funktion
forward_activation.
#activations-----------------------------------------------
def forward_activation(A_prev, w, b, activation):
z = np.dot(A_prev, w.T) + b.T
if activation == 'relu':
A = np.maximum(0, z)
elif activation == 'sigmoid':
A = 1/(1+np.exp(-z))
else:
A = np.tanh(z)
return A
#________model forward ____________________________________________________________________________________________________________
def model_forward(X,params, L,keep_prob):
cache = {}
A =X
for l in range(L-1):
w = params['W' + str(l)]
b = params['b' + str(l)]
A = forward_activation(A, w, b, 'relu')
if l%2 == 0:
cache['D' + str(l)] = np.random.randn(A.shape[0],A.shape[1]) < keep_prob
A = A * cache['D' + str(l)] / keep_prob
cache['A' + str(l)] = A
w = params['W' + str(L-1)]
b = params['b' + str(L-1)]
A = forward_activation(A, w, b, 'sigmoid')
cache['A' + str(L-1)] = A
return cache, A
3. Backpropagation:
Hier schreiben wir die Backpropagation-Funktion. Es wird grad ( Steigung ) zurückgegeben. Wir verwenden
gradbei der Aktualisierung der Parameter (wenn Sie nichts darüber wissen). Ich empfehle diesen Artikel zu lesen .
def backward(X, Y, params, cach,L,keep_prob):
grad ={}
m = Y.shape[0]
cach['A' + str(-1)] = X
grad['dz' + str(L-1)] = cach['A' + str(L-1)] - Y
cach['D' + str(- 1)] = 0
for l in reversed(range(L)):
grad['dW' + str(l)] = (1 / m) * np.dot(grad['dz' + str(l)].T, cach['A' + str(l-1)])
grad['db' + str(l)] = 1 / m * np.sum(grad['dz' + str(l)].T, axis=1, keepdims=True)
if l%2 != 0:
grad['dz' + str(l-1)] = ((np.dot(grad['dz' + str(l)], params['W' + str(l)]) * cach['D' + str(l-1)] / keep_prob) *
np.int64(cach['A' + str(l-1)] > 0))
else :
grad['dz' + str(l - 1)] = (np.dot(grad['dz' + str(l)], params['W' + str(l)]) *
np.int64(cach['A' + str(l - 1)] > 0))
return grad
Wir haben die Optimierungs-Update-Funktion bereits gesehen, daher werden wir sie hier verwenden. Nehmen wir einige geringfügige Änderungen an der Modellfunktion aus der SGD-Diskussion vor.
def model(X,Y,learning_rate,num_iter,hidden_size,keep_prob,optimizer):
L = len(hidden_size)
params = initilization(X.shape[1], hidden_size)
costs = []
itr = []
if optimizer == 'momentum':
v = initilization_moment(params)
elif optimizer == 'rmsprop':
s = initilization_RMS(params)
elif optimizer == 'adam' :
v,s = initilization_Adam(params)
for i in range(1,num_iter):
MiniBatches = RandomMiniBatches(X, Y, 32) # GET RAMDOMLY MINIBATCHES
p , q = MiniBatches[2]
for MiniBatch in MiniBatches: #LOOP FOR MINIBATCHES
(MiniBatch_X, MiniBatch_Y) = MiniBatch
cache, A = model_forward(MiniBatch_X, params, L,keep_prob) #FORWARD PROPOGATIONS
cost = cost_f(A, MiniBatch_Y) #COST FUNCTION
grad = backward(MiniBatch_X, MiniBatch_Y, params, cache, L,keep_prob) #BACKWARD PROPAGATION
if optimizer == 'momentum':
params = update_params_with_momentum(params, grad, v, beta=0.9,learning_rate=learning_rate)
elif optimizer == 'rmsprop':
params = update_params_with_RMS(params, grad, s, beta=0.9,learning_rate=learning_rate)
elif optimizer == 'adam' :
params = update_params_with_Adam(params, grad,v, s, beta1=0.9,beta2=0.999, learning_rate=learning_rate,t=i) #UPDATE PARAMETERS
elif optimizer == "minibatch":
params = update_params(params, grad,learning_rate=learning_rate)
if i%5 == 0:
costs.append(cost)
itr.append(i)
if i % 100 == 0 :
print('cost of iteration______{}______{}'.format(i,cost))
return params,costs,itr
Training mit Mini-Packs
params, cost_sgd,itr = model(X_train, Y_train, learning_rate = 0.01,
num_iter=500, hidden_size=[100, 1],keep_prob=1,optimizer='minibatch')
Y_train_pre = predict(X_train, params, 2)
print('train_accuracy------------', accuracy_score(Y_train_pre, Y_train))Fazit bei Annäherung mit Minipaketen:
cost of iteration______100______0.35302967575683797
cost of iteration______200______0.472914548745098
cost of iteration______300______0.4884728238471557
cost of iteration______400______0.21551100063345618
train_accuracy------------ 0.8494208494208494
Pulse Optimizer Training
params,cost_momentum, itr = model(X_train, Y_train, learning_rate = 0.01,
num_iter=500, hidden_size=[100, 1],keep_prob=1,optimizer='momentum')
Y_train_pre = predict(X_train, params, 2)
print('train_accuracy------------', accuracy_score(Y_train_pre, Y_train))Impulsoptimierungsausgang:
cost of iteration______100______0.36278494129038086
cost of iteration______200______0.4681552335189021
cost of iteration______300______0.382226159384529
cost of iteration______400______0.18219310793752702 train_accuracy------------ 0.8725868725868726Training mit RMSprop
params,cost_rms,itr = model(X_train, Y_train, learning_rate = 0.01,
num_iter=500, hidden_size=[100, 1],keep_prob=1,optimizer='rmsprop')
Y_train_pre = predict(X_train, params, 2)
print('train_accuracy------------', accuracy_score(Y_train_pre, Y_train))RMSprop-Ausgabe:
cost of iteration______100______0.2983858963793841
cost of iteration______200______0.004245700579927428
cost of iteration______300______0.2629426607580565
cost of iteration______400______0.31944824707807556 train_accuracy------------ 0.9613899613899614Training mit Adam
params,cost_adam, itr = model(X_train, Y_train, learning_rate = 0.01,
num_iter=500, hidden_size=[100, 1],keep_prob=1,optimizer='adam')
Y_train_pre = predict(X_train, params, 2)
print('train_accuracy------------', accuracy_score(Y_train_pre, Y_train))Adams Schlussfolgerung:
cost of iteration______100______0.3266223660473619
cost of iteration______200______0.08214547683157716
cost of iteration______300______0.0025645257286439583
cost of iteration______400______0.058015188756586206 train_accuracy------------ 0.9845559845559846Haben Sie den Unterschied in der Genauigkeit zwischen den beiden gesehen? Wir haben dieselben Initialisierungsparameter, dieselbe Lernrate und dieselbe Anzahl von Iterationen verwendet. Nur der Optimierer ist anders, aber sehen Sie sich das Ergebnis an!
Mini-batch accuracy : 0.8494208494208494
momemtum accuracy : 0.8725868725868726
Rms accuracy : 0.9613899613899614
adam accuracy : 0.9845559845559846Grafische Visualisierung des Modells

Sie können das Repository überprüfen, wenn Sie Zweifel am Code haben.
Zusammenfassung
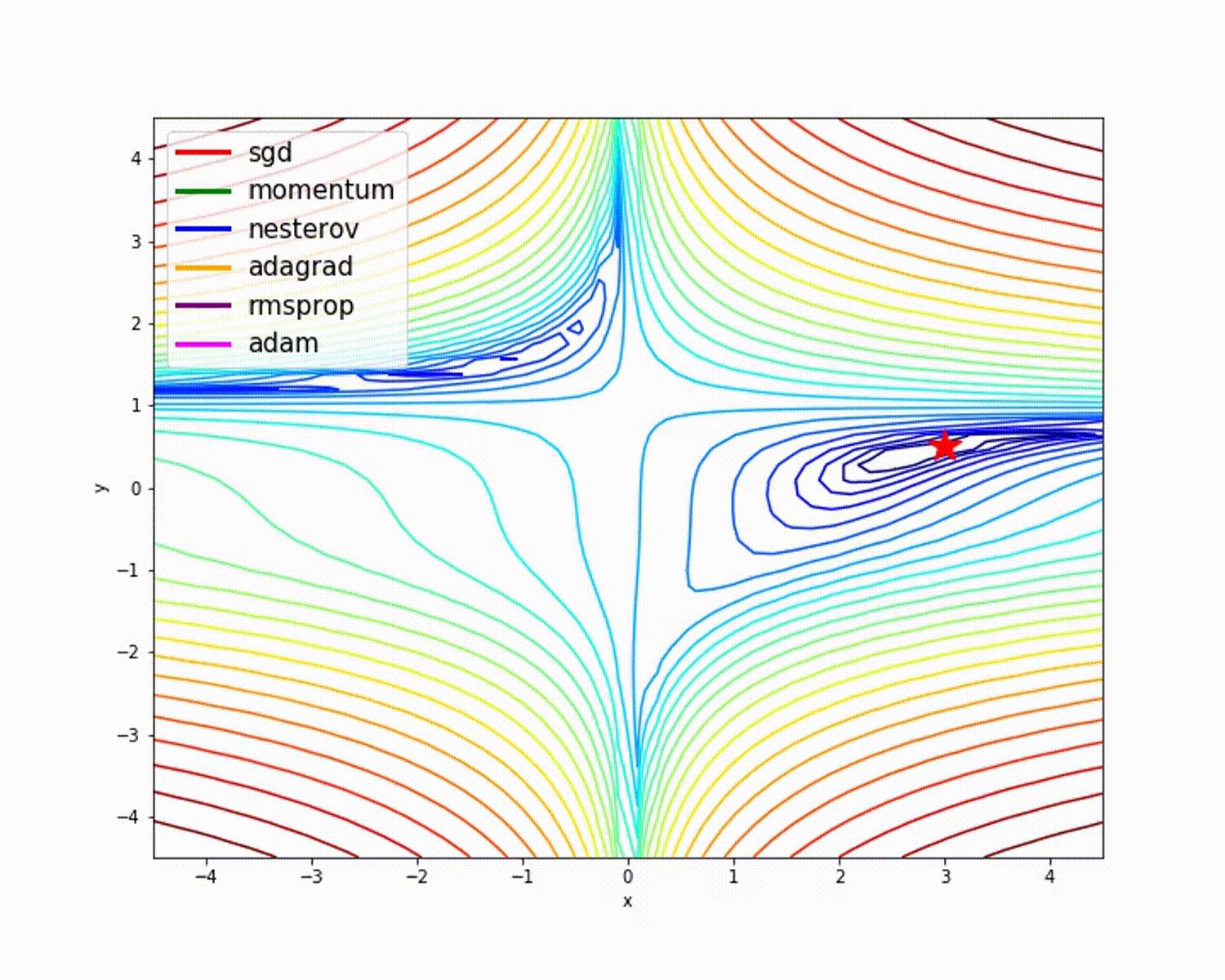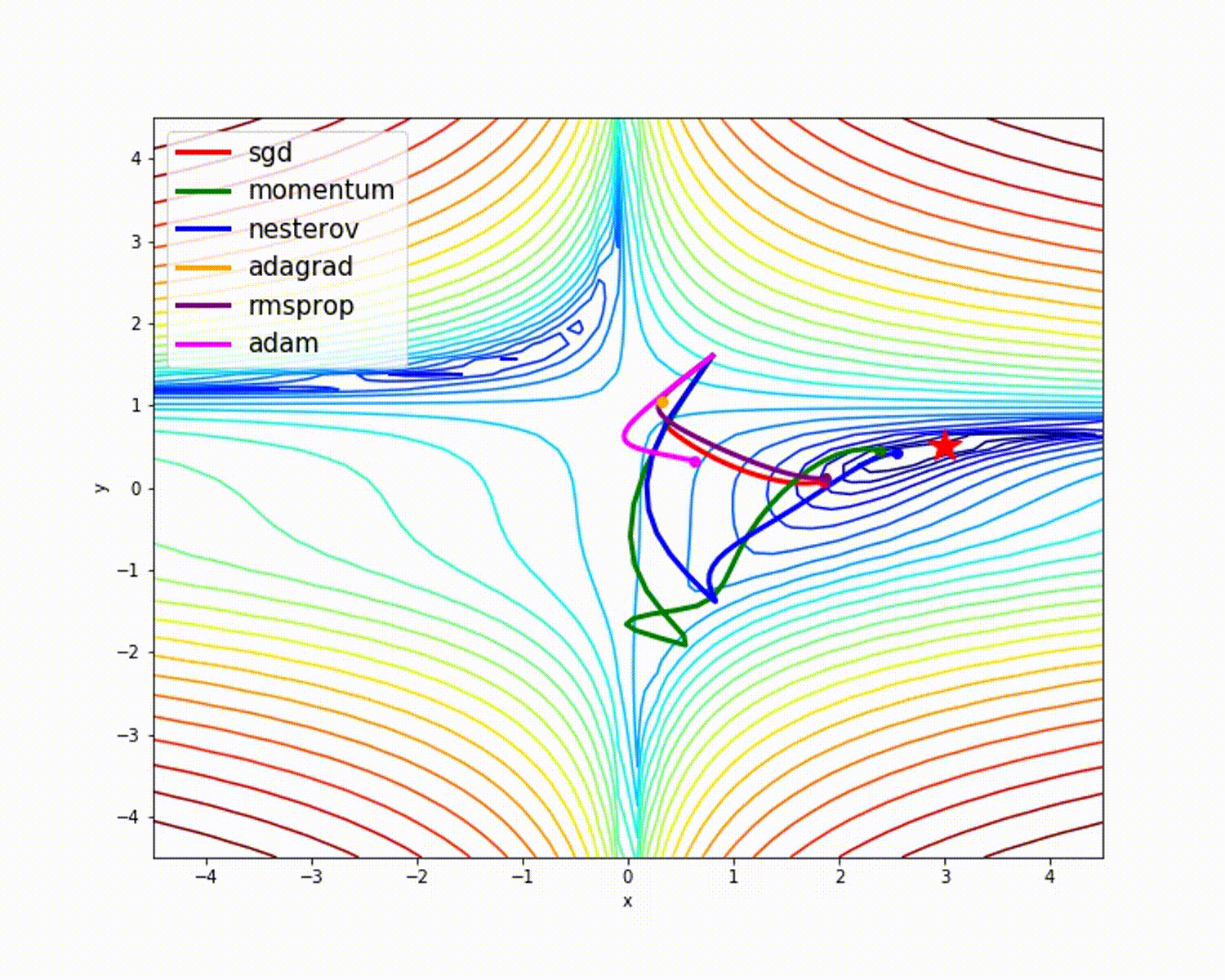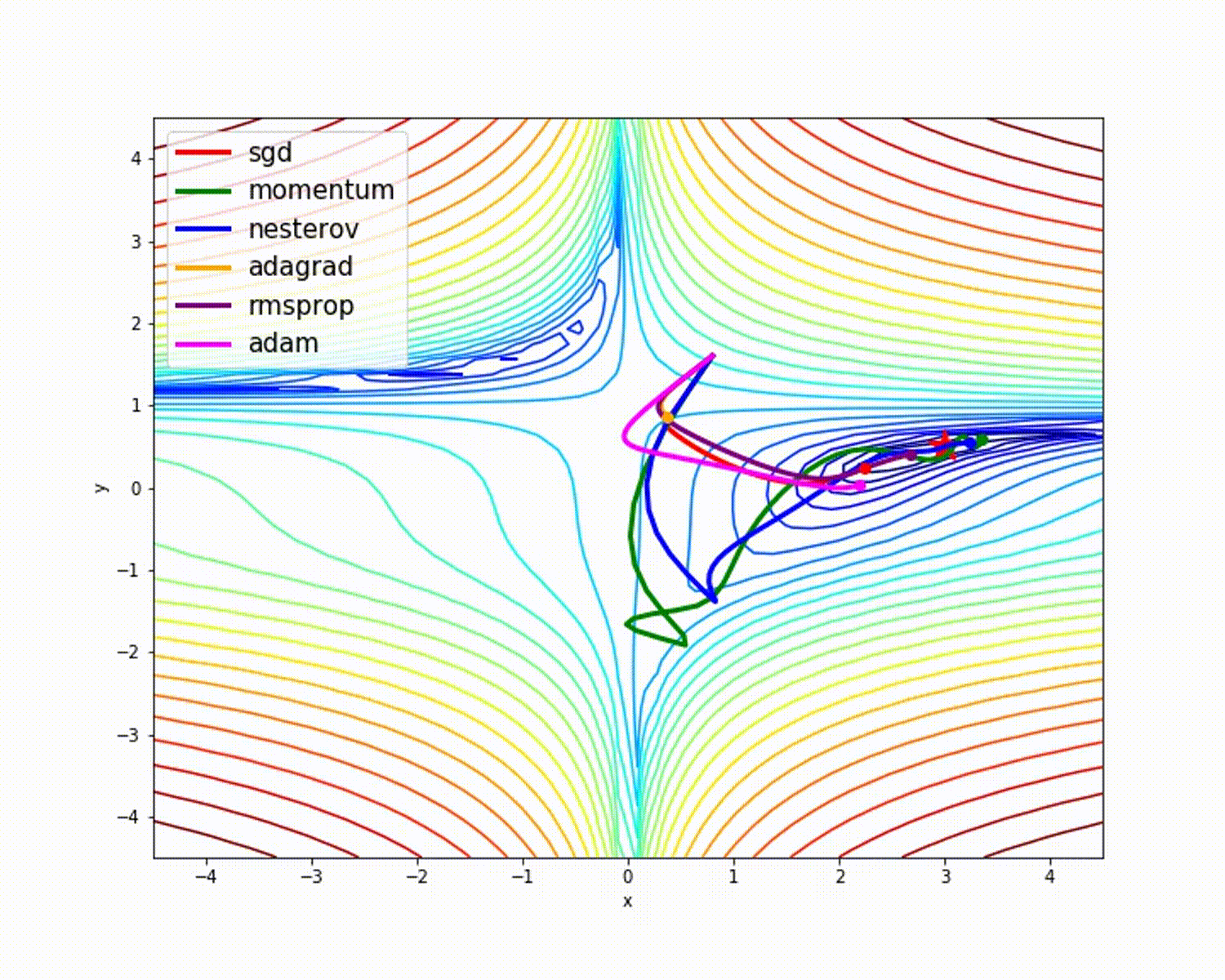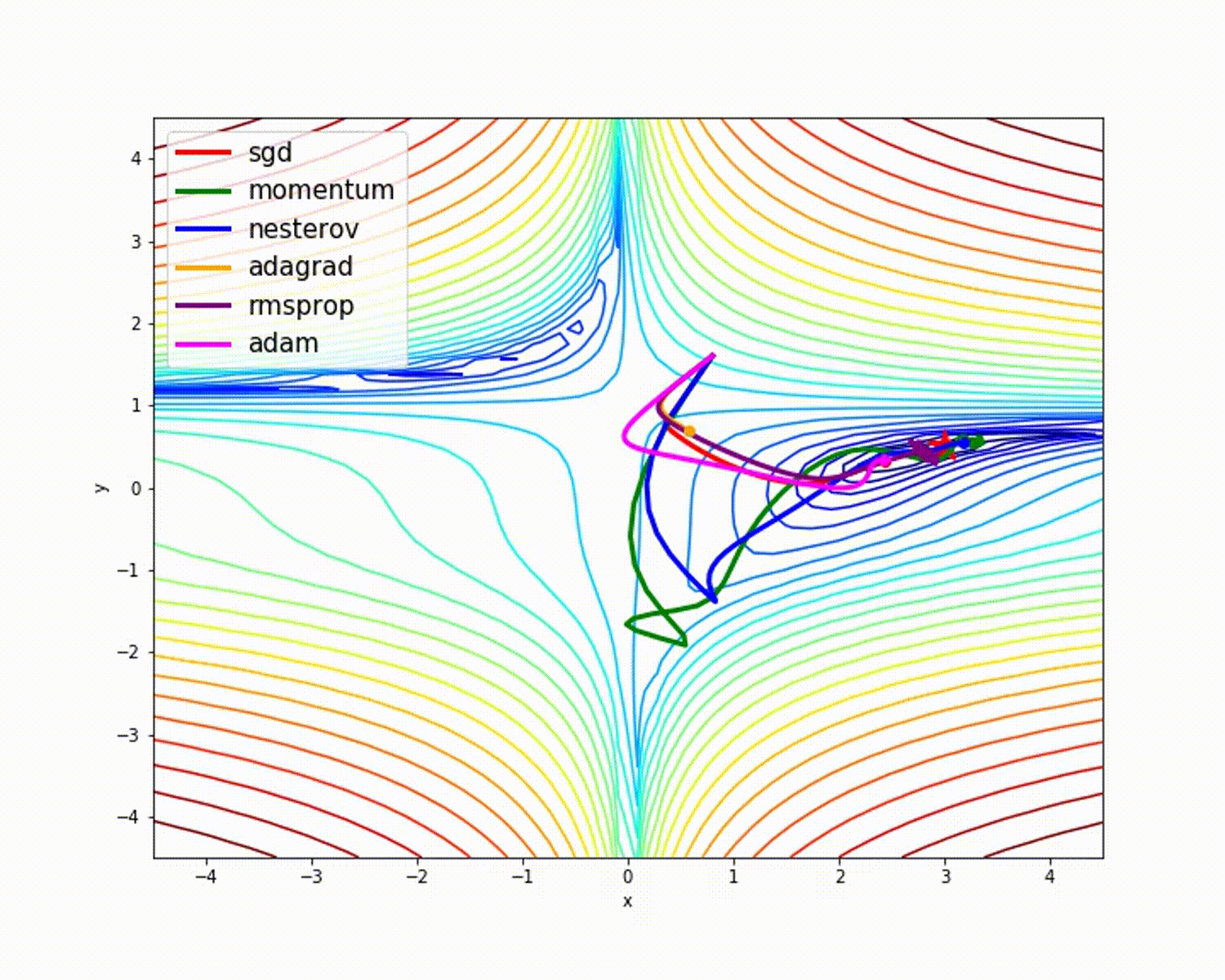
Quelle
Wie wir gesehen haben, bietet der Adam-Optimierer im Vergleich zu anderen Optimierern eine gute Genauigkeit. Das obige Bild zeigt, wie das Modell durch Iterationen lernt. Das Momentum gibt die SGD-Geschwindigkeit an und RMSProp gibt den exponentiellen Durchschnitt der Gewichte für die aktualisierten Parameter an. Wir haben im obigen Modell weniger Daten verwendet, aber wir werden mehr Nutzen aus Optimierern ziehen, wenn wir mit großen Datenmengen und vielen Iterationen arbeiten. Wir haben die Grundidee von Optimierern besprochen, und ich hoffe, dies gibt Ihnen Motivation, mehr über Optimierer zu erfahren und sie zu verwenden!
Ressourcen
Die Aussichten für neuronale Netze und tiefes maschinelles Lernen sind enorm, und nach konservativsten Schätzungen werden ihre Auswirkungen auf die Welt in etwa den Auswirkungen der Elektrizität auf die Industrie im 19. Jahrhundert entsprechen. Diejenigen Experten, die diese Aussichten vor allen anderen bewerten, haben jede Chance, der Führer des Fortschritts zu werden. Für diese Personen haben wir einen Promo-Code HABR erstellt , der zusätzlich 10% zum auf dem Banner angegebenen Schulungsrabatt gewährt.

- Kurs für maschinelles Lernen
- Kurs "Mathematik und maschinelles Lernen für Data Science"
- Fortgeschrittenenkurs "Maschinelles Lernen Pro + Deep Learning"
- Online-Bootcamp für Data Science
- Schulung des Data Analyst-Berufs von Grund auf
- Data Analytics Online Bootcamp
- Unterrichten des Data Science-Berufs von Grund auf
- Python für Webentwicklungskurs