
Mythisches Nashorn-Einhorn. MS TECH / PIXABAY Das
Training in weniger als einem Versuch hilft einem Modell, mehr Objekte zu identifizieren als die Anzahl der Beispiele, an denen es trainiert hat.
Typischerweise erfordert maschinelles Lernen viele Beispiele. Damit ein KI-Modell ein Pferd erkennt, müssen Sie ihm Tausende von Pferdebildern zeigen. Aus diesem Grund ist Technologie so rechenintensiv und unterscheidet sich stark vom menschlichen Lernen. Ein Kind muss oft nur einige Beispiele eines Objekts oder sogar eines sehen, um zu lernen, es lebenslang zu erkennen.
Tatsächlich brauchen Kinder manchmal keine Beispiele, um etwas zu identifizieren. Zeigen Sie Bilder von einem Pferd und einem Nashorn, sagen Sie ihnen, dass sich das Einhorn dazwischen befindet, und sie werden das Fabelwesen im Bilderbuch erkennen, sobald sie es zum ersten Mal sehen.

Mmm ... nicht wirklich! MS TECH / PIXABAY
Untersuchungen der University of Waterloo in Ontario legen nahe, dass KI-Modelle dies auch können - ein Prozess, den Forscher als "Lernen in weniger als einem" Versuch bezeichnen. Mit anderen Worten, das KI-Modell kann deutlich mehr Objekte erkennen als die Anzahl der Beispiele, an denen es trainiert hat. Dies kann in einem Bereich kritisch sein, der mit zunehmender Anzahl der verwendeten Datensätze immer teurer und unzugänglicher wird.
« »
Die Forscher demonstrierten diese Idee zunächst, indem sie mit einem beliebten Computer-Vision-Trainingsdatensatz experimentierten, der als MNIST bekannt ist. MNIST enthält 60.000 Bilder handgeschriebener Zahlen von 0 bis 9, und das Set wird häufig verwendet, um neue Ideen in diesem Bereich zu testen.
In einem früheren Artikel stellten Forscher am Massachusetts Institute of Technology eine Methode vor, um riesige Datensätze in kleine zu "destillieren". Als Proof of Concept haben sie MNIST auf 10 Bilder komprimiert. Bilder wurden nicht aus dem Originaldatensatz entnommen. Sie wurden sorgfältig entworfen und optimiert, um das Äquivalent eines vollständigen Satzes von Informationen zu enthalten. Wenn das AI-Modell auf diesen 10 Bildern trainiert wird, erreicht es fast die gleiche Genauigkeit wie das gesamte MNIST-Set.

Beispielbilder aus dem MNIST-Set. Das

abgebildete WIKIMEDIA 10, "destilliert" von MNIST, kann ein KI-Modell trainieren, um eine Genauigkeit von 94 Prozent bei der handschriftlichen Ziffernerkennung zu erreichen. Tongzhou Wang et al.
Forscher der Wotrelu-Universität wollten den Destillationsprozess fortsetzen. Wenn es möglich ist, 60.000 Bilder auf 10 zu reduzieren, warum nicht auf fünf komprimieren? Sie erkannten, dass der Trick darin bestand, mehrere Zahlen in einem Bild zu mischen und sie dann in ein KI-Modell mit sogenannten Hybrid- oder "weichen" Etiketten einzuspeisen. (Stellen Sie sich ein Pferd und ein Nashorn vor, denen die Merkmale eines Einhorns verliehen wurden.)
"Denken Sie an die Nummer 3, es sieht aus wie die Nummer 8, aber nicht die Nummer 7", sagt Ilya Sukholutsky, eine Waterloo-Doktorandin und Hauptautorin des Artikels. - Weiche Markierungen versuchen, diese Ähnlichkeiten zu erfassen. Anstatt dem Auto zu sagen: "Dieses Bild ist Nummer 3", sagen wir: "Dieses Bild ist 60% Nummer 3, 30% Nummer 8 und 10% Nummer 0".
Einschränkungen der neuen Lehrmethode
Nachdem die Forscher in weniger als einem Versuch erfolgreich Soft Labels verwendet hatten, um MNIST-Anpassungen an das Lernen zu erreichen, fragten sie sich, wie weit die Idee gehen könnte. Gibt es eine Begrenzung für die Anzahl der Kategorien, die ein KI-Modell anhand einer kleinen Anzahl von Beispielen identifizieren kann?
Überraschenderweise scheint es keine Einschränkung zu geben. Mit sorgfältig gestalteten Soft Labels könnten sogar zwei Beispiele theoretisch eine beliebige Anzahl von Kategorien codieren. „Mit nur zwei Punkten können Sie tausend Klassen oder 10.000 Klassen oder eine Million Klassen teilen“, sagt Sukholutsky.
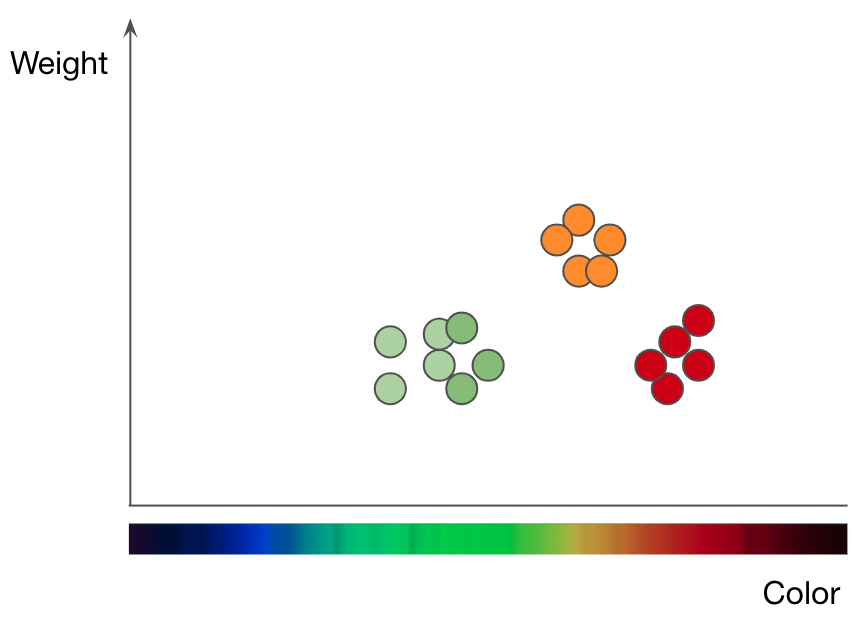
Aufschlüsselung von Äpfeln (grüne und rote Punkte) und Orangen (orange Punkte) nach Gewicht und Farbe. Adaptiert von Jason Maces Präsentation Machine Learning 101
Dies haben die Wissenschaftler in ihrem neuesten Artikel durch rein mathematische Forschung gezeigt. Sie implementierten dieses Konzept mithilfe eines der einfachsten Algorithmen für maschinelles Lernen, die als k-next neighbours (kNN) bekannt sind und Objekte mithilfe eines grafischen Ansatzes klassifizieren.
Um zu verstehen, wie die kNN-Methode funktioniert, nehmen wir als Beispiel ein Problem mit der Fruchtklassifizierung. Um das kNN-Modell zu trainieren, um den Unterschied zwischen Äpfeln und Orangen zu verstehen, müssen Sie zuerst die Funktionen auswählen, die Sie zur Darstellung jeder Frucht verwenden möchten. Wenn Sie Farbe und Gewicht wählen, geben Sie für jeden Apfel und jede Orange einen Datenpunkt mit der Fruchtfarbe als x- Wert und dem Gewicht als y- Wert ein... Der kNN-Algorithmus zeichnet dann alle Datenpunkte in einem 2D-Diagramm und zeichnet eine Linie auf halber Strecke zwischen Äpfeln und Orangen. Das Diagramm ist jetzt sauber in zwei Klassen unterteilt, und der Algorithmus kann entscheiden, ob die neuen Datenpunkte Äpfel oder Orangen darstellen - je nachdem, auf welcher Seite der Linie sich der Punkt befindet.
Um das Lernen in weniger als einem Versuch mit dem kNN-Algorithmus zu untersuchen, erstellten die Forscher eine Reihe winziger synthetischer Datensätze und überlegten sorgfältig, welche Soft Labels sie verwenden sollten. Anschließend erlaubten sie dem kNN-Algorithmus, die Grenzen zu zeichnen, die er sah, und stellten fest, dass der Graph erfolgreich in mehr Klassen aufgeteilt wurde, als Datenpunkte vorhanden waren. Die Forscher haben auch weitgehend kontrolliert, wo die Grenzen verlaufen. Mit verschiedenen Modifikationen an den weichen Etiketten ließ der kNN-Algorithmus präzise Muster in Form von Blumen zeichnen.
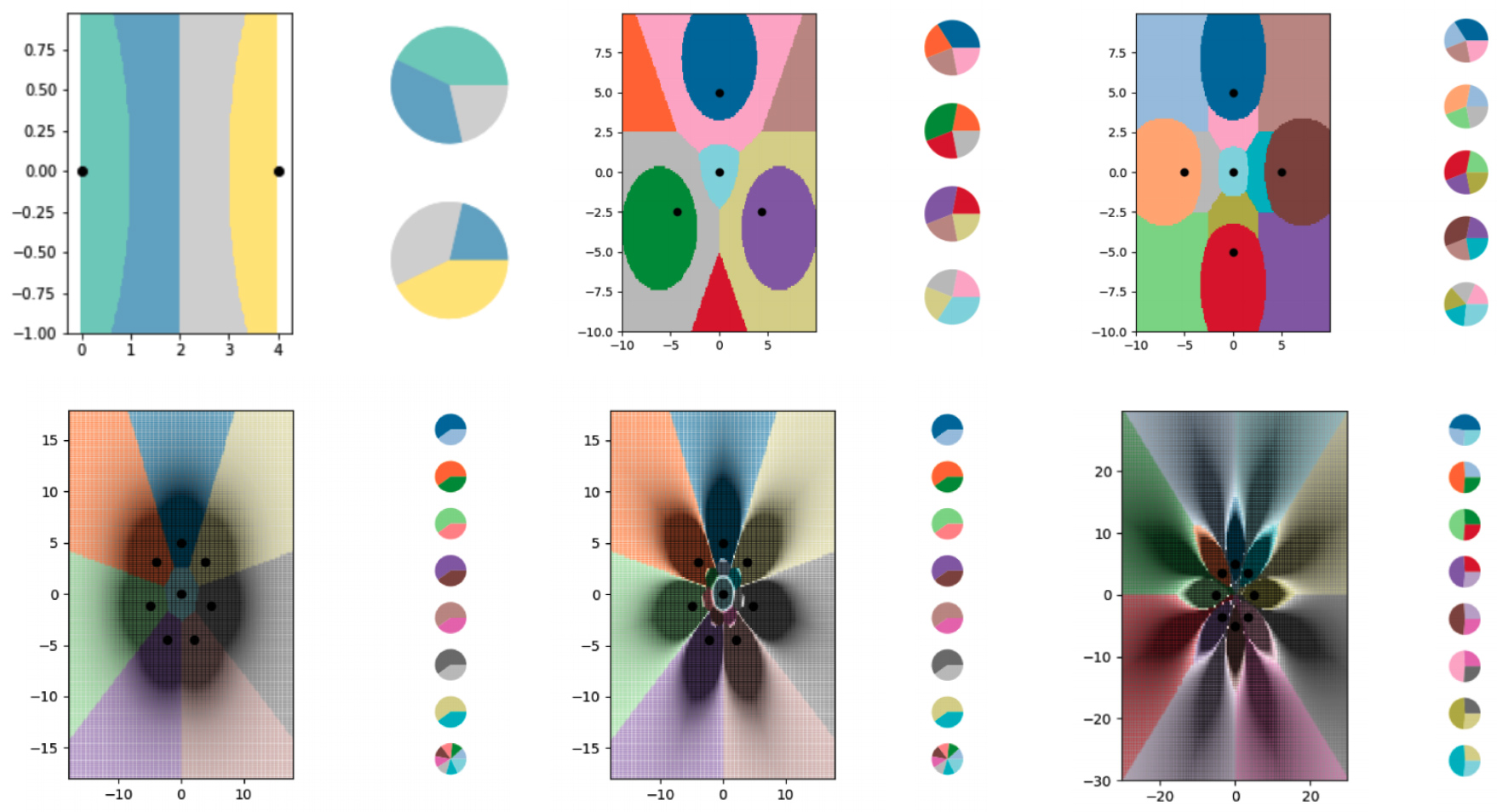
Die Forscher verwendeten Soft-Label-Beispiele, um den kNN-Algorithmus so zu trainieren, dass er immer komplexere Grenzen codiert und das Diagramm in mehr Klassen unterteilt, als es Datenpunkte enthält. Jeder der farbigen Bereiche stellt eine separate Klasse dar, und die Kreisdiagramme neben jedem Diagramm zeigen die Verteilung der weichen Beschriftungen für jeden Datenpunkt.
Ilya Sukholutsky et al.
Verschiedene Diagramme zeigen die Grenzen, die unter Verwendung des kNN-Algorithmus konstruiert wurden. Jedes Diagramm hat immer mehr Grenzlinien, die in winzigen Datensätzen codiert sind.
Natürlich hat diese theoretische Forschung einige Einschränkungen. Während die Idee, aus "weniger als einem" Versuch zu lernen, auf komplexere Algorithmen übertragen würde, wird die Aufgabe, Beispiele mit einem "weichen" Etikett zu entwickeln, viel schwieriger. Der kNN-Algorithmus ist interpretierbar und visuell, sodass Benutzer Beschriftungen erstellen können. Neuronale Netze sind komplex und undurchdringlich, was bedeutet, dass dies möglicherweise nicht für sie gilt. Die Datendestillation, die sich gut für die Entwicklung von Soft-Label-Beispielen für neuronale Netze eignet, hat auch einen erheblichen Nachteil: Bei dieser Methode müssen Sie mit einem gigantischen Datensatz beginnen und ihn auf etwas Effizienteres verkleinern.
Sukholutsky sagt, er versuche andere Wege zu finden, um diese kleinen synthetischen Datensätze zu erstellen - entweder von Hand oder mit einem anderen Algorithmus. Trotz dieser zusätzlichen Forschungskomplexität präsentiert der Artikel die theoretischen Grundlagen des Lernens. "Unabhängig davon, über welche Datensätze Sie verfügen, können Sie erhebliche Effizienzgewinne erzielen", sagte er.
Dies interessiert Tongzhou Wang, einen Doktoranden am Massachusetts Institute of Technology. Er leitete die frühere Forschung zu Destillationsdaten. „Dieser Artikel baut auf einem wirklich neuen und wichtigen Ziel auf: das Trainieren leistungsfähiger Modelle aus kleinen Datensätzen“, sagt er über Sukholutskys Beitrag.
Ryan Hurana, ein Forscher am Montreal Institute for the Ethics of Artificial Intelligence, teilt diese Ansicht: "Noch wichtiger ist, dass das Lernen in weniger als einem Versuch die Datenanforderungen für die Erstellung eines funktionierenden Modells drastisch reduziert." Dies könnte die KI für Unternehmen und Branchen zugänglicher machen, die bisher durch Datenanforderungen in diesem Bereich behindert wurden. Dies kann auch den Datenschutz der Daten verbessern, da für Schulungsmodelle weniger Informationen von Personen benötigt werden.
Sukholutsky betont, dass sich die Forschung in einem frühen Stadium befindet. Trotzdem regt es schon die Fantasie an. Immer wenn ein Autor seine Arbeit anderen Forschern vorstellt, besteht seine erste Reaktion darin, zu argumentieren, dass die Idee außerhalb des Bereichs der Möglichkeiten liegt. Wenn sie plötzlich erkennen, dass sie falsch liegen, öffnet sich eine ganz neue Welt.

