
- Was genau verbraucht so viel Speicher?
- Gibt es eine Möglichkeit, dies zu vermeiden?
Hier möchte ich darüber sprechen, wie ich nach Antworten auf diese Fragen gesucht habe. Ich habe vor, dieses Material als Referenz zu verwenden, wenn ich Python-Code profilieren muss.
Ich begann mit der Analyse von Pylint, beginnend am Programmeinstiegspunkt (
pylint/__main__.py), und kam zu der "grundlegenden" Schleife for, die Sie in einem Programm erwarten würden, das viele Dateien überprüft:
def _check_files(self, get_ast, file_descrs):
# pylint/lint/pylinter.py
with self._astroid_module_checker() as check_astroid_module:
for name, filepath, modname in file_descrs:
self._check_file(get_ast, check_astroid_module, name, filepath, modname)
Zunächst habe ich nur eine Anweisung in diese Schleife eingefügt
print(«HI»), um sicherzustellen, dass dies tatsächlich die Schleife ist, die beim Ausführen des Befehls beginnt pylint my_code. Dieses Experiment verlief reibungslos.
Als nächstes beschloss ich herauszufinden, was genau während der Arbeit von Pylint im Speicher gespeichert ist. Also habe ich es benutzt
heapyund einen einfachen "Heap-Dump" erstellt, in der Hoffnung, diesen Dump auf etwas Ungewöhnliches zu analysieren:
from guppy import hpy
hp = hpy()
i = 0
for name, filepath, modname in file_descrs:
self._check_file(get_ast, check_astroid_module, name, filepath, modname)
i += 1
if i % 10 == 0:
print("HEAP")
print(hp.heap())
if i == 100:
raise ValueError("Done")
Das Heap-Profil bestand fast ausschließlich aus Call-Stack-Frames (
types.FrameType). Ich habe aus irgendeinem Grund so etwas erwartet. Eine solche Anzahl solcher Objekte in der Müllkippe ließ mich denken, dass es mehr davon zu geben scheint, als es sein sollte.
Partition of a set of 2751394 objects. Total size = 436618350 bytes.
Index Count % Size % Cumulative % Kind (class / dict of class)
0 429084 16 220007072 50 220007072 50 types.FrameType
1 535810 19 30005360 7 250012432 57 types.TracebackType
2 516282 19 29719488 7 279731920 64 tuple
3 101904 4 29004928 7 308736848 71 set
4 185568 7 21556360 5 330293208 76 dict (no owner)
5 206170 7 16304240 4 346597448 79 list
6 117531 4 9998322 2 356595770 82 str
7 38582 1 9661040 2 366256810 84 dict of astroid.node_classes.Name
8 76755 3 6754440 2 373011250 85 tokenize.TokenInfo
In diesem Moment fand ich das Profilbrowser- Tool , mit dem Sie bequem mit solchen Daten arbeiten können.
Ich habe die Dump-Engine so konfiguriert, dass alle 10 Schleifeniterationen Daten in eine Datei geschrieben werden. Dann habe ich ein Diagramm erstellt, das das Verhalten des Programms während des Betriebs zeigt.
for name, filepath, modname in file_descrs:
self._check_file(get_ast, check_astroid_module, name, filepath, modname)
i += 1
if i % 10 == 0:
hp.heap().stat.dump("/tmp/linting.stats")
if i == 100:
hp.pb("/tmp/linting.stats")
raise ValueError("Done")
Am Ende hatte ich das, was unten gezeigt wird. Dieses Diagramm bestätigt, dass Objekte
type.FrameTypeund type.TracebackType(Trace-Informationen) während des untersuchten Pylint-Laufs viel Speicher verbraucht haben.

Datenanalyse
Die nächste Stufe der Studie war die Analyse von Objekten
types.FrameType. Da die Speicherverwaltungsmechanismen in Python darauf basieren, die Anzahl der Verweise auf Objekte zu zählen, werden Daten im Speicher gespeichert, solange sich etwas darauf bezieht. Ich beschloss herauszufinden, was genau die Daten im Speicher "hält".
Hier habe ich eine hervorragende Bibliothek verwendet
objgraph, die mithilfe der Funktionen des Python-Speichermanagers Informationen darüber liefert, welche Objekte sich im Speicher befinden, und mit denen Sie herausfinden können, was genau auf diese Objekte verweist.
Tatsächlich ist es großartig, dass wir diese Art von Software-Recherche durchführen können. Wenn es nämlich einen Verweis auf ein Objekt gibt, können Sie alles finden, was auf dieses Objekt verweist (bei C-Erweiterungen ist nicht alles so glatt, aber im Allgemeinen
objgraphgibt einigermaßen genaue Informationen). Vor uns liegt ein großartiges Tool zum Debuggen von Code, mit dem Sie auf eine Vielzahl von Informationen über die internen Mechanismen von CPython zugreifen können. Für mich ist dies ein weiterer Grund, Python als eine angenehme Arbeitssprache zu betrachten.
Zuerst bin ich auf eine Objektsuche gestoßen, weil das Team
objgraph.by_type('types.TracebackType')überhaupt nichts gefunden hat. Und das trotz der Tatsache, dass ich wusste, dass es eine große Anzahl solcher Objekte gibt. Es stellte sich heraus, dass eine Zeichenfolge als Typname verwendet werden sollte traceback. Der Grund dafür ist mir nicht ganz klar, aber was ist - das ist. Der richtige Befehl sieht am Ende so aus:
random.choice(objgraph.by_type('traceback'))
Dieses Konstrukt wählt Objekte zufällig aus
traceback. Und mit Hilfe können objgraph.show_backrefsSie ein Diagramm erstellen, das zeigt, was sich auf diese Objekte bezieht.
Am Ende habe ich mich entschieden, anstatt nur eine Ausnahme auszulösen, zu untersuchen, was nach 100 Iterationen in der Schleife
for( import pdb; pdb.set_trace()) passiert . Ich begann zufällig ausgewählte Objekte zu studieren traceback.
def exclude(obj):
return 'Pdb' in str(type(obj))
def f(depth=7):
objgraph.show_backrefs([random.choice(objgraph.by_type('traceback'))],
max_depth=depth,
filter=lambda elt: not exclude(elt))
Anfangs sah ich nur Ketten von Objekten
traceback, also beschloss ich, bis zu einer Tiefe von 100 Objekten zu klettern ...

Traceback-Objekte analysieren
Wie sich herausstellte,
tracebackverweiseneinige Objekteauf andere Objekte desselben Typs. Gut gut. Und es gab viele solcher Ketten.
Für einige Zeit, ohne großen Erfolg für das Unternehmen, studierte ich sie und ging dann zum Studium von Objekten der zweiten Art von Interesse für mich über -
FrameType(frame). Sie sahen auch misstrauisch aus. Als ich sie analysierte, kam ich zu Diagrammen, die den folgenden ähneln.

Analysieren von Frame-Objekten
Es stellt sich heraus, dass Objekte
tracebackObjekte enthaltenframe(es gibt also eine ähnliche Anzahl solcher Objekte). All dies sieht natürlich äußerst verwirrend aus, aber Objekte zeigenframezumindest auf bestimmte Codezeilen. All dies führte mich zu einer lächerlich einfachen Sache: Ich habe mich nie darum gekümmert, Daten mit so viel Speicher zu betrachten. Ich sollte mir auf jeden Fall die Objekte selbst ansehentraceback.
Ich bin auf dieses Ziel zugegangen, den kurvenreichsten aller möglichen Wege. Es erkannte nämlich die Adressen in dem Dump, der von erstellt wurde
objgraph, sah sich dann die Adressen im Speicher an und suchte im Internet nach "wie man ein Python-Objekt erhält, dessen Adresse bekannt ist". Nach all diesen Experimenten habe ich das folgende Aktionsschema entwickelt:
ipdb> import ctypes
ipdb> ctypes.cast(0x7f187d22b880, ctypes.py_object)
py_object(<traceback object at 0x7f187d22b880>)
ipdb> ctypes.cast(0x7f187d22b880, ctypes.py_object).value
<traceback object at 0x7f187d22b880>
ipdb> my_tb = ctypes.cast(0x7f187d22b880, ctypes.py_object).value
ipdb> traceback.print_tb(my_tb, limit=20)
Tatsächlich können Sie Python einfach sagen: „Sehen Sie sich diese Erinnerung an. Hier gibt es definitiv mindestens ein reguläres Python-Objekt. "
Später stellte ich fest, dass ich dank bereits Links zu Objekten hatte, die mich interessierten
objgraph. Das heißt - ich könnte sie einfach benutzen.
Es
astroidschien, als würde die Bibliothek , der in Pylint verwendete AST-Parser, überall Objekte tracebackdurch Ausnahmebehandlungscode erstellen. Ich vermute, wenn jemand etwas benutzt, das irgendwo als "interessanter Trick" bezeichnet werden kann, vergisst er, wie das Gleiche einfacher gemacht werden kann. Ich beschwere mich also nicht wirklich darüber.
Objekte
tracebackhaben viele Daten in Bezug auf astroid. Meine Forschung hat einige Fortschritte gemacht! Bibliothekastroidist einem Programm ziemlich ähnlich, das große Datenmengen im Speicher speichern kann, da es Dateien analysiert.
Ich kramte durch den Code und fand die folgenden Zeilen in der Datei
astroid/manager.py:
except Exception as ex:
raise exceptions.AstroidImportError(
"Loading {modname} failed with:\n{error}",
modname=modname,
path=found_spec.location,
) from ex
"Das ist es", dachte ich, "genau das suche ich!" Es ist eine Folge von Ausnahmen, die zu den längsten Ketten von Objekten führt
traceback. Und hier werden unter anderem Dateien analysiert, so dass auch hier rekursive Mechanismen auftreten können. Und etwas, das einer Konstruktion ähnelt, raise thing from other_thingverbindet alles miteinander.
Ich entfernte
from exund ... nichts passierte. Die vom Programm verbrauchte Speichermenge ist praktisch gleich geblieben, die Objekte tracebacksind auch nirgendwo hingegangen.
Mir war bewusst, dass Ausnahmen ihre lokalen Bindungen in Objekten speichern
traceback, damit Sie darauf zugreifen können ex. Infolgedessen kann der Speicher von ihnen nicht gelöscht werden.
Ich habe den Code massiv überarbeitet und versucht, den Block im Grunde genommen loszuwerden
exceptoder zumindest von einem Link zu ex. Aber ich habe wieder nichts bekommen.
Zumindest Crack konnte ich den Garbage Collector nicht zu Objekten "anregen"
traceback, selbst wenn man bedachte, dass es keine Verweise auf diese Objekte gab. Ich nahm an, dass der Grund dafür war, dass es irgendwo einen anderen Link gab.
Tatsächlich bin ich damals eine falsche Spur gegangen. Ich wusste nicht, ob dies die Ursache für den Speicherverlust war, da mir irgendwann klar wurde, dass ich keine Beweise für meine "Theorie der Ausnahmeketten" hatte. Ich hatte nur ein paar Vermutungen und Millionen von Objekten
traceback.
Dann fing ich an, diese Objekte zufällig zu betrachten, um nach zusätzlichen Hinweisen zu suchen. Ich habe versucht, die Gliederkette manuell zu "erklimmen", aber am Ende fand ich nur Leere.
Dann wurde mir klar: Alle diese Objekte
tracebackbefinden sich "übereinander", aber es muss ein Objekt geben, das "über" allen anderen liegt. Eines, auf das von keinem der anderen derartigen Objekte verwiesen wird.
Verknüpfungen wurden durch eine Eigenschaft hergestellt
tb_next, die Reihenfolge solcher Verknüpfungen war eine einfache Kette. Also habe ich beschlossen, mir die Objekte tracebackam Ende der jeweiligen Ketten anzusehen :
bottom_tbs = [tb for tb in objgraph.by_type('traceback') if tb.tb_next is None]
Es ist etwas Magisches, sich mit einem Einzeiler durch eine halbe Million Objekte zu stöbern und das zu finden, was Sie brauchen.
Im Allgemeinen habe ich gefunden, wonach ich gesucht habe. Es wurde der Grund gefunden, warum Python all diese Objekte im Speicher behalten musste.

Die Ursache des Problems finden
Es ging nur um den Datei-Cache!
Der Punkt ist, dass die Bibliothek
astroiddie Ergebnisse des Ladens von Modulen zwischenspeichert. Wenn der Code ein Modul benötigt, das bereits verwendet wurde, stellt die Bibliothek ihm einfach das Ergebnis des Ladens dieses Moduls zur Verfügung, das bereits vorhanden ist. Dies führt auch zur Reproduktion von Fehlern durch Speichern der ausgelösten Ausnahmen.
Zu diesem Zeitpunkt traf ich eine mutige Entscheidung und argumentierte folgendermaßen: „Es ist sinnvoll, etwas zwischenzuspeichern, das keine Fehler enthält. Aber meiner Meinung nach macht es keinen Sinn, Objekte zu speichern,
tracebackdie von unserem Code generiert wurden. "
Ich beschloss, die Ausnahme loszuwerden, meine eigene Klasse zu behalten
Errorund die Ausnahmen bei Bedarf neu zu erstellen. Details finden Sie hierPR, aber es stellte sich wirklich als nicht besonders interessant heraus.
Infolgedessen konnte ich den Speicherverbrauch bei der Arbeit mit unserer Codebasis von 500 MB auf 100 MB reduzieren.
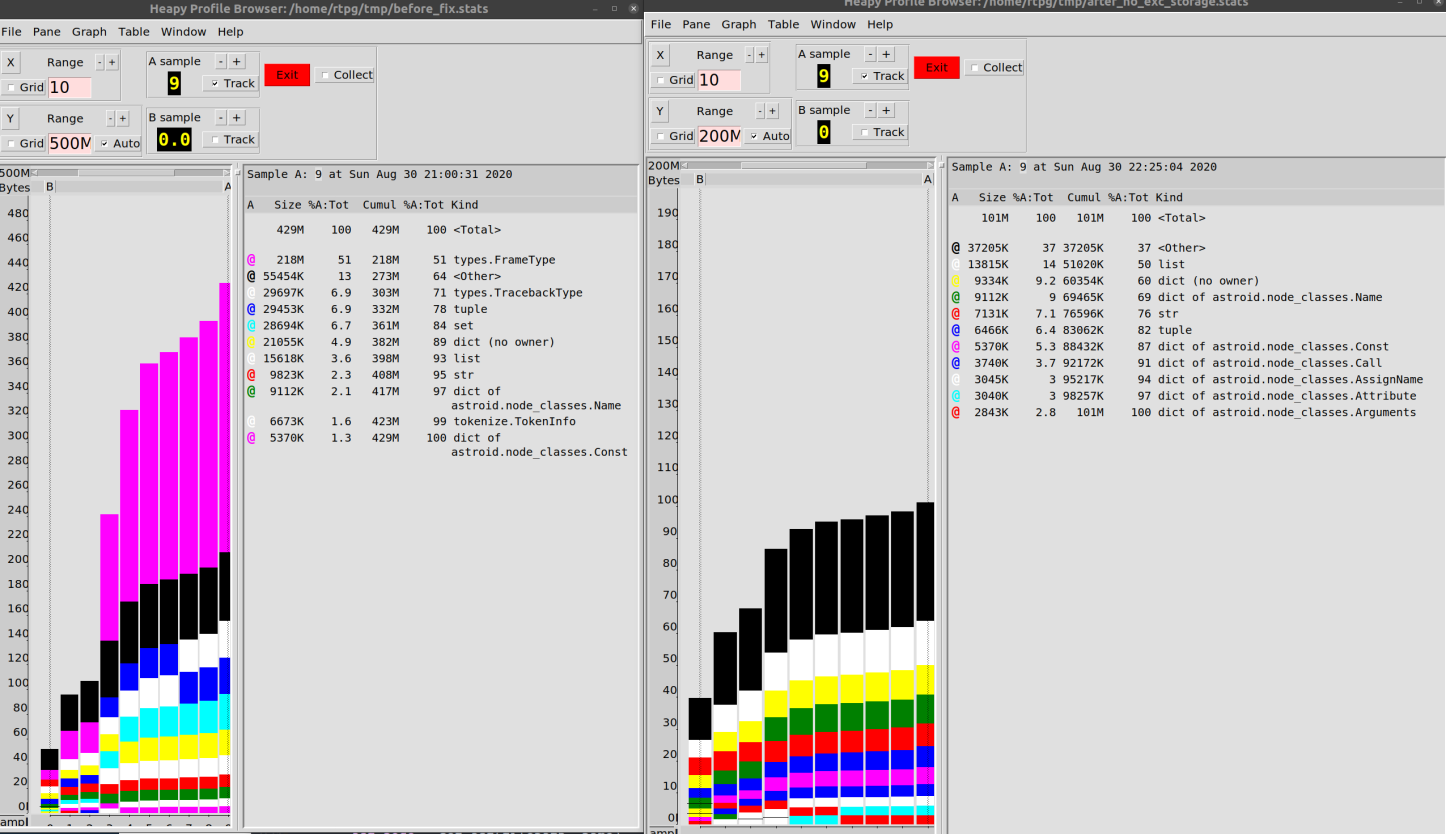
Ich würde sagen, dass eine Verbesserung um 80% nicht so schlimm ist.
Apropos PR, ich bin mir nicht sicher, ob es in das Projekt aufgenommen wird. Die Änderungen, die es an sich bringt, hängen nicht nur mit der Leistung zusammen. Ich glaube, dass die Art und Weise, wie es funktioniert, in einigen Situationen den Wert der Stack-Trace-Daten verringern kann. Dies ist unter Berücksichtigung aller Details eine ziemlich grobe Änderung, obwohl diese Lösung alle Tests besteht.
Infolgedessen habe ich folgende Schlussfolgerungen für mich gezogen:
- Python bietet uns großartige Funktionen zur Speicheranalyse. Ich sollte diese Funktionen beim Debuggen von Code häufiger verwenden.
- , .
- , -, « ». . , , , .
- , (, , Git). , , . , .
Während ich dies schrieb, stellte ich fest, dass ich bereits viel vergessen hatte, was es mir ermöglichte, zu bestimmten Schlussfolgerungen zu kommen. Also habe ich einige der Code-Schnipsel noch einmal überprüft. Dann habe ich Messungen auf einer anderen Codebasis durchgeführt und festgestellt, dass Speicher-Kuriositäten nur für ein Projekt spezifisch sind. Ich habe viel Zeit damit verbracht, dieses Ärgernis zu finden und zu beheben, aber es ist sehr wahrscheinlich, dass dies nur ein Merkmal des Verhaltens der von uns verwendeten Tools ist, das sich nur bei einer kleinen Anzahl derjenigen manifestiert, die diese Tools verwenden.
Es ist sehr schwierig, selbst nach solchen Messungen etwas Bestimmtes über die Leistung zu sagen.
Ich werde versuchen, die Erfahrungen aus den von mir beschriebenen Experimenten auf andere Projekte zu übertragen. Ich glaube, es gibt viele dieser Leistungsprobleme in Open-Source-Python-Projekten, die leicht zu beheben sind. Tatsache ist, dass die Python-Entwicklergemeinde diesem Problem normalerweise relativ wenig Aufmerksamkeit schenkt (abgesehen von Projekten, bei denen es sich um Erweiterungen von Python handelt, die in C geschrieben wurden).
Mussten Sie jemals die Leistung Ihres Python-Codes optimieren?

