Woher wissen wir, dass der Algorithmus funktioniert?
Bevor Sie einen Algorithmus entwickeln, müssen Sie sich überlegen, wie wir seine Leistung bewerten. Nehmen wir an, wir haben einen Algorithmus geschrieben, der besagt, dass "dieses Bild die folgenden Farben hat" - wird seine Entscheidung richtig sein? Und was bedeutet das überhaupt - "richtig"?
Um dieses Problem zu lösen, haben wir zwei wichtige Dimensionen ausgewählt - die korrekte Kennzeichnung der Primärfarbe und die richtige Anzahl von Farben. Wir setzen dies als den Abstand CIEDE 2000 ( Farbdifferenzformel ) zwischen der von unserem Algorithmus vorhergesagten Vordergrundfarbe und unserer tatsächlichen Vordergrundfarbe und berechnen auch den durchschnittlichen absoluten Fehler in der Anzahl der Farben. Wir haben diese Wahl aus folgenden Gründen getroffen:
- Diese Parameter sind einfach zu berechnen.
- Mit zunehmender Anzahl von Metriken wäre es schwieriger, den „besten“ Algorithmus auszuwählen.
- Durch die Reduzierung der Anzahl der Metriken fehlt möglicherweise ein wichtiger Unterschied zwischen den beiden Algorithmen.
- In jedem Fall haben die meisten Kleidungsstücke eine oder zwei Primärfarben, und viele unserer Prozesse basieren auf einer Primärfarbe. Daher ist die korrekte Berechnung der Grundfarbe viel wichtiger als die korrekte Berechnung der zweiten oder dritten Farbe.
Was ist mit "echten" Daten? Unser Merchandiser-Team hat uns Etiketten zur Verfügung gestellt. Mit unseren Tools können sie jedoch nur die gängigsten Farben wie "Grau" oder "Blau" auswählen. Sie können nicht als exakter Wert bezeichnet werden. Solche allgemeinen Definitionen umfassen einige verschiedene Farbtöne, so dass sie nicht als echte Farben verwendet werden können. Wir müssen unseren eigenen Datensatz erstellen.
Einige von Ihnen denken möglicherweise bereits an Dienstleistungen wie Mechanical Turk. Wir müssen jedoch nicht zu viele Bilder markieren, sodass es möglicherweise noch schwieriger ist, diese Aufgabe zu beschreiben, als sie nur zu erledigen. Darüber hinaus hilft Ihnen das Erstellen eines Datensatzes dabei, diesen besser zu verstehen. Wir haben schnell eine HTML / Javascript-Anwendung verpfuscht und zufällig 1000 Bilder ausgewählt, die für jedes Pixel ausgewählt wurden, das seine Primärfarbe darstellt, und die Anzahl der Farben markiert, die wir im Bild gesehen haben. Danach wurde es einfach, zwei Zahlen zu erhalten, die die Qualität unseres Algorithmus bewerten (Abstand zur Hauptfarbe CIEDE und Anzahl der Farben MAE).
Manchmal haben wir die Programme manuell überprüft, beide Algorithmen auf einem Bild ausgeführt und zwei Farblisten angezeigt. Wir haben dann manuell 200 Bilder bewertet und ausgewählt, welche Farben als „am besten“ erkannt wurden. Es ist sehr wichtig, auf diese Weise eng mit den Daten zusammenzuarbeiten - nicht nur, um das Ergebnis zu erhalten („Algorithmus B hat in 70% der Fälle besser funktioniert als Algorithmus A“), sondern auch um zu verstehen, was in jedem Fall passiert („Algorithmus B wählt normalerweise zu viele Gruppen aus, aber Algorithmus A vermisst helle Farben “).

Pullover und Farben werden durch zwei verschiedene Algorithmen ausgewählt
Unser Farbextraktionsalgorithmus
Bevor wir die Bilder verarbeiten, konvertieren wir sie in den CIELAB-Farbraum (oder einfach in LAB) anstelle des allgemeineren RGB. Infolgedessen repräsentieren unsere drei Zahlen nicht die Menge an Rot, Grün und Blau. Die Punkte des LAB-Raums (L * a * b * wäre korrekter, aber wir werden der Einfachheit halber LAB schreiben) bezeichnen drei verschiedene Achsen. L bezeichnet die Helligkeit von Schwarz 0 bis Weiß 100. A und B bezeichnen Farbe: A bezeichnet einen Ort im Bereich von -128 Grün bis 127 Rot und B von -128 Blau bis 127 Gelb. Der Hauptvorteil dieses Raums ist die wahrgenommene Gleichmäßigkeit. Der Abstand oder Unterschied zwischen zwei Punkten im LAB-Raum wird unabhängig von ihrer Position gleich wahrgenommen, wenn der euklidische Abstand zwischen ihnen im Raum ebenfalls gleich ist.
Natürlich hat das LAB andere Probleme: Wir betrachten beispielsweise Bilder auf Computerbildschirmen, die gerätespezifischen RGB-Speicherplatz verwenden. Außerdem ist der LAB-Farbumfang breiter als der von RGB, dh in LAB können Sie Farben ausdrücken, die nicht über RGB ausgedrückt werden können. Daher kann die Konvertierung von LAB in RGB nicht zweiseitig sein. Wenn Sie einen Punkt in eine Richtung und dann in die entgegengesetzte Richtung konvertieren, erhalten Sie einen anderen Wert. Theoretisch sind diese Mängel vorhanden, aber in der Praxis funktioniert die Methode immer noch.
Durch Konvertieren des Bildes in LAB erhalten wir eine Reihe von Pixeln, die als Punkte (L, A, B, X, Y) angezeigt werden können. Der Rest des Algorithmus befasst sich mit der Gruppierung dieser Punkte, wobei die Gruppen der ersten Stufe alle fünf Messungen verwenden und die zweite Stufe die X- und Y-Messungen weglässt.
Gruppierung im Raum
Wir beginnen mit einem Bild ohne Pixelgruppierung, das wie im vorherigen Artikel beschrieben farbkorrigiert , auf 320 x 200 komprimiert und in LAB konvertiert wurde.

Wenden wir zunächst den Quickshift-Algorithmus an, der benachbarte Pixel in „Superpixel“ gruppiert.

Dies reduziert unser 60.000-Pixel-Bild bereits auf einige hundert Superpixel, wodurch unnötige Komplexität vermieden wird. Sie können die Situation noch weiter vereinfachen, indem Sie benachbarte Superpixel mit einem kleinen Farbabstand zwischen ihnen zusammenführen. Dazu zeichnen wir ihren regionalen Näherungsgraphen - einen Graphen, in dem die Knoten, die zwei verschiedene Superpixel bezeichnen, durch eine Kante verbunden sind, wenn sich ihre Pixel berühren.

– (Regional Adjacency Graph, RAG) . , , , , . , , , , . – , .
Die Knoten des Diagramms sind die von uns berechneten Superpixel, und die Kanten sind der Abstand zwischen ihnen im Farbraum. Eine Kante, die zwei nahegelegene Superpixel mit ähnlichen Farben verbindet, hat ein geringes Gewicht (dunkle Linien), und eine Kante zwischen Superpixeln mit sehr unterschiedlichen Farben hat ein hohes Gewicht (helle Linien sowie das Fehlen von Linien - sie wurden nicht gezeichnet, wenn ihr Gewicht mehr als 20 betrug). Es gibt viele Möglichkeiten, nahegelegene Superpixel zu kombinieren, aber eine einfache Schwelle von 10 hat uns gereicht.
In unserem Fall ist es uns gelungen, 60.000 Pixel auf 100 Bereiche zu reduzieren, von denen jeder Pixel derselben Farbe enthält. Dies bietet Rechenvorteile: Erstens wissen wir, dass ein großes Superpixel mit fast weißer Farbe der Hintergrund ist und entfernt werden kann. Wir entfernen alle Superpixel mit L> 99 und A und B im Bereich von -0,5 bis 0,5. Zweitens können wir die Pixelanzahl im nächsten Schritt erheblich reduzieren. Wir werden ihre Anzahl nicht auf 100 reduzieren können, da wir die Bereiche basierend auf der Anzahl der enthaltenen Pixel abwägen müssen. Wir können jedoch problemlos 90% der Pixel aus jeder Gruppe entfernen, ohne zu viele Details und fast keine Verzerrungen bei der nächsten Gruppierung zu verlieren.
Gruppieren ohne Leerzeichen
In diesem Schritt haben wir mehrere tausend Pixel mit Koordinaten (L, A, B). Es gibt viele Techniken, mit denen diese Pixel gut gruppiert werden können. Wir haben uns für die k-means-Methode entschieden, weil sie schnell und einfach zu verstehen ist, unsere Daten nur drei Dimensionen haben und der euklidische Abstand im LAB-Raum sinnvoll ist.
Wir waren nicht zu schlau und hatten eine Gruppierung mit K = 8. Wenn eine Gruppe weniger als 3% der Punkte enthält, versuchen wir es erneut, diesmal mit K = 7, dann 6 und so weiter. Als Ergebnis haben wir eine Liste von 1 bis 8 Gruppierungszentren und einen Bruchteil der Anzahl von Punkten, die zu jedem der Zentren gehören. Sie werden nach dem im vorherigen Artikel beschriebenen Colornamer-Algorithmus benannt.
Ergebnisse und verbleibende Probleme
Auf der CIEDE 2000- Skala haben wir einen durchschnittlichen Abstand von 5,86 zwischen vorhergesagter und „realer“ Farbe erreicht. Es ist ziemlich schwierig, diesen Indikator richtig zu interpretieren. Bei der einfachen CIE76- Entfernungsmetrik beträgt unsere durchschnittliche Entfernung 7,82. Bei dieser Metrik bedeutet ein Wert von 2,3 einen subtilen Unterschied. Daher können wir sagen, dass unsere Ergebnisse, etwas über 3, einen subtilen Unterschied anzeigen.
Auch unser MAE war 2,28 Farben. Aber auch dies ist eine sekundäre Metrik. Viele der unten beschriebenen Algorithmen reduzieren diesen Fehler, jedoch auf Kosten der Vergrößerung des Farbabstands. Es ist viel einfacher, falsche Farben des 5. oder 6. Platzes zu ignorieren, als die falsche 1. Farbe zu ignorieren.

Sogar Dinge, die eindeutig dieselbe Farbe haben, wie diese Shorts, enthalten Bereiche, die aufgrund
von Schatten viel dunkler erscheinen . Das Problem der Schatten bleibt bestehen. Der Stoff kann nicht perfekt gleichmäßig verlegt werden, daher bleibt ein Teil des Bildes immer im Schatten und es scheint täuschend eine andere Farbe zu haben. Die einfachsten Ansätze wie das Auffinden von Duplikaten von Farben mit demselben Farbton und unterschiedlicher Helligkeit funktionieren nicht, da der Übergang von „Pixel ohne Schatten“ zu „Pixel im Schatten“ nicht immer auf die gleiche Weise funktioniert. Wir hoffen, in Zukunft komplexere Techniken wie DeshadowNet oder die automatische Schattenerkennung verwenden zu können .

Wir haben uns nur auf die Farbe der Kleidung konzentriert. Schmuck und Schuhe haben ihre eigenen Probleme: Unsere Fotos von Schmuck sind zu klein, und Fotos von Schuhen zeigen oft das Innere von ihnen. Im obigen Beispiel würden wir das Vorhandensein von Burgund und Ocker auf dem Foto anzeigen, obwohl nur der erste von ihnen wichtig ist.
Was haben wir noch versucht?
Dieser letzte Algorithmus scheint ziemlich einfach zu sein, aber es war nicht einfach, ihn zu finden! In diesem Abschnitt werde ich die Optionen beschreiben, aus denen wir versucht und gelernt haben.
Hintergrundentfernung
Wir haben Algorithmen zum Entfernen des Hintergrunds ausprobiert - zum Beispiel den Algorithmus von Lyst . Die informelle Auswertung ergab, dass sie nicht so genau funktionierten wie das einfache Entfernen des weißen Hintergrunds. Wir planen jedoch, es genauer zu untersuchen, wenn wir Bilder verarbeiten, an denen unser Fotostudio nicht gearbeitet hat.
Pixel hacken
Einige Farbextraktionsbibliotheken haben eine einfache Lösung für dieses Problem gewählt: Gruppieren Sie Pixel, indem Sie sie in mehrere ausreichend breite Container zerlegen und dann die Durchschnittswerte der LAB-Container mit der größten Anzahl von Pixeln zurückgeben. Wir haben die Colorgram.py-Bibliothek ausprobiert. Trotz seiner Einfachheit funktioniert es überraschend gut. Darüber hinaus funktioniert es schnell - nicht mehr als eine Sekunde pro Bild, während unser Algorithmus mehrere zehn Sekunden pro Bild verbringt. Colorgram.py hatte jedoch einen größeren durchschnittlichen Abstand zur Grundfarbe als unser Algorithmus - hauptsächlich, weil das Ergebnis aus den durchschnittlichen Abständen zu großen Containern abgeleitet wird. Wir verwenden es jedoch manchmal in Fällen, in denen Geschwindigkeit wichtiger ist als Genauigkeit.
Ein weiterer Superpixel-Splitting-Algorithmus
Wir verwenden den Quickshift-Algorithmus, um das Bild in Superpixel zu segmentieren, aber es gibt mehrere mögliche Algorithmen - zum Beispiel SLIC, Watershed und Felzenszwalb. In der Praxis hat Quickshift dank seiner Arbeit mit kleinen Teilen die besten Ergebnisse gezeigt. Zum Beispiel hat SLIC ein Problem mit Dingen wie Streifen, die viel Platz im Bild einnehmen. Hier sind die indikativen Ergebnisse des SLIC-Algorithmus mit verschiedenen Einstellungen:

Originalbildkompaktheit

= 1

Kompaktheit = 10

Kompaktheit = 100
Um mit unseren Daten zu arbeiten, hat Quickshift einen theoretischen Vorteil: Es erfordert keine kontinuierliche Superpixel-Kommunikation. Die Forscher stellten fest, dass dies Probleme für die Algorithmen verursachen kann, aber in unserem Fall ist dies ein Vorteil - wir stoßen häufig auf kleine Bereiche mit kleinen Details, die wir einer Gruppe zuordnen möchten. Kariertes

Hemd

Seine Superpixel-Gruppierung durch Quickshift
Während die Superpixel- Gruppierung von Quickshift chaotisch aussieht, gruppiert sie tatsächlich alle roten Streifen mit anderen roten, blauen mit blauen usw.
Verschiedene Methoden zum Zählen der Anzahl der Gruppen
Bei Verwendung der k-means-Methode stellt sich die häufigste Frage: Wie wird "k" hergestellt? Das heißt, wenn wir Punkte in eine bestimmte Anzahl von Gruppen gruppieren müssen, wie viele sollten wir tun? Zur Beantwortung der Frage wurden verschiedene Ansätze entwickelt. Die einfachste ist die „Ellbogenmethode“, erfordert jedoch eine manuelle Verarbeitung des Diagramms, und wir benötigen eine automatische Lösung. Die Gap-Statistik formalisiert diese Methode, und mit ihrer Hilfe haben wir die besten Ergebnisse für die Metrik „Anzahl der Farben“ erzielt, jedoch auf Kosten der Genauigkeit der Bestimmung der Grundfarbe. Da die Hauptfarbe am wichtigsten ist, haben wir sie nicht im Arbeitsprogramm verwendet, aber wir planen, dieses Problem weiter zu untersuchen.
Schließlich ist die Silhouette-Methode eine weitere beliebte k-Auswahlmethode. Es liefert Ergebnisse, die etwas schlechter sind als unser Algorithmus, und es hat einen schwerwiegenden Nachteil: Es benötigt mindestens 2 Gruppen. Viele Kleidungsstücke haben jedoch nur eine Farbe.
DBSCAN
Eine mögliche Lösung für die Frage der Auswahl von k besteht darin, einen Algorithmus zu verwenden, bei dem Sie diesen Parameter nicht auswählen müssen. Ein beliebtes Beispiel ist DBSCAN, das Daten nach Gruppen mit ungefähr gleicher Dichte durchsucht.

Mehrfarbige Bluse
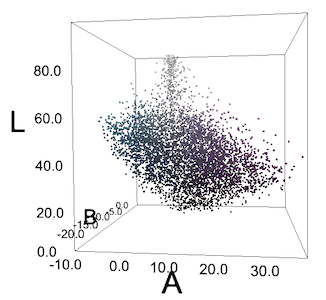
Alle Pixel ihres Bildes befinden sich im LAB-Bereich. Pixel bilden keine klaren Cyan- und Violettgruppen.
Oft bekommen wir solche Gruppen nicht oder wir sehen so etwas nur aufgrund der Besonderheiten der menschlichen Wahrnehmung. Für uns heben sich die grünlich-blauen "Gurken" auf der Bluse vom violetten Hintergrund ab, aber wenn wir alle Pixel in RGB- oder LAB-Koordinaten darstellen, bilden sie keine Gruppen. Aber wir haben DBSCAN trotzdem mit unterschiedlichen Epsilon-Werten ausprobiert - und wir haben vorhersehbar schlechte Ergebnisse erzielt.
Lösung aus Algolia
Eines der guten Prinzipien von Forschern ist es, zu sehen, ob jemand Ihr Problem bereits gelöst hat. Leo Ercolanelli von der Algolia- Website hat vor mehr als drei Jahren eine detaillierte Beschreibung der Lösung eines solchen Problems veröffentlicht. Dank ihrer Großzügigkeit bei der Verteilung der Quellen konnten wir ihre Lösung selbst ausprobieren. Die Ergebnisse waren jedoch etwas schlechter als unsere, so dass wir unseren Algorithmus verlassen haben. Sie lösen nicht das gleiche Problem wie wir: Sie hatten Bilder von Produkten auf Modellen und auf einem anderen Hintergrund als Weiß, daher ist es sinnvoll, dass sich ihre Ergebnisse von unseren unterscheiden.
Farbabstimmung
Dieser Algorithmus vervollständigt den in unserem vorherigen Artikel beschriebenen Prozess. Nach dem Extrahieren der Gruppenzentren verwenden wir Colornamer, um sie zu benennen, und importieren diese Farben dann in unsere internen Werkzeuge. Dies hilft uns, unsere Produkte einfach nach Farben zu visualisieren. Wir hoffen, diese Daten in Kaufempfehlungsalgorithmen zu integrieren. Dieser Prozess ist nicht perfekt, er hilft uns, bessere Daten über unsere Tausenden von Produkten zu erhalten, was wiederum zu unserem primären Ziel beiträgt, Menschen dabei zu helfen, die Stile zu finden, die sie lieben.
Interview über die Übersetzung des ersten Teils