Sie können sich auf Ihre Meinung verlassen, die sich aus verschiedenen Informationsquellen zusammensetzt, z. B. Veröffentlichungen auf Websites oder Erfahrungen. Sie können Kollegen und Bekannte fragen. Eine weitere Option ist die Betrachtung der Konferenzthemen: Das Programmkomitee besteht aus aktiven Vertretern der Branche, daher vertrauen wir darauf, dass sie relevante Themen auswählen. Ein separater Bereich sind Forschung und Berichte. Aber es gibt ein Problem. Jährlich werden weltweit Untersuchungen zum Zustand von DevOps durchgeführt, Berichte von ausländischen Unternehmen veröffentlicht und es gibt fast keine Informationen über russische DevOps.
Aber der Tag ist gekommen, an dem eine solche Studie durchgeführt wurde, und heute werden wir Ihnen über die erzielten Ergebnisse berichten. Der Zustand von DevOps in Russland wurde gemeinsam von Express 42 und Ontiko untersucht". Express 42 unterstützt Technologieunternehmen bei der Implementierung und Entwicklung von DevOps-Praktiken und -Tools und war einer der ersten, der über DevOps in Russland sprach. Die Autoren der Studie, Igor Kurochkin und Vitaly Khabarov, beschäftigen sich mit Analyse und Beratung bei Express 42 und verfügen über einen technischen Hintergrund aus Betrieb und Berufserfahrung in verschiedenen Unternehmen. Seit 8 Jahren beschäftigen sich Kollegen mit Dutzenden von Unternehmen und Projekten - vom Start-up bis zum Unternehmen - mit unterschiedlichen Problemen sowie unterschiedlicher kultureller und technischer Reife.
In ihrem Bericht erklärten Igor und Vitaly, welche Probleme sich im Forschungsprozess befanden, wie sie gelöst wurden, wie die DevOps-Forschung im Prinzip durchgeführt wird und warum Express 42 beschlossen hat, eine eigene durchzuführen. Ihr Bericht kann hier eingesehen werden .

DevOps-Forschung
Igor Kurochkin begann das Gespräch.
Auf DevOps-Konferenzen stellen wir dem Publikum regelmäßig eine Frage: "Haben Sie den DevOps-Statusbericht für dieses Jahr gelesen?" Nur wenige heben die Hände, und unsere Studie hat gezeigt, dass nur ein Drittel sie untersucht. Wenn Sie solche Berichte noch nie gesehen haben, sagen wir sofort, dass sie alle sehr ähnlich sind. Am häufigsten gibt es Sätze wie: "Im Vergleich zum letzten Jahr ..."
Hier haben wir das erste Problem und danach zwei weitere:
- Wir haben keine Daten für das vergangene Jahr. Der Zustand von DevOps in Russland ist für niemanden von Interesse.
- Methodik. Es ist nicht klar, wie man Hypothesen testet, wie man Fragen aufbaut, wie man Analysen durchführt, Ergebnisse vergleicht, Zusammenhänge findet;
- Terminologie. Alle Berichte sind in englischer Sprache, eine Übersetzung ist erforderlich, ein gemeinsames DevOps-Framework wurde noch nicht erfunden und jeder hat sein eigenes.
Lassen Sie uns einen Blick darauf werfen, wie die Analysen des Zustands von DevOps auf der ganzen Welt im Allgemeinen durchgeführt wurden.
Historischer Bezug
DevOps-Forschung wird seit 2011 durchgeführt. Die erste wurde von Puppet gehalten, einem Entwickler von Konfigurationsmanagementsystemen. Zu dieser Zeit war es eines der wichtigsten Werkzeuge zur Beschreibung der Infrastruktur in Form von Code. Bis 2013 wurden diese Studien lediglich in Form von geschlossenen Umfragen und ohne öffentliche Berichte durchgeführt.
2013 wurde IT Revolution geboren, der Herausgeber aller wichtigen DevOps-Bücher. Zusammen mit Puppet bereiteten sie die erste Veröffentlichung "State of DevOps" vor, in der erstmals 4 Schlüsselkennzahlen veröffentlicht wurden. Im folgenden Jahr schloss sich ThoughtWorks an, ein Beratungsunternehmen, das für seine regelmäßigen Technologie-Radargeräte zu Branchenpraktiken und -werkzeugen bekannt ist. Im Jahr 2015 wurde ein Methodikabschnitt hinzugefügt, und es wurde klar, wie sie die Analyse durchführen.
2016 veröffentlichten die Autoren der Studie, nachdem sie ihre Firma DORA (DevOps Research and Assessment) gegründet hatten, einen Jahresbericht. Im folgenden Jahr veröffentlichten DORA und Puppet zum letzten Mal einen gemeinsamen Bericht.
Und dann begann das Interessante:

Im Jahr 2018 trennten sich die Unternehmen und zwei unabhängige Berichte wurden veröffentlicht: einer von Puppet, der zweite von DORA in Zusammenarbeit mit Google. DORA hat seine Methodik weiterhin mit Schlüsselmetriken, Leistungsprofilen und Konstruktionspraktiken verwendet, die sich auf Schlüsselmetriken und die unternehmensweite Leistung auswirken. Und Puppet bot einen eigenen Ansatz an, der den Prozess und die Entwicklung von DevOps beschreibt. Die Geschichte setzte sich jedoch nicht durch. 2019 gab Puppet diese Methode auf und veröffentlichte eine neue Version der Berichte, in der die wichtigsten Praktiken und deren Auswirkungen auf DevOps aus ihrer Sicht aufgeführt waren. Dann passierte noch etwas: Google kaufte DORA und zusammen veröffentlichten sie einen weiteren Bericht. Sie haben ihn vielleicht gesehen.
Dieses Jahr wurde es kompliziert. Puppet hat bekanntlich eine eigene Umfrage gestartet. Sie haben es eine Woche früher gemacht als wir und es ist bereits zu Ende. Wir haben daran teilgenommen und gesehen, an welchen Themen sie interessiert sind. Puppet führt derzeit seine Analyse durch und bereitet die Veröffentlichung des Berichts vor.
Es gibt jedoch noch keine Ankündigung von DORA und Google. Im Mai, als die Umfrage normalerweise begann, kam die Information, dass Nicole Forsgren, eine der Gründerinnen von DORA, zu einem anderen Unternehmen gewechselt war. Wir gingen daher davon aus, dass es in diesem Jahr keine Untersuchungen und keinen Bericht von DORA geben wird.
Wie ist es in Russland?
Wir haben keine DevOps-Forschung durchgeführt. Wir sprachen auf Konferenzen, erzählten die Schlussfolgerungen anderer und die Raiffeisenbank übersetzte "State of DevOps" für 2019 (ihre Ankündigung finden Sie auf Habré), vielen Dank an sie. Und das ist alles.
Daher haben wir unsere eigenen Forschungen in Russland unter Verwendung von DORA-Methoden und -Ergebnissen durchgeführt. Wir haben den Bericht unserer Kollegen von der Raiffeisenbank für unsere Forschung verwendet, einschließlich der Synchronisation von Terminologie und Übersetzung. Die branchenspezifischen Fragen stammen aus DORA-Berichten und der diesjährigen Puppet-Umfrage.
Suchprozess
Der Bericht ist nur der letzte Teil. Der gesamte Forschungsprozess besteht aus vier großen Schritten:
Während der Vorbereitungsphase haben wir Branchenexperten befragt und eine Liste von Hypothesen erstellt. Auf ihrer Grundlage wurden Fragen erstellt und eine Umfrage für den gesamten August gestartet. Dann haben wir den Bericht selbst analysiert und vorbereitet. Für DORA dauert dieser Vorgang 6 Monate. Wir haben uns 3 Monate lang getroffen und jetzt verstehen wir, dass wir kaum genug Zeit hatten: Erst wenn Sie die Analyse durchführen, verstehen Sie, welche Fragen gestellt werden müssen.
Teilnehmer
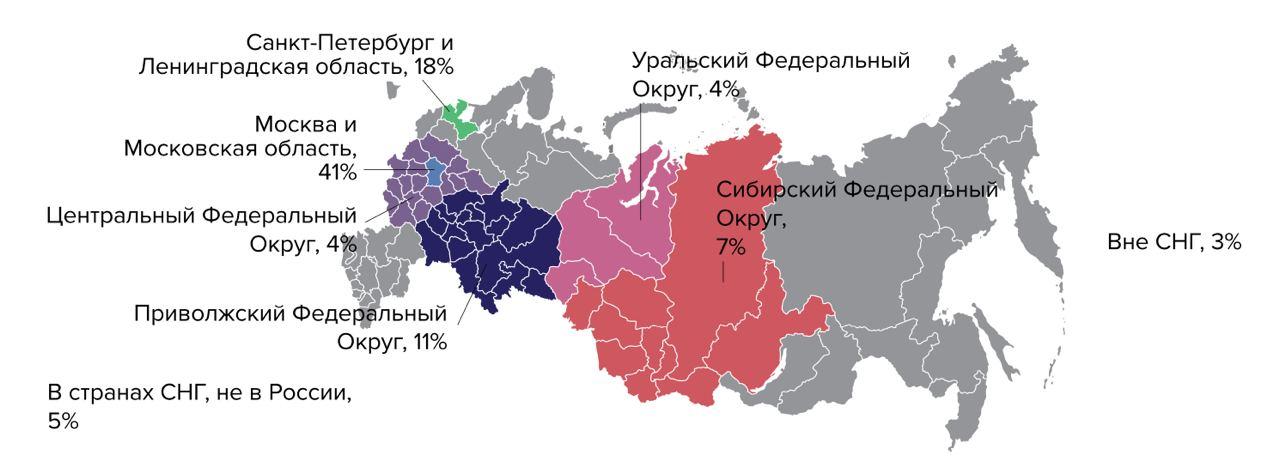
Alle Auslandsberichte beginnen mit einem Porträt der Teilnehmer, und die meisten von ihnen stammen nicht aus Russland. Der Prozentsatz der russischen Befragten schwankt von Jahr zu Jahr zwischen 5 und 1%, so dass keine Schlussfolgerungen gezogen werden können.
Karte aus dem Bericht Accelerate State of DevOps 2019:

In unserer Studie konnten wir 889 Personen interviewen - das ist ziemlich viel (DORA befragt jährlich etwa tausend Personen in seinen Berichten) und hier haben wir das Ziel erreicht:
Richtig, nicht alle unserer Teilnehmer haben das Ende erreicht: Prozentsatz Die Füllung war etwas weniger als die Hälfte. Aber auch dies reichte aus, um eine repräsentative Probe zu erhalten und eine Analyse durchzuführen. DORA gibt den Prozentsatz der Füllung in seinen Berichten nicht an, daher kann er hier nicht verglichen werden.
Branchen und Positionen
Unsere Befragten repräsentieren ein Dutzend Branchen. Die Hälfte von ihnen arbeitet in der Informationstechnologie. Es folgen Finanzdienstleistungen, Handel, Telekommunikation und andere. Zu den Positionen gehören Spezialisten (Entwickler, Tester, Betriebsingenieur) und Managementteams (Leiter von Teams, Gruppen, Anweisungen, Direktoren):

Jede Sekunde arbeitet in einem mittelständischen Unternehmen. Jede dritte Person arbeitet in großen Unternehmen. Die meisten arbeiten in Teams von bis zu 9 Personen. Unabhängig davon haben wir nach den Hauptaktivitäten gefragt, und die meisten sind auf die eine oder andere Weise mit dem Betrieb verbunden, und etwa 40% sind in der Entwicklung tätig: Auf

diese Weise haben wir Informationen zum Vergleich und zur Analyse von Vertretern verschiedener Branchen, Unternehmen und Teams gesammelt. Mein Kollege Vitaly Khabarov wird Ihnen von der Analyse erzählen.
Analyse und Vergleich
Vitaly Khabarov: Vielen Dank an alle Teilnehmer, die unsere Umfrage ausgefüllt, die Fragebögen ausgefüllt und uns Daten zur weiteren Analyse und Prüfung unserer Hypothesen gegeben haben. Dank unserer Kunden und Kunden verfügen wir über einen großen Erfahrungsschatz, der dazu beigetragen hat, Probleme zu identifizieren, die für die Branche von Belang sind, und die Hypothesen zu formulieren, die wir in unserer Forschung getestet haben.
Leider kann man nicht einfach eine Liste von Fragen einerseits und Daten andererseits nehmen, sie irgendwie vergleichen, sagen: "Ja, alles funktioniert so, wir hatten Recht" und sich zerstreuen. Nein, wir brauchen Methoden und statistische Methoden, um sicherzugehen, dass wir uns nicht irren und unsere Schlussfolgerungen zuverlässig sind. Dann können wir unsere weitere Arbeit auf der Grundlage dieser Daten aufbauen:

Schlüsselkennzahlen
Wir haben die DORA-Methodik zugrunde gelegt, die sie im Buch "Accelerate State of DevOps" ausführlich beschrieben haben. Wir haben geprüft, ob die Schlüsselkennzahlen für den russischen Markt geeignet sind. Können sie auf die gleiche Weise verwendet werden, wie DORA die Frage beantwortet: "Wie entspricht die Branche in Russland der ausländischen Branche?"
Schlüsselkennzahlen:
- Bereitstellungshäufigkeit. Wie oft wird eine neue Version einer Anwendung in der Produktionsumgebung bereitgestellt (geplante Änderungen, ausgenommen Hotfixes und Reaktion auf Vorfälle)?
- Lieferzeit. Was ist die durchschnittliche Zeit zwischen dem Festschreiben einer Änderung (Schreiben von Funktionen als Code) und dem Bereitstellen der Änderung in der Produktumgebung?
- . , , ?
- . ( , )?
DORA hat in seiner Forschung einen Zusammenhang zwischen diesen Metriken und der organisatorischen Leistung festgestellt. Wir überprüfen es auch in unserer Studie.
Aber um sicherzustellen, dass die vier Schlüsselmetriken etwas beeinflussen können, müssen Sie verstehen - sind sie irgendwie miteinander verbunden? DORA bejahte dies mit einer Einschränkung: Die Beziehung zwischen der Änderungsfehlerrate und den anderen drei Metriken ist etwas schwächer. Wir haben ungefähr das gleiche Bild. Wenn Lieferzeit, Bereitstellungshäufigkeit und Wiederherstellungszeit miteinander korrelieren (wir haben diese Korrelation durch die Pearson-Korrelation und durch die Chaddock-Skala gefunden), gibt es keine so starke Korrelation mit erfolglosen Änderungen.
Grundsätzlich neigen die meisten Befragten dazu zu antworten, dass sie nur eine relativ geringe Anzahl von Vorfällen in der Produktion haben. Obwohl wir in Zukunft feststellen werden, dass es zwischen den Befragtengruppen immer noch einen signifikanten Unterschied in Bezug auf die Rate erfolgloser Änderungen gibt, können wir diese Metrik für diese Abteilung noch nicht verwenden.
Wir verbinden dies mit der Tatsache, dass (wie sich bei der Analyse und Kommunikation mit einigen unserer Kunden herausstellte) ein geringfügiger Unterschied in der Wahrnehmung eines Vorfalls besteht. Wenn wir es geschafft haben, die Funktionsfähigkeit unseres Dienstes während des technischen Fensters wiederherzustellen, kann dies als Vorfall angesehen werden? Wahrscheinlich nicht, weil wir alles repariert haben, sind wir großartig. Kann es als Vorfall angesehen werden, wenn wir unsere Anwendung 10 Mal in einem für uns üblichen, für uns üblichen Modus neu ausrollen mussten? Es scheint nicht. Daher bleibt die Frage nach der Beziehung erfolgloser Änderungen zu anderen Metriken offen. Wir werden es weiter verfeinern.
Hierbei ist es wichtig, dass wir eine signifikante Korrelation zwischen Lieferzeiten, Wiederherstellungszeiten und Bereitstellungshäufigkeit gefunden haben. Daher haben wir diese drei Metriken verwendet, um die Befragten weiter in Leistungsgruppen zu unterteilen.
Wie viel in Gramm wiegen?
Wir haben eine hierarchische Clusteranalyse verwendet:
- Wir verteilen die Befragten im n-dimensionalen Raum, wobei die Koordinate jedes Befragten die Antwort auf Fragen ist.
- Wir deklarieren jeden Befragten als kleinen Cluster.
- Wir kombinieren die beiden Cluster, die einander am nächsten liegen, zu einem größeren Cluster.
- Suchen Sie das nächste Clusterpaar und kombinieren Sie sie zu einem größeren Cluster.
Auf diese Weise gruppieren wir alle unsere Befragten in die erforderliche Anzahl von Clustern. Mit Hilfe eines Dendrogramms (eines Baums von Verbindungen zwischen Clustern) sehen wir den Abstand zwischen zwei benachbarten Clustern. Wir müssen nur noch eine bestimmte Entfernungsgrenze zwischen diesen Clustern festlegen und sagen: "Diese beiden Gruppen sind ziemlich voneinander unterscheidbar, weil die Entfernung zwischen ihnen sehr groß ist."
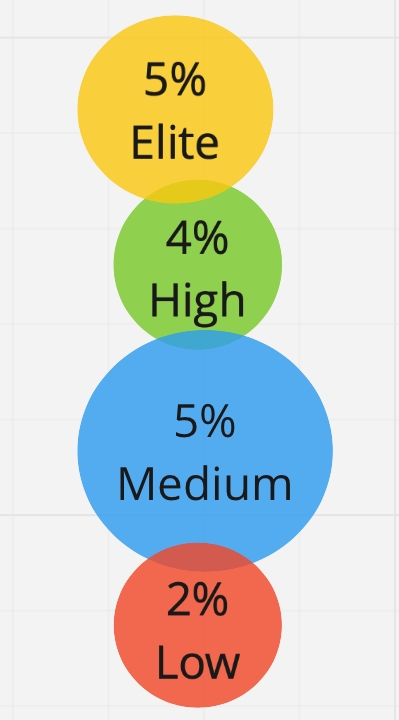
Hier gibt es jedoch ein verstecktes Problem: Wir haben keine Einschränkungen hinsichtlich der Anzahl der Cluster - wir können 2, 3, 4, 10 Cluster erhalten. Und die erste Idee war - warum nicht alle unsere Befragten in 4 Gruppen aufteilen, wie es DORA tut. Wir haben jedoch festgestellt, dass die Unterschiede zwischen diesen Gruppen unbedeutend werden, und wir können nicht sicher sein, dass der Befragte wirklich zu seiner eigenen Gruppe und nicht zu der benachbarten gehört. Wir können den russischen Markt immer noch nicht in vier Gruppen einteilen. Daher haben wir bei genau drei Profilen angehalten, zwischen denen es einen statistisch signifikanten Unterschied gibt:

Als Nächstes haben wir das Profil durch Cluster bestimmt: Wir haben die Mediane für jede Metrik für jede Gruppe genommen und eine Tabelle mit Leistungsprofilen erstellt. Tatsächlich haben wir die Leistungsprofile des durchschnittlichen Teilnehmers in jeder Gruppe erhalten. Wir haben drei Effizienzprofile identifiziert: Niedrig, Mittel, Hoch:

Hier haben wir unsere Hypothese bestätigt, dass die 4 Schlüsselmetriken zur Bestimmung des Leistungsprofils geeignet sind und sowohl auf dem westlichen als auch auf dem russischen Markt funktionieren. Es gibt einen Unterschied zwischen den Gruppen und er ist statistisch signifikant. Ich möchte betonen, dass es einen signifikanten Unterschied im Durchschnitt zwischen den Leistungsprofilen gemäß der Metrik der erfolglosen Änderungen gibt, obwohl wir die Befragten anfangs nicht durch diesen Parameter geteilt haben.
Dann stellt sich die Frage: Wie benutzt man das alles?
Wie benutzt man
Wenn wir ein Team mit 4 Schlüsselkennzahlen auf die Tabelle anwenden, erhalten wir in 85% der Fälle keine vollständige Übereinstimmung - dies ist nur ein durchschnittlicher Teilnehmer und nicht das, was in der Realität der Fall ist. Wir sind alle (und jedes Team) ein bisschen anders.
Wir haben überprüft: Wir haben unsere Befragten und das DORA-Leistungsprofil genommen und uns angesehen, wie viele Befragte zu einem bestimmten Profil passen. Wir haben festgestellt, dass nur 16% der Befragten eines der Profile genau getroffen haben. Alle anderen sind irgendwo dazwischen verstreut:
Dies bedeutet, dass das Leistungsprofil einen begrenzten Umfang hat. Um zu verstehen, wo Sie sich in erster Näherung befinden, können Sie diese Tabelle verwenden: "Oh, es scheint, wir sind näher an Mittel oder Hoch!" Wenn Sie verstehen, wohin Sie als Nächstes gehen müssen, kann dies ausreichen. Wenn Ihr Ziel jedoch eine konstante, kontinuierliche Verbesserung ist und Sie genauer wissen möchten, wo Sie sich entwickeln und was zu tun ist, benötigen Sie zusätzliche Mittel. Wir nannten sie Taschenrechner:
- DORA Rechner
- Rechner Express 42 * (in Entwicklung)
- Eigene Entwicklung (Sie können Ihren eigenen internen Rechner erstellen).
Wofür werden sie benötigt? Verstehen:
- Entspricht das Team in unserer Organisation unseren Standards?
- Wenn nicht, können wir ihr helfen - sie im Rahmen des Fachwissens unseres Unternehmens beschleunigen?
- Wenn ja, können wir es noch besser machen?
Sie können sie auch verwenden, um Statistiken innerhalb des Unternehmens zu sammeln:
- Welche Teams haben wir?
- Teilen Sie Teams in Profile auf.
- Siehe: Oh, diese Teams sind unterdurchschnittlich (sie ziehen nicht ein wenig), und diese sind cool: Sie werden jeden Tag ohne Fehler eingesetzt und haben eine Vorlaufzeit von weniger als einer Stunde.
Und dann können Sie feststellen, dass in unserem Unternehmen das erforderliche Fachwissen und die erforderlichen Tools für die Teams vorhanden sind, die sich immer noch nicht behaupten.
Oder wenn Sie verstehen, dass Sie sich innerhalb des Unternehmens großartig fühlen, dass Sie besser als viele sind, können Sie einen breiteren Blick darauf werfen. Dies ist nur die russische Industrie: Können wir das notwendige Fachwissen in der russischen Industrie erhalten, um uns selbst zu beschleunigen? Calculator Express 42 hilft hier (es befindet sich in der Entwicklung). Wenn Sie dem russischen Markt entwachsen sind, schauen Sie sich den DORA-Rechner und den globalen Markt an.
Okay. Und was tun, wenn Sie in der Elit-Gruppe des DORA-Rechners sind? Hier gibt es keine gute Lösung. Höchstwahrscheinlich sind Sie an der Spitze der Branche, und eine weitere Beschleunigung und Verbesserung der Zuverlässigkeit ist aufgrund interner F & E und höherer Ressourcen möglich.
Kommen wir zum süßesten Vergleich.
Vergleich
Wir wollten zunächst die russische Industrie mit der westlichen Industrie vergleichen. Wenn wir direkt vergleichen, sehen wir, dass wir weniger Profile haben und sie etwas mehr miteinander vermischt sind, die Grenzen etwas verschwommener sind:

Unsere Elite-Performer sind unter den High-Performern versteckt, aber sie existieren - sie sind die Elite, Einhörner, die bedeutende Höhen erreicht haben. In Russland ist der Unterschied zwischen dem Elite-Profil und dem High-Profil noch nicht signifikant genug. Wir glauben, dass diese Trennung in Zukunft im Zusammenhang mit der Verbesserung der Ingenieurkultur, der Qualität der Umsetzung der Ingenieurspraktiken und dem Fachwissen in Unternehmen stattfinden wird.
Wenn wir zu einem direkten Vergleich innerhalb der russischen Industrie übergehen, sehen wir, dass die hochkarätigen Teams in jeder Hinsicht besser sind. Wir haben auch unsere Hypothese bestätigt, dass es einen Zusammenhang zwischen diesen Kennzahlen und der organisatorischen Leistung gibt: Teams mit hohem Bekanntheitsgrad erreichen Ziele viel eher nicht nur, sondern übertreffen sie auch.
Lassen Sie uns zu hochkarätigen Teams werden und nicht aufhören:
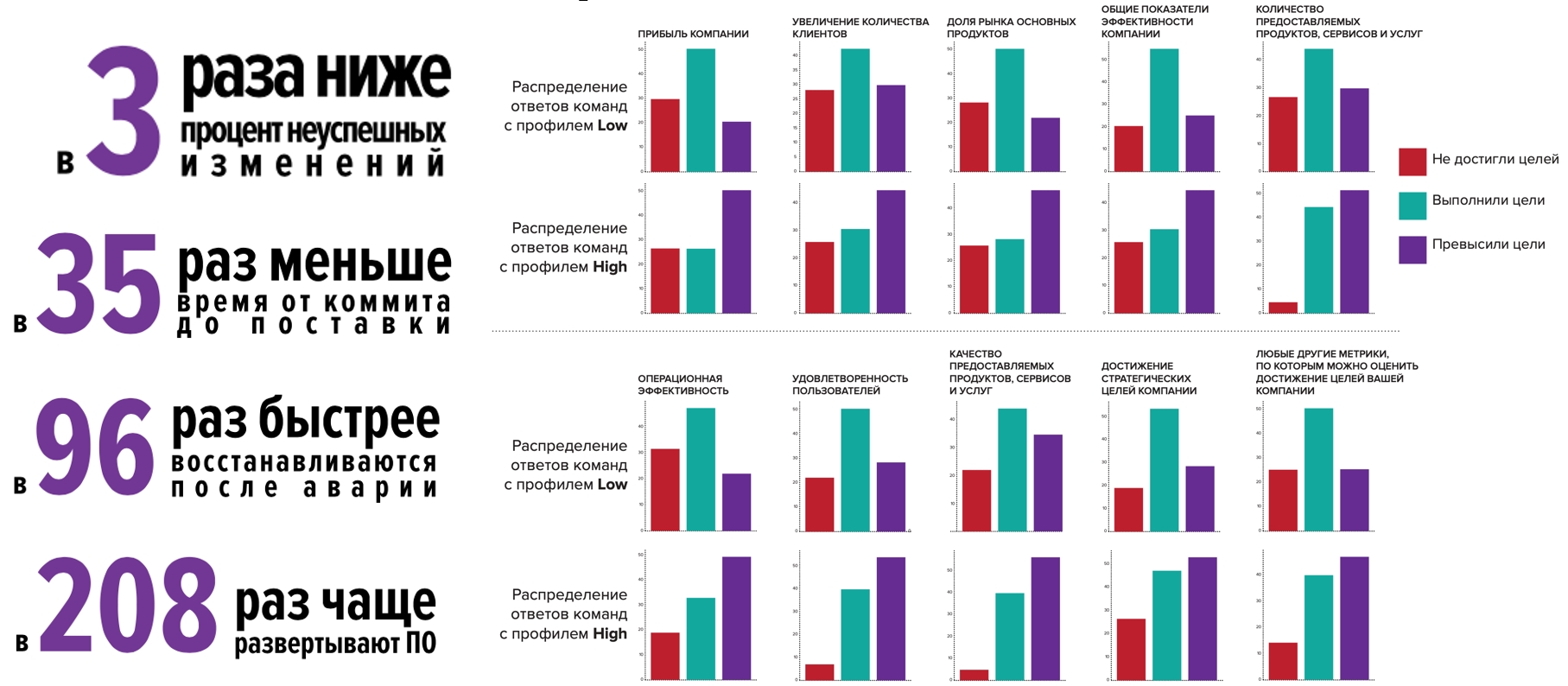
Aber dieses Jahr ist etwas Besonderes, und wir haben uns entschlossen zu prüfen, wie Unternehmen in einer Pandemie leben: Hochkarätige Teams schneiden viel besser ab und fühlen sich besser als der Branchendurchschnitt:
- Neue Produkte wurden 1,5-2-mal häufiger veröffentlicht
- 2x höhere Wahrscheinlichkeit, die Zuverlässigkeit und / oder Leistung der Anwendungsinfrastruktur zu verbessern.
Das heißt, die Kompetenzen, die sie bereits hatten, halfen ihnen, sich schneller zu entwickeln, neue Produkte einzuführen, bestehende Produkte zu modifizieren und dadurch neue Märkte und neue Benutzer zu erobern:

Was hat unseren Teams noch geholfen?
Ingenieurspraktiken

Ich erzähle Ihnen von den signifikanten Ergebnissen jeder Praxis, die wir überprüft haben. Vielleicht hat etwas anderes den Teams geholfen, aber wir sprechen über DevOps. Und innerhalb von DevOps sehen wir einen Unterschied zwischen Teams in verschiedenen Profilen.
Plattform als Service
Wir fanden keine signifikante Beziehung zwischen dem Alter der Plattform und dem Teamprofil: Plattformen wurden sowohl für niedrige als auch für hohe Teams ungefähr zur gleichen Zeit angezeigt. Für letztere bietet die Plattform im Durchschnitt mehr Dienste und mehr Programmierschnittstellen zur Steuerung durch Programmcode. Und Plattformteams helfen ihren Entwicklern und Teams eher dabei, die Plattform zu nutzen, häufiger ihre plattformbezogenen Probleme und Vorfälle zu lösen und andere Teams zu schulen.

Infrastruktur als Code
Hier ist alles ziemlich normal. Wir haben eine Beziehung zwischen der Automatisierung des Infrastrukturcodes und der Speicherung von Informationen im Infrastruktur-Repository gefunden. Hochkarätige Befehle speichern weitere Informationen in Repositorys: Infrastrukturkonfiguration, CI / CD-Pipeline, Umgebungseinstellungen und Erstellungsparameter. Sie speichern diese Informationen häufiger, arbeiten besser mit Infrastrukturcode und haben mehr Prozesse und Aufgaben für die Arbeit mit Infrastrukturcode automatisiert.
Interessanterweise konnten wir bei den Infrastrukturtests keinen signifikanten Unterschied feststellen. Ich verbinde dies mit der Tatsache, dass die High Profile-Befehle im Allgemeinen mehr Testautomatisierung haben. Vielleicht sollten sie nicht separat durch Infrastrukturtests abgelenkt werden, aber die Tests, mit denen sie Anwendungen überprüfen, reichen aus, und dank ihnen können sie bereits sehen, was und wo sie kaputt gegangen sind.
Integration und Lieferung
Der langweiligste Abschnitt, da wir bestätigt haben, dass je mehr Automatisierung Sie haben, desto besser Sie mit dem Code arbeiten, desto wahrscheinlicher ist es, dass Sie die besten Metriken erhalten.
Die Architektur
Wir wollten sehen, wie sich Microservices auf die Leistung auswirken. In Wahrheit jedoch nicht, da der Einsatz von Microservices nicht mit einer Erhöhung der Leistungsindikatoren verbunden ist. Microservices werden sowohl von den High Profile-Befehlen als auch von den Low Profile-Befehlen verwendet.
Entscheidend ist jedoch, dass High-Teams durch den Übergang zu einer Microservice-Architektur ihre Services unabhängig entwickeln und einführen können. Wenn die Architektur es Entwicklern ermöglicht, autonom zu handeln und nicht auf jemanden außerhalb des Teams zu warten, ist dies eine Schlüsselkompetenz zur Steigerung der Geschwindigkeit. Hier helfen Microservices. Und nur ihre Umsetzung spielt keine große Rolle.
Wie haben wir das alles gefunden?
Wir hatten einen ehrgeizigen Plan, um die DORA-Methodik vollständig zu replizieren, aber es fehlten uns Ressourcen. Wenn DORA viel Sponsoring einsetzt und die Forschung ein halbes Jahr dauert, haben wir unsere Forschung in kurzer Zeit durchgeführt. Wir wollten ein DevOps-Modell wie DORA bauen und werden es in Zukunft tun. Bisher haben wir uns auf Heatmaps beschränkt:

Wir haben die Verteilung der Konstruktionspraktiken auf die Teams jedes Profils untersucht und festgestellt, dass Teams im High Profile im Durchschnitt häufiger Konstruktionspraktiken anwenden. Mehr dazu lesen Sie in unserem Bericht .
Wechseln wir zur Abwechslung von komplexen zu einfachen Statistiken.
Was haben wir noch gefunden?
Werkzeuge
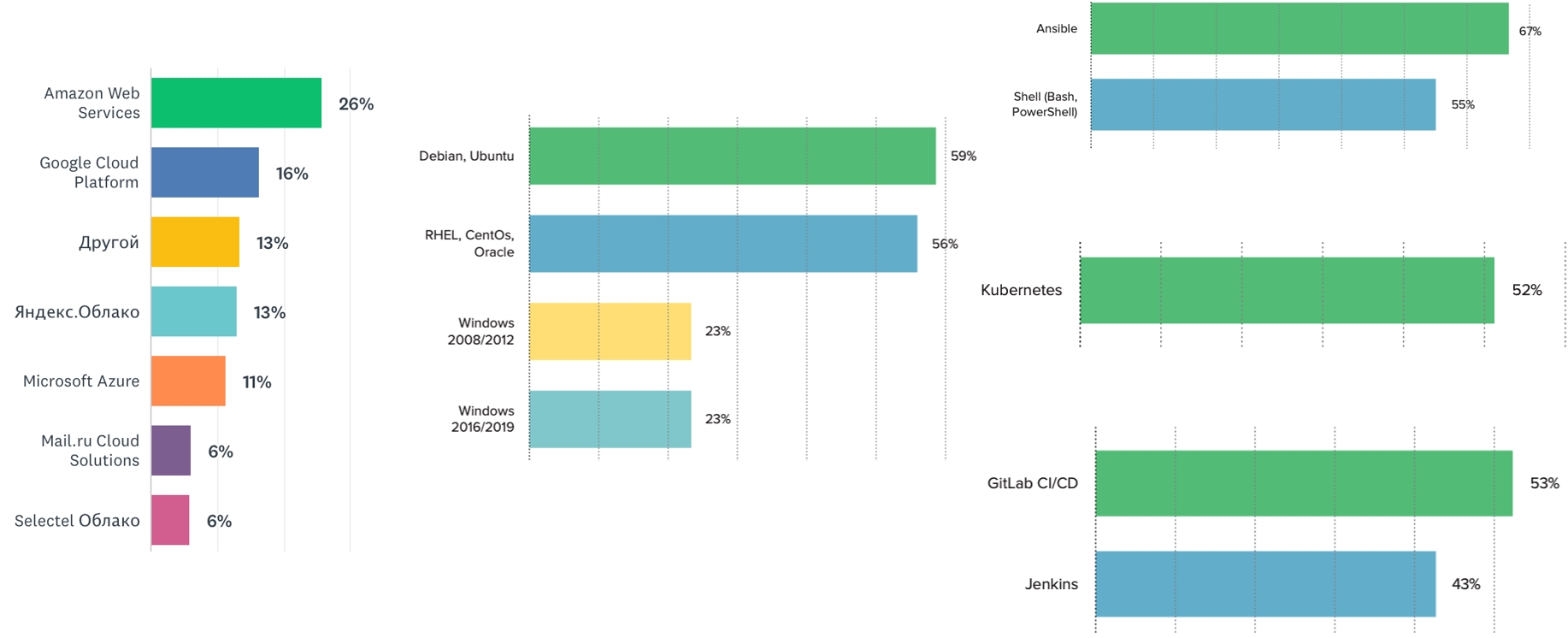
Wir stellen fest, dass die meisten Teams das Linux-Betriebssystem verwenden. Windows ist jedoch immer noch im Trend - mindestens ein Viertel unserer Befragten gab an, die eine oder andere Version davon zu verwenden. Der Markt scheint dieses Bedürfnis zu haben. Daher können Sie diese Kompetenzen entwickeln und Präsentationen auf Konferenzen halten.
Kubernetes ist führend unter den Orchestratoren (52%). Der nächste Orchestrator in der Reihe ist Docker Swarm (ca. 12%). Die beliebtesten CI-Systeme sind Jenkins und GitLab. Das beliebteste Konfigurationsmanagementsystem ist Ansible, gefolgt von unserer geliebten Shell.
Amazon ist nach wie vor führend unter den Cloud-Hosting-Diensten. Der Anteil der russischen Wolken nimmt allmählich zu. Nächstes Jahr wird es interessant sein zu sehen, wie sich russische Cloud-Anbieter fühlen und ob ihr Marktanteil wächst. Sie sind es, Sie können sie verwenden, und es ist gut:
Ich gebe Igor das Wort, der weitere Statistiken geben wird.
Verbreitung von Praktiken
Igor Kurochkin: Unabhängig davon haben wir die Befragten gebeten anzugeben, wie die berücksichtigten technischen Praktiken im Unternehmen verbreitet werden. Die meisten Unternehmen verfolgen einen gemischten Ansatz mit unterschiedlichen Mustern, und Pilotprojekte sind sehr beliebt. Wir haben auch einen kleinen Unterschied zwischen den Profilen gesehen. Hochkarätige Vertreter verwenden häufiger das Muster „Initiative von unten“, wenn kleine Spezialistenteams Arbeitsprozesse und Tools ändern und erfolgreiche Entwicklungen mit anderen Teams teilen. Bei Medium ist dies eine Initiative von oben, die sich auf das gesamte Unternehmen auswirkt, indem Gemeinschaften und Kompetenzzentren geschaffen werden:

Agile und DevOps
Die Beziehung zwischen Agile und DevOps ist ein heißes Thema in der Branche. Dieses Problem wird auch im State of Agile-Bericht für 2019/2020 angesprochen. Daher haben wir beschlossen, die Beziehung zwischen Agile- und DevOps-Aktivitäten in Unternehmen zu vergleichen. Wir haben festgestellt, dass nicht agile DevOps selten sind. Bei der Hälfte der Befragten begann die Verbreitung von Agile viel früher, und etwa 20% beobachteten einen gleichzeitigen Start. Eines der Anzeichen für ein geringes Profil ist das Fehlen von Agile- und DevOps-Praktiken:

Befehlstopologien
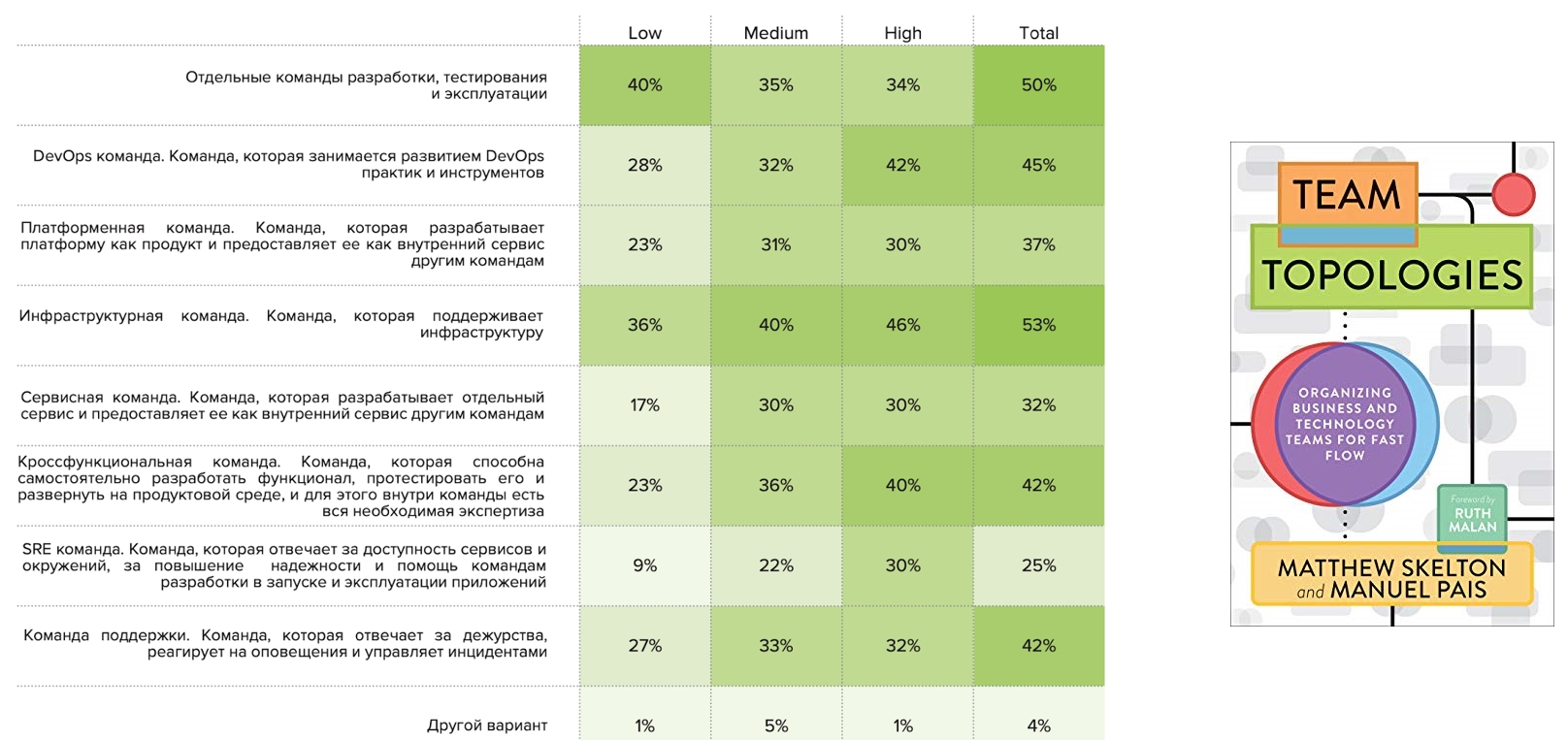
Ende letzten Jahres wurde das Buch " Teamtopologien " veröffentlicht, in dem ein Rahmen für die Beschreibung von Teamtopologien vorgeschlagen wurde. Wir haben uns gefragt, ob es für russische Unternehmen gilt. Und wir stellten die Frage: "Welche Muster finden Sie?"
Infrastrukturteams werden von der Hälfte der Befragten sowie separate Entwicklungs-, Test- und Betriebsteams beobachtet. Einzelne DevOps-Teams wurden von 45% vermerkt, darunter sind häufig hohe Vertreter vertreten. Es folgen funktionsübergreifende Teams, die auch für High häufiger sind. Separate SRE-Befehle werden in den Profilen "Hoch" und "Mittel" und selten im Profil "Niedrig" angezeigt:
DevQaOps-Verhältnis
Wir haben diese Frage in FaceBook vom Teamleiter der Skyeng-Plattform gesehen - er war am Verhältnis von Entwicklern, Testern und Administratoren in Unternehmen interessiert. Wir haben danach gefragt und uns die Antworten anhand der Profile angesehen: Die Vertreter des High Profile haben weniger Test- und Betriebsingenieure für jeden Entwickler:
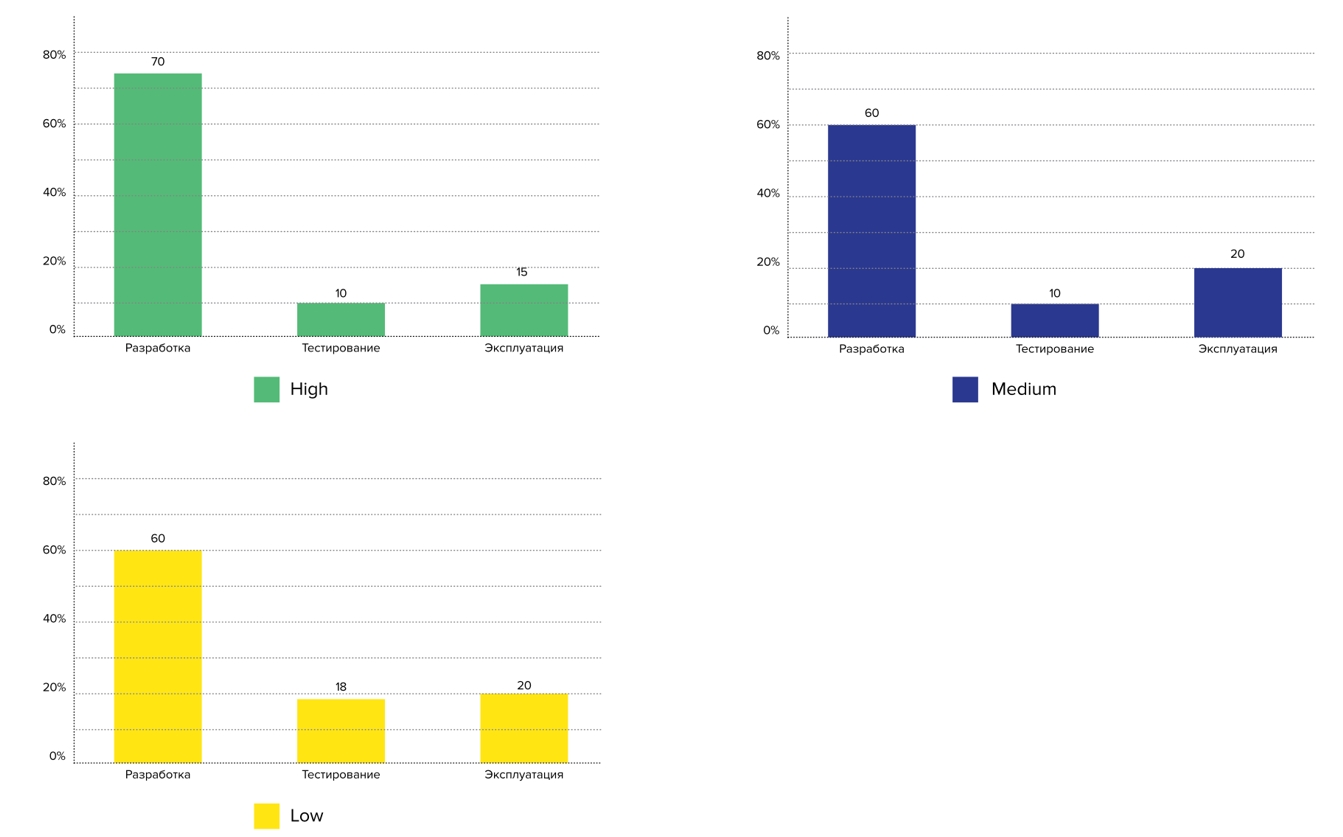
Pläne für 2021
In ihren Plänen für das nächste Jahr haben die Befragten die folgenden Aktivitäten vermerkt:

Hier sehen Sie den Schnittpunkt mit der DevOps Live 2020-Konferenz. Wir haben das Programm sorgfältig geprüft:
- Infrastruktur als Produkt
- DevOps-Transformation
- Verbreitung von DevOps-Praktiken
- DevSecOps
- Fallclubs und Diskussionen
Unsere Rede wird jedoch nicht ausreichen, um alle Themen zu behandeln. Hinter den Kulissen gelassen:
- Plattform als Dienstleistung und als Produkt;
- Infrastruktur als Code, Umgebungen und Clouds;
- Kontinuierliche Integration und Bereitstellung;
- Die Architektur;
- DevSecOps-Muster;
- Plattform- und funktionsübergreifende Teams.
Unser Bericht erwies sich auf 50 Seiten als umfangreich, und Sie können ihn detaillierter sehen.
Zusammenfassen
Wir hoffen, dass unsere Forschung und unser Bericht Sie dazu inspirieren werden, mit neuen Ansätzen für Entwicklung, Test und Betrieb zu experimentieren und Ihnen dabei zu helfen, zu navigieren, sich mit anderen Forschungsteilnehmern zu vergleichen und Bereiche zu identifizieren, in denen Sie Ihre eigenen Ansätze verbessern können.
Ergebnisse der ersten Umfrage zum Zustand von DevOps in Russland:
- Schlüsselkennzahlen. Wir haben festgestellt, dass wichtige Metriken (Vorlaufzeit, Bereitstellungshäufigkeit, Wiederherstellungszeit und erfolglose Änderungen) für die Analyse der Effektivität von Entwicklung, Test und Betrieb geeignet sind.
- High, Medium, Low. High, Medium, Low , , . High , Low. .
- , 2021 . , . High , , .
- DevOps-Praktiken, -Tools und deren Entwicklung. Die Hauptpläne der Unternehmen für das nächste Jahr umfassen die Entwicklung von DevOps-Praktiken und -Tools, die Einführung von DevSecOps-Praktiken und eine Änderung der Organisationsstruktur. Die effektive Implementierung und Entwicklung von DevOps-Praktiken erfolgt durch Pilotprojekte, die Bildung von Communities und Kompetenzzentren sowie Initiativen auf der oberen und unteren Ebene des Unternehmens.
Wir freuen uns über Ihr Feedback, Ihre Geschichten und Ihr Feedback. Vielen Dank an alle, die an der Studie teilgenommen haben, und wir freuen uns auf Ihre Teilnahme im nächsten Jahr.