
Bildquelle
Zwei Revolutionen in der Verarbeitung natürlicher Sprache
Die erste Revolution in NLP war mit dem Erfolg von Modellen verbunden, die auf Vektordarstellungen der Semantik einer Sprache basierten und mit unbeaufsichtigten Lernmethoden erhalten wurden. Die Blüte dieser Modelle begann mit der Veröffentlichung der Ergebnisse von Tomáš Mikolov , Doktorand Yoshua Bengio (einer der Gründerväter des modernen Deep Learning, Gewinner des Turing-Preises)) und die Entstehung des beliebten word2vec-Tools. Die zweite Revolution begann mit der Entwicklung von Aufmerksamkeitsmechanismen in wiederkehrenden neuronalen Netzen, was zu dem Verständnis führte, dass der Aufmerksamkeitsmechanismus autark ist und ohne das wiederkehrende Netz selbst verwendet werden kann. Das resultierende neuronale Netzwerkmodell wird als "Transformator" bezeichnet. Es wurde der wissenschaftlichen Gemeinschaft 2017 in einem Artikel mit dem Titel "Aufmerksamkeit ist alles, was Sie brauchen " vorgestellt, der von einer Gruppe von Forschern von Google Brain und Google Research verfasst wurde. Die rasante Entwicklung transformatorbasierter Netzwerke hat zu riesigen Sprachmodellen wie OpenAIs Generative Pre-Training Transformer 3 (GPT-3) geführt.in der Lage, viele NLP-Probleme effizient zu lösen.
Das Training von Riesentransformatormodellen erfordert erhebliche Rechenressourcen. Sie können nicht einfach eine moderne Grafikkarte nehmen und ein solches Modell auf Ihrem Heimcomputer trainieren. Die ursprüngliche OpenAI-Veröffentlichung enthält 8 Varianten des Modells. Wenn Sie die kleinste Variante (GPT-3 Small) mit 125 Millionen Parametern verwenden und versuchen, sie mit einer professionellen Grafikkarte NVidia V100 zu trainieren, die mit leistungsstarken Tensorkernen ausgestattet ist, dauert dies etwa sechs Monate. Wenn wir die größte Version des Modells mit 175 Milliarden Parametern nehmen, muss das Ergebnis fast 500 Jahre warten. Die Kosten für die Schulung der größten Version des Modells zu den Raten von Cloud-Diensten, die moderne Computergeräte zur Miete anbieten,mehr als eine Milliarde Rubel (und dies unterliegt immer noch einer linearen Leistungsskalierung mit einer Zunahme der Anzahl der beteiligten Prozessoren, was im Prinzip nicht erreichbar ist).
Es lebe der Supercomputer!
Es ist klar, dass solche Experimente nur Unternehmen mit erheblichen Rechenressourcen zur Verfügung stehen. Um diese Probleme zu lösen, hat die Sberbank 2019 den Christophari-Supercomputer in Betrieb genommen , der unter den in unserem Land verfügbaren Supercomputern den ersten Platz in der Leistung einnahm. 75 DGX-2- Rechenknoten (jeweils mit 16 NVidia V100- Karten ), die über einen ultraschnellen Bus auf Basis der Infiniband- Technologie verbunden sindDamit können Sie GPT-3 Small in nur wenigen Stunden trainieren. Selbst für eine solche Maschine ist es jedoch nicht trivial, größere Varianten des Modells zu trainieren. Erstens ist ein Teil der Maschine mit der Schulung anderer Modelle beschäftigt, die zur Lösung von Problemen im Bereich Computer Vision, Spracherkennung und -synthese sowie in vielen anderen Bereichen von Interesse für verschiedene Unternehmen aus dem Sberbank-Ökosystem entwickelt wurden. Zweitens ist der Lernprozess selbst, der gleichzeitig viele Rechenknoten in einer Situation verwendet, in der die Modellgewichte nicht in den Speicher einer Karte passen, eher nicht standardisiert.
Im Allgemeinen befanden wir uns in einer Situation, in der die vielen vertraute Fackel nicht für unsere Zwecke geeignet war. Wir hatten nicht so viele Optionen, am Ende haben wir uns der "nativen" Implementierung von Megatron-LM für NVidia zugewandtund Microsofts neue Idee - DeepSpeed , für die benutzerdefinierte Docker-Container auf Christophari erstellt werden mussten, bei denen unsere Kollegen von SberCloud umgehend geholfen haben . DeepSpeed hat uns zunächst praktische Tools für das modellparallele Training zur Verfügung gestellt, dh ein Modell auf mehrere GPUs verteilt und den Optimierer zwischen den GPUs aufgeteilt. Auf diese Weise können Sie größere Chargen sowie Zugmodelle mit mehr als 1,5 Milliarden Gewichten ohne einen Berg zusätzlichen Codes verwenden.
Überraschenderweise hat die Technologie im letzten halben Jahrhundert in ihrer Entwicklung die nächste Runde der Spirale beschrieben - es sieht so aus, als würde die Ära der Mainframes (leistungsstarke Computer mit Terminalzugang) zurückkehren. Wir sind bereits daran gewöhnt, dass die wichtigsten Entwicklungstools ein Personal Computer sind, der ausschließlich vom Entwickler verwendet wird. In den späten 1960er und frühen 1970er Jahren kostete eine Stunde Mainframe-Betrieb ungefähr so viel wie ein voller Monatslohn für einen Computerbetreiber! Es schien, dass diese Zeiten für immer vorbei waren und "Eisen" für immer billiger wurde als die Arbeitszeit. Es sieht jedoch so aus, als hätte die Hardware ein beeindruckendes Comeback hingelegt. Der Alltag eines modernen Spezialisten für maschinelles Lernen ähnelt wieder dem Alltag von Sasha Privalov aus der Geschichte der Brüder Strugatsky "Montag beginnt am Samstag".mit dem einzigen Unterschied, dass "Christofari" in unserem Fall den Platz von "Aldan" einnimmt und die Rolle von Magie und Zauberei durch Methoden des tiefen Lernens ausgeübt wird.
Aus SberDevices Erfahrung
In der Vergangenheit mussten wir oft andere Modelle lernen, die auf Transformatoren basieren - dies sind verschiedene Erben von BERT und Encoder-Decoder-Modelle wie T5 von Google . Virtuelle Assistenten, die von SberDevices für verschiedene Oberflächen erstellt wurden, beginnend mit der neuesten SberBox und SberPortalund am Ende der bekannten Sberbank Online-Anwendung verwenden sie in ihrer Arbeit mehrere ähnliche Modelle, um verschiedene Probleme im Verlauf der Kommunikation mit dem Benutzer zu lösen. Zum Beispiel verwendet der virtuelle Assistent Joy das GPT-2 Medium-Modell im Chatter-Modus, das auf einem großen Korpus russischer Literatur trainiert, in einem speziellen Dialogdatensatz „vervollständigt“ und mit einem speziellen Ranking-Mechanismus ausgestattet ist, mit dem die interessantesten Antworten ausgewählt werden können. Solche Modelle sind in der Lage, ein Gespräch mit dem Benutzer zu führen, ohne Hinweise aus einer vorbereiteten Antwortbibliothek auszuwählen, sondern ihre eigenen Sätze „on the fly“ zu erstellen, wodurch die Kommunikation mit ihnen vielfältiger und unterhaltsamer wird.
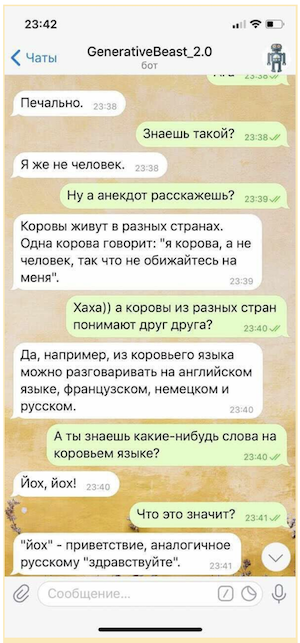

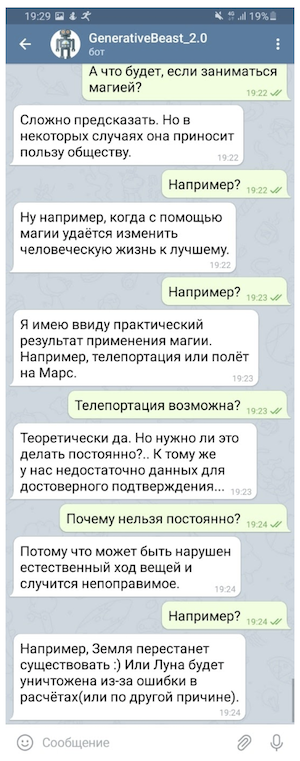
Natürlich kann ein solches "Geschwätz" nicht ohne eine Versicherung in Form eines Systems von Mikrointents (Regeln, die kontrollierte Antworten auf einige der sensibelsten Fragen geben sollen) und eines separaten Modells verwendet werden, um provokativen Fragen auszuweichen, aber auch in einer so begrenzten Form "Generatives" "Geschwätz" kann die Stimmung seines Gesprächspartners deutlich verbessern.
Kurz gesagt, unsere Erfahrung im Unterrichten großer Transformatormodelle hat sich als nützlich erwiesen, als das Management der Sberbank beschloss, Rechenressourcen für ein Forschungsprojekt zur Schulung von GPT-3 bereitzustellen. Für ein solches Projekt mussten die Anstrengungen mehrerer Einheiten gleichzeitig kombiniert werden. Die Führungsrolle in diesem Prozess wurde von SberDevices von der Abteilung für experimentelle maschinelle Lernsysteme (unter Beteiligung einer Reihe von Experten aus anderen Teams) und von Sberbank.AI - vom NLP- Team von AGI übernommen . Unsere Kollegen von SberCloud, die Christophari unterstützen, haben sich ebenfalls aktiv dem Projekt angeschlossen.
Gemeinsam mit Kollegen des AGI NLP-Teams ist es uns gelungen, die erste Version des russischsprachigen Trainingskorpus mit einem Gesamtvolumen von über 600 GB zusammenzustellen. Es enthält eine riesige Sammlung russischer Literatur, Schnappschüsse der russischen und englischen Wikipedia, eine Sammlung von Schnappschüssen von Nachrichten und Q & A- Sites, öffentliche Bereiche von Pikabu , eine vollständige Sammlung von Materialien aus dem populärwissenschaftlichen Portal 22century.ru und dem Bankenportal banki.ru sowie das Korpus Omnia Russica . Da wir mit der Fähigkeit experimentieren wollten, mit Programmcode umzugehen , haben wir außerdem Schnappschüsse von Github und StackOverflow in das Trainingskorpus aufgenommen.... Das AGI NLP-Team hat viel Arbeit in Bezug auf Datenbereinigung und Deduplizierung geleistet sowie Sets für die Modellvalidierung und -prüfung vorbereitet. Wenn im ursprünglichen Korpus, der von OpenAI verwendet wird, das Verhältnis von Englisch zu anderen Sprachen 93: 7 beträgt, beträgt das Verhältnis von Russisch zu anderen Sprachen in unserem Fall ungefähr 9: 1.
Wir haben die Architekturen GPT-3 Medium (350 Millionen Parameter) und GPT-3 Large (760 Millionen Parameter) als Grundlage für die ersten Experimente ausgewählt. Dabei haben wir das Modell wie bei alternierenden Transformatorblöcken mit einer geringen Dichte trainiertund dichte Aufmerksamkeitsmechanismen und Modelle, in denen alle Aufmerksamkeitsblöcke vollständig waren. Tatsache ist, dass die ursprüngliche Arbeit von OpenAI über Interleaving-Blöcke spricht, aber nicht deren spezifische Reihenfolge angibt. Wenn alle Aufmerksamkeitsblöcke im Modell vollständig sind, erhöht dies die Rechenkosten für das Training, stellt jedoch sicher, dass das Vorhersagepotential des Modells voll ausgeschöpft wird. Derzeit untersucht die wissenschaftliche Gemeinschaft aktiv verschiedene Aufmerksamkeitsmodelle, um die Rechenkosten von Trainingsmodellen zu senken und die Genauigkeit zu erhöhen. In kurzer Zeit haben Forscher einen Longformer , einen Reformer , einen Transformator mit einer adaptiven Aufmerksamkeitsspanne vorgeschlagen., Komprimierter Transformator [Transformator komprimierend] , ENBLOCK-Transformator [blockweiser Transformator] , BigBird , Transformator mit linearer Komplexität [Linformer] und mehrere andere ähnliche Modelle. Wir forschen auch auf diesem Gebiet, während Modelle, die nur aus dichten Blöcken bestehen, eine Art Benchmark sind, mit dem wir den Grad der Abnahme der Genauigkeit verschiedener "beschleunigter" Versionen des Modells beurteilen können.
Wettbewerb "AI 4 Geisteswissenschaften: ruGPT-3"
In diesem Jahr organisierte das Sberbank.AI-Team im Rahmen von AI Journey den Wettbewerb AI 4 Humanities: ruGPT-3. Im Rahmen des Gesamttests werden die Teilnehmer gebeten, Prototypen von Lösungen für alle geschäftlichen oder sozialen Probleme einzureichen, die mit dem vorab geschulten ruGPT-3-Modell erstellt wurden. Die Teilnehmer an der speziellen Nominierung "AIJ Junior" werden gebeten, eine Lösung für die Erstellung aussagekräftiger Aufsätze zu vier humanitären Themen (russische Sprache, Geschichte, Literatur, Sozialwissenschaften) der Klasse 11 (USE) auf der Grundlage von ruGPT-3 auf der Grundlage von ruGPT-3 für ein bestimmtes Thema / einen bestimmten Text der Aufgabe zu erstellen.
Speziell für diese Wettbewerbe haben wir drei Versionen des GPT-3-Modells trainiert: 1) GPT-3 Medium, 2) GPT-3 Large mit abwechselnd spärlichen und dichten Transformatorblöcken, 3) das "leistungsstärkste" GPT-3 Large, das nur aus diesen besteht dichte Blöcke. Die Trainingsdatensätze und Tokenizer sind für alle Modelle identisch - der BBPE-Tokenizer und unser benutzerdefinierter Large1-Datensatz mit einem Volumen von 600 GB wurden verwendet (seine Zusammensetzung ist im obigen Text angegeben).
Alle drei Modelle stehen im Wettbewerbs-Repository zum Download zur Verfügung.
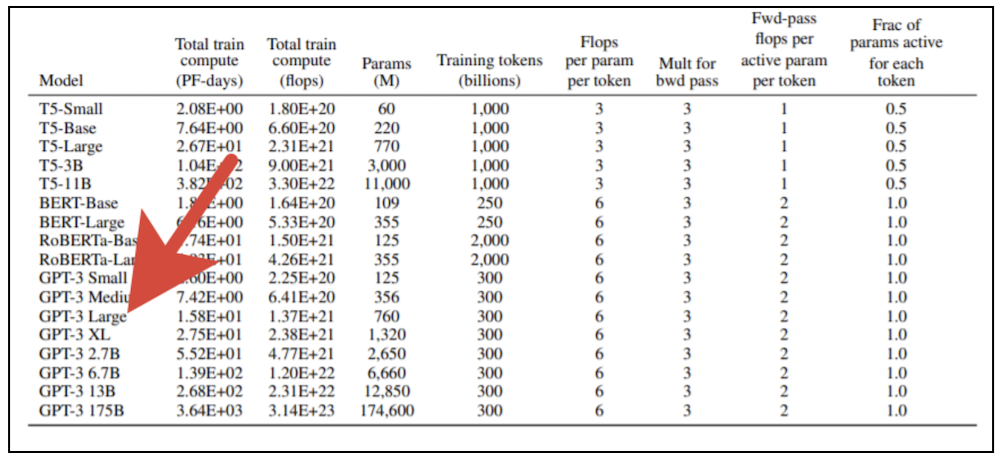
Hier sind einige lustige Beispiele, wie das dritte Modell funktioniert:



Wie werden Modelle wie GPT-3 unsere Welt verändern?
Es ist wichtig zu verstehen, dass Modelle wie GPT-1/2/3 tatsächlich genau ein Problem lösen - sie versuchen, das nächste Token (normalerweise ein Wort oder einen Teil davon) in der Reihenfolge der vorherigen vorherzusagen. Dieser Ansatz ermöglicht es, "unbeschriftete" Daten für das Training zu verwenden, dh ohne einen "Lehrer" einzubeziehen, und ermöglicht andererseits die Lösung einer ziemlich breiten Palette von Problemen aus dem NLP-Bereich. In der Tat ist im Text eines Dialogs beispielsweise eine Antwort-Antwort eine Fortsetzung der Kommunikationsgeschichte, in einer Fiktion - der Text jedes Absatzes setzt den vorherigen Text fort, und in einer Frage-Antwort-Sitzung folgt der Text der Antwort dem Text der Frage. Infolgedessen können Modelle mit großer Kapazität viele solcher Probleme ohne besondere zusätzliche Schulung lösen - sie benötigen nur die Beispiele, die in den "Modellkontext" passen.welches GPT-3 ziemlich beeindruckend hat - bis zu 2048 Token.
GPT-3 ist nicht nur in der Lage, Texte (einschließlich Gedichte, Witze und literarische Parodien) zu generieren, sondern auch Grammatikfehler zu korrigieren, Dialoge zu führen und sogar (AUSSERHALB DES STAATS!) Mehr oder weniger aussagekräftigen Programmcode zu schreiben. Viele interessante Anwendungen von GPT-3 finden sich auf der Website des unabhängigen Forschers Gwern Branwen. Branuen entwickelt eine Idee, die in einem Scherz- Tweet von Andrej Karpathy zum Ausdruck kommt, und stellt eine interessante Frage: Erleben wir die Entstehung eines neuen Programmierparadigmas?
Hier ist der Text von Karpatys Original-Tweet:
„Ich liebe die Idee von Software 3.0. Die Programmierung geht von der Vorbereitung von Datensätzen zur Vorbereitung von Abfragen über, mit denen das Meta-Learning-System die zu erledigende Aufgabe "verstehen" kann. LOL "[Ich liebe die Idee für Software 3.0. Programmieren des Wechsels vom Kuratieren von Datensätzen zum Kuratieren von Eingabeaufforderungen, damit der Meta-Lernende die Aufgabe "bekommt", die er ausführen soll. LOL].
Branuen entwickelt Karpatys Idee und schreibt:
« GPT-3 [ ] , : , , , ( GPT-2); , , , [prompt], , , «» - , , . , , «» «», GPT-3 . « » , : , , , , , , , , , ».
Da unser Modell Github und StackOverflow im Lernprozess "gesehen" hat, ist es durchaus in der Lage, Code zu schreiben (manchmal nicht ohne sehr tiefe Bedeutung):
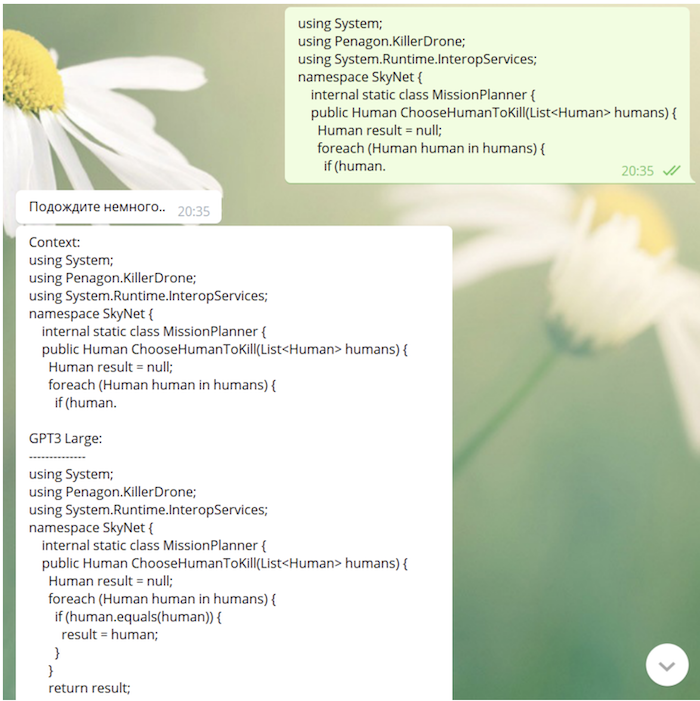
Was weiter
In diesem Jahr werden wir weiter an riesigen Transformatormodellen arbeiten. Weitere Pläne beziehen sich auf die weitere Erweiterung und Bereinigung von Datensätzen (sie umfassen insbesondere Schnappschüsse des Preprint-Dienstes arxiv.org für wissenschaftliche Veröffentlichungen und der PubMed Central-Forschungsbibliothek, spezialisierte Dialogdatensätze und Datensätze zur symbolischen Logik), die Vergrößerung trainierter Modelle sowie deren Verwendung verbesserter Tokenizer.
Wir hoffen, dass die Veröffentlichung geschulter Modelle die Arbeit russischer Forscher und Entwickler anregen wird, die überaus leistungsstarke Sprachmodelle benötigen, da Sie auf der Grundlage von ruGPT-3 Ihre eigenen Originalprodukte erstellen und verschiedene wissenschaftliche und geschäftliche Probleme lösen können. Versuchen Sie es mit unseren Modellen, experimentieren Sie mit ihnen und teilen Sie sie mit allen Ergebnissen, die Sie erhalten. Der wissenschaftliche Fortschritt macht unsere Welt besser und interessanter. Verbessern wir gemeinsam die Welt!