

Neue Datenlandschaft - neue Datenspeicherung
Die Intensität der Datenmanipulation nimmt in allen Branchen zu. Und der Bankensektor ist ein klares Beispiel dafür. In den letzten Jahren hat sich die Anzahl der Bankgeschäfte mehr als verzehnfacht. Wie die BCG-Studie zeigt , hat sich die Zahl der bargeldlosen Transaktionen mit Plastikkarten allein in Russland im Zeitraum von 2010 bis 2018 mehr als verdreifacht - von 5,8 auf 172 pro Person und Jahr. Der Punkt ist vor allem der Triumph der Mikrozahlungen: Die meisten von uns sind dem Online-Banking ähnlich geworden, und die Bank ist jetzt zur Hand - am Telefon.
Die IT-Infrastruktur eines Kreditinstituts muss für eine solche Herausforderung gerüstet sein. Und das ist wirklich eine Herausforderung. Unter anderem, wenn die Bank früher die Verfügbarkeit von Daten nur während ihrer Arbeitszeit sicherstellen musste, ist sie jetzt rund um die Uhr verfügbar. Bis vor kurzem galten 5 ms als akzeptable Norm für die Latenz, na und? Jetzt ist sogar 1 ms zu viel. Für ein modernes Speichersystem beträgt das Ziel 0,5 ms.
Gleiches gilt für die Zuverlässigkeit: In den 2010er Jahren wurde ein empirisches Verständnis gebildet, dass es ausreichte, sein Niveau auf „fünf Dutzend“ zu bringen - 99,999%. Dieses Verständnis ist zwar veraltet. Im Jahr 2020 ist es für Unternehmen völlig normal, 99,9999% für Speicher und 99,99999% für die Gesamtarchitektur zu verlangen. Und das ist überhaupt keine Laune, sondern ein dringender Bedarf: Entweder gibt es kein Zeitfenster für die Wartung der Infrastruktur oder es ist winzig.

Aus Gründen der Übersichtlichkeit ist es zweckmäßig, diese Indikatoren auf die Geldebene zu projizieren. Am einfachsten geht es am Beispiel von Finanzinstituten. Das obige Diagramm zeigt, wie viel jede der Top 10 Weltbanken in einer Stunde verdient. Allein für die Industrial and Commercial Bank of China sind dies nicht weniger als 5 Millionen US-Dollar. Genau wie viel kostet eine Stunde Ausfallzeit der IT-Infrastruktur des größten Kreditinstituts in China (und nur entgangene Gewinne werden bei der Berechnung berücksichtigt!). Aus dieser Perspektive ist klar, dass die Reduzierung von Ausfallzeiten und die Erhöhung der Zuverlässigkeit nicht nur um einige Prozent - sogar um einen Bruchteil eines Prozent - völlig rational gerechtfertigt sind. Nicht nur aus Gründen der Steigerung der Wettbewerbsfähigkeit, sondern auch einfach, um die Marktposition zu behaupten.
Vergleichbare Veränderungen finden in anderen Branchen statt. Zum Beispiel im Flugverkehr: Vor der Pandemie gewann der Flugverkehr nur von Jahr zu Jahr an Fahrt, und viele benutzten ihn fast wie ein Taxi. In Bezug auf die Verbrauchermuster hat die Gesellschaft eine tief verwurzelte Angewohnheit der vollständigen Zugänglichkeit von Diensten: Bei der Ankunft am Flughafen benötigen wir eine Wi-Fi-Verbindung, Zugang zu Zahlungsdiensten, zu einer Karte des Gebiets usw. Infolgedessen die Belastung der Infrastruktur und der Dienste im öffentlichen Raum um ein Vielfaches erhöht. Und die Ansätze, Infrastruktur, Bau, die wir noch vor einem Jahr für akzeptabel hielten, werden schnell obsolet.

Ist es zu früh, um auf All-Flash umzusteigen?
Um die oben genannten Probleme zu lösen, sind aus Sicht der AFA-Leistung All-Flash-Arrays, dh Arrays, die vollständig auf Flash basieren, am besten geeignet. Es sei denn, bis vor kurzem bestanden Zweifel daran, ob sie in ihrer Zuverlässigkeit mit denen vergleichbar sind, die auf der Basis von Festplatten und mit Hybrid-Festplatten zusammengebaut wurden. Immerhin hat Solid-State-Flash eine Metrik wie die mittlere Zeit zwischen Ausfällen oder MTBF. Der Abbau von Zellen aufgrund von E / A-Operationen ist leider eine Selbstverständlichkeit.
Die Aussichten für All-Flash wurden daher von der Frage überschattet, wie Datenverluste für den Fall verhindert werden können, dass SSDs eine lange Lebensdauer haben. Das Sichern ist eine übliche Option, aber die Wiederherstellungszeit wäre aufgrund moderner Anforderungen unannehmbar lang. Ein anderer Ausweg besteht darin, eine zweite Speicherebene auf Spindelantrieben einzurichten. Dieses Schema verliert jedoch einige der Vorteile eines "streng Flash" -Systems.
Die Zahlen sagen jedoch etwas anderes aus: Statistiken der Giganten der digitalen Wirtschaft, einschließlich Google, haben in den letzten Jahren gezeigt, dass Flash um ein Vielfaches zuverlässiger ist als Festplatten. Darüber hinaus sowohl über einen kurzen Zeitraum als auch über einen langen Zeitraum: Im Durchschnitt dauert es vier bis sechs Jahre, bis Flash-Laufwerke ausfallen. In Bezug auf die Zuverlässigkeit der Datenspeicherung sind sie Laufwerken auf Spindelmagnetplatten in keiner Weise unterlegen oder übertreffen diese sogar.
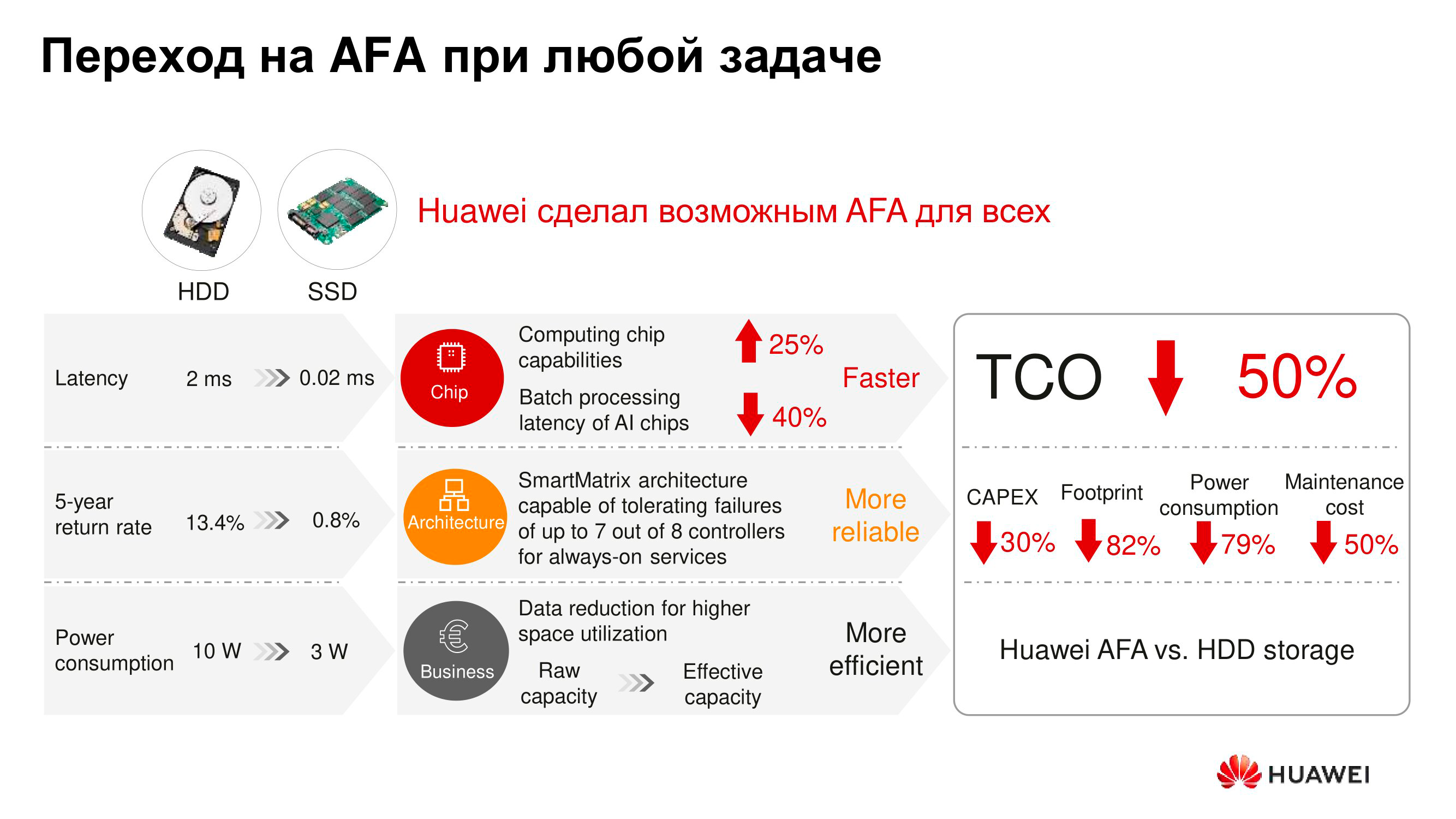
Ein weiteres traditionelles Argument für Spindelantriebe ist deren Erschwinglichkeit. Es besteht kein Zweifel, dass die Kosten für das Speichern eines Terabytes auf einer Festplatte immer noch relativ niedrig sind. Und wenn Sie nur die Kosten für die Ausrüstung berücksichtigen, ist es billiger, ein Terabyte auf einem Spindelantrieb zu halten als auf einem Solid-State-Antrieb. Im Rahmen der Finanzplanung spielt es jedoch nicht nur eine Rolle, wie viel ein bestimmtes Gerät gekauft wurde, sondern auch die Gesamtkosten für den Besitz eines Geräts über einen langen Zeitraum - von drei bis sieben Jahren.
Aus dieser Sicht ist alles ganz anders. Selbst wenn wir die Deduplizierung und Komprimierung in den Klammern weglassen, die in der Regel für Flash-Arrays verwendet werden und deren Betrieb wirtschaftlich rentabler ist, bleiben Eigenschaften wie der von Trägern belegte Rack-Platz, die Wärmeableitung und der Stromverbrauch erhalten. Und ihnen zufolge gewinnt der Flush seine Vorgänger. Infolgedessen ist die Gesamtbetriebskosten von Flash-Speichersystemen unter Berücksichtigung aller Parameter häufig fast halb so hoch wie bei Arrays auf Spindelantrieben oder mit Hybriden.
Laut ESG-Berichten können Dorado V6 All-Flash-Speichersysteme über einen Zeitraum von fünf Jahren tatsächlich eine Reduzierung der Betriebskosten um 78% erzielen - unter anderem durch effiziente Deduplizierung und Komprimierung sowie geringen Stromverbrauch und Wärmeableitung. Das deutsche Analyseunternehmen DCIG empfiehlt sie auch zur Verwendung als optimale TCO, die heute verfügbar sind.
Die Verwendung von Solid-State-Laufwerken ermöglicht es, nutzbaren Platz zu sparen, die Anzahl der Ausfälle zu verringern, die Zeit für die Wartung der Lösung zu verkürzen und den Energieverbrauch und die Wärmeableitung des Speichersystems zu reduzieren. Und es stellt sich heraus, dass AFA in wirtschaftlicher Hinsicht zumindest mit herkömmlichen Arrays auf Spindelantrieben vergleichbar ist, diese jedoch häufig übertrifft.

Royal Flush von Huawei
Unter unseren All-Flash-Speichern gehört der Spitzenplatz zum Hi-End-System OceanStor Dorado 18000 V6. Und das nicht nur bei uns: In der gesamten Branche hält es den Geschwindigkeitsrekord - bis zu 20 Millionen IPOS in der maximalen Konfiguration. Darüber hinaus ist es äußerst zuverlässig: Selbst wenn zwei Steuerungen gleichzeitig oder bis zu sieben Steuerungen nacheinander oder ein ganzer Motor gleichzeitig fliegen, bleiben die Daten erhalten. Die beträchtlichen Vorteile des "achtzehntausendsten" ergeben sich aus der darin verdrahteten KI, einschließlich der Flexibilität bei der Verwaltung interner Prozesse. Mal sehen, wie das alles erreicht wird.

Huawei hat weitgehend einen Vorsprung, da es der einzige Hersteller auf dem Markt ist, der Datenspeichersysteme selbst herstellt - vollständig und vollständig. Wir haben unsere eigene Schaltung, unseren eigenen Mikrocode, unseren eigenen Service.
Der Controller in OceanStor Dorado-Systemen basiert auf dem Kunpeng 920, einem proprietären und hergestellten Huawei-Prozessor. Er verwendet den Intelligent Baseboard Management Controller (iBMC), ebenfalls unseren. Die AI-Chips, nämlich der Ascend 310, die Fehlervorhersagen optimieren und Empfehlungen zu Einstellungen geben, sind ebenso huavean wie die E / A-Karten - das Smart I / O-Modul. Schließlich werden die Steuerungen in Halbleiterantrieben von uns entworfen und hergestellt. All dies bildete die Grundlage für eine vollständig ausgewogene und leistungsstarke Lösung.

, . 40 OceanStor Dorado 18000 V6 metro- : IOPS, - .

NVMe
Die neuesten Speichersysteme von Huawei unterstützen End-to-End-NVMe, auf die wir uns aus einem bestimmten Grund konzentrieren. Traditionell verwendete Speicherzugriffsprotokolle wurden in der frühen IT-Antike entwickelt: Sie basieren auf SCSI-Befehlen (Hallo 1980er Jahre!), Die viele Funktionen zur Gewährleistung der Abwärtskompatibilität enthalten. Unabhängig davon, welche Zugriffsmethode Sie verwenden, ist der Protokollaufwand in diesem Fall enorm. Daher weisen Speicher, die SCSI-bezogene Protokolle verwenden, eine E / A-Latenz auf, die nicht unter 0,4 bis 0,5 ms liegen darf. NVMe - Non-Volatile Memory Express - ist ein Protokoll, das für die Arbeit mit Flash-Speicher erstellt wurde und aus Gründen der berüchtigten Abwärtskompatibilität frei von Krücken ist. Außerdem verringert es die Latenz auf 0,1 ms, nicht auf Speichersystemen, sondern auf dem gesamten Stapel von Host für Laufwerke. Kein Wunder,dass NVMe auf absehbare Zeit den Entwicklungstrends für Datenspeicher entspricht. Wir setzen auch auf NVMe - und entfernen uns allmählich von SCSI. Alle heute hergestellten Huawei-Speichersysteme, einschließlich der Dorado-Reihe, unterstützen NVMe (obwohl es als End-to-End-System nur bei den fortschrittlichen Modellen der Dorado V6-Serie implementiert ist).

FlashLink: eine Handvoll Technologie
Die Eckpfeilertechnologie für die gesamte OceanStor Dorado-Linie ist FlashLink. Genauer gesagt handelt es sich um einen Begriff, der einen integralen Satz von Technologien umfasst, die dazu dienen, eine hohe Leistung und Zuverlässigkeit sicherzustellen. Dies umfasst Deduplizierungs- und Komprimierungstechnologien, die Funktionsweise des RAID 2.0+ -Datenverteilungssystems, die Trennung von "kalten" und "heißen" Daten sowie die sequenzielle Datenaufzeichnung über einen ganzen Streifen (zufällige Schreibvorgänge mit neuen und geänderten Daten werden zu einem großen Stapel zusammengefasst und nacheinander geschrieben, was die Geschwindigkeit erhöht lesen Schreiben).
FlashLink enthält unter anderem zwei wichtige Komponenten: Wear Leveling und Global Garbage Collection. Es lohnt sich, separat darauf einzugehen.
Praktisch jede SSD ist ein Miniaturspeichersystem mit einer großen Anzahl von Blöcken und einem Controller, der die Datenverfügbarkeit sicherstellt. Und dies wird unter anderem dadurch bereitgestellt, dass Daten von "getöteten" Zellen auf "nicht getötete" Zellen übertragen werden. Dies stellt sicher, dass sie gelesen werden können. Für diese Übertragung gibt es verschiedene Algorithmen. Im Allgemeinen versucht die Steuerung, den Verschleiß aller Speicherzellen auszugleichen. Dieser Ansatz hat einen Nachteil. Wenn Daten innerhalb einer SSD verschoben werden, wird die Anzahl der durchgeführten E / A-Vorgänge drastisch reduziert. Im Moment ist dies ein notwendiges Übel.
Wenn das System über viele Solid-State-Laufwerke verfügt, wird in der Grafik seiner Leistung eine "Säge" mit scharfen Höhen und Tiefen angezeigt. Das Problem besteht darin, dass ein Laufwerk aus dem Pool jederzeit mit der Datenmigration beginnen kann und die Gesamtleistung gleichzeitig von allen SSDs im Array entfernt wird. Aber die Ingenieure von Huawei haben herausgefunden, wie man die "Säge" vermeidet.
Glücklicherweise sind die Controller in den Laufwerken und der Speichercontroller sowie der Mikrocode von Huawei "nativ". Diese Prozesse in OceanStor Dorado 18000 V6 werden zentral und synchron auf allen Laufwerken des Arrays gestartet. Darüber hinaus auf Befehl des Speichercontrollers und genau dann, wenn die E / A nicht stark belastet wird.
: , -, , , : Wear Leveling, .
Außerdem sieht der Systemcontroller im Gegensatz zu den Speichersystemen konkurrierender Hersteller, was in jeder Zelle des Laufwerks passiert: Sie sind gezwungen, Solid-State-Medien von Drittanbietern zu kaufen, weshalb den Controllern solcher Speicher keine Detaillierung auf Zellebene zur Verfügung steht.
Infolgedessen weist der OceanStor Dorado 18000 V6 während des Wear Leveling einen sehr kurzen Leistungsverlust auf und wird hauptsächlich durchgeführt, wenn keine anderen Prozesse gestört werden. Dies ergibt eine hohe, konsistente Leistung auf konsistenter Basis.

Was macht den OceanStor Dorado 18000 V6 zuverlässig?
In modernen Datenspeichersystemen werden vier Zuverlässigkeitsstufen unterschieden:
- Hardware auf Laufwerksebene;
- architektonisch auf der Ebene der Ausrüstung;
- Architektur zusammen mit dem Software-Teil;
- kumulativ unter Bezugnahme auf die Entscheidung als Ganzes.
Da wir uns erinnern, dass unser Unternehmen alle Komponenten des Speichersystems selbst entwirft und herstellt, stellen wir die Zuverlässigkeit auf jeder der vier Ebenen sicher und können genau verfolgen, was auf welcher von ihnen gerade passiert.

Die Zuverlässigkeit der Laufwerke wird in erster Linie durch die zuvor beschriebene Verschleißnivellierung und globale Speicherbereinigung gewährleistet. Wenn eine SSD für das System wie eine Black Box aussieht, hat sie keine Ahnung, wie sich Zellen darin abnutzen. Beim OceanStor Dorado 18000 V6 sind die Laufwerke transparent, wodurch alle Laufwerke im Array gleichmäßig verteilt werden können. Es stellt sich daher heraus, dass dies die Lebensdauer von SSDs erheblich verlängert und ein hohes Maß an Zuverlässigkeit ihres Betriebs gewährleistet.

Zusätzliche redundante Zellen beeinträchtigen die Zuverlässigkeit des Laufwerks. Neben einer einfachen Reserve im Speichersystem werden sogenannte DIF-Zellen verwendet, die neben dem Schutz auf RAID-Array-Ebene Prüfsummen sowie zusätzliche Codes enthalten, um jeden Block vor einem einzelnen Fehler zu schützen.

Die SmartMatrix-Lösung ist der Schlüssel zur Zuverlässigkeit der Architektur. Kurz gesagt, dies sind vier Controller, die als Teil eines Motors auf einer passiven Rückwandplatine sitzen. Zwei solcher Motoren mit jeweils acht Steuerungen sind mit Antrieben an gemeinsame Regale angeschlossen. Dank SmartMatrix bleibt der Zugriff auf alle Lese- und Schreibdaten auch dann erhalten, wenn sieben von acht Controllern nicht mehr funktionieren. Und wenn Sie sechs der acht Controller verlieren, können Sie sogar mit dem Caching fortfahren.

E / A-Karten auf derselben passiven Rückwandplatine stehen allen Controllern sowohl im Front-End als auch im Back-End zur Verfügung. Bei diesem vollmaschigen Verbindungsschema bleibt der Zugriff auf die Laufwerke immer erhalten, unabhängig davon, was fehlschlägt.

Es ist am besten geeignet, über die Zuverlässigkeit der Architektur im Zusammenhang mit Fehlerszenarien zu sprechen, vor denen das Speichersystem schützen kann.
Der Speicher überlebt die Situation ohne Verlust, wenn zwei Controller "abfallen", auch gleichzeitig. Eine solche Stabilität wird durch die Tatsache erreicht, dass jeder Cache-Block sicherlich zwei weitere Kopien auf verschiedenen Controllern hat, dh insgesamt in drei Kopien vorhanden ist. Und mindestens einer hat einen anderen Motor. Selbst wenn die gesamte Engine nicht mehr funktioniert - mit allen vier Controllern - wird garantiert, dass alle Informationen im Cache-Speicher gespeichert werden, da der Cache in mindestens einem Controller der verbleibenden Engine dupliziert wird. Schließlich können Sie bei einer Daisy-Chain-Verbindung bis zu sieben Controller verlieren, und selbst wenn diese in Zweierblöcken entfernt werden, werden alle E / A und alle Daten aus dem Cache-Speicher gespeichert.

Im Vergleich zu Hi-End-Speichern anderer Hersteller zeigt sich, dass nur Huawei auch nach dem Tod von zwei Controllern oder der gesamten Engine vollen Datenschutz und volle Verfügbarkeit bietet. Die meisten Anbieter verwenden eine Schaltung mit sogenannten Controller-Paaren, an die Antriebe angeschlossen sind. Wenn in dieser Konfiguration zwei Controller ausfallen, besteht leider die Gefahr, dass der E / A-Zugriff auf das Laufwerk verloren geht.

Leider ist der Ausfall einer einzelnen Komponente nicht objektiv ausgeschlossen. In diesem Fall wird die Leistung für eine Weile verlangsamt: Es ist erforderlich, die Pfade neu zu erstellen und den Zugriff für E / A-Vorgänge in Bezug auf die Blöcke wieder aufzunehmen, die entweder zum Schreiben kamen, aber noch nicht geschrieben wurden oder zum Lesen angefordert wurden. Der OceanStor Dorado 18000 V6 hat eine durchschnittliche Wiederherstellungszeit von ungefähr einer Sekunde - deutlich weniger als sein branchenweit am nächsten liegendes Analog (4 Sekunden). Dies wird durch dieselbe passive Rückwandplatine erreicht: Wenn der Controller ausfällt, sehen die anderen sofort seine E / A und insbesondere, welcher Datenblock nicht hinzugefügt wurde; Infolgedessen nimmt der nächstgelegene Controller den Prozess auf. Daher die Möglichkeit, die Leistung in nur einer Sekunde wiederherzustellen. Es sollte hinzugefügt werden, dass das Intervall stabil ist: eine Sekunde pro Controller,Sekunde für andere usw.

In der passiven OceanStor Dorado 18000 V6-Rückwandplatine stehen alle Steuerungen allen Controllern ohne zusätzliche Adressierung zur Verfügung. Dies bedeutet, dass jeder Controller E / A an jedem Port empfangen kann. Unabhängig davon, zu welcher Front-End-Port-E / A es kommt, ist der Controller bereit, dies zu ermitteln. Daher - die Mindestanzahl interner Überweisungen und eine spürbare Vereinfachung des Ausgleichs.
Das Front-End-Balancing wird mit dem Multipathing-Treiber durchgeführt, und das Balancing wird zusätzlich im System selbst durchgeführt, da alle Controller alle E / A-Ports sehen.

Traditionell sind alle Huawei-Arrays so konzipiert, dass sie keinen einzigen Fehlerpunkt haben. Alle seine Komponenten können "heiß" ausgetauscht werden, ohne das System neu zu starten: Steuerungen, Leistungsmodule, Kühlmodule, E / A-Karten usw.

Eine Technologie wie RAID-TP verbessert auch die Zuverlässigkeit des gesamten Systems. Dies ist der Name einer RAID-Gruppe, mit der Sie sich gegen den gleichzeitigen Ausfall von bis zu drei Laufwerken absichern können. Darüber hinaus dauert eine Wiederherstellung mit 1 TB durchweg weniger als 30 Minuten. Beste aufgezeichnete Ergebnisse - achtmal schneller als bei gleicher Datenmenge auf einem Spindelantrieb. Somit ist es möglich, extrem geräumige Laufwerke zu verwenden, beispielsweise 7,68 oder sogar 15 TB, und sich keine Sorgen um die Zuverlässigkeit des Systems zu machen.
Es ist wichtig, dass der Umbau nicht im Reserverad, sondern im Reserveraum - der Reservekapazität - durchgeführt wird. Jedes Laufwerk verfügt über dedizierten Speicherplatz für die Notfallwiederherstellung. Somit wird die Wiederherstellung nicht nach dem "Viele zu Eins" -Schema durchgeführt, sondern nach dem "Viele zu Viele" -Schema, wodurch es möglich ist, den Prozess erheblich zu beschleunigen. Und solange freie Kapazität vorhanden ist, kann die Wiederherstellung fortgesetzt werden.

Unabhängig davon sollte die Zuverlässigkeit einer Lösung aus mehreren Speichern erwähnt werden - in einem Metro-Cluster oder in der Huawei-Terminologie in HyperMetro. Solche Schemata werden für die gesamte Modellpalette unserer Datenspeichersysteme unterstützt und können sowohl mit Datei- als auch mit Blockzugriff arbeiten. Darüber hinaus funktioniert der Block sowohl über Fibre Channel als auch über Ethernet (einschließlich iSCSI).
Im Wesentlichen handelt es sich um eine bidirektionale Replikation von einem Speichersystem zu einem anderen, bei der der replizierten LUN dieselbe LUN-ID wie der Haupt-LUN zugewiesen wird. Die Technologie funktioniert hauptsächlich aufgrund der Konsistenz von Caches aus zwei verschiedenen Systemen. Für den Host ist es also absolut gleich, von welcher Seite er stammt: Hier und da sieht er dieselbe logische Festplatte. Daher hindert Sie nichts daran, einen Failovercluster bereitzustellen, der sich über zwei Standorte erstreckt.
Für das Quorum wird eine physische oder virtuelle Linux-Maschine verwendet. Es kann sich am dritten Standort befinden, und die Anforderungen an seine Ressourcen sind gering. Ein häufiges Szenario besteht darin, eine virtuelle Site ausschließlich zum Hosten einer Quorum-VM zu mieten.
Die Technologie ermöglicht auch eine Erweiterung: zwei Speicher - in einem Metro-Cluster, einer zusätzlichen Plattform - mit asynchroner Replikation.

In der Vergangenheit haben viele Kunden einen "Speicherzoo" gegründet: eine Reihe von Speichersystemen verschiedener Hersteller, verschiedener Modelle, verschiedener Generationen mit unterschiedlichen Funktionen. Die Anzahl der Hosts kann jedoch beeindruckend sein und sie werden häufig virtualisiert. Unter solchen Bedingungen besteht eine der vorrangigen Aufgaben der Verwaltung darin, Hosts schnell, einheitlich und bequem logische Datenträger bereitzustellen, vorzugsweise so, dass nicht untersucht wird, wo sich diese Datenträger physisch befinden. Genau dafür ist unsere OceanStor DJ-Softwarelösung gedacht, mit der verschiedene Speichersysteme vereinheitlicht verwaltet und Dienste von ihnen bereitgestellt werden können, ohne an ein bestimmtes Speichermodell gebunden zu sein.

Gleiche und KI
Wie bereits erwähnt, verfügt der OceanStor Dorado 18000 V6 über integrierte Prozessoren mit Algorithmen für künstliche Intelligenz - Ascend. Sie werden zum einen verwendet, um Fehler vorherzusagen, und zum anderen, um Empfehlungen für die Optimierung zu bilden, was auch die Leistung und Zuverlässigkeit des Speichers erhöht.
Der Prognosehorizont beträgt zwei Monate: Die KI-Maschinerie geht davon aus, dass dies höchstwahrscheinlich in dieser Zeit geschehen wird. Es ist an der Zeit, eine Erweiterung vorzunehmen, Zugriffsrichtlinien zu ändern usw. Empfehlungen werden im Voraus gegeben, sodass Fenster für die Systemwartung im Voraus geplant werden können.
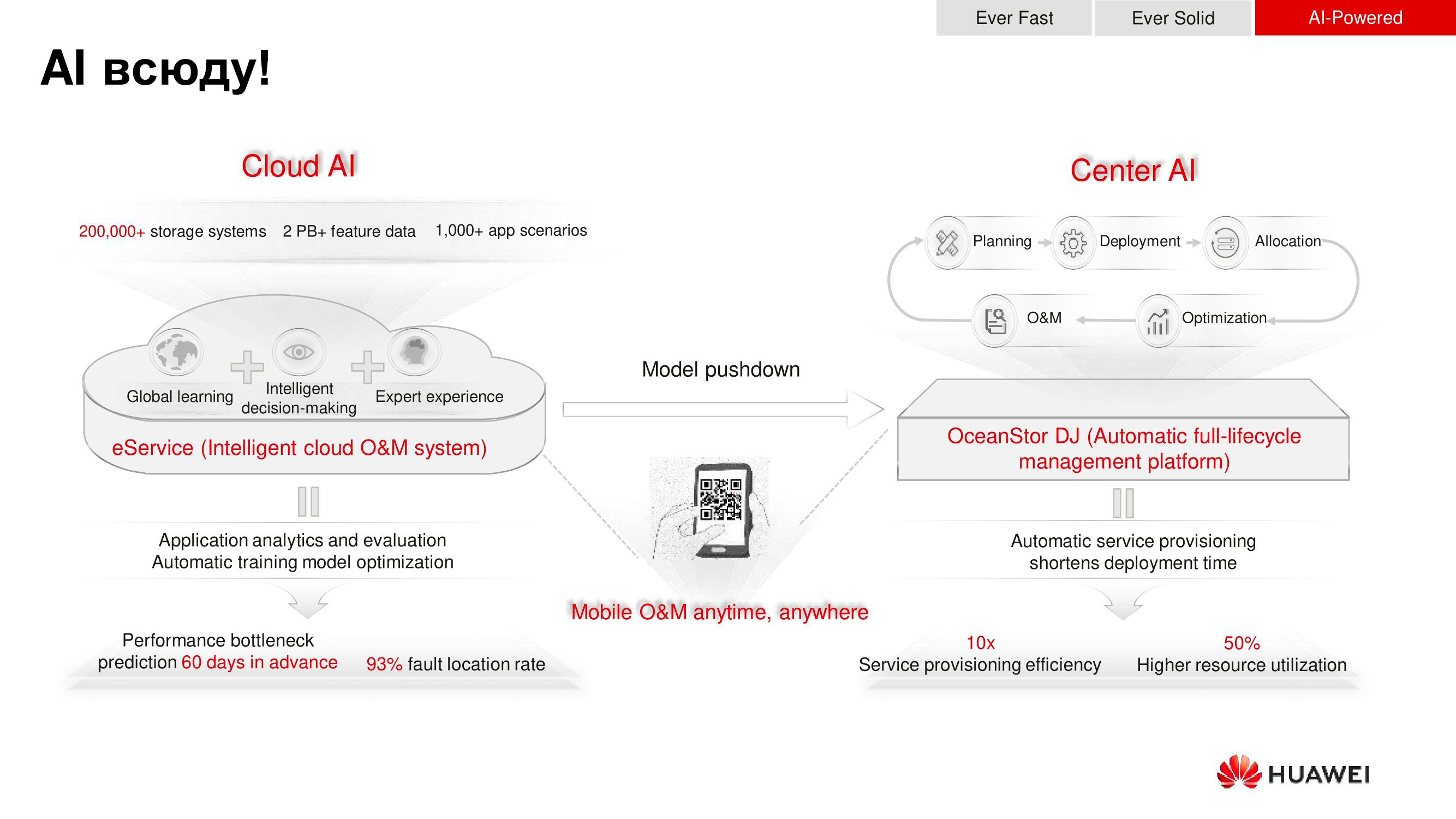
Die nächste Stufe in der Entwicklung der KI von Huawei besteht darin, sie auf die globale Ebene zu bringen. Während des Service - Failover oder Empfehlung - sammelt Huawei Informationen aus Protokollierungssystemen aus allen Repositorys unserer Kunden. Basierend auf den gesammelten Daten wird eine Analyse der aufgetretenen oder potenziellen Fehler durchgeführt und globale Empfehlungen abgegeben - nicht basierend auf der Funktionsweise eines bestimmten Speichersystems oder sogar eines Dutzend, sondern basierend auf dem, was mit Tausenden solcher Geräte geschieht und geschieht. Die Stichprobe ist riesig und basierend darauf beginnen KI-Algorithmen extrem schnell zu lernen, was Vorhersagen genauer macht.
Kompatibilität

In den Jahren 2019-2020 gab es viele Anspielungen darauf, wie unsere Hardware mit VMware-Produkten interagiert. Um sie endgültig zu stoppen, erklären wir verantwortungsbewusst: VMware ist Partner von Huawei. Alle vorstellbaren Tests wurden auf die Kompatibilität unserer Hardware mit ihrer Software durchgeführt. Daher werden auf der VMware-Website in der Hardwarekompatibilitätsliste die derzeit verfügbaren Speichersysteme unserer Produktion ohne Vorbehalte angegeben. Mit anderen Worten, mit VMware können Sie Huawei-Speicher, einschließlich Dorado V6, mit voller Unterstützung verwenden.

Gleiches gilt für unsere Zusammenarbeit mit Brocade. Wir interagieren weiterhin und führen Interoperabilitätstests für unsere Produkte durch, um sicherzustellen, dass unsere Speichersysteme mit den neuesten Brocade FC-Switches vollständig interoperabel sind.

Was weiter?
Wir entwickeln und verbessern unsere Prozessoren weiter: Sie werden schneller, zuverlässiger und ihre Leistung wächst. Wir verbessern auch KI-Chips - auf ihrer Basis werden unter anderem Module hergestellt, die die Deduplizierung und Komprimierung beschleunigen. Diejenigen, die Zugriff auf unseren Konfigurator haben, haben möglicherweise bemerkt, dass diese Karten in Dorado V6-Modellen bereits bestellt werden können.
Wir bewegen uns auch in Richtung zusätzliches Caching im Speicher der Speicherklasse - nichtflüchtiger Speicher mit besonders geringen Latenzen, etwa zehn Mikrosekunden pro Lesevorgang. SCM bietet unter anderem eine Leistungssteigerung, insbesondere bei der Arbeit mit Big Data und bei der Lösung von OLTP-Problemen. Nach dem nächsten Update sollten SCM-Karten zur Bestellung verfügbar sein.
Und natürlich wird die Dateizugriffsfunktionalität in der gesamten Huawei-Datenspeicherpalette erweitert - seien Sie gespannt auf unsere Updates.