Mit Trauer stelle ich fest, dass die Waage (DAS IST ICH!) An letzter Stelle steht ... Obwohl es nach den Daten für mich Anomalien gibt. Irgendwie verdächtig kleine Waage!
Teil 1. Analysieren und Abrufen von Anfangsdaten
Wikipedia Liste der Listen mit Listen
am Ausgang Sie benötigen eine Basis mit vollständigem Namen + Geburtsdatum + (wenn es andere Anzeichen gibt - zum Beispiel m / w, Land usw.), gibt es eine API .
Wir haben es geschafft, diese Site (Ernten / Abrufen / Extrahieren (Extrahieren) / Sammeln von Daten aus Webressourcen) mithilfe der Python Scrapy-Bibliothek zu kratzen.
Detaillierte Anweisungen erhalten
zuerst Links (Blätter mit Personen aus Wikipedia und dann Daten).
In anderen Fällen analysierten sie erfolgreich wie diese .
Ergebnis: BD-Datei wiki.zip
Teil 2. Über die Vorverarbeitung (von Stanislav Kostenkov - Kontakte unten)
Viele Menschen sind mit der Komplexität der Verarbeitung von Eingabedaten konfrontiert. Bei dieser Aufgabe war es daher notwendig, Geburtsdaten aus mehr als 42.000 Artikeln herauszuholen und, wenn möglich, das Geburtsland zu bestimmen. Dies ist einerseits eine einfache algorithmische Aufgabe, andererseits erlauben die Tools von Excel- und BI-Systemen nicht, dass sie "frontal" ausgeführt werden.
In einem solchen Moment kommen Programmiersprachen (Python, R) zur Hilfe, deren Start in den meisten BI-Systemen vorgesehen ist. Es ist erwähnenswert, dass beispielsweise in Power BI die Ausführung eines Skripts (Programms) in Python auf 30 Minuten begrenzt ist. Daher werden viele "schwere" Verarbeitungen vor dem Start von BI-Systemen durchgeführt, beispielsweise in einem Datensee.
Wie das Problem gelöst wurde
Das erste, was ich nach dem Herunterladen und Überprüfen auf falsche Werte tat, war, jeden Artikel in eine Liste von Wörtern umzuwandeln.
Bei dieser Aufgabe hatte ich Glück mit der Sprache Englisch. Diese Sprache zeichnet sich durch eine starre Form der Satzkonstruktion aus, die die Suche nach dem Geburtsdatum erheblich erleichterte. Das Schlüsselwort hier ist "geboren", dann sieht es aus und analysiert, was danach ist.
Andererseits wurden alle Artikel aus einer Hand entnommen, was auch die Aufgabe erleichterte. Alle Artikel hatten ungefähr die gleiche Struktur und Geschwindigkeit.
Außerdem waren alle Jahre 4 Zeichen lang, alle Daten waren 1–2 Zeichen lang und die Monate waren textuell. Es gab nur 3-4 mögliche Variationen in der Schreibweise des Geburtsdatums, die durch einfache Logik gelöst wurden. Es könnte auch durch reguläre Ausdrücke analysiert werden.
Der reale Code ist nicht optimiert (eine solche Aufgabe wurde nicht festgelegt, möglicherweise sind die Namen der Variablen fehlerhaft).
Wie vom Land vorhergesagt, hatte ich das Glück, eine Korrespondenztabelle von Ländern und Nationalitäten zu finden. Normalerweise beschreiben die Artikel nicht das Land, sondern das dazugehörige. Zum Beispiel Russland - russisch. Daher haben wir nach Einträgen von Nationalitäten gesucht, aber da es in einem Artikel mehr als 5 verschiedene Nationalitäten geben kann, habe ich die Hypothese aufgestellt, dass das gewünschte Wort dem Schlüsselwort "brennen" am nächsten kommt. Das Kriterium war also - der minimale Indexabstand zwischen den erforderlichen Wörtern im Artikel. Dann wurde in einer Zeile von Nationalität zu Land umbenannt.
Was wurde nicht gemacht
In den Artikeln hatten viele Wörter Müll, das heißt, ein Codefragment wurde mit dem Wort verbunden oder zwei Wörter wurden zusammengeführt. Daher wurde die Wahrscheinlichkeit, die gewünschten Werte in solchen Worten zu finden, nicht überprüft. Sie können diese Wörter mithilfe von Ähnlichkeitsalgorithmen bereinigen.
Die Entitäten, zu denen das Schlüsselwort "burn" gehört, wurden nicht analysiert. Es gab mehrere Beispiele, bei denen das Schlüsselwort mit der Geburt von Verwandten zusammenhängt. Diese Beispiele waren vernachlässigbar. Diese Beispiele lassen sich auf die Tatsache zurückführen, dass das Schlüsselwort weit vom Anfang des Artikels entfernt ist. Sie können die Perzentile für die Suche nach einem Schlüsselwort berechnen und das Beschneidungskriterium bestimmen.
Ein paar Worte zur Nützlichkeit der Vorverarbeitung beim Bereinigen von Daten
Es gibt alltägliche Fälle, in denen wir genau erraten können, was anstelle der Lücken sein sollte. Es gibt jedoch Fälle, in denen beispielsweise Auslassungen aufgrund des Geschlechts eines Geschäftskäufers vorliegen und Daten zu seinen Einkäufen vorliegen. Es gibt keine Standardtechniken zur Lösung dieses Problems in BI-Systemen. Gleichzeitig können Sie auf der Vorverarbeitungsebene ein "leichtes" Modell erstellen und verschiedene Optionen zum Ausfüllen der Lücken anzeigen. Es gibt Fülloptionen, die auf einfachen Algorithmen für maschinelles Lernen basieren. Und es lohnt sich zu benutzen. Es ist nicht schwer.
Der Quellcode (Python) ist unter dem Link
Ergebnis verfügbar : Datei out_data_fin.xls
Stanislav Kostenkov / CBS Consulting (Ischewsk, Russland) staskostenkov@gmail.com
Teil 3. Qlik Sense App
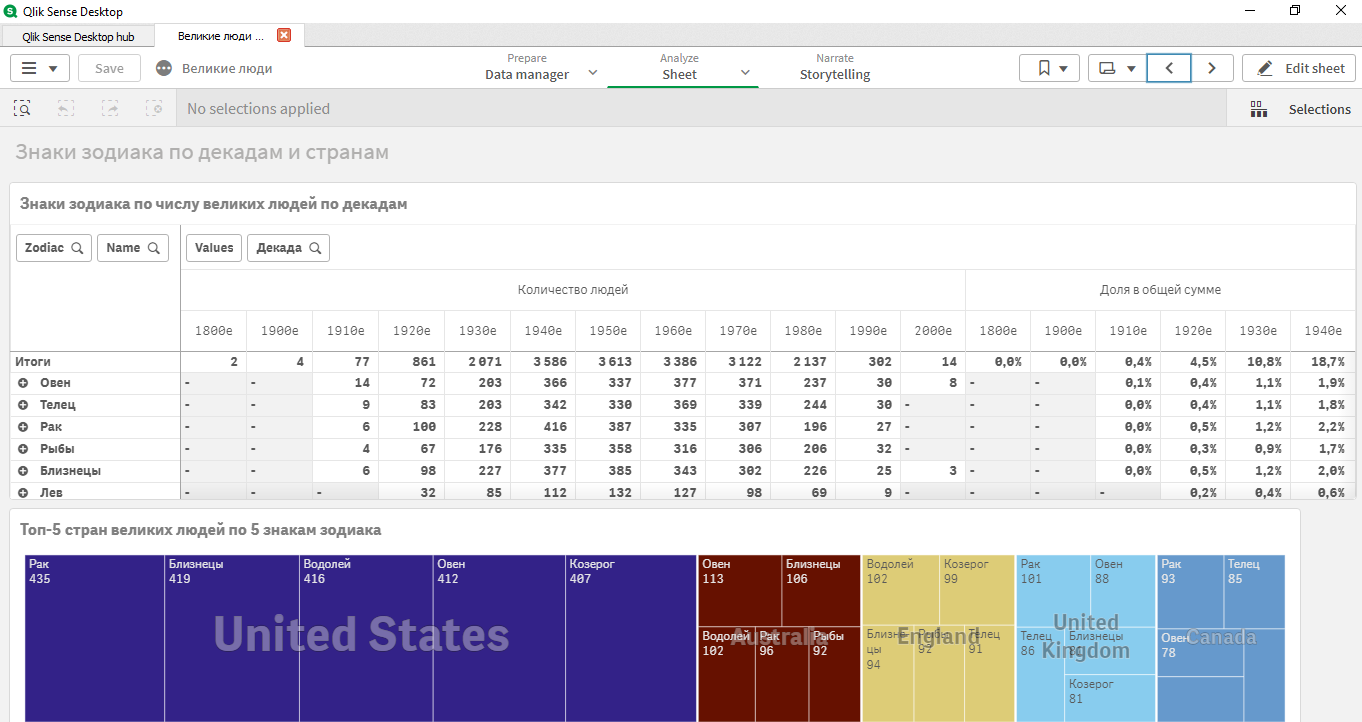
Dann wurde eine klassische Anwendung gemacht, bei der einige Anomalien mit dem Datensatz aufgedeckt wurden:
- es machte Sinn, nur Jahrzehnte von 1920 bis 1980 zu wählen;
- In verschiedenen Ländern gab es unterschiedliche Führer in Bezug auf Horoskopzeichen.
- Top Zeichen: Krebs, Widder, Zwillinge, Stier, Steinbock.
Alle Daten (Datensatz, Rohdaten, die von der Qlik Sense-App zur Datenanalyse empfangen wurden) werden als Referenz lokalisiert .