Siehe vorherige Artikel: Einfacher Bewegungserkennungsalgorithmus und ein Algorithmus zum Ermitteln der Verschiebung von Objekten im Bild . Ich möchte Sie daran erinnern, dass ich motiviert war, diese Artikel zu schreiben, weil ich zu Beginn meiner Masterarbeit über "Analyse der räumlichen Struktur dynamischer Bilder" auf das Problem stieß, dass es sehr schwierig ist, einige vorgefertigte Beispiele für Algorithmen zur Erkennung von Bildern und sich bewegenden Objekten zu finden. Überall, sowohl in der Literatur als auch im Internet, gibt es nur eine nackte Theorie. Seitdem ist eine lange Zeit vergangen. Ich habe es geschafft, meine Diplomarbeit erfolgreich zu verteidigen und ein rotes Diplom zu erhalten. Jetzt schreibe ich, um meine Erfahrungen zu teilen.
Als ich anfing, an meinen Dissertationen zu arbeiten, war mein Wissen auf dem Gebiet der Computer Vision gleich Null. Wo habe ich angefangen? Aus den einfachsten Experimenten an Bildern, die in den obigen Artikeln beschrieben sind. Ich schrieb ein paar primitive Algorithmen, von denen einer mir in Form von Stellen zeigte, an denen sich bewegte Objekte befinden, und der zweite fand ein Stück des Bildes in einem größeren Bild (es funktionierte natürlich langsam).
Was kommt als nächstes? Weiteres Einstecken. Meine Aufgabe war es, dass das unbemannte Luftfahrzeug durch Luftaufnahmen navigierte oder ein Auto verfolgte, das sich entlang der Straße bewegte. Und ich hatte keine Ahnung, wie ich die Aufgabe starten sollte. Was habe ich angefangen zu tun? Theorie lesen. Und die Theorie besagt, dass Computer Vision in die folgenden Phasen unterteilt ist:
- Bildvorverarbeitung (Rauschunterdrückung, Kontrastverbesserung, Skalierung usw.).
- Details finden (Linien, Ränder, Sonderziele)
- Erkennung, Segmentierung.
- Verarbeitung auf hohem Niveau.
Okay, ich habe ein Diagramm des Programms gezeichnet, das all dies tun sollte:
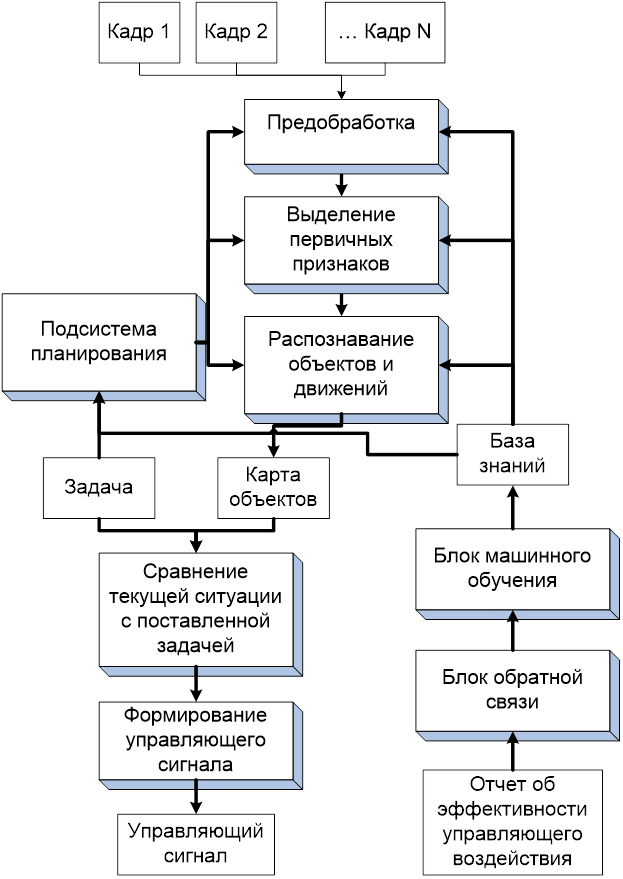
Kurz gesagt, es stellte sich heraus, dass ich auf der Ebene der künstlichen Intelligenz etwas Grandioses schaffen musste. Na gut, ich werde versuchen es zu schaffen. Ich nehme Visual Studio und beginne mit dem Bildhauerkurs in C #. Genauer gesagt, Klassenrohlinge. Wenig später wurde mir klar, was ich anstrebte…
Also beginne ich den ersten Schritt zu üben. Vorverarbeitung. Ich habe mit ihr angefangen, weil
- Das ist das einfachste.
- Dies ist der erste Schritt auf der Liste.
Ich fing an, verschiedene Filter auf das Bild anzuwenden, um zu sehen, was passiert ist. Ich habe zum Beispiel versucht, den Sobel-Filter anzuwenden:

Entfernen Sie das Bildrauschen mit Gaußscher Unschärfe: Ich habe

die Medianfilterung und Kantenauswahl studiert:

Die Vorlesung über Computer Vision aus dem Hörsaal hat mir sehr geholfen .
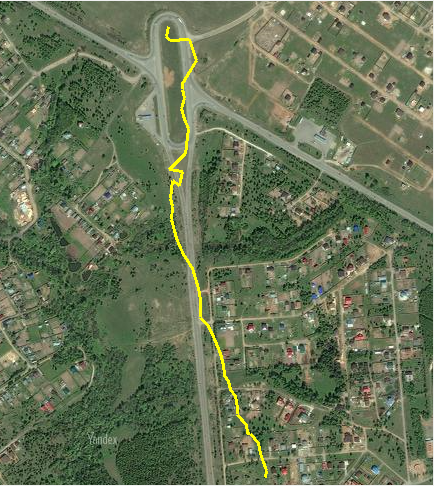
Das Wissen ist also viel größer geworden, aber es ist immer noch nicht klar, wie das Problem gelöst werden soll. Zu diesem Zeitpunkt waren das Thema und die Aufgabe der Masterarbeit mehrmals überarbeitet worden und wurden daher wie folgt formuliert: "Verfolgung der Flugbahn eines UAV mithilfe von Luftbildrahmen." Das heißt, ich musste eine Reihe von Fotos machen und eine Flugbahn entlang dieser erstellen.
Ich hatte die Idee, die Kontur in Form von unterbrochenen Linien (beschrieben durch viele Segmente) zu beschreiben und dann zu vergleichen, wie weit sich diese Linien verschoben haben. Es stellte sich jedoch heraus, dass die Konturen selbst in zwei benachbarten Rahmen so unterschiedlich waren, dass es nicht möglich war, die Sätze der resultierenden unterbrochenen Linien angemessen zu vergleichen. Ich habe versucht, die Konturen selbst mit verschiedenen Methoden und deren Kombinationen zu verbessern:
- Klassische Canny-Kantenauswahl aus der OpenCV-Bibliothek
- Verbesserter Kantenerkennungsalgorithmus, der von meinem Vorgesetzten entwickelt wurde.
- Auswahl der Konturen durch Binarisierung.
- Auswahl der Konturen durch Segmentierung. Die Segmentierung wurde auf verschiedene Weise durchgeführt, insbesondere unter Verwendung von Texturmerkmalen.
Als Ergebnis haben wir ein Durcheinander von Algorithmen erhalten, die sehr langsam arbeiteten, aber dem Ergebnis kein Jota näher kamen. Einige meiner Arbeiten wurden als Materialien für diesen Artikel verwendet .
Nun, dann schlug der Vorgesetzte eine Idee vor: Es ist notwendig, spezielle Punkte zu verwenden. Und er gab sogar einen Algorithmus zur Berechnung dieser Schlüsselpunkte. Ich muss sagen, dass dies eine sehr ungewöhnliche Methode war. Dies ist kein Harris-Detektor oder BRISK oder MSER oder AKAZE. Obwohl ich versucht habe, sie auch zu benutzen. Wie sich herausstellte, funktionierte der vom Vorgesetzten vorgeschlagene Detektor jedoch besser. Und so funktioniert es. Zunächst berechnen wir die Konturvorbereitung nach folgender Formel:
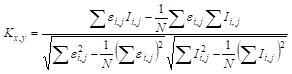

Dann finden wir die Extreme dieser Funktion. Dies sind die besonderen Punkte. Bezeichnenderweise kann es zwei Arten von Punkten geben: "Peaks" und "Pits". Hier ist ein Beispiel für diese Punkte im Bild:
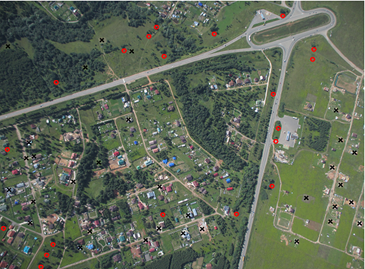
Als nächstes werden 50 Punkte mit der maximalen Antwort aus den erhaltenen Punkten ausgewählt. Für alle diese Punkte werden Dreiecke gebildet. Die Anzahl der durch diese Punkte gebildeten Dreiecke beträgt:

Dabei ist k die Anzahl der an der Berechnung beteiligten singulären Punkte. Für jedes Dreieck wird ein spezieller Index von 0 bis 16383 berechnet. Der nächste Schritt besteht darin, die Dreiecke über ein spezielles Array zu verteilen, in dem die Zellennummer dem Dreiecksindex entspricht. Jede Zelle in einem solchen Array ist eine Liste von Dreiecken. Ein solches Array wird aus zwei verglichenen Frames zusammengestellt. Die Vergleiche werden durchgeführt, indem jede Zelle im Array mit der entsprechenden Zelle im Array eines anderen Rahmens abgeglichen wird. Insgesamt müssen 16384 Gruppen abgeglichen werden, was für einen Computer in relativ kurzer Zeit durchaus machbar ist.
Beim Matching von Arrays füllen wir die Matching-Matrix aus. Die Matrix ist horizontal die Winkel zwischen den übereinstimmenden Dreiecken, und die vertikale Skala ist die Skala, die als Verhältnis der Längen der längsten Seiten berechnet wird. Die gefundene Skala und der gefundene Winkel sind die Zellen der Matrix, die die meisten Übereinstimmungen aufweisen. Ein ähnlicher Vergleich wird durchgeführt, um die horizontale und vertikale Verschiebung von Bildern zu berechnen.
Weitere Informationen zu dieser Methode finden Sie im Artikel.
So fanden wir die horizontale und vertikale Verschiebung, den Winkel und die Skalenänderung (dh das UAV ging nach oben oder unten). Jetzt bleibt ein Programm zu schreiben, das die Verfolgung einer Trajektorie über eine Reihe von Frames simuliert und genau diese Trajektorie zeichnet, und wir können sagen, dass die Dissertation fertig ist: