
Ein dorniger und schwieriger Weg einer Person, die mit dem FSIS USRN Rosreestr kollidierte. Er wartet auf endloses Warten auf das Laden des Browsers, Schlüssel, Captchas und Intervalle zwischen Anfragen von 5 Minuten. Warum sollte er so viel leiden? Er hatte bereits sein eigenes Geld beigesteuert, als er sich entschied, mit diesem System zu arbeiten und seine Auszüge zu bestellen. Aber nein - einen Auszug aus der USRN zu bekommen ist wie Zwiebeln auszuziehen. Der letzte Schritt, der auf den Betroffenen wartet - der heruntergeladene, begehrte Auszug wird durch ein Zip-Archiv dargestellt, in dem sich ein weiteres Archiv und eine Sig-Datei befinden. Und schon drin ist die Anweisungsdatei selbst. Aber es ist auch nicht einfach zu lesen - es ist in XML. Und damit alles zusammenwächst, muss diese XML zusammen mit sig auf eine spezielle Seite von Rosreestr heruntergeladen werden. Und dort wartet noch ein Captcha. Und so bei jeder Aussage! Wir werden diesen letzten Schmerz heute mit Python überwinden.
Aufgabe:
- entpacke alle zip im Ordner,
- Download nach Spezifikation. Link zu Rosreestr,
- endlich herunterladen!, eine für Menschen lesbare Ansicht der Aussage.
Zunächst werden also im Ordner Zip-Archive mit Auszügen heruntergeladen:
Nach dem Importieren von Python-Modulen:
import os
import zipfile
import webbrowser,time
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
Packen wir alle Zip-Archive aus und löschen sie, damit sie nicht mit dem Inhalt verwechselt werden:
zipFiles = []
sigFiles = []
for filename in os.listdir('.'):
if filename.endswith('.zip'):
zipfile.ZipFile(filename, 'r').extractall()
os.remove(filename)
Wir haben Zip-Archive und Sig-Dateien für diese, die dann auf die Rosreestr-Website hochgeladen werden:
Gehen Sie zum Hauptprogrammzyklus für alle Dateien im Verzeichnis (in meinem Fall "C: / 2"):
for filename in zipFiles:
act = browser.find_element_by_id('sig_file')
act.send_keys('C:\\2\\'+str(filename)+'.sig')
act = browser.find_element_by_id('xml_file')
# zip
zip_ref = zipfile.ZipFile(filename, 'r').extractall()
# xml
for f in os.listdir('.'):
if f.endswith('.xml'):
print(f)
# xml
act.send_keys('C:\\2\\'+str(f))
act = browser.find_element_by_css_selector('input.brdg1111')
act.click()
i = str(input(" : "))
for b in i:
act.send_keys(b)
time.sleep (0.1)
#act.submit()
act = browser.find_element_by_css_selector('.terminal-button-bright')
act.click()
time.sleep (5)
try:
act = browser.find_element_by_link_text(' ')
act.click()
Nach dem erfolgreichen Laden der Rosreestr-Portalseite rosreestr.gov.ru/wps/portal/cc_vizualisation findet das Programm das Zip-Archiv im Verzeichnis, ruft die XML-Anweisungsdatei von dort ab und fügt sie in das erforderliche Feld auf der Website ein. Das Programm macht dasselbe mit der an die XML angehängten Sig-Datei:
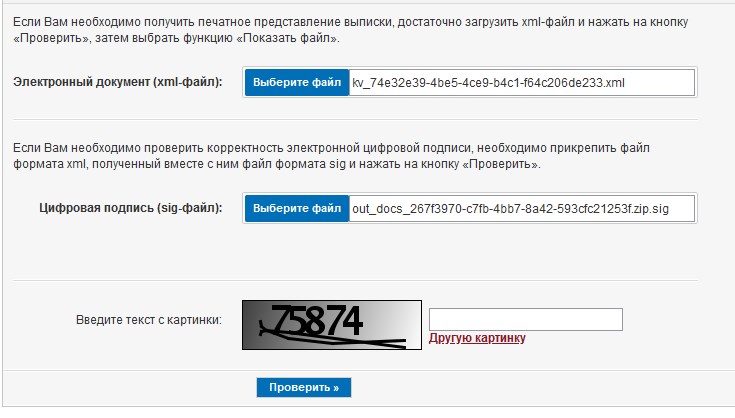
Als nächstes wartet das Programm auf
die Eingabe des Captchas : Nachdem der Benutzer das Captcha eingegeben hat , sendet es es an die Site und klickt auf den Download-Link für den bereits "normalen" Auszug aus der USRN:
Ein Fenster wird geöffnet, in dem das fertige Fenster geöffnet wird Extrakt, der in HTML oder durch Drücken von STRG + P in Chrome gespeichert werden kann - im PDF-Format.
Es bleibt das automatische Lösen von Captcha und das automatische Herunterladen von lesbaren Auszügen. Aber das ist hier das Einfachste, nicht wahr?
Der Programmcode ist hier .