Nach allgemeiner Meinung sollte das Extrahieren von Text aus PDFs nicht so schwierig sein. Schließlich ist hier der Text direkt vor unseren Augen, und die Menschen nehmen den Inhalt von PDF ständig und mit großem Erfolg wahr. Woher kommt die Schwierigkeit bei der automatischen Textextraktion?
Es stellt sich heraus, dass das Arbeiten mit den Namen von Personen für Algorithmen aufgrund vieler Randfälle und falscher Annahmen schwierig ist, das Arbeiten mit PDF aufgrund der extremen Flexibilität des PDF-Formats schwierig ist.
Das Hauptproblem besteht darin, dass PDF nicht als Format für die Dateneingabe gedacht war - es wurde als Ausgabekanal entwickelt, um das Erscheinungsbild des endgültigen Dokuments zu optimieren.
Grundsätzlich besteht das PDF-Format aus einer Reihe von Anweisungen, die beschreiben, wie ein Bild auf einer Seite erstellt wird. Insbesondere werden Textdaten nicht als Absätze - oder sogar Wörter - gespeichert, sondern als Zeichen, die an bestimmten Stellen auf der Seite gezeichnet werden. Infolgedessen geht beim Konvertieren von Text oder Word-Dokumenten in PDF der größte Teil der Semantik des Inhalts verloren. Die gesamte interne Struktur des Textes verwandelt sich in eine amorphe Suppe von Zeichen, die auf der Seite schweben.
Durch das Ausfüllen von FilingDB haben wir Textdaten aus Zehntausenden von PDF-Dokumenten extrahiert. Dabei haben wir beobachtet, wie sich alle unsere Annahmen über die Struktur von PDF-Dateien als falsch herausstellten. Unsere Mission war besonders schwierig, da wir PDF-Dokumente aus verschiedenen Quellen mit völlig unterschiedlichen Stilen, Schriftarten und Erscheinungsbildern verarbeiten mussten.
Im Folgenden wird beschrieben, welche Funktionen von PDF-Dateien es schwierig oder sogar unmöglich machen, Text daraus zu extrahieren.
PDF-Leseschutz
Möglicherweise sind Sie auf PDF-Dateien gestoßen, die das Kopieren von Textinhalten untersagen. Dies ist beispielsweise das, was das SumatraPDF-Programm erzeugt, wenn versucht wird, Text aus einem kopiergeschützten Dokument zu kopieren:

Interessanterweise ist der Text sichtbar, aber der Betrachter weigert sich, den ausgewählten Text in die Zwischenablage zu übertragen.
Dies wird mit mehreren "Zugriffsberechtigungs" -Flaggen erreicht, von denen eines die Kopierberechtigung steuert. Es ist wichtig zu verstehen, dass die PDF-Datei selbst dies nicht erzwingt - ihr Inhalt ändert sich nicht davon, und die Aufgabe ihrer Implementierung liegt vollständig beim Betrachter.
Dies schützt natürlich nicht vor dem Extrahieren von Text aus PDF, da jede ausreichend erweiterte Bibliothek für die Arbeit mit PDF es dem Benutzer ermöglicht, diese Flags entweder zu ändern oder zu ignorieren.
Zeichen außerhalb von Seiten
Oft enthält ein PDF mehr Textdaten als auf der Seite angezeigt. Nehmen Sie diese Seite aus dem Nestle-Geschäftsbericht 2010.
Dieser Seite ist mehr Text beigefügt, als sichtbar ist. Im zugehörigen Inhalt ist insbesondere Folgendes zu finden:
KitKat feierte 2010 seinen 75. Geburtstag, bleibt aber mit über 2,5 Millionen Facebook-Fans jung und trendy. Die Produkte werden in über 70 Ländern verkauft, und in Industrieländern und Schwellenländern wie dem Nahen Osten, Indien und Russland wächst der Umsatz gut. Japan ist der zweitgrößte Markt des Unternehmens.
Dieser Text ist nicht auf der Seite, sodass die meisten PDF-Viewer ihn nicht anzeigen. Die Daten sind jedoch vorhanden und können programmgesteuert abgerufen werden.
Dies geschieht manchmal aufgrund von Entscheidungen in letzter Minute, Text während des Genehmigungsprozesses zu ersetzen oder zu entfernen.
Kleine oder unsichtbare Zeichen
Manchmal finden sich auf der PDF-Seite sehr kleine oder sogar unsichtbare Zeichen. Hier ist zum Beispiel eine Seite aus dem Nestle-Bericht 2012.

Die Seite hat einen kleinen weißen Text auf einem weißen Hintergrund, der sagt:
Wyeth Nutrition-Logo Identitätsrichtlinien für Märkte
Vevey Octobre 2012 RCC / CI & D.
Dies geschieht manchmal, um die Barrierefreiheit zu verbessern, und zwar zum gleichen Zweck wie das Alt-Tag in HTML.
Zu viele Leerzeichen
Manchmal werden zusätzliche Leerzeichen zwischen Buchstaben von Wörtern in PDF eingefügt. Dies geschieht wahrscheinlich zu Kerning-Zwecken (Ändern des Abstands zwischen Zeichen).
Zum Beispiel enthält der Hikma Pharma-Bericht 2013 den folgenden Text:

Wenn Sie ihn kopieren, erhalten wir:
ch a i r m a n ' s s tat em en tIm Allgemeinen ist es schwierig, das Problem der Rekonstruktion des Originaltextes zu lösen. Unser erfolgreichster Ansatz ist die optische Zeichenerkennung OCR.
Nicht genug Platz
Manchmal fehlen in der PDF-Datei Leerzeichen oder sie wurden durch ein anderes Zeichen ersetzt.
Beispiel 1: Der folgende Auszug stammt aus dem SEB-Geschäftsbericht 2017.

Extrahierter Text:
TenyearsafterthefinancialcrisisstartedBeispiel 2: Der Eurobank 2013-Bericht enthält Folgendes:

Extrahierter Text:
On_April_7,_2013,_the_competent_authoritiesAuch hier ist OCR die beste Wahl für diese Seiten.
Eingebaute Schriftarten
PDF arbeitet auf komplexe Weise mit Schriftarten, um es milde auszudrücken. Um zu verstehen, wie Textdaten in PDF gespeichert werden, müssen zunächst Glyphen, Glyphennamen und Schriftarten verstanden werden.
- Eine Glyphe ist eine Reihe von Anweisungen, die beschreiben, wie ein Zeichen oder ein Buchstabe gezeichnet wird.
- – , . , « » ™ «» «».
- – . , , , «», .
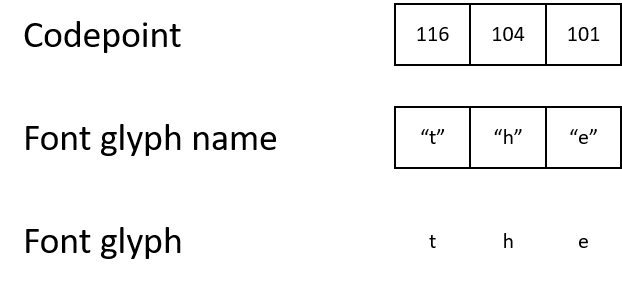
In PDF werden Zeichen als Zahlen, Zeichencodes [Codepunkte] gespeichert. Um zu verstehen, was auf dem Bildschirm angezeigt werden muss, muss der Renderer der Kette vom Zeichencode bis zum Namen des Glyphen und dann bis zum Glyphen selbst folgen.
Beispielsweise kann eine PDF-Datei einen Zeichencode 116 enthalten, der dem Namen des Glyphen "t" zugeordnet ist, der wiederum einem Glyphen zugeordnet ist, der beschreibt, wie das Zeichen "t" angezeigt wird.
Die meisten PDFs verwenden die Standard-Zeichenkodierung. Die Zeichenkodierung besteht aus einer Reihe von Regeln, die den Zeichencodes selbst eine Bedeutung zuweisen. Z.B:
- ASCII und Unicode verwenden den Zeichencode 116, um den Buchstaben "t" darzustellen.
- Unicode ordnet den Zeichencode 9786 dem Glyphen "weißer Smiley" zu, der als ☺ angezeigt wird, aber ASCII definiert einen solchen Code nicht.
Ein PDF-Dokument verwendet jedoch manchmal eine eigene Zeichenkodierung und spezielle Schriftarten. Es mag seltsam klingen, aber das Dokument kann den Buchstaben "t" mit Zeichencode 1 bezeichnen. Es ordnet den Zeichencode 1 dem Glyphennamen "c1" zu, der einer Glyphe zugeordnet wird, die beschreibt, wie der Buchstabe "t" angezeigt wird.
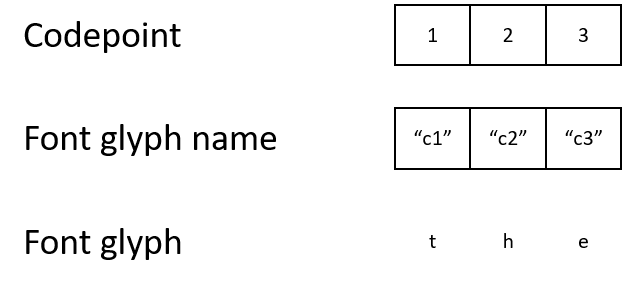
Während sich das Endergebnis nicht von einem Menschen unterscheidet, wird die Maschine durch diese Zeichencodes verwirrt. Wenn die Zeichencodes nicht mit der Standardcodierung übereinstimmen, ist es fast unmöglich, programmgesteuert zu verstehen, was die Codes 1, 2 oder 3 bedeuten.
Warum sollte eine PDF-Datei nicht standardmäßige Schriftarten und Codierungen enthalten?
- Ein Grund ist, das Extrahieren von Text zu erschweren.
- – . , PDF . PDF , .
Eine Möglichkeit, dies zu umgehen, besteht darin, Schriftzeichen aus dem Dokument zu extrahieren, sie über OCR auszuführen und die Schrift Unicode zuzuordnen. Auf diese Weise können Sie die schriftartenbezogene Codierung beispielsweise in Unicode übersetzen: Der Zeichencode 1 entspricht dem Namen "c1", der laut Glyphe "t" darstellen sollte, was dem Unicode-Code 116 entspricht.
Die Codierungszuordnung haben Sie gerade done - diejenige, die den Nummern 1 und 116 entspricht - wird im PDF-Standard als ToUnicode-Karte bezeichnet. PDF-Dokumente können eigene ToUnicode-Karten enthalten, dies ist jedoch nicht erforderlich.
Erkennung von Wörtern und Absätzen
Die Rekonstruktion von Absätzen und sogar Wörtern aus der amorphen symbolischen Suppe von PDFs ist eine entmutigende Aufgabe.
Ein PDF-Dokument enthält eine Liste von Zeichen auf einer Seite, und es ist Sache des Verbrauchers, Wörter und Absätze zu erkennen. Menschen sind dabei natürlich effektiv, weil Lesen eine häufige Fähigkeit ist.
Der am häufigsten verwendete Gruppierungsalgorithmus besteht darin, die Größe, Position und Ausrichtung von Zeichen zu vergleichen, um zu bestimmen, was ein Wort oder ein Absatz ist.
Die einfachsten Implementierungen solcher Algorithmen können leicht eine O (n²) -Komplexität erreichen, was lange dauern kann, um dicht gepackte Seiten zu verarbeiten.
Reihenfolge von Text und Absätzen
Das Erkennen der Text- und Absatzreihenfolge ist aus zwei Gründen eine Herausforderung.
Erstens gibt es manchmal einfach keine richtige Antwort. Während Dokumente mit einem regulären typografischen Satz mit einer Spalte eine natürliche Lesereihenfolge aufweisen, sind Dokumente mit einer kühneren Anordnung der Elemente schwieriger zu bestimmen. Zum Beispiel ist nicht ganz klar, ob die nächste Einfügung vor, nach oder in der Mitte des Artikels erfolgen soll, neben dem sie sich befindet:

Zweitens kann es für Computer sehr schwierig sein, die genaue Reihenfolge der Absätze zu bestimmen, selbst wenn die Antwort für eine Person klar ist - selbst unter Verwendung von KI. Sie mögen diese Aussage etwas gewagt finden, aber in einigen Fällen kann die richtige Reihenfolge der Absätze nur durch das Verständnis des Textinhalts bestimmt werden.
Betrachten Sie diese Anordnung der Komponenten in zwei Spalten, die die Zubereitung eines Gemüsesalats beschreibt.

In der westlichen Welt ist anzunehmen, dass das Lesen von links nach rechts und von oben nach unten erfolgt. Ohne den Inhalt des Textes zu studieren, können wir daher alle Optionen auf zwei reduzieren: ABCD und ACB D.
Nachdem wir den Inhalt untersucht, verstanden haben, was darin steht, und wissen, dass Gemüse vor dem Schneiden gewaschen wird, können wir verstehen, dass die richtige Reihenfolge ACB D ist. Es ist äußerst schwierig, dies algorithmisch zu bestimmen.
Gleichzeitig funktioniert "in den meisten Fällen" ein Ansatz, der sich auf die Reihenfolge stützt, in der der Text im PDF-Dokument gespeichert ist. Es folgt normalerweise der Reihenfolge, in der der Text zum Zeitpunkt der Erstellung eingefügt wird. Wenn große Textblöcke viele Absätze enthalten, folgen sie normalerweise der vom Autor beabsichtigten Reihenfolge.
Eingebettete Bilder
Oft ist ein Teil des Inhalts des Dokuments (oder des gesamten Dokuments) das gescannte Bild. In solchen Fällen sind keine Textdaten enthalten, und Sie müssen auf OCR zurückgreifen.
Beispielsweise ist der Yell-Geschäftsbericht 2011 nur als Scan verfügbar:

Warum nicht einfach alles erkennen?
OCR kann zwar bei einigen der beschriebenen Probleme helfen, hat aber auch seine Nachteile.
- Lange Bearbeitungszeit. Das Ausführen von OCR bei einem Scan aus PDF dauert normalerweise eine Größenordnung länger (oder sogar länger) als das Extrahieren von Text direkt aus PDF.
- Schwierigkeiten mit nicht standardmäßigen Zeichen und Glyphen. Für OCR-Algorithmen ist es schwierig, mit neuen Zeichen zu arbeiten - Emoticons, Sternchen, Kreise, Quadrate (in Listen), hochgestellte Zeichen, komplexe mathematische Symbole usw.
- . , PDF-, , . .
Bisher haben wir nicht erwähnt, wie schwierig es ist, zu bestätigen, dass der Text korrekt oder wie erwartet extrahiert wurde. Wir haben festgestellt, dass es am besten ist, eine umfangreiche Reihe von Tests durchzuführen, die sowohl grundlegende Metriken (Textlänge, Seitenlänge, Verhältnis von Wörtern zu Leerzeichen) als auch komplexere (Prozentsatz der englischen Wörter, Prozentsatz der nicht erkannten Wörter, Prozentsatz der Zahlen) sowie den Monitor untersuchen Warnungen wie verdächtige oder unerwartete Zeichen.
Was können wir zum Extrahieren von Text aus PDF empfehlen? Stellen Sie zunächst sicher, dass der Text keine bequemere Quelle hat.
Wenn die Daten, an denen Sie interessiert sind, nur im PDF-Format vorliegen, ist es wichtig zu verstehen, dass dieses Problem nur auf den ersten Blick einfach erscheint und möglicherweise nicht mit 100% iger Genauigkeit gelöst werden kann.