Aufgabe
Gegeben: Ein auf OpenWRT basierendes Projekt (und es basiert auf BuildRoot) mit einem zusätzlichen Repository, das als Feed verbunden ist. Aufgabe: Führen Sie ein zusätzliches Repository mit dem Haupt-Repository zusammen.
Hintergrund
Wir stellen Router her und wollten Kunden eines Tages die Möglichkeit geben, ihre Anwendungen in die Firmware aufzunehmen. Um nicht unter der Zuweisung des SDK, der Toolchain und den damit verbundenen Schwierigkeiten zu leiden, haben wir beschlossen, das gesamte Projekt auf Github in ein privates Repository zu stellen. Repository-Struktur:
/target //
/toolchain // gcc, musl
/feeds //
/package //
...
Es wurde beschlossen, einige der Anwendungen unserer eigenen Entwicklung vom Haupt-Repository in das zusätzliche zu übertragen, damit niemand ausspionierte. Wir haben alles gemacht, es auf Github gelegt und es wurde gut.
Seitdem ist viel Wasser unter die Brücke geflossen…
Der Client ist schon lange nicht mehr vorhanden, das Repository wurde aus Github entfernt, und die Idee, Clients Zugriff auf das Repository zu gewähren, ist schlecht. Es blieben jedoch zwei Repositories im Projekt. Und alle Skripte / Anwendungen, die auf die eine oder andere Weise mit git zusammenhängen, müssen kompliziert werden, um mit einer solchen Struktur zu arbeiten. Einfach gesagt, es ist technische Schuld. Um beispielsweise die Reproduzierbarkeit von Releases sicherzustellen, müssen Sie eine Datei, Secondary.version, mit einem Hash aus dem zweiten Repository an das primäre Repository übergeben. Natürlich macht das Skript das und es ist nicht sehr schwierig für es. Aber es gibt ein Dutzend solcher Skripte, und sie sind alle komplizierter, als sie sein könnten. Im Allgemeinen habe ich mich freiwillig entschieden, das sekundäre Repository wieder in das primäre Repository zu integrieren. Gleichzeitig wurde die Hauptbedingung festgelegt - die Reproduzierbarkeit von Releases zu erhalten.
Sobald eine solche Bedingung festgelegt ist, funktionieren triviale Zusammenführungsmethoden, z. B. das separate Festschreiben aller Elemente von der Sekundärseite und das Zusammenführen von zwei unabhängigen Bäumen von oben, nicht. Sie müssen die Haube öffnen und sich die Hände schmutzig machen.
Git Datenstruktur
Wie sieht ein Git-Repository aus? Dies ist eine Datenbank mit Objekten. Es gibt drei Arten von Objekten: Blobs, Bäume und Commits. Alle Objekte werden durch den sha1-Hash ihres Inhalts angesprochen. Ein Blob ist dummerweise Daten ohne zusätzliche Attribute. Ein Baum ist eine sortierte Liste von Links zu Bäumen und Blobs der Form "<right> <type> <hash> <name>" (wobei <type> entweder Blob oder Baum ist). Ein Baum ist also wie ein Verzeichnis im Dateisystem, und ein Blob ist wie eine Datei. Ein Commit enthält den Namen des Autors und des Committers, das Erstellungs- und Hinzufügungsdatum, einen Kommentar, einen Hash des Baums und eine beliebige Anzahl (normalerweise ein oder zwei) von Links zu übergeordneten Commits. Diese Links zu übergeordneten Commits verwandeln die Objektbasis in einen azyklischen Digraphen (unter Ausländern als DAG bekannt).Lesen Sie im Detailhier :
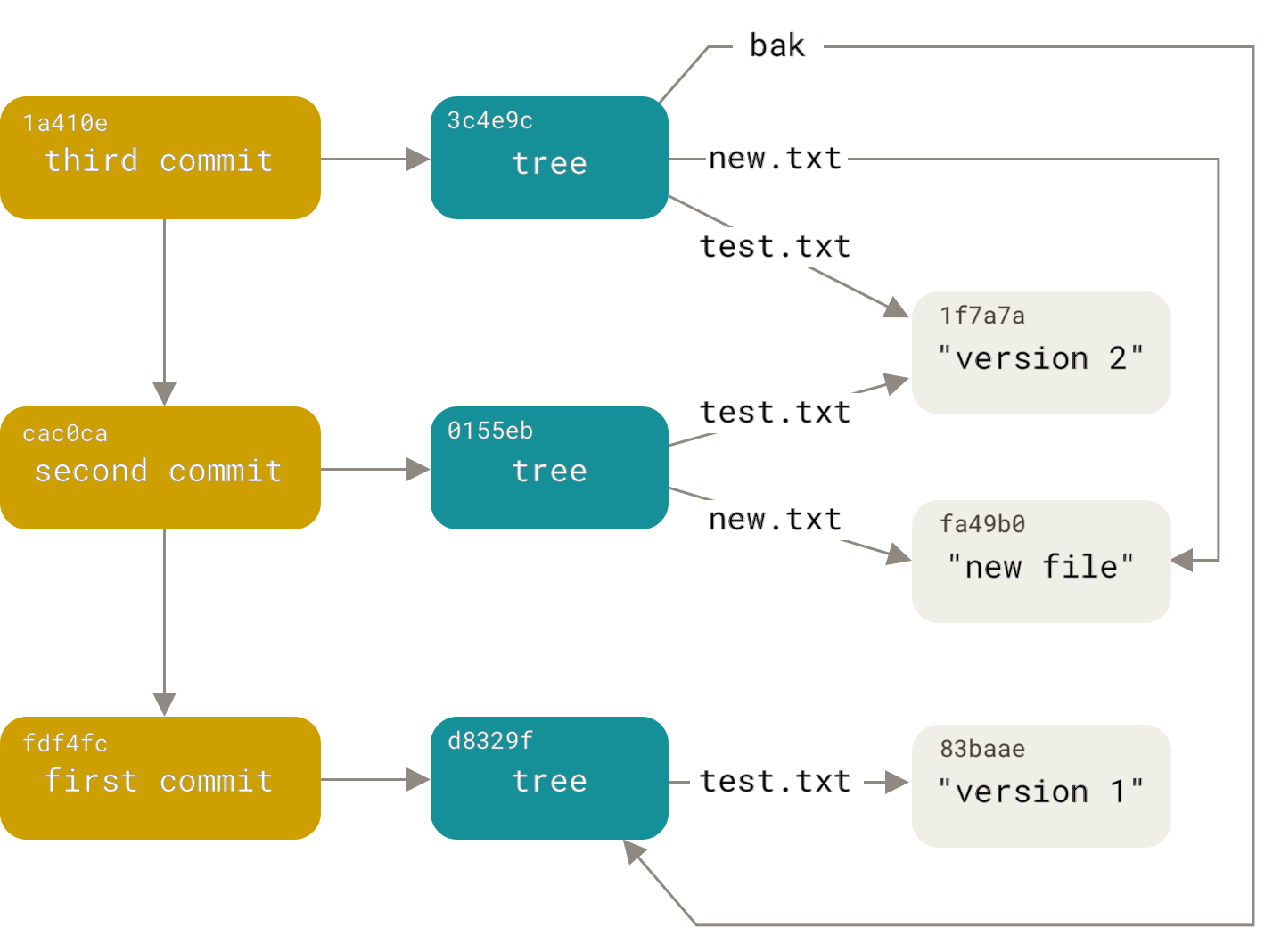
So wurde unsere Aufgabe in die Aufgabe umgewandelt, einen neuen Digraphen zu bauen, der die Struktur des alten wiederholt. Mit dem Ersetzen der Commits der Datei

second.version durch Commits aus dem zusätzlichen Repository ist der Entwicklungsprozess jedoch weit vom klassischen Gitflow entfernt. Wir verpflichten alles dem Meister und versuchen, es nicht gleichzeitig zu brechen. Wir bauen von dort aus. Bei Bedarf machen wir stabilisierende Zweige, die wir dann wieder in den Master einbinden. Dementsprechend sieht das Repository-Diagramm aus wie ein nackter Stamm eines mit Weinreben geflochtenen Mammutbaums.
Analyse
Die Aufgabe gliedert sich natürlich in zwei Phasen: Analyse und Synthese. Da es für die Synthese offensichtlich erforderlich ist, ab dem Zeitpunkt der Zuordnung des sekundären Repositorys zu allen Tags und Zweigen zu laufen und Commits aus dem zweiten Repository einzufügen, müssen in der Analysephase Orte gefunden werden, an denen sekundäre Commits eingefügt werden können, und diese Commits selbst. Sie müssen also ein reduziertes Diagramm erstellen, in dem die Knoten die Commits des Hauptdiagramms sind, die die Datei second.version ändern (Key Commits). Wenn sich die Knoten dieser Gita auf Eltern beziehen, werden in der neuen Grafik Verweise auf Nachkommen benötigt. Ich erstelle ein benanntes Tupel:
node = namedtuple(‘Node’, [‘primary_commit’, ‘secondary_commit’, ‘children’])
notwendige Reservierung
, . , .
Ich habe es in das Wörterbuch aufgenommen:
master_tip = repo.commit(‘master’)
commit_map = {master_tip : node(master_tip, get_sec_commit(master_tip), [])}Ich habe alle Commits, die die sekundäre Version ändern, dort abgelegt:
for c in repo.iter_commits(all=True, path=’secondary.verion’) :
commit_map[c] = node(c, get_sec_commit(c), [])Und ich baue einen einfachen rekursiven Algorithmus:
def build_dag(commit, commit_map, node):
for p in commit.parents :
if p in commit_map :
if node not in commit_map[p].children :
commit_map[p].children.append(node)
build_dag(p, commit_map, commit_map[p])
else :
build_dag(p, commit_map, node)Das heißt, ich strecke die Schlüsselknoten in die Vergangenheit und verbinde sie mit neuen Eltern.
Ich führe es aus und ... RuntimeError maximale Rekursionstiefe überschritten
Wie ist es passiert? Gibt es zu viele Commits? Git Log und wc kennen die Antwort. Die Gesamtzahl der Commits seit dem Split beträgt ungefähr 20.000 und diejenigen, die die sekundäre Version betreffen - fast 700. Das Rezept ist bekannt, es wird eine nicht rekursive Version benötigt.
def build_dag(master_tip, commit_map, master_node):
to_process = [(master_tip, master_node)]
while len(to_process) > 0:
c, node = to_process.pop()
for p in c.parents :
if p in commit_map :
if node not in commit_map[p].children :
commit_map[p].children.append(node)
to_process.append(p, commit_map[p])
else :
to_process.append(p, node)(Und Sie sagten, dass all diese Algorithmen nur für das Bestehen des Interviews benötigt werden!) Ich
starte es und ... es funktioniert. Eine Minute, fünf, zwanzig ... Nein, so lange kann man nicht dauern. Ich halte an. Anscheinend wird jedes Commit und jeder Pfad viele Male verarbeitet. Wie viele Äste hat der Baum? Es stellte sich heraus, dass der Baum 40 Äste enthält und dementsprechendandere Pfade nur vom Master. Und es gibt viele Wege, die zu einem erheblichen Teil der wichtigsten Commits führen. Da ich nicht Tausende von Jahren auf Lager habe, muss ich den Algorithmus so ändern, dass jedes Commit genau einmal verarbeitet wird. Dazu füge ich einen Satz hinzu, in dem ich jedes verarbeitete Commit markiere. Es gibt jedoch ein kleines Problem: Bei diesem Ansatz gehen einige der Links verloren, da unterschiedliche Pfade mit unterschiedlichen Schlüssel-Commits dieselben Commits durchlaufen können und nur der erste weiter geht. Um dieses Problem zu umgehen, ersetze ich das Set durch ein Wörterbuch, in dem die Schlüssel Festschreibungen und die Werte Listen erreichbarer Schlüsselüberschreibungen sind:
def build_dag(master_tip, commit_map, master_node):
processed_commits = {}
to_process = [(master_tip, master_node, [])]
while len(to_process) > 0:
c, node, path = to_process.pop()
p_node = commit_map.get(c)
if p_node :
commit_map[p].children.append(p_node)
for path_c in path :
if all(p_node.trunk_commit != nc.trunk_commit for nc
in processed_cmmts[path_c]) :
processed_cmmts[path_c].append(p_node)
path = []
node = p_node
processed_cmmts[c] = []
for p in c.parents :
if p != root_commit and and p not in processed_cmmts :
newpath = path.copy()
newpath.append(c)
to_process.append((p, node, newpath,))
else :
p_node = commit_map.get(p)
if p_node is None :
p_nodes = processed_cmmts.get(p, [])
else :
p_nodes = [p_node]
for pn in p_nodes :
node.children.append(pn)
if all(pn.trunk_commit != nc.trunk_commit for nc
in processed_cmmts[c]) :
processed_cmmts[c].append(pn)
for path_c in path :
if all(pn.trunk_commit != nc.trunk_commit
for nc in processed_cmmts[path_c]) :
processed_cmmts[path_c].append(pn)Als Ergebnis dieses zeitlosen kunstlosen Speicheraustauschs wird der Graph in 30 Sekunden erstellt.
Synthese
Jetzt habe ich eine commit_map mit Schlüsselknoten, die über untergeordnete Links mit einem Diagramm verbunden sind. Der Einfachheit halber werde ich es in eine Folge von Paaren (Vorfahr, Nachkomme) umwandeln . Die Reihenfolge muss gewährleistet sein, dass alle Paare, bei denen ein Knoten als Kind auftritt, früher liegen als jedes Paar, bei dem ein Knoten als Vorfahr auftritt. Dann müssen Sie nur noch diese Liste durchgehen und zuerst Commits aus dem Haupt-Repository und dann aus dem zusätzlichen Repository festschreiben. Hier müssen Sie beachten, dass das Commit einen Link zum Baum enthält, der den Status des Dateisystems darstellt. Da das zusätzliche Repository zusätzliche Unterverzeichnisse im Paket / Verzeichnis enthältDann müssen für alle Commits neue Bäume erstellt werden. In der ersten Version habe ich nur Blobs in Dateien geschrieben und den Git gebeten, einen Index für das Arbeitsverzeichnis zu erstellen. Diese Methode war jedoch nicht sehr produktiv. Es gibt immer noch 20.000 Commits, und jeder muss erneut festgeschrieben werden. Leistung ist also sehr wichtig. Ein wenig Recherche in den Interna von GitPython führte mich zur Klasse gitdb.LooseObjectDB , die den direkten Zugriff auf Git-Repository-Objekte ermöglicht. Damit können Blobs und Bäume (und auch alle anderen Objekte) aus einem Repository direkt in ein anderes geschrieben werden. Eine wunderbare Eigenschaft der Git-Objektdatenbank ist, dass die Adresse eines Objekts ein Hash seiner Daten ist. Daher hat derselbe Blob auch in verschiedenen Repositorys dieselbe Adresse.
secondary_paths = set()
ldb = gitdb.LooseObjectDB(os.path.join(repo.git_dir, 'objects'))
while len(pc_pairs) > 0:
parent, child = pc_pairs.pop()
for c in all_but_last(repo.iter_commits('{}..{}'.format(
parent.trunk_commit, child.trunk_commit), reverse = True)) :
newparents = [new_commits.get(p, p) for p in c.parents]
new_commits[c] = commit_primary(repo, newparents, c, secondary_paths)
newparents = [new_commits.get(p, p) for p in child.trunk_commit.parents]
c = secrepo.commit(child.src_commit)
sc_message = 'secondary commits {}..{} <devonly>'.format(
parent.src_commit, child.src_commit)
scm_details = '\n'.join(
'{}: {}'.format(i.hexsha[:8], textwrap.shorten(i.message, width = 70))
for i in secrepo.iter_commits(
'{}..{}'.format(parent.src_commit, child.src_commit), reverse = True))
sc_message = '\n\n'.join((sc_message, scm_details))
new_commits[child.trunk_commit] = commit_secondary(
repo, newparents, c, secondary_paths, ldb, sc_message)Das Commit funktioniert selbst:
def commit_primary(repo, parents, c, secondary_paths) :
head_tree = parents[0].tree
repo.index.reset(parents[0])
repo.git.read_tree(c.tree)
for p in secondary_paths :
# primary commits don't change secondary paths, so we'll just read secondary
# paths into index
tree = head_tree.join(p)
repo.git.read_tree('--prefix', p, tree)
return repo.index.commit(c.message, author=c.author, committer=c.committer
, parent_commits = parents
, author_date=git_author_date(c)
, commit_date=git_commit_date(c))
def commit_secondary(repo, parents, sec_commit, sec_paths, ldb, message):
repo.index.reset(parents[0])
if len(sec_paths) > 0 :
repo.index.remove(sec_paths, r=True, force = True, ignore_unmatch = True)
for o in sec_commit.tree.traverse() :
if not ldb.has_object(o.binsha) :
ldb.store(gitdb.IStream(o.type, o.size, o.data_stream))
if o.path.find(os.sep) < 0 and o.type == 'tree': # a package root
repo.git.read_tree('--prefix', path, tree)
sec_paths.add(p)
return repo.index.commit(message, author=sec_commit.author
, committer=sec_commit.committer
, parent_commits=parents
, author_date=git_author_date(sec_commit)
, commit_date=git_commit_date(sec_commit))
Wie Sie sehen können, werden Commits aus dem sekundären Repository in großen Mengen hinzugefügt. Zuerst habe ich sichergestellt, dass einzelne Commits hinzugefügt wurden, aber (plötzlich!) Es stellte sich heraus, dass manchmal ein neueres Key-Commit eine frühere Version des sekundären Repositorys enthält (mit anderen Worten, die Version wird zurückgesetzt). In einer solchen Situation übergibt die Methode iter_commit eine leere Liste und gibt sie zurück. Infolgedessen ist das Repository falsch. Daher musste ich nur die aktuelle Version festschreiben.
Interessant ist die Geschichte des Auftretens des Generators all_but_last. Ich habe die Beschreibung weggelassen, aber sie macht genau das, was Sie erwarten. Anfangs gab es nur eine Herausforderung
repo.iter_commits('{}..{}^'.format(parent.trunk_commit, child.trunk_commit), reverse = True)Im Allgemeinen endete alles gut. Das gesamte Skript passte in 300 Zeilen und lief in ca. 6 Stunden. Moral: GitPython ist praktisch, um alle möglichen coolen Dinge mit Repositories zu erledigen, aber es ist besser, die technischen Schulden rechtzeitig zu behandeln