Wir setzen eine Reihe von Artikeln über die Moderation von Inhalten an den Standorten des Financial Technologies Development Center der Russischen Landwirtschaftsbank fort. Im letzten Artikel haben wir darüber gesprochen, wie wir das Problem der Textmoderation für einen der Standorte des Ökosystems für Landwirte "Own Farming" gelöst haben . Sie können ein wenig über die Website selbst und das Ergebnis lesen, das wir hier erhalten haben .
Kurz gesagt, wir haben ein Ensemble aus einem naiven Klassifikator (Filter nach Wörterbuch) und BERT verwendet. Die Texte, die den Wörterbuchfilter bestanden haben, durften BERT eingeben, wo sie auch überprüft wurden.
Zusammen mit dem MIPT-Labor verbessern wir unsere Website weiter und stellen uns vor eine schwierigere Aufgabe, grafische Informationen vorab zu moderieren. Diese Aufgabe erwies sich als schwieriger als die vorherige, da bei der Verarbeitung natürlicher Sprache auf die Verwendung neuronaler Netzwerkmodelle verzichtet werden kann. Mit Bildern ist alles komplizierter - die meisten Aufgaben werden mithilfe neuronaler Netze und der Auswahl ihrer richtigen Architektur gelöst. Aber mit dieser Aufgabe haben wir es, wie es uns scheint, gut gemeistert! Und was wir daraus haben, lesen Sie weiter.

Was wir wollen?
So lass uns gehen! Lassen Sie uns sofort definieren, was ein Bildmoderationswerkzeug sein soll. In Analogie zu einem Textmoderationstool sollte dies eine Art "Black Box" sein. Durch das Einreichen eines von Verkäufern von Waren auf die Website hochgeladenen Bildes als Eingabe möchten wir verstehen, wie dieses Bild für die Veröffentlichung auf der Website akzeptabel ist. Damit haben wir die Aufgabe: festzustellen, ob das Bild für die Veröffentlichung auf der Website geeignet ist oder nicht.
Die Aufgabe der Vormoderation von Bildern ist üblich, aber die Lösung unterscheidet sich häufig von Standort zu Standort. Bilder von inneren Organen sind möglicherweise für medizinische Foren akzeptabel, aber für soziale Medien nicht geeignet. Zum Beispiel sind Bilder von geschnittenen Tierkadavern auf einer Website, auf der sie verkauft werden, akzeptabel, aber es ist unwahrscheinlich, dass sie Kindern gefallen, die online gehen, um Smesharikov zu sehen. Für unsere Website wären Bilder von landwirtschaftlichen Produkten (Gemüse / Obst, Tierfutter, Düngemittel usw.) akzeptabel. Andererseits ist es offensichtlich, dass das Thema unseres Marktes nicht das Vorhandensein von Bildern mit verschiedenen obszönen oder anstößigen Inhalten impliziert.
Zunächst haben wir uns entschlossen, die bereits bekannten Problemlösungen kennenzulernen und sie an unsere Website anzupassen. In der Regel beschränken sich viele Aufgaben der Moderation grafischer Inhalte auf die Lösung von Problemen der NSFW- Klasse , für die es einen öffentlich verfügbaren Datensatz gibt .
Zur Lösung von NSFW-Problemen werden in der Regel Klassifikatoren auf Basis von ResNet verwendet, die eine Qualitätsgenauigkeit von> 93% aufweisen.
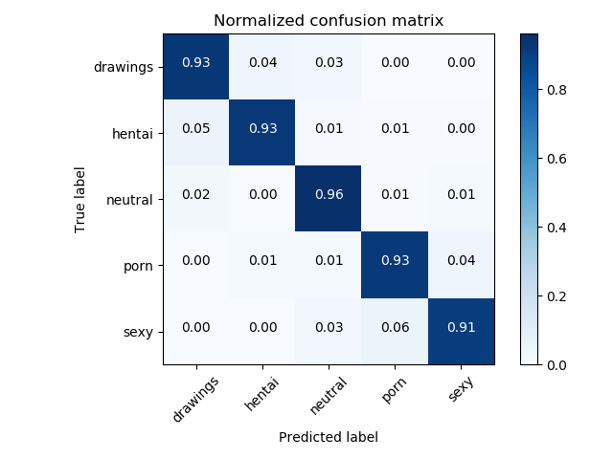
Fehlermatrix des ursprünglichen NSFW-Klassifikators
Angenommen, wir haben ein gutes Modell und einen vorgefertigten Datensatz für NSFW. Wird dies jedoch ausreichen, um die Akzeptanz des Bildes für die Site zu bestimmen? Es stellte sich nicht heraus. Nachdem wir diesen ersten Ansatz mit dem NSFW-Modell mit den Eigentümern unserer Website besprochen hatten, stellten wir fest, dass es notwendig ist, ein wenig mehr Kategorien zu definieren, nämlich:
- ( , )
- ( , , , . )
- ( )
Das heißt, wir mussten immer noch unseren eigenen Datensatz zusammenstellen und darüber nachdenken, welche anderen Modelle nützlich sein könnten.
Hier stoßen wir auf ein häufiges Problem des maschinellen Lernens: Datenmangel. Dies liegt an der Tatsache, dass unsere Website vor nicht allzu langer Zeit erstellt wurde und es keine negativen Beispiele gibt, die als inakzeptabel markiert sind. Um dies zu lösen, hilft uns die Lernmethode mit wenigen Schüssen . Das Wesentliche dieser Methode ist, dass wir beispielsweise ResNet für kleine Datensätze, die wir zusammengestellt haben, neu trainieren und eine höhere Genauigkeit erzielen können, als wenn wir einen Klassifikator von Grund auf neu erstellt hätten und nur unseren kleinen Datensatz verwenden würden.
Wie hast du es gemacht?
Im Folgenden finden Sie ein allgemeines Schema unserer Lösung, das vom Eingabebild ausgeht und mit dem Ergebnis der Erkennung verschiedener Kategorien endet, wenn der Eingabe ein Apfelbild zugeführt wird.

Allgemeines Schema der Lösung
Betrachten wir jeden Teil des Schemas genauer.
Stufe 1: Graffiti-Detektor
Wir erwarten, dass Waren mit Text auf Paketen auf unsere Website geladen werden und dementsprechend die Aufgabe besteht, Inschriften zu erkennen und deren Bedeutung zu identifizieren.
In der ersten Phase haben wir die OpenCV-Texterkennungsbibliothek verwendet, um die Beschriftungen auf den Paketen zu finden.
OpenCV Text Detection ist ein OCR-Tool (Optical Character Recognition) für Python. Das heißt, es erkennt und "liest" Text, der in Bilder eingebettet ist.

Beispiel für den Betrieb des EAST-Detektors
Auf dem Foto sehen Sie ein Beispiel für die Erkennung von Inschriften. Um den Begrenzungsrahmen zu identifizieren, haben wir das EAST-Modell verwendet, aber hier kann der Leser einen Haken spüren, da dieses Modell darauf trainiert ist, englische Texte zu erkennen, und auf unseren Bildern sind die Texte in russischer Sprache. Aus diesem Grund verwenden wir außerdem ein binäres Klassifizierungsmodell (Graffiti / nicht Graffiti) auf der Basis von ResNet, das auf die erforderliche Qualität unserer Daten trainiert wurde. Wir haben ResNet-18 gewählt, da sich dieses Modell bei der Auswahl einer Architektur als das beste erwiesen hat.
In unserer Aufgabe möchten wir ein Foto, bei dem es sich bei den Inschriften um Inschriften auf der Verpackung von Waren handelt, von Graffiti unterscheiden. Aus diesem Grund haben wir beschlossen, alle Fotos mit Text in zwei Klassen zu unterteilen: Graffiti und Nicht-Graffiti. Die
erhaltene Modellgenauigkeit betrug 95% für eine vorab zurückgestellte Stichprobe:
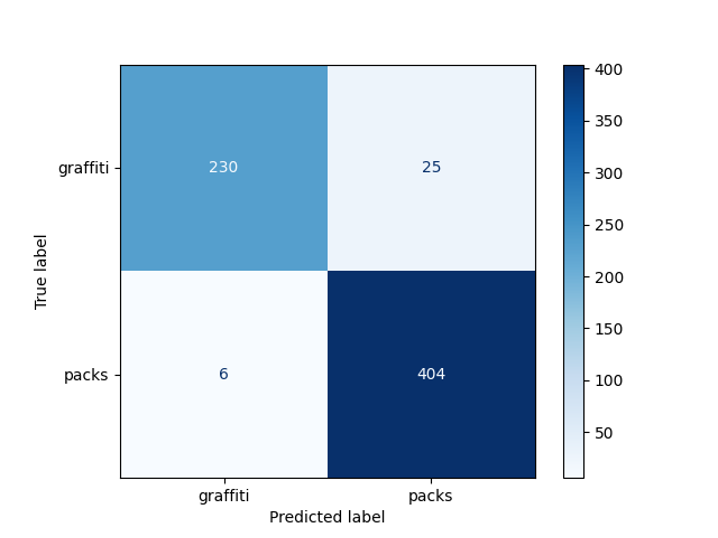
Graffiti Detector Bug Matrix
Nicht schlecht! Jetzt können wir den Text auf dem Foto isolieren und mit guter Wahrscheinlichkeit verstehen, ob er für die Veröffentlichung geeignet ist. Aber was ist, wenn das Foto keinen Text enthält?
Stufe 2: NSFW-Detektor
Wenn wir keinen Text im Bild finden, bedeutet dies nicht, dass er nicht akzeptabel ist. Daher möchten wir als Nächstes bewerten, wie der Inhalt des Bildes dem Thema der Site entspricht.
In dieser Phase besteht die Aufgabe darin, das Bild einer der Kategorien zuzuordnen:
- Drogen
- Porno (Porno)
- Tiere
- Fotos, die zur Ablehnung führen können (einschließlich Zeichnungen) (gore / draw_gore)
- Hentai (Hentai)
- neutrale Bilder (neutral)
Es ist wichtig, dass das Modell nicht nur die Kategorie, sondern auch den Grad des Vertrauens der darin enthaltenen Algorithmen zurückgibt.
Zur Klassifizierung wurde ein NSFW-basiertes Modell verwendet. Sie ist so ausgebildet, dass sie das Foto in 7 Klassen unterteilt, von denen wir nur eine auf der Website erwarten. Daher hinterlassen wir nur neutrale Fotos.
Das Ergebnis eines solchen Modells ist eine NSFW-Detektorfehlermatrix von 97% (in Bezug auf die Genauigkeit)

Stufe 3: Personendetektor
Aber selbst nachdem wir gelernt haben, wie man NSFW filtert, kann das Problem immer noch nicht als gelöst betrachtet werden. Beispielsweise fällt ein Foto einer Person weder in die NSFW-Kategorie noch in das Foto mit der Textkategorie, aber wir möchten solche Bilder auch nicht auf der Website sehen. Dann haben wir unserer Architektur ein Modell der menschlichen Erkennung hinzugefügt - Single Shot Detector (im Folgenden als SSD bezeichnet).
Die Auswahl von Personen oder eines anderen zuvor bekannten Objekts ist ebenfalls eine beliebte Aufgabe bei einer Vielzahl von Anwendungen. Wir haben das fertige Modell nvidia_ssd von pytorch verwendet.

Ein Beispiel für den SSD-Algorithmus
Die Ergebnisse des Modells sind niedriger (Genauigkeit - 96%):

Human Detector Error Matrix
Ergebnisse
Wir haben die Qualität unseres Instruments anhand der gewichteten Metriken F1, Präzision und Rückruf bewertet. Die Ergebnisse sind in der Tabelle dargestellt:
| Metriken | Genauigkeit erhalten |
| Gewichtete F1 | 0,96 |
| Gewichtete Präzision | 0,96 |
| Gewichteter Rückruf | 0,96 |
Und hier sind einige anschaulichere Beispiele seiner Arbeit:
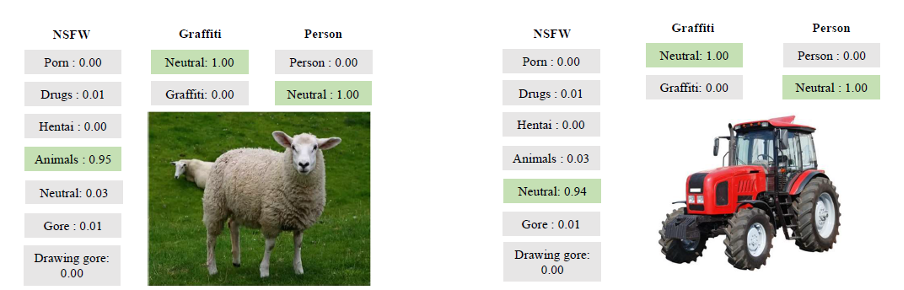
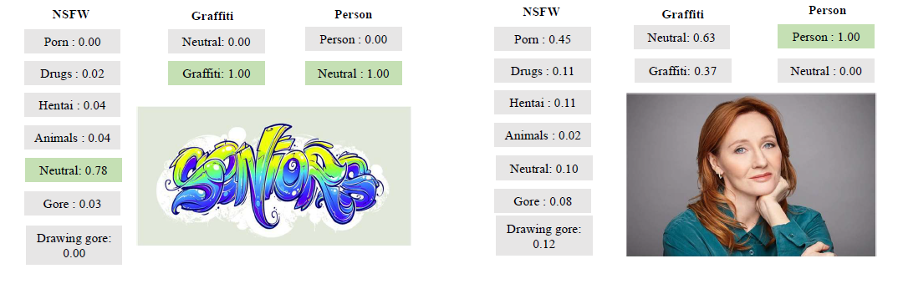
Beispiele des Werkzeugs
Fazit
Beim Lösen haben wir einen ganzen "Zoo" von Modellen verwendet, die häufig für Computer-Vision-Aufgaben verwendet werden. Wir haben gelernt, Text aus Fotos zu „lesen“, Personen zu finden und unangemessene Inhalte zu unterscheiden.
Abschließend möchte ich darauf hinweisen, dass das betrachtete Problem unter dem Gesichtspunkt des Sammelns von Erfahrungen und der Verwendung modifizierter klassischer Modelle nützlich ist. Hier sind einige der Erkenntnisse, die wir erhalten haben:
- Sie können das Problem der Datenknappheit mithilfe der Lernmethode mit wenigen Schüssen umgehen: Große Modelle können anhand ihrer eigenen Daten mit der erforderlichen Genauigkeit trainiert werden
- : ,
- , ,
- , , . , , ,
- Trotz der Tatsache, dass die Aufgabe der Bildmoderation sehr beliebt ist, kann ihre Lösung, wie im Fall von Texten, von Standort zu Standort unterschiedlich sein, da jeder von ihnen für ein anderes Publikum konzipiert ist. In unserem Fall haben wir beispielsweise neben unangemessenen Inhalten auch Tiere und Menschen entdeckt
Vielen Dank für Ihre Aufmerksamkeit und bis zum nächsten Artikel!