Heute führen wir ein physisches und technisches Gespräch mit Mikhail Burtsev , dem Leiter des Labors für neuronale Netze am MIPT. Seine Forschungsinteressen umfassen Lernmodelle für neuronale Netze, neurokognitive und Neurohybrid-Systeme, Evolution adaptiver Systeme und evolutionärer Algorithmen, Neurocontroller und Robotik. All dies wird diskutiert.

- Wie begann die Geschichte des Labors für Neuronale Netze und Deep Learning bei Phystech?
- 2015 nahm ich an einer Initiative der Agentur für strategische Initiativen (ASI) mit dem Namen "Foresight Fleet" teil - dies ist eine mehrtägige Diskussionsplattform im Rahmen der Nationalen Technischen Initiative. Das Schlüsselthema betraf die Technologien, die entwickelt werden müssen, damit Unternehmen in Russland auftreten können und das Potenzial haben, führende Positionen auf den globalen Märkten einzunehmen. Die Hauptbotschaft war, dass es äußerst schwierig ist, in die gebildeten Märkte einzutreten, aber Technologien eröffnen neue Gebiete und neue Märkte, und genau auf diesen müssen wir eintreten.
Also segelten wir auf einem Motorschiff entlang der Wolga und diskutierten, welche Technologien dazu beitragen könnten, solche Märkte zu schaffen und die gegenwärtigen technologischen Barrieren zu überwinden. Und in dieser Diskussion über die Zukunft ist das Thema mit persönlichen Assistenten gewachsen. Es ist klar, dass wir bereits damit begonnen haben - Alexa, Alice, Siri ... und es war offensichtlich, dass es technische Hindernisse beim Verständnis zwischen Mensch und Computer gibt. Andererseits haben sich viele Forschungsentwicklungen angesammelt, beispielsweise im Bereich des verstärkten Lernens in der Verarbeitung natürlicher Sprache. Und es wurde klar: Viele schwierige Aufgaben werden mit Hilfe neuronaler Netze immer besser gelöst.
Und ich habe gerade über neuronale Netzwerkalgorithmen geforscht. Basierend auf den Ergebnissen der Foresight Fleet-Diskussionen formulierten wir das Konzept eines Technologieentwicklungsprojekts für die nahe Zukunft, das später in das iPavlov-Projekt umgewandelt wurde. Dies war der Beginn meiner Interaktion mit Phystech.
Im Detail haben wir drei Aufgaben formuliert. Infrastruktur - Erstellen einer offenen Bibliothek für die Durchführung von Dialogen mit dem Benutzer. Die zweite ist die Forschung in der Verarbeitung natürlicher Sprache. Plus die Lösung spezifischer geschäftlicher Probleme .
Die Sberbank fungierte als Partner, und das Projekt selbst wurde unter der Leitung der Nationalen Technischen Initiative gegründet.
, 2015 -: deephack.me — , , - , . Open Data Science.
Anfang 2018 haben wir das erste Repository unserer offenen Bibliothek DeepPavlov veröffentlicht. In den letzten zwei Jahren haben wir eine stetige Zunahme der Benutzer festgestellt (es konzentriert sich auf Russisch und Englisch): Wir haben ungefähr 50% der Installationen aus den USA, 20-30% aus Russland. Insgesamt stellte sich heraus, dass es sich um ein recht erfolgreiches Open Source-Projekt handelte.
Wir entwickeln nicht nur, sondern versuchen auch, einen Beitrag zur globalen Forschungsagenda zur Konversations-KI zu leisten. Wir erkannten die Notwendigkeit eines akademischen Wettbewerbs in diesem Bereich und starteten die Conversational AI Challenges- Reihe im Rahmen von NeuIPS, der führenden Konferenz für maschinelles Lernen.
Darüber hinaus organisieren wir nicht nur Wettbewerbe, sondern nehmen auch teil. Das Team unseres Labors nahm letztes Jahr an einem Wettbewerb von Amazon namens Alexa Prize teil, bei dem ein Chat-Bot erstellt wurde, mit dem eine Person 20 Minuten lang sprechen möchte.
Der nächste Wettbewerb beginnt im November.
Dies ist ein Universitätswettbewerb. Der Kern der Teilnehmer bestand aus Studenten und Universitätsmitarbeitern. Insgesamt gab es 350 Teams, sieben wurden für die Spitze ausgewählt und drei werden aufgrund der Ergebnisse des letzten Jahres eingeladen - wir haben es an die Spitze geschafft.
Unser Dialogsystem führte ungefähr 100.000 Dialoge mit Benutzern in den Vereinigten Staaten und hatte am Ende eine Bewertung von ungefähr 3,35-3,4 von 5, was ziemlich gut ist. Dies deutet darauf hin, dass es uns in relativ kurzer Zeit gelungen ist, ein Weltklasse-Team bei MIPT zu bilden.
Jetzt führt das Labor Projekte mit verschiedenen Unternehmen durch, darunter Huawei und Sberbank. Projekte in verschiedene Richtungen: AutoML, Theorie neuronaler Netze und natürlich unsere Hauptrichtung - NLP.
- Über die Aufgaben, die früher für maschinelles Lernen schwierig waren: Warum hat Deep Learning bei der Lösung dieser Probleme begonnen?
- Schwer zu erzählen. Ich werde jetzt meine Intuition etwas vereinfacht beschreiben. Der Punkt ist, dass wenn das Modell viele Parameter hat, es überraschenderweise die Ergebnisse gut auf neue Daten verallgemeinern kann. In dem Sinne, dass die Anzahl der Parameter der Anzahl der Beispiele entsprechen kann. Aus dem gleichen Grund hat sich die klassische ML lange dem Druck neuronaler Netze widersetzt - es scheint, dass in dieser Situation nichts Gutes daraus werden sollte.
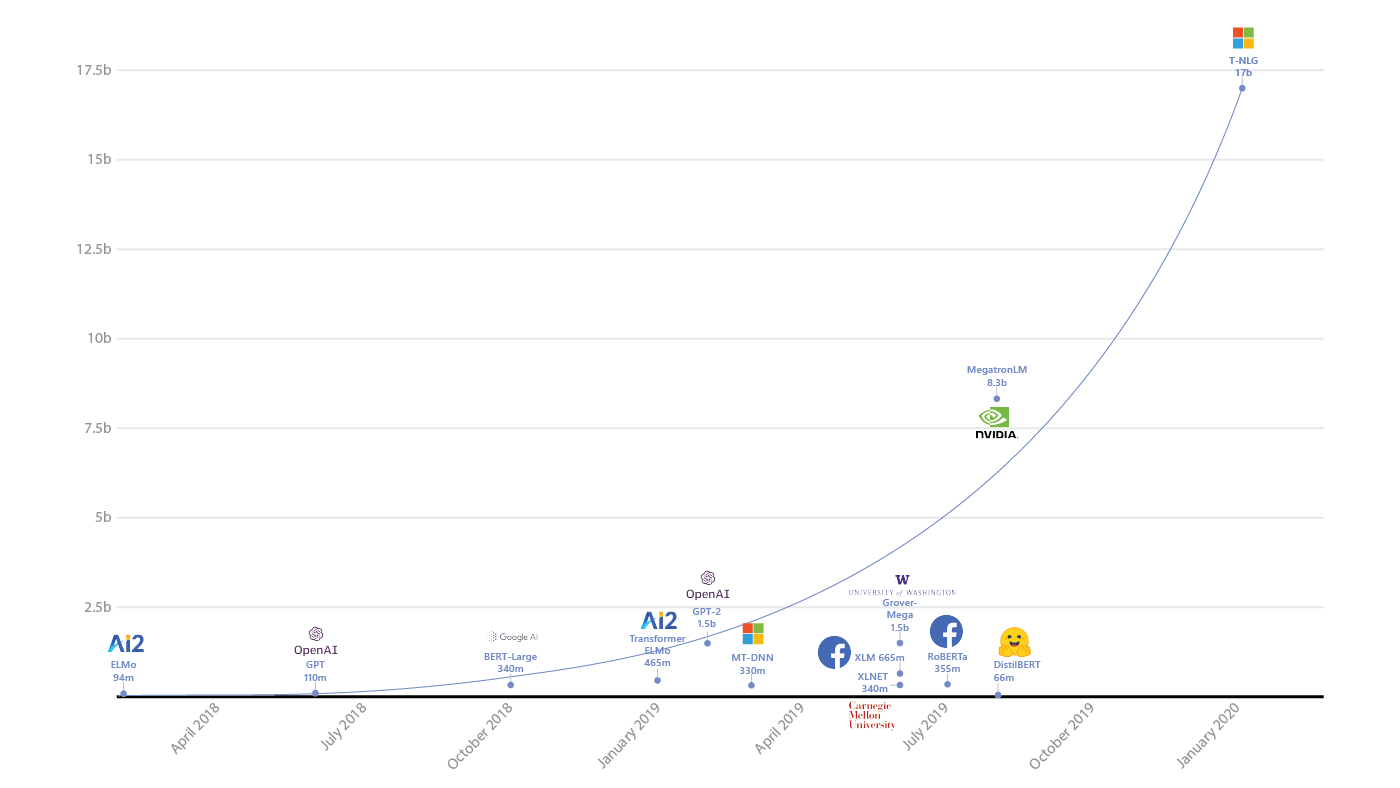
Der Anstieg von Parametern in Deep-Learning-Modellen ( Quelle )
Überraschenderweise nicht. Ivan Skorokhodov von unserem Labor zeigte ( .pdf ), dass fast jedes zweidimensionale Muster im Raum der Verlustfunktion des neuronalen Netzwerks gefunden werden kann.
Sie können eine Ebene so auswählen, dass jeder Punkt auf dieser Ebene einem Satz neuronaler Netzwerkparameter entspricht. Und ihr Verlust entspricht einem beliebigen Muster, und dementsprechend können Sie solche neuronalen Netze aufnehmen, dass sie direkt auf dieses Bild fallen.
Ein sehr lustiges Ergebnis. Dies legt nahe, dass das neuronale Netzwerk selbst mit solch absurden Einschränkungen die ihm zugewiesene Aufgabe lernen kann. Das ist ungefähr die Art von Intuition hier, ja.

Beispiele für Muster aus dem Artikel von Ivan Skorokhodov
- In den letzten Jahren wurden im Bereich des tiefen Lernens erhebliche Fortschritte erzielt. Ist jedoch bereits der Horizont sichtbar, an dem wir uns an der Grenze der Indikatoren vergraben werden?

Das Wachstum der Größe von KI-Modellen und der Ressourcen, die sie verbrauchen (Quelle: openai.com/blog/ai-and-compute/ )
- In unserem NLP ist die Grenze noch nicht spürbar, obwohl es den Anschein hat, dass beispielsweise beim verstärkten Lernen bereits etwas begonnen hat Unterhose. Das heißt, in den letzten Jahren gab es keine qualitativen Änderungen. Es gab einen großen Boom von Atari zu AlphaGo mit der Hybridisierung mit Monte Carlo Tree Search, aber jetzt gibt es keinen direkten Durchbruch.
In NLP ist es jedoch umgekehrt: wiederkehrende Netzwerke, Faltungsnetzwerke und schließlich die Transformatorarchitektur und GPT selbst ( eines der neuesten und interessantesten Transformatormodelle, die häufig zur Erstellung von Texten verwendet werden - Anmerkung des Autors) Ist schon eine rein umfangreiche Entwicklung. Und hier scheint es noch einen Spielraum zu geben, um etwas Neues zu erreichen. Daher ist in NLP der Balken von oben noch nicht sichtbar. Obwohl es hier natürlich fast unmöglich ist, etwas vorherzusagen.
- Wenn wir uns die Entwicklung von Sprachen und Frameworks für maschinelles Lernen vorstellen, dann gingen wir vom Schreiben (bedingt) in rein numpy, Scikit-Learn zu Tensorflow, Keras über - die Abstraktionsebenen wuchsen. Was kommt als nächstes für uns?
— , : - . , , low level high level code: numpy . , , NLP : .
- Tensorflow / Pytorch — : .
- : NLP- — DeepPavlov.
- : — DeepPavlov Dream .
- Ein System zum Wechseln zwischen Skills / Pipelines, einschließlich unseres DeepPavlov-Agenten.
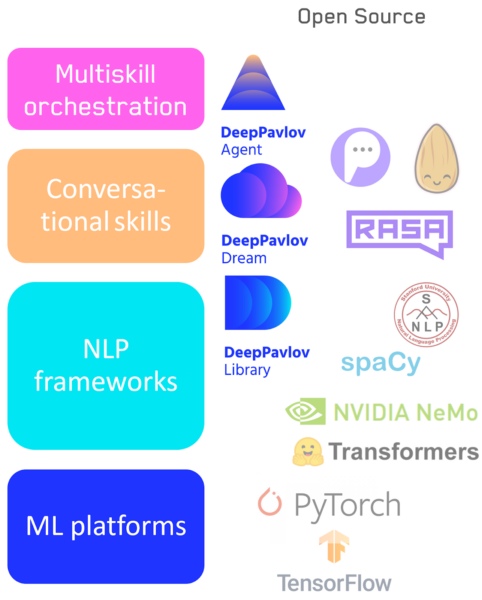
Konversations-KI-Technologie-Stack
Unterschiedliche Anwendungen und Aufgaben erfordern unterschiedliche Flexibilität der Tools. Daher glaube ich nicht, dass Elemente dieser Hierarchie verschwinden werden. Sowohl Low-Level- als auch High-Level-Systeme werden sich nach Bedarf weiterentwickeln. Beispielsweise werden visuelle Bibliotheken, die Programmierern nicht zur Verfügung stehen, aber auch Bibliotheken auf niedriger Ebene für Entwickler nirgendwo hingehen.
- Werden soziale Experimente jetzt analog zum klassischen Turing-Test durchgeführt, bei dem die Menschen verstehen müssen, ob sich ein neuronales Netzwerk vor ihnen oder eine Person befindet?
- Solche Versuche werden regelmäßig durchgeführt. Bei der Alexa Challenge musste eine Person die Qualität eines Gesprächs bewerten, ohne zu wissen, ob sie mit einem Bot oder einer Person sprach. Bisher ist der Unterschied zwischen einer Maschine und einer Person aus Sicht eines Live-Gesprächs erheblich, nimmt jedoch jedes Jahr ab. Unser Artikel dazu ist übrigens gerade im AI Magazine erschienen.
Außerhalb der wissenschaftlichen Gemeinschaft erfolgt dies regelmäßig. Kürzlich hat jemand ein GPT-Modell geschult, ein Twitter-Konto für sie eingerichtet und Antworten veröffentlicht. Viele Leute haben sich angemeldet, der Account wurde immer beliebter und niemand wusste, dass es sich um ein neuronales Netzwerk handelt.
Solch ein kurzes Format, wie bei Twitter, wenn die Formulierungen allgemein und "tiefgreifend" sind, passt einfach gut zum Inferenzsystem des neuronalen Netzwerks.
- Welche Bereiche halten Sie für die vielversprechendsten, wo ist ein Sprung zu erwarten?
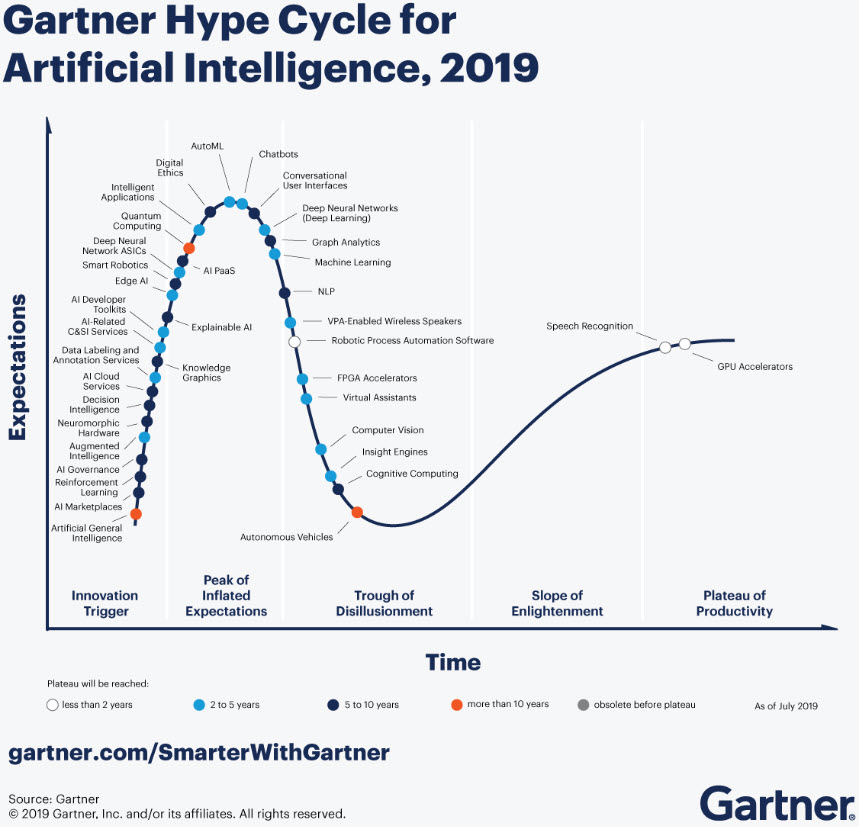
- ( lacht ) Ich könnte sagen, dass es in der Vereinigung aller meiner Lieblingsrichtungen einen Sprung geben wird. Ich werde versuchen, im Rahmen der Problematisierung näher zu beschreiben. Wir haben die aktuellen transformatorbasierten GPT-Modelle - sie haben keinen Sinn im Leben, sie erzeugen nur menschenähnlichen Text, völlig ziellos. Und sie können es nicht an die Situation und an Ziele im Kontext der Welt selbst binden.
Und eine der Möglichkeiten besteht darin, eine Bindung einer logischen Sicht der Welt an GPT herzustellen, die viel, viel Text gelesen hat, und darin gibt es tatsächlich bereits viele logische Verbindungen. Zum Beispiel durch Hybridisierung mit "Wikidata" (dies ist eine Grafik, die das Wissen über die Welt beschreibt, an deren Eckpunkten Wikipedia-Artikel stehen).
Wenn wir die beiden verbinden könnten, damit GPT die Wissensbasis nutzen kann, wäre das ein Sprung nach vorne.
Der zweite Ansatz für das Problem der Ziellosigkeit von NLP-Modellen basiert auf der Integration des Verständnisses menschlicher Ziele in diese. Wenn wir ein Modell haben, das ein generatives Sprachmodell steuern kann, das an ein Wissensdiagramm gebunden ist, können wir es trainieren, um einer Person zu helfen, ihre Ziele zu erreichen. Und ein solcher Assistent muss die Person durch NLP und die Ziele der Person und die Situation verstehen - dann muss er Maßnahmen planen. Und bei der Planung funktioniert das Lernen zur Stärkung am besten.
Wie all dies kombiniert und optimiert werden kann, ist eine offene Frage.
Und das letzte ist die Suche nach neuronalen Netzwerkarchitekturen. Wenn wir zum Beispiel evolutionäre Ansätze verwenden, betrachten wir den Raum von Architekturen, die für eine bestimmte Aufgabe optimal sind. Aber all dies wird heute nicht entschieden - es gibt zu viel Platz zum Suchen.
Aus den guten Nachrichten: Die Hardware entwickelt sich sehr schnell und ermöglicht es uns möglicherweise in 5-10 Jahren, Sprachmodelle für neuronale Netze, Wissensgraphen und verstärkendes Lernen zu kombinieren. Und dann werden wir einen Quantensprung im Verständnis der Maschine vom Menschen haben.
Mit Hilfe eines solchen Assistenten wird es möglich sein, die Lösung anderer Aufgaben zu starten: Bildanalyse, Analyse von Krankenakten oder der wirtschaftlichen Situation, Auswahl von Waren.
Daher würde ich sagen, dass wir aus wissenschaftlicher Sicht in den nächsten fünf Jahren eine rasante Entwicklung im Bereich der Hybridisierung sehen werden - es gibt viele coole Aufgaben.
Leute, der Personalmangel wird riesig sein, und es besteht eine große Chance, neue und interessante Ergebnisse zu erzielen und auch die Entwicklung der Branche zu beeinflussen. Verbinden Sie sich - Sie müssen den Moment nutzen!( Der Autor unterstützt diese Antwort aktiv, da er sich nur mit solchen Systemen befasst. )
- Wie fange ich an, in tiefes Lernen einzutauchen?
- Der einfachste Weg, so scheint es mir, ist ein Kurs an einer Deep-Learning-Schule : Ursprünglich war er für Schüler gedacht, aber für Schüler ist er durchaus geeignet. Im Allgemeinen ist dies ein großartiges Unterfangen. Ich half bei der Planung und hielt dort Einführungsvorträge.
Ich empfehle auch, Einführungskurse von Universitäten zu sehen und Aufgaben zu erledigen - es gibt nur eine Menge Dinge im Internet. Das beste aller Tools zum "Spielen" ist Colab von Google. Es gibt Millionen von Beispielen für Aufgaben. Sie können die modernsten Lösungen verstehen und ausführen - ohne Software auf Ihrem Computer zu installieren.
Ein anderer Weg ist, auf Kaggle anzutreten. Schließen Sie sich auch Open Data Science an - einer russischsprachigen Community für Data Science, wo es mehrere Deep-Learning-Kanäle gibt. Es gibt immer Leute, die bereit sind, mit Rat und Tat zu helfen.
Dies sind die Hauptwege.
Leader-ID : Freunde, für die jetzt gestartete Auswahl für den Beschleuniger zur Förderung von KI-Projekten haben wir uns eine Anmeldeoption für Indie-Entwickler ausgedacht. Nein, dies ändert nichts an den Grundbedingungen, unter denen nur Teams am Intensivkurs teilnehmen. Wir haben jedoch viele Fragen von Personen, die derzeit kein eigenes Projekt haben, aber teilnehmen möchten (und dies sind nicht nur Programmierer, Designer haben ein großes Interesse an KI-Projekten). Und wir haben eine Lösung gefunden: Wir werden helfen, ein Team und Gleichgesinnte durch einen kostenlosen Online-Hackathon zusammenzubringen . Es beginnt am 10. Oktober um 12:00 Uhr und endet genau einen Tag später. Darauf verteilt der Bot Sie in Teams, und dann durchlaufen Sie unter seiner Führung die Hauptphasen der Projektentwicklung und reichen sie beim Archipel 20.35 ein. Alle Details befinden sich in Ihrem persönlichen Konto. Sie müssen sich nur rechtzeitig registrieren.