
Unsere Welt generiert immer mehr Informationen. Ein Teil davon ist flüchtig und geht so schnell verloren, wie es gesammelt wird. Der andere sollte länger gelagert werden, während der andere "für Jahrhunderte" konzipiert ist - zumindest sehen wir das so aus der Gegenwart. Informationsflüsse werden in Rechenzentren mit einer solchen Geschwindigkeit abgewickelt, dass jeder neue Ansatz, jede Technologie, die entwickelt wurde, um diese endlose "Nachfrage" zu befriedigen, schnell überholt ist.
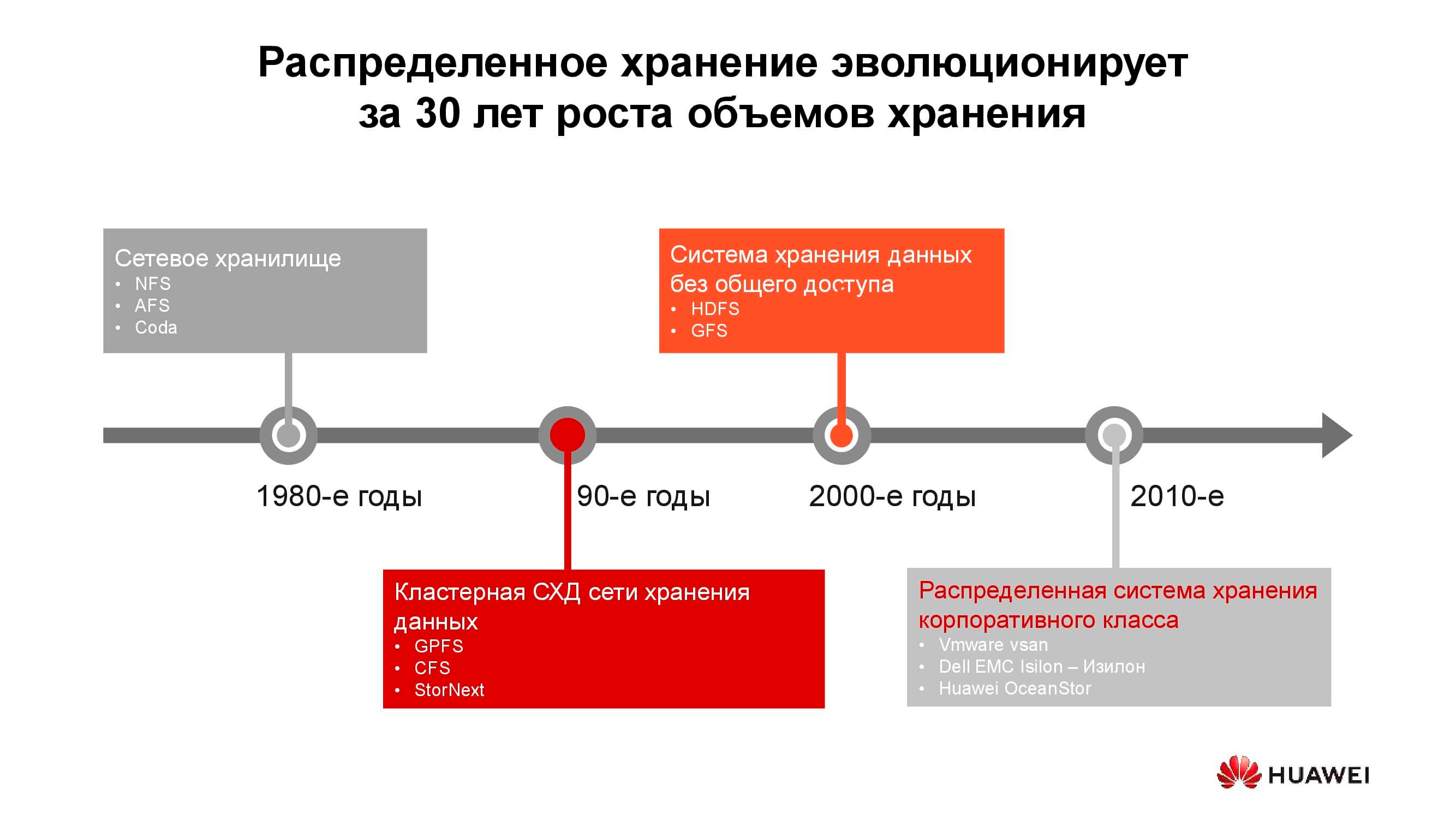
40 Jahre Entwicklung verteilter Speichersysteme
Die ersten netzwerkgebundenen Speicher erschienen in den 1980er Jahren in der üblichen Form. Viele von Ihnen sind auf NFS (Network File System), AFS (Andrew File System) oder Coda gestoßen. Ein Jahrzehnt später haben sich Mode und Technologie geändert, und verteilte Dateisysteme sind Cluster-Speichersystemen gewichen, die auf GPFS (General Parallel File System), CFS (Clustered File Systems) und StorNext basieren. Als Basis wurden Blockspeicher der klassischen Architektur verwendet, auf denen ein einzelnes Dateisystem unter Verwendung einer Softwareschicht erstellt wurde. Diese und ähnliche Lösungen werden immer noch verwendet, besetzen ihre eigene Nische und sind sehr gefragt.
Um die Jahrtausendwende änderte sich das Paradigma des verteilten Speichers etwas, und Systeme mit der SN-Architektur (Shared-Nothing) übernahmen die Führung. Es gab einen Übergang vom Cluster-Speicher zum Speicher auf separaten Knoten, bei denen es sich in der Regel um klassische Server mit Software handelte, die zuverlässigen Speicher bietet. Auf solchen Prinzipien basieren beispielsweise HDFS (Hadoop Distributed File System) und GFS (Global File System).
Näher an den 2010er Jahren spiegeln sich die zugrunde liegenden Konzepte des verteilten Speichers zunehmend in vollwertigen kommerziellen Produkten wie VMware vSAN, Dell EMC Isilon und unserem Huawei OceanStor wider.... Hinter den genannten Plattformen steht nicht mehr eine Community von Enthusiasten, sondern bestimmte Anbieter, die für die Funktionalität, den Support und den Service des Produkts verantwortlich sind und dessen Weiterentwicklung garantieren. Solche Lösungen sind in mehreren Bereichen am gefragtesten.
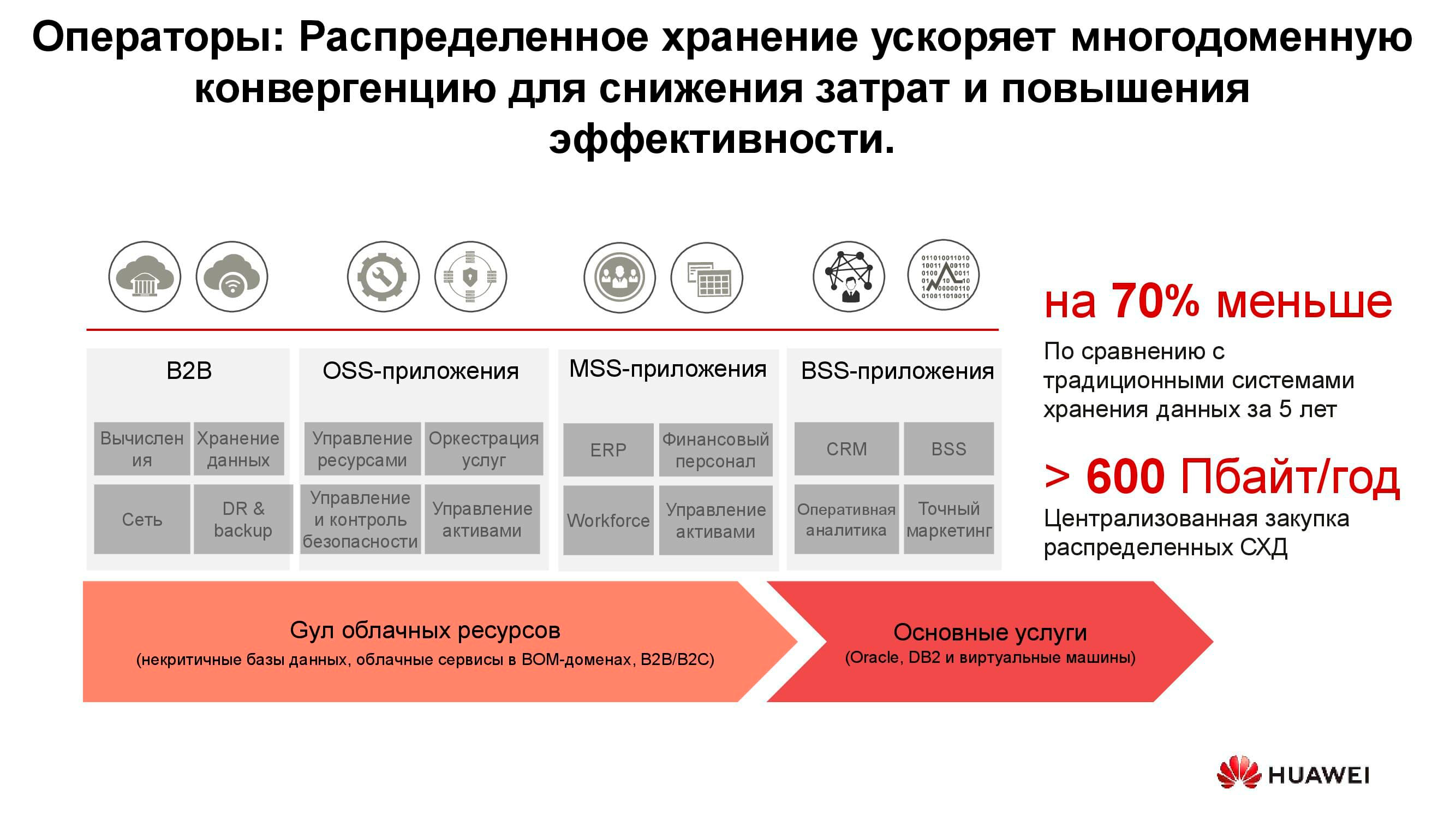
Telekommunikationsbetreiber
Möglicherweise sind Telekommunikationsbetreiber einer der ältesten Verbraucher verteilter Speichersysteme. Das Diagramm zeigt, welche Anwendungsgruppen den Großteil der Daten erzeugen. OSS (Operations Support Systems), MSS (Management Support Services) und BSS (Business Support Systems) sind drei komplementäre Softwareschichten, die für die Bereitstellung von Diensten für Abonnenten, die Finanzberichterstattung an den Anbieter und die Betriebsunterstützung für die Ingenieure des Betreibers erforderlich sind.
Oft sind die Daten dieser Schichten stark miteinander vermischt, und um die Anhäufung unnötiger Kopien zu vermeiden, werden verteilte Speicher verwendet, die die gesamte Menge an Informationen aus dem Arbeitsnetzwerk ansammeln. Die Speicher werden zu einem gemeinsamen Pool zusammengefasst, auf den sich alle Dienste beziehen.
Unsere Berechnungen zeigen, dass Sie durch den Übergang von klassischen Speichersystemen zu Blockspeichersystemen bis zu 70% des Budgets einsparen können, da dedizierte High-End-Speichersysteme aufgegeben werden und herkömmliche Server mit klassischer Architektur (normalerweise x86) in Verbindung mit spezieller Software verwendet werden. Mobilfunkbetreiber haben lange begonnen, solche Lösungen in großen Mengen zu kaufen. Insbesondere russische Betreiber verwenden solche Produkte von Huawei seit mehr als sechs Jahren.
Ja, eine Reihe von Aufgaben können nicht mit verteilten Systemen ausgeführt werden. Zum Beispiel mit erhöhten Leistungsanforderungen oder Kompatibilität mit älteren Protokollen. Mindestens 70% der vom Bediener verarbeiteten Daten können sich jedoch in einem verteilten Pool befinden.
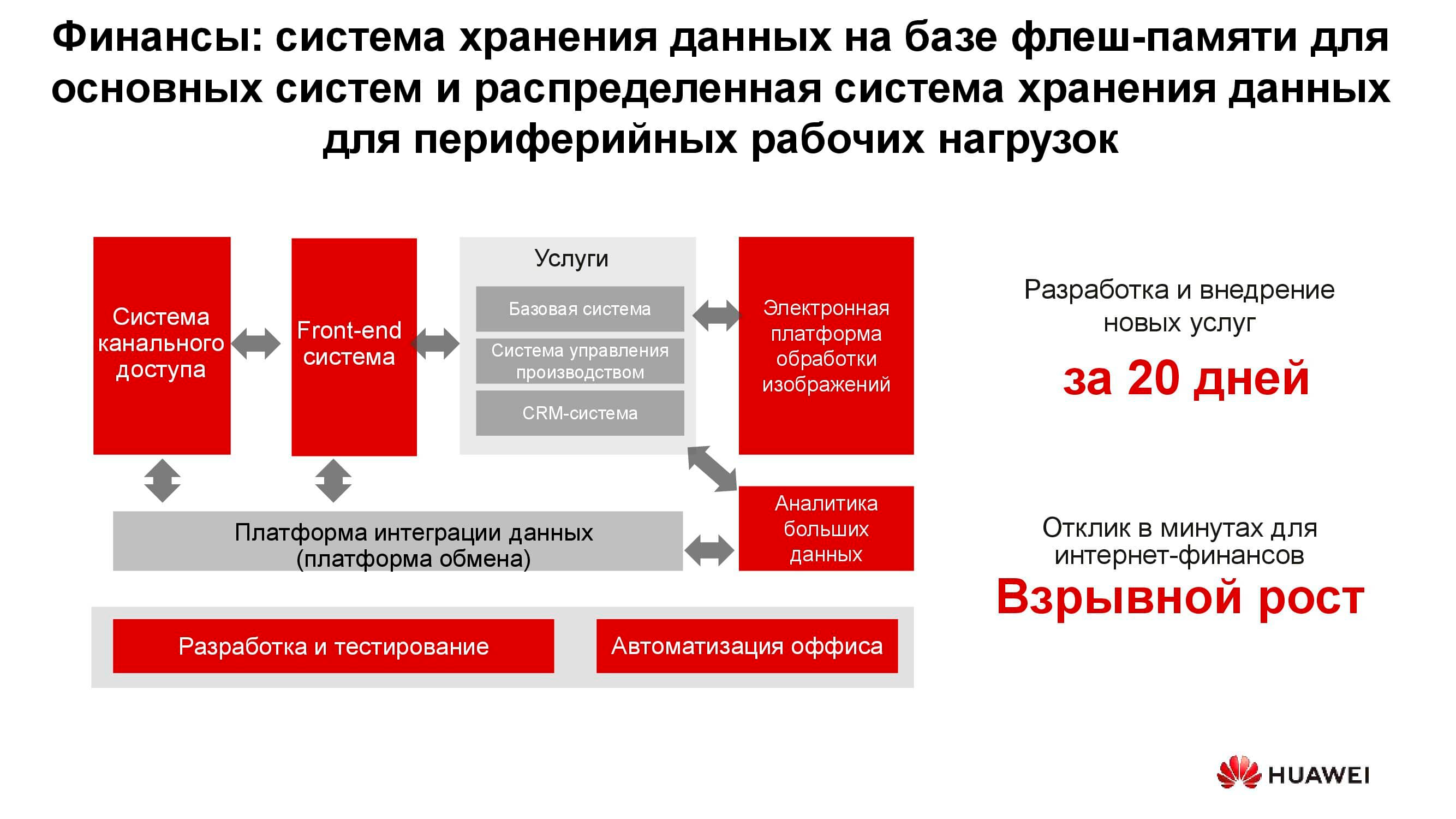
Bankensphäre
In jeder Bank gibt es viele verschiedene IT-Systeme, von der Verarbeitung bis zum automatisierten Bankensystem. Diese Infrastruktur arbeitet auch mit einer großen Menge an Informationen, während die meisten Aufgaben keine erhöhte Leistung und Zuverlässigkeit von Speichersystemen erfordern, z. B. Entwicklung, Test, Automatisierung von Büroprozessen usw. Hier ist die Verwendung klassischer Speichersysteme möglich, aber jedes Jahr wird sie immer weniger rentabel. Darüber hinaus gibt es in diesem Fall keine Flexibilität bei der Verwendung von Speicherressourcen, deren Leistung aus der Spitzenlast berechnet wird.
Bei Verwendung verteilter Speichersysteme können deren Knoten, bei denen es sich tatsächlich um normale Server handelt, jederzeit beispielsweise in eine Serverfarm konvertiert und als Computerplattform verwendet werden.
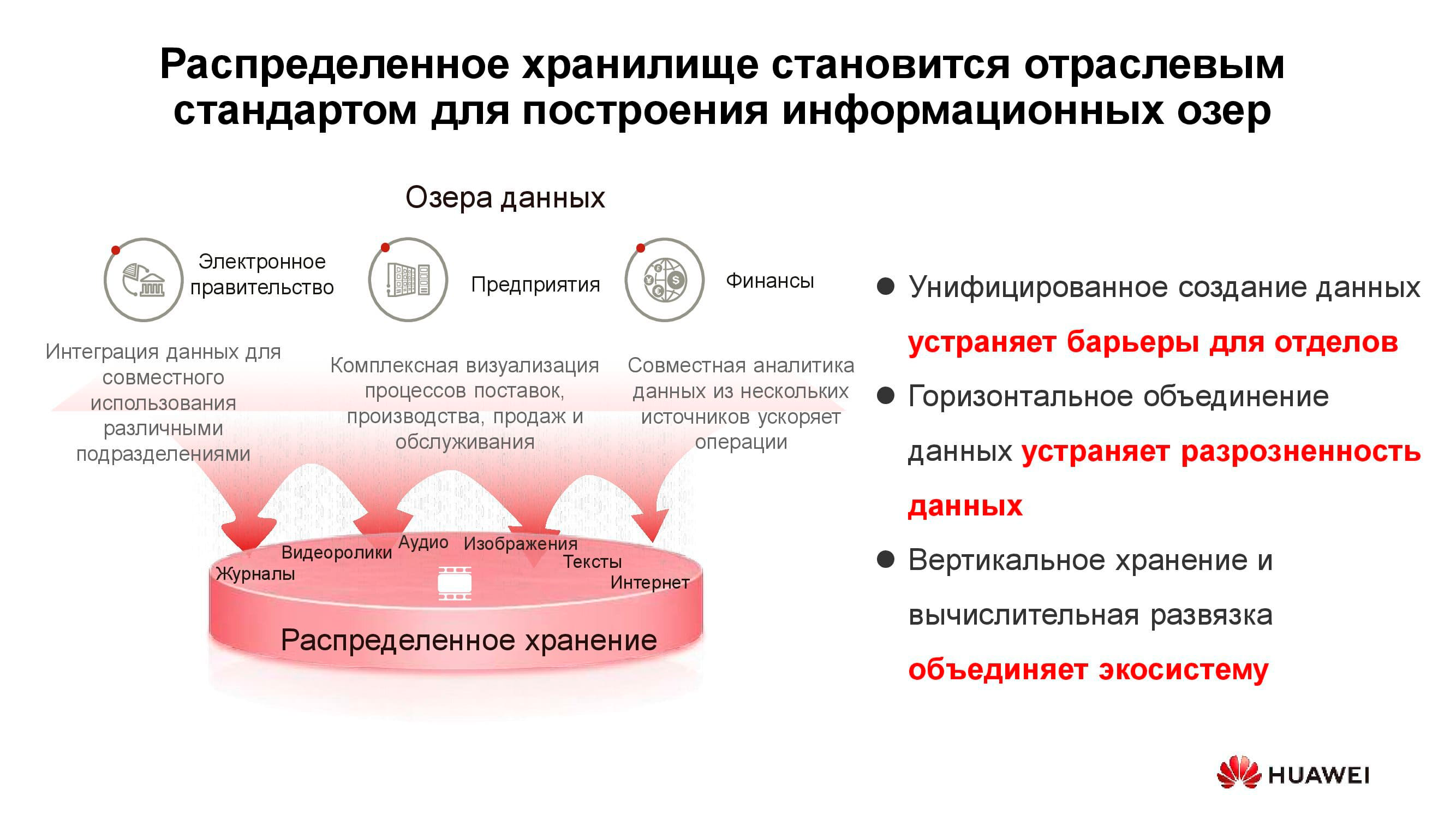
Datenseen
Das obige Diagramm zeigt eine Liste typischer Verbraucher von Data Lake- Diensten . Dies können E-Government-Dienste (z. B. "Gosuslugi"), digitalisierte Unternehmen, Finanzstrukturen usw. sein. Alle müssen mit großen Mengen heterogener Informationen arbeiten.
Der Betrieb klassischer Speichersysteme zur Lösung solcher Probleme ist ineffektiv, da sowohl ein Hochleistungszugriff auf Blockdatenbanken als auch ein regelmäßiger Zugriff auf Bibliotheken gescannter Dokumente, die als Objekte gespeichert sind, erforderlich sind. Dies kann beispielsweise auch ein Bestellsystem über ein Webportal verknüpfen. Um all dies auf einer klassischen Speicherplattform zu implementieren, benötigen Sie eine große Anzahl von Geräten für verschiedene Aufgaben. Ein horizontales universelles Speichersystem kann durchaus alle zuvor aufgeführten Aufgaben abdecken: Sie müssen lediglich mehrere Pools mit unterschiedlichen Speichereigenschaften erstellen.

Generatoren neuer Informationen
Die Menge der weltweit gespeicherten Informationen wächst jährlich um etwa 30%. Dies sind gute Nachrichten für Speicheranbieter, aber was ist und bleibt die Hauptquelle für diese Daten?
Vor zehn Jahren wurden soziale Netzwerke zu solchen Generatoren, für die eine Vielzahl neuer Algorithmen, Hardwarelösungen usw. entwickelt werden mussten. Jetzt gibt es drei Haupttreiber für das Wachstum des Speichervolumens. Das erste ist Cloud Computing. Derzeit nutzen etwa 70% der Unternehmen Cloud-Dienste auf die eine oder andere Weise. Dies können E-Mail-Systeme, Backups und andere virtualisierte Entitäten sein.
Der zweite Treiber sind Netzwerke der fünften Generation. Dies sind neue Geschwindigkeiten und neue Datenübertragungsvolumina. Wir gehen davon aus, dass die weit verbreitete Einführung von 5G zu einem Rückgang der Nachfrage nach Flash-Speicherkarten führen wird. Unabhängig davon, wie viel Speicher im Telefon vorhanden ist, ist der Speicher immer noch leer. Wenn das Gadget einen 100-Megabit-Kanal enthält, müssen keine Fotos lokal gespeichert werden.
Die dritte Gruppe von Gründen für die wachsende Nachfrage nach Speichersystemen sind die rasche Entwicklung der künstlichen Intelligenz, der Übergang zur Big-Data-Analyse und der Trend zur universellen Automatisierung von allem, was möglich ist.
Ein Merkmal des "neuen Verkehrs" ist seine Unstrukturiertheit... Wir müssen diese Daten speichern, ohne ihr Format anzugeben. Es ist nur für das spätere Lesen erforderlich. Ein Bank-Scoring-System zur Ermittlung des verfügbaren Kreditbetrags überprüft beispielsweise die Fotos, die Sie in sozialen Netzwerken veröffentlicht haben, um festzustellen, ob Sie häufig das Meer und Restaurants besuchen, und untersucht gleichzeitig die Auszüge aus Ihren medizinischen Dokumenten, die ihm zur Verfügung stehen. Diese Daten sind einerseits allumfassend und andererseits nicht einheitlich.

Ein Ozean unstrukturierter Daten
Welche Probleme bringt die Entstehung "neuer Daten" mit sich? Das wichtigste unter ihnen ist natürlich die Informationsmenge selbst und die geschätzte Speicherzeit. Ein modernes autonomes Auto allein ohne Fahrer generiert täglich bis zu 60 TB Daten aus all seinen Sensoren und Mechanismen. Um neue Bewegungsalgorithmen zu entwickeln, müssen diese Informationen am selben Tag verarbeitet werden, da sie sich sonst ansammeln. Darüber hinaus sollte es sehr lange gelagert werden - zig Jahre. Nur dann wird es in Zukunft möglich sein, aus großen analytischen Proben Schlussfolgerungen zu ziehen.
Ein genetisches Sequenzierungsgerät erzeugt ungefähr 6 TB pro Tag. Und die mit seiner Hilfe gesammelten Daten bedeuten überhaupt keine Löschung, dh sie sollten hypothetisch für immer gespeichert werden.
Schließlich alle die gleichen Netzwerke der fünften Generation. Zusätzlich zu den tatsächlich übertragenen Informationen ist ein solches Netzwerk selbst ein riesiger Datengenerator: Aktionsprotokolle, Anrufaufzeichnungen, Zwischenergebnisse von Maschinen-zu-Maschinen-Interaktionen usw.
All dies erfordert die Entwicklung neuer Ansätze und Algorithmen zum Speichern und Verarbeiten von Informationen. Und solche Ansätze erscheinen.
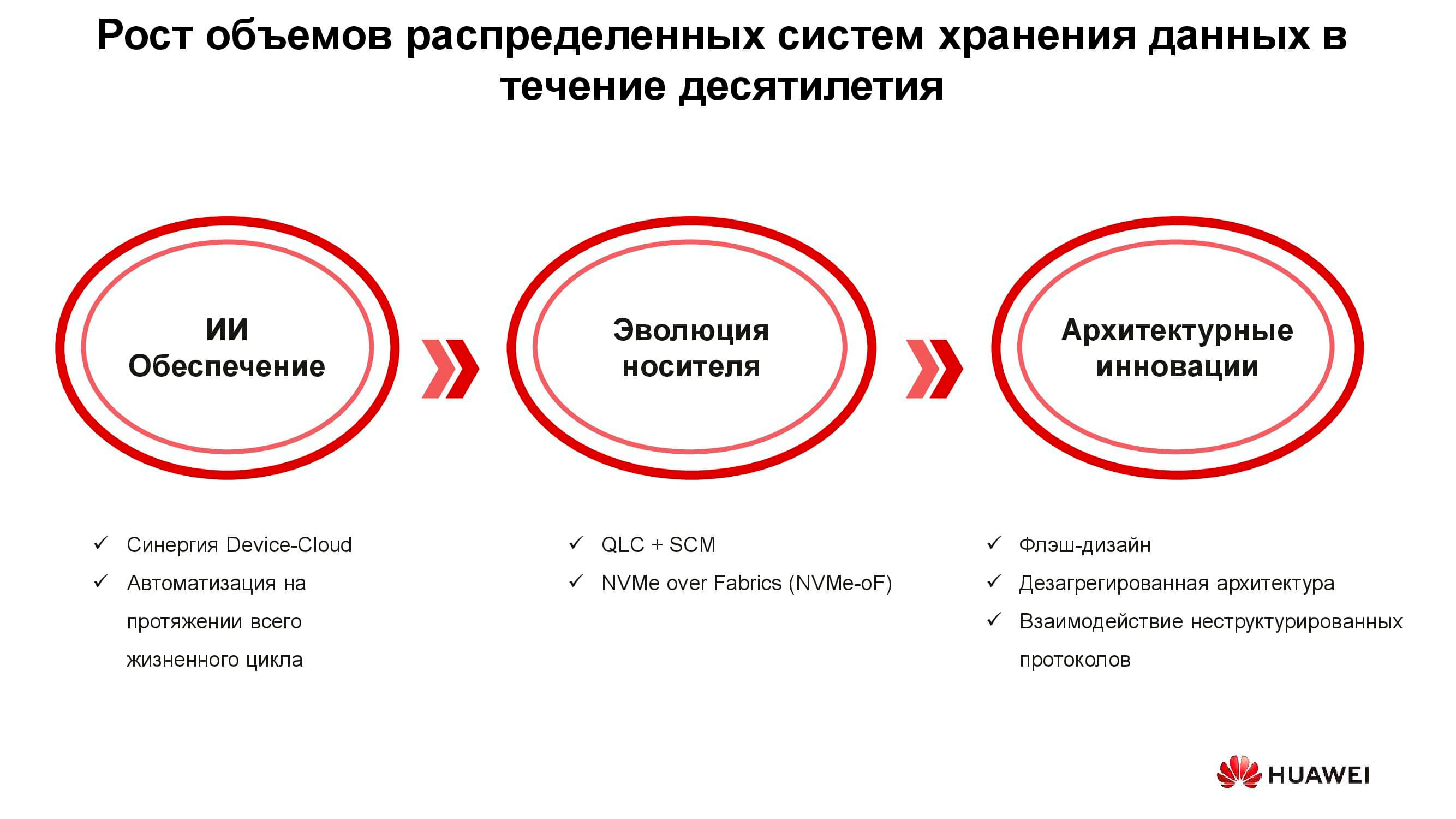
Technologien einer neuen Ära
Es gibt drei Gruppen von Lösungen, die den neuen Anforderungen an Informationsspeichersysteme gerecht werden: die Einführung künstlicher Intelligenz, die technische Entwicklung von Speichermedien und Innovationen auf dem Gebiet der Systemarchitektur. Beginnen wir mit AI.

In neuen Huawei-Lösungen wird künstliche Intelligenz bereits auf der Ebene des Speichers selbst verwendet, der mit einem AI-Prozessor ausgestattet ist, mit dem das System seinen Status unabhängig analysieren und Fehler vorhersagen kann. Wenn das Speichersystem mit einer Service-Cloud verbunden ist, die über erhebliche Rechenkapazitäten verfügt, kann künstliche Intelligenz mehr Informationen verarbeiten und die Genauigkeit ihrer Hypothesen verbessern.
Zusätzlich zu Ausfällen kann eine solche KI zukünftige Spitzenlasten und die verbleibende Zeit bis zur Erschöpfung der Kapazität vorhersagen. Auf diese Weise können Sie die Leistung optimieren und das System skalieren, noch bevor unerwünschte Ereignisse auftreten.

Nun zur Entwicklung der Datenträger. Die ersten Flash-Laufwerke wurden mit der SLC-Technologie (Single-Level Cell) hergestellt. Die darauf basierenden Geräte waren schnell, zuverlässig, stabil, hatten aber eine geringe Kapazität und waren sehr teuer. Die Steigerung des Volumens und der Preissenkung wurde durch bestimmte technische Zugeständnisse erreicht, wodurch die Geschwindigkeit, Zuverlässigkeit und Lebensdauer der Antriebe verringert wurden. Der Trend wirkte sich jedoch nicht auf die Speichersysteme selbst aus, die aufgrund verschiedener Architekturtricks im Allgemeinen sowohl produktiver als auch zuverlässiger geworden sind.
Aber warum brauchten Sie All-Flash-Speichersysteme? War es nicht genug, die alten Festplatten in einem bereits verwendeten System einfach durch neue SSDs mit demselben Formfaktor zu ersetzen? Dies war erforderlich, um alle Ressourcen neuer Solid-State-Laufwerke effektiv zu nutzen, was in alten Systemen einfach unmöglich war.
Huawei hat zum Beispiel eine Reihe von Technologien entwickelt, um dieser Herausforderung zu begegnen. Eine davon ist FlashLink , das die Interaktion zwischen Festplatte und Controller maximiert.
Die intelligente Identifizierung ermöglichte es, Daten in mehrere Ströme zu zerlegen und eine Reihe unerwünschter Phänomene wie WA (Schreibverstärkung) zu bewältigen . Gleichzeitig neue Wiederherstellungsalgorithmen, insbesondere RAID 2.0+erhöhte die Geschwindigkeit des Wiederaufbaus und reduzierte die Zeit auf völlig unbedeutende Werte.
Ausfall, Überfüllung, "Speicherbereinigung" - diese Faktoren wirken sich dank einer speziellen Modifikation der Steuerungen auch nicht mehr auf die Leistung des Speichersystems aus.
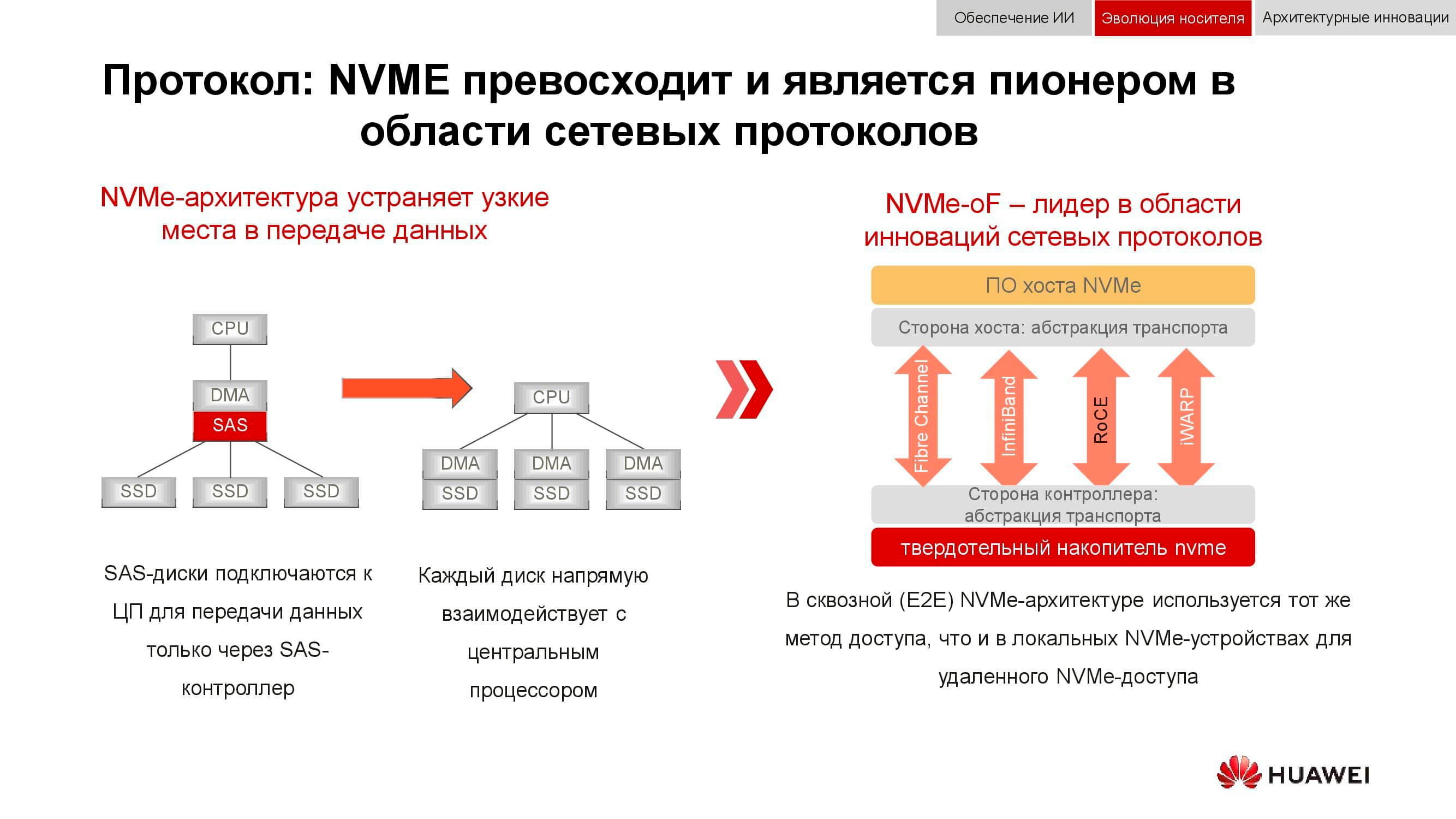
Und die Blockdatenspeicherung bereitet sich auf NVMe vor . Denken Sie daran, dass das klassische Schema zur Organisation des Datenzugriffs wie folgt funktioniert hat: Der Prozessor hat über den PCI Express-Bus auf den RAID-Controller zugegriffen. Dies wiederum interagierte mit mechanischen Festplatten über SCSI oder SAS. Die Verwendung von NVMe im Backend beschleunigte den gesamten Prozess erheblich, hatte jedoch einen Nachteil: Die Laufwerke mussten direkt mit dem Prozessor verbunden werden, um direkten Zugriff auf den Speicher zu ermöglichen.
Die nächste Phase der Technologieentwicklung, die wir jetzt sehen, ist die Verwendung von NVMe-oF (NVMe over Fabrics). Die Huawei-Blocktechnologien unterstützen bereits FC-NVMe (NVMe über Fibre Channel) und NVMe über RoCE (RDMA über Converged Ethernet). Die Testmodelle sind recht funktionsfähig, einige Monate verbleiben vor ihrer offiziellen Präsentation. Beachten Sie, dass all dies auch in verteilten Systemen auftritt, in denen "verlustfreies Ethernet" sehr gefragt ist.
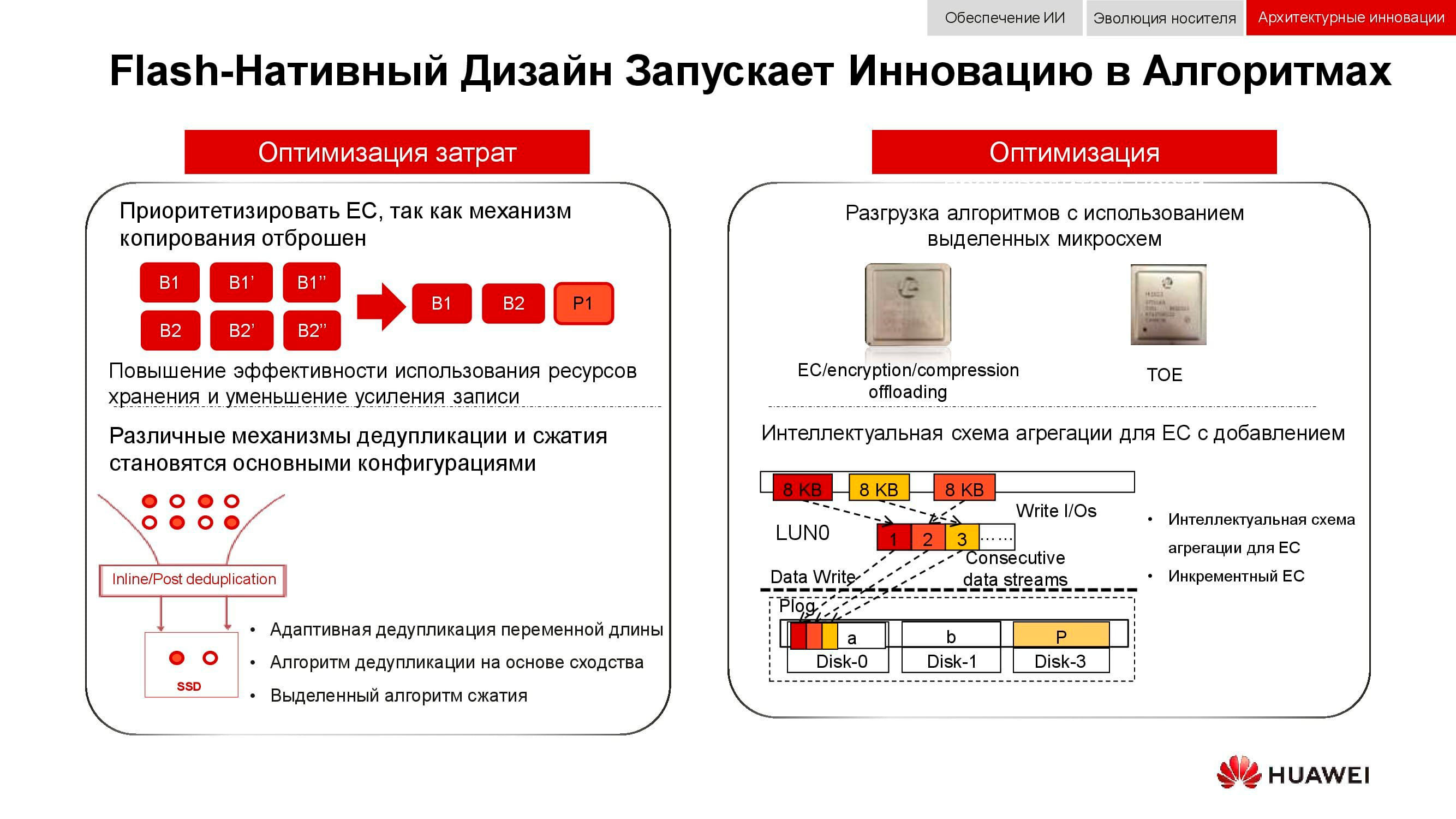
Eine zusätzliche Möglichkeit, die Arbeit des verteilten Speichers zu optimieren, ist die vollständige Ablehnung der Datenspiegelung. Huawei-Lösungen verwenden nicht mehr n Kopien wie beim üblichen RAID 1 und wechseln vollständig zum EC- Mechanismus(Löschcodierung). Ein spezielles mathematisches Paket mit einer bestimmten Häufigkeit berechnet Steuerblöcke, mit denen Sie bei Verlust Zwischendaten wiederherstellen können.
Deduplizierungs- und Komprimierungsmechanismen werden immer obligatorischer. Wenn wir in klassischen Speichersystemen durch die Anzahl der in Controllern installierten Prozessoren begrenzt sind, enthält jeder Knoten in verteilten Scale-Out-Speichersystemen alles, was Sie benötigen: Festplatten, Speicher, Prozessoren und Interconnect. Diese Ressourcen reichen aus, damit Deduplizierung und Komprimierung nur minimale Auswirkungen auf die Leistung haben.
Und über Hardwareoptimierungsmethoden. Hier konnte die Belastung der Zentralprozessoren mithilfe zusätzlicher dedizierter Mikroschaltungen (oder dedizierter Blöcke im Prozessor selbst), die die Rolle des EVG spielen, reduziert werden(TCP / IP Offload Engine) oder Übernahme der mathematischen Probleme von EC, Deduplizierung und Komprimierung.
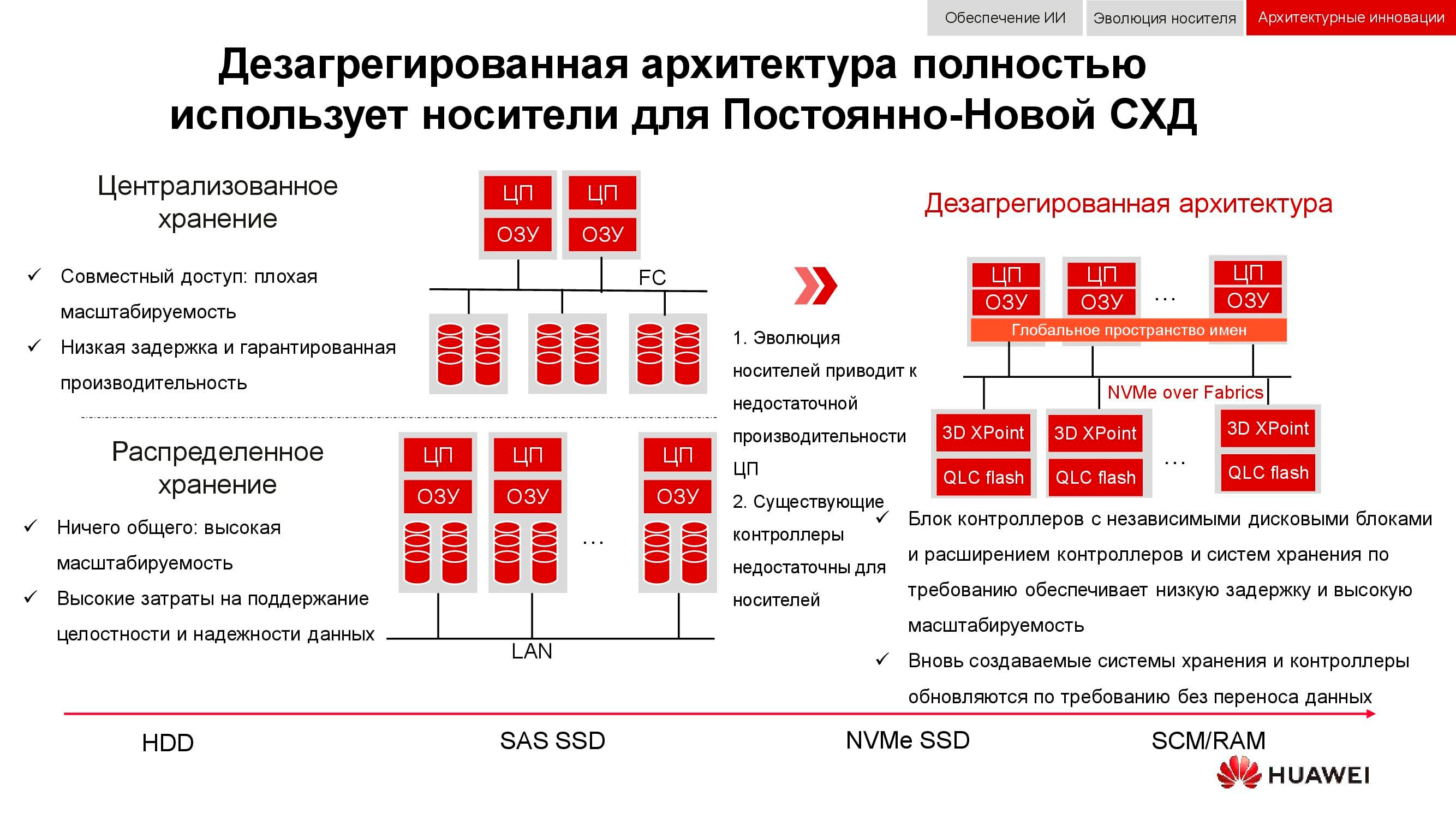
Neue Ansätze zur Datenspeicherung sind in einer disaggregierten (verteilten) Architektur enthalten. In zentralisierten Speichersystemen gibt es eine Serverfabrik, die über Fibre Channel mit einem SAN mit einer großen Anzahl von Arrays verbunden ist. Die Nachteile dieses Ansatzes sind die Schwierigkeiten bei der Skalierung und Bereitstellung garantierter Service-Levels (Leistung oder Latenz). Hyperkonvergierte Systeme verwenden dieselben Hosts zum Speichern und Verarbeiten von Informationen. Dies bietet praktisch unbegrenzte Skalierbarkeit, ist jedoch mit hohen Kosten für die Aufrechterhaltung der Datenintegrität verbunden.
Im Gegensatz zu beiden oben genannten impliziert eine disaggregierte Architektur die Trennung des Systems in eine Rechenstruktur und ein horizontales Speichersystem . Dies bietet die Vorteile beider Architekturen und ermöglicht es Ihnen, nahezu unbegrenzt nur auf das Element zu skalieren, dem die Leistung fehlt.
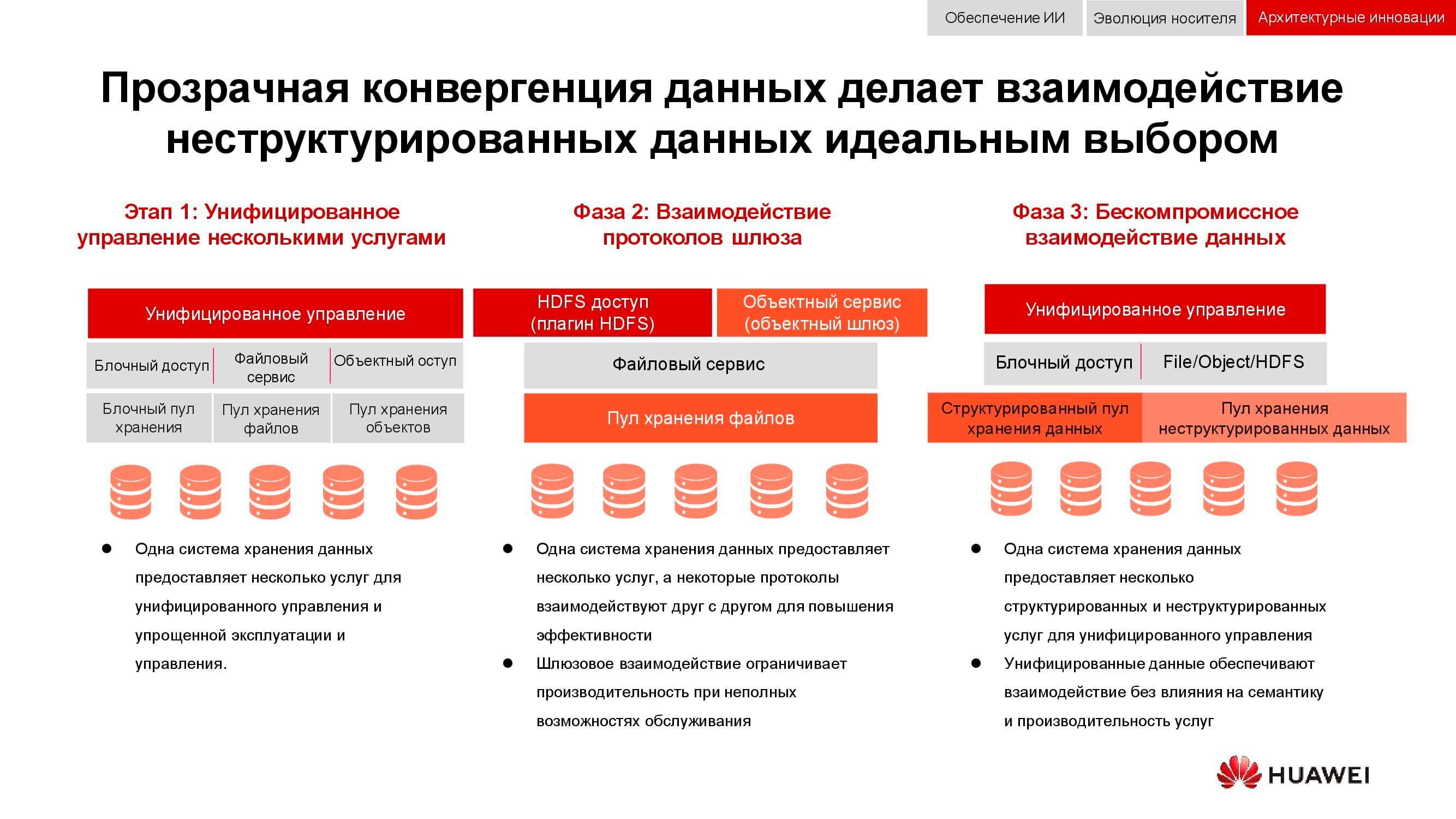
Von der Integration zur Konvergenz
Eine klassische Aufgabe, deren Relevanz erst in den letzten 15 Jahren zugenommen hat, ist die Notwendigkeit, gleichzeitig Blockspeicher, Dateizugriff, Zugriff auf Objekte, Farmbetrieb für Big Data usw. bereitzustellen. Die Kirsche auf dem Kuchen kann beispielsweise auch ein Backup-System für Magnetbänder sein.
In der ersten Phase war es nur möglich, die Verwaltung dieser Dienste zu vereinheitlichen. Heterogene Datenspeichersysteme wurden in eine spezielle Software eingebunden, über die der Administrator Ressourcen aus den verfügbaren Pools zuordnete. Da sich diese Pools in der Hardware unterschieden, war eine Migration der Last zwischen ihnen unmöglich. Auf einer höheren Integrationsebene fand die Konsolidierung auf Gateway-Ebene statt. Wenn es einen gemeinsamen Dateizugriff gab, konnte dieser über verschiedene Protokolle erfolgen.
Die fortschrittlichste Konvergenzmethode, die uns jetzt zur Verfügung steht, ist die Schaffung eines universellen Hybridsystems. Genau das, was unser OceanStor 100D sein sollte . Die Barrierefreiheit verwendet dieselben Hardwareressourcen, die logisch in verschiedene Pools unterteilt sind, jedoch eine Workload-Migration ermöglichen. All dies kann über eine einzige Verwaltungskonsole erfolgen. Auf diese Weise ist es uns gelungen, das Konzept "ein Rechenzentrum - ein Speichersystem" umzusetzen.
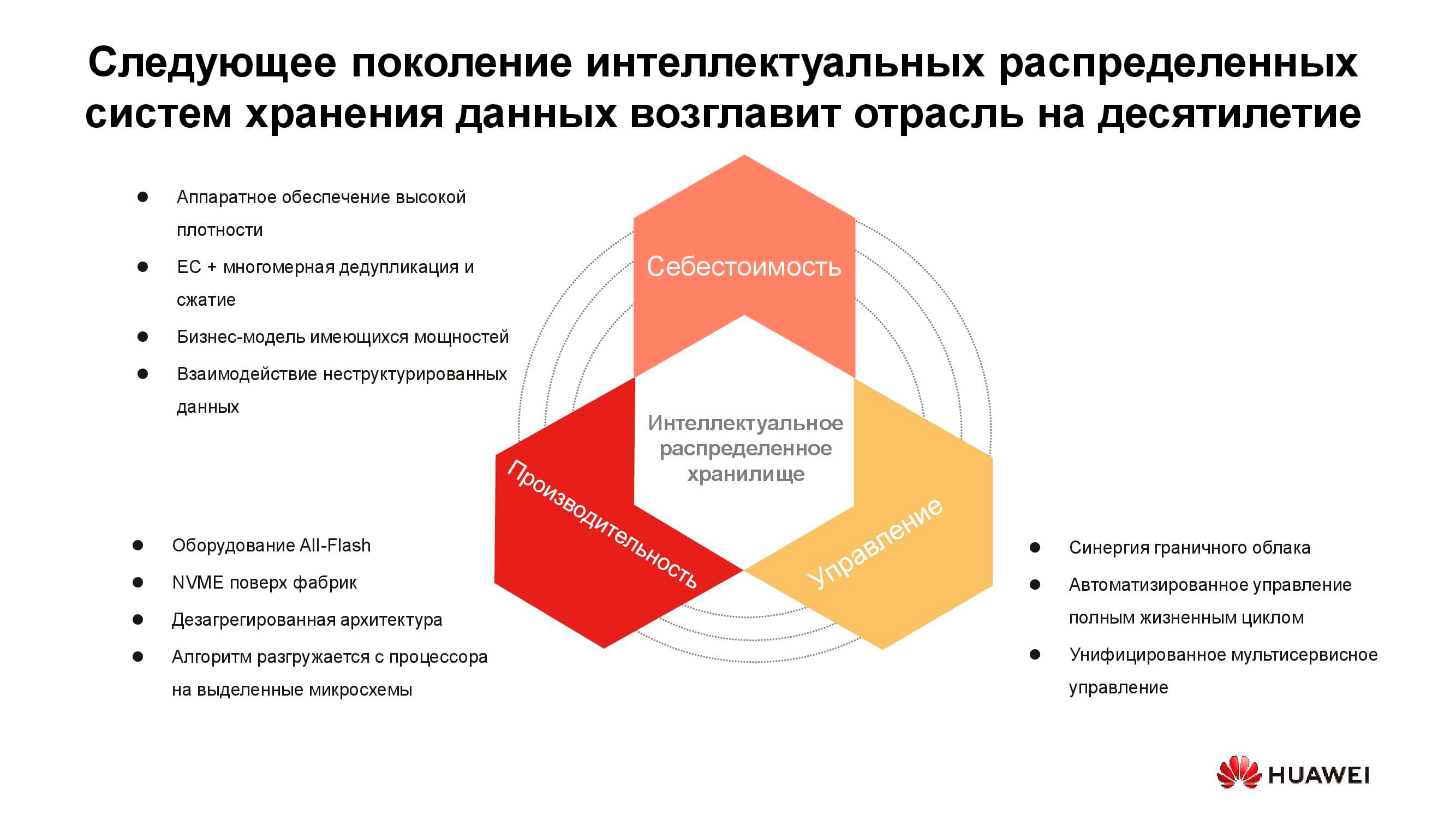
Die Kosten für das Speichern von Informationen bestimmen jetzt viele Architekturentscheidungen. Und obwohl es sicher in den Vordergrund gerückt werden kann, diskutieren wir heute über Live-Speicher mit aktivem Zugriff, daher muss auch die Leistung berücksichtigt werden. Eine weitere wichtige Eigenschaft verteilter Systeme der nächsten Generation ist die Vereinheitlichung. Schließlich möchte niemand, dass mehrere unterschiedliche Systeme von verschiedenen Konsolen aus verwaltet werden. All diese Eigenschaften sind in der neuen Serie von Huawei OceanStor Pacific- Produkten enthalten .
Massenspeicher einer neuen Generation
OceanStor Pacific erfüllt die Anforderungen an die Zuverlässigkeit auf der Ebene von "sechs Neunen" (99,9999%) und kann zum Erstellen von Rechenzentren der HyperMetro-Klasse verwendet werden. Mit einer Entfernung von bis zu 100 km zwischen zwei Rechenzentren weisen die Systeme eine zusätzliche Verzögerung von 2 ms auf, die es ermöglicht, auf ihrer Basis alle katastrophenresistenten Lösungen zu erstellen, einschließlich solcher mit Quorum-Servern.
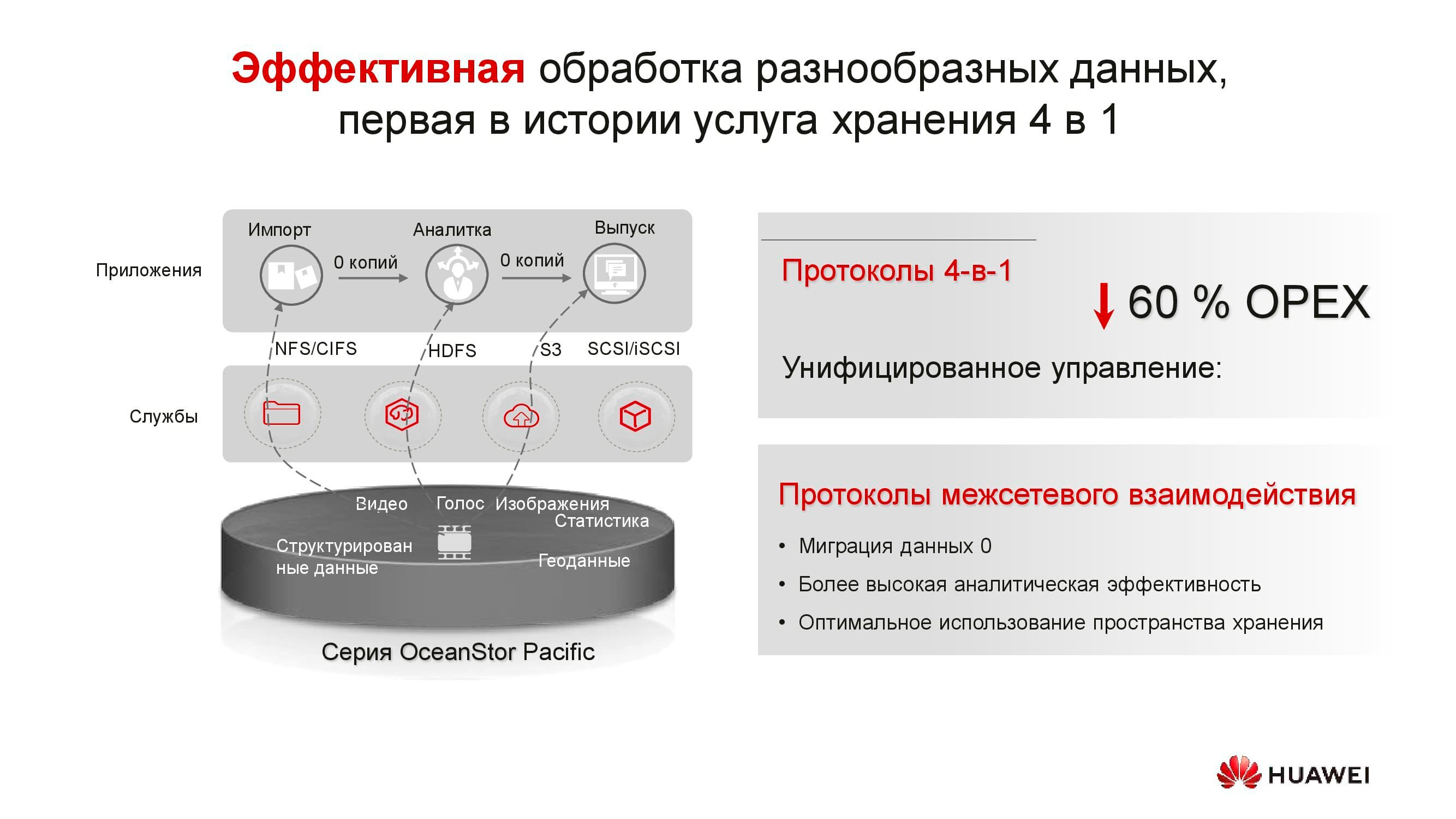
Die Produkte der neuen Serie demonstrieren die Vielseitigkeit des Protokolls. OceanStor 100D unterstützt bereits Blockzugriff, Objektzugriff und Hadoop-Zugriff. Der Dateizugriff wird in naher Zukunft ebenfalls implementiert. Es ist nicht erforderlich, mehrere Kopien der Daten aufzubewahren, wenn diese über verschiedene Protokolle übermittelt werden können.
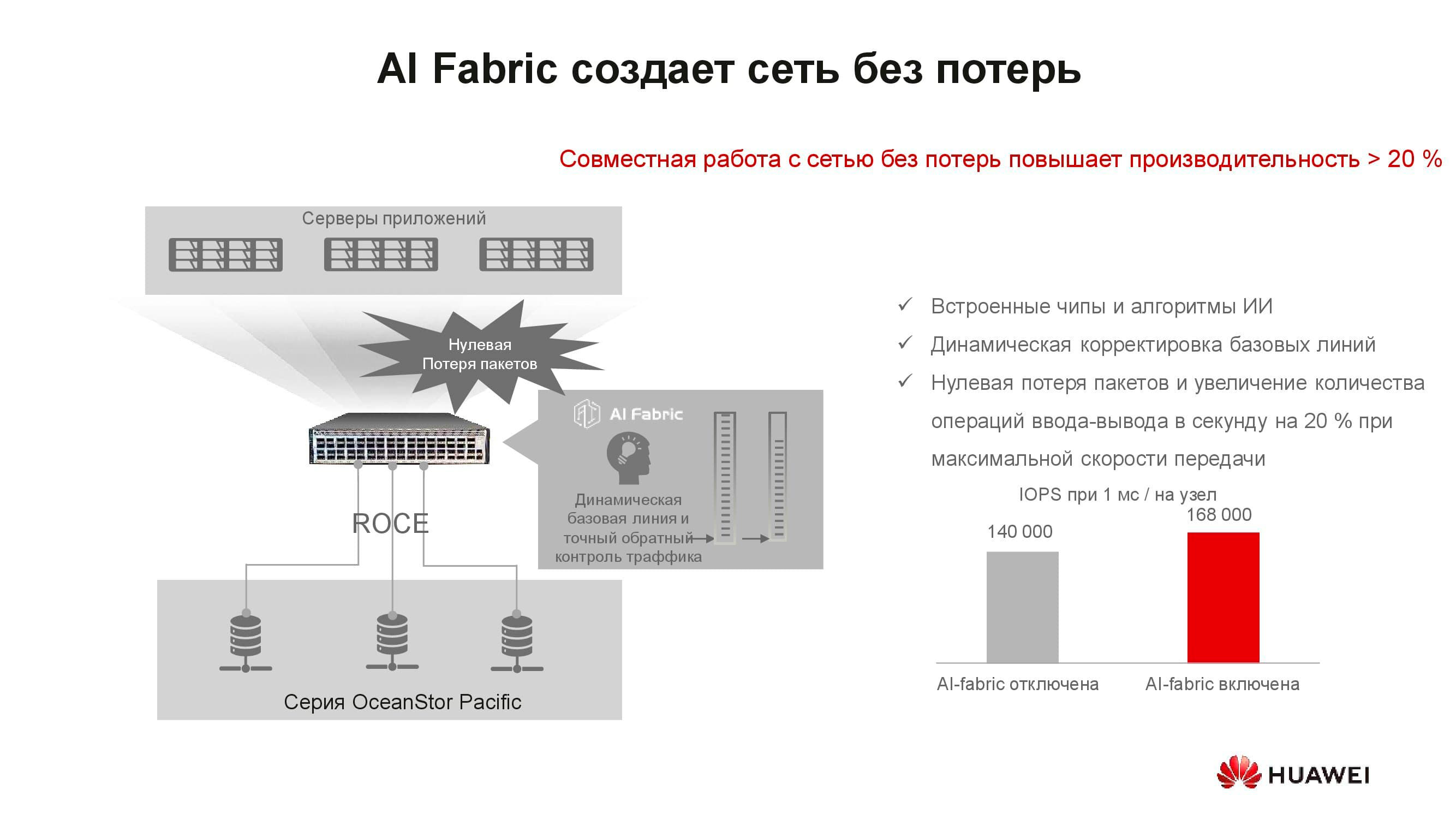
Was hat das Konzept eines "verlustfreien Netzwerks" mit Speicher zu tun? Tatsache ist, dass verteilte Speichersysteme auf der Basis eines schnellen Netzwerks aufgebaut sind, das die entsprechenden Algorithmen und den RoCE-Mechanismus unterstützt. Die von unseren Switches unterstützte AI-Struktur hilft, die Netzwerkgeschwindigkeit weiter zu erhöhen und die Latenz zu verringern . Die Steigerung der Speicherleistung durch die Aktivierung von AI Fabric kann bis zu 20% betragen.
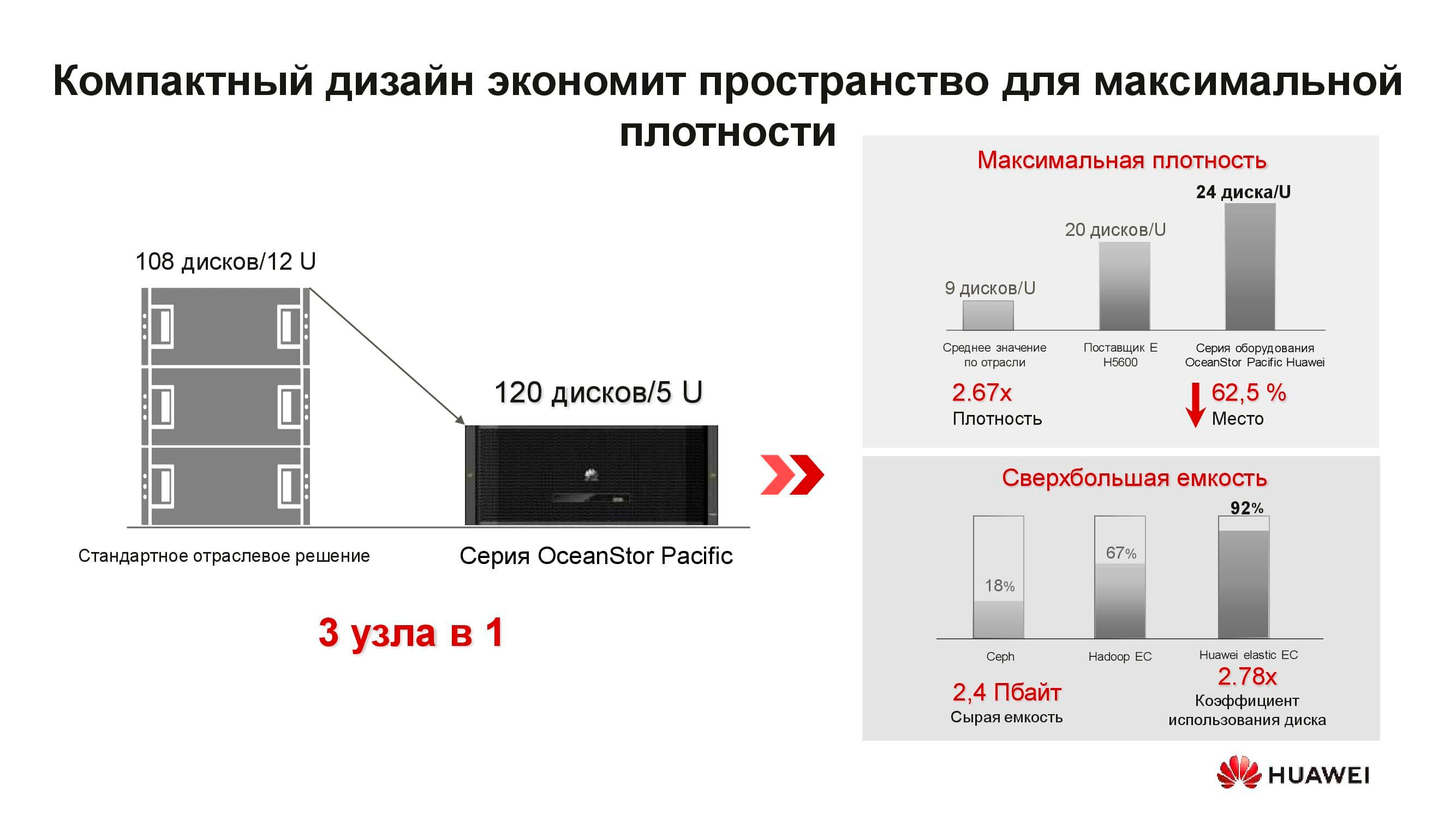
Was ist der neue verteilte OceanStor Pacific-Speicherknoten? Die 5U-Lösung umfasst 120 Laufwerke und kann drei klassische Knoten ersetzen, was mehr als das Zweifache des Rack-Platzes spart. Aufgrund der Weigerung, Kopien zu speichern, steigt die Effizienz von Laufwerken erheblich (bis zu + 92%).
Wir sind daran gewöhnt, dass SDS eine spezielle Software ist, die auf einem klassischen Server installiert ist. Um nun optimale Parameter zu erreichen, erfordert diese Architekturlösung nun auch spezielle Knoten. Es besteht aus zwei Servern, die auf ARM-Prozessoren basieren und ein Array von 3-Zoll-Laufwerken verwalten.
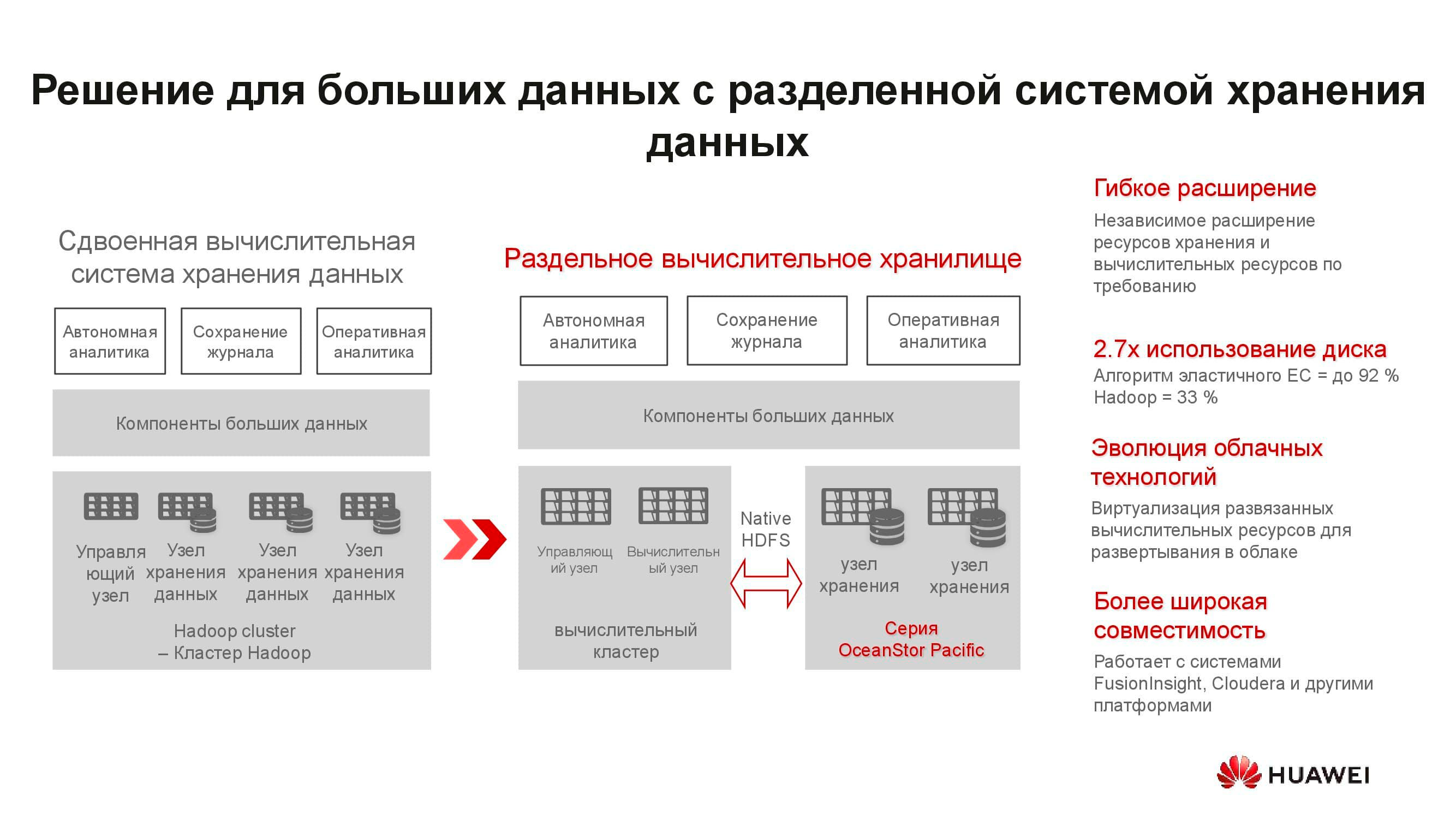
Diese Server sind für hyperkonvergente Lösungen schlecht geeignet. Erstens gibt es nur wenige Anwendungen für ARM, und zweitens ist es schwierig, den Lastausgleich aufrechtzuerhalten. Wir schlagen vor, auf einen separaten Speicher umzusteigen: Ein Computercluster, der durch klassische oder Rack-Server dargestellt wird, arbeitet separat, stellt jedoch eine Verbindung zu OceanStor Pacific-Speicherknoten her, die auch ihre direkten Aufgaben ausführen. Und es rechtfertigt sich.
Nehmen wir zum Beispiel eine klassische hyperkonvergente Big-Data-Speicherlösung, die 15 Server-Racks belegt. Durch die Trennung der Arbeitslast zwischen einzelnen Computerservern und OceanStor Pacific-Speicherknoten und deren Trennung wird die Anzahl der erforderlichen Racks halbiert! Dies reduziert die Betriebskosten des Rechenzentrums und die Gesamtbetriebskosten. In einer Welt, in der das Volumen der gespeicherten Informationen um 30% pro Jahr wächst, sind solche Vorteile nicht verstreut.
***.
Weitere Informationen zu Huawei-Lösungen und -Szenarien für deren Verwendung erhalten Sie auf unserer Website oder indem Sie sich direkt an die Unternehmensvertreter wenden.