- Worüber werden wir genau sprechen? Nicht über primitive Auswahlen und Verknüpfungen - ich denke, die meisten von Ihnen kennen sie bereits.
Wir werden über die tatsächliche Verwendung von Datenbanken sprechen, welche Schwierigkeiten Sie haben können und was Sie als Backend-Entwickler wissen müssen. Es wird viele Informationen geben, hier ist der Inhalt. Sie müssen die Details jedes dieser Punkte nicht direkt und gründlich kennen, aber Sie müssen wissen, dass dieser Punkt vorhanden ist.

Und Sie müssen wissen, wie welche Probleme gelöst werden, damit Sie wissen, welches Datenmodell Sie auswählen und wie Sie es speichern müssen, wenn Sie eine Aufgabe zum Erstellen einer Struktur und zum Speichern von Daten haben. Oder nehmen wir an, Sie haben ein Problem, Sie sehen, dass die Datenbank ausgefallen ist, langsam ist oder Sie Datenprobleme haben, Inkonsistenz. Dann muss man verstehen, wo man gräbt. Das heißt, Sie müssen wissen, welche Konzepte existieren und von welcher Seite aus Sie die Probleme angehen können.

Zuerst werden wir über Daten sprechen. Was ist das überhaupt? Es gibt viele Fakten um uns herum, viele Informationen, aber bis sie in irgendeiner Weise gesammelt wurden, sind sie für uns nutzlos. Wir sammeln, strukturieren und lagern sie. Und diese gespeicherte Strukturierung wird als Daten bezeichnet, und was sie speichert, wird als Datenbank bezeichnet. Solange diese Daten aber nur irgendwo gesammelt werden, sind sie für uns grundsätzlich nutzlos. Daher befindet sich über den Datenbanken eine Ebene - das DBMS. Auf diese Weise können wir Daten abrufen, speichern und analysieren. So wandeln wir die empfangenen Daten in Informationen um, die wir dem Benutzer bereits anzeigen können. Der Benutzer gewinnt Wissen und wendet es an.

Wir werden diskutieren, wie Informationen und Fakten strukturiert, in welcher Form von Daten und in welchem Modell gespeichert werden können. Und wie man sie erhält, damit viele Benutzer gleichzeitig auf die Daten zugreifen und das richtige Ergebnis erhalten können, damit unser endgültiges Wissen, das wir anwenden werden, wahr und richtig ist.

Zunächst werden wir über relationale Datenbanken sprechen. Ich denke, das Beziehungsmodell ist vielen von Ihnen vertraut. Es ist ein Modell für die Art der Tabellen und die Beziehungen zwischen Tabellen. Stellen Sie sich vor, wir haben einen Messenger, in dem wir Daten und Nachrichten zwischen Benutzern schreiben. Wir können sie alle in eine so große, umfangreiche Tabelle schreiben, in der wir viele sich wiederholende Daten haben - von wem, wer, zu wem, in welchem Chat. Und wir können dies alles in verschiedene Tabellen schreiben, dh unsere Daten normalisieren und in die dritte Normalform bringen.
Auf den Folien befinden sich Hinweise und Verweise. Wir werden jetzt nicht auf jedes Konzept eingehen. Ich werde versuchen, nicht über technische Konzepte zu sprechen, die Ihnen möglicherweise unbekannt sind. Aber alles, was ich sage, finden Sie in den Foliennotizen. Inklusive Normalisierung gibt es auch eine Referenz, die Sie lesen können, wenn Sie mit diesem Konzept nicht vertraut sind.

Im Allgemeinen ist Normalisierung die Aufteilung von Daten in Tabellen mit dem Ziel, die Daten strukturierter zu gestalten. Zum Beispiel gibt es jetzt eine Tabelle mit Benutzern, Messenger-Chat und Nachrichten. Diese Struktur stellt sicher, dass Nachrichten von genau den Benutzern, die wir kennen, und von den Chats, die wir kennen, hier aufgezeichnet werden. Das heißt, wir stellen die Datenintegrität sicher. Wir sorgen dafür, dass wir immer das ganze Bild sammeln können. Gleichzeitig speichern wir beispielsweise in der Nachrichtentabelle nur IDs, nur Bezeichner. Daher reduzieren wir die Gesamtgröße der Datenbank und verkleinern sie. Dementsprechend erleichtern wir das Schreiben in diese Datenbank. Wir müssen nicht ständig in viele Tabellen schreiben. Wir schreiben nur in eine Tabelle mit dem ID-Spezialisten.

Wenn wir über Normalisierung sprechen, vereinfacht dies im Allgemeinen die Sicht des Systems erheblich, da es sehr grafisch ist und uns sofort klar wird, welche Beziehungen wir zwischen welchen Tabellen haben.
Wir reduzieren die Anzahl der Fehler beim Schreiben von Daten, denn wenn wir eine Nachricht in den Messenger schreiben und noch keinen solchen Benutzer haben, müssen wir einen erstellen. Das endgültige Bild, die allgemeinen Daten, bleiben jedoch vollständig.
Ich habe bereits über die Reduzierung der Größe der Datenbank gesagt. Wir müssen nicht jedes Mal alle Daten über den Benutzer in die Nachrichtentabelle schreiben. Um das Profil anzuzeigen, gehen Sie einfach zur Benutzertabelle.
Ich habe auch vor der inkonsistenten Abhängigkeit gewarnt. Dies sind nur Links zu IDs anderer Tabellen. Bezeichner sind eindeutige Werte innerhalb einer Tabelle. Auf andere Weise werden sie als Primärschlüssel bezeichnet. Wenn wir eine Verknüpfung zu diesen Primärschlüsseln haben, wird die Verknüpfung selbst in einer anderen Tabelle als Fremdschlüssel bezeichnet.
Diese Struktur schützt unsere Daten auch vor versehentlichem Löschen. Wir können einen Benutzer nicht löschen, da er beispielsweise eine Nachricht hat. Dies ist so ein kleines, aber sicheres Netz.
Es scheint, dass wir eine hervorragende Struktur geschaffen haben, alles ist klar, alles ist abhängig, alles ist ganzheitlich. Mit was müssen Sie noch arbeiten?

Stellen wir uns vor, wir haben es tatsächlich in Betrieb genommen, wir haben viele Benutzer und dementsprechend viele Nachrichten. Sie kommunizieren ständig miteinander. Was ist in unserer Nachrichtentabelle los? Es wächst ständig. Und um in Nicht-Daten zu suchen, müssen wir ständig alle Nachrichten durchgehen, prüfen, ob sie von diesem Benutzer stammen oder nicht, in diesem Chat oder nicht, und sie erst dann anzeigen.
Je mehr Benutzer, desto mehr Nachrichten, desto länger dauern natürlich die Suchanfragen. Wir brauchen eine Lösung, mit der wir schnell nach Nachrichten in der Tabelle suchen können.
In einem solchen Fall werden Indizes verwendet, um die Suche zu beschleunigen. Die einfachste Zuordnung zu Indizes ist der Inhalt eines Buches. Wenn Sie Informationen in einem Buch suchen müssen, können Sie einfach durch das Buch blättern oder zum Inhaltsverzeichnis gehen. Indizes sind eine Art Inhaltsverzeichnis.
Es gibt auch ein gutes Beispiel für ein Telefonbuch. Sie können auf Ihrem Telefon auf einen Buchstaben klicken, und Sie werden sofort durch Verweis auf Nachnamen, die mit diesem Buchstaben beginnen, geworfen. Datenbankindizes funktionieren auf sehr ähnliche Weise. Sehen wir uns unsere Tabelle mit Nachrichten an und wie wir diese Daten erhalten.

Bitte achten Sie darauf, wie wir mit Daten arbeiten. Nicht mit welchen Zeilen wir in der Tabelle haben, sondern im Allgemeinen. Indizes werden auf der Grundlage Ihrer Abfragen erstellt.
Stellen wir uns vor, wir stellen hauptsächlich Anfragen per Chat, dh wir finden heraus, welche Nachrichten in diesem Chat enthalten sind. Lassen Sie uns den Index genau in der Chat-Spalte erstellen. Datenbankindizes sind eine separate Struktur. Die Tabelle ist davon unabhängig. Das heißt, Sie können den Index jederzeit löschen und neu erstellen, und die Tabelle leidet nicht darunter.
Hier sehen Sie, dass wir ausgewählt haben, einen Index für die Spalte erstellt haben und eine separate Struktur haben, die die Anzahl der Einträge bereits geringfügig reduziert hat, da bereits mehrere Nachrichten in Chat 11 vorhanden sind. Das DBMS bietet eine schnelle Suche in dieser kleinen Chat-Tabelle. Wie es gemacht wird? Natürlich ist die Suche keine einfache Suche. Es gibt viele schnelle Suchalgorithmen. Wir werden uns einen der beliebtesten Algorithmen ansehen, die standardmäßig in den meisten Datenbanken verwendet werden. Es ist ein ausgeglichener Baum.

Wie funktioniert es? Wir haben eine Chat-Nummer, dies ist ein ganzzahliger Wert, und der Baum wird nach dem folgenden Prinzip erstellt: Was weniger links vom Knoten ist, mehr Werte rechts vom Knoten. Was gibt uns diese Struktur? Wenn Sie sich die Zusammenfassungsblätter dieses Baums ansehen, werden alle Werte unten sortiert. Dies ist ein großes Plus an Produktivitätsgewinnen. Jetzt zeige ich dir warum.
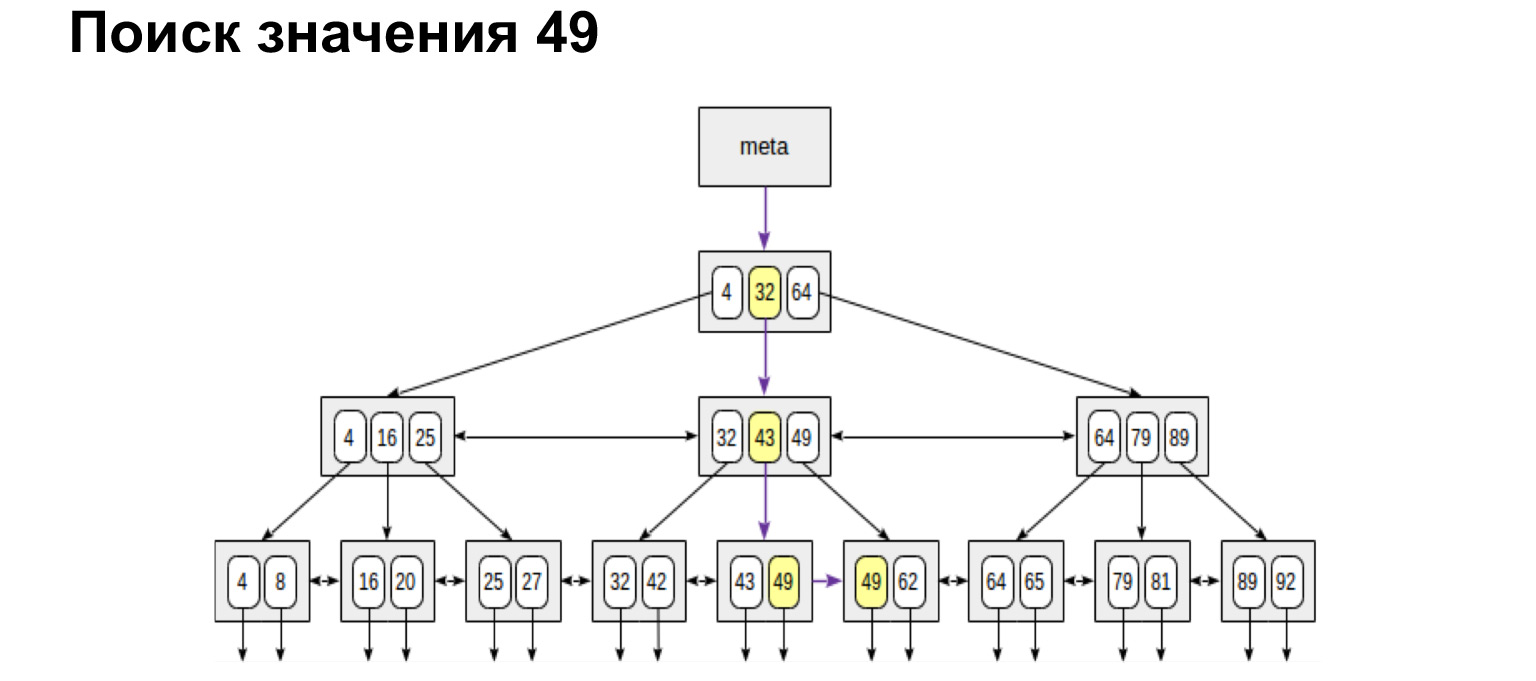
Zum Beispiel suchen wir einen Wert. Es ist sehr einfach, nach einer Bedeutung zu suchen. Wir gehen den Baum hinunter oder nach links, nach rechts - je nachdem, ob dieser Wert größer oder kleiner ist.
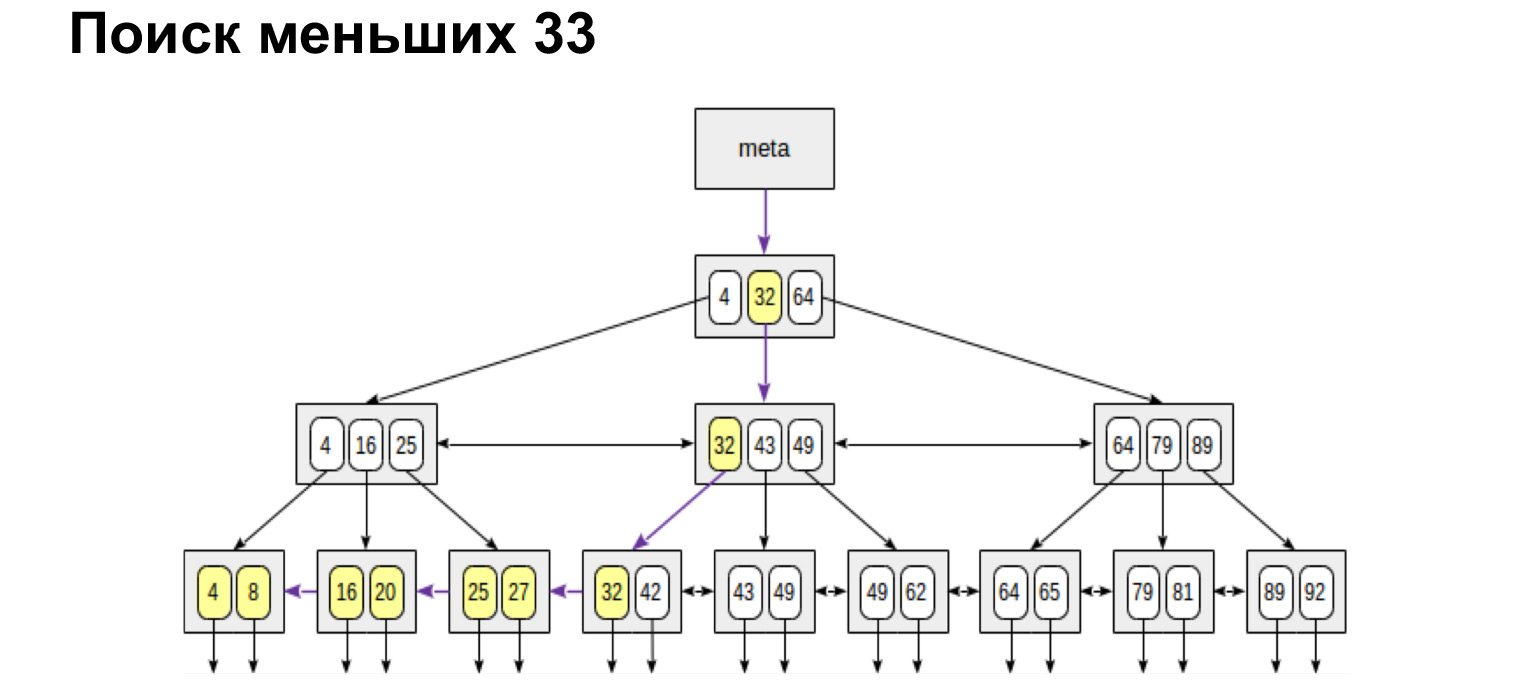
Und wenn wir zum Beispiel einen Bereich finden wollen, dann schauen Sie, wie einfach und schnell er sich herausstellt. Wir erreichen den Wert und folgen dann den Links in den Blättern bereits entlang der geordneten Werte, gehen Sie einfach bis zum Ende.
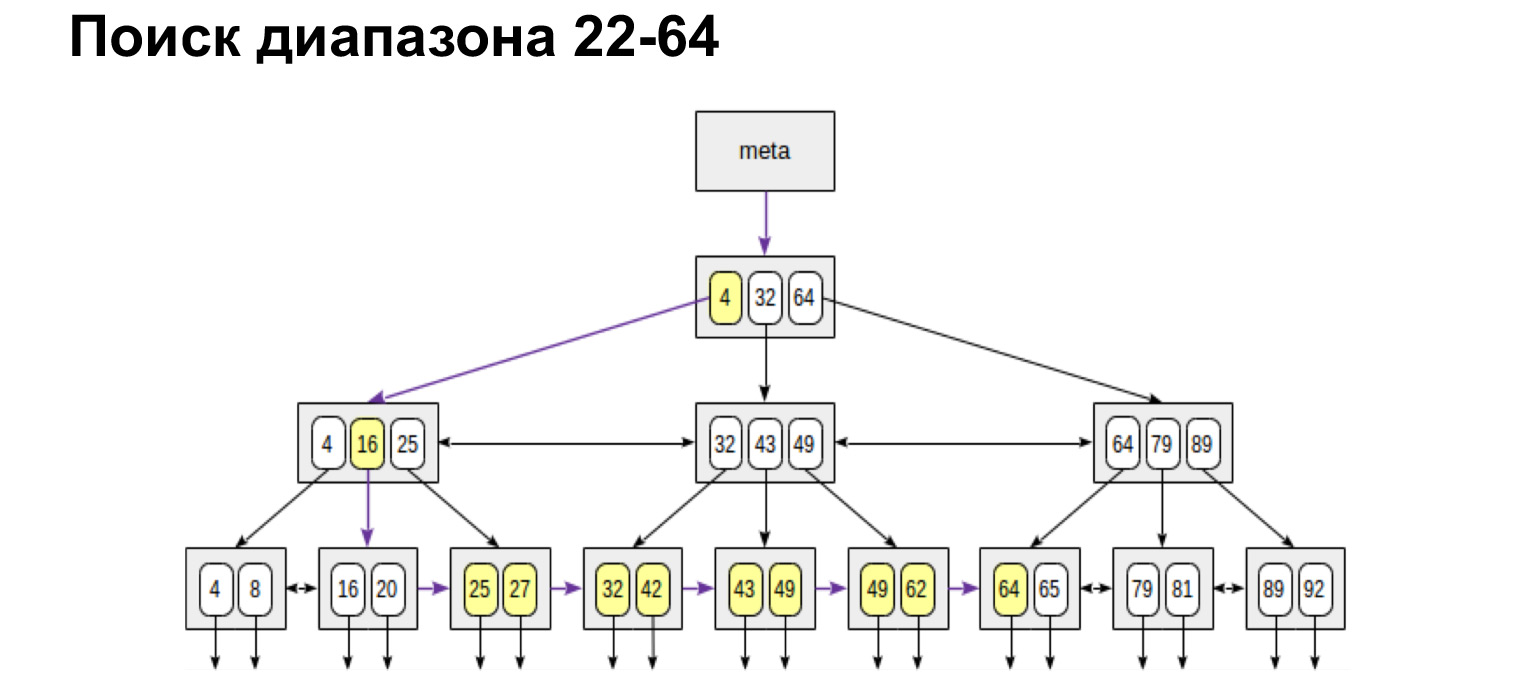
Wenn wir einen Bereich benötigen, der von und bis definiert ist, machen wir genau das Gleiche. Suchen Sie den Anfangswert und folgen Sie den Blattverknüpfungen zum Maximalwert. Wir gingen nur einmal über den Baum. Es ist sehr praktisch, sehr schnell.
Auf die gleiche Weise werden wir nach den Maximal- und Minimalwerten suchen. Gehen Sie ganz nach links, ganz nach rechts. Wir erhalten auch eine bestellte Liste. Das heißt, wenn wir nur alle Chats in einer geordneten Weise erhalten müssen, erreichen wir den ersten und gehen die Blätter bis zum äußersten rechten Wert durch. Wir erhalten eine geordnete Liste. Nach diesem Prinzip sucht die Datenbank in der Indextabelle sehr schnell nach den Zeilen, die wir auswählen müssen, und gibt sie zurück.
Was ist hier wichtig zu wissen? Es scheint eine coole Struktur zu sein - jetzt werden wir für jede Spalte einen solchen Baum erstellen und suchen. Warum denkst du, wird es nicht funktionieren? Warum wird die Geschwindigkeit nicht erhöht, wenn wir für jede Spalte einen Baum erstellen? (...)
Unsere Auswahl wird sich wirklich beschleunigen. Jedes Mal, wenn wir einen Wert überschreiten müssen, gehen wir zum Index und finden dort einen Link zu den Werten selbst. Indizes enthalten normalerweise genau die Verweise auf die Zeichenfolgen, nicht die Zeichenfolgen selbst. Und für die Auswahl funktioniert es perfekt. Sobald wir jedoch Tabellendaten festlegen, Daten aktualisieren oder löschen möchten, müssen alle diese Bäume neu erstellt werden.
In der Tat wird das Löschen nicht neu erstellt, sondern nur diesen Baum fragmentiert, und wir werden am Ende viele leere Werte haben. Es wird einen riesigen Baum mit leeren Werten geben. Mit Update und Create werden diese Bäume jedoch jedes Mal neu erstellt. Infolgedessen erhalten wir einen enormen Overhead für all diese Strukturen. Und anstatt schnell Daten abzurufen und die Datenbank zu beschleunigen, werden wir unsere Abfragen verlangsamen.
Was ist sonst noch wichtig zu wissen? Wenn Sie mit einer Datenbank arbeiten, suchen und lesen Sie, welche Indizes darin vorhanden sind, da jede Datenbank ihre eigenen Implementierungen und ihre eigenen unterschiedlichen Indizes hat. Es gibt Indizes, die beschleunigt werden müssen, es gibt Indizes, um die Integrität sicherzustellen. Einer der einfachsten ist nur der Primärschlüssel. Dies ist auch ein eindeutiger Index. Sehen Sie sich in Bezug auf Ihre Datenbank an, wie sie funktioniert und wie Sie damit arbeiten, denn diese Art von Wissen hilft Ihnen beim Schreiben der optimalsten Abfragen.
Wir haben besprochen, wie der Aufwand für die Verwaltung von Indizes beim Einfügen von Daten zu beachten ist. Ich habe vergessen zu sagen, dass ein Index beim Erstellen sehr selektiv sein muss. Was bedeutet das?
Schauen wir uns diesen Baum an. Wir verstehen, dass wenn der Index auf wahr falsch gesetzt ist, wir nur zwei riesige Holzstücke links und rechts bekommen. Und wir gehen bestenfalls 50% der Tabelle durch, was eigentlich nicht sehr effizient ist. Es ist am besten, einen Index für die Spalten zu erstellen, die die unterschiedlichsten Werte haben. Dies wird unsere Auswahl beschleunigen.
Ich sagte über Fragmentierung: Wenn Sie Daten löschen, müssen Sie dies berücksichtigen. Wenn die im Index enthaltenen Daten häufig gelöscht werden, müssen sie möglicherweise defragmentiert und auch überwacht werden. Es ist auch wichtig zu verstehen, dass Sie einen Index erstellen, der nicht auf Ihren Spalten basiert, sondern darauf, wie Sie diese Daten verwenden. Und Abfragen, die Indizes enthalten, müssen sehr sorgfältig geschrieben werden. Was bedeutet ordentlich? Wenn Sie eine Anforderung schreiben und an die Datenbank senden, wird sie nicht direkt an die Datenbank gesendet, sondern an eine bestimmte Softwareschicht, die als Abfrageplaner bezeichnet wird.
Der Planer hat eine bestimmte Korrespondenztabelle, die angibt, wie viel der Betrieb kostet und wie teuer er ist. Im PostgreSQL-Beispiel gibt es spezielle technische Tabellen, die Informationen zu Ihren Daten und zu Ihren Tabellen sammeln. Der Planer überprüft, welche Abfrage Sie haben und welche Daten in der Tabelle pg_stat gespeichert sind. Dies ist genau die Tabelle, in der allgemeine Informationen darüber gespeichert sind, wie viele Daten Sie haben, welche Spalten sich in Ihrer Tabelle befinden und welche Indizes sich darauf befinden. Auf dieser Grundlage prüft er die Pläne für die Ausführung Ihrer Abfrage, berechnet, wie lange es dauern wird, bis welcher Plan die Abfrage abgeschlossen hat, und wählt den optimalsten aus.

Wenn Sie die vorhergesagte Ausführungszeit für Ihre Abfrage anzeigen möchten, können Sie die Operation Explain verwenden. Wenn Sie die tatsächliche Ausführung wünschen, können Sie Explain analyse verwenden. Egal? Wie gesagt, der Scheduler berechnet zunächst die Ausführungszeit basierend auf der geschätzten Zeit für jede Operation. Daher kann die tatsächliche Zeit je nach Maschine und Art Ihrer Daten unterschiedlich sein. Wenn Sie also die eigentliche Ausführung wünschen, ist es natürlich besser, Explain analyse zu verwenden.
Auf dieser Folie sehen Sie ein Beispiel. Es zeigt, dass Abfragen, die auf Ihrer Spalte mit Indizes basieren, manchmal nicht den Scan-Index verwenden, sondern nur einen vollständigen Scan über die gesamte Tabelle. Dies geschieht, wenn wir eine geringe Indexselektivität haben und der Planer der Meinung ist, dass eine vollständige Scanabfrage in der Tabelle rentabler ist.
Stellen wir uns vor, wir haben unseren Messenger und möchten in der Chat-Liste beispielsweise den Chat-Namen oder die Anzahl der ungelesenen Nachrichten anzeigen. Wenn wir jedes Mal, wenn wir einen Chat öffnen, alle Daten für alle Chats neu berechnen, ist dies sehr unrentabel.
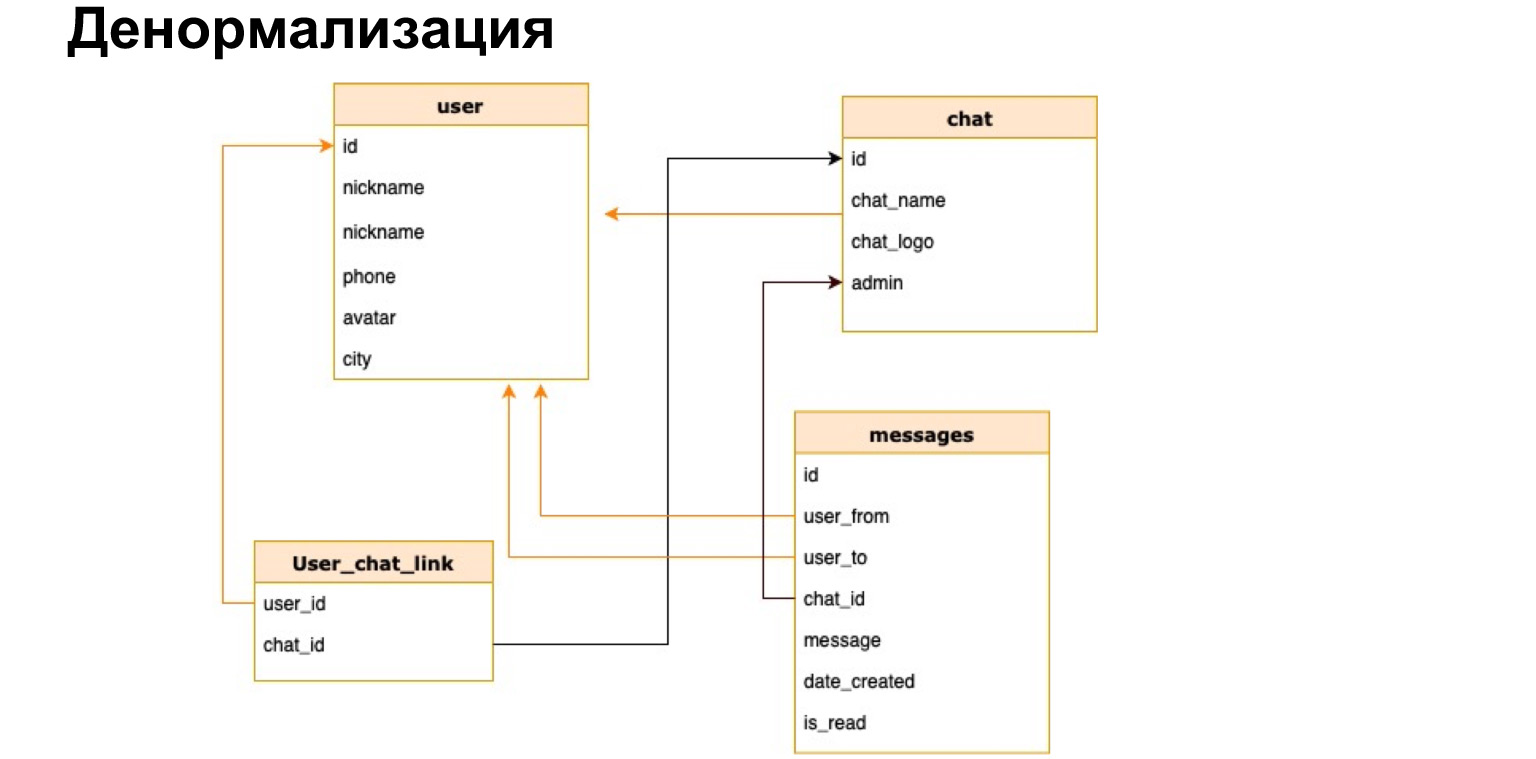
Es gibt so etwas - Denormalisierung. Dies ist ein Kopieren der heißesten verwendeten Daten oder eine Vorberechnung der erforderlichen Daten und das Speichern in einer Tabelle.
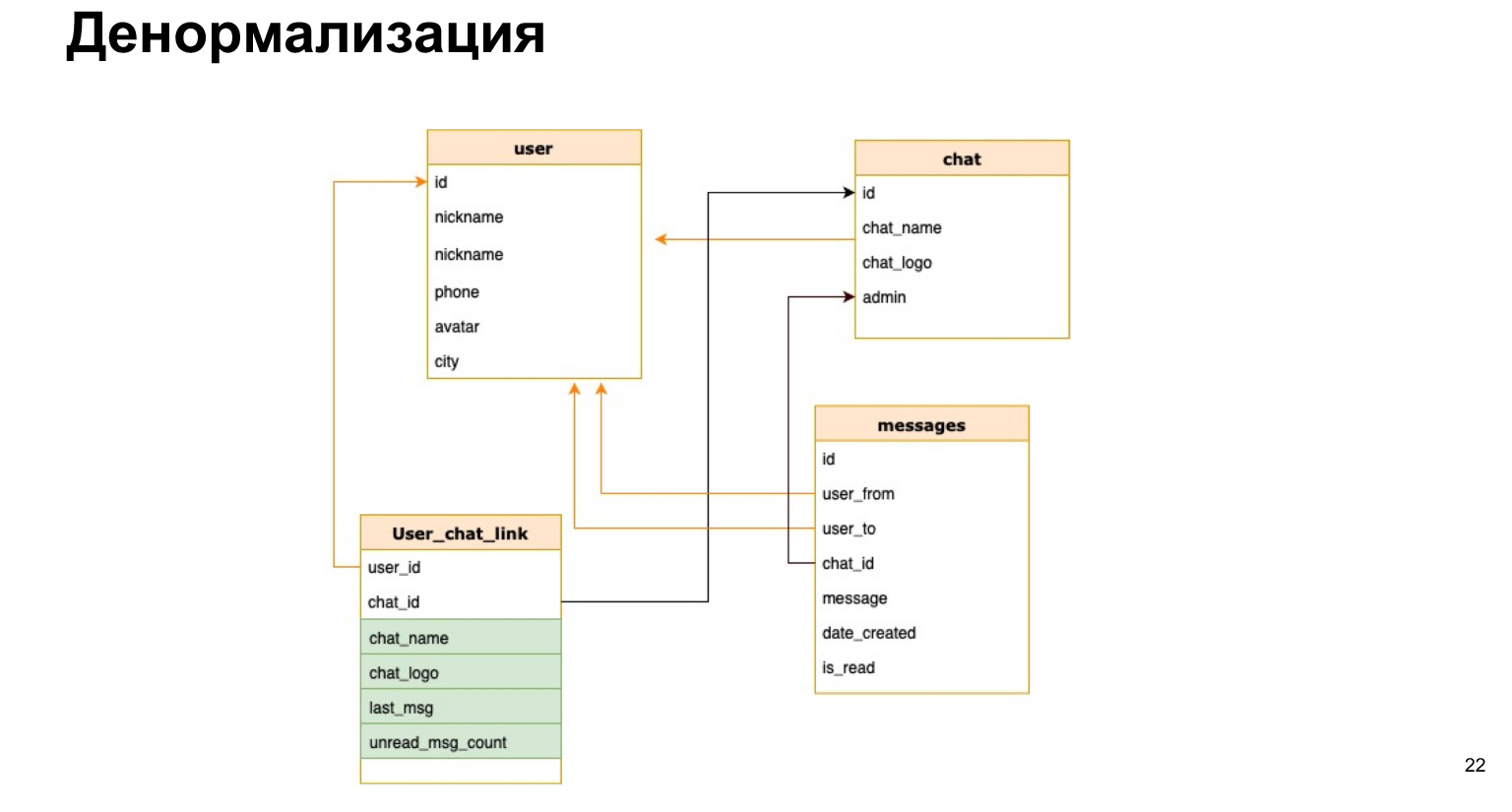
So könnte die Beziehung zwischen Benutzer und Chat aussehen. Das heißt, zusätzlich zur Benutzer-ID und Chat-ID speichern wir kurz den Chat-Namen, das Chat-Protokoll und die Anzahl der ungelesenen Nachrichten dort. Daher müssen wir nicht jedes Mal alle unsere Tabellen laden, eine Auswahl treffen und all dies neu berechnen.

Was ist das Plus der Denormalisierung? Wir beschleunigen den Datenerfassungsprozess. Das heißt, unsere Auswahl geht so schnell wie möglich durch, wir geben den Benutzern so schnell wie möglich eine Antwort.
Die Schwierigkeit besteht darin, dass jedes Mal, wenn wir neue Daten hinzufügen, alle diese Spalten neu berechnet werden müssen und die Fehlerwahrscheinlichkeit sehr hoch ist. Das heißt, wenn unsere Auswahl viel einfacher wird und wir nicht ständig beitreten müssen, wird unser Aktualisieren und Erstellen sehr umständlich, da wir dort Trigger aufhängen, neu berechnen und nichts vergessen müssen.
Daher sollten Sie die Denormalisierung nur verwenden, wenn Sie sie wirklich benötigen. Und da wir jetzt dieser ganzen Logik gefolgt sind, müssen Sie zuerst die Daten normalisieren, sehen, wie Sie sie verwenden werden, und die Indizes anpassen. Wenn Sie Fragen haben, von denen Sie glauben, dass sie nicht gut funktionieren, werfen Sie einen Blick auf Erklären, bevor Sie sie denormalisieren. Finden Sie heraus, wie sie tatsächlich ausgeführt werden und wie der Scheduler sie ausführt. Und nur dann, wenn Sie bereits zu dem Schluss gekommen sind, dass eine Denormalisierung noch erforderlich ist, können Sie dies tun. Es gibt jedoch eine solche Praxis, und in realen Projekten wird häufig die Denormalisierung von Daten verwendet.
Gehen wir weiter. Selbst wenn Sie die Daten gut strukturiert, ein Datenmodell ausgewählt, gesammelt, alles denormalisiert und Indizes erstellt haben, kann in der IT-Welt noch viel schief gehen.
Software kann ausfallen, Strom kann ausfallen, Hardware oder Netzwerk können ausfallen. Es gibt eine zweite Klasse von Problemen: Unsere Datenbanken werden von vielen Benutzern gleichzeitig verwendet. Sie können dieselben Daten gleichzeitig aktualisieren. Wir müssen in der Lage sein, all diese Probleme zu lösen.
Schauen wir uns konkrete Beispiele an, worum es geht.

Stellen wir uns vor, es gibt zwei Benutzer, die einen Besprechungsraum buchen möchten. Benutzer 1 sieht, dass der Besprechungsraum zu diesem Zeitpunkt frei ist, und beginnt, ihn zu buchen. Sein Fenster öffnet sich und er überlegt, welchen meiner Kollegen ich anrufen werde. Während er nachdenkt, sieht Benutzer 2 auch, dass der Besprechungsraum frei ist und öffnet ein Bearbeitungsfenster für sich.
Als Benutzer 1 diese Daten gespeichert hat, ist er gegangen und denkt, dass alles in Ordnung ist. Der Besprechungsraum ist ausgebucht. Zu diesem Zeitpunkt überschreibt Benutzer 2 jedoch seine Daten, und es stellt sich heraus, dass der Chatraum Benutzer 2 zugewiesen ist. Dies wird als Datenkonflikt bezeichnet. Und wir müssen in der Lage sein, diese Konflikte den Menschen zu zeigen und sie irgendwie zu lösen. An diesem Ort werden wir eine Neuaufnahme haben.

Wie kann man es machen? Wir können den Besprechungsraum einfach für eine Weile blockieren, während Benutzer 1 nachdenkt. Wenn er die Daten gespeichert hat, wird Benutzer 2 dies nicht zulassen. Wenn er die Daten freigegeben und nicht gespeichert hat, kann Benutzer 2 ein Meeting buchen. Sie könnten ein ähnliches Bild sehen, wenn Sie Kinokarten kaufen. Sie haben 15 Minuten Zeit, um die Tickets zu bezahlen, andernfalls werden sie erneut anderen Personen zur Verfügung gestellt, die sie ebenfalls nehmen und bezahlen können.
Hier ist ein weiteres Beispiel, das uns zeigt, wie wichtig es ist, sicherzustellen, dass unsere Operationen vollständig ausgeführt werden. Angenommen, ich möchte Geld von Bankkonto 1 auf Konto 2 überweisen. In diesem Moment habe ich drei Operationen. Ich überprüfe, ob ich genug Geld habe, ziehe Geld von meinem ersten Konto ab und zahle es auf das zweite Konto ein. Es ist klar, dass, wenn ich in einem dieser Momente einen Fehler habe, etwas schief gehen wird.
Wenn zu diesem Zeitpunkt beispielsweise eine andere Transaktion stattfindet, bei der Daten gelesen werden, reicht das Guthaben auf meinem Konto nicht mehr aus, und ich kann keine anderen Vorgänge ausführen. Wenn im zweiten Moment ein Problem auftritt, haben wir beispielsweise Geld von einem Konto abgebucht, aber kein Geld auf das zweite Konto gelegt. Es stellt sich heraus, dass dadurch mein Bankkonto und alle meine Konten um einen gewissen Betrag reduziert werden. Dieses Geld kann in keiner Weise zurückgegeben werden.
Um solche Probleme zu lösen, gibt es das Konzept einer Transaktion - eine atomare, integrale Ausführung aller drei Operationen gleichzeitig.
Wie macht die Datenbank das? Es schreibt alle diese Änderungen in ein bestimmtes Protokoll und wendet sie nur an, wenn unsere Transaktion festgeschrieben ist. Somit garantieren wir, dass alle diese Vorgänge als Ganzes oder überhaupt nicht ausgeführt werden.
Wenn wir zu irgendeinem Zeitpunkt einen Fehler haben, wird das Geld nicht vom ersten Konto abgezogen und wir werden es dementsprechend nicht verlieren.
Transaktionen haben vier Eigenschaften, vier Anforderungen für sie. Dies sind Atomizität, Konsistenz, Isolation und Haltbarkeit - Datenatomizität, Konsistenz, Isolation und Persistenz. Was sind diese Eigenschaften?
- Atomizität oder Atomizität ist eine Garantie dafür, dass die von Ihnen ausgeführte Operation vollständig abgeschlossen wird und nicht teilweise ausgeführt wird. Auf diese Weise stellen wir sicher, dass die Gesamtkonsistenz der Daten in unserer Datenbank sowohl vor als auch nach dem Vorgang gewährleistet ist.
- Consistency — -, . (Integrity). - , , Integrity Error, : , . . — , .
, , , , . . .
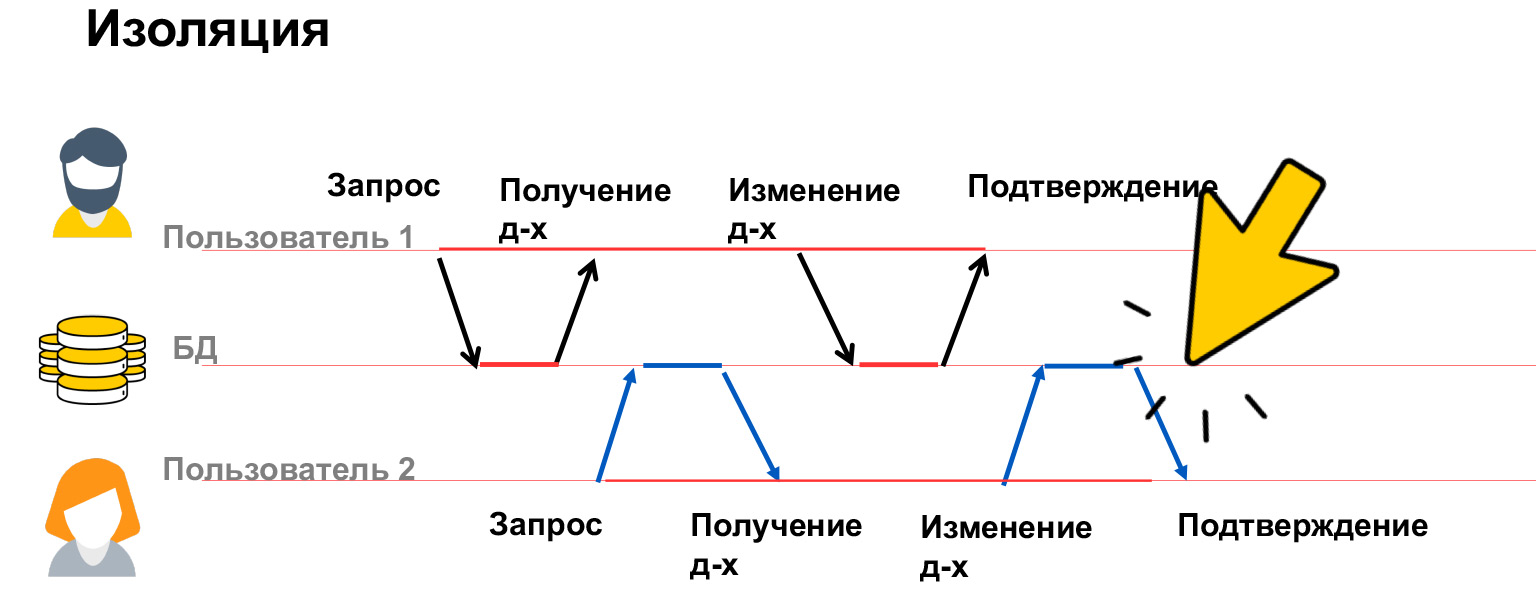
- Isolation — , . . , .
- Durability — , , , , .
Lassen Sie uns etwas mehr über Isolierung sprechen. Die Isolierung von Transaktionen ist eine sehr teure Eigenschaft, für die viele Ressourcen aufgewendet werden, weshalb wir in unseren Datenbanken mehrere Isolationsstufen haben. Mal sehen, was Probleme sein können, und auf dieser Grundlage werden wir bereits diskutieren, wie sie gelöst werden können.
Es gibt vier Hauptklassen von Problemen: verlorenes Update, Dirty Read, nicht wiederholbares Lesen und Ghost Read. Lass uns genauer hinschauen.
Ein verlorenes Update ist wie im Beispiel mit Chatrooms, wenn Benutzer 1 Daten überschrieben hat und nichts davon weiß. Das heißt, wir haben die Daten, die dieser Benutzer ändert, nicht blockiert und dementsprechend ihre Überschreibung erhalten.
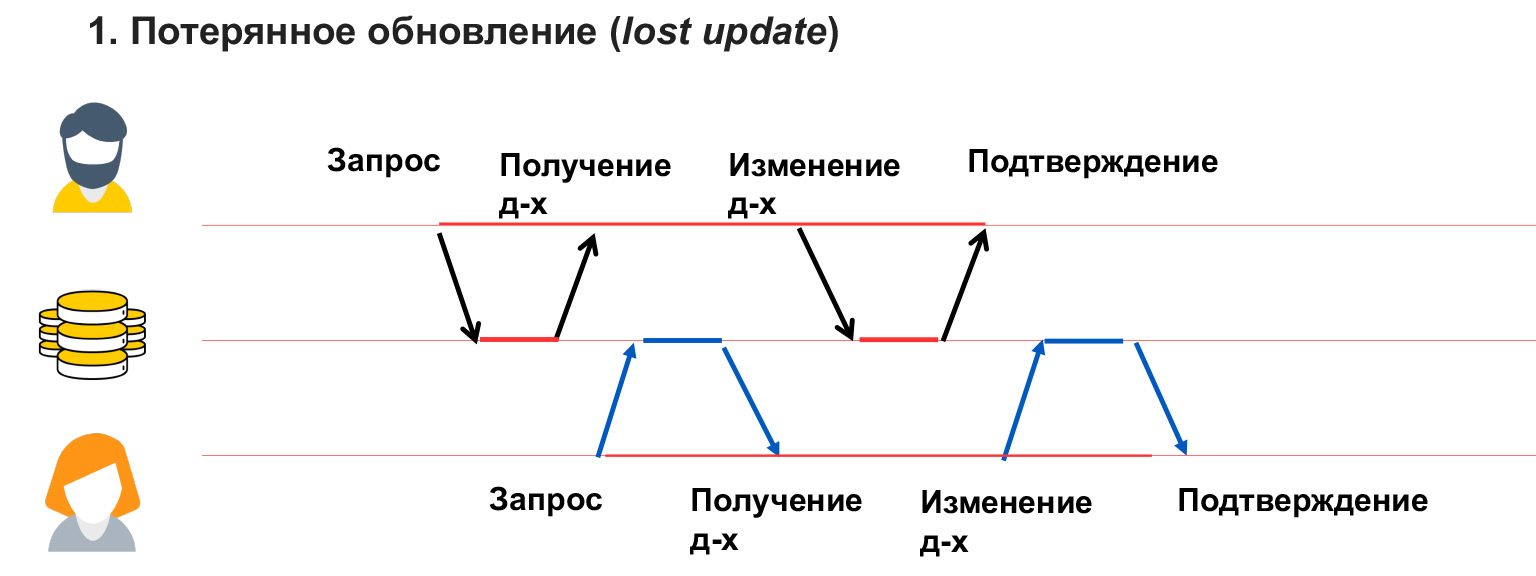
Ein Dirty-Read-Problem tritt auf, wenn ein Benutzer temporäre Änderungen von einem anderen Benutzer sieht, die dann zurückgesetzt oder einfach vorübergehend vorgenommen werden können.

In diesem Fall hat Benutzer 1 etwas in die Datenbank geschrieben. Benutzer 2 berechnete zu diesem Zeitpunkt etwas von dort und baute Analysen auf diesen Daten auf. Benutzer 1 hat einen Fehler und eine Inkonsistenz festgestellt und setzt diese Daten zurück. Daher ist die Analyse, die Benutzer 2 aufgeschrieben hat, falsch und falsch, da die Daten, aus denen er sie berechnet hat, nicht mehr vorhanden sind. Sie müssen auch in der Lage sein, dieses Problem zu lösen.
Ein nicht wiederholbarer Lesevorgang liegt vor, wenn wir einen Benutzer mit einer langen Transaktion haben. Er ruft Daten aus der Datenbank ab und zu diesem Zeitpunkt ändert Benutzer 2 einen Teil derselben Daten.
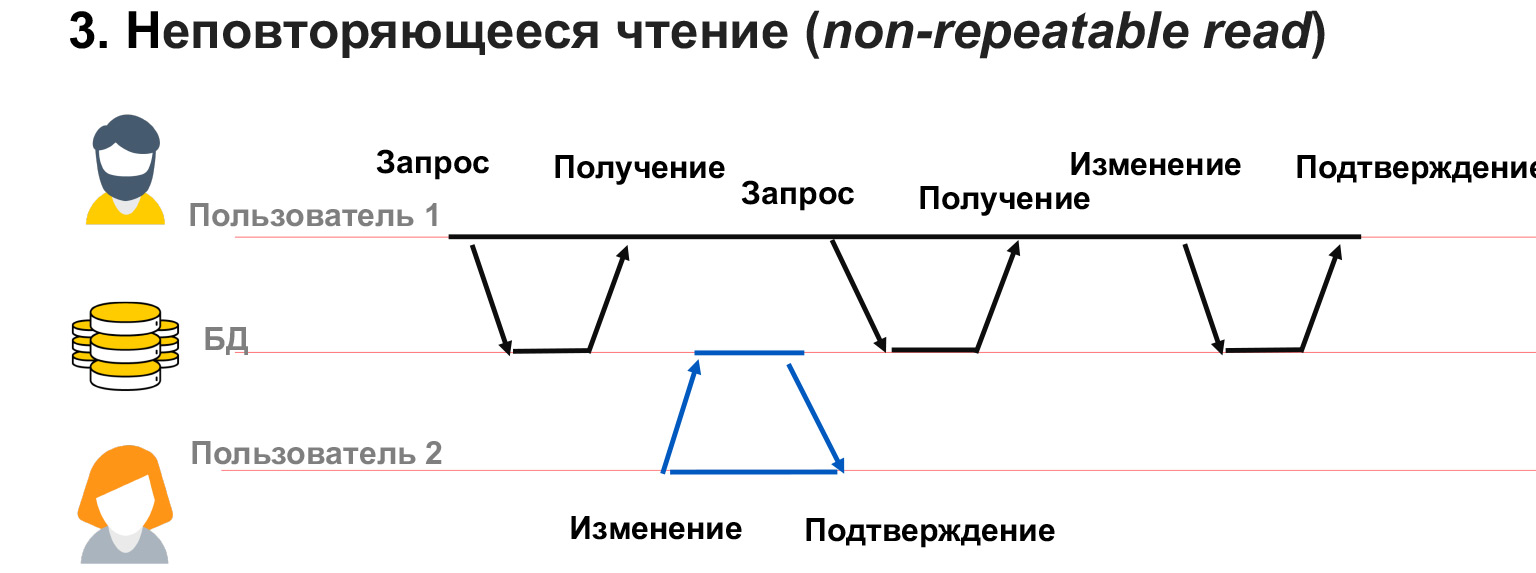
In diesem Fall stellt sich heraus, dass Benutzer 1 Änderungen an den Daten, die er hat, nicht blockiert hat. Und trotz der Tatsache, dass er selbst eine Momentaufnahme der Daten erhalten hat, kann er bei wiederholter Anforderung derselben Auswahl unterschiedliche Werte in diesen Zeilen erhalten. Somit kommt es zu einem Konflikt, einer Nichtübereinstimmung der von ihm geschriebenen Daten.

Ein ähnliches Problem kann auftreten, wenn Benutzer 2 Daten hinzugefügt oder gelöscht hat. Das heißt, Benutzer 1 hat eine Anfrage gestellt, und nach einer zweiten Anfrage nach denselben Daten hatte oder verschwand er Zeilen. In diesem Fall ist es im Rahmen einer Transaktion sehr schwierig zu verstehen, was mit ihnen zu tun ist und wie sie überhaupt zu verarbeiten sind.

Um diese Probleme zu lösen, gibt es vier Isolationsstufen. Die erste und unterste Ebene ist "Nicht festgeschrieben". Dies beschreibt PostgreSQL als Keine Sperre. Wenn wir Daten lesen oder schreiben, hindern wir andere Benutzer nicht daran, diese Daten zu lesen oder zu schreiben. Es stellt sich heraus, dass wir keine Änderungen blockieren. Alle vier Probleme können weiterhin auftreten. Aber wovor schützt diese Isolationsstufe? Es stellt sicher, dass alle Transaktionen, die in die Datenbank gelangen, ausgeführt werden. Wenn zwei Benutzer gleichzeitig Abfragen mit denselben Daten ausführen, werden beide Transaktionen nacheinander ausgeführt.
Wofür ist das nützlich? Diese Isolationsstufe wird in der Praxis sehr selten verwendet, kann jedoch nützlich sein, wenn beispielsweise eine große analytische Abfrage vorliegt und Sie die zweite Abfrage einlesen möchten, um zu sehen, in welchem Stadium sich Ihre Analyse befindet, welche Daten bereits aufgezeichnet wurden und welche nicht. Und dann die zweite Anforderung - das Debuggen, Debuggen und Überprüfen - wird nur in dieser Isolationsstufe ausgeführt. Und er sieht alle Änderungen in Ihrer ersten analytischen Abfrage, die eventuell rückgängig gemacht werden kann. Oder nicht zurückgesetzt, aber im aktuellen Moment können Sie den Status des Systems sehen.

Festgeschriebene Daten lesen, festgeschriebene Daten lesen. Diese Isolationsstufe wird standardmäßig in den meisten relationalen Datenbanken verwendet, einschließlich PostgreSQL und Oracle. Es stellt sicher, dass Sie niemals schmutzige Daten lesen. Das heißt, eine andere Transaktion sieht niemals die Zwischenstufen der ersten Transaktion. Der Vorteil ist, dass es sehr gut für kleine, kurze Abfragen funktioniert. Wir garantieren, dass wir niemals eine Situation haben werden, in der wir einige Teile der Daten sehen, unvollständige Daten. Zum Beispiel erhöhen wir das Gehalt einer ganzen Abteilung und sehen nicht, wann nur ein Teil der Menschen eine Erhöhung erhalten hat, und der zweite Teil sitzt mit einem nicht indizierten Gehalt. Denn wenn wir eine solche Situation haben, ist es logisch, dass unser Analyst sofort "geht".
Wovor schützt diese Isolationsstufe nicht? Es schützt nicht vor der Tatsache, dass die von Ihnen ausgewählten Daten geändert werden können. Für kleine Abfragen ist diese Isolationsstufe ausreichend, aber für große, lange Abfragen und komplexe Analysen können Sie natürlich komplexere Ebenen verwenden, die Ihre Tabellen sperren.
Die Isolationsstufe für wiederholbares Lesen schützt vor den ersten drei Problemen, die wir mit Ihnen besprochen haben. Dies und das verlorene Update, als wir unseren Chatraum neu aufgenommen haben; Dirty Read - Lesen nicht festgeschriebener Daten; und diese nicht wiederholbaren Lese- / Lesedaten, die durch andere Transaktionen aktualisiert wurden.

Wie wird es bereitgestellt? Durch Sperren der Tabelle, dh Sperren unserer Auswahl. Wenn wir die Auswahl in unsere Transaktion aufnehmen, sieht es aus wie eine Momentaufnahme der Daten. Und in diesem Moment sehen wir nicht die Änderungen anderer Benutzer, während wir mit dieser Momentaufnahme von Daten arbeiten. Der Nachteil ist, dass wir Daten blockieren und dementsprechend weniger parallele Anforderungen haben, die mit Daten arbeiten können. Dies ist ein sehr wichtiger Aspekt. Und warum gibt es im Allgemeinen so viele dieser Isolationsstufen?
Je höher die Ebene, desto mehr Blöcke und weniger Benutzer können parallel mit der Datenbank arbeiten. Jede Transaktion sieht einen bestimmten Snapshot der Daten, der nicht geändert werden kann. Es können jedoch neue Daten angezeigt werden. Diese Isolationsstufe bewahrt uns also nicht vor der Entstehung neuer Daten, die zur Auswahl geeignet sind.
Es gibt noch eine Isolationsstufe - die Serialisierung. Dies wird oft als Bestellung bezeichnet. Dies ist eine vollständige Datensperre für die Tabelle. Es erspart das Lesen von Phantomen, dh das Lesen nur der Daten, die wir hinzugefügt oder gelöscht haben, da wir die Tabelle sperren und das Schreiben nicht zulassen. Und wir erfüllen unsere Wünsche ganzheitlich.

Dies ist sehr nützlich für komplexe, große analytische Abfragen, bei denen Genauigkeit und Datenintegrität von entscheidender Bedeutung sind. Es wird sich nicht herausstellen, dass wir irgendwann die Benutzerdaten gelesen haben und dann neue Statistiken in einer anderen Tabelle angezeigt wurden und sich herausstellte, dass sie nicht synchron waren.
Dies ist die höchste Isolationsstufe. Es hat die größte Anzahl von Sperren und die kleinstmögliche Parallelisierung von Abfragen.
Was müssen Sie über Transaktionen wissen? Dass sie unser Leben vereinfachen, weil sie auf DBMS-Ebene implementiert sind und wir nur unsere Abfragen korrekt durchführen und sie korrekt bilden müssen, damit die Daten schließlich konsistent sind. Und um genau die Daten zu blockieren, mit denen unsere Benutzer arbeiten. Es sollte bedacht werden, dass es schlecht ist, überall alles zu blockieren. Je nachdem, welches System Sie haben und wer wie viel liest / schreibt, haben Sie eine unterschiedliche Isolationsstufe. Wenn Sie das schnellstmögliche System suchen, das einige Fehler macht, können Sie die minimale Isolationsstufe auswählen. Wenn Sie ein Bankensystem haben, das sicherstellen muss, dass die Daten konsistent sind, alles erledigt ist und nichts verloren geht, müssen Sie natürlich die maximale Isolationsstufe auswählen.
Wir haben bereits einige gute Fortschritte beim Verständnis der Strukturierung der Datenbank und der möglichen Ereignisse erzielt. Gehen wir weiter.
Wie sicher ist es, eine Datenbank zu speichern? Sicher nicht sicher. Wenn ihr etwas passiert, verlieren wir alle Daten. Wenn es ein Backup gibt, können wir es rollen, aber dann kommt es zu Systemausfällen. Wenn unser Netzwerk ausfällt oder der Knoten nicht mehr verfügbar ist, ist das System während der Ausfallzeit auch einige Zeit im Leerlauf.
Wie kann das gelöst werden? Es gibt ein solches Konzept - Replikation. Dies ist eine Duplizierung der Datenbank auf andere Knoten und Server.

Dies ist genau eine vollständige Vervielfältigung, eine Kopie der Datenbank. Wie können wir diesen Mechanismus nutzen?
Erstens, wenn etwas mit der Datenbank passiert ist, können wir Anforderungen an eine andere Kopie der Datenbank umleiten, was im Prinzip logisch ist. Dies ist die Hauptanwendung. Wie können wir das sonst nutzen?
Stellen wir uns vor, der Benutzer ist weit vom Server entfernt. Wir können Server so verteilen, dass sie die maximale Anzahl von Benutzern abdecken und ihnen so schnell wie möglich Anfragen stellen. Jeder dieser Server hat dieselbe Kopie wie die anderen, aber Anfragen werden schneller an die Benutzer zurückgegeben.

Eine weitere sehr beliebte Anwendung ist der Lastausgleich. Da wir identische Kopien der Daten haben, können wir nicht aus unserem Kopf lesen, nicht aus einer Datenbank, sondern aus verschiedenen. Daher entladen wir unseren Server.

Wir haben auch das Konzept von OLTP-Abfragen und OLAP-Abfragen. Was ist das? OLTP - kurze Transaktionsabfragen. OLAP ist eine Langzeitanalyse. In diesem Fall führen wir einen großen Join, eine große Auswahl, alles zusammen und es ist für uns sehr wichtig, dass in diesem Moment alle Daten gesperrt sind, damit keine Änderungen vorgenommen werden und die Datenbank vollständig ist.
In solchen Situationen können Sie Analysen für eine separate Kopie der Datenbank durchführen. Damit unsere Benutzer nicht betroffen sind, können sie auch Einträge in der Datenbank vornehmen. In diesem Fall werden diese Einträge in unsere Kopie aufgenommen.
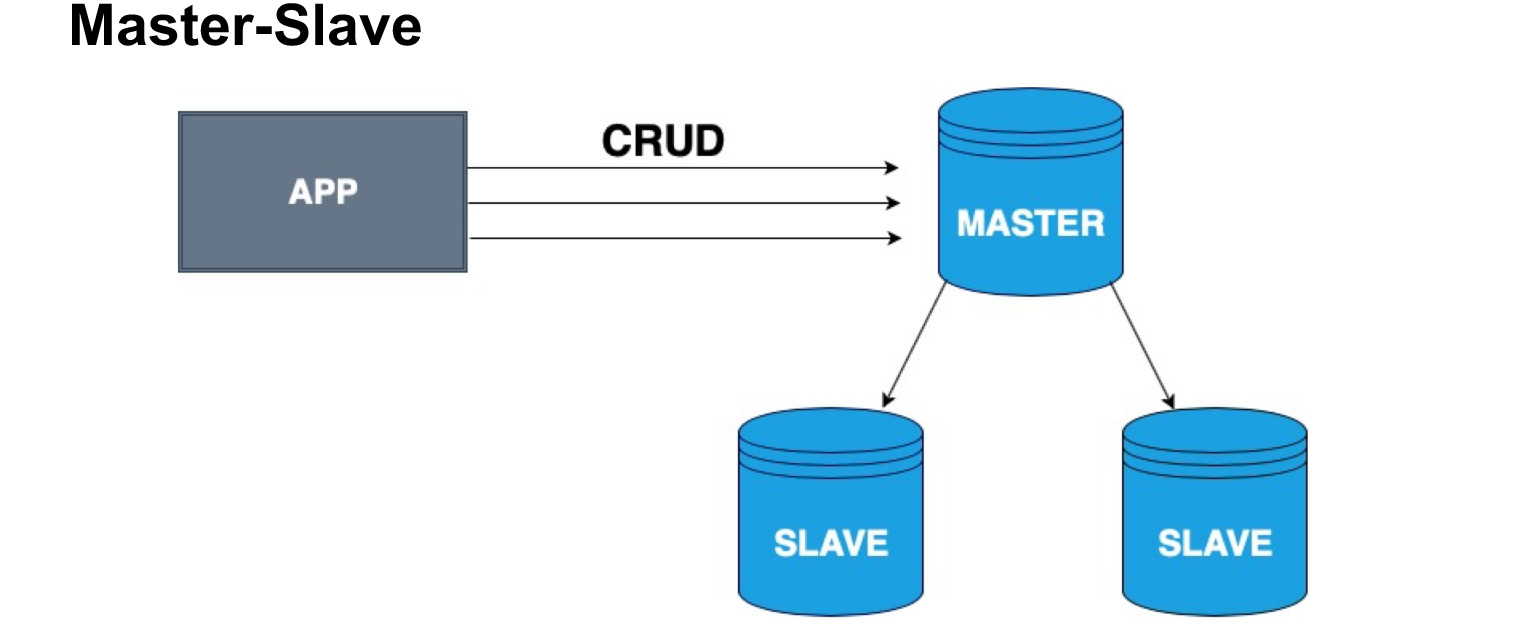
Um Datenbankkopien korrekt zu verteilen, wird das Konzept eines Masterknotens und eines Slaveknotens, Master und Slave, eingeführt. Slave wird sehr oft als Replik oder Follower bezeichnet. Master - der Knoten, auf den unser Benutzer, unsere Anwendung, schreibt. Der Master wendet alle Änderungen an, führt ein Protokoll der Änderungen und sendet dieses Protokoll an den Slave. Der Slave akzeptiert keine Änderungen von Benutzern, sondern wendet nur Änderungen vom Master auf das Protokoll an. Bitte beachten Sie, dass der Master nicht jedes Mal eine Kopie sendet, sondern Änderungen sendet. Der Slave überträgt diese Änderungen und erhält dieselbe Kopie der Daten wie im Master.
Ein sehr wichtiger Parameter des replizierten Systems ist, dass Anforderungen synchron oder asynchron ausgeführt werden. Was ist eine synchrone Anforderung? In diesem Fall sendet der Master eine Anforderung an eine synchrone Replik, an einen synchronen Slave und wartet darauf, dass der Slave "Ja, ich habe akzeptiert" sagt, und sendet die Bestätigung an den Master zurück. Erst dann gibt der Master die Antwort an den Benutzer zurück. Wenn das Replikat asynchron ist, sendet der Master eine Anforderung an das Replikat, teilt dem Benutzer jedoch sofort mit, dass "Das war's, ich habe es aufgeschrieben." Mal sehen, wie es funktioniert.
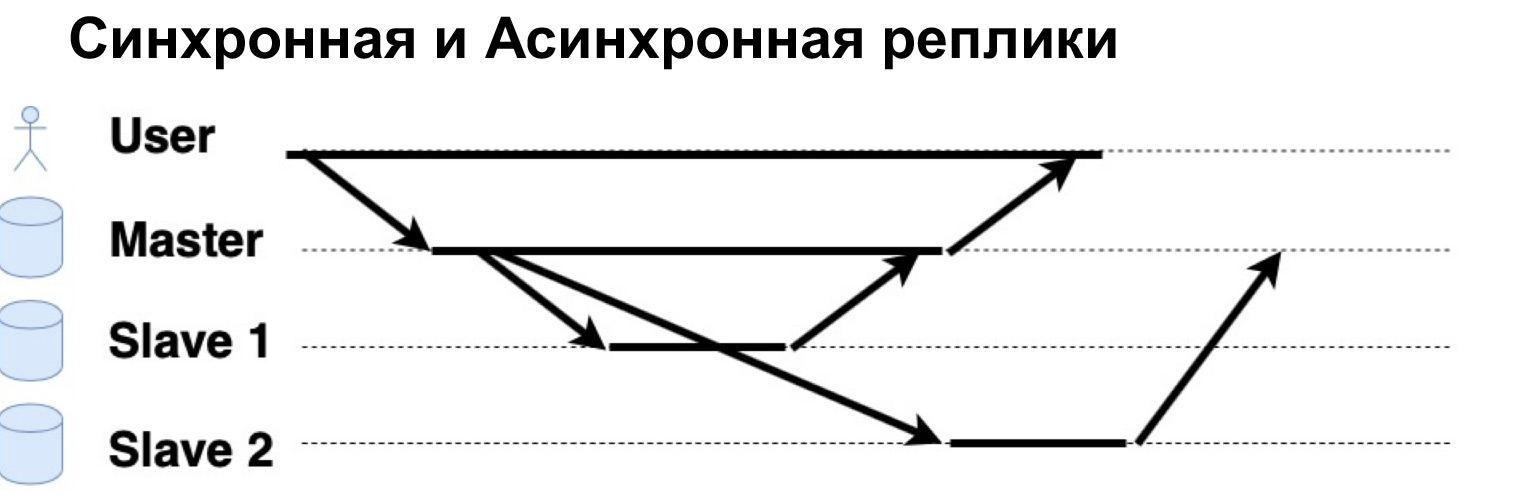
Es gibt einen Benutzer, der Daten an den Master geschrieben hat. Der Master schickte sie an zwei Replikate, wartete auf eine Antwort von einem synchronen Replikat und gab dem Benutzer sofort eine Antwort. Eine asynchrone Replik zeichnete auf und sagte zum Master: "Ja, es ist okay, die Daten werden geschrieben."
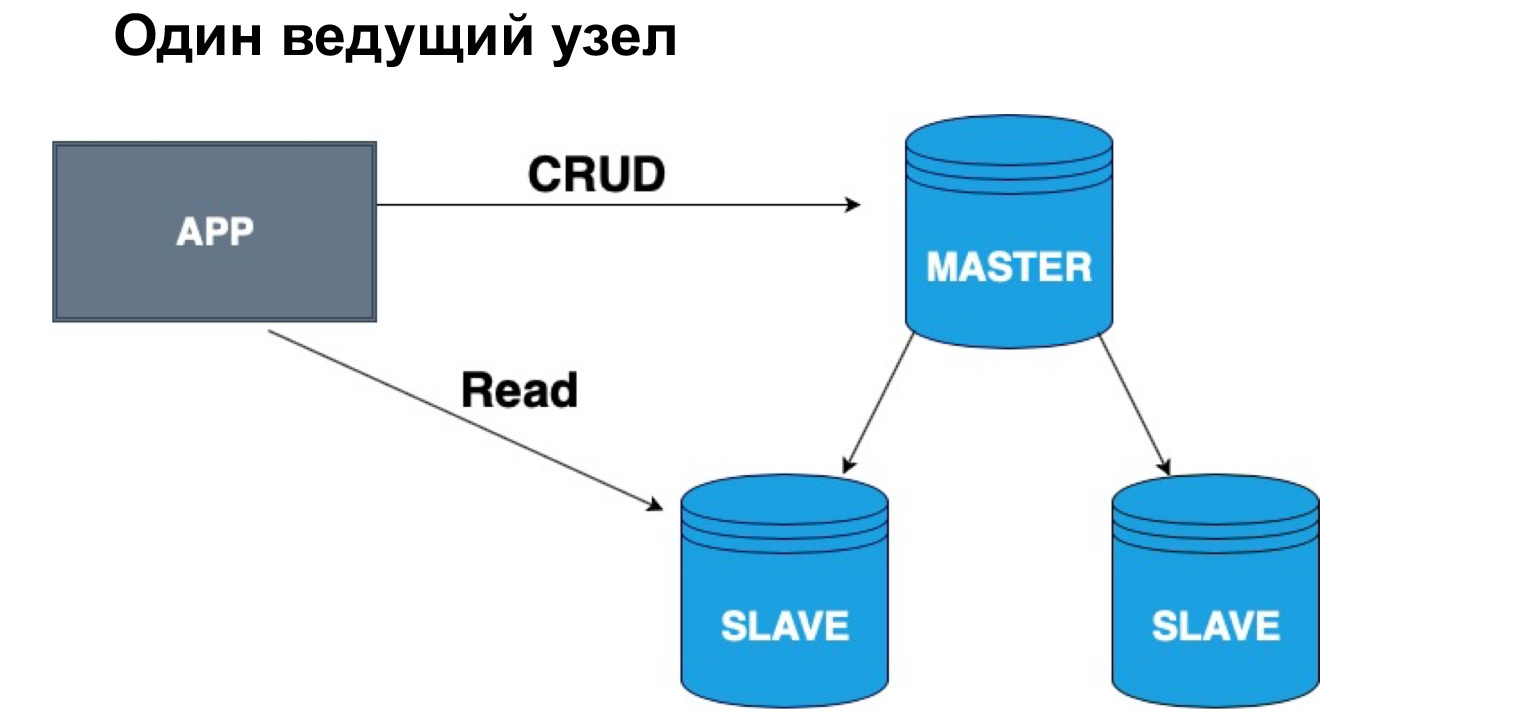
In Bezug auf eine solche Hierarchie, Master und Slave, können wir einen oder mehrere Köpfe haben. Wenn wir einen Masterknoten haben, ist es sehr praktisch, darauf zu schreiben, aber Sie können von einem synchronen Replikat lesen. Warum genau synchron? Weil ein synchrones Replikat sicherstellt, dass die Daten mit maximaler Genauigkeit auf dem neuesten Stand sind.
Wenn eine Abfrage auf Daten angewendet wird, eine Operation aus dem Protokoll, dauert es auch einige Zeit. Wenn Ihnen daher die hundertprozentige Genauigkeit der Daten, die Sie empfangen möchten, wichtig ist, sollten Sie eine Auswahl im Master treffen. Wenn Sie nicht kritisch sind, dass die Daten mit einer leichten Verzögerung eintreffen, können Sie vom synchronen Slave lesen. Wenn Sie die Relevanz der Daten absolut nicht kritisch beurteilen, können Sie auch aus dem asynchronen Replikat lesen und so den Master und das synchrone Replikat von Anforderungen entladen.
Die Replikation kann auch mehrere Master haben. Verschiedene Anwendungen können in verschiedene Köpfe schreiben, und diese Master lösen dann Konflikte miteinander.
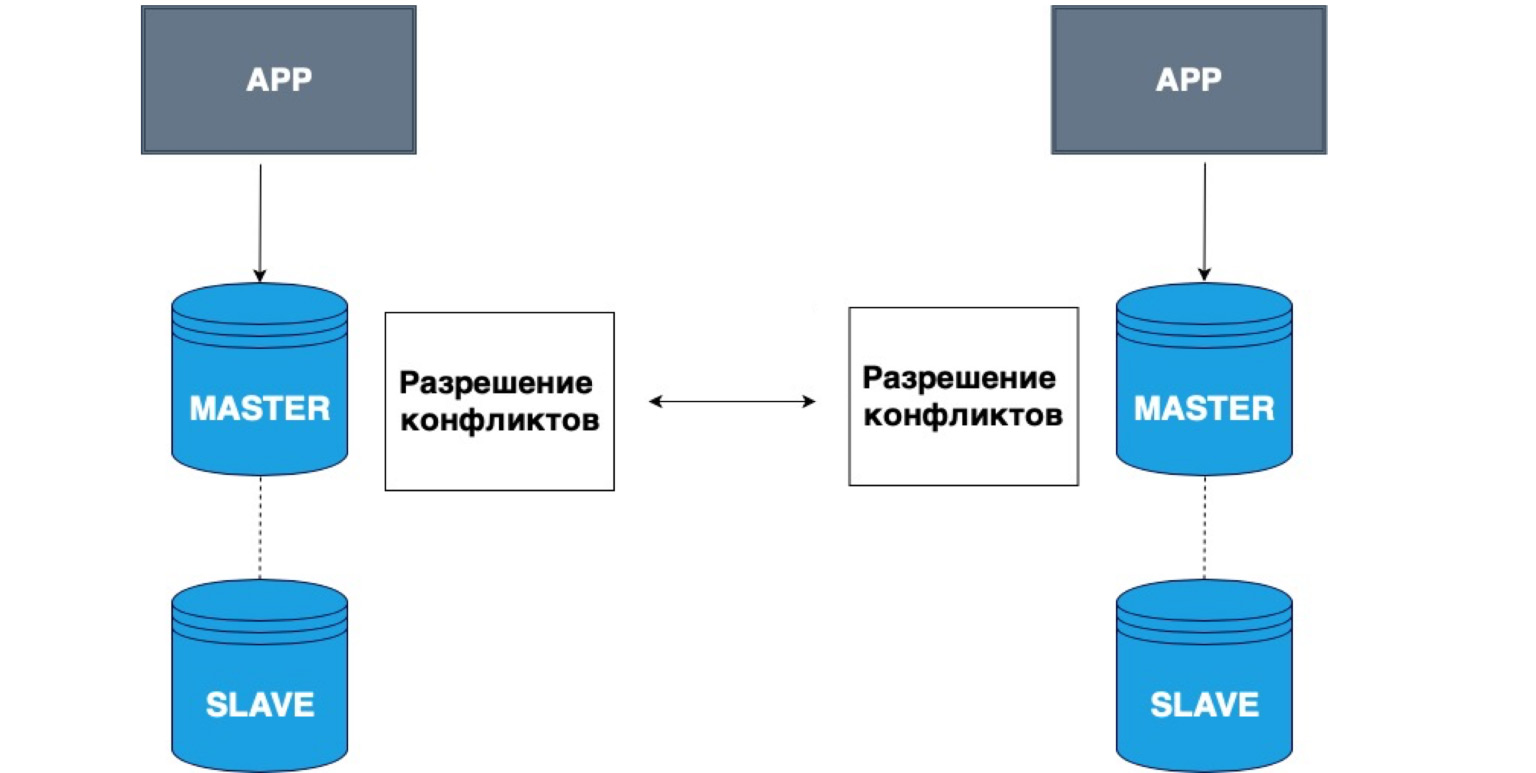
Ein sehr einfaches Beispiel für die Verwendung solcher Daten sind alle Arten von Offline-Anwendungen. Sie haben beispielsweise einen Kalender auf Ihrem Telefon. Sie haben die Verbindung zum Netzwerk getrennt und ein Ereignis im Kalender aufgezeichnet. In diesem Fall ist Ihr lokaler Speicher, Ihr Telefon, Master. Die Daten wurden in sich selbst gespeichert. Wenn das Master-Netzwerk angezeigt wird, lösen Ihre lokale Kopie und die Kopie auf dem Server Konflikte und kombinieren diese Daten.
Dies ist ein sehr einfaches Beispiel für eine solche Replikation. Es wird häufig für die gemeinsame Bearbeitung von Online-Dokumenten verwendet oder wenn die Wahrscheinlichkeit eines Netzwerkverlusts sehr hoch ist.
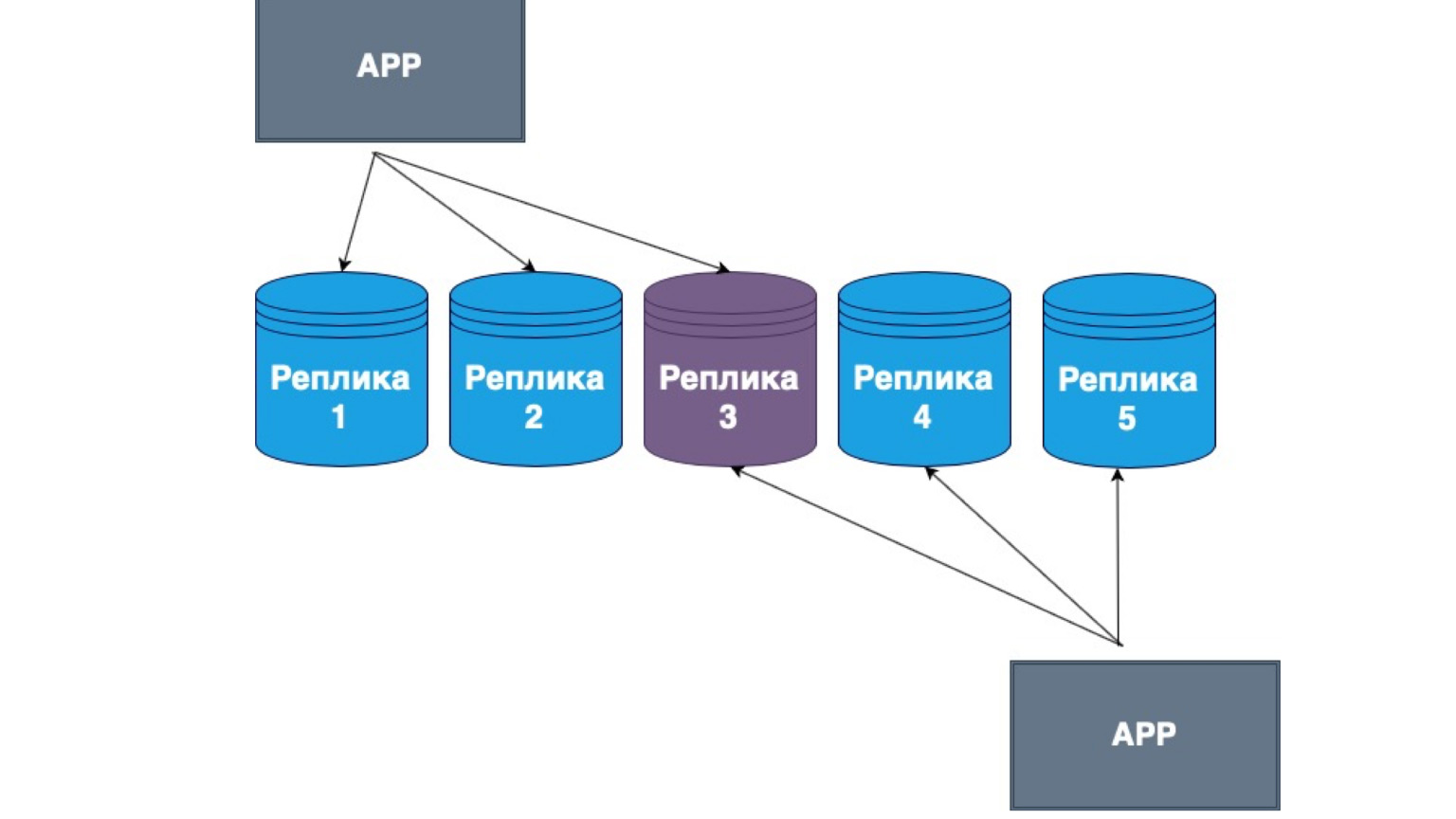
Masterless-Replikationen existieren ebenfalls. Was ist das? Dies ist die Replikation, bei der der Client selbst Daten an die meisten Replikate sendet und diese auch aus den meisten Replikaten liest. Hier können Sie sehen, dass unser mittleres Replikat die Schnittstelle zwischen Lesen und Aktualisieren ist.
Das heißt, wir garantieren, dass wir jedes Mal, wenn wir die Daten lesen, in mindestens eine der Repliken gelangen, in denen die Daten am relevantesten sind. Untereinander bilden die Replikate einen Mechanismus für den Informationsaustausch mit dem Hauptprotokoll der Änderungen und Konflikte zwischen Replikaten. In diesem Fall wird sehr oft der Fat Client implementiert. Wenn er Daten von einem Replikat erhalten hat, das aktuellere Änderungen als ein anderes enthält, sendet er die Daten einfach an ein anderes Replikat oder löst den Konflikt.

Was ist über die Replikation zu wissen? Der Hauptpunkt der Replikation ist die Systemfehlertoleranz und die hohe Verfügbarkeit Ihres Servers. Was auch immer mit der Datenbank passiert, das System ist verfügbar, Ihre Benutzer können Daten schreiben, und wenn die Verbindung mit dem Master oder einem anderen Replikat wiederhergestellt wird, werden auch alle Daten wiederhergestellt.
Die Replikation ist sehr hilfreich beim Auslagern von Servern und beim Umverteilen von Leseanforderungen vom Master auf Replikate. Wir können diesen Lesevorgang skalieren, mehr Lesereplikate erstellen und unser System noch schneller machen. Sie können auch komplexe, langfristige analytische Abfragen replizieren, die eine große Anzahl von Sperren erfordern und die Systemverfügbarkeit beeinträchtigen können.
Am Beispiel von Offline-Anwendungen haben wir untersucht, wie Sie solche Daten speichern und Konflikte lösen können. Im Fall eines synchronen Replikats kann es zu einer Replikationsverzögerung kommen, dh zu einer Zeitverzögerung. Bei einem asynchronen Replikat ist es fast immer vorhanden. Das heißt, wenn Sie Daten von einem asynchronen Replikat lesen, müssen Sie verstehen, dass sie möglicherweise nicht relevant sind.
Gemäß der Hierarchie habe ich vergessen zu sagen, dass wenn ein Master auf eine Antwort von einem synchronen Replikat wartet, es logisch ist anzunehmen, dass unser System die Anforderung nicht speichern kann, wenn alle Replikate synchron sind und eines plötzlich nicht mehr verfügbar ist. Dann schreibt der Master uns an den ersten synchronen Slave, erhält eine Antwort, fragt nach dem zweiten Slave, erhält keine Antwort und muss schließlich die gesamte Transaktion zurücksetzen.
Daher wird in solchen Systemen in der Regel ein Replikat synchronisiert und der Rest asynchron. Das synchrone Replikat stellt sicher, dass Ihre Daten an einem anderen Ort gespeichert werden. Das heißt, zusätzlich zum Master, mit dem etwas passieren kann, garantieren wir, dass es mindestens einen weiteren Knoten gibt, der eine vollständige Kopie genau desselben Transaktionsprotokolls und derselben Daten enthält.
Das asynchrone Replikat hingegen garantiert keine Datenintegrität. Wenn wir nur asynchrone Replikate haben und der Master die Verbindung getrennt hat, können sie zurückbleiben und die Daten sind möglicherweise noch nicht dort angekommen. In solchen Fällen bauen sie in der Regel eine solche Hierarchie auf, dass entweder ein Master, ein synchrones Replikat und der Rest asynchron sind oder wir einen Master haben und alle Replikate asynchron sind, wenn die Datenpersistenz für uns nicht wichtig ist.
Es gibt ein "aber": Alle Replikate müssen dieselbe Konfiguration haben. Wenn wir als Beispiel über PostgreSQL sprechen, müssen sie dieselbe Version von PostgreSQL selbst haben, da verschiedene Versionen der Datenbank unterschiedliche Protokollformate haben können. Wenn das Replikat aus einer anderen Version stammt, werden die von der anderen Basis geschriebenen Vorgänge möglicherweise nicht gelesen.
Was ist eine Replik? Dies ist eine vollständige Kopie aller Daten. Stellen wir uns vor, es gibt so viele Daten, dass der Server nicht damit umgehen kann. Was ist die erste Lösung?
Die erste Lösung besteht darin, eine teurere Maschine mit mehr Speicher, einer größeren CPU und einer größeren Festplatte zu kaufen. Diese Entscheidung wird größtenteils richtig sein, solange Sie nicht mit dem Problem der hohen Eisenkosten konfrontiert sind. Eines Tages wird es zu teuer sein, ein neues Auto zu kaufen, oder es wird einfach keinen Ort geben, an dem man wachsen kann. Es gibt eine riesige Datenmenge, die physisch einfach nicht auf einen Computer passt.
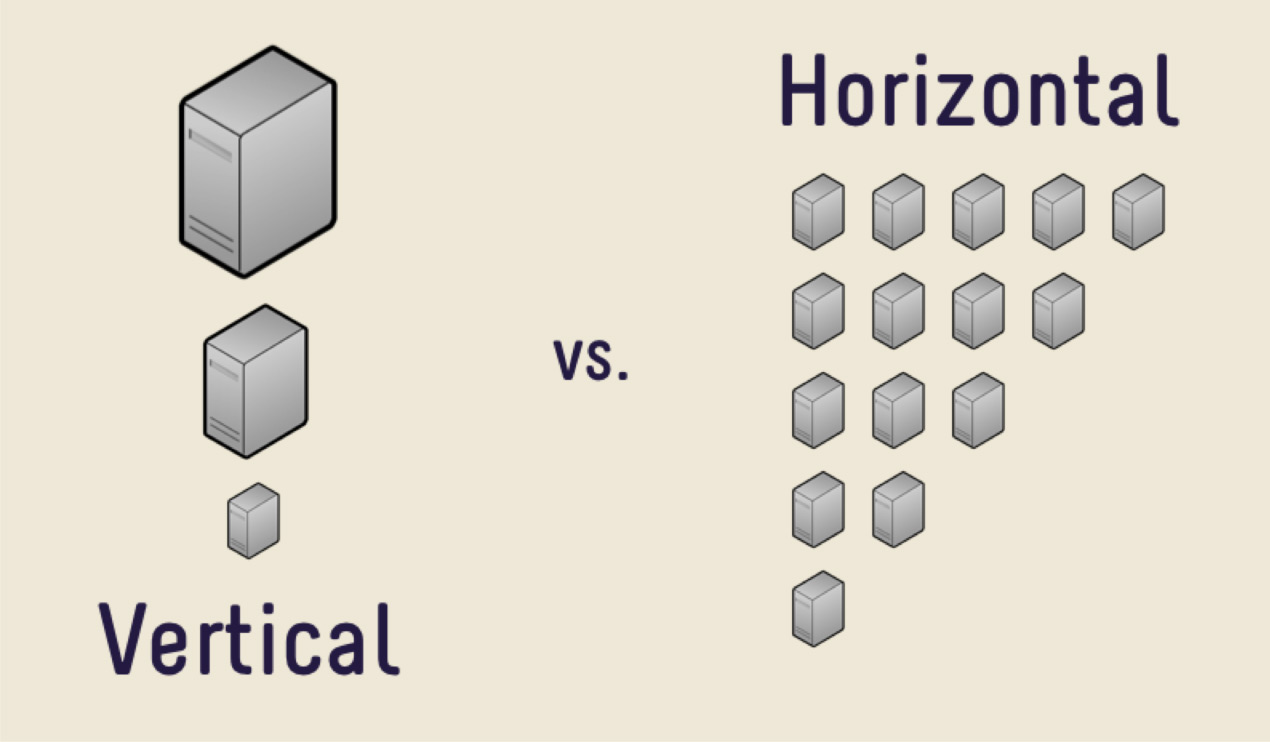
In solchen Fällen können Sie die horizontale Skalierung verwenden. Was wir zuvor gesehen haben, die Steigerung der Leistung pro Maschine, ist die vertikale Skalierung. Die Zunahme der Anzahl der Maschinen ist eine horizontale Skalierung.
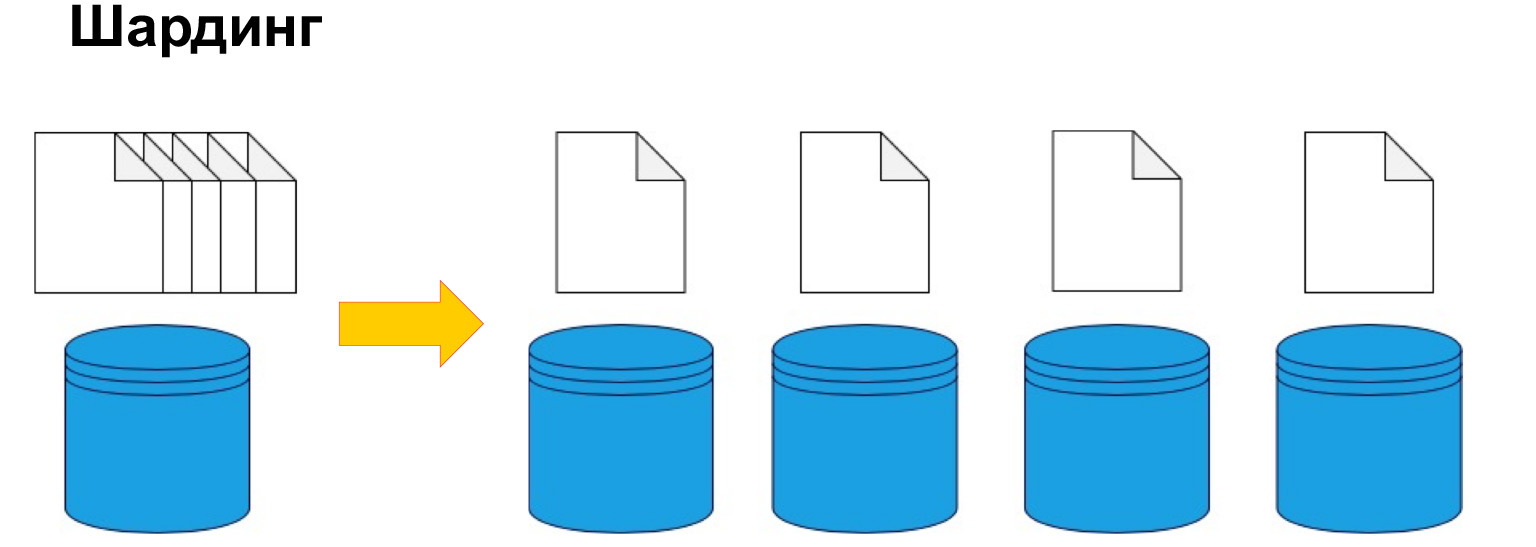
Um Daten nach Maschinen aufzuteilen, wird Sharding oder mit anderen Worten Partitionierung verwendet. Das heißt, Daten werden nach Schlüssel, ID und Datum in Abschnitte und Blöcke aufgeteilt. Wir werden weiter darüber sprechen, dies ist einer der Schlüsselparameter, aber es geht genau darum, die Daten nach einem bestimmten Kriterium zu teilen und an verschiedene Maschinen zu senden. Dadurch werden unsere Maschinen möglicherweise weniger effizient, aber das System kann weiterhin funktionieren und Daten von verschiedenen Maschinen empfangen.
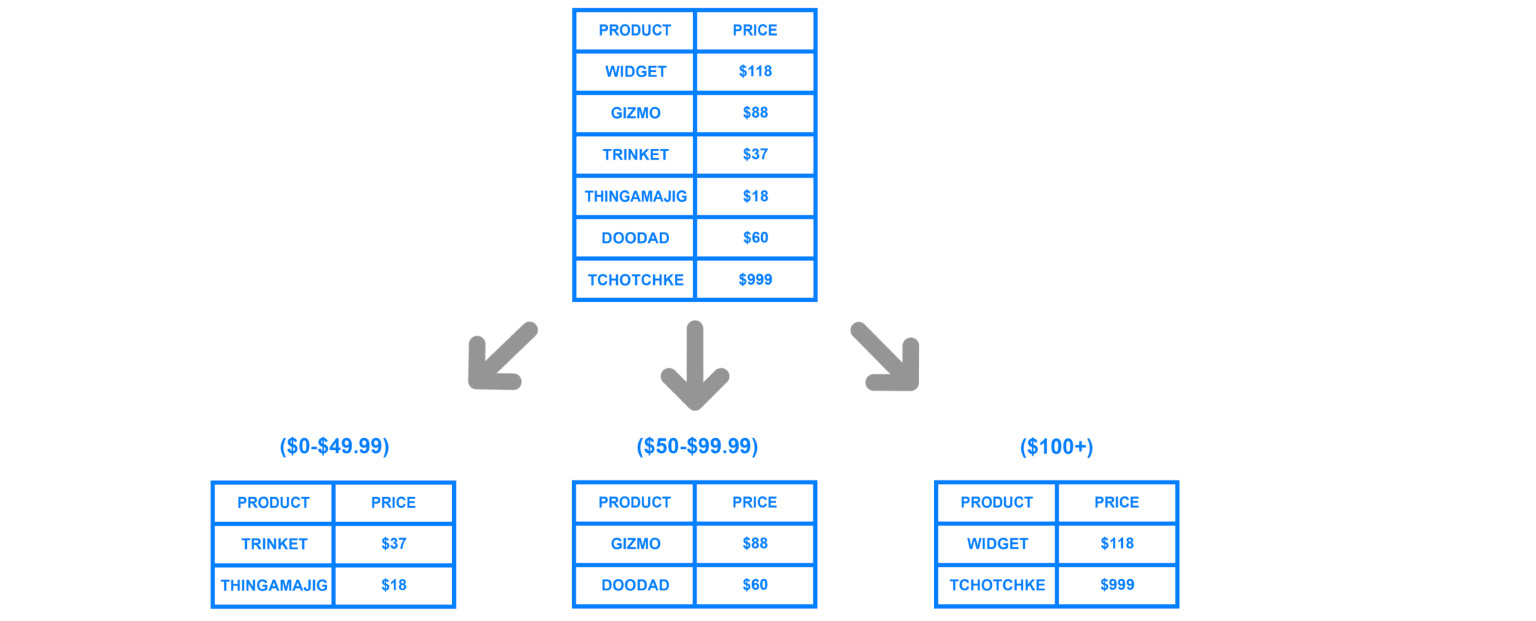
Um allgemein zu verstehen, wo sich die Daten befinden, benötigen Sie eine bestimmte Korrespondenztabelle des Shards, unserer Kopie und der Daten.
Es gibt Zeiten, in denen ein spezieller Datenspeicher nicht verwendet wird und der Client einfach nacheinander durch jeden Shard geht und prüft, ob Daten vorhanden sind, die seiner Anforderung entsprechen.
Es gibt eine spezielle Softwareschicht, die bestimmte Kenntnisse darüber speichert, welcher Shard sich in welchem Datenbereich befindet. Und dementsprechend geht es genau dort zu dem Knoten, an dem sich die erforderlichen Daten befinden.

Es gibt einen fetten Kunden. Dies ist der Fall, wenn wir den Kunden nicht selbst in eine separate Schicht nähen, sondern die Daten darüber, wie unsere Daten gespeichert werden, in ihn nähen.
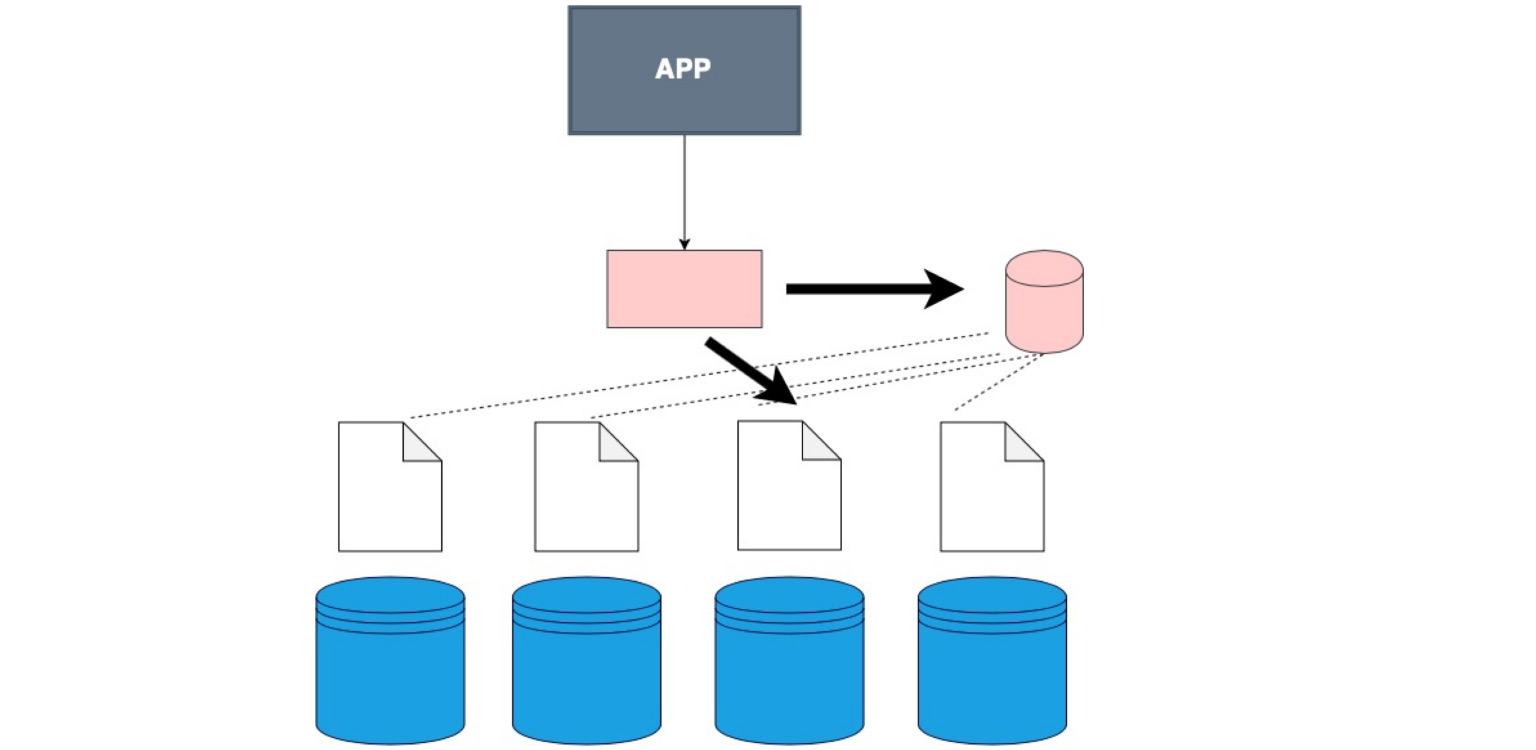
Das ist der Fall. Übrigens ist es das am häufigsten verwendete. Das Gute ist, dass unsere Anwendung, unser Client, selbst der von Ihnen geschriebene Code, nicht weiß, dass die Tabelle gespalten ist, obwohl wir dies in der Konfiguration in der Datenbank selbst angeben. Wir sagen ihr nur - wählen Sie aus, und bereits in der Datenbank selbst gibt es eine Unterteilung in Shards und ein Verständnis dafür, wo Sie auswählen können. Hier definieren Sie im Code selbst, wo die Daten gelesen werden sollen.
Es gibt spezielle Dienste, mit denen Informationen strukturiert und allgemein aktualisiert werden können. Es ist schwierig, es konsistent und relevant zu halten. Wir haben etwas ausgewählt, neue Daten aufgenommen. Oder etwas hat sich geändert und wir müssen unsere Anfragen sehr korrekt weiterleiten. Es gibt spezielle Dienste zur Koordination von Anfragen. Einer von ihnen ist Zookeper. Sie können sehen, wie sie im Allgemeinen funktionieren. Eine sehr interessante Struktur. Sie haben den Entwicklern viel Nerven und Zeit gespart.
Was ist wichtig, welche Aspekte sind beim Partitionieren zu beachten? Es ist wichtig zu verstehen, welchen Schlüssel wir verwenden, um in Scherben aufzuteilen. Das erneute Sammeln all dieser Daten ist ziemlich teuer, daher ist es sehr wichtig, sich nicht zu irren, wie die Daten möglicherweise in Zukunft verwendet werden. Wenn wir das Sharding gut und korrekt durchgeführt haben, wissen wir bei den am häufigsten verwendeten Abfragen immer, zu welchem Replikat wir gehen müssen.
Wenn wir beispielsweise gemäß den Benutzer-IDs alle ihre Daten auf bestimmten Replikaten speichern, verstehen wir, dass wir zu diesem einen Replikat kommen und alle Verknüpfungen darauf durchführen können. Aber es ist nicht die coolste Idee, es nach Ausweis zu behalten. Jetzt sage ich dir warum.
Wenn wir den Schlüssel in der Partitionierung falsch identifiziert haben und eine sehr komplexe Abfrage haben, müssen wir wirklich zu verschiedenen Shards gehen, alle Daten kombinieren und erst dann an die Anwendung weitergeben. Glücklicherweise tun dies die meisten DBMS für uns. Aber welche Art von Overhead würde bei schlecht geschriebenen Anfragen anfallen? Oder unter Sharding, was am falschen Knoten kaputt ist?
Über IDs. Wenn das System nur mit neuen Benutzern funktioniert und die IDs erhöht sind, werden alle Anforderungen an den letzten Knoten gesendet.
Was geschieht? Die anderen drei laufenden Maschinen stehen still. Und dieses Auto wird einfach brennen - der sogenannte Hot Spot. Dies ist der Engpass Ihres potenziellen Systems, der möglicherweise sogar Verbindungen verweigert.
Wenn wir den Sharding-Schlüssel definieren, ist es daher sehr wichtig zu verstehen, wie ausgeglichen diese Knoten sind. Hashes werden sehr oft verwendet, dies ist eine mehr oder weniger neutrale, ausgewogene Anordnung von Daten. Wenn Sie jedoch eine Hash-Funktion für eine Taste haben, können Sie beispielsweise keine Bereiche auswählen. Dies ist logisch, da die Bereiche nicht auf verschiedene Shards verteilt werden können.
Nach Datum - das gleiche. Wenn wir zum Beispiel Analysen streuen und Shards nach Datum erstellen, wird natürlich ein Shard vor zehn Jahren überhaupt nicht verwendet. Es ist für uns nicht rentabel. Und es ist immer sehr teuer, die Daten neu zu erstellen und zu überlasten.
Ich werde die vorhergehende Frage beantworten. Ist es besser, Indizes zu definieren oder Shards zu erstellen? Indizes natürlich.
Schauen Sie, Shards sind separate Maschinen mit einer ganzen erhöhten Infrastruktur. Und diese mittlere Komponente enthält so etwas wie Indizes. Es gibt eine schnelle Suche nach Parametern - wohin, wohin. Hier ist das Verhältnis. Aber wenn es Scherben gibt, wird das endgültige Bild so aussehen:

Es gibt Anwendungen, eine Art Kopf, der weiß, wohin er gehen soll. Und es gibt Shards, auf denen jeweils ein Replikat konfiguriert ist. Dies ist ein sehr großer Aufwand, wenn nicht viele Daten vorhanden sind. Das heißt, Sie müssen nur dann auf Sharding zurückgreifen, wenn Sie die vertikale Skalierungsgrenze tatsächlich erreicht haben und der Kauf einer teureren Maschine für Ihre Daten oder Ihr Einkommen nicht relevant ist. Dann können Sie mehrere verschiedene, billigere Autos kaufen und eine solche Architektur darauf bauen.
Ich denke, es ist klar, wofür Replikate gedacht sind: Weil Shards kaputt sind, sind sie Teile von Datenbanken, aber sie sind irgendwie einzigartig. Sie sind nur an diesen Orten zu finden. Wir zerlegen sie auch in Kopien, die unsere Knoten fehlertolerant machen und gegen Probleme versichern.

Das Wichtigste: Sharding wird genau dort eingesetzt, wo Sie die Daten nicht nur in Klassifikationen aufteilen möchten, sondern genau dort, wo wirklich viele Daten vorhanden sind.
Kommen wir nun zu Datenmodellen und sehen, wie Daten gespeichert werden können.
Die relationalen Datenbanken, die wir uns zuvor angesehen haben, haben eine Vielzahl von Vorteilen, da sie zuallererst sehr häufig und für alle verständlich sind. Sie zeigen visuell die Beziehung zwischen Objekten und sorgen für Integrität.
Aber es gibt einen Nachteil: Sie erfordern eine klare Struktur. Es gibt eine Tabelle, in der wir alle Daten pushen müssen. Wenn Sie sich alle Informationen und Fakten ansehen, die wir im Allgemeinen sammeln, sind sie sehr unterschiedlich. Das heißt, wir können mit Produktdaten, Benutzerdaten, Nachrichten usw. arbeiten. Diese Daten erfordern wirklich eine klare Struktur, Integrität. Eine relationale Datenbank ist ideal für sie.
Angenommen, wir haben zum Beispiel ein Protokoll von Operationen oder eine Beschreibung von Objekten, wobei jedes Objekt unterschiedliche Eigenschaften hat. Wir können dies natürlich in einem Jason in einer relationalen Datenbank aufschreiben und sind froh, dass es mit uns endlos wächst.
Und wir können uns andere Schemata und andere Speichersysteme ansehen. NoSQL ist eine sehr auffällige Abkürzung, sogar direkt provokativ - "no SQL". Wie kam es dazu?
Als die Leute mit der Tatsache konfrontiert wurden, dass relationale Datenbanken nicht überall erfolgreich sind, stellten sie eine Konferenz zusammen, für die ein Hashtag erforderlich war, und entwickelten daher #NoSQL. Es hat Wurzeln geschlagen. Später sagten sie nicht "kein SQL", sondern "nicht nur SQL". Es ist einfach alles, was nicht relational ist: eine riesige Familie verschiedener Datenbanken, die nicht so starr strukturiert, schematisch und tabellarisch sind wie relationale Datenbanken.
Die Familie der nicht relationalen Datenmodelle ist in vier Typen unterteilt: Schlüsselwert-, dokumentenorientierte, Spalten- und Diagrammdatenbanken. Betrachten wir jeden dieser Punkte und finden Sie heraus, welche Daten in welchen besser gespeichert werden können und wofür sie verwendet werden.

Schlüsselwert. Das ist das einfachste. Hier ist das Wörterbuch, hier ist das Verhältnis. Dies ist eine Datenbank, in der Daten durch Schlüssel gespeichert werden, und es spielt keine Rolle, was sich unter einem bestimmten Schlüssel befindet. Wir haben sowohl den Schlüssel selbst als auch die Daten können sowohl einfache als auch viel komplexere Strukturen sein. Das Gute an einer solchen Datenbank ist, dass sie wie ein Index sehr schnell nach Daten sucht. Aus diesem Grund wird der Schlüsselwert sehr häufig für den Cache verwendet. Der Vorteil ist, dass unser Wert in verschiedenen Schlüsseln unterschiedlich sein kann.
Mit dem Schlüssel können wir beispielsweise Benutzersitzungen speichern. Der Benutzer hat geklickt, wir haben dies in Wert geschrieben. Es ist ein Schema, ein Datenmodell ohne ein bestimmtes Schema, eine bestimmte Wertestruktur. Da es sich um eine sehr einfache Struktur handelt, ist sie schnell und einfach zu skalieren. Wir haben bereits die Schlüssel, und wir können sie sehr leicht zerschneiden, ihre Hashes machen. Es ist eine der am besten skalierbaren Datenbanken.
Beispiele sind Redis, Memcached, Amazon DynamoDB, Riak, LevelDB. Sie können die Implementierungsfunktionen von Schlüsselwertspeichern anzeigen.

Dokumentendatenbanken sind in einigen ihrer Verwendungen dem Schlüsselwert sehr ähnlich. Aber ihre Einheit ist ein Dokument. Dies ist eine so komplexe Struktur, mit der wir bestimmte Daten auswählen und Massenoperationen ausführen können: Masseneinfügung, Massenaktualisierung.
Jedes Dokument kann in der Regel XML, JSON oder BSON - binär gespeichertes JSON - in sich speichern. Aber jetzt ist es fast immer JSON oder BSON. Dies ist auch wie ein Schlüssel-Wert-Paar. Sie können es sich als eine Tabelle vorstellen, in der jede Zeile bestimmte Eigenschaften aufweist, und wir können mit diesen Schlüsseln etwas daraus ziehen.
Der Vorteil dokumentenorientierter Datenbanken besteht darin, dass sie eine sehr hohe Datenverfügbarkeit und Flexibilität aufweisen. In jedem Dokument, in jedem JSON können Sie absolut jeden Datensatz schreiben. Und sie werden sehr häufig verwendet - zum Beispiel, wenn Sie einen Katalog erstellen müssen und wenn jedes Produkt im Katalog unterschiedliche Eigenschaften haben kann.
Oder zum Beispiel Benutzerprofile. Jemand wies auf seinen Lieblingsfilm hin, jemand - auf sein Lieblingsessen. Um nicht alles in ein Feld zu stecken, in dem es nicht klar ist, was, können wir alles in JSON einer Dokumentbasis schreiben.
Ein weiteres Modell, das zum Speichern von Daten geeignet ist, sind Säulendatenbanken. Sie werden auch als Spalten- und Spaltendatenbank bezeichnet.

Dies ist eine sehr interessante Struktur, die meines Erachtens in fast allen großen und komplexen Projekten verwendet wird. Eine solche Datenbank impliziert, dass wir Daten auf der Festplatte nicht in Zeilen, sondern in Spalten speichern. Wird für sehr schnelle Suchvorgänge über eine große Datenmenge verwendet. In der Regel - für Analysen, wenn Sie nur Werte aus bestimmten Spalten auswählen müssen.
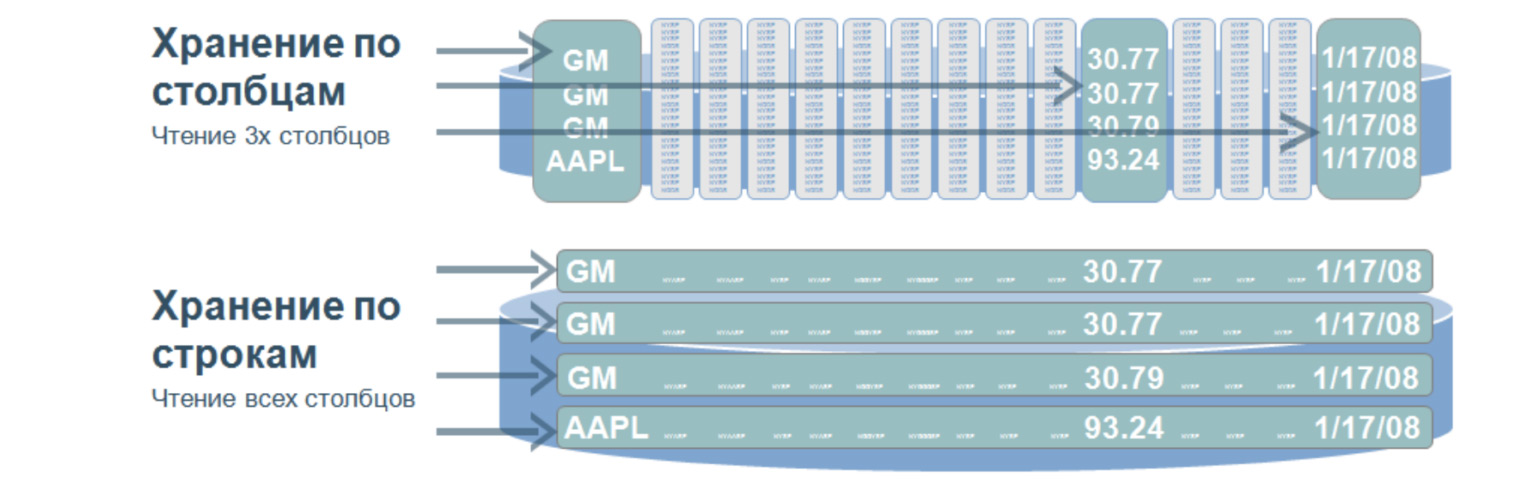
Stellen wir uns vor, wir haben einen riesigen Tisch. Und wenn wir Daten in Zeilen speichern würden, wäre es das Folgende: eine große Anzahl von Zeilen. Um auch nur drei Parameter dieser Tabelle auszuwählen, müssen wir die gesamte Tabelle durchgehen. Und wenn wir Werte nach Spalten speichern und dann nach drei Werten auswählen, müssen wir nur drei solcher, grob gesagt, Zeilen durchgehen, da unsere Spalten so geschrieben sind. Wenn wir diese drei Zeilen durchlaufen, erhalten wir sofort die Ordnungszahl des benötigten Werts und erhalten sie aus den anderen Spalten.
Was ist der Vorteil solcher Datenbanken? Aufgrund der Tatsache, dass sie nach einer kleinen Datenmenge suchen, haben sie eine sehr hohe Abfrageverarbeitungsgeschwindigkeit und eine große Datenflexibilität, da wir eine beliebige Anzahl von Spalten hinzufügen können, ohne die Struktur zu ändern. Hier müssen wir, anders als in relationalen Datenbanken, unsere Daten nicht in bestimmte Frames zwingen.
Die beliebtesten Säulen sind wahrscheinlich Cassandra, HBase und ClickHouse. Testen Sie sie. Es ist sehr interessant, das Verhältnis von Zeilen und Spalten in Ihrem Kopf umzukehren. Und das ist ein wirklich effizienter und schneller Zugriff auf große Datenmengen.

Es gibt auch eine Familie von Diagrammdatenbanken. Sie enthalten auch Knoten und Kanten. Kanten werden verwendet, um Beziehungen anzuzeigen, genau wie in relationalen Datenbanken. Aber Graphbasen können unendlich in verschiedene Richtungen wachsen. Daher ist es flexibler. Es hat eine sehr hohe Suchgeschwindigkeit, da nicht alle Tabellen ausgewählt und verknüpft werden müssen. Unser Knoten hat sofort Kanten, die die Beziehung zu allen verschiedenen Objekten anzeigen.
Wofür werden diese Datenbanken verwendet? Meistens - nur um die Beziehung zu zeigen. In sozialen Netzwerken können Sie beispielsweise die Frage beantworten, wer wem folgt. Wir haben sofort Links zu allen Followern der richtigen Person. Diese Datenbanken werden immer noch sehr häufig zur Identifizierung von Betrugsprogrammen verwendet, da dies auch mit dem Nachweis der Beziehung von Transaktionen untereinander verbunden ist. Sie können beispielsweise verfolgen, wann dieselbe Bankkarte in einer anderen Stadt verwendet wurde oder wann eine andere Person das Konto eines anderen Benutzers von derselben IP-Adresse aus eingegeben hat.
Es sind diese komplexen Beziehungen, die zur Lösung ungewöhnlicher Situationen beitragen, die häufig zur Analyse solcher Interaktionen und Beziehungen verwendet werden.
Nicht relationale Datenbanken ersetzen keine relationalen Datenbanken. Sie sind einfach anders. Unterschiedliches Datenformat und unterschiedliche Logik ihrer Arbeit, nicht schlechter und nicht besser. Es ist nur ein anderer Ansatz für andere Daten. Und ja, nicht relationale Datenbanken werden häufig verwendet. Sie müssen keine Angst vor ihnen haben, im Gegenteil, Sie müssen sie ausprobieren.
Wenn Sie einen Cache erstellen, nehmen Sie natürlich eine Art Redis, einen einfachen und schnellen Schlüsselwert. Wenn Sie eine große Anzahl von Protokollen zur Analyse haben, können Sie diese in ClickHouse oder in eine Spaltenbasis ablegen, die dann sehr bequem zu durchsuchen ist. Oder schreiben Sie es in die Dokumentbasis, da Dokumente unterschiedliche Bedeutungen haben können. Dies kann auch bei der Auswahl hilfreich sein.
Wählen Sie ein Datenmodell basierend auf den Daten, die Sie verwenden werden. Entweder relational oder nicht relational. Beschreiben Sie die Daten. Auf diese Weise finden Sie den am besten geeigneten Speicher, den Sie in Zukunft skalieren können.

Heute haben Sie viel über eine Vielzahl von Problemen und Möglichkeiten zum Speichern von Daten gelernt. Ich werde noch einmal wiederholen, was ich ganz am Anfang gesagt habe: Sie müssen nicht alles im Detail wissen, Sie müssen sich nicht mit einer Sache befassen. Wenn Sie interessiert sind, können Sie natürlich. Es ist jedoch wichtig zu wissen, dass es im Allgemeinen existiert, welche Ansätze es gibt und wie Sie im Allgemeinen denken können. Wenn Sie Fehlertoleranz benötigen, ist es sinnvoll, eine Replik zu erstellen. Angenommen, ich habe die Daten aufgeschrieben, aber nicht gesehen. Dann gab meine Bemerkung wahrscheinlich eine Verzögerung. Das Rad muss nicht neu erfunden werden - es gibt bereits viele vorgefertigte Lösungen für verschiedene Aufgaben. Erweitern Sie Ihren Horizont, und wenn ein Fehler oder ein anderes Problem auftritt, werden Sie anhand der Merkmale des Fehlers genau verstehen, wo der Fehler aufgetreten ist, und Sie können über eine Suchmaschine eine Lösung finden. Vielen Dank für Ihre Aufmerksamkeit.