In diesem Artikel geht es um diese Nuance.
Ich verwende Selen wie gewohnt und nach dem ersten Klick auf den Link, auf dem sich die erforderliche Tabelle mit den Wahlergebnissen der Republik Tatarstan befindet, stürzt es ab

Wie Sie verstehen, liegt die Nuance in der Tatsache, dass nach jedem Klick auf den Link ein Captcha angezeigt wird.
Nach Analyse der Struktur der Site wurde festgestellt, dass die Anzahl der Links etwa 30.000 erreicht.
Ich hatte keine andere Wahl, als im Internet nach Möglichkeiten zu suchen, Captcha zu erkennen. Ich habe festgestellt, dass ein Dienst
+ Captcha zu 100% erkannt wird, genau wie eine Person.
Die durchschnittliche Erkennungszeit beträgt 9 Sekunden, was sehr lang ist, da wir ungefähr 30.000 verschiedene Links haben, über die wir das Captcha erkennen müssen.
Ich habe diese Idee sofort aufgegeben. Nach mehreren Versuchen, das Captcha zu bekommen, bemerkte ich, dass es sich nicht viel ändert, alle gleichen schwarzen Zahlen auf grünem Hintergrund.
Und da ich schon lange den "Vision Computer" mit meinen Händen berühren wollte, entschied ich, dass ich eine großartige Chance hatte, das Lieblings-MNIST-Problem aller selbst auszuprobieren.
Es war bereits 17:00 Uhr und ich suchte nach vorgefertigten Modellen zum Erkennen von Zahlen. Nachdem ich sie auf diesem Captcha überprüft hatte, hat mich die Genauigkeit nicht befriedigt - nun, es ist Zeit, Bilder zu sammeln und Ihr neuronales Netzwerk zu trainieren.
Zunächst müssen Sie ein Trainingsmuster sammeln.
Ich öffne den Chrome-Webtreiber und überprüfe 1000 Captchas in meinem Ordner.
from selenium import webdriver
i = 1000
driver = webdriver.Chrome('/Users/aleksejkudrasov/Downloads/chromedriver')
while i>0:
driver.get('http://www.vybory.izbirkom.ru/region/izbirkom?action=show&vrn=4274007421995®ion=27&prver=0&pronetvd=0')
time.sleep(0.5)
with open(str(i)+'.png', 'wb') as file:
file.write(driver.find_element_by_xpath('//*[@id="captchaImg"]').screenshot_as_png)
i = i - 1Da wir nur zwei Farben haben, habe ich unsere Captchas in bw konvertiert:
from operator import itemgetter, attrgetter
from PIL import Image
import glob
list_img = glob.glob('path/*.png')
for img in list_img:
im = Image.open(img)
im = im.convert("P")
im2 = Image.new("P",im.size,255)
im = im.convert("P")
temp = {}
#
for x in range(im.size[1]):
for y in range(im.size[0]):
pix = im.getpixel((y,x))
temp[pix] = pix
if pix != 0:
im2.putpixel((y,x),0)
im2.save(img)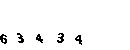
Jetzt müssen wir unsere Captchas in Zahlen schneiden und sie in eine einzelne Größe von 10 * 10 konvertieren.
Zuerst schneiden wir das Captcha in Zahlen, dann müssen wir, da das Captcha entlang der OY-Achse verschoben ist, alles Unnötige zuschneiden und das Bild um 90 ° drehen.
def crop(im2):
inletter = False
foundletter = False
start = 0
end = 0
count = 0
letters = []
name_slise=0
for y in range(im2.size[0]):
for x in range(im2.size[1]):
pix = im2.getpixel((y,x))
if pix != 255:
inletter = True
# OX
if foundletter == False and inletter == True:
foundletter = True
start = y
# OX
if foundletter == True and inletter == False:
foundletter = False
end = y
letters.append((start,end))
inletter = False
for letter in letters:
#
im3 = im2.crop(( letter[0] , 0, letter[1],im2.size[1] ))
# 90°
im3 = im3.transpose(Image.ROTATE_90)
letters1 = []
#
for y in range(im3.size[0]): # slice across
for x in range(im3.size[1]): # slice down
pix = im3.getpixel((y,x))
if pix != 255:
inletter = True
if foundletter == False and inletter == True:
foundletter = True
start = y
if foundletter == True and inletter == False:
foundletter = False
end = y
letters1.append((start,end))
inletter=False
for letter in letters1:
#
im4 = im3.crop(( letter[0] , 0, letter[1],im3.size[1] ))
#
im4 = im4.transpose(Image.ROTATE_270)
resized_img = im4.resize((10, 10), Image.ANTIALIAS)
resized_img.save(path+name_slise+'.png')
name_slise+=1
"Es ist schon Zeit, 18:00 Uhr, es ist Zeit, dieses Problem zu lösen", dachte ich und verteilte die Zahlen in den Ordnern mit ihren Zahlen auf dem Weg.
Wir deklarieren ein einfaches Modell, das eine erweiterte Matrix unseres Bildes als Eingabe akzeptiert.
Erstellen Sie dazu eine Eingabeebene mit 100 Neuronen, da die Bildgröße 10 * 10 beträgt. Als Ausgangsschicht gibt es 10 Neuronen, von denen jedes einer Ziffer von 0 bis 9 entspricht.
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout, Activation, BatchNormalization, AveragePooling2D
from tensorflow.keras.optimizers import SGD, RMSprop, Adam
def mnist_make_model(image_w: int, image_h: int):
# Neural network model
model = Sequential()
model.add(Dense(image_w*image_h, activation='relu', input_shape=(image_h*image_h)))
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=RMSprop(), metrics=['accuracy'])
return model
Wir teilen unsere Daten in Trainings- und Testsätze auf:
list_folder = ['0','1','2','3','4','5','6','7','8','9']
X_Digit = []
y_digit = []
for folder in list_folder:
for name in glob.glob('path'+folder+'/*.png'):
im2 = Image.open(name)
X_Digit.append(np.array(im2))
y_digit.append(folder)Wir haben es in Trainings- und Test-Sets aufgeteilt:
from sklearn.model_selection import train_test_split
X_Digit = np.array(X_Digit)
y_digit = np.array(y_digit)
X_train, X_test, y_train, y_test = train_test_split(X_Digit, y_digit, test_size=0.15, random_state=42)
train_data = X_train.reshape(X_train.shape[0], 10*10) # 100
test_data = X_test.reshape(X_test.shape[0], 10*10) # 100
# 10
num_classes = 10
train_labels_cat = keras.utils.to_categorical(y_train, num_classes)
test_labels_cat = keras.utils.to_categorical(y_test, num_classes)
Wir trainieren das Modell.
Wählen Sie empirisch die Parameter der Anzahl der Epochen und der Größe der "Charge" aus:
model = mnist_make_model(10,10)
model.fit(train_data, train_labels_cat, epochs=20, batch_size=32, verbose=1, validation_data=(test_data, test_labels_cat))
Wir sparen die Gewichte:
model.save_weights("model.h5")
Die Genauigkeit in der 11. Epoche erwies sich als ausgezeichnet: Genauigkeit = 1,0000. Zufrieden gehe ich um 19:00 Uhr nach Hause, um mich auszuruhen. Morgen muss ich noch einen Parser schreiben, um Informationen von der CEC-Website zu sammeln.
Morgen am nächsten Tag.
Die Angelegenheit blieb klein, es bleibt, alle Seiten der CEC-Website durchzugehen und die Daten aufzunehmen:
Laden Sie die Gewichte des trainierten Modells:
model = mnist_make_model(10,10)
model.load_weights('model.h5')
Wir schreiben eine Funktion, um das Captcha zu speichern:
def get_captcha(driver):
with open('snt.png', 'wb') as file:
file.write(driver.find_element_by_xpath('//*[@id="captchaImg"]').screenshot_as_png)
im2 = Image.open('path/snt.png')
return im2
Schreiben wir eine Funktion für die Captcha-Vorhersage:
def crop_predict(im):
list_cap = []
im = im.convert("P")
im2 = Image.new("P",im.size,255)
im = im.convert("P")
temp = {}
for x in range(im.size[1]):
for y in range(im.size[0]):
pix = im.getpixel((y,x))
temp[pix] = pix
if pix != 0:
im2.putpixel((y,x),0)
inletter = False
foundletter=False
start = 0
end = 0
count = 0
letters = []
for y in range(im2.size[0]):
for x in range(im2.size[1]):
pix = im2.getpixel((y,x))
if pix != 255:
inletter = True
if foundletter == False and inletter == True:
foundletter = True
start = y
if foundletter == True and inletter == False:
foundletter = False
end = y
letters.append((start,end))
inletter=False
for letter in letters:
im3 = im2.crop(( letter[0] , 0, letter[1],im2.size[1] ))
im3 = im3.transpose(Image.ROTATE_90)
letters1 = []
for y in range(im3.size[0]):
for x in range(im3.size[1]):
pix = im3.getpixel((y,x))
if pix != 255:
inletter = True
if foundletter == False and inletter == True:
foundletter = True
start = y
if foundletter == True and inletter == False:
foundletter = False
end = y
letters1.append((start,end))
inletter=False
for letter in letters1:
im4 = im3.crop(( letter[0] , 0, letter[1],im3.size[1] ))
im4 = im4.transpose(Image.ROTATE_270)
resized_img = im4.resize((10, 10), Image.ANTIALIAS)
img_arr = np.array(resized_img)/255
img_arr = img_arr.reshape((1, 10*10))
list_cap.append(model.predict_classes([img_arr])[0])
return ''.join([str(elem) for elem in list_cap])
Fügen Sie eine Funktion hinzu, die die Tabelle herunterlädt:
def get_table(driver):
html = driver.page_source #
soup = BeautifulSoup(html, 'html.parser') # " "
table_result = [] #
tbody = soup.find_all('tbody') #
list_tr = tbody[1].find_all('tr') #
ful_name = list_tr[0].text #
for table in list_tr[3].find_all('table'): #
if len(table.find_all('tr'))>5: #
for tr in table.find_all('tr'): #
snt_tr = []#
for td in tr.find_all('td'):
snt_tr.append(td.text.strip())#
table_result.append(snt_tr)#
return (ful_name, pd.DataFrame(table_result, columns = ['index', 'name','count']))
Wir sammeln alle Links für den 13. September:
df_table = []
driver.get('http://www.vybory.izbirkom.ru')
driver.find_element_by_xpath('/html/body/table[2]/tbody/tr[2]/td/center/table/tbody/tr[2]/td/div/table/tbody/tr[3]/td[3]').click()
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
list_a = soup.find_all('table')[1].find_all('a')
for a in list_a:
name = a.text
link = a['href']
df_table.append([name,link])
df_table = pd.DataFrame(df_table, columns = ['name','link'])
Um 13:00 Uhr beende ich das Schreiben des Codes mit einer Durchquerung aller Seiten:
result_df = []
for index, line in df_table.iterrows():#
driver.get(line['link'])#
time.sleep(0.6)
try:#
captcha = crop(get_captcha(driver))
driver.find_element_by_xpath('//*[@id="captcha"]').send_keys(captcha)
driver.find_element_by_xpath('//*[@id="send"]').click()
time.sleep(0.6)
true_cap(driver)
except NoSuchElementException:#
pass
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
if soup.find('select') is None:#
time.sleep(0.6)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
for i in range(len(soup.find_all('tr'))):#
if '\n \n' == soup.find_all('tr')[i].text:# ,
rez_link = soup.find_all('tr')[i+1].find('a')['href']
driver.get(rez_link)
time.sleep(0.6)
try:
captcha = crop(get_captcha(driver))
driver.find_element_by_xpath('//*[@id="captcha"]').send_keys(captcha)
driver.find_element_by_xpath('//*[@id="send"]').click()
time.sleep(0.6)
true_cap(driver)
except NoSuchElementException:
pass
ful_name , table = get_table(driver)#
head_name = line['name']
child_name = ''
result_df.append([line['name'],line['link'],rez_link,head_name,child_name,ful_name,table])
else:# ,
options = soup.find('select').find_all('option')
for option in options:
if option.text == '---':#
continue
else:
link = option['value']
head_name = option.text
driver.get(link)
try:
time.sleep(0.6)
captcha = crop(get_captcha(driver))
driver.find_element_by_xpath('//*[@id="captcha"]').send_keys(captcha)
driver.find_element_by_xpath('//*[@id="send"]').click()
time.sleep(0.6)
true_cap(driver)
except NoSuchElementException:
pass
html2 = driver.page_source
second_soup = BeautifulSoup(html2, 'html.parser')
for i in range(len(second_soup.find_all('tr'))):
if '\n \n' == second_soup.find_all('tr')[i].text:
rez_link = second_soup.find_all('tr')[i+1].find('a')['href']
driver.get(rez_link)
try:
time.sleep(0.6)
captcha = crop(get_captcha(driver))
driver.find_element_by_xpath('//*[@id="captcha"]').send_keys(captcha)
driver.find_element_by_xpath('//*[@id="send"]').click()
time.sleep(0.6)
true_cap(driver)
except NoSuchElementException:
pass
ful_name , table = get_table(driver)
child_name = ''
result_df.append([line['name'],line['link'],rez_link,head_name,child_name,ful_name,table])
if second_soup.find('select') is None:
continue
else:
options_2 = second_soup.find('select').find_all('option')
for option_2 in options_2:
if option_2.text == '---':
continue
else:
link_2 = option_2['value']
child_name = option_2.text
driver.get(link_2)
try:
time.sleep(0.6)
captcha = crop(get_captcha(driver))
driver.find_element_by_xpath('//*[@id="captcha"]').send_keys(captcha)
driver.find_element_by_xpath('//*[@id="send"]').click()
time.sleep(0.6)
true_cap(driver)
except NoSuchElementException:
pass
html3 = driver.page_source
thrid_soup = BeautifulSoup(html3, 'html.parser')
for i in range(len(thrid_soup.find_all('tr'))):
if '\n \n' == thrid_soup.find_all('tr')[i].text:
rez_link = thrid_soup.find_all('tr')[i+1].find('a')['href']
driver.get(rez_link)
try:
time.sleep(0.6)
captcha = crop(get_captcha(driver))
driver.find_element_by_xpath('//*[@id="captcha"]').send_keys(captcha)
driver.find_element_by_xpath('//*[@id="send"]').click()
time.sleep(0.6)
true_cap(driver)
except NoSuchElementException:
pass
ful_name , table = get_table(driver)
result_df.append([line['name'],line['link'],rez_link,head_name,child_name,ful_name,table])
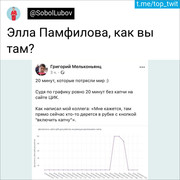
Und dann kommt der Tweet, der mein Leben verändert hat