
Amazon SageMaker bietet mehr als nur die Möglichkeit, Notebooks in Jupyter zu verwalten, sondern einen konfigurierbaren Dienst, mit dem Sie Modelle für maschinelles Lernen erstellen, trainieren, optimieren und bereitstellen können. Ein häufiges Missverständnis, insbesondere wenn Sie mit SageMaker beginnen, ist, dass Sie SageMaker Notebook Instance oder SageMaker (Studio) Notebook benötigen, um diese Dienste nutzen zu können. Tatsächlich können Sie alle Dienste direkt von Ihrem lokalen Computer oder sogar Ihrer bevorzugten IDE ausführen.
Bevor wir fortfahren, wollen wir verstehen, wie Sie mit Amazon SageMaker-Diensten interagieren. Sie haben zwei APIs:
SageMaker Python SDK - Eine Python-API auf hoher Ebene, die Code zum Erstellen , Trainieren und Bereitstellen von Modellen für maschinelles Lernen abstrahiert. Insbesondere bietet es Evaluatoren für erstklassige oder integrierte Algorithmen und unterstützt auch Frameworks wie TensorFlow, MXNET usw. In den meisten Fällen verwenden Sie es, um mit interaktiven maschinellen Lernaufgaben zu interagieren.
AWS SDKIst eine Low-Level-API, die für die Interaktion mit allen unterstützten AWS-Services verwendet wird, nicht unbedingt für SageMaker. AWS SDK ist für die gängigsten Sprachen wie Java, Javascript, Python (Boto) usw. verfügbar. In den meisten Fällen verwenden Sie diese API beispielsweise zum Erstellen von Automatisierungsressourcen oder zur Interaktion mit anderen AWS-Diensten, die vom SageMaker Python SDK nicht unterstützt werden.
Warum lokale Umgebung?
Die Kosten sind das erste, was Ihnen in den Sinn kommt, aber auch die Flexibilität bei der Verwendung Ihrer nativen IDE und die Möglichkeit, offline zu arbeiten und Aufgaben in der AWS-Cloud auszuführen, wenn Sie bereit sind.
Wie die lokale Umgebung funktioniert
Sie schreiben den Code zum Erstellen des Modells, aber anstelle einer Instanz von SageMake Notebook oder SageMaker Studio Notebook tun Sie dies auf Ihrem lokalen Computer in Jupyter oder über Ihre IDE. Wenn alles fertig ist, beginnen Sie mit dem Training für SageMaker-Instanzen in AWS. Nach dem Training wird das Modell in AWS gespeichert. Sie können dann die Bereitstellung oder Stapelkonvertierung von Ihrem lokalen Computer aus ausführen.
Einrichten der Umgebung mit conda
Es wird empfohlen, eine virtuelle Python-Umgebung einzurichten. In unserem Fall verwenden wir conda, um virtuelle Umgebungen zu verwalten, aber Sie können virtualenv verwenden. Wieder verwendet Amazon SageMaker conda, um Umgebungen und Pakete zu verwalten. Es wird davon ausgegangen, dass Sie bereits conda installiert haben. Wenn nicht, klicken Sie hier .
Erstellen Sie eine neue Conda-Umgebung
conda create -n sagemaker python=3Wir aktivieren und verifizieren die Umgebung

Installieren der erforderlichen Pakete
Verwenden Sie zum Installieren von Paketen die Befehle
condaoder pip. Lassen Sie uns die Option mit conda wählen .
conda install -y pandas numpy matplotlibAWS-Pakete installieren
Installieren Sie AWS SDK für Python (boto), awscli und SageMaker Python SDK. Das SageMaker Python SDK ist nicht als Conda-Paket verfügbar, daher verwenden wir es hier
pip.
pip install boto3 awscli sagemakerWenn Sie awscli zum ersten Mal verwenden, müssen Sie es konfigurieren. Hier können Sie sehen, wie es geht.
Die zweite Version des SageMaker Python SDK wird standardmäßig installiert. Stellen Sie sicher, dass in der zweiten Version des SDK nach Änderungen gesucht wird.
Jupyter installieren und den Kern erstellen
conda install -c conda-forge jupyterlab
python -m ipykernel install --user --name sagemakerWir überprüfen die Umgebung und überprüfen die Versionen
Starten Sie Jupyter über das Jupiter-Labor und wählen Sie den
sagemakeroben erstellten Kern aus.
Überprüfen Sie dann die Versionen im Notizbuch, um sicherzustellen, dass sie die gewünschten sind.
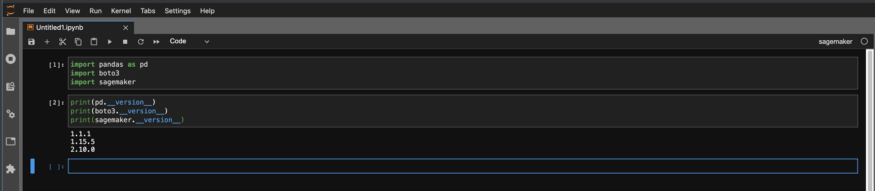
Wir kreieren und trainieren
Sie können jetzt mit dem lokalen Erstellen Ihres Modells beginnen und mit dem Lernen in AWS beginnen, wenn Sie bereit sind.
Pakete importieren
Importieren Sie die erforderlichen Pakete und geben Sie die Rolle an. Der Hauptunterschied besteht darin, dass Sie
arnRollen direkt angeben müssen , nicht get_execution_role(). Da Sie alles auf Ihrem lokalen Computer mit AWS-Anmeldeinformationen und nicht mit einer Notebook-Instanz mit einer Rolle ausführen get_execution_role(), funktioniert die Funktion nicht.
from sagemaker import image_uris # Use image_uris instead of get_image_uri
from sagemaker import TrainingInput # Use instead of sagemaker.session.s3_input
region = boto3.Session().region_name
container = image_uris.retrieve('image-classification',region)
bucket= 'your-bucket-name'
prefix = 'output'
SageMakerRole='arn:aws:iam::xxxxxxxxxx:role/service-role/AmazonSageMaker-ExecutionRole-20191208T093742'Erstellen Sie einen Gutachter
Erstellen Sie einen Evaluator und legen Sie die Hyperparameter wie gewohnt fest. Im folgenden Beispiel trainieren wir einen Bildklassifizierer mithilfe des integrierten Bildklassifizierungsalgorithmus. Sie geben auch den Typ der Stagemaker-Instanz und die Anzahl der Instanzen an, die Sie für das Training verwenden möchten.
s3_output_location = 's3://{}/output'.format(bucket, prefix)
classifier = sagemaker.estimator.Estimator(container,
role=SageMakerRole,
instance_count=1,
instance_type='ml.p2.xlarge',
volume_size = 50,
max_run = 360000,
input_mode= 'File',
output_path=s3_output_location)
classifier.set_hyperparameters(num_layers=152,
use_pretrained_model=0,
image_shape = "3,224,224",
num_classes=2,
mini_batch_size=32,
epochs=30,
learning_rate=0.01,
num_training_samples=963,
precision_dtype='float32')
Lernkanäle
Geben Sie die Lernkanäle so an, wie Sie es immer tun. Es gibt auch keine Änderungen im Vergleich dazu, wie Sie es auf Ihrer Notebook-Kopie tun würden.
train_data = TrainingInput(s3train, distribution='FullyReplicated',
content_type='application/x-image', s3_data_type='S3Prefix')
validation_data = TrainingInput(s3validation, distribution='FullyReplicated',
content_type='application/x-image', s3_data_type='S3Prefix')
train_data_lst = TrainingInput(s3train_lst, distribution='FullyReplicated',
content_type='application/x-image', s3_data_type='S3Prefix')
validation_data_lst = TrainingInput(s3validation_lst, distribution='FullyReplicated',
content_type='application/x-image', s3_data_type='S3Prefix')
data_channels = {'train': train_data, 'validation': validation_data,
'train_lst': train_data_lst, 'validation_lst': validation_data_lst}Wir fangen an zu trainieren
Starten Sie die Trainingsaufgabe in SageMaker, indem Sie die Fit-Methode aufrufen, mit der das Training für Ihre SageMaker AWS-Instanzen gestartet wird.
classifier.fit(inputs=data_channels, logs=True)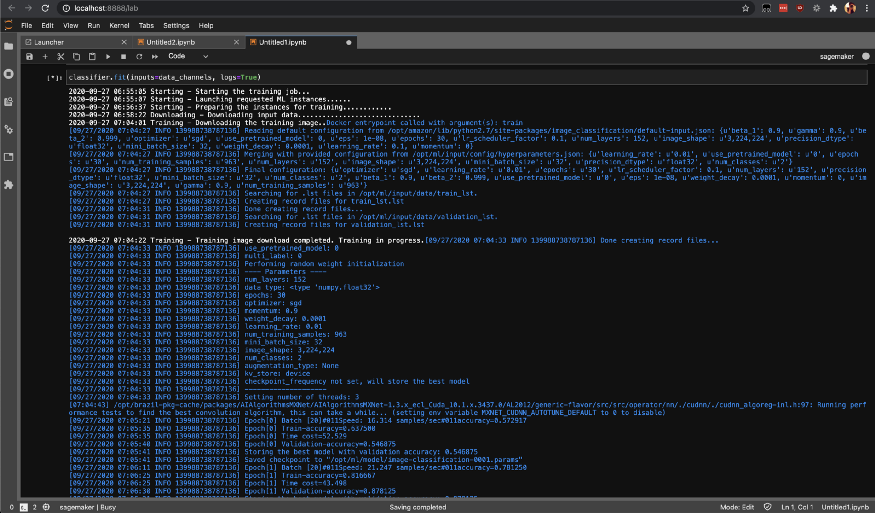
Sie können den Status von Schulungsjobs mit List-Training-Jobs überprüfen .
Das ist alles. Heute haben wir herausgefunden, wie die SageMaker-Umgebung lokal eingerichtet und mit Jupyter Modelle für maschinelles Lernen auf einem lokalen Computer erstellt werden können. Neben Jupyter können Sie dies auch über Ihre eigene IDE tun.
Viel Spaß beim Lernen!
