Es kommt oft vor, wenn viele Conversions stattfinden, der Preis akzeptabel ist und der Umsatz nicht wächst und nicht einmal fällt. Hier reichen Analysen "vor Gewinn pro Klick" nicht mehr aus, um den Grund herauszufinden. Und dann kommt die Analyse "vor dem Gewinn des Managers" zur Rettung. Denn egal wie ideal die Werbung aufgebaut ist, Kunden interagieren zuerst mit Managern und treffen erst dann eine Entscheidung. Der Erfolg Ihres Unternehmens hängt von der Qualität der Arbeit Ihrer Mitarbeiter ab.
Herkömmliche Analysesysteme verwenden CRM, um die Tatsache eines Verkaufs / Kontakts mit einem Manager aufzuzeichnen. Dieser Ansatz löst das Problem jedoch nur teilweise: Er bewertet die Effizienz des Mitarbeiters "unter dem Strich". Das heißt, es zeigt Verkäufe und Conversions, lässt aber die Kommunikation mit dem Kunden „über Bord“. Das Ergebnis hängt jedoch von der Kommunikationsstufe ab.
Um diese Lücke zu schließen, haben wir ein Tool entwickelt, das jeden Anruf automatisch mit dem Manager verknüpft, der ihn bearbeitet hat. Sie müssen keine CRM- und Drittanbieter-Services verwenden. Tatsächlich fügt unser System jedem eingehenden Anruf ein Tag "Managername" hinzu.
So werden die Leiter der Verkaufs- / Kundendienstabteilung die Qualität der Arbeit kontrollieren, Problembereiche finden und Analysen erstellen. Auf diese Weise können Anrufe schnell an die Manager segmentiert werden, die sie erhalten.
Formulierung des Problems
Die Aufgabe, die wir uns stellen, lautet wie folgt: Teilen Sie dem System die Sprachmuster aller Manager mit, die Anrufe empfangen können. Für einen neuen Anruf müssen Sie dann den Manager, dessen Stimme im Gespräch am "ähnlichsten" ist, aus der Liste der bekannten markieren.
In diesem Fall wird a priori davon ausgegangen, dass der neue Anruf erfolgreich ist. Das heißt, das Gespräch zwischen dem Manager und dem Kunden fand tatsächlich statt. Informell gesehen kann diese Aufgabe der Aufgabenklasse "Unterrichten mit einem Lehrer", dh der Klassifizierung, zugeordnet werden.
Als Objekte - in gewisser Weise vektorisierte (digitalisierte) Audioaufnahmen, bei denen nur die Stimme des Managers ertönt. Die Antworten sind Klassenbezeichnungen (Managernamen). Dann ist die Aufgabe des Markierungsalgorithmus:
- Extraktion aussagekräftiger Funktionen aus Audiodateien
- Auswahl des am besten geeigneten Klassifizierungsalgorithmus
- Erlernen des Algorithmus und Speichern von Manager-Modellen
- Bewertung der Qualität des Algorithmus und Änderung seiner Parameter
- Neue Anrufe markieren (klassifizieren)
Einige dieser Aufgaben fallen in separate Unteraufgaben. Dies ist auf die Besonderheiten der Bedingungen zurückzuführen, unter denen der Algorithmus arbeiten muss. Telefonanrufe sind normalerweise laut. Ein Kunde innerhalb eines Gesprächs kann mit mehreren Managern kommunizieren. Außerdem findet es überhaupt nicht statt, und Anrufe umfassen häufig IVR usw.
Die Aufgabe des Kennzeichnens neuer Anrufe kann beispielsweise unterteilt werden in:
- Überprüfen des Anrufs auf Erfolg (die Tatsache, dass ein Anruf vorliegt)
- Aufteilen von Stereo in Monospuren
- Rauschfilterung
- Identifizierung von Bereichen mit Sprache (Filtern von Musik und anderen Nebengeräuschen)
In Zukunft werden wir über jede solche Unteraufgabe separat sprechen. In der Zwischenzeit werden wir die technischen Einschränkungen formulieren, die wir den Eingabedaten, der resultierenden Lösung sowie dem Klassifizierungsalgorithmus selbst auferlegen.
Lösungsbeschränkungen
Die Notwendigkeit von Einschränkungen wird teilweise durch die Technik und die Anforderungen der Komplexität der Implementierung sowie durch das Gleichgewicht zwischen der Universalität des Algorithmus und der Genauigkeit seiner Funktionsweise bestimmt.
Einschränkungen für die Eingabedatei und die Trainingsbeispieldateien:
- Format - WAV oder Wave (Sie können weiter in MP3 umcodieren)
- Die Stereoanlage muss anschließend in zwei Spuren unterteilt werden - den Operator und den Client
- Abtastrate - 16.000 Hz und höher
- Bittiefe - ab 16 Bit
- Die Datei zum Trainieren des Modells muss mindestens 30 Sekunden lang sein und nur die Stimme eines bestimmten Managers enthalten
- , , ,
Alle oben genannten Anforderungen mit Ausnahme der letzten wurden als Ergebnis einer Reihe von Experimenten formuliert, die in der Phase der Einrichtung der Algorithmen durchgeführt wurden. Diese Kombination hat sich als am effektivsten erwiesen, um die Fehlerwahrscheinlichkeit zu minimieren, nämlich die Fehlklassifizierung unter nicht belastenden Abstimmungsbedingungen.
Zum Beispiel ist es offensichtlich, dass der Klassifikator umso genauer ist, je länger die Datei im Trainingssatz ist. Je schwieriger es jedoch ist, eine solche Datei im Anrufprotokoll (unserem Schulungsbeispiel) zu finden. Daher ist die Dauer von 30 Sekunden ein Kompromiss zwischen Genauigkeit und Komplexität der Einstellungen. Die letzte Voraussetzung (Erfolg) ist notwendig. Das System sollte einen Manager nicht mit einem Anruf versehen, bei dem tatsächlich keine Konversation stattgefunden hat.
Die Einschränkungen des Algorithmus führten zu folgender Lösung:
- , . « ». . - , .
- . , , .
Die erste Anforderung stammte aus Experimenten. Dann stellte sich heraus, dass der "unbekannte" Manager die Architektur der Lösung kompliziert. Hierzu müssen Schwellenwerte ausgewählt werden, nach denen der Mitarbeiter als „nicht anerkannt“ eingestuft wird. Außerdem reduziert der "unbekannte" Manager die Genauigkeit um 10 Prozentpunkte.
Außerdem tritt ein Fehler der zweiten Art auf, wenn ein bekannter Manager als unbekannt eingestuft wird. Die Wahrscheinlichkeit eines solchen Fehlers beträgt 7-10%, abhängig von der Anzahl der bekannten. Diese Anforderung kann als wesentlich bezeichnet werden. Der Algorithmus-Tuner ist verpflichtet, alle Manager im Trainingsbeispiel anzugeben. Fügen Sie dort auch Modelle neuer Mitarbeiter hinzu und entfernen Sie diejenigen, die gekündigt haben.
Die zweite Anforderung ergibt sich aus praktischen Überlegungen und der Architektur des von uns verwendeten Algorithmus. Kurz gesagt, der Algorithmus zerlegt das analysierte Audio in Sprachfragmente und "vergleicht" jedes einzeln mit allen trainierten Manager-Modellen.
Infolgedessen wird jedem der Mini-Fragmente ein "Mini-Tag" zugewiesen. Bei diesem Ansatz besteht eine hohe Wahrscheinlichkeit, dass einige der Fragmente falsch erkannt werden. Zum Beispiel, wenn sie laut bleiben oder ihre Länge zu kurz ist.
Wenn dann alle "Mini-Tags" in der endgültigen Lösung angezeigt werden, werden zusätzlich zum Tag des realen Managers viele "Papierkorb" -Tags angezeigt. Daher wird nur das "häufigste" Tag angezeigt.
Beschreibung der Eingabe- / Ausgabedaten
Wir werden die Eingabedaten in zwei Typen unterteilen:
Daten am Eingang des Algorithmus zum Generieren von Managermodellen (Daten für das Training):
- Audiodatei + Klassenbezeichnung
Daten am Eingang des Markierungsalgorithmus (Daten zum Testen / Normalbetrieb):
- Externe Daten (Audiodatei)
- Interne Daten (gespeicherte Modelle)
Die Ausgabe ist ebenfalls in zwei Typen unterteilt:
- Ausgabedaten des Modellgenerierungsalgorithmus
- Geschulte Manager-Modelle
- Ausgabe vom Tagging-Algorithmus
- Manager-Tag
Bei der Eingabe des Algorithmus wird in jedem Betriebsmodus eine Audiodatei empfangen, die die Anforderungen erfüllt. Sie befinden sich im Abschnitt "Einschränkungen".
Bei der Eingabe des Modellgenerierungsalgorithmus dürfen mehrere Eingabedateien einer Klasse (Manager) entsprechen. Eine Datei kann jedoch nicht mehreren Managern entsprechen. Der Name der Klassenbezeichnung kann in den Dateinamen eingefügt werden. Oder erstellen Sie einfach ein separates Verzeichnis für jeden Mitarbeiter.
Der auf Eingabedaten basierende Modelltrainingsalgorithmus generiert viele Modelle, die während des Trainings geladen werden können. Ihre Anzahl entspricht der Anzahl der verschiedenen Tags in den Audiodateien.
Wenn es also M Dateien gibt, die mit n markiert sind Mit verschiedenen Klassenbezeichnungen erstellt der Algorithmus n Modelle von Managern in der Schulungsphase:
- Model_manager_1.pkl
- Model_manager_2.pkl
- ...
- Model_manager_n.pkl
Dabei ist anstelle von " manager _... " der Name der Klasse.
Die Eingabe in den Tagging-Algorithmus ist eine unbeschriftete Audiodatei, in der a priori ein Gespräch zwischen einem Manager und einem Kunden sowie n Mitarbeitermodellen stattfindet. Infolgedessen gibt der Algorithmus ein Tag zurück - den Namen der Klasse des "plausibelsten" Managers.
Datenvorverarbeitung
Audiodateien werden vorverarbeitet. Es ist sequentiell und wird sowohl im Tagging-Modus als auch im Modelltrainingsmodus ausgeführt:
- Überprüfen des Anruferfolgs - nur in der Tagging-Phase
- Teilen Sie Stereo in 2 Monospuren auf und arbeiten Sie nur mit der Spur des Bedieners weiter
- Digitalisierung - Extraktion von Audiosignalparametern
- Rauschfilterung
- "Lange" Pausen entfernen - Fragmente mit Ton identifizieren
- Filtern von Nicht-Sprachfragmenten - Entfernen Sie Musik, Hintergrund usw.
- Fusion von Fragmenten mit Sprache (nur im Stadium des Trainings)
Wir werden uns nicht mit der Erfolgsprüfung befassen. Dies ist ein Thema für einen separaten Artikel. Kurz gesagt, das Wesentliche der Bühne ist, dass der Anruf danach klassifiziert wird, ob sich darin ein Gespräch über "lebende Menschen" befindet. Mit „lebenden Menschen“ meinen wir einen Kunden und einen Manager, keinen Sprachassistenten, keine Musik usw.
Der Erfolg eines Anrufs wird mithilfe eines speziell geschulten Klassifikators mit einem externen Schwellenwert überprüft - „die Mindestdauer eines Gesprächs, nach der der Anruf als erfolgreich angesehen wird“.
In der zweiten Phase wird die Stereodatei in zwei Spuren unterteilt: den Manager und den Client. Die Weiterverarbeitung erfolgt nur für die Spur des Mitarbeiters.
Im Stadium der Digitalisierung werden die Parameter des "Merkmals" aus der Bedienerspur extrahiert, die eine digitale Darstellung des Signals darstellen. Wir bei Calltouch verwendeten Kreide-Cepstral-Komponenten. Außerdem werden die Parameter in einem sehr kleinen Fragment extrahiert, das als Fensterbreite (0,025 Sekunden) bezeichnet wird. Alle Funktionen werden gleichzeitig normalisiert.
nfft=2048 //
appendEnergy = False
def get_MFCC(sr,audio): // , sr=16000 -
features = mfcc.mfcc(audio, sr, 0.025, 0.01, 13, 26, nfft, 0, 1000, appendEnergy)
features = preprocessing.scale(features)
return features
count = 1
features = np.asarray(()) //
for path in file_paths: //
path = path.strip()
sr,audio = read(source + path) //
vector = get_MFCC (sr, audio) #
if features.size == 0:
features = vector
else:
features = np.vstack((features, vector))Am Ausgang wird jede Audiodatei zu einem Array, in dem die Mel-Cepstral-Eigenschaften jedes 0,025-Sekunden-Fragments zeilenweise aufgezeichnet werden.
Die weitere Verarbeitung der Datei besteht darin, Rauschen zu filtern, lange Pausen (keine Pausen zwischen Tönen) zu entfernen und nach Sprache zu suchen. Diese Aufgaben können mit einer Vielzahl von Werkzeugen ausgeführt werden. In unserer Lösung verwendeten wir Methoden aus der Pyaudioanalyse-Bibliothek:
clear_noise(fname,outname,ch_n) # .- fname - Eingabedatei
- outname - Ausgabedatei
- ch_n - Anzahl der Kanäle
Am Ausgang erhalten wir den Datei-Outnamen, der den von Rauschen gereinigten Sound enthält, aus der Datei fname.
silenceRemoval(x, Fs, stWin, stStep) # « »- x - Eingangsarray (digitalisiertes Signal)
- Fs - Abtastrate
- stWin - Breite des Feature-Extraktionsfensters
- stStep - Versatzschrittgröße
Am Ausgang erhalten wir ein Array der Form:
[l_1, r_1]
[l_2, r_2]
[l_3, r_3]
…
[l_N, r_N]
wobei l_i die Startzeit des i-ten Segments (Sek.) Ist , r_i die Endzeit des i-ten Segments (Sek.) ).
detect_audio_segment(x,thrs) # .- x - Eingangsarray (digitalisiertes Signal)
- Stunden - Mindestlänge (in Sekunden) des erkannten Sprachfragments
Am Ausgang erhalten wir die Fragmente [l_i, r_i] , die eine Sprache von drei Sekunden enthalten.
Als Ergebnis der Vorverarbeitung wird die eingegebene Audiodatei in die Form eines Arrays konvertiert:
[l_1, r_1]
[l_2, r_2]
[l_3, r_3]
…
[l_N, r_N],
wobei jedes Fragment ein Zeitintervall der bereinigten Sprachdatei ist.
Somit können wir jedes dieser Fragmente mit einer Matrix von Merkmalen (klein-cepstrale Merkmale) abgleichen, die zum Trainieren des Modells und in der Markierungsphase verwendet werden.
Verwendete Methoden / Algorithmen
Wie oben erwähnt, basiert unsere Lösung auf der in Python 2.7 geschriebenen Bibliothek pyaudioanalysis.py. Aufgrund der Tatsache, dass unsere allgemeine Lösung in Python 3.7 implementiert ist, wurden einige der Bibliotheksfunktionen für diese Version der Sprache geändert und angepasst.
Im Allgemeinen kann der Algorithmus des Tools zum Kennzeichnen von Managern in zwei Teile unterteilt werden:
- Model Manager Training
- Markieren
Eine detailliertere Beschreibung jedes Teils sieht so aus.
Model Manager Training:
- Laden des Trainingsmusters
- Datenvorverarbeitung
- Anzahl der Klassen zählen
- Erstellen eines Manager-Modells für jede der Klassen
- Modell speichern
Tagging:
- Laden laden
- Überprüfen Sie den Aufruf zum Erfolg
- Vorverarbeitung eines erfolgreichen Anrufs
- Laden aller geschulten Manager-Modelle
- Klassifizierung jedes Fragments des verarbeiteten Anrufs
- Das wahrscheinlichste Manager-Modell finden
- Markieren
Die Aufgaben der Datenvorverarbeitung haben wir bereits ausführlich besprochen. Schauen wir uns nun Methoden zum Erstellen von Manager-Modellen an.
Wir haben den GMM- Algorithmus (Gaussian Mixture Model) als Modell verwendet . Es modelliert unsere Daten unter der Annahme, dass es sich um Realisierungen einer Zufallsvariablen mit einer Verteilung handelt, die durch eine Mischung von Gaußschen beschrieben wird - jede mit ihrer eigenen Varianz und ihrer eigenen mathematischen Erwartung.
Es ist bekannt, dass der gebräuchlichste Algorithmus zum Finden der optimalen Parameter einer solchen Mischung der EM-Algorithmus (Expectation Maximization) ist . Er unterteilt das schwierige Problem der Maximierung der Wahrscheinlichkeit einer mehrdimensionalen Zufallsvariablen in eine Reihe von Maximierungsproblemen niedrigerer Dimension.
Als Ergebnis einer Reihe von Experimenten kamen wir zu den folgenden Parametern des GMM-Algorithmus:
gmm = GMM(n_components = 16, n_iter = 200, covariance_type='diag',n_init = 3)Ein solches Modell wird für jeden Manager erstellt und dann trainiert - seine Parameter werden auf bestimmte Daten abgestimmt.
gmm.fit(features)Als nächstes wird das Modell gespeichert, um in der Markierungsphase verwendet zu werden:
picklefile = path[path.find('/')+1:path.find('.')]+".gmm"
pickle.dump(gmm,open(dest + picklefile,'wb'))In der Tagging-Phase laden wir die zuvor gespeicherten Modelle:
gmm_files = [os.path.join(modelpath,fname) for fname in
os.listdir(modelpath) if fname.endswith('.gmm')]modelpath ist das Verzeichnis, in dem wir die Modelle gespeichert haben.
models = [pickle.load(open(fname,'rb'),encoding='latin1') for fname in gmm_files]Und laden Sie auch die Namen der Modelle (dies sind unsere Tags):
speakers = [fname.split("/")[-1].split(".gmm")[0] for fname
in gmm_files]Die hochgeladene Audiodatei, für die Sie ein Tag erstellen müssen, wird vektorisiert und vorverarbeitet. Ferner wird jedes Fragment mit der darin enthaltenen Sprache mit den trainierten Modellen verglichen und der Gewinner wird anhand des maximalen Logarithmus der Wahrscheinlichkeit bestimmt:
log_likelihood = np.zeros(len(models)) #
for i in range(len(models)):
gmm = models[i] #
scores = np.array(gmm.score(vector))
log_likelihood[i] = scores.sum() # i –
winner = np.argmax(log_likelihood) #
print("\tdetected as - ", speakers[winner])Infolgedessen hat unser Algorithmus ungefähr die folgende Schlussfolgerung:
beginnt in: 1,92 endet in: 8,72
[-10400,93604115 -12111,38278205]
erkannt als - Olga
beginnt in: 9,22 endet in: 15,72
[-10193,80504138 -11911.11095894]
erkannt als - Olga
beginnt in: 26,7 endet in:
29.82 [-4867.97641331 -5506.44233563]
erkannt als - Ivan
beginnt in: 33.34 endet in: 47.14
[-21143.02629011 -24796.44582627]
erkannt als - Ivan
beginnt in: 52.56 endet in: 59.24
[-10916.83282132 -12124.26855 beginnt538]
erkannt als -
Ol in: 116.32 endet in: 134.56
[-36764.94876054 -34810.38959083]
erkannt als - Olga
beginnt in: 151.18 endet in: 154.86
[-8041.33666572 -6859.14253903]
erkannt als - Olga
beginnt in: 159.7 endet in: 162.92
[-6421.72235531 -5983.90538059]
erkannt in - Olga
beginnt in: 185.02 endet in: 208.7
…
beginnt in: 442.04 endet in: 445.5
[-7451.0289 ]
erkannt als - Olga
*******
GEWINNER - Olga In
diesem Beispiel wird davon ausgegangen , dass es mindestens 2 Klassen gibt - [Olga, Ivan] . Die Audiodatei wird in Segmente [1.92, 8.72], [9.22, 15.72],…, [442.04, 445.5] geschnitten und für jedes Segment das am besten geeignete Modell ermittelt.
Der kumulative Wahrscheinlichkeitslogarithmus ist in Klammern neben jedem Block angegeben:[-10400.93604115 -12111.38278205] , das erste Element ist Olgas Wahrscheinlichkeit und das zweite ist Ivan . Da das erste Argument größer als das zweite ist, wird dieses Segment als Olga klassifiziert . Der endgültige Gewinner wird durch die Mehrheit der "Stimmen" der Fragmente bestimmt.
Ergebnisse
Zunächst haben wir den Algorithmus unter der Annahme entworfen, dass bei eingehenden Anrufen möglicherweise ein "unbekannter" Manager vorhanden ist - das heißt, sein Modell ist im Trainingsbeispiel nicht vorhanden.
Um einen solchen Benutzer zu erkennen, müssen wir eine Metrik für den Vektor log_likelihood eingeben . So dass bestimmte seiner Werte darauf hinweisen, dass dieses Fragment höchstwahrscheinlich von keinem der vorhandenen Modelle angemessen beschrieben wird. Wir haben die folgende Metrik als Test vorgeschlagen:
Leukl=(log_likelihood-np.min(log_likelihood))/(np.max(log_likelihood)-np.min(log_likelihood))
-sorted(-np.array(Leukl))[1]<TDieser Wert gibt an, wie „gleichmäßig“ die Bewertungen im Vektor log_likelihood verteilt sind . Die Einheitlichkeit der Schätzungen (ihre Nähe zueinander) bedeutet, dass sich alle Modelle gleich verhalten und es keinen klaren Führer gibt.
Dies deutet darauf hin, dass höchstwahrscheinlich alle Modelle falsch sind und wir einen Manager haben, der sich nicht in der Trainingsphase befand. Die Beziehung zwischen T und der Qualität der Klassifizierung ist in den Figuren gezeigt.
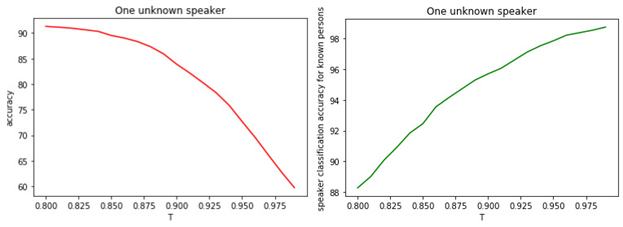
Zahl: 1.
a) Genauigkeit der binären Klassifizierung bekannter und unbekannter Manager.
b) Die Genauigkeit der Klassifizierung berühmter Manager.

Zahl: 2.
a) Der Anteil bekannter Manager, der der Klasse bekannter Manager zugeordnet ist.
b) Der Anteil unbekannter Manager, der der Klasse der bekannten zugeordnet ist.
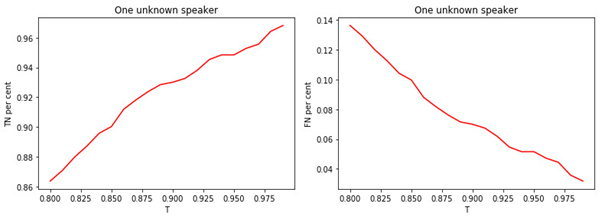
Zahl: 3.
a) Der Anteil unbekannter Manager, der der Klasse der Unbekannten zugeordnet ist.
b) Der Anteil bekannter Manager, die der Klasse der Unbekannten zugeordnet sind.
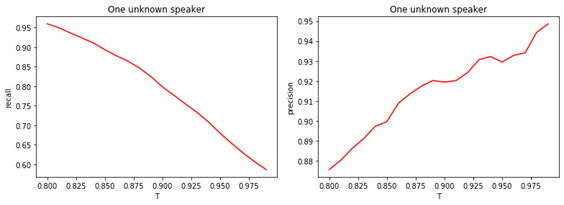
Zahl: 4.
a) Vollständigkeit der binären Klassifikation (Rückruf).
b) Präzision der binären Klassifikation (Präzision).
Die Beziehung zwischen dem Wert des Schwellenwerts T und der Qualität der Klassifizierung (Markierung) ist offensichtlich. Je größer T (je strenger die Bedingungen für die Zuordnung eines Managers zur Klasse der Unbekannten), desto weniger wahrscheinlich ist es, dass ein bekannter Manager als unbekannt eingestuft wird. Es ist jedoch wahrscheinlicher, dass ein unbekannter Manager "vermisst" wird.
Der optimale Schwellenwert beträgt 0,8 . Weil wir bekannte Manager mit einer Genauigkeit von ca. 90% klassifizierenund bestimmen Sie die "Unbekannten" mit einer Genauigkeit von 81% . Wenn wir davon ausgehen, dass uns alle Manager "vertraut" sind, liegt die Genauigkeit bei etwa 98% .
Schlussfolgerungen
In dem Artikel haben wir die allgemeinen Ideen zur Funktionsweise unseres Tools zur Identifizierung von Managern in Anrufen beschrieben. Natürlich geben wir nicht vor, dass unser Algorithmus optimal und nicht verbesserungsfähig ist.
Es basiert auf einer Reihe von Annahmen, die in der Praxis nicht immer erfüllt sind. Beispielsweise können wir einem unbekannten Manager gegenüberstehen, wenn keine Daten über ihn vorliegen. Oder zwei oder mehr Manager können "zu gleichen Teilen" ein Gespräch mit dem Kunden führen. Aus Sicht des Algorithmus können die folgenden Anweisungen für weitere Verbesserungen vorgeschlagen werden:
- Auswahl eines anderen Algorithmusmodells als GMM
- GMM-Parameter optimieren
- Auswählen einer anderen Metrik zum Erkennen eines neuen Managers
- Suchen Sie nach den wichtigsten Merkmalen des Sprachsignals
- Kombination verschiedener Audio-Vorverarbeitungswerkzeuge und Optimierung der Parameter dieser Methoden