
DBMS arbeiten in dieser Hinsicht nach den gleichen Prinzipien - " sie sagten zu graben, und ich grabe ". Ihre Anfrage kann nicht nur benachbarte Prozesse verlangsamen und ständig Prozessorressourcen belegen, sondern auch die gesamte Datenbank vollständig "löschen" und den gesamten verfügbaren Speicher "verbrauchen". Der Schutz vor unendlicher Rekursion liegt daher in der Verantwortung des Entwicklers.
In PostgreSQL ist die Fähigkeit, rekursive Abfragen zu verwenden,
WITH RECURSIVEseit undenklichen Zeiten in Version 8.4 aufgetaucht. Sie können jedoch weiterhin regelmäßig auf potenziell anfällige "wehrlose" Abfragen stoßen. Wie können Sie sich vor solchen Problemen schützen?
Schreiben Sie keine rekursiven Abfragen
Und schreibe nicht rekursiv. Mit freundlichen Grüßen Ihr K.O.Tatsächlich bietet PostgreSQL eine ziemlich große Menge an Funktionen, mit denen SieRekursionen vermeiden können .
Verwenden Sie einen grundlegend anderen Ansatz für die Aufgabe
Manchmal kann man das Problem einfach "von der anderen Seite" betrachten. Ein Beispiel für eine solche Situation habe ich im Artikel "SQL HowTo: 1000 und eine Art der Aggregation" gegeben - Multiplikation einer Reihe von Zahlen ohne Verwendung benutzerdefinierter Aggregatfunktionen:
WITH RECURSIVE src AS (
SELECT '{2,3,5,7,11,13,17,19}'::integer[] arr
)
, T(i, val) AS (
SELECT
1::bigint
, 1
UNION ALL
SELECT
i + 1
, val * arr[i]
FROM
T
, src
WHERE
i <= array_length(arr, 1)
)
SELECT
val
FROM
T
ORDER BY --
i DESC
LIMIT 1;Eine solche Anfrage kann durch eine Variante von Experten für Mathematik ersetzt werden:
WITH src AS (
SELECT unnest('{2,3,5,7,11,13,17,19}'::integer[]) prime
)
SELECT
exp(sum(ln(prime)))::integer val
FROM
src;Verwenden Sie generate_series anstelle von Schleifen
Angenommen, wir stehen vor der Aufgabe, alle möglichen Präfixe für eine Zeichenfolge zu generieren
'abcdefgh':
WITH RECURSIVE T AS (
SELECT 'abcdefgh' str
UNION ALL
SELECT
substr(str, 1, length(str) - 1)
FROM
T
WHERE
length(str) > 1
)
TABLE T;Benötigen Sie hier genau eine Rekursion? .. Wenn Sie
LATERALund verwenden generate_series, werden nicht einmal CTEs benötigt:
SELECT
substr(str, 1, ln) str
FROM
(VALUES('abcdefgh')) T(str)
, LATERAL(
SELECT generate_series(length(str), 1, -1) ln
) X;Ändern Sie die Datenbankstruktur
Sie haben beispielsweise eine Tabelle mit Forenbeiträgen mit Links zu Personen, die jemandem oder einem Thread in einem sozialen Netzwerk geantwortet haben :
CREATE TABLE message(
message_id
uuid
PRIMARY KEY
, reply_to
uuid
REFERENCES message
, body
text
);
CREATE INDEX ON message(reply_to);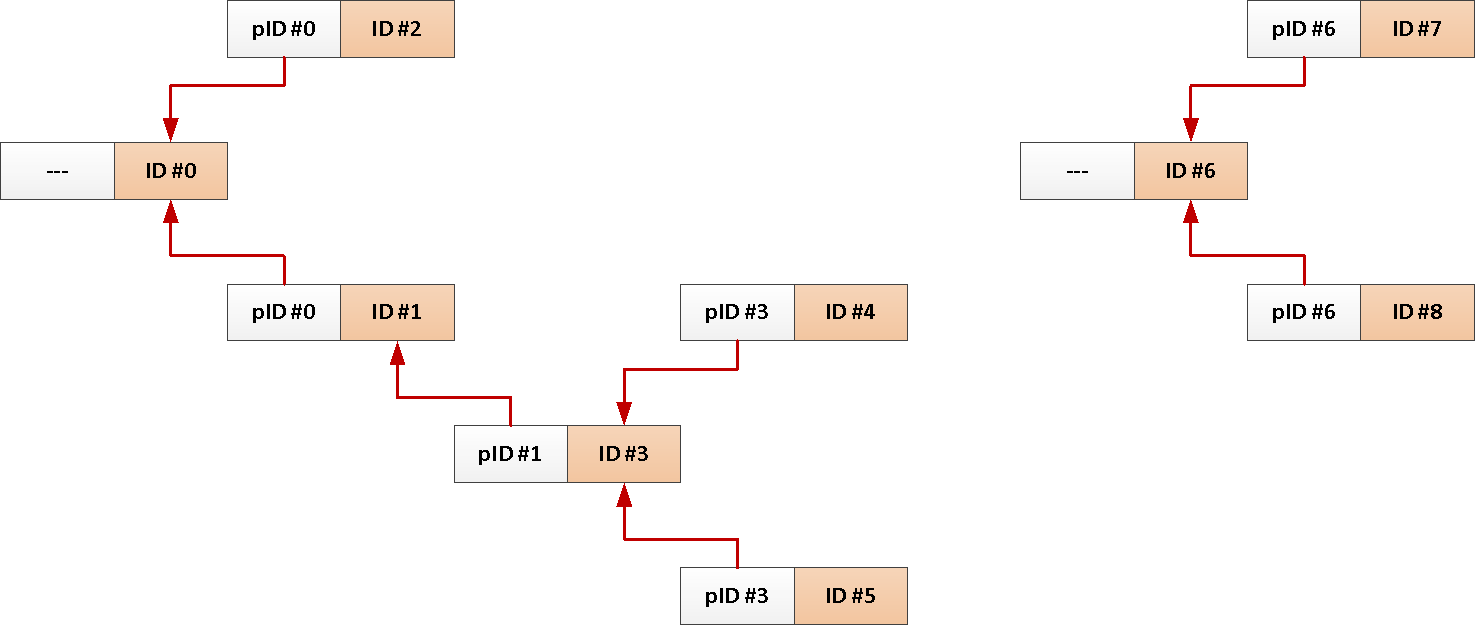
Eine typische Anfrage zum Herunterladen aller Nachrichten zu einem Thema sieht ungefähr so aus:
WITH RECURSIVE T AS (
SELECT
*
FROM
message
WHERE
message_id = $1
UNION ALL
SELECT
m.*
FROM
T
JOIN
message m
ON m.reply_to = T.message_id
)
TABLE T;Da wir jedoch immer den gesamten Betreff aus der Stammnachricht benötigen , können Sie jedem Beitrag automatisch seine Kennung hinzufügen .
--
ALTER TABLE message
ADD COLUMN theme_id uuid;
CREATE INDEX ON message(theme_id);
--
CREATE OR REPLACE FUNCTION ins() RETURNS TRIGGER AS $$
BEGIN
NEW.theme_id = CASE
WHEN NEW.reply_to IS NULL THEN NEW.message_id --
ELSE ( -- ,
SELECT
theme_id
FROM
message
WHERE
message_id = NEW.reply_to
)
END;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER ins BEFORE INSERT
ON message
FOR EACH ROW
EXECUTE PROCEDURE ins();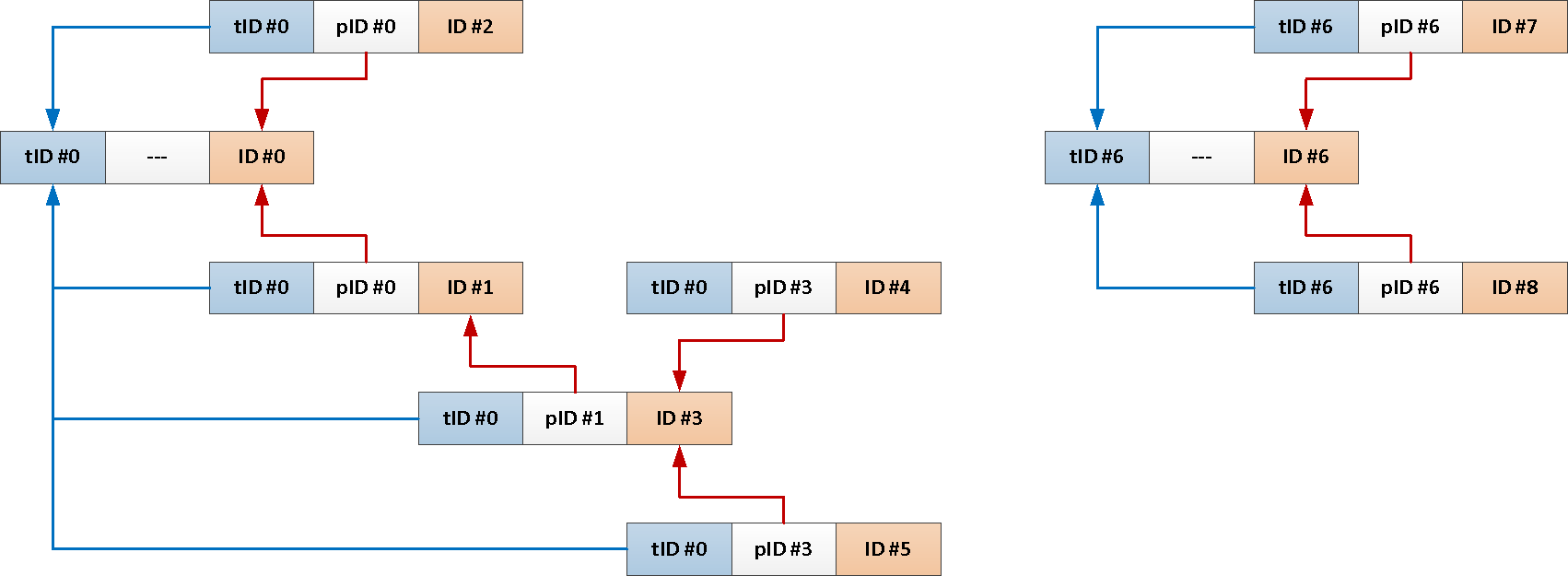
Jetzt kann unsere gesamte rekursive Abfrage auf genau das reduziert werden:
SELECT
*
FROM
message
WHERE
theme_id = $1;Verwenden Sie angewandte "Einschränkungen"
Wenn wir die Struktur der Datenbank aus irgendeinem Grund nicht ändern können, schauen wir uns an, worauf wir uns verlassen können, damit selbst das Vorhandensein eines Fehlers in den Daten nicht zu einer unendlichen Rekursion führt.
Rekursions- "Tiefen" -Zähler
Wir erhöhen den Zähler einfach bei jedem Schritt der Rekursion um eins, bis das Limit erreicht ist, das wir absichtlich als unzureichend betrachten:
WITH RECURSIVE T AS (
SELECT
0 i
...
UNION ALL
SELECT
i + 1
...
WHERE
T.i < 64 --
)Pro: Wenn wir versuchen, eine Schleife zu erstellen, machen wir immer noch nicht mehr als die angegebene Grenze der Iterationen "tief".
Contra: Es gibt keine Garantie dafür, dass wir nicht denselben Datensatz erneut verarbeiten - zum Beispiel in Tiefen von 15 und 25, und dann gibt es alle +10. Und niemand versprach etwas über "Breite".
Formal wird eine solche Rekursion nicht unendlich sein, aber wenn bei jedem Schritt die Anzahl der Datensätze exponentiell zunimmt, wissen wir alle genau, wie sie endet ...

Wächter des "Weges"
Nacheinander fügen wir alle Objektkennungen, die wir entlang des Rekursionspfads gefunden haben, zu einem Array hinzu, das ein eindeutiger "Pfad" dazu ist:
WITH RECURSIVE T AS (
SELECT
ARRAY[id] path
...
UNION ALL
SELECT
path || id
...
WHERE
id <> ALL(T.path) --
)Pro: Wenn die Daten eine Schleife enthalten, werden wir denselben Datensatz auf demselben Pfad absolut nicht erneut verarbeiten.
Contra: Aber gleichzeitig können wir buchstäblich alle Aufzeichnungen umgehen, ohne sie zu wiederholen.
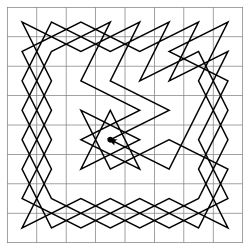
Pfadlängenbeschränkung
Um zu vermeiden, dass die Rekursion in einer unverständlichen Tiefe "wandert", können wir die beiden vorherigen Methoden kombinieren. Wenn Sie keine unnötigen Felder unterstützen möchten, ergänzen Sie die Rekursionsfortsetzungsbedingung durch eine Schätzung der Pfadlänge:
WITH RECURSIVE T AS (
SELECT
ARRAY[id] path
...
UNION ALL
SELECT
path || id
...
WHERE
id <> ALL(T.path) AND
array_length(T.path, 1) < 10
)Wählen Sie die Methode nach Ihrem Geschmack!