- Hallo! Ich werde Ihnen sagen, welche Probleme Sie lösen müssen, wenn Sie Ihren Service auf mehrere hundert Gigabit oder sogar Terabit pro Sekunde vorbereiten müssen. Ein solches Problem hatten wir erstmals 2018, als wir uns auf die Ausstrahlung der FIFA-Weltmeisterschaft vorbereiteten.
Beginnen wir mit den Streaming-Protokollen und ihrer Funktionsweise - der oberflächlichsten Übersichtsoption.

Jedes Streaming-Protokoll basiert auf einem Manifest oder einer Wiedergabeliste. Es ist eine kleine Textdatei, die Metainformationen zum Inhalt enthält. Es beschreibt die Art des Inhalts - Live-Übertragung oder VoD-Übertragung (Video on Demand). Im Falle eines Live-Spiels handelt es sich beispielsweise um ein Fußballspiel oder eine Online-Konferenz, wie wir sie jetzt bei Ihnen haben. Bei VoD werden Ihre Inhalte im Voraus vorbereitet und liegen auf Ihren Servern und können an die Benutzer verteilt werden. Dieselbe Datei beschreibt die Dauer des Inhalts und Informationen zu DRM.

Es werden auch Inhaltsvariationen beschrieben - Videospuren, Audiospuren, Untertitel. Videospuren können in verschiedenen Codecs dargestellt werden. Beispielsweise wird Universal H.264 auf jedem Gerät unterstützt. Mit ihm können Sie Videos auf jedem Bügeleisen in Ihrem Zuhause abspielen. Oder es gibt modernere und effizientere HEVC- und VP9-Codecs, mit denen Sie 4K mit HDR-Unterstützung übertragen können.
Audiospuren können auch in verschiedenen Codecs mit unterschiedlichen Bitraten dargestellt werden. Und es kann mehrere davon geben - die Original-Audiospur des Films in englischer Sprache, die Übersetzung ins Russische, Intershum oder beispielsweise eine Aufzeichnung eines Sportereignisses direkt aus dem Stadion ohne Kommentatoren.

Was macht der Spieler mit all dem? Die Aufgabe des Spielers besteht zunächst darin, die Variationen des Inhalts auszuwählen, die abgespielt werden können, einfach weil nicht alle Codecs universell sind und nicht alle auf einem bestimmten Gerät abgespielt werden können.
Danach muss er die Qualität von Video und Audio auswählen, ab der er mit der Wiedergabe beginnen möchte. Er kann dies basierend auf den Netzwerkbedingungen tun, wenn er sie kennt, oder auf der Grundlage einer sehr einfachen Heuristik. Beginnen Sie beispielsweise mit geringer Qualität und erhöhen Sie die Auflösung langsam, wenn das Netzwerk dies zulässt.
Ebenfalls zu diesem Zeitpunkt wählt er die Audiospur aus, von der aus er mit der Wiedergabe beginnen möchte. Angenommen, Sie haben Englisch in Ihrem Betriebssystem. Dann kann er standardmäßig die englische Audiospur auswählen. Vielleicht ist es für Sie bequemer.
Danach werden Verknüpfungen zu Video- und Audiosegmenten hergestellt. Tatsächlich handelt es sich hierbei um reguläre HTTP-Links, genau wie in allen anderen Szenarien im Internet. Und es beginnt damit, Video- und Audiosegmente herunterzuladen, sie nacheinander in den Puffer zu legen und nahtlos abzuspielen. Solche Videosegmente sind normalerweise 2, 4, 6 Sekunden lang, möglicherweise 10 Sekunden, abhängig von Ihrem Dienst.

Was sind hier die wichtigen Punkte, über die wir nachdenken müssen, wenn wir unser CDN entwerfen? Zunächst haben wir eine Benutzersitzung.
Wir können einem Benutzer nicht einfach eine Datei geben und diesen Benutzer vergessen. Er kommt ständig zurück und lädt neue und neue Segmente in seinen Puffer herunter.
Es ist wichtig zu verstehen, dass auch die Antwortzeit des Servers wichtig ist. Wenn wir eine Art Live-Übertragung in Echtzeit zeigen, können wir keinen großen Puffer erstellen, nur weil der Benutzer das Video so nah wie möglich an der Echtzeit ansehen möchte. Grundsätzlich kann Ihr Puffer nicht groß sein. Wenn der Server keine Zeit zum Antworten hat, während der Benutzer Zeit zum Anzeigen des Inhalts hat, friert das Video dementsprechend einfach irgendwann ein. Außerdem ist der Inhalt ziemlich schwer. Die Standardbitrate für Full HD 1080p beträgt 3-5 Mbit / s. Dementsprechend können Sie auf einem Gigabit-Server nicht mehr als 200 Benutzer gleichzeitig bedienen. Und dies ist ein perfektes Bild, da Benutzer ihre Anforderungen in der Regel im Laufe der Zeit nicht gleichmäßig verfolgen.

Ab wann interagiert ein Benutzer tatsächlich mit Ihrem CDN? Die Interaktion erfolgt hauptsächlich an zwei Stellen: wenn der Player das Manifest (Wiedergabeliste) herunterlädt und wenn er Segmente herunterlädt.
Wir haben bereits über Manifeste gesprochen, dies sind kleine Textdateien. Es gibt keine besonderen Probleme bei der Verteilung solcher Dateien. Wenn Sie möchten, verteilen Sie sie von mindestens einem Server. Und wenn es sich um Segmente handelt, machen sie den größten Teil Ihres Datenverkehrs aus. Wir werden über sie sprechen.
Die Aufgabe unseres gesamten Systems reduziert sich auf die Tatsache, dass wir die richtige Verknüpfung zu diesen Segmenten herstellen und dort die richtige Domäne einiger unserer CDN-Hosts ersetzen möchten. Zu diesem Zeitpunkt verwenden wir die folgende Strategie: Sofort in der Wiedergabeliste geben wir den gewünschten CDN-Host an, wohin der Benutzer gehen wird. Dieser Ansatz weist viele Nachteile auf, weist jedoch eine wichtige Nuance auf. Sie müssen sicherstellen, dass Sie über einen Mechanismus verfügen, mit dem der Benutzer während der Wiedergabe nahtlos von einem Host auf einen anderen übertragen werden kann, ohne die Anzeige zu unterbrechen. Tatsächlich verfügen alle modernen Streaming-Protokolle über diese Funktion, die sowohl von HLS als auch von DASH unterstützt wird. Nuance: Selbst in sehr populären Open-Source-Bibliotheken wird eine solche Möglichkeit häufig nicht implementiert, obwohl sie standardmäßig vorhanden ist. Wir mussten selbst Bundles an die Open-Source-Bibliothek von Shaka senden.Es ist Javascript, das für den Web-Player zum Spielen von DASH verwendet wird.
Es gibt noch ein weiteres Schema - Anycast-Schema, wenn Sie eine einzelne Domain verwenden und diese in allen Links angeben. In diesem Fall müssen Sie nicht über Nuancen nachdenken - Sie verschenken eine Domain und alle sind glücklich. (...)
Lassen Sie uns nun darüber sprechen, wie wir unsere Links bilden werden.
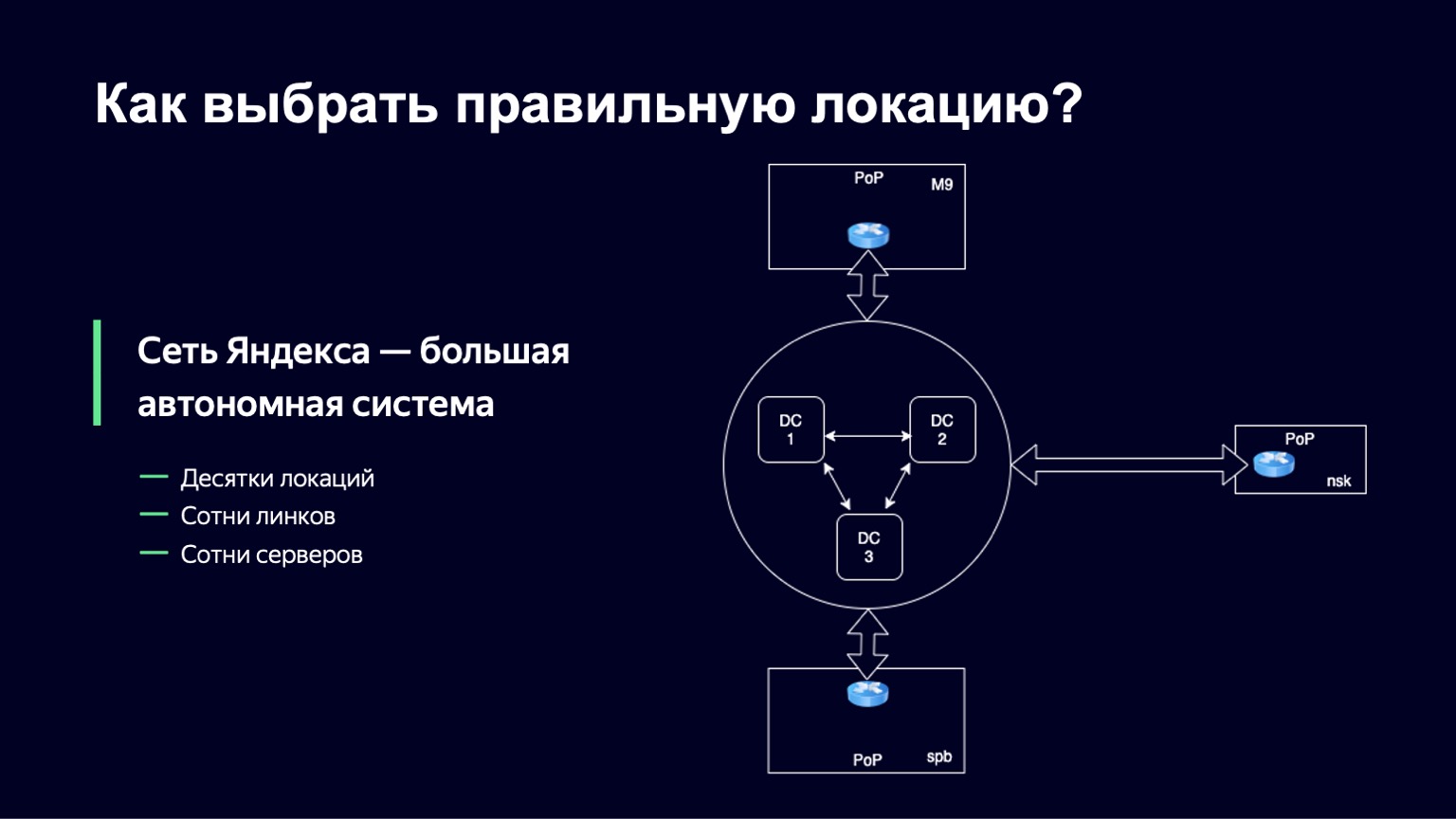
Aus Netzwerksicht ist jedes große Unternehmen als autonomes System organisiert und oft nicht einmal als eines. Tatsächlich ist ein autonomes System ein System von IP-Netzwerken und Routern, die von einem einzelnen Betreiber gesteuert werden und eine einzige Routing-Richtlinie für das externe Netzwerk und das Internet bereitstellen. Yandex ist keine Ausnahme. Das Yandex-Netzwerk ist ebenfalls ein autonomes System, und die Kommunikation mit anderen autonomen Systemen findet außerhalb der Yandex-Rechenzentren an Präsenzpunkten statt. Physikalische Kabel von Yandex, physische Kabel anderer Betreiber kommen zu diesen Präsenzpunkten und werden vor Ort an Eisengeräten geschaltet. An solchen Stellen haben wir die Möglichkeit, mehrere unserer Server, Festplatten und SSDs zu installieren. Hier leiten wir den Benutzerverkehr.
Wir werden diese Gruppe von Servern als Standort bezeichnen. Und an jedem dieser Orte haben wir eine eindeutige Kennung. Wir werden es als Teil des Domainnamens der Hosts auf dieser Site verwenden und nur, um es eindeutig zu identifizieren.
Es gibt mehrere Dutzend solcher Sites in Yandex, es gibt mehrere hundert Server auf ihnen, und Links von mehreren Betreibern kommen zu jedem Standort, so dass wir auch ungefähr mehrere hundert Links haben.
Wie wählen wir den Ort aus, an den ein bestimmter Benutzer gesendet werden soll?

Derzeit gibt es nicht sehr viele Optionen. Wir können die IP-Adresse nur verwenden, um Entscheidungen zu treffen. Ein separates Yandex Traffic Team hilft uns dabei, das alles über die Funktionsweise von Verkehr und Netzwerk im Unternehmen weiß. Sie sammelt die Routen anderer Betreiber, damit wir dieses Wissen beim Ausgleich der Benutzer nutzen können.
Es sammelt eine Reihe von Routen mit BGP. Wir werden nicht im Detail über BGP sprechen. Es ist ein Protokoll, mit dem Netzwerkteilnehmer an den Grenzen ihrer autonomen Systeme bekannt geben können, welche Routen ihr autonomes System bedienen kann. Das Verkehrsteam sammelt all diese Informationen, aggregiert, analysiert und erstellt eine vollständige Karte des gesamten Netzwerks, die wir für den Ausgleich verwenden.
Wir erhalten vom Verkehrsteam eine Reihe von IP-Netzwerken und Links, über die wir Kunden bedienen können. Als nächstes müssen wir verstehen, welches IP-Subnetz für einen bestimmten Benutzer geeignet ist.
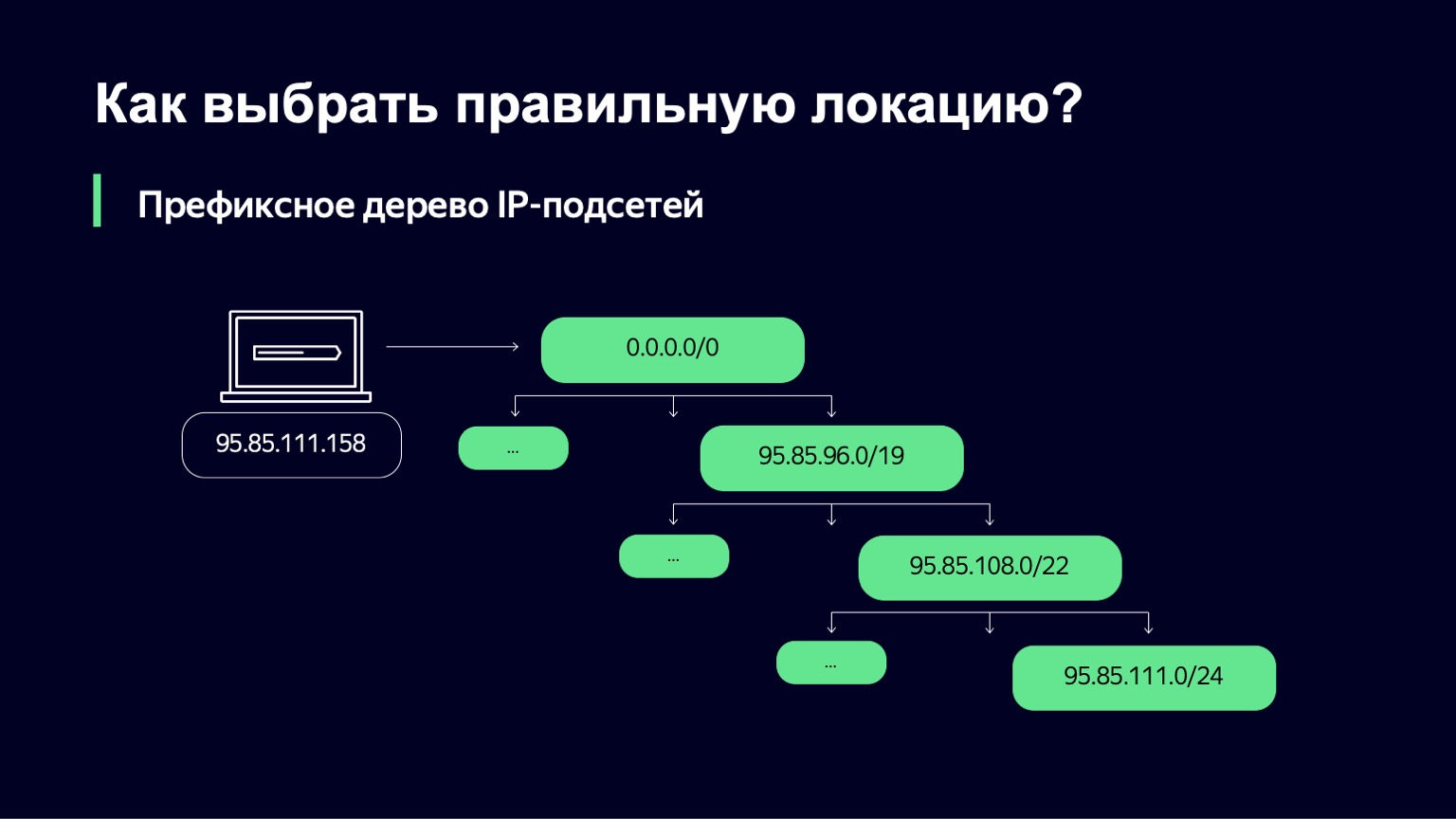
Wir machen das auf ziemlich einfache Weise - wir erstellen einen Präfixbaum. Und dann besteht unsere Aufgabe darin, die IP-Adresse des Benutzers als Schlüssel zu verwenden, um herauszufinden, welches Subnetz dieser IP-Adresse am ehesten entspricht.
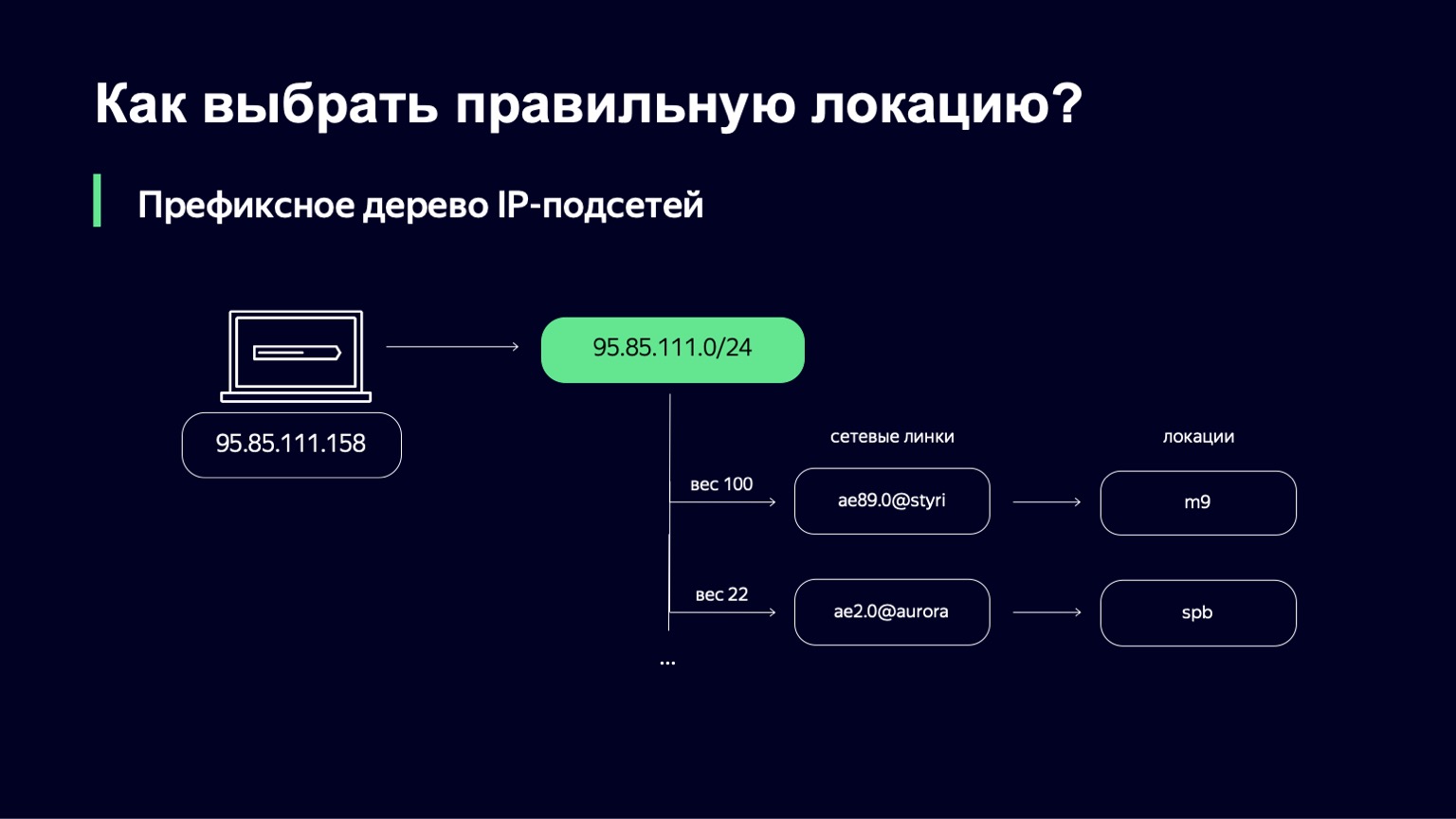
Als wir es gefunden haben, haben wir eine Liste von Links, deren Gewichtung und durch Links können wir den Ort, an den wir den Benutzer senden, eindeutig bestimmen.

Was ist das Gewicht an diesem Ort? Dies ist eine Metrik, mit der Sie die Verteilung von Benutzern auf verschiedene Standorte verwalten können. Wir können zum Beispiel Verbindungen mit unterschiedlichen Kapazitäten haben. Wir können einen 100-Gigabit-Link und einen 10-Gigabit-Link auf derselben Site haben. Natürlich möchten wir mehr Benutzer zum ersten Link senden, da dieser umfangreicher ist. Diese Gewichtung berücksichtigt die Netzwerktopologie, da das Internet ein komplexes Diagramm miteinander verbundener Netzwerkgeräte ist, Ihr Datenverkehr auf verschiedenen Pfaden verlaufen kann und diese Topologie ebenfalls berücksichtigt werden muss.
Achten Sie darauf, wie Benutzer tatsächlich Daten herunterladen. Dies kann sowohl auf Server- als auch auf Clientseite erfolgen. Auf dem Server sammeln wir aktiv Benutzerverbindungen in den TCP-Infoprotokollen und betrachten die Umlaufzeit. Auf der Benutzerseite sammeln wir aktiv Browser- und Player-Perf-Protokolle. Diese Perf-Protokolle enthalten detaillierte Informationen darüber, wie die Dateien von unserem CDN heruntergeladen wurden.
Wenn wir all dies aggregieren, können wir mithilfe dieser Daten die Gewichte verbessern, die in der ersten Phase vom Verkehrsteam ausgewählt wurden.

Angenommen, wir haben einen Link ausgewählt. Können wir Benutzer zu diesem Zeitpunkt dorthin schicken? Wir können nicht, weil das Gewicht über einen langen Zeitraum ziemlich statisch ist und keine wirkliche Dynamik der Last berücksichtigt. Wir möchten in Echtzeit feststellen, ob wir jetzt einen Link verwenden können, der beispielsweise zu 80% geladen ist, wenn sich in der Nähe ein Link mit etwas niedrigerer Priorität befindet, der nur zu 10% geladen ist. In diesem Fall möchten wir höchstwahrscheinlich nur den zweiten verwenden.

Was muss an dieser Stelle noch berücksichtigt werden? Wir müssen die Bandbreite der Verbindung berücksichtigen und ihren aktuellen Status verstehen. Es kann funktionieren oder technisch defekt sein. Oder wir möchten es zum Service bringen, damit Benutzer nicht dorthin gehen und es bedienen, zum Beispiel erweitern. Wir müssen immer die aktuelle Last dieses Links berücksichtigen.
Hier gibt es einige interessante Nuancen. Sie können an mehreren Stellen Informationen zum Laden von Links sammeln, z. B. zu Netzwerkgeräten. Dies ist der genaueste Weg, aber das Problem ist, dass Sie auf den Netzwerkgeräten keinen schnellen Aktualisierungszeitraum für diesen Download erhalten können. In Yandex beispielsweise ist die Netzwerkausrüstung sehr unterschiedlich, und wir können diese Daten nicht öfter als einmal pro Minute erfassen. Wenn das System hinsichtlich der Last ziemlich stabil ist, ist dies überhaupt kein Problem. Alles wird gut funktionieren. Sobald Sie jedoch plötzliche Lastströme haben, haben Sie einfach keine Zeit mehr zu reagieren, und dies führt beispielsweise dazu, dass Tropfen verpackt werden.
Andererseits wissen Sie, wie viele Bytes an den Benutzer gesendet wurden. Sie können diese Informationen auf den Verteilungsmaschinen selbst sammeln und direkt einen Bytezähler erstellen. Aber es wird nicht so genau sein. Warum?
Es gibt andere Benutzer auf unserem CDN. Wir sind nicht der einzige Dienst, der diese Ausgabemaschinen einsetzt. Und vor dem Hintergrund unserer Last ist die Last anderer Dienste nicht so bedeutend. Aber auch vor unserem Hintergrund kann es durchaus auffallen. Ihre Verteilung erfolgt nicht über unsere Rennstrecke, daher können wir diesen Verkehr nicht kontrollieren.
Ein weiterer Punkt: Selbst wenn Sie auf dem sendenden Computer glauben, dass Sie Datenverkehr an eine bestimmte Verbindung gesendet haben, ist dies alles andere als eine Tatsache, da BGP als Protokoll Ihnen keine solche Garantie gibt. Und es gibt Möglichkeiten, die Wahrscheinlichkeit zu erhöhen, dass Sie richtig raten, aber das ist ein Thema für eine andere Diskussion.

Nehmen wir an, wir haben die Metriken berechnet und alles gesammelt. Jetzt brauchen wir einen Entscheidungsalgorithmus für das Balancing. Es muss vier wichtige Eigenschaften haben:
- Geben Sie die Verbindungsbandbreite an.
- Verhindern Sie eine Überlastung der Verbindung, einfach weil, wenn Sie eine Verbindung zu 95% oder 98% geladen haben, die Puffer auf den Netzwerkgeräten überlaufen, Pakete verworfen werden, Neuübertragungen beginnen und Benutzer nichts Gutes davon erhalten.
- Um "getrunkene" Ladungen zu warnen, werden wir etwas später darüber sprechen.
„In einer idealen Welt wäre es großartig, wenn wir lernen könnten, eine Verbindung zu einer bestimmten Ebene zu recyceln, die wir für richtig halten. Zum Beispiel 85% herunterladen.

Wir haben die folgende Idee zugrunde gelegt. Wir haben zwei verschiedene Klassen von Benutzersitzungen. Die erste Klasse sind neue Sitzungen, in denen der Benutzer den Film gerade geöffnet hat, noch nichts gesehen hat und wir versuchen herauszufinden, wohin er gesendet werden soll. Oder die zweite Klasse, wenn wir eine aktuelle Sitzung haben, wird der Benutzer bereits auf der Verbindung bedient, belegt einen bestimmten Teil der Bandbreite, wird auf einem bestimmten Server bedient.
Was machen wir mit ihnen? Wir führen einen Wahrscheinlichkeitswert für jede solche Klasse der Sitzung ein. Wir haben einen Wert namens Slowdown, der den Prozentsatz der neuen Sitzungen bestimmt, die wir für diesen Link nicht zulassen. Wenn die Verlangsamung Null ist, akzeptieren wir alle neuen Sitzungen, und wenn sie 50% beträgt, lehnen wir es grob gesagt ab, jede zweite Sitzung über diesen Link zu bedienen. Gleichzeitig prüft unser Ausgleichsalgorithmus auf einer höheren Ebene Alternativen für diesen Benutzer. Das Löschen ist nur für aktuelle Sitzungen gleich. Wir können einige der Benutzersitzungen von der Site woanders übernehmen.
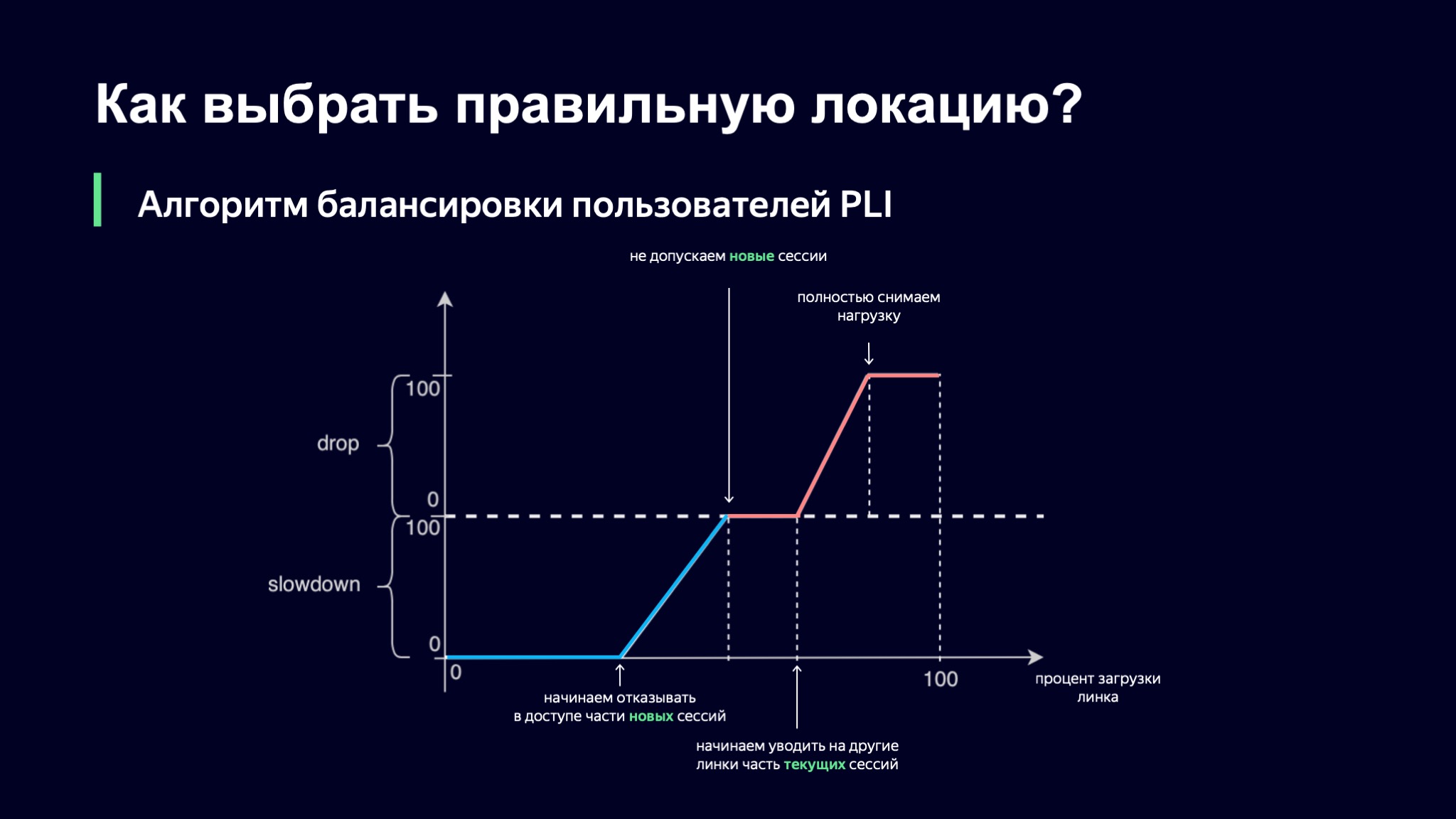
Wie wählen wir den Wert unserer probabilistischen Metriken aus? Wir werden den Prozentsatz des Linkladens als Grundlage nehmen, und dann war unsere erste Idee folgende: Verwenden wir die stückweise lineare Interpolation.
Wir haben eine solche Funktion übernommen, die mehrere Brechungspunkte hat, und wir betrachten den Wert unserer Koeffizienten damit. Wenn der Download-Level des Links minimal ist, ist alles in Ordnung, Slowdown und Drop sind gleich Null, wir lassen alle neuen Benutzer herein. Sobald der Lastpegel einen bestimmten Schwellenwert überschreitet, verweigern wir einigen Benutzern über diesen Link den Dienst. Wenn die Last weiter wächst, hören wir irgendwann einfach auf, neue Sitzungen zu starten.
Hier gibt es eine interessante Nuance: Aktuelle Sitzungen haben in diesem Schema Vorrang. Ich denke, es ist klar, warum dies geschieht: Wenn Ihr Benutzer Ihnen bereits ein stabiles Lastmuster zur Verfügung stellt, möchten Sie ihn nicht überall hin mitnehmen, da Sie auf diese Weise die Dynamik des Systems erhöhen und je stabiler das System ist, desto einfacher ist es für uns, es zu steuern.
Der Download kann jedoch weiter zunehmen. Irgendwann können wir beginnen, einige der Sitzungen zu entfernen oder sogar die Last vollständig von diesem Link zu entfernen.
In dieser Form haben wir diesen Algorithmus in den ersten Spielen der FIFA-Weltmeisterschaft eingeführt. Es ist wahrscheinlich interessant zu sehen, was für ein Bild wir gesehen haben. Sie war über das Folgende.
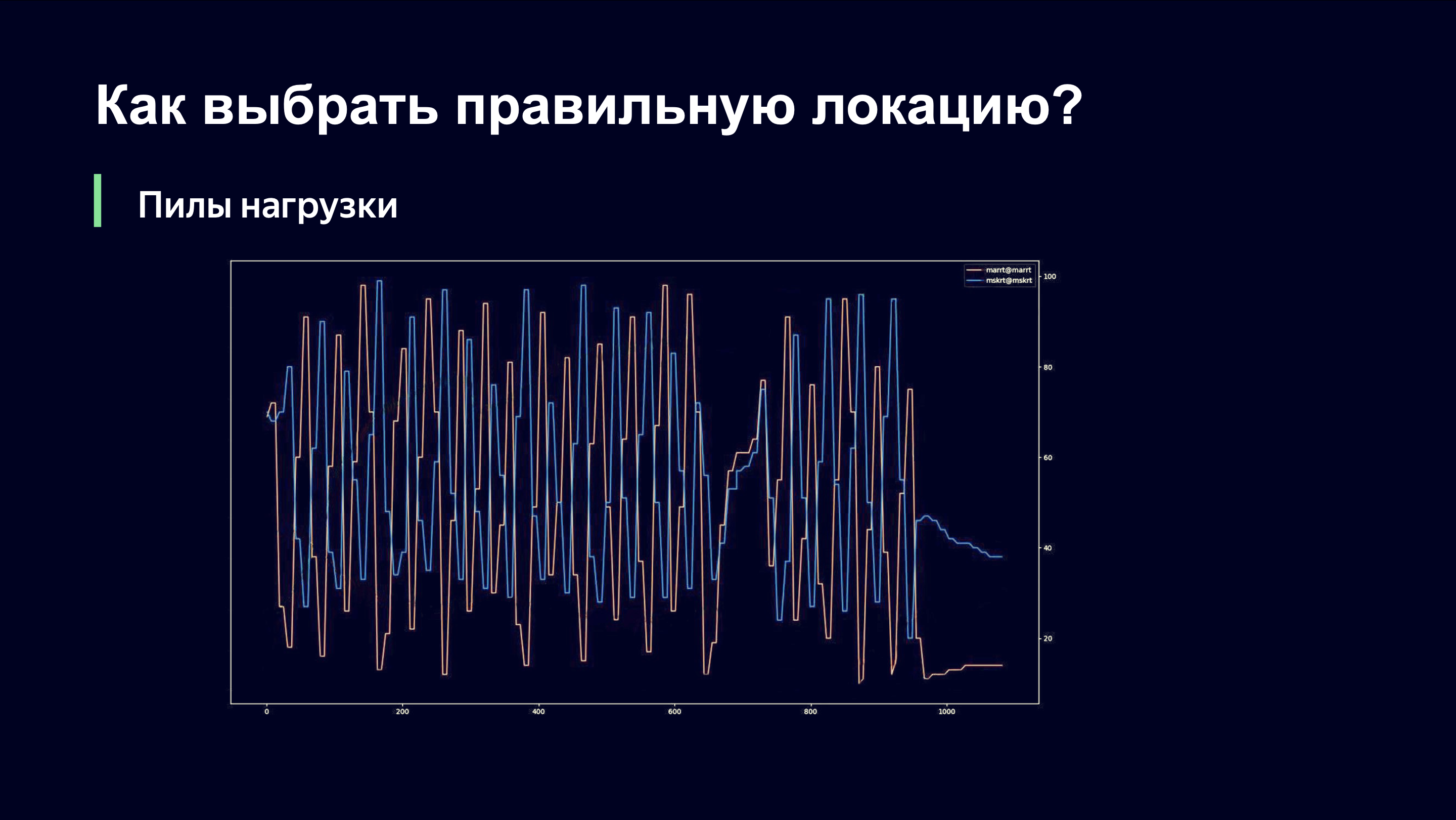
Selbst mit bloßem Auge kann ein externer Beobachter verstehen, dass hier wahrscheinlich etwas nicht stimmt, und mich fragen: "Andrey, geht es dir gut?" Und wenn du mein Chef wärst, würdest du durch den Raum rennen und rufen: „Andrey, mein Gott! Roll alles zurück! Gib alles so zurück, wie es war! " Sagen wir Ihnen, was hier los ist.
Auf der X-Achse, Zeit, auf der Y-Achse beobachten wir den Grad der Verbindungslast. Es gibt zwei Links, die dieselbe Site bedienen. Es ist wichtig zu verstehen, dass wir zu diesem Zeitpunkt nur das Verbindungslastüberwachungsschema verwendet haben, das von den Netzwerkgeräten entfernt wurde und daher nicht schnell auf die Lastdynamik reagieren konnte.
Wenn wir Benutzer zu einem der Links senden, steigt der Datenverkehr auf diesem Link stark an. Der Link ist überlastet. Wir nehmen die Last ab und befinden uns auf der rechten Seite der Funktion, die wir in der vorherigen Grafik gesehen haben. Und wir lassen alte Benutzer fallen und lassen keine neuen mehr ein. Sie müssen irgendwohin und natürlich zum nächsten Link. Das letzte Mal war es vielleicht eine niedrigere Priorität, aber jetzt haben sie Priorität.
Der zweite Link wiederholt das gleiche Bild. Wir erhöhen die Last stark, stellen fest, dass die Verbindung überlastet ist, entfernen die Last und diese beiden Verbindungen sind in Bezug auf das Lastniveau gegenphasig.
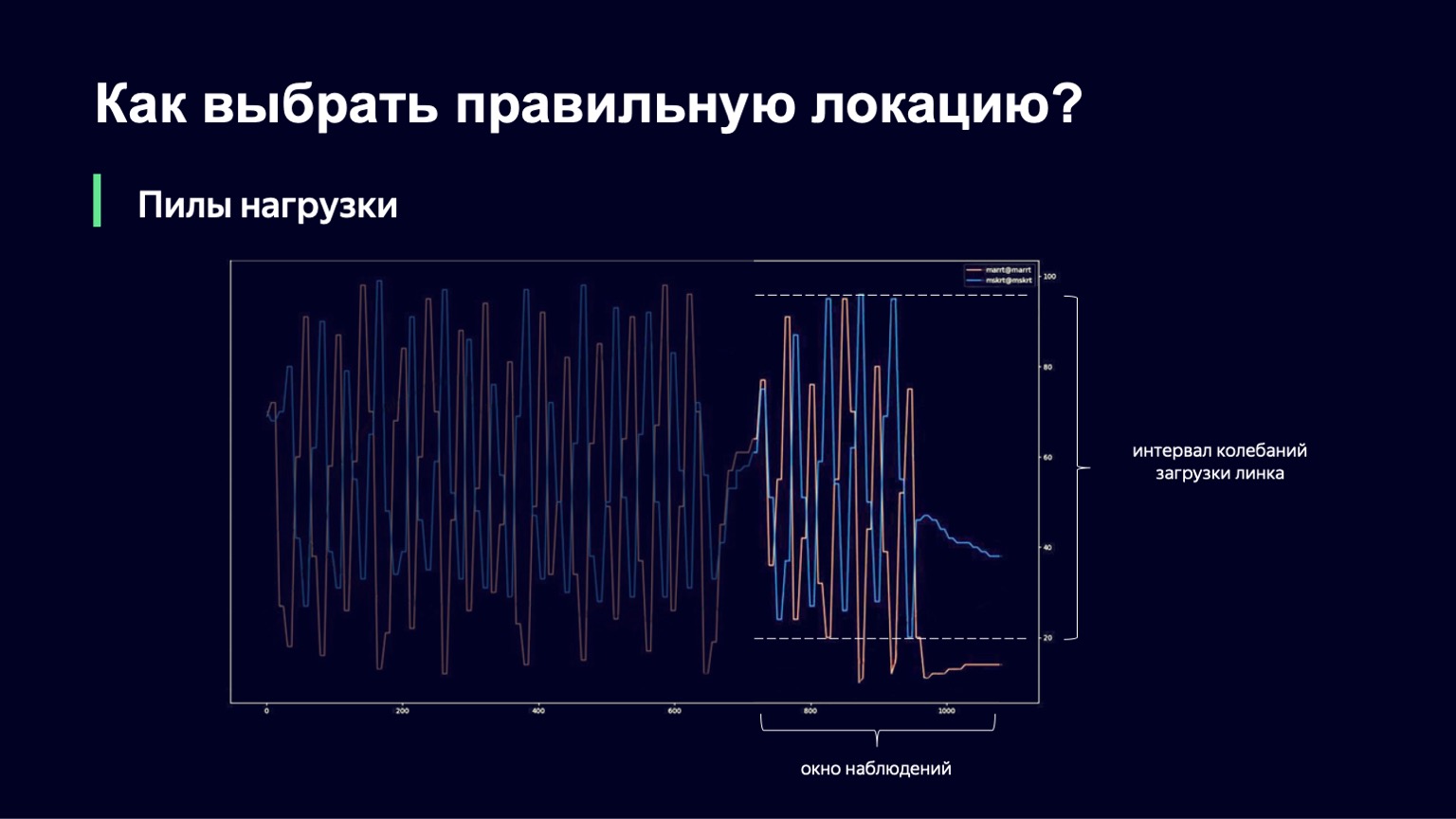
Was kann getan werden? Wir können die Dynamik des Systems analysieren, dies mit einem starken Anstieg der Last feststellen und ein wenig dämpfen. Genau das haben wir getan. Wir haben den aktuellen Moment genommen, das Beobachtungsfenster für einige Minuten in die Vergangenheit verschoben, zum Beispiel 2-3 Minuten, und uns angesehen, wie stark sich die Verbindungslast in diesem Intervall ändert. Die Differenz zwischen den Minimal- und Maximalwerten wird als Schwingungsintervall dieser Verbindung bezeichnet. Und wenn dieses Schwingungsintervall groß ist, fügen wir eine Dämpfung hinzu, wodurch unsere Verlangsamung erhöht wird und weniger Sitzungen ausgeführt werden.
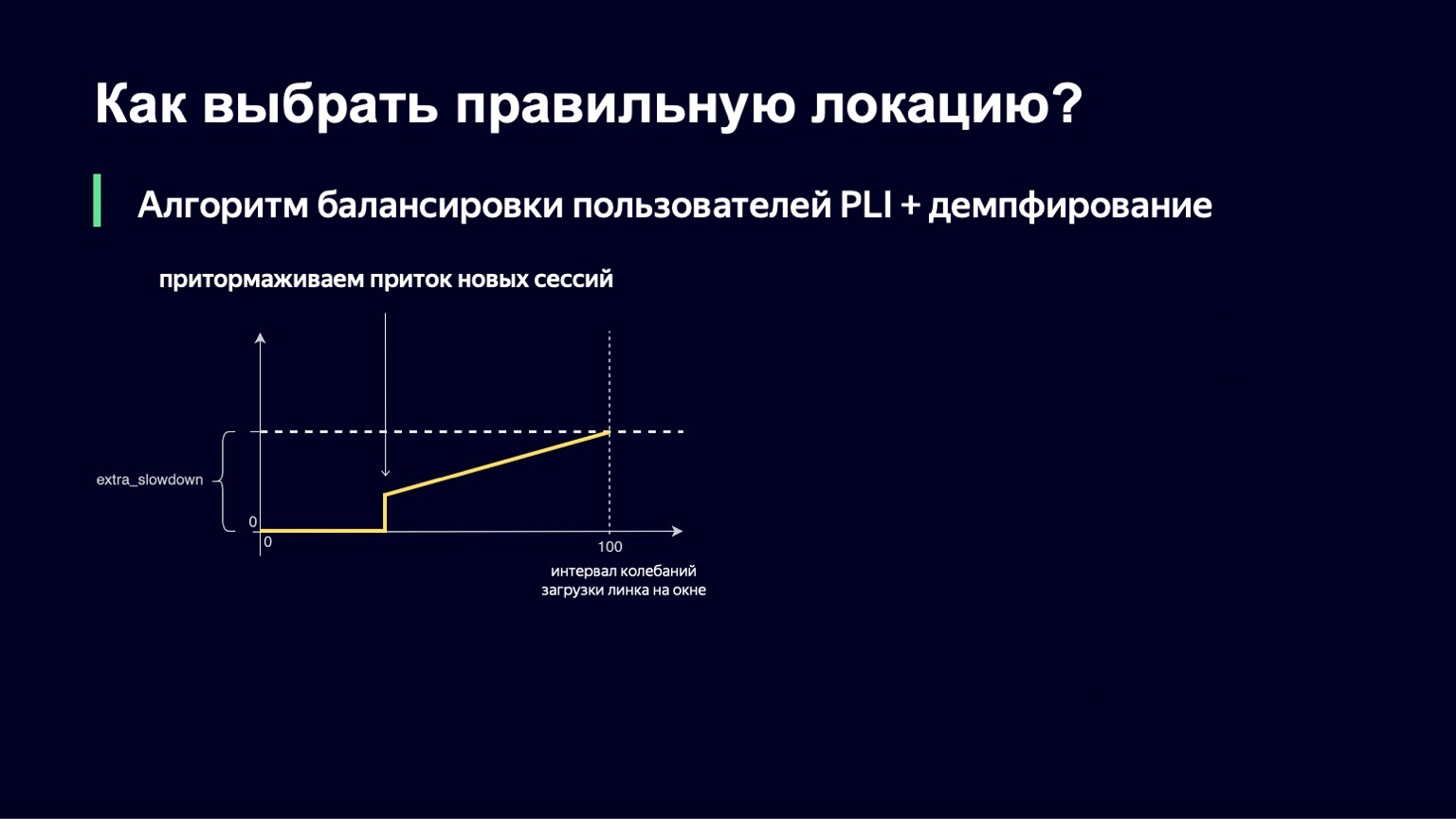
Diese Funktion sieht ungefähr genauso aus wie die vorherige, mit etwas weniger Frakturen. Wenn wir ein kleines Intervall zum Herunterladen von Oszillationen haben, fügen wir keine extra_slowdown hinzu. Und wenn das Oszillationsintervall zu wachsen beginnt, nimmt extra_slowdown Werte ungleich Null an. Später werden wir es der Hauptverlangsamung hinzufügen.
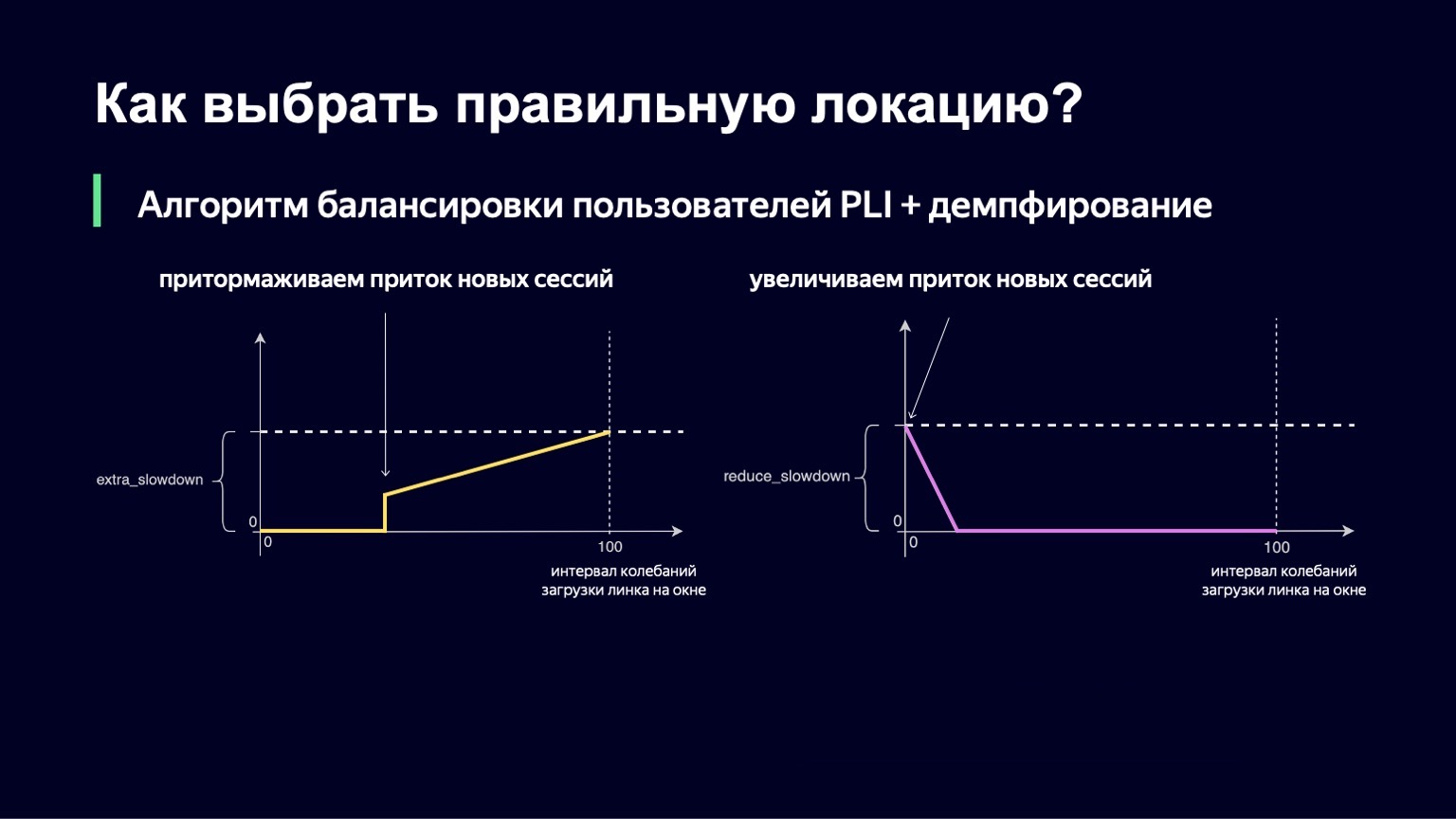
Die gleiche Logik arbeitet bei niedrigen Werten des Schwingungsintervalls. Wenn Sie nur minimale Bedenken bezüglich des Links haben, möchten Sie im Gegenteil etwas mehr Benutzer dort einlassen, die Verlangsamung verringern und somit Ihren Link besser nutzen.
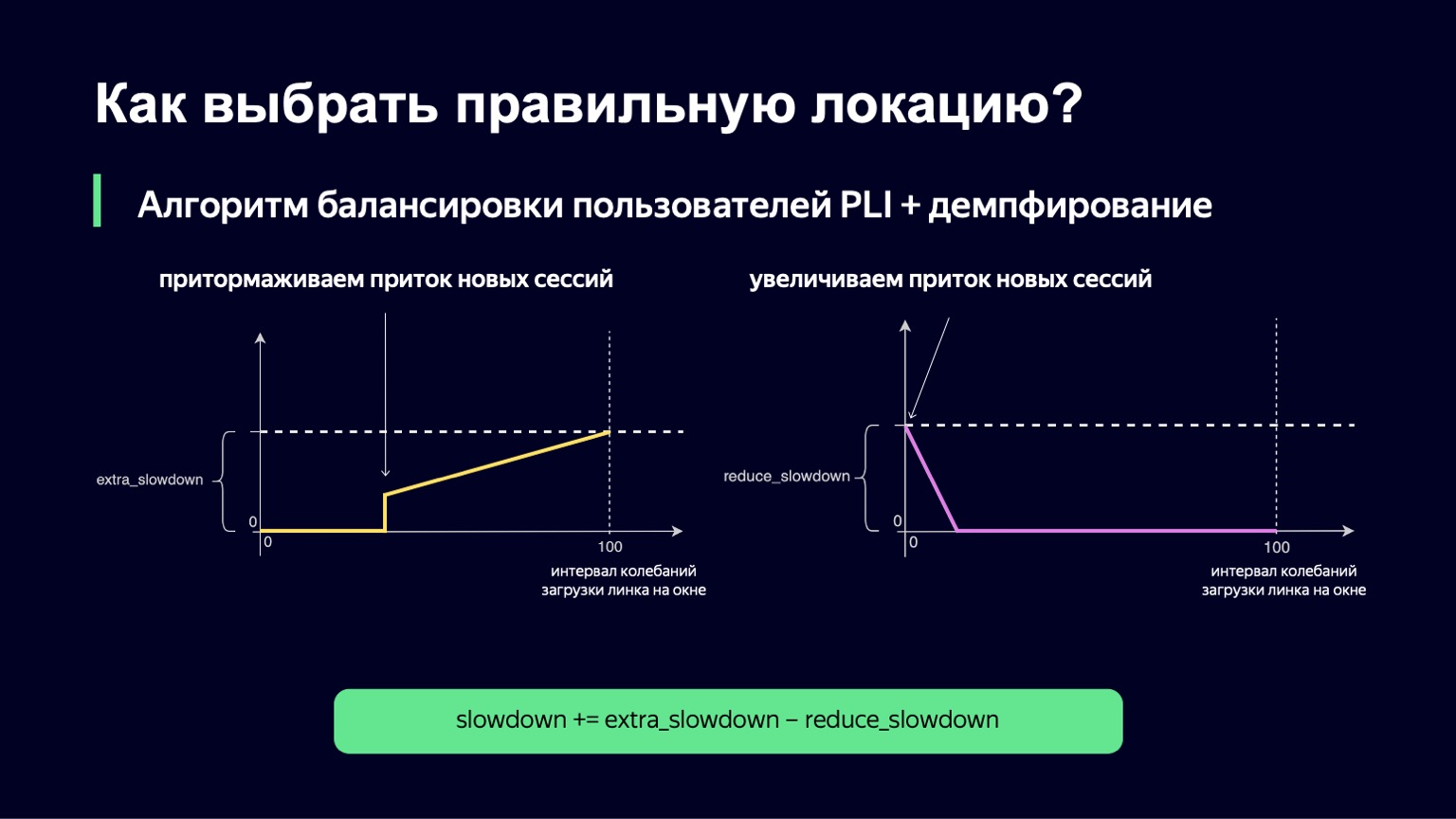
Wir haben diesen Teil auch implementiert. Die endgültige Formel sieht so aus. Gleichzeitig garantieren wir, dass diese beiden Werte - extra_slowdown und reduct_slowdown - niemals gleichzeitig einen Wert ungleich Null haben, sodass nur einer von ihnen effektiv funktioniert. In dieser Form hat diese Ausgleichsformel alle Top-Spiele der Weltmeisterschaft überstanden. Selbst bei den beliebtesten Spielen hat sie ganz gut gearbeitet: Das sind "Russland - Kroatien", "Russland - Spanien". Während dieser Spiele haben wir einen Rekord für das Yandex-Verkehrsaufkommen verteilt - 1,5 Terabit pro Sekunde. Wir gingen ruhig durch. Seitdem hat sich die Formel in keiner Weise geändert, da seitdem - bis zu einem bestimmten Moment - kein solcher Verkehr in unserem Dienst stattgefunden hat.
Dann kam eine Pandemie zu uns. Die Leute wurden nach Hause geschickt, um zu sitzen, und zu Hause gibt es gutes Internet, Fernsehen, Tablet und viel Freizeit. Der Verkehr zu unseren Diensten begann organisch zu wachsen, ziemlich schnell und signifikant. Jetzt ist diese Art von Ladung, wie es während der Weltmeisterschaft war, unsere tägliche Routine. Seitdem haben wir unsere Kanäle mit Betreibern ein wenig erweitert, aber dennoch über die nächste Iteration unseres Algorithmus nachgedacht, was er sein sollte und wie wir unser Netzwerk besser nutzen können.

Was sind die Nachteile unseres vorherigen Algorithmus? Wir haben zwei Probleme nicht gelöst. Wir haben die "Säge" -Ladungen nicht vollständig beseitigt. Wir haben das Bild stark verbessert und die Amplitude dieser Schwankungen ist minimal, die Periode hat sich stark vergrößert, was auch eine bessere Auslastung des Netzwerks ermöglicht. Trotzdem bleiben sie von Zeit zu Zeit. Wir haben nicht gelernt, das Netzwerk so zu nutzen, wie wir es möchten. Beispielsweise können wir die Konfiguration nicht verwenden, um die gewünschte maximale Verbindungslast von 80-85% festzulegen.

Welche Gedanken haben wir für die nächste Iteration des Algorithmus? Wie stellen wir uns die ideale Netzwerkauslastung vor? Einer der vielversprechenden Bereiche scheint die Option zu sein, wenn Sie einen einzigen Ort haben, an dem Sie Entscheidungen über den Verkehr treffen können. Sie sammeln alle Metriken an einem Ort, eine Benutzeranforderung zum Herunterladen von Segmenten wird dort angezeigt, und zu jedem Zeitpunkt, zu dem Sie einen vollständigen Systemstatus haben, können Sie ganz einfach Entscheidungen treffen.
Aber hier gibt es zwei Nuancen. Erstens ist es in Yandex nicht üblich, „gemeinsame Entscheidungspunkte“ zu schreiben, einfach weil ein solcher Ort mit unserer Auslastung und unserem Verkehr schnell zu einem Engpass wird.
Es gibt noch eine Nuance: In Yandex ist es auch wichtig, fehlertolerante Systeme zu schreiben. Wir haben Rechenzentren häufig vollständig heruntergefahren, während Ihre Komponente fehlerfrei und ohne Unterbrechungen weiterarbeiten sollte. In dieser Form wird dieser einzelne Ort tatsächlich zu einem verteilten System, das Sie steuern müssen, und dies ist eine etwas schwierigere Aufgabe als die, die wir an diesem Ort lösen möchten.

Wir brauchen definitiv schnelle Metriken. Ohne sie können Sie nur das Netzwerk nicht ausreichend nutzen, um das Leiden der Benutzer zu vermeiden. Aber das passt auch nicht zu uns.
Wenn Sie unser System auf hohem Niveau betrachten, wird klar, dass unser System ein dynamisches System mit Feedback ist. Wir haben eine benutzerdefinierte Last, die ein Eingangssignal ist. Menschen kommen und gehen. Wir haben ein Steuersignal - genau die zwei Werte, die wir in Echtzeit ändern können. Für solche dynamischen Systeme mit Rückkopplung wurde die Theorie der automatischen Steuerung über einen langen Zeitraum von mehreren Jahrzehnten entwickelt. Und es sind seine Komponenten, die wir gerne verwenden würden, um unser System zu stabilisieren.
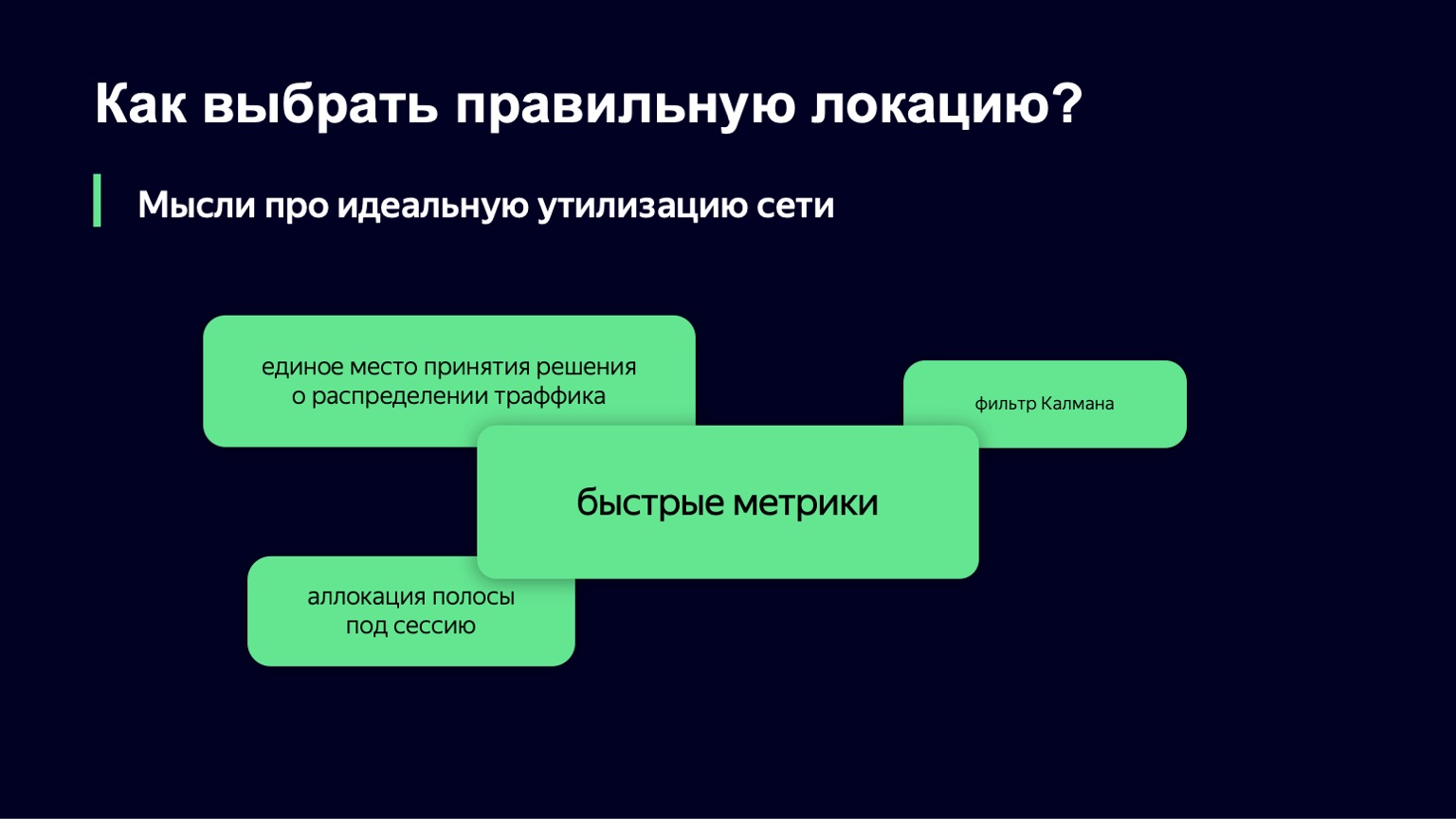
Wir haben uns den Kalman-Filter angesehen. Dies ist eine coole Sache, mit der Sie ein mathematisches Modell des Systems erstellen und mit verrauschten Metriken oder in Abwesenheit einiger Metrikklassen das Modell mithilfe Ihres realen Systems verbessern können. Und dann treffen Sie eine Entscheidung über ein reales System basierend auf einem mathematischen Modell. Leider stellte sich heraus, dass wir nicht viele Klassen von Metriken haben, die wir verwenden können, und dieser Algorithmus kann nicht angewendet werden.
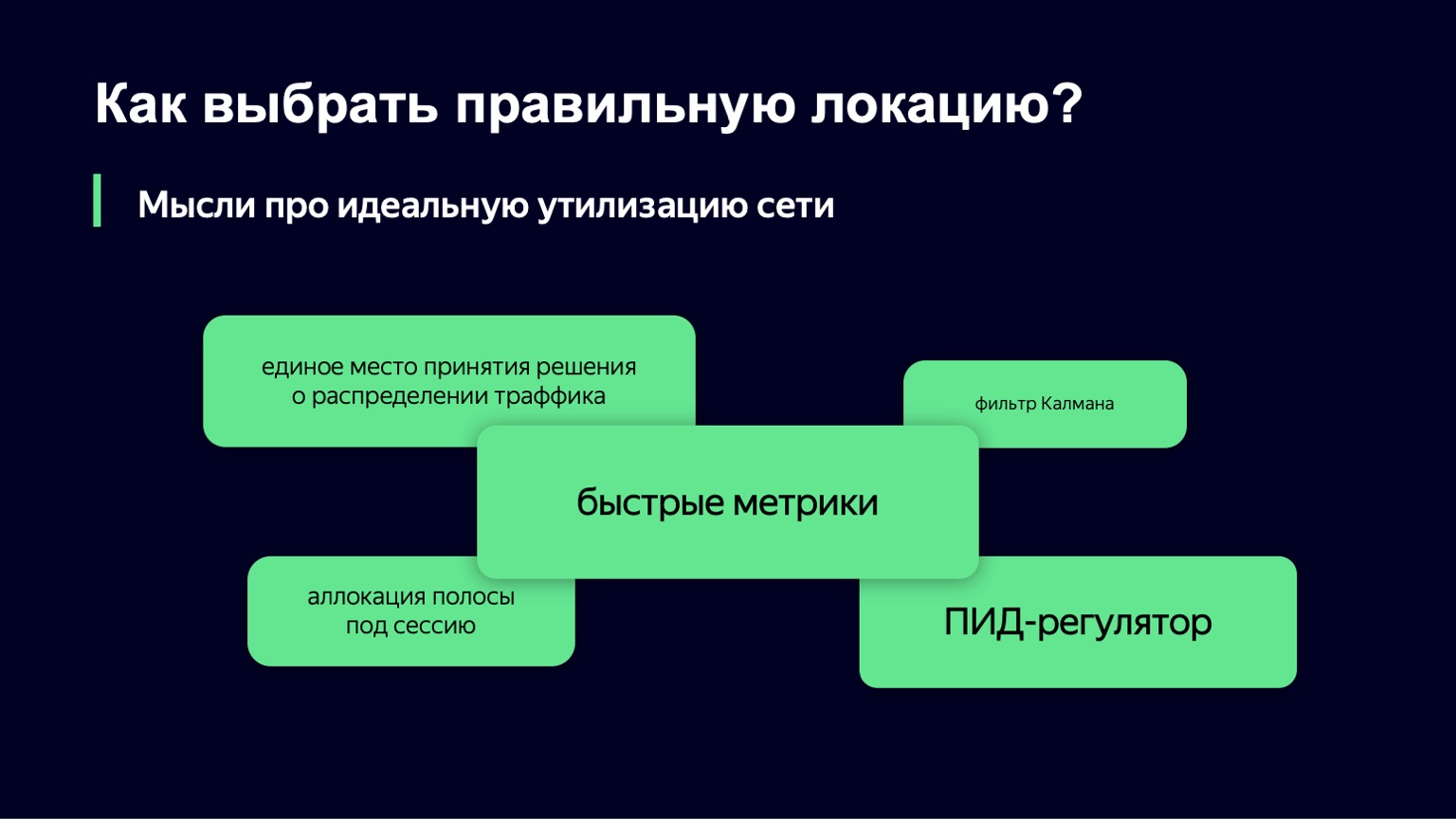
Wir näherten uns von der anderen Seite und nahmen als Grundlage eine weitere Komponente dieser Theorie - den PID-Regler. Er weiß nichts über Ihr System. Seine Aufgabe ist es, den idealen Zustand des Systems, dh unser gewünschtes Lastniveau, und den aktuellen Zustand des Systems, beispielsweise das Lastniveau, zu kennen. Er betrachtet den Unterschied zwischen diesen beiden Zuständen als Fehler und verwaltet mithilfe seiner internen Algorithmen das Steuersignal, dh unsere Slowdown- und Drop-Werte. Ziel ist es, den Fehler im System zu minimieren.
Wir werden diesen PID-Regler von Tag zu Tag in der Produktion testen. Vielleicht können wir Ihnen in ein paar Monaten etwas über die Ergebnisse erzählen.
Darauf werden wir wahrscheinlich über das Netzwerk fertig sein. Ich möchte Ihnen sehr gerne erzählen, wie wir den Datenverkehr innerhalb des Standorts selbst verteilen, wenn wir ihn bereits zwischen den Hosts ausgewählt haben. Dafür ist aber keine Zeit. Dies ist wahrscheinlich ein Thema für einen separaten großen Bericht.

In der nächsten Serie erfahren Sie daher, wie Sie den Cache auf Hosts optimal nutzen, wie Sie mit heißem und kaltem Verkehr umgehen, woher der warme Verkehr kommt, wie sich die Art des Inhalts auf den Algorithmus für seine Verteilung auswirkt und welches Video den höchsten Cache-Treffer für den Dienst erzielt und wer wer singt ein Lied.
Ich habe noch eine interessante Geschichte. Wie Sie wissen, begann im Frühjahr die Quarantäne. Yandex hat seit langem eine Bildungsplattform namens Yandex.Tutorial, mit der Lehrer Videos und Lektionen hochladen können. Die Schüler kommen dorthin und schauen sich den Inhalt an. Während der Pandemie begann Yandex, Schulen zu unterstützen und sie aktiv auf seine Plattform einzuladen, damit die Schüler aus der Ferne lernen können. Und irgendwann sahen wir ein ziemlich gutes Verkehrswachstum, ein ziemlich stabiles Bild. Aber an einem der Aprilabende sahen wir so etwas wie das Folgende in den Charts.
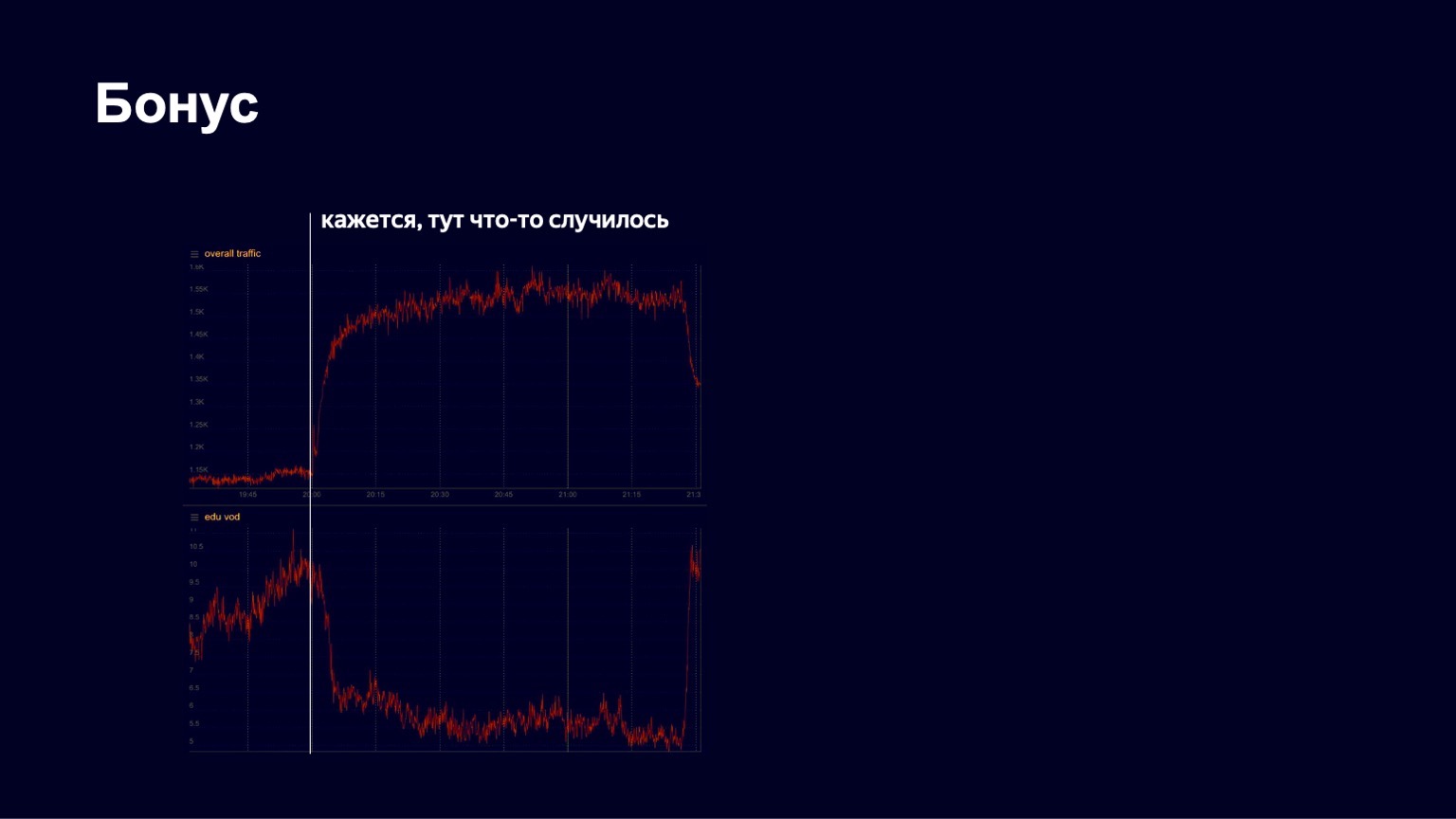
Unten sehen Sie ein Bild des Verkehrs mit Bildungsinhalten. Wir haben gesehen, dass er irgendwann stark gefallen ist. Wir gerieten in Panik, um herauszufinden, was im Allgemeinen vor sich ging, was kaputt war. Dann bemerkten wir, dass der gesamte Verkehr zum Dienst zu wachsen begann. Offensichtlich ist etwas Interessantes passiert.
In diesem Moment geschah Folgendes.
So schnell tanzt der Mann.
Das Little Big-Konzert begann und alle Schüler gingen, um es zu sehen. Aber nach dem Ende des Konzerts kehrten sie zurück und studierten erfolgreich weiter. Wir sehen solche Bilder ziemlich oft in unserem Dienst. Daher finde ich unsere Arbeit sehr interessant. Danke an alle! Ich werde wahrscheinlich damit über CDN enden.