( NLP) von Tim Dettmers, Ph.D. Deep Learning (DL) ist ein Bereich mit einem hohen Bedarf an Rechenleistung. Ihre Wahl der GPU bestimmt daher grundlegend Ihre Erfahrung in diesem Bereich. Aber welche Eigenschaften müssen beim Kauf einer neuen GPU berücksichtigt werden? Speicher, Kerne, Tensorkerne? Wie kann man die beste Wahl in Bezug auf das Preis-Leistungs-Verhältnis treffen? In diesem Artikel werde ich all diese Fragen, häufige Missverständnisse, detailliert analysieren, Ihnen ein intuitives Verständnis der GPU vermitteln sowie einige Tipps geben, die Ihnen helfen, die richtige Wahl zu treffen.
Dieser Artikel soll Ihnen verschiedene Ebenen des Verständnisses der GPU vermitteln, einschließlich. neue Ampere-Serie von NVIDIA. Du hast eine Wahl:
- Wenn Sie nicht an den Details der GPU interessiert sind, was genau die GPU schnell macht und was an den neuen GPUs der NVIDIA RTX 30 Ampere-Serie einzigartig ist, können Sie den Anfang des Artikels überspringen, bis hin zu den Grafiken zu Geschwindigkeit und Geschwindigkeit pro 1-Dollar-Kosten sowie dem Abschnitt mit Empfehlungen. Dies ist der Kern dieses Artikels und der wertvollste Inhalt.
- Wenn Sie an bestimmten Fragen interessiert sind, habe ich die häufigsten im letzten Teil des Artikels behandelt.
- Wenn Sie ein tiefes Verständnis der Funktionsweise von GPUs und Tensorkernen benötigen, lesen Sie diesen Artikel am besten von Anfang bis Ende. Abhängig von Ihren Kenntnissen in bestimmten Themen können Sie ein oder zwei Kapitel überspringen.
Vor jedem Abschnitt befindet sich eine kurze Zusammenfassung, anhand derer Sie entscheiden können, ob Sie ihn vollständig lesen möchten oder nicht.
Inhalt
GPU?
GPU,
/ L1 /
Ampere
Ampere
Ampere
Ampere / RTX 30
GPU
GPU
GPU
11 ?
11 ?
GPU-
GPU
GPU?
PCIe 4.0?
PCIe 8x/16x?
RTX 3090, 3 PCIe?
4 RTX 3090 4 RTX 3080?
GPU ?
NVLink, ?
. ?
?
?
Intel GPU?
?
AMD GPU + ROCm - NVIDIA GPU + CUDA?
, – GPU?
,
Dieser Artikel ist wie folgt aufgebaut. Zuerst erkläre ich, was eine GPU schnell macht. Ich werde den Unterschied zwischen Prozessoren und GPUs, Tensorkernen, Speicherbandbreite, GPU-Speicherhierarchie und den Zusammenhang zwischen Leistung und GO-Aufgaben beschreiben. Diese Erklärungen können Ihnen helfen, besser zu verstehen, welche GPU-Parameter Sie benötigen. Dann werde ich theoretische Schätzungen der GPU-Leistung und deren Übereinstimmung mit einigen NVIDIA-Geschwindigkeitstests geben, um zuverlässige Leistungsdaten ohne Verzerrung zu erhalten. Ich werde die einzigartigen Eigenschaften der NVIDIA RTX 30 Ampere-GPUs beschreiben, die beim Kauf zu berücksichtigen sind. Dann gebe ich GPU-Empfehlungen für 1-2 Chip-, 4, 8- und GPU-Cluster. Dann gibt es einen Abschnitt mit Antworten auf häufig gestellte Fragen, die mir auf Twitter gestellt wurden.Es wird auch häufige Missverständnisse zerstreuen und verschiedene Probleme wie Clouds gegenüber Desktops, Kühlung, AMD gegenüber NVIDIA und andere hervorheben.
Wie funktionieren GPUs?
Wenn Sie häufig GPUs verwenden, ist es hilfreich zu verstehen, wie diese funktionieren. Dieses Wissen ist hilfreich, um zu verstehen, warum GPUs in einigen Fällen langsamer und in anderen schneller sind. Und dann werden Sie vielleicht verstehen, ob Sie überhaupt eine GPU benötigen und welche Hardwareoptionen in Zukunft damit konkurrieren können. Sie können diesen Abschnitt überspringen, wenn Sie nur einige nützliche Leistungsinformationen und Argumente für die Auswahl einer bestimmten GPU benötigen. Meine beste allgemeine Erklärung für die Funktionsweise von GPUs ist die Antwort auf Quora .
Dies ist eine allgemeine Erklärung und erklärt gut die Frage, warum GPUs für GO besser geeignet sind als Prozessoren. Wenn wir die Details untersuchen, können wir verstehen, wie sich GPUs voneinander unterscheiden.
Die wichtigsten GPU-Eigenschaften, die die Verarbeitungsgeschwindigkeit beeinflussen
Dieser Abschnitt hilft Ihnen dabei, intuitiver über die Leistung im Bereich GO nachzudenken. Dieses Verständnis hilft Ihnen, zukünftige GPUs selbst zu bewerten.
Tensorkerne
Zusammenfassung:
- Tensorkerne reduzieren die Anzahl der zum Zählen von Multiplikationen und Additionen erforderlichen Taktzyklen um das 16-fache - in meinem Beispiel für eine 32 × 32-Matrix von 128 auf 8 Taktzyklen.
- Tensorkerne reduzieren die Abhängigkeit von wiederholtem Zugriff auf gemeinsam genutzten Speicher und sparen Speicherzugriffszyklen.
- Tensorkerne sind so schnell, dass die Berechnung kein Engpass mehr ist. Der einzige Engpass ist die Übertragung von Daten an sie.
Es gibt heutzutage so viele kostengünstige GPUs, dass sich fast jeder eine GPU mit Tensorkernen leisten kann. Daher empfehle ich immer GPUs mit Tensorkernen. Es ist hilfreich zu verstehen, wie sie funktionieren, um die Bedeutung dieser auf Matrixmultiplikation spezialisierten Rechenmodule zu erkennen. Anhand eines einfachen Beispiels für die Matrixmultiplikation A * B = C, bei der die Größe aller Matrizen 32 × 32 beträgt, zeige ich Ihnen, wie die Multiplikation mit und ohne Tensorkerne aussieht.
Um dies zu verstehen, müssen Sie zuerst das Konzept der Balken verstehen. Wenn der Prozessor mit 1 GHz läuft, macht er 10 9Zecken pro Sekunde. Jede Uhr ist eine Gelegenheit für Berechnungen. In den meisten Fällen dauert der Betrieb jedoch länger als einen Taktzyklus. Es stellt sich eine Pipeline heraus. Um eine Operation auszuführen, müssen Sie zunächst so viele Taktzyklen warten, wie erforderlich sind, um die vorherige Operation abzuschließen. Dies wird auch als verzögerter Betrieb bezeichnet.
Hier sind einige wichtige Dauern oder Verzögerungen einer Operation in Zecken:
- Zugriff auf globalen Speicher bis zu 48 GB: ~ 200 Taktzyklen.
- Shared Memory-Zugriff (bis zu 164 KB pro Streaming-Multiprozessor): ~ 20 Takte.
- Kombinierte Multiplikationsaddition (SUS): 4 Maßnahmen.
- Matrixmultiplikation in Tensorkernen: 1 Taktzyklus.
Außerdem müssen Sie wissen, dass die kleinste Thread-Einheit in einer GPU - ein Paket mit 32 Threads - als Warp bezeichnet wird. Warps arbeiten normalerweise synchron - alle Threads im Warp müssen aufeinander warten. Alle GPU-Speicheroperationen sind für Warps optimiert. Zum Laden aus dem globalen Speicher werden beispielsweise 32 * 4 Bytes benötigt - 32 Gleitkommazahlen, eine solche Zahl für jeden Thread im Warp. In einem Streaming-Multiprozessor (entspricht einem Prozessorkern für eine GPU) können bis zu 32 Warps = 1024 Threads vorhanden sein. Multiprozessor-Ressourcen werden von allen aktiven Warps gemeinsam genutzt. Daher benötigen wir manchmal weniger Warps, um zu arbeiten, sodass ein Warp mehr Register, gemeinsamen Speicher und Tensorkernressourcen hat.
Nehmen wir für beide Beispiele an, wir haben die gleichen Rechenressourcen. In diesem kleinen Beispiel für eine 32 × 32-Matrixmultiplikation verwenden wir 8 Multiprozessoren (~ 10% des RTX 3090) und 8 Warps auf einem Multiprozessor.
Matrixmultiplikation ohne Tensorkerne
Wenn wir Matrizen A * B = C multiplizieren müssen, von denen jede eine Größe von 32 × 32 hat, müssen wir Daten aus dem Speicher, auf den wir ständig zugreifen, in den gemeinsamen Speicher laden, da die Zugriffsverzögerungen etwa zehnmal geringer sind (nicht 200 Takte und 20 Takte). Ein Speicherblock im gemeinsam genutzten Speicher wird häufig als Speicherkachel oder einfach als Kachel bezeichnet. Das Laden von zwei 32 × 32-Gleitkommazahlen in eine gemeinsam genutzte Speicherkachel kann parallel mit 2 * 32-Warps erfolgen. Wir haben 8 Multiprozessoren mit jeweils 8 Warps. Dank der Parallelisierung müssen wir also eine sequentielle Last vom globalen in den gemeinsam genutzten Speicher ausführen, die 200 Taktzyklen benötigt.
Um Matrizen zu multiplizieren, müssen wir einen Vektor mit 32 Zahlen aus dem gemeinsam genutzten Speicher A und dem gemeinsam genutzten Speicher B laden, das CMS ausführen und dann die Ausgabe in den Registern C speichern. Wir teilen diese Arbeit so auf, dass jeder Multiprozessor 8 skalare Produkte (32 × 32) behandelt ) um 8 Ausgabedaten für C zu berechnen. Warum es genau 8 davon gibt (in alten Algorithmen - 4), ist dies eine rein technische Funktion. Um es herauszufinden, empfehle ich, den Artikel von Scott Gray zu lesen . Dies bedeutet, dass wir 8 Zugriffe auf den gemeinsam genutzten Speicher haben, die jeweils 20 Zyklen kosten, und 8 SLS-Operationen (32 parallel), die jeweils 4 Zyklen kosten. Insgesamt betragen die Kosten:
200 Ticks (globaler Speicher) + 8 * 20 Ticks (gemeinsamer Speicher) + 8 * 4 Ticks (CMS) = 392 Ticks.
Betrachten wir nun diese Kosten für Tensorkerne.
Matrixmultiplikation mit Tensorkernen
Tensorkerne können verwendet werden, um 4 × 4-Matrizen in einem Zyklus zu multiplizieren. Dazu müssen wir Speicher in Tensorkerne kopieren. Wie oben müssen wir Daten aus dem globalen Speicher (200 Ticks) lesen und im gemeinsamen Speicher speichern. Um 32 × 32 Matrizen zu multiplizieren, müssen wir 8 × 8 = 64 Operationen in Tensorkernen ausführen. Ein Multiprozessor enthält 8 Tensorkerne. Mit 8 Multiprozessoren haben wir 64 Tensorkerne - genau so viele wie wir brauchen! Wir können Daten aus dem gemeinsam genutzten Speicher in 1 Übertragung (20 Taktzyklen) auf Tensorkerne übertragen und dann alle diese 64 Operationen parallel ausführen (1 Taktzyklus). Dies bedeutet, dass die Gesamtkosten der Matrixmultiplikation in Tensorkernen betragen:
200 Taktzyklen (globaler Speicher) + 20 Taktzyklen (gemeinsamer Speicher) + 1 Taktzyklus (Tensorkerne) = 221 Taktzyklen
Durch die Verwendung von Tensorkernen reduzieren wir die Kosten für die Matrixmultiplikation erheblich von 392 auf 221 Taktzyklen. In unserem vereinfachten Beispiel haben Tensorkerne die Kosten sowohl für den Zugriff auf gemeinsam genutzten Speicher als auch für SNS-Operationen gesenkt.
Obwohl dieses Beispiel ungefähr der Abfolge von Rechenschritten mit und ohne Tensorkerne folgt, beachten Sie bitte, dass dies ein sehr vereinfachtes Beispiel ist. In realen Fällen beinhaltet die Matrixmultiplikation ähnliche Speicherkacheln und leicht unterschiedliche Abfolgen von Aktionen.
Mir scheint jedoch, dass dieses Beispiel deutlich macht, warum das nächste Attribut, die Speicherbandbreite, für GPUs mit Tensorkernen so wichtig ist. Da globaler Speicher beim Multiplizieren von Matrizen mit Tensorkernen am teuersten ist, wären unsere GPUs viel schneller, wenn wir die Latenz des Zugriffs auf globalen Speicher verringern könnten. Dies kann entweder durch Erhöhen der Speichertaktrate (mehr Takte pro Sekunde, aber mehr Wärme- und Stromverbrauch) oder durch Erhöhen der Anzahl von Elementen erfolgen, die gleichzeitig übertragen werden können (Busbreite).
Speicherbandbreite
Im vorherigen Abschnitt haben wir gesehen, wie schnell Tensorkerne sind. Sie sind so schnell, dass sie die meiste Zeit im Leerlauf sitzen und darauf warten, dass Daten aus dem globalen Speicher eintreffen. Während des Trainings für das BERT Large-Projekt, bei dem sehr große Matrizen verwendet wurden - je größer, desto besser für Tensorkerne -, betrug die Auslastung der Tensorkerne in TFLOPS etwa 30%, was bedeutet, dass die Tensorkerne in 70% der Fälle im Leerlauf waren.
Dies bedeutet, dass beim Vergleich von zwei GPUs mit Tensorkernen einer der besten Leistungsindikatoren für jeden die Speicherbandbreite ist. Beispielsweise hat die A100-GPU eine Bandbreite von 1,555 GB / s, während die V100 900 GB / s hat. Eine einfache Berechnung besagt, dass der A100 1555/900 = 1,73-mal schneller sein wird als der V100.
Shared Memory / L1 Cache / Register
Da der Geschwindigkeitsbegrenzungsfaktor die Übertragung von Daten in den Speicher von Tensorkernen ist, müssen wir uns anderen Eigenschaften der GPU zuwenden, um die Übertragung von Daten an diese zu beschleunigen. Damit verbunden sind Shared Memory, L1-Cache und Anzahl der Register. Um zu verstehen, wie die Speicherhierarchie die Datenübertragung beschleunigt, ist es hilfreich zu verstehen, wie sich die Matrix in der GPU vervielfacht.
Für die Matrixmultiplikation verwenden wir eine Speicherhierarchie, die vom langsamen globalen Speicher zum schnellen lokalen gemeinsam genutzten Speicher und dann zu ultraschnellen Registern reicht. Je schneller der Speicher ist, desto kleiner ist er jedoch. Daher müssen wir die Matrizen in kleinere aufteilen und diese kleineren Kacheln dann im lokalen gemeinsamen Speicher multiplizieren. Dann geschieht dies schnell und näher am Streaming-Multiprozessor (PM) - dem Äquivalent des Prozessorkerns. Mit Tensorkernen können wir noch einen Schritt tun: Wir nehmen alle Kacheln und laden einige davon in Tensorkerne. Der gemeinsam genutzte Speicher verarbeitet Matrixkacheln 10-50-mal schneller als der globale GPU-Speicher, und Tensorkernregister verarbeiten sie 200-mal schneller als der globale GPU-Speicher.
Durch Erhöhen der Kacheln können wir mehr Speicher wiederverwenden. Ich habe darüber ausführlich in meinem Artikel TPU vs GPU geschrieben . In TPU gibt es für jeden Tensorkern eine sehr, sehr große Kachel. TPUs können mit jeder neuen Übertragung aus dem globalen Speicher viel mehr Speicher wiederverwenden, was sie bei der Handhabung der Matrixmultiplikation im Vergleich zu GPUs etwas effizienter macht.
Die Kachelgrößen werden durch die Speichermenge für jede PM bestimmt - das Äquivalent eines Prozessorkerns auf einer GPU. Abhängig von den Architekturen sind diese Volumes:
- Volta: 96 KB gemeinsamer Speicher / 32 KB L1
- Turing: 64 KB gemeinsamer Speicher / 32 KB L1
- Ampere: 164 KB gemeinsamer Speicher / 32 KB L1
Sie können sehen, dass Ampere über viel mehr gemeinsam genutzten Speicher verfügt, wodurch größere Kacheln verwendet werden können, wodurch die Anzahl der globalen Speicherzugriffe verringert wird. Daher nutzt Ampere die GPU-Speicherbandbreite effizienter. Dies erhöht die Leistung um 2-5%. Der Anstieg macht sich insbesondere bei großen Matrizen bemerkbar.
Ampere-Tensorkerne haben einen weiteren Vorteil: Sie haben eine größere Datenmenge, die mehreren Threads gemeinsam ist. Dies reduziert die Anzahl der Registeraufrufe. Die Größe der Register ist auf 64 k pro PM oder 255 pro Thread begrenzt. Im Vergleich zu Volta verwenden Ampere-Tensorkerne dreimal weniger Register, sodass sich im gemeinsam genutzten Speicher mehr aktive Tensorkerne pro Kachel befinden. Mit anderen Worten, wir können dreimal so viele Tensorkerne mit der gleichen Anzahl von Registern laden. Da die Bandbreite jedoch ein Engpass bleibt, wird der Anstieg der TFLOPS in der Praxis im Vergleich zur Theorie vernachlässigbar sein. Neue Tensorkerne haben die Leistung um etwa 1-3% verbessert.
Insgesamt ist ersichtlich, dass die Ampere-Architektur optimiert wurde, um die Speicherbandbreite durch eine verbesserte Hierarchie effizienter zu nutzen - vom globalen Speicher über gemeinsam genutzte Speicherkacheln bis hin zu Tensorkernregistern.
Bewertung der Wirksamkeit von Ampere in GO
Zusammenfassung:
- Theoretische Schätzungen basierend auf der Speicherbandbreite und der verbesserten Speicherhierarchie für Ampere-GPUs sagen eine 1,78- bis 1,87-fache Beschleunigung voraus.
- NVIDIA hat Daten zu Geschwindigkeitsmessungen für Tesla A100- und V100-GPUs veröffentlicht. Sie sind mehr Marketing, aber ein unvoreingenommenes Modell kann auf ihrer Basis aufgebaut werden.
- Das unvoreingenommene Modell legt nahe, dass der Tesla A100 im Vergleich zum V100 1,7-mal schneller in der Verarbeitung natürlicher Sprache und 1,45-mal schneller in der Bildverarbeitung ist.
Dieser Abschnitt richtet sich an diejenigen, die sich eingehender mit den technischen Details befassen möchten, wie ich die Ampere-GPU-Leistungswerte erhalten habe. Wenn Sie nicht interessiert sind, können Sie es sicher überspringen.
Ampere theoretische Geschwindigkeitsschätzungen
Angesichts der obigen Argumente würde man erwarten, dass der Unterschied zwischen den beiden GPU-Architekturen mit Tensorkernen hauptsächlich in der Speicherbandbreite liegen sollte. Weitere Vorteile ergeben sich aus dem erhöhten gemeinsamen Speicher und L1-Cache sowie der effizienten Verwendung von Registern.
Die Bandbreite der Tesla A100-GPU ist im Vergleich zum Tesla V100 um das 1555/900 = 1,73-fache erhöht. Es ist auch vernünftig, eine Geschwindigkeitssteigerung von 2 bis 5% aufgrund des größeren Gesamtspeichers und von 1 bis 3% aufgrund der Verbesserung der Tensorkerne zu erwarten. Es stellt sich heraus, dass die Beschleunigung das 1,78- bis 1,87-fache betragen sollte.
Ampere
Angenommen, wir haben einen einzelnen GPU-Score für eine Architektur wie Ampere, Turing oder Volta. Es ist einfach, diese Ergebnisse auf andere GPUs derselben Architektur oder Serie zu extrapolieren. Glücklicherweise hat NVIDIA bereits Benchmarks durchgeführt, in denen A100 und V100 für verschiedene Aufgaben im Zusammenhang mit Computer Vision und dem Verständnis natürlicher Sprache verglichen wurden. Leider hat NVIDIA alles getan, damit diese Zahlen nicht direkt verglichen werden können. In den Tests wurden unterschiedliche Paketgrößen und eine unterschiedliche Anzahl von GPUs verwendet, sodass der A100 nicht gewinnen konnte. In gewissem Sinne sind die erhaltenen Leistungsindikatoren teils ehrlich, teils werblich. Im Allgemeinen kann argumentiert werden, dass die Erhöhung der Datenpaketgröße gerechtfertigt ist, da der A100 über mehr Speicher verfügt - jedochUm GPU-Architekturen zu vergleichen, müssen wir unverzerrte Leistungsdaten für Aufgaben mit derselben Datenpaketgröße vergleichen.
Um unvoreingenommene Schätzungen zu erhalten, können Sie die V100- und A100-Messungen auf zwei Arten skalieren: Berücksichtigen Sie den Unterschied in der Datenpaketgröße oder berücksichtigen Sie den Unterschied in der Anzahl der GPUs - 1 gegenüber 8. Wir haben Glück und können ähnliche Schätzungen für beide Fälle in den von NVIDIA bereitgestellten Daten finden.
Durch Verdoppeln der Paketgröße wird der Durchsatz in Bildern pro Sekunde um 13,6% erhöht (für Faltungs-Neuronale Netze CNN). Ich habe die Geschwindigkeit derselben Aufgabe mit der Transformer-Architektur auf meinem RTX Titan gemessen und überraschenderweise das gleiche Ergebnis erzielt - 13,5%. Dies scheint eine verlässliche Schätzung zu sein.
Durch die Erhöhung der Parallelisierung von Netzwerken und die Erhöhung der Anzahl von GPUs verlieren wir an Leistung aufgrund des mit Netzwerken verbundenen Overheads. Die A100 8x-GPU bietet im Netzwerk eine bessere Leistung (NVLink 3.0) als die V100 8x-GPU (NVLink 2.0) - ein weiterer verwirrender Faktor. Wenn Sie sich die Daten von NVIDIA ansehen, sehen Sie, dass das System mit dem 8. A100 für die Verarbeitung des SNS 5% weniger Overhead hat als das System mit dem 8. V10000. Dies bedeutet, dass wenn der Übergang vom 1. A10000 zum 8. A10000 eine Beschleunigung von beispielsweise 7,0-mal ergibt, der Übergang vom 1. V10000 zum 8. V10000 nur eine 6,67-fache Beschleunigung ergibt. Bei Transformatoren beträgt diese Zahl 7%.
Mithilfe dieser Informationen können wir die Beschleunigung einiger spezifischer GO-Architekturen direkt anhand der von NVIDIA bereitgestellten Daten abschätzen. Der Tesla A100 bietet gegenüber dem Tesla V100 folgende Geschwindigkeitsvorteile:
- SE-ResNeXt101: 1,43 mal.
- Maskiertes R-CNN: 1,47-mal.
- Transformator (12 Schichten, maschinelle Übersetzung, WMT14 en-de): 1,70-mal.
Für die Bildverarbeitung werden die Zahlen daher unterhalb der theoretischen Schätzung erhalten. Dies kann auf kleinere Tensordimensionen, den Aufwand für die zur Erstellung einer Matrixmultiplikation wie img2col oder FFT erforderlichen Operationen oder auf Operationen zurückzuführen sein, die die GPU nicht sättigen können (die resultierenden Schichten sind häufig relativ klein). Es können auch Artefakte bestimmter Architekturen sein (gruppierte Faltung).
Die praktische Beurteilung der Drehzahl des Transformators kommt der theoretischen sehr nahe. Wahrscheinlich, weil die Algorithmen für die Arbeit mit großen Matrizen sehr einfach sind. Ich werde praktische Schätzungen verwenden, um die Kosteneffizienz einer GPU zu berechnen.
Mögliche Ungenauigkeiten der Schätzungen
Die obigen Angaben sind Vergleichswerte für A100 und V100. In der Vergangenheit hat NVIDIA die Leistung von "Gaming" RTX-GPUs heimlich verschlechtert: Reduzierte Nutzung von Tensorkernen, zusätzliche Gaming-Lüfter zur Kühlung und verbotene Datenübertragung zwischen GPUs. Es ist möglich, dass die RT 30-Serie gegenüber dem Ampere A100 auch unbekannte Beeinträchtigungen aufweist.
Was ist beim Ampere / RTX 30 noch zu beachten?
Zusammenfassung:
- Mit Ampere können Sie Netzwerke trainieren, die auf spärlichen Matrizen basieren, was den Trainingsprozess bis zu zweimal beschleunigt.
- Spärliches Netzwerktraining wird immer noch selten eingesetzt, aber dank dessen wird Ampere nicht so schnell veraltet sein.
- Ampere verfügt über neue Datentypen mit geringer Genauigkeit, die die Verwendung mit geringer Genauigkeit erheblich vereinfachen, jedoch nicht unbedingt eine Geschwindigkeitssteigerung gegenüber früheren GPUs bewirken.
- Das neue Lüfterdesign ist gut, wenn Sie freien Platz zwischen den GPUs haben. Es ist jedoch nicht klar, ob nahe beieinander stehende GPUs effektiv kühlen.
- Das 3-Slot-Design des RTX 3090 wird eine Herausforderung für 4 GPU-Builds sein. Mögliche Lösungen sind die Verwendung von 2-Slot-Optionen oder PCIe-Expandern.
- Die vier RTX 3090 benötigen mehr Strom als jedes Standardnetzteil auf dem Markt bieten kann.
Der neue NVIDIA Ampere RTX 30 bietet gegenüber dem NVIDIA Turing RTX 20 zusätzliche Vorteile - spärliches Lernen und verbesserte Verarbeitung neuronaler Netze. Der Rest der Eigenschaften, wie z. B. neue Datentypen, kann als einfache Komfortverbesserung angesehen werden - sie beschleunigen die Dinge auf die gleiche Weise wie die Turing-Serie, ohne dass zusätzliche Programmierung erforderlich ist.
Sparsames Lernen
Mit Ampere können Sie spärliche Matrizen mit hoher Geschwindigkeit und automatisch multiplizieren. Das funktioniert so: Sie nehmen eine Matrix, schneiden sie in Stücke von 4 Elementen, und der Tensorkern, der spärliche Matrizen unterstützt, ermöglicht, dass zwei dieser vier Elemente Null sind. Dies führt zu einer zweifachen Beschleunigung, da sich die Bandbreitenanforderungen während der Matrixmultiplikation halbieren.
In meiner Forschung habe ich mit spärlichen Lernnetzwerken gearbeitet. Die Arbeit wurde insbesondere dafür kritisiert, dass ich "die für das Netzwerk erforderlichen FLOPS reduziere, aber aus diesem Grund die Geschwindigkeit nicht erhöhe, weil GPUs dünn besetzte Matrizen nicht schnell multiplizieren können". In Tensorkernen und meinem Algorithmus oder einem anderen Algorithmus ( Link) wurde die Unterstützung für die Multiplikation mit spärlicher Matrix gut unterstützt, link , link , link ), die mit spärlichen Matrizen arbeiten, können jetzt während des Trainings tatsächlich doppelt so schnell arbeiten.
Obwohl diese Eigenschaft derzeit als experimentell angesehen wird und spärliches Netzwerktraining nicht universell angewendet wird, sind Sie bereit für die Zukunft des spärlichen Trainings, wenn Ihre GPU diese Technologie unterstützt.
Berechnungen mit geringer Genauigkeit
Ich habe bereits in meiner Arbeit gezeigt, wie neue Datentypen die Stabilität der Backpropagation mit niedriger Wiedergabetreue verbessern können. Bisher besteht das Problem bei einer stabilen Backpropagation mit 16-Bit-Gleitkommazahlen darin, dass reguläre Datentypen nur die Spanne unterstützen [-65.504, 65.504]. Wenn Ihr Gradient diese Lücke überschreitet, explodiert er und ergibt NaN-Werte. Um dies zu verhindern, skalieren wir die Werte normalerweise, indem wir sie vor dem Backpropagieren mit einer kleinen Zahl multiplizieren, um die Explosion des Gradienten zu vermeiden.
Das Brain Float 16 (BF16) -Format verwendet mehr Bits für den Exponenten, sodass der Bereich möglicher Werte der gleiche ist wie in FP32: [-3 * 10 ^ 38, 3 * 10 ^ 38]. Der BF16 hat eine geringere Präzision, d.h. weniger signifikante Stellen, aber die Genauigkeit des Gradienten beim Training von Netzwerken ist nicht so wichtig. Daher stellt BF16 sicher, dass Sie keine Skalierung durchführen oder sich um eine Gradientenexplosion sorgen müssen. Bei diesem Format sollte die Trainingsstabilität auf Kosten eines geringen Präzisionsverlusts erhöht werden.
Was dies für Sie bedeutet: Die Genauigkeit von BF16 kann konsistenter sein als die Genauigkeit von FP16, aber die Geschwindigkeit ist dieselbe. Mit TF32-Präzision erhalten Sie Stabilität fast wie bei FP32 und Beschleunigung fast wie bei FP16. Das Plus ist, dass Sie bei Verwendung dieser Datentypen FP32 in TF32 und FP16 in BF16 ändern können, ohne den Code zu ändern!
Im Allgemeinen können diese neuen Datentypen als faul angesehen werden, da Sie alle ihre Vorteile mit den alten Datentypen und ein wenig Programmierung (korrekte Skalierung, Initialisierung, Normalisierung, Verwendung von Apex) erzielen können. Daher bieten diese Datentypen keine Beschleunigung, erleichtern jedoch die Verwendung von Low-Fidelity im Training.
Neues Lüfterdesign und Probleme mit der Wärmeableitung
Das neue Lüfterdesign für die RTX 30-Serie verfügt über einen Luftgebläse und einen Luftzugventilator. Das Design selbst ist genial und funktioniert sehr effizient, wenn zwischen den GPUs freier Speicherplatz vorhanden ist. Es ist jedoch nicht klar, wie sich GPUs verhalten, wenn sie zueinander gezwungen werden. Der Gebläse kann Luft von anderen GPUs wegblasen, aber es ist unmöglich zu sagen, wie dies funktioniert, da sich seine Form von der vorherigen unterscheidet. Wenn Sie planen, 1 oder 2 GPUs mit 4 Steckplätzen zu platzieren, sollten Sie kein Problem haben. Wenn Sie jedoch 3-4 RTX 30-GPUs nebeneinander verwenden möchten, würde ich zuerst auf Berichte über das Temperaturregime warten und dann entscheiden, ob ich mehr Lüfter, PCIe-Expander oder andere Lösungen benötige.
In jedem Fall kann die Wasserkühlung helfen, das Problem mit dem Kühlkörper zu lösen. Viele Hersteller bieten solche Lösungen für RTX 3080 / RTX 3090-Karten an, und dann werden sie auch bei 4 nicht warm. Kaufen Sie jedoch keine vorgefertigten GPU-Lösungen, wenn Sie einen Computer mit 4 GPUs bauen möchten, da dies in den meisten Fällen sehr schwierig ist Heizkörper verteilen.
Eine andere Lösung für das Kühlungsproblem besteht darin, PCIe-Expander zu kaufen und die Karten im Gehäuse zu verteilen. Dies ist sehr effektiv - ich und andere Doktoranden der Vanington University haben diese Option mit großem Erfolg genutzt. Es sieht nicht sehr ordentlich aus, aber GPUs werden nicht heiß! Diese Option hilft auch, wenn Sie nicht genügend Speicherplatz für die GPU haben. Wenn Sie Platz in Ihrem Koffer haben, können Sie beispielsweise einen Standard-RTX 3090 mit drei Steckplätzen kaufen und diese mithilfe von Expandern im gesamten Koffer verteilen. Somit ist es möglich, gleichzeitig das Problem des Raums und der Kühlung von 4 RTX 3090 zu lösen

. 1: 4 GPU mit PCIe Expanders
Karten mit drei Steckplätzen und Stromprobleme
Der RTX 3090 belegt 3 Steckplätze, sodass sie nicht mit den Standardlüftern von NVIDIA jeweils 4 verwendet werden können. Dies ist nicht überraschend, da 350 W TDP erforderlich sind. Der RTX 3080 ist nur geringfügig schlechter und benötigt 320 W TDP. Die Kühlung eines Systems mit vier RTX 3080 wird sehr schwierig sein.
Es ist auch schwierig, ein System mit 4 Karten mit 350 W = 1400 W zu betreiben. Es gibt 1600-W-Netzteile (PSUs), aber 200 W für Prozessor und Motherboard reichen möglicherweise nicht aus. Der maximale Stromverbrauch tritt nur bei Volllast auf, und während der HE ist der Prozessor normalerweise leicht belastet. Daher ist ein 1600-W-Netzteil möglicherweise für 4 RTX 3080 geeignet. Für 4 RTX 3090 ist es jedoch besser, nach einem 1700-W- oder mehr-Netzteil zu suchen. Es gibt heute keine derartigen Netzteile auf dem Markt. Server-Netzteile oder spezielle Blöcke für Kryptominierer funktionieren möglicherweise, haben jedoch möglicherweise einen ungewöhnlichen Formfaktor.
GPU-Effizienz beim Deep Learning
Der nächste Test umfasste nicht nur Vergleiche von Tesla A100 und Tesla V100 - ich baute ein Modell, das in diese Daten passt, und vier verschiedene Tests, bei denen Titan V, Titan RTX, RTX 2080 Ti und RTX 2080 getestet wurden ( Link , Link , Link , Link ).
Ich habe auch die Benchmark-Ergebnisse für Karten mit mittlerer Reichweite wie RTX 2070, RTX 2060 oder Quadro RTX durch Interpolation der Testdatenpunkte skaliert. Typischerweise werden solche Daten in der GPU-Architektur in Bezug auf Matrixmultiplikation und Speicherbandbreite linear skaliert.
Ich habe nur Daten aus FP16-Trainingstests mit gemischter Präzision gesammelt, da ich keinen Grund sehe, warum Training mit FP32-Nummern verwendet werden sollte.

Zahl: 2: Durch RTX 2080 Ti normalisierte Leistung
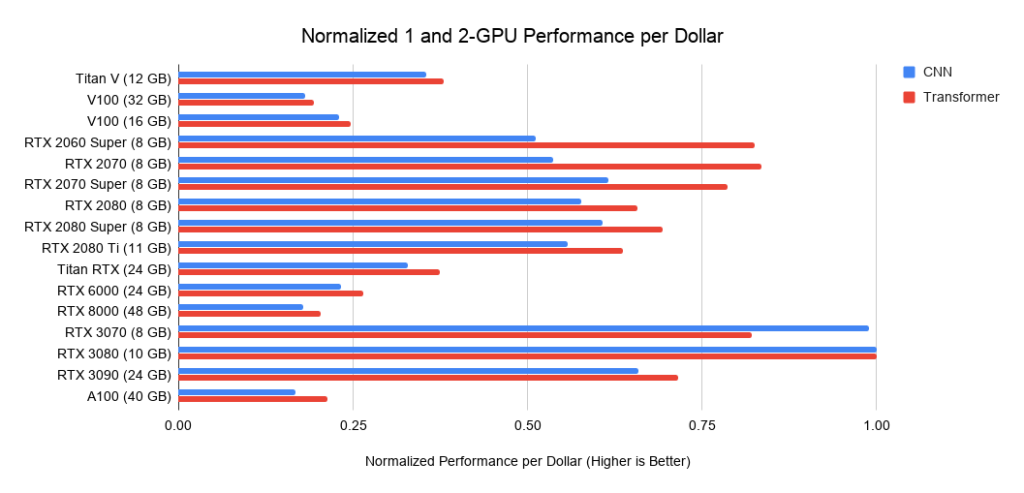
Im Vergleich zum RTX 2080 Ti läuft der RTX 3090 mit Faltungsnetzwerken 1,57-mal schneller, mit Transformatoren 1,5-mal schneller und kostet 15% mehr. Es stellt sich heraus, dass der Ampere RTX 30 seit der Turing RTX 20-Serie eine deutliche Verbesserung aufweist.
GPU Deep Learning Rate pro Kosten
Welche GPU bietet das beste Preis-Leistungs-Verhältnis? Es hängt alles von den Gesamtkosten des Systems ab. Wenn es teuer ist, ist es sinnvoll, in teurere GPUs zu investieren.
Nachfolgend finden Sie Daten zu drei Baugruppen auf PCIe 3.0, die ich als Grundlage für die Kosten von Systemen mit 2 oder 4 GPUs verwende. Ich nehme diese Grundkosten und addiere die GPU-Kosten dazu. Letzteres berechne ich als Durchschnittspreis zwischen Angeboten von Amazon und eBay. Für neue Ampere verwende ich nur einen Preis. Zusammen mit den obigen Leistungsdaten ergeben sich die Leistungswerte pro Dollar. Für ein System mit 8 GPUs nehme ich den Supermicro-Barebone als Industriestandard für RTX-Server. Die gezeigten Grafiken enthalten keinen Speicherbedarf. Sie müssen zuerst überlegen, welchen Speicher Sie benötigen, und dann nach den besten Optionen in den Diagrammen suchen. Beispieltipps für das Gedächtnis:
- Verwenden Sie vorab trainierte Transformatoren oder trainieren Sie einen kleinen Transformator von Grund auf> = 11 GB.
- Schulung eines großen Transformators oder Faltungsnetzwerks in Forschung oder Produktion:> = 24 GB.
- Prototyping neuronaler Netze (Transformator oder Faltungsnetzwerk)> = 10 GB.
- Teilnahme an Kaggle-Wettbewerben> = 8 GB.
- Computer Vision> = 10 GB.
Zahl:

Abbildung 3: Normalisierte Dollar-Performance gegenüber RTX 3080 . Abbildung 4: Normalisierte Dollar-Performance gegenüber RTX 3080
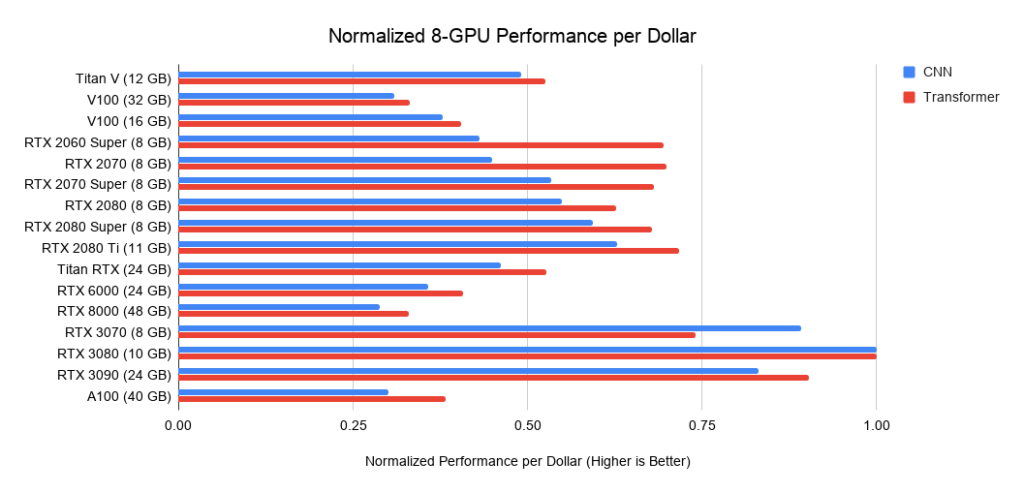
. 5: Normalisierte Dollar-Performance gegenüber RTX 3080.
GPU-Empfehlungen
Ich möchte noch einmal betonen: Stellen Sie bei der Auswahl einer GPU zunächst sicher, dass genügend Speicher für Ihre Aufgaben vorhanden ist. Die Schritte zur Auswahl einer GPU sollten wie folgt sein:
- , GPU: Kaggle, , , , - .
- , .
- GPU, .
- GPU - ? , RTX 3090, ? GPU? , GPU?
Bei einigen Schritten müssen Sie überlegen, was Sie möchten, und ein wenig nachforschen, wie viel Speicher andere Benutzer verwenden, wenn sie dasselbe tun. Ich kann einige Ratschläge geben, aber ich kann nicht alle Fragen in diesem Bereich vollständig beantworten.
Wann benötige ich mehr als 11 GB Speicherplatz?
Ich habe bereits erwähnt, dass Sie für die Arbeit mit Transformatoren mindestens 11 GB und für die Forschung in diesem Bereich mindestens 24 GB benötigen. Die meisten der zuvor vorgefertigten Modelle haben einen sehr hohen Speicherbedarf und wurden auf einer RTX 2080 Ti oder höheren GPU mit mindestens 11 GB Speicher trainiert. Wenn Sie weniger als 11 GB Arbeitsspeicher haben, kann das Starten einiger Modelle daher schwierig oder sogar unmöglich werden.
Andere Bereiche, die viel Speicher benötigen, sind medizinische Bildgebung, fortschrittliche Computer-Vision-Modelle und alle mit großen Bildern.
Wenn Sie Modelle entwickeln möchten, die die Konkurrenz übertreffen können - sei es Forschung, industrielle Anwendungen oder Kaggle-Konkurrenz -, kann Ihnen der zusätzliche Speicher insgesamt einen Wettbewerbsvorteil verschaffen.
Wann kommen Sie mit weniger als 11 GB Speicher aus?
Die RTX 3070- und RTX 3080-Karten sind leistungsstark, haben jedoch keinen Speicher. Für viele Aufgaben ist diese Speichermenge jedoch möglicherweise nicht erforderlich.
Der RTX 3070 ist ideal für das GO-Training. Grundlegende Netzwerkfähigkeiten für die meisten Architekturen können durch Herunterskalieren der Netzwerke oder Verwenden kleinerer Bilder erworben werden. Wenn ich GO lernen müsste, würde ich mir den RTX 3070 aussuchen oder sogar ein paar, wenn ich sie mir leisten könnte.
Die RTX 3080 ist heute die kostengünstigste Karte und daher ideal für das Prototyping. Prototyping erfordert viel Speicher und Speicher ist kostengünstig. Mit Prototyping meine ich Prototyping in jedem Bereich - Forschung, Kaggle-Wettbewerbe, Ideen für ein Startup ausprobieren, mit Forschungscode experimentieren. Für all diese Anwendungen ist der RTX 3080 am besten geeignet.
Wenn ich zum Beispiel ein Forschungslabor oder ein Startup betreiben würde, würde ich 66-80% des Gesamtbudgets für RTX 3080-Maschinen und 20-33% für RTX 3090-Maschinen mit zuverlässiger Wasserkühlung ausgeben. RTX 3080 ist kostengünstiger und kann über Slurm aufgerufen werden... Da das Prototyping im agilen Modus durchgeführt werden muss, muss es mit kleineren Modellen und Datensätzen durchgeführt werden. Und dafür ist der RTX 3080 perfekt. Sobald Studenten / Kollegen ein großartiges Prototypmodell erstellt haben, können sie es auf dem RTX 3090 ausrollen und auf größere Modelle skalieren.
Allgemeine Empfehlungen
Insgesamt sind die Modelle der RTX 30-Serie sehr leistungsstark und ich empfehle sie auf jeden Fall. Berücksichtigen Sie die oben genannten Speicheranforderungen sowie die Strom- und Kühlanforderungen. Wenn Sie einen freien Steckplatz zwischen den GPUs haben, gibt es keine Probleme mit der Kühlung. Andernfalls versorgen Sie die RTX 30-Karten mit Wasserkühlung, PCIe-Expandern oder effizienten Karten mit Lüftern.
Insgesamt würde ich den RTX 3090 jedem empfehlen, der es sich leisten kann. Es wird nicht nur jetzt zu Ihnen passen, sondern es wird auch für die nächsten 3-7 Jahre sehr effektiv bleiben. Es ist unwahrscheinlich, dass der HBM-Speicher in den nächsten drei Jahren viel billiger wird, sodass die nächste GPU nur 25% besser sein wird als der RTX 3090. In 5-7 Jahren werden wir wahrscheinlich einen billigen HBM-Speicher sehen, nach dem Sie die Flotte definitiv aktualisieren müssen ...
Wenn Sie ein System aus mehreren RTX 3090 bauen, sorgen Sie für ausreichende Kühlung und Stromversorgung.
Sofern Sie keine strengen Anforderungen an den Wettbewerbsvorteil haben, würde ich den RTX 3080 empfehlen. Dies ist eine kostengünstigere Lösung und bietet für die meisten Netzwerke ein schnelles Training. Wenn Sie die gewünschten Speichertricks ausführen und nichts dagegen haben, zusätzlichen Code zu schreiben, gibt es viele Tricks, um ein 24-GB-Netzwerk in eine 10-GB-GPU zu packen.
Der RTX 3070 ist auch eine großartige Karte für GO-Schulungen und Prototypen und 200 US-Dollar billiger als der RTX 3080. Wenn Sie sich den RTX 3080 nicht leisten können, ist der RTX 3070 Ihre Wahl.
Wenn Ihr Budget knapp ist und der RTX 3070 zu teuer für Sie ist, können Sie einen gebrauchten RTX 2070 bei eBay für etwa 260 US-Dollar finden. Es ist noch nicht klar, ob der RTX 3060 herauskommen wird, aber wenn Ihr Budget knapp ist, lohnt sich das Warten möglicherweise. Wenn der Preis dem RTX 2060 und dem GTX 1060 entspricht, sollte er zwischen 250 und 300 US-Dollar liegen und eine gute Leistung bringen.
Empfehlungen für GPU-Cluster
Das GPU-Cluster-Layout hängt stark von seiner Verwendung ab. Bei einem System mit 1024 GPUs oder mehr ist das Vorhandensein eines Netzwerks die Hauptsache. Wenn Sie jedoch nicht mehr als 32 GPUs gleichzeitig verwenden, ist es sinnlos, in den Aufbau eines leistungsstarken Netzwerks zu investieren.
Im Allgemeinen können RTX-Karten gemäß der CUDA-Vereinbarung nicht in Rechenzentren verwendet werden. Universitäten können jedoch häufig die Ausnahme von dieser Regel sein. Wenn Sie eine solche Genehmigung erhalten möchten, wenden Sie sich an einen NVIDIA-Vertreter. Wenn Sie RTX-Karten verwenden können, würde ich das 8-GPU-Standardsystem RTX 3080 oder RTX 3090 von Supermicro empfehlen (wenn Sie sie gekühlt halten können). Ein kleiner Satz von 8 A10000-Knoten gewährleistet die effiziente Verwendung von Modellen nach dem Prototyping, insbesondere wenn keine Kühlung von Servern mit 8 RTX 3090 möglich ist. In diesem Fall würde ich den A10000 gegenüber dem RTX 6000 / RTX 8000 empfehlen, da die A10000 recht kostengünstig sind und nicht schnell alt werden.
Wenn Sie sehr große Netzwerke in einem GPU-Cluster (256 GPUs oder mehr) trainieren müssen, würde ich das NVIDIA DGX SuperPOD-System mit A10000 empfehlen. Ab 256 GPUs wird die Vernetzung unverzichtbar. Wenn Sie über 256 GPUs hinaus expandieren möchten, benötigen Sie ein hochoptimiertes System, für das Standardlösungen nicht mehr funktionieren.
Insbesondere auf der 1.024-GPU-Skala und darüber hinaus bleiben Google TPU Pod und NVIDIA DGX SuperPod die einzigen wettbewerbsfähigen Lösungen auf dem Markt. In dieser Größenordnung würde ich den Google TPU Pod bevorzugen, da die dedizierte Netzwerkinfrastruktur besser aussieht als der NVIDIA DGX SuperPod - obwohl die beiden Systeme im Prinzip ziemlich nahe beieinander liegen. In Anwendungen und Hardware ist ein GPU-System flexibler als eine TPU, während TPU-Systeme größere Modelle unterstützen und besser skalieren. Daher haben beide Systeme ihre Vor- und Nachteile.
Welche GPU ist besser nicht zu kaufen
Ich empfehle nicht, mehrere RTX Founders Editions oder RTX Titans gleichzeitig zu kaufen, es sei denn, Sie haben PCIe-Expander, um ihre Kühlprobleme zu lösen. Sie werden sich nur aufwärmen und ihre Geschwindigkeit wird im Vergleich zu den Angaben in den Diagrammen dramatisch sinken. Die vier RTX 2080 Ti Founders Editions heizen sich schnell auf 90 ° C auf, senken die Taktraten und laufen langsamer als ein normal gekühlter RTX 2070.
Ich empfehle den Kauf eines Tesla V100 oder A100 nur in extremen Fällen, da die Verwendung in Rechenzentren von Unternehmen verboten ist. Oder kaufen Sie sie, wenn Sie sehr große Netzwerke in großen GPU-Clustern trainieren müssen - ihr Preis-Leistungs-Verhältnis ist nicht ideal.
Wenn Sie sich etwas Besseres leisten können, entscheiden Sie sich nicht für Karten der GTX 16-Serie. Sie haben keine Tensorkerne, daher ist ihre Leistung in GO schlecht. Ich würde stattdessen einen gebrauchten RTX 2070 / RTX 2060 / RTX 2060 Super nehmen. Sie können ausgeliehen werden, wenn Ihr Budget sehr begrenzt ist.
Wann ist es besser, keine neuen GPUs zu kaufen?
Wenn Sie bereits einen RTX 2080 Ti oder besser besitzen, ist ein Upgrade auf einen RTX 3090 fast sinnlos. Ihre GPUs sind bereits gut und die Geschwindigkeitsvorteile sind im Vergleich zu den erworbenen Strom- und Kühlungsproblemen vernachlässigbar - es lohnt sich nicht.
Der einzige Grund, warum ich von vier RTX 2080 Ti auf vier RTX 3090 upgraden möchte, ist, wenn ich an sehr großen Transformatoren oder anderen Netzwerken geforscht habe, die stark auf Rechenleistung angewiesen sind. Wenn Sie jedoch Speicherprobleme haben, sollten Sie zunächst verschiedene Tricks in Betracht ziehen, um große Modelle in den vorhandenen Speicher zu packen.
Wenn Sie einen oder mehrere RTX 2070 besitzen, würde ich vor dem Upgrade zweimal überlegen, ob ich Sie wäre. Das sind ziemlich gute GPUs. Es kann sinnvoll sein, sie bei eBay zu verkaufen und einen RTX 3090 zu kaufen, wenn Ihnen 8 GB nicht ausreichen - wie dies bei vielen anderen GPUs der Fall ist. Wenn nicht genügend Speicher vorhanden ist, wird ein Update erstellt.
Antworten auf Fragen und Missverständnisse
Zusammenfassung:
- PCIe-Lanes und PCIe 4.0 sind für Dual-GPU-Systeme irrelevant. Bei Systemen mit 4 GPUs ist dies praktisch nicht der Fall.
- Das Abkühlen des RTX 3090 und des RTX 3080 ist schwierig. Verwenden Sie Wasserkühler oder PCIe-Expander.
- NVLink wird nur für GPU-Cluster benötigt.
- Auf demselben Computer können verschiedene GPUs verwendet werden (z. B. GTX 1080 + RTX 2080 + RTX 3090), eine effiziente Parallelisierung funktioniert jedoch nicht.
- Um mehr als zwei Computer gleichzeitig zu betreiben, benötigen Sie Infiniband und ein 50-Gbit / s-Netzwerk.
- AMD-Prozessoren sind billiger als Intel-Prozessoren, und letztere haben fast keine Vorteile.
- Trotz der heldenhaften Bemühungen der Ingenieure wird AMD GPU + ROCm in den nächsten 1-2 Jahren kaum mit NVIDIA konkurrieren können, da es an Community und gleichwertigen Tensorkernen mangelt.
- Cloud-GPUs sind vorteilhaft, wenn sie weniger als ein Jahr lang verwendet werden. Danach wird die Desktop-Version billiger.
Benötige ich PCIe 4.0?
Normalerweise nicht. PCIe 4.0 eignet sich hervorragend für einen GPU-Cluster. Nützlich, wenn Sie einen 8-GPU-Computer haben. In anderen Fällen hat es fast keine Vorteile. Es verbessert die Parallelisierung und überträgt Daten etwas schneller. Die Datenübertragung ist jedoch kein Engpass. In der Bildverarbeitung besteht der Engpass möglicherweise in der Datenspeicherung, nicht jedoch in der PCIe-Datenübertragung von der GPU zur GPU. Daher gibt es für die meisten Menschen keinen Grund, PCIe 4.0 zu verwenden. Dies wird möglicherweise die Parallelisierung von vier GPUs um 1-7% verbessern.
Benötige ich PCIe 8x / 16x-Lanes?
Wie bei PCIe 4.0 normalerweise nicht. PCIe-Lanes sind für die Parallelisierung und schnelle Datenübertragung erforderlich, was fast nie ein Engpass ist. Wenn Sie 2 GPUs haben, reichen 4 Leitungen für sie aus. Für 4 GPUs würde ich 8 Leitungen pro GPU bevorzugen, aber wenn es 4 Leitungen gibt, wird die Leistung nur um 5-10% verringert.
Wie passen Sie vier RTX 3090 an, wenn sie jeweils 3 PCIe-Steckplätze belegen?
Sie können eine von zwei Optionen für einen Steckplatz kaufen oder diese mit PCIe-Expandern verteilen. Neben dem Platzbedarf müssen Sie sofort über Kühlung und ein geeignetes Netzteil nachdenken. Anscheinend wäre die einfachste Lösung der Kauf von 4 x RTX 3090 EVGA Hydro Coppers mit einem speziellen Wasserkühlkreislauf. EVGA stellt seit vielen Jahren wassergekühlte Kupferversionen von Karten her, und Sie können der Qualität ihrer GPUs vertrauen. Vielleicht gibt es billigere Optionen.
PCIe-Expander können Platz- und Kühlungsprobleme lösen, aber Ihr Gehäuse sollte genügend Platz für alle Karten bieten. Und stellen Sie sicher, dass die Extender lang genug sind!
Wie kühle ich 4 RTX 3090 oder 4 RTX 3080?
Siehe den vorherigen Abschnitt.
Kann ich mehrere verschiedene GPU-Typen verwenden?
Ja, aber Sie können die Arbeit nicht effektiv parallelisieren. Ich kann mir ein System vorstellen, auf dem 3 RTX 3070 + 1 RTX 3090 ausgeführt wird. Andererseits funktioniert die Parallelisierung zwischen vier RTX 3070 sehr schnell, wenn Sie Ihr Modell darauf stopfen. Ein weiterer Grund, warum Sie es möglicherweise benötigen, ist die Verwendung alter GPUs. Es wird funktionieren, aber die Parallelisierung wird unwirksam sein, da die schnellsten GPUs an Synchronisationspunkten auf die langsamsten GPUs warten (normalerweise bei einem Gradienten-Update).
Was ist NVLink und brauche ich es?
Normalerweise benötigen Sie NVLink nicht. Es ist eine Hochgeschwindigkeitskommunikation zwischen mehreren GPUs. Dies ist erforderlich, wenn Sie einen Cluster mit 128 oder mehr GPUs haben. In anderen Fällen hat es fast keine Vorteile gegenüber der Standard-PCIe-Datenübertragung.
Ich habe nicht einmal das Geld für Ihre billigsten Empfehlungen. Was zu tun ist?
Auf jeden Fall eine gebrauchte GPU kaufen. Verwendete RTX 2070 (400 US-Dollar) und RTX 2060 (300 US-Dollar) reichen völlig aus. Wenn Sie sie sich nicht leisten können, ist die nächstbeste Option eine gebrauchte GTX 1070 (220 USD) oder GTX 1070 Ti (230 USD). Wenn das zu teuer ist, finden Sie eine gebrauchte GTX 980 Ti (6 GB $ 150) oder GTX 1650 Super ($ 190). Wenn das auch teuer ist, ist es besser, Cloud-Dienste zu nutzen. Sie bieten GPUs normalerweise ein Zeit- oder Leistungslimit, nach dem Sie bezahlen müssen. Tauschen Sie die Dienste aus, bis Sie sich Ihre eigene GPU leisten können.
Was braucht es, um ein Projekt zwischen zwei Maschinen zu parallelisieren?
Um die Arbeit durch Parallelisierung zwischen zwei Computern zu beschleunigen, benötigen Sie Netzwerkkarten mit 50 Gbit / s oder mehr. Ich empfehle, mindestens EDR Infiniband zu installieren, dh eine Netzwerkkarte mit einer Geschwindigkeit von mindestens 50 Gbit / s. Mit zwei EDR-Karten mit Kabel bei eBay erhalten Sie 500 US-Dollar zurück.
In einigen Fällen können Sie mit 10-Gbit / s-Ethernet auskommen, dies funktioniert jedoch normalerweise nur für bestimmte Arten von neuronalen Netzen (bestimmte Faltungsnetzwerke) oder für bestimmte Algorithmen (Microsoft DeepSpeed).
Sind Multiplikationsalgorithmen für die Sparse-Matrix für eine Sparse-Matrix geeignet?
Scheinbar nicht. Da eine Matrix 2 Nullen pro 4 Elemente haben muss, müssen dünn besetzte Matrizen gut strukturiert sein. Es ist wahrscheinlich möglich, den Algorithmus leicht zu optimieren, indem 4 Werte als komprimierte Darstellung von zwei Werten verarbeitet werden. Dies bedeutet jedoch, dass die genaue Multiplikation von Matrizen mit geringer Dichte mit Ampere nicht verfügbar ist.
Benötige ich einen Intel-Prozessor, um mehrere GPUs auszuführen?
Ich empfehle nicht, einen Intel-Prozessor zu verwenden, es sei denn, Sie belasten den Prozessor in Kaggle-Wettbewerben (bei denen der Prozessor mit linearen Algebra-Berechnungen geladen ist) stark. Und selbst für solche Wettbewerbe sind AMD-Prozessoren großartig. AMD-Prozessoren sind im Durchschnitt billiger und besser für GO. Für einen 4-GPU-Build ist Threadripper meine endgültige Wahl. An unserer Universität haben wir Dutzende von Systemen gesammelt, die auf solchen Prozessoren basieren, und alle funktionieren perfekt, ohne Beschwerden. Für Systeme mit 8 GPUs würde ich den Prozessor verwenden, mit dem Ihr Hersteller Erfahrung hat. Die Zuverlässigkeit von Prozessoren und PCIe in 8-Karten-Systemen ist wichtiger als Geschwindigkeit oder Kosteneffizienz.
Ist die Form des Gehäuses für die Kühlung von Bedeutung?
Nein. Normalerweise kühlen GPUs perfekt ab, wenn zwischen den GPUs sogar kleine Lücken bestehen. Unterschiedliche Gehäuse können einen Unterschied von 1-3 ° C ergeben, und unterschiedliche Kartenabstände können einen Unterschied von 10-30 ° C ergeben. Wenn zwischen Ihren Karten Lücken bestehen, gibt es im Allgemeinen kein Problem mit der Kühlung. Wenn keine Lücken vorhanden sind, benötigen Sie die richtigen Lüfter (Gebläse) oder eine andere Lösung (Wasserkühlung, PCIe-Expander). In jedem Fall spielen die Art des Gehäuses und seine Lüfter keine Rolle.
Wird AMD GPU + ROCm jemals NVIDIA GPU + CUDA fangen?
Nicht in den nächsten paar Jahren. Es gibt drei Probleme: Tensorkerne, Software und die Community.
Die GPU-Kristalle selbst von AMD sind gut: hervorragende Leistung auf FP16, hervorragende Speicherbandbreite. Das Fehlen von Tensorkernen oder deren Äquivalenten führt jedoch dazu, dass ihre Leistung im Vergleich zur GPU von NVIDIA leidet. Und ohne die Implementierung von Tensorkernen in Hardware werden AMD-GPUs niemals wettbewerbsfähig sein. Gerüchten zufolge ist für 2020 eine Art Karte für Rechenzentren mit einem Analogon von Tensorkernen geplant, aber es liegen noch keine genauen Daten vor. Wenn sie nur eine Tensor Core-Karte für Server haben, können sich nur wenige AMD-GPUs leisten, was NVIDIA einen Wettbewerbsvorteil verschafft.
Angenommen, AMD wird in Zukunft Hardware mit Tensorkernen einführen. Dann werden viele sagen: „Aber es gibt keine Programme, die mit AMD-GPUs arbeiten! Wie kann ich sie verwenden? " Dies ist meist ein Missverständnis. Die AMD-Software, auf der ROCm ausgeführt wird, ist bereits gut entwickelt, und die Unterstützung in PyTorch ist gut organisiert. Und obwohl ich nicht viele Berichte über die Arbeit von AMD GPU + PyTorch gesehen habe, sind dort alle Softwarefunktionen integriert. Anscheinend können Sie jedes Netzwerk auswählen und auf einer AMD-GPU ausführen. Daher ist AMD in diesem Bereich bereits gut entwickelt, und dieses Problem wurde praktisch gelöst.
Nachdem AMD jedoch die Probleme mit der Software und das Fehlen von Tensorkernen gelöst hat, steht AMD vor einem weiteren Problem: dem Mangel an Community. Wenn Sie auf ein Problem mit NVIDIA-GPUs stoßen, können Sie Google nach einer Lösung durchsuchen und diese finden. Dies schafft Vertrauen in NVIDIA-GPUs. Es entsteht eine Infrastruktur, die die Verwendung von NVIDIA-GPUs erleichtert (jede Plattform für GO funktioniert, jede wissenschaftliche Aufgabe wird unterstützt). Es gibt eine Reihe von Hacks und Tricks, die die Verwendung von NVIDIA-GPUs (z. B. Apex) erheblich vereinfachen. NVIDIA GPU-Experten und Programmierer sind unter jedem Busch zu finden, aber ich kenne viel weniger AMD GPU-Experten.
In Bezug auf die Community ähnelt die AMD-Situation der von Julia gegen Python. Julia hat viel Potenzial und viele werden zu Recht darauf hinweisen, dass diese Programmiersprache besser für wissenschaftliche Arbeiten geeignet ist. Julia wird jedoch im Vergleich zu Python selten verwendet. Es ist nur so, dass die Python-Community sehr groß ist. Es gibt Unmengen von Menschen, die sich um leistungsstarke Pakete wie Numpy, SciPy und Pandas versammeln. Diese Situation ähnelt der von NVIDIA gegenüber AMD.
Daher ist es sehr wahrscheinlich, dass AMD NVIDIA erst einholt, wenn es das Äquivalent von Tensorkernen und einer soliden Community einführt, die auf ROCm aufgebaut ist. AMD wird immer seinen Marktanteil in bestimmten Untergruppen (Cryptocurrency Mining, Rechenzentren) haben. Aber NVIDIA wird höchstwahrscheinlich das Monopol für weitere zwei Jahre halten.
Wann ist es besser, Cloud-Dienste zu nutzen, und wann ist ein dedizierter GPU-Computer?
Eine einfache Faustregel: Wenn Sie länger als ein Jahr mit GO rechnen, ist es billiger, einen Computer mit einer GPU zu kaufen. Andernfalls ist es besser, Cloud-Dienste zu verwenden - es sei denn, Sie verfügen über umfangreiche Erfahrung in der Cloud-Programmierung und möchten die Anzahl der GPUs nach Belieben skalieren.
Der genaue Wendepunkt, an dem Cloud-GPUs teurer werden als der Besitz eines Computers, hängt stark von den verwendeten Diensten ab. Es ist besser, es selbst zu berechnen. Im Folgenden finden Sie eine Beispielberechnung für einen AWS V100-Server mit einem V100 und einen Vergleich mit den Kosten eines Desktop-Computers mit einem RTX 3090, der eine hohe Leistung aufweist. Ein RTX 3090-PC kostet 2200 US-Dollar (2-GPU-Barebone + RTX 3090). Wenn Sie in den USA sind, fügen Sie 0,12 USD pro kWh für Strom hinzu. Vergleichen Sie dies mit 2,14 USD pro Stunde und Server in AWS.
Bei einem Recycling von 15% pro Jahr verbraucht der Computer
(350 W (GPU) + 100 W (CPU)) * 0,15 (Recycling) * 24 Stunden * 365 Tage = 591 kWh pro Jahr.
591 kWh pro Jahr ergeben zusätzliche 71 USD.
Der Wendepunkt, wenn der Preis von Computer und Cloud bei 15% Auslastung verglichen wird, liegt um den 300. Tag (2.311 USD gegenüber 2.270 USD):
2,14 USD / h * 0,15 USD (Recycling) * 24 Stunden * 300 Tage = 2.311 USD
Wenn Sie rechnen, Da Ihre GO-Modelle eine Lebensdauer von mehr als 300 Tagen haben, ist es besser, einen Computer zu kaufen, als AWS zu verwenden.
Ähnliche Berechnungen können für jeden Cloud-Dienst durchgeführt werden, um zu entscheiden, ob Sie Ihren Computer oder die Cloud verwenden.
Übliche Zahlen für die Nutzung der Rechenleistung lauten wie folgt:
- PhD-Computer: <15%;
- GPU-Cluster auf PhD Slurm:> 35%
- Unternehmensforschungscluster zu Slurm:> 60%.
Im Allgemeinen sind die Recyclingquoten in Bereichen niedriger, in denen das Nachdenken über innovative Ideen wichtiger ist als die Entwicklung praktischer Lösungen. In einigen Bereichen ist die Nutzungsrate niedriger (Interpretierbarkeitsstudien), in anderen viel höher (maschinelle Übersetzung, Sprachmodellierung). Im Allgemeinen wird das Recycling von Personenkraftwagen immer überschätzt. In der Regel werden die meisten persönlichen Systeme zu 5-10% recycelt. Daher empfehle ich Forschungsteams und Unternehmen dringend, GPU-Cluster auf Slurm anstelle separater Desktops zu organisieren.
Tipps für diejenigen, die zu faul zum Lesen sind
Beste GPUs insgesamt : RTX 3080 und RTX 3090.
Zu vermeidende GPUs (als Forscher) : Tesla-Karten, Quadro, Founders Edition, Titan RTX, Titan V, Titan XP.
Gutes Leistungs- / Preisverhältnis, aber teuer : RTX 3080.
Gutes Leistungs- / Preisverhältnis, billiger : RTX 3070, RTX 2060 Super.
Ich habe wenig Geld : Kaufen Sie gebrauchte Karten. Hierarchie: RTX 2070 (400 USD), RTX 2060 (300 USD), GTX 1070 (220 USD), GTX 1070 Ti (230 USD), GTX 1650 Super (190 USD), GTX 980 Ti (6 GB 150 USD).
Ich habe fast kein Geld : Viele Startups bewerben ihre Cloud-Dienste. Verwenden Sie kostenlose Credits in den Clouds und ändern Sie diese im Kreis, bis Sie eine GPU kaufen können.
Ich nehme an Kaggle-Wettbewerben teil: RTX 3070.
Ich versuche, den Wettbewerb in den Bereichen Computer Vision, Pre-Training oder maschinelle Übersetzung zu gewinnen : 4 Teile RTX 3090. Warten Sie jedoch, bis Experten bestätigen, dass es Baugruppen mit guter Kühlung und ausreichender Leistung gibt.
Ich lerne die Verarbeitung natürlicher Sprache : Wenn Sie sich nicht für maschinelle Übersetzung, Sprachmodellierung oder Vorlernen interessieren, reicht der RTX 3080 aus.
Ich habe angefangen, GO zu machen und habe mich wirklich darauf eingelassen: Beginnen Sie mit RTX 3070. Wenn Sie sich in 6-9 Monaten nicht langweilen, verkaufen und kaufen Sie vier RTX 3080. Je nachdem, was Sie als nächstes wählen (Startup, Kaggle, Forschung, angewandtes GO), Jahre In drei Fällen verkaufen Sie Ihre GPUs und kaufen Sie etwas Besseres (RTX-GPUs der nächsten Generation).
Ich möchte GO ausprobieren, habe aber keine ernsthaften Absichten : RTX 2060 Super ist eine ausgezeichnete Wahl, erfordert jedoch möglicherweise den Austausch des Netzteils. Wenn Sie einen PCIe x16-Steckplatz auf Ihrem Motherboard haben und das Netzteil etwa 300 Watt leistet, ist die GTX 1050 Ti eine hervorragende Option, da keine weiteren Investitionen erforderlich sind.
GPU-Cluster für parallele Simulation mit weniger als 128 GPUs : Wenn Sie RTX für den Cluster kaufen dürfen: 66% 8x RTX 3080 und 33% 8x RTX 3090 (nur wenn Sie die Baugruppe gut kühlen können). Wenn die Kühlung nicht ausreicht, kaufen Sie eine 33% RTX 6000 GPU oder 8x Tesla A100. Wenn Sie keine RTX-GPU kaufen können, würde ich 8 Supermicro A100-Knoten oder 8 RTX 6000-Knoten wählen.
GPU-Cluster für parallele Simulation mit mehr als 128 GPUs: Denken Sie an Autos mit 8 Tesla A100. Wenn Sie mehr als 512 GPUs benötigen, ziehen Sie das DGX A100 SuperPOD-System in Betracht.