
Lassen Sie uns über ein neuronales Netzwerk sprechen, das Deep Learning und Enforcement Learning verwendet, um Snake zu spielen. Sie finden den Code auf Github, die Analyse von Fehlern, Demonstrationen von KI und Experimente dazu unter dem Schnitt.
Seit ich die Netflix-Dokumentation über AlphaGo gesehen habe, war ich fasziniert vom verstärkten Lernen. Solches Lernen ist vergleichbar mit menschlichem Lernen: Sie sehen etwas, Sie tun etwas und Ihre Handlungen haben Konsequenzen. Gut oder schlecht. Sie lernen aus den Konsequenzen und den richtigen Handlungen. Reinforcement Learning hat viele Anwendungen: autonomes Fahren, Robotik, Handel, Spiele. Wenn Sie mit dem Lernen der Verstärkung vertraut sind, überspringen Sie die nächsten beiden Abschnitte.
Verstärkungslernen
Das Prinzip ist einfach. Der Agent lernt durch Interaktion mit der Umgebung. Er wählt eine Aktion aus und erhält eine Antwort von der Umgebung in Form von Zuständen (oder Beobachtungen) und Belohnungen. Dieser Zyklus wird kontinuierlich fortgesetzt oder bis er unterbrochen wird. Dann beginnt eine neue Episode. Schematisch sieht es so aus:

Das Ziel des Agenten ist es, die maximalen Belohnungen pro Episode zu erhalten. Zu Beginn des Trainings untersucht der Agent die Umgebung: Er versucht verschiedene Aktionen im selben Zustand. Während das Lernen fortschreitet, recherchiert der Agent weniger. Stattdessen wählt er die lohnendste Aktion basierend auf seiner eigenen Erfahrung.
Deep Reinforcement Learning
Deep Learning verwendet neuronale Netze, um Ausgaben aus Eingaben zu generieren. Mit nur einer verborgenen Ebene kann Deep Learning jede Funktion vergrößern. Wie es funktioniert? Ein neuronales Netzwerk besteht aus Schichten mit Knoten. Die erste Schicht ist die Eingangsdatenschicht. Die versteckte zweite Schicht transformiert die Daten mithilfe von Gewichten und einer Aktivierungsfunktion. Die letzte Ebene ist die Prognoseschicht.

Wie der Name schon sagt, ist Deep Reinforcement Learning eine Kombination aus Deep Learning und Reinforcement Learning. Der Agent lernt, die beste Aktion für einen bestimmten Zustand vorherzusagen, indem er Zustände als Eingaben, Werte für Aktionen als Ausgaben und Belohnungen verwendet, um die Gewichte in die richtige Richtung anzupassen. Schreiben wir eine Schlange mit tiefem Verstärkungslernen.

Aktionen, Belohnungen und Bedingungen definieren
Um das Spiel für den Agenten vorzubereiten, formalisieren wir das Problem. Aktionen zu definieren ist einfach. Der Agent kann die Richtung wählen: nach oben, rechts, unten oder links. Die Belohnungen und der Zustand des Raumes sind etwas komplexer. Es gibt viele Lösungen und eine funktioniert besser und die andere schlechter. Ich werde einen von ihnen unten beschreiben und es versuchen.
Wenn Snake einen Apfel aufnimmt, beträgt ihre Belohnung 10 Punkte. Wenn die Schlange stirbt, ziehen Sie 100 Punkte von der Auszeichnung ab. Um dem Agenten zu helfen, addieren Sie 1 Punkt, wenn sich die Schlange dem Apfel nähert, und subtrahieren Sie einen Punkt, wenn sich die Schlange vom Apfel entfernt.
Der Staat hat viele Möglichkeiten. Sie können die Koordinaten der Schlange und des Apfels oder die Richtung zum Apfel nehmen. Es ist wichtig, die Position der Hindernisse, dh der Wände und des Körpers der Schlange, hinzuzufügen, damit der Agent das Überleben lernt. Unten finden Sie eine Zusammenfassung der Aktionen, Bedingungen und Belohnungen. Wir werden später sehen, wie sich Statusanpassungen auf die Leistung auswirken.

Erstellen Sie eine Umgebung und einen Agenten
Durch Hinzufügen von Methoden zum Snake-Programm schaffen wir eine Lernumgebung zur Verstärkung. Die Verfahren sind wie folgt:
reset(self), step(self, action)und get_state(self). Zusätzlich ist es notwendig, die Belohnung bei jedem Schritt des Agenten zu berechnen. Schau es dir an run_game(self).
Der Agent arbeitet mit dem Deep Q-Netzwerk zusammen, um die beste Aktion zu finden. Modellparameter unten:
# epsilon sets the level of exploration and decreases over time
params['epsilon'] = 1
params['gamma'] = .95
params['batch_size'] = 500
params['epsilon_min'] = .01
params['epsilon_decay'] = .995
params['learning_rate'] = 0.00025
params['layer_sizes'] = [128, 128, 128]
Wenn Sie sich den Code ansehen möchten, finden Sie ihn auf GitHub .
Agent spielt Snake
Und jetzt - die Schlüsselfrage! Wird der Agent das Spielen lernen? Mal sehen, wie es mit der Umgebung interagiert. Unten sind die ersten Spiele. Der Agent versteht nichts:

Der erste Apfel! Aber es sieht immer noch so aus, als ob das neuronale Netzwerk nicht weiß, was es tut.

Findet den ersten Apfel ... und trifft später die Wand. Der Beginn des vierzehnten Spiels:

Der Agent lernt: Sein Weg zum Apfel ist nicht der kürzeste, aber er findet den Apfel. Unten ist das dreißigste Spiel:

Nach nur 30 Spielen vermeidet Snake Kollisionen mit sich selbst und findet einen schnellen Weg zum Apfel.
Lass uns mit dem Weltraum spielen
Es kann möglich sein, den Zustandsraum zu ändern und eine ähnliche oder bessere Leistung zu erzielen. Nachfolgend sind die möglichen Optionen aufgeführt.
- Keine Anweisungen: Teilen Sie dem Agenten nicht die Richtungen mit, in die sich die Schlange bewegt.
- Zustand mit Koordinaten: Ersetzen Sie die Position des Apfels (oben, rechts, unten und / oder links) durch die Koordinaten des Apfels (x, y) und der Schlange (x, y). Koordinatenwerte liegen auf einer Skala von 0 bis 1.
- Richtung Richtung 0 oder 1 Zustand.
- Nur Wandstatus: Meldet nur, wenn eine Wand vorhanden ist. Aber nicht darüber, wo sich der Körper befindet: unten, oben, rechts oder links.

Nachfolgend finden Sie Leistungsdiagramme für verschiedene Zustände:
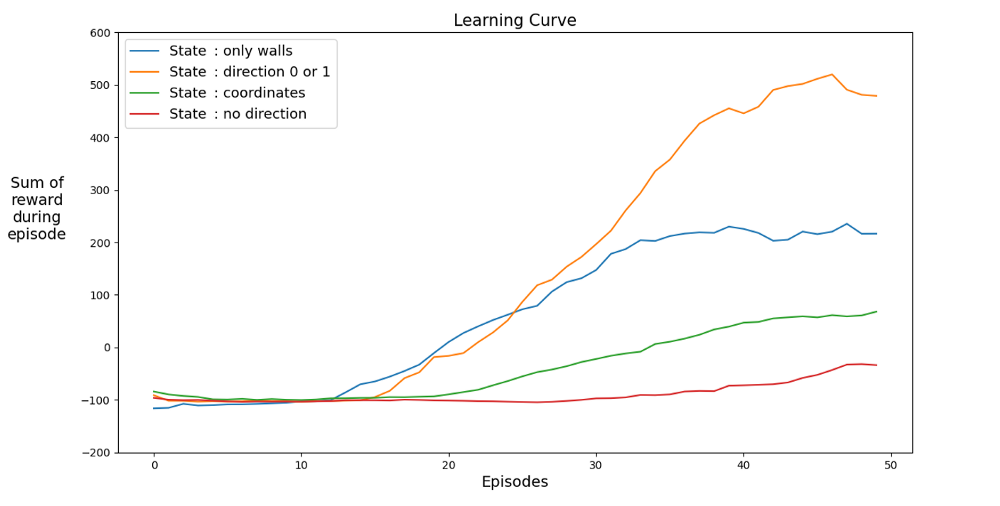
Lassen Sie uns einen Raum finden, der das Lernen beschleunigt. Die Grafik zeigt die durchschnittlichen Erfolge der letzten 12 Spiele mit unterschiedlichen Status.
Es ist klar, dass der Agent schnell lernt, wenn der Zustandsraum Anweisungen hat, und die besten Ergebnisse erzielt. Aber Raum mit Koordinaten ist besser. Vielleicht können Sie bessere Ergebnisse erzielen, indem Sie das Netzwerk länger trainieren. Der Grund für das langsame Lernen kann die Anzahl der möglichen Zustände sein: 20⁴ * 2⁴ * 4 = 1.024.000. Ein 20 x 20 Kurs, 64 Hindernisoptionen und 4 aktuelle Kursoptionen. Für den ursprünglichen Variantenraum ist 3² * 2⁴ * 4 = 576. Dies ist mehr als 1700-mal weniger als 1.024.000 und wirkt sich natürlich auf das Lernen aus.
Lass uns mit Auszeichnungen spielen
Gibt es eine bessere interne Belohnungslogik? Ich möchte Sie daran erinnern, dass die Schlange wie folgt vergeben wird:

Erster Fehler. Gehen im Kreis
Was ist, wenn Sie -1 in +1 geändert haben? Dies kann die Lernkurve verlangsamen, aber am Ende stirbt die Schlange nicht. Und das ist sehr wichtig für das Spiel. Der Agent lernt schnell, den Tod zu vermeiden.

Zu einem bestimmten Zeitpunkt erhält der Agent einen Überlebenspunkt.
Zweiter Fehler. Auf die Wand schlagen
Lassen Sie uns die Anzahl der Punkte für das Umgehen des Apfels auf -1 ändern. Setzen wir die Belohnung für den Apfel selbst auf 100 Punkte. Was wird passieren? Der Agent erhält für jede Bewegung eine Strafe, damit er so schnell wie möglich zum Apfel geht. Es kann passieren, aber es gibt noch eine andere Option.

KI geht entlang der nächsten Wand, um Verluste zu minimieren.
Erfahrung
Sie brauchen nur 30 Spiele. Das Geheimnis der künstlichen Intelligenz ist die Erfahrung früherer Spiele, die berücksichtigt wird, damit das neuronale Netzwerk schneller lernt. Bei jedem regulären Schritt wird eine Reihe von Wiedergabeschritten ausgeführt (Parameter
batch_size). Dies funktioniert so gut, weil es für ein bestimmtes Paar von Aktionen und Zuständen kaum Unterschiede zwischen Belohnung und nächstem Zustand gibt.
Fehler Nummer 3. Keine Erfahrung Ist Erfahrung
wirklich so wichtig? Lass es uns rausnehmen. Und nimm die 100 Punkte Belohnung für den Apfel. Unten ist ein Agent ohne Erfahrung, der 2500 Spiele gespielt hat.

Obwohl der Agent 2500 (!) Spiele gespielt hat, spielt er die Schlange nicht. Das Spiel endet schnell. Andernfalls hätten 10.000 Spiele Tage gedauert. Nach 3000 Spielen haben wir nur noch 3 Äpfel. Nach 10.000 Spielen sind die Äpfel immer noch 3. Ist es Glück oder ein Lernergebnis?
Erfahrung hilft in der Tat sehr. Zumindest eine Erfahrung, die Belohnungen und Art des Raums berücksichtigt. Wie viele Wiederholungen benötigen Sie pro Schritt? Die Antwort kann überraschen. Um diese Frage zu beantworten, spielen wir mit dem Parameter batch_size. Im ursprünglichen Experiment wurde es auf 500 eingestellt. Übersicht der Ergebnisse mit unterschiedlichen Erfahrungen:

200 Spiele mit unterschiedlicher Erfahrung: 1 Spiel (keine Erfahrung), 2 und 4. Durchschnitt für 20 Spiele.
Selbst mit Erfahrung in 2 Spielen lernt der Agent bereits zu spielen. In der Grafik sehen Sie die Auswirkungen.
batch_sizeBei 100 Spielen wird die gleiche Leistung erzielt, wenn 4 anstelle von 2 verwendet wird. Die Lösung im Artikel gibt das Ergebnis an. Der Agent lernt Snake zu spielen und erzielt gute Ergebnisse, indem er in 50 Spielen 40 bis 60 Äpfel sammelt.
Ein aufmerksamer Leser kann sagen: Die maximale Anzahl von Äpfeln in einer Schlange beträgt 399. Warum gewinnt AI nicht? Der Unterschied zwischen 60 und 399 ist in der Tat gering. Und das ist wahr. Und hier gibt es ein Problem: Die Schlange vermeidet Kollisionen beim Zurückschleifen nicht.
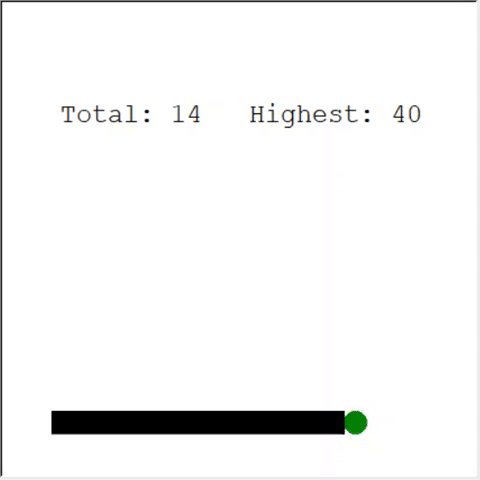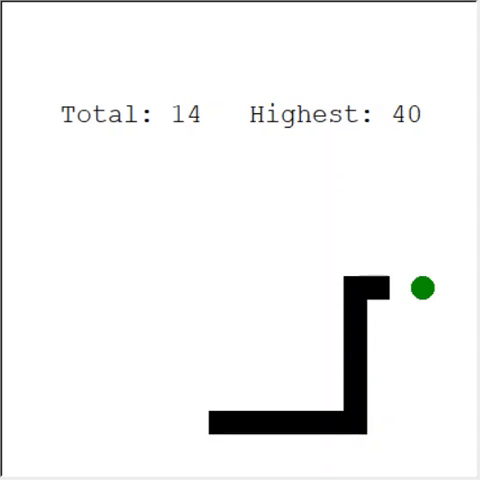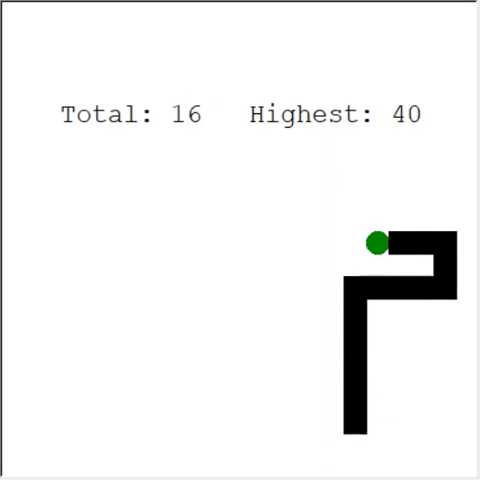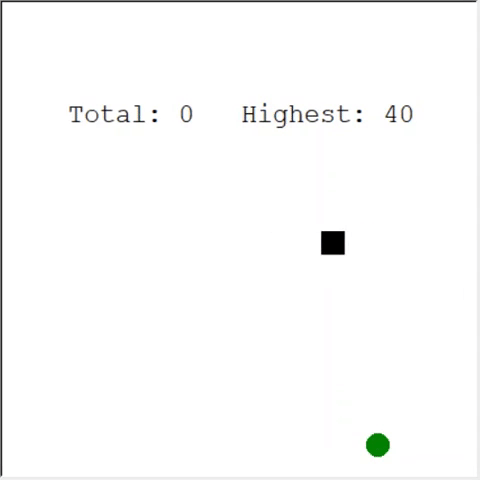
Ein interessanter Weg, um das Problem zu lösen, ist die Verwendung von CNN für das Spielfeld. Auf diese Weise kann die KI das gesamte Spiel sehen, nicht nur die Hindernisse in der Nähe. Er wird in der Lage sein, die Orte zu erkennen, die umrunden werden müssen, um zu gewinnen.
Literaturverzeichnis
[1] K. Hornik, M. Stinchcombe, H. White, Multilayer feedforward networks are universal approximators (1989), Neural networks 2.5: 359–366
[2] Mnih et al, Playing Atari with Deep Reinforcement Learning (2013)
[2] Mnih et al, Playing Atari with Deep Reinforcement Learning (2013)
, Level Up , - SkillFactory:
- Machine Learning (12 )
- « Machine Learning Data Science» (20 )
- «Machine Learning Pro + Deep Learning» (20 )
- Data Science (12 )
E
- - (8 )
- - Data Analytics (5 )
- (6 )
- (18 )
- «Python -» (9 )
- DevOps (12 )
- Java- (18 )
- JavaScript (12 )
- UX- (9 )
- Web- (7 )
