
Unternehmen können ihren Entwicklern auf verschiedene Weise helfen, ihre Produktivität zu maximieren, von der Änderung von Büroräumen über die Beschaffung besserer Tools bis hin zur Bereinigung des Quellcodes. Aber welche Entscheidungen werden den größten Einfluss haben? Ausgehend von der Literatur zur Softwareentwicklung und Arbeits- / Organisationspsychologie haben wir produktivitätsbezogene Faktoren identifiziert und 622 Entwickler aus drei Unternehmen befragt. Wir waren an den genannten Faktoren interessiert und daran, wie die Menschen selbst ihre eigene Produktivität bewerten. Unsere Ergebnisse legen nahe, dass das Selbstwertgefühl am stärksten von nichttechnischen Faktoren beeinflusst wird: Begeisterung bei der Arbeit, Unterstützung für neue Ideen durch Ihre Kollegen und nützliches Feedback zu Ihrer Produktivität. Im Vergleich zu anderen WissensarbeiternDie Beurteilung der Produktivität von Softwareentwicklern hängt mehr von der Vielfalt der Aufgaben und der Fähigkeit ab, remote zu arbeiten.
1. Einleitung
Die Verbesserung der Entwicklerproduktivität ist wichtig. Per Definition können sie nach Abschluss ihrer Aufgaben die Freizeit für andere nützliche Aufgaben verwenden: Einführung neuer Funktionen und neuer Überprüfungen. Aber was hilft Entwicklern, produktiver zu sein?
Unternehmen benötigen praktische Anleitungen zu den zu manipulierenden Faktoren, um die Produktivität zu maximieren. Sollte ein Entwickler beispielsweise Zeit damit verbringen, nach besseren Tools und Ansätzen zu suchen, oder sollte er Benachrichtigungen tagsüber deaktivieren? Sollte ein Marktführer in Refactoring investieren, um die Codekomplexität zu verringern, oder Entwicklern mehr Autonomie geben? Sollten Chefs in bessere Entwicklungstools oder ein komfortableres Büro investieren? In einer idealen Welt würden wir in verschiedene Faktoren investieren, um die Produktivität zu steigern, aber Zeit und Geld sind begrenzt, daher müssen wir uns entscheiden.
Dieser Artikel befasst sich mit der bislang umfassendsten Studie zur Produktivitätsprognose für Softwareentwickler. Wie in Abschnitt 3.1 beschrieben, kann die Produktivität objektiv (z. B. in Codezeilen pro Monat) oder subjektiv (wie vom Entwickler selbst geschätzt) gemessen werden. Obwohl keiner der beiden Ansätze bevorzugt wird, haben wir versucht, das Thema mit subjektivem Urteilsvermögen umfassend zu behandeln, um drei Fragen zu beantworten:
- Welche Faktoren sind die besten Prädiktoren dafür, wie ein Entwickler seine Produktivität bewertet?
- Wie verändern sich diese Faktoren von Unternehmen zu Unternehmen?
- Was sagt die Einschätzung eines Entwicklers hinsichtlich seiner Produktivität im Vergleich zu anderen Wissensarbeitern voraus?
Um die erste Frage zu beantworten, haben wir eine Studie bei einem großen Softwareunternehmen durchgeführt.
Um die zweite Frage zu beantworten, die hilft zu verstehen, inwieweit die erzielten Ergebnisse verallgemeinert werden können, haben wir eine Studie in zwei Unternehmen aus verschiedenen Branchen durchgeführt.
Um die dritte Frage zu beantworten, die hilft zu verstehen, wie sich Entwickler von anderen unterscheiden, haben wir eine Studie unter Vertretern anderer Berufe durchgeführt und diese mit den Ergebnissen der Entwicklerstudie verglichen.
Unsere Ergebnisse zeigen, dass in den von uns untersuchten Unternehmen das Selbstwertgefühl für ihre Produktivität stark von der Begeisterung bei der Arbeit, der Unterstützung durch Gleichaltrige für neue Ideen und nützlichen Rückmeldungen über ihre Produktivität beeinflusst wird. Im Vergleich zu anderen Wissensarbeitern hängt die Beurteilung der Produktivität von Softwareentwicklern stärker von der Vielfalt der Aufgaben und der Fähigkeit ab, remote zu arbeiten. Unternehmen können unsere Ergebnisse nutzen, um produktivitätsbezogene Initiativen zu priorisieren (Abschnitt 4.7).
Abschnitt 2 beschreibt die von uns untersuchten Unternehmen. Abschnitt 3 beschreibt die Forschungsmethodik. Abschnitt 4 beschreibt und analysiert die erzielten Ergebnisse. Abschnitt 5 beschreibt andere Arbeiten zu diesem Thema.

2. Unternehmen recherchiert
2.1. Google
Google hat weltweit rund 40 Entwicklungsbüros, in denen Zehntausende von Entwicklern beschäftigt sind. Das Unternehmen legt Wert auf eine enge Zusammenarbeit innerhalb der Teams, und die Büros sind in der Regel offen, um die Teammitglieder näher zusammenzubringen. Das Unternehmen ist relativ jung (Ende der 90er Jahre gegründet), seine Organisationsstruktur ist eher flach und die Entwickler haben viel Autonomie. Der Beförderungsprozess umfasst Feedback von Kollegen, und Entwickler müssen nicht in Führungspositionen wechseln, um voranzukommen. Entwickler planen ihre Zeit selbst, ihre Kalender werden im Unternehmensnetzwerk angezeigt. Google verwendet agile Entwicklungsprozesse (wie Agile), die normalerweise auf das gesamte Team angewendet werden.
Google schätzt Offenheit. Die meisten Entwickler arbeiten an einer gemeinsamen monolithischen Codebasis und werden aufgefordert, Änderungen am Code der Projekte anderer Personen vorzunehmen. Das Unternehmen hat eine starke Kultur des Testens und der Codeüberprüfung: Der an das Repository gesendete Code wird von einem anderen Entwickler überprüft, normalerweise unter Verwendung von Tests. Die meisten schreiben serverseitigen Code, der häufig veröffentlicht wird und die Einführung von Fixes relativ einfach macht. Das Entwicklungs-Toolkit ist weitgehend einheitlich (ohne Editoren) und wird intern erstellt, einschließlich Analyse- und kontinuierlicher Integrationstools sowie der Infrastruktur für die Veröffentlichung.
2.2. ABB
ABB beschäftigt weltweit weit über 100.000 Mitarbeiter. Als Ingenieurkonglomerat beschäftigt das Unternehmen eine Vielzahl von Berufen. Es gibt ungefähr 4.000 gängige Softwareentwickler und über 10.000 Anwendungsentwickler, die industrielle Systeme mit branchenspezifischen Bild- und Textsprachen erstellen. Für den Betrieb seiner großen IT-Infrastruktur verfügt das Unternehmen über eine beträchtliche Anzahl von Mitarbeitern, zu deren Aufgaben die Skripterstellung und die vereinfachte Programmierung gehören.
Obwohl ABB eine Reihe kleinerer Unternehmen übernommen hat, verfügt es über eine zentrale Organisation, die für die Vereinheitlichung der Softwareentwicklungsprozesse verantwortlich ist. Trotz der Unterschiede zwischen den Abteilungen sind die meisten Tools und Ansätze konsistent. Gleiches gilt für die meisten Karrierewege: für Technikfreaks vom Junior bis zum Senior Developer und für Führungskräfte vom Gruppenleiter zum Abteilungsleiter und zum zentralen Management.
2.3. Nationale Instrumente
National Instruments wurde in den 1970er Jahren gegründet. Die Softwareentwicklung konzentriert sich hauptsächlich auf vier internationale Forschungs- und Entwicklungszentren. Mitarbeiterkalender sind für das gesamte Unternehmen sichtbar, jeder kann einen Termin mit einem anderen Mitarbeiter vereinbaren.
Jobverantwortlichkeiten erleichtern Entwicklungsprozesse. Entwickler können ein Projekt nicht unabhängig auswählen, sondern bestimmte Aufgaben oder Funktionen übernehmen. Die meisten arbeiten mit einer gemeinsamen monolithischen Codebasis, deren verschiedene logische Teile bestimmte Eigentümer haben. Der eingegebene Code muss vom "Eigentümer" genehmigt werden. Es ist wünschenswert, dass der Code von technischen Leitern analysiert wird. Diese Richtlinie ist optional, wird jedoch von vielen befolgt.
Entwickler haben viel Freiheit bei der Auswahl der Tools. Es gibt keine generischen Tools, es sei denn, es gibt einen unmittelbaren Nutzen. Beispielsweise hängt die Wahl der IDE stark von der Aufgabe ab. Es stehen eine Reihe von benutzerdefinierten Build- und Testtools zur Verfügung. Verschiedene Teile des Unternehmens haben unterschiedliche Systeme für die Verwaltung und Analyse von Quellcode standardisiert. Software-Updates werden normalerweise vierteljährlich oder jährlich veröffentlicht, mit Ausnahme seltener kritischer Patches.
Tabelle 1. Profile der drei untersuchten Unternehmen:
| ABB | Nationale Instrumente | ||
| Die Größe | Groß. | Groß. | Zierlich. |
| Büros | Offene Büros. | Offene und geschlossene Büros. | Offene Büros. |
| Werkzeuge | Meist einheitliche Entwicklungstools. | Gleiche Werkzeuge. | Flexibilität bei der Auswahl der Werkzeuge |
| Entwicklungstyp | Meistens serverseitiger und mobiler Code. | Eine Kombination aus Webentwicklung, eingebetteter und Desktop-Software. | Meist eingebettete und Desktop-Software. |
| Repository | Monolithisches Repository. | Separate Repositorys. | Monolithisches Repository. |
| Vorspannen | Software-Entwicklung. | Engineering-Konglomerat. | Entwicklung von Software und Ausrüstung. |
3. Methodik
Unser Ziel: herauszufinden, welche Faktoren die Produktivität von Softwareentwicklern vorhersagen. Zu diesem Zweck haben wir eine Studie durchgeführt, die eine Reihe von Fragen, eine Reihe von Produktivitätsfaktoren und eine Reihe von demografischen Variablen enthält.
3.1 Beurteilung Ihrer Produktivität
Beschreiben wir zunächst, wie wir die Produktivität messen. Ramírez und Nembhard haben eine Klassifizierung der in der Literatur beschriebenen Leistungsmesstechniken vorgeschlagen, einschließlich Funktionspunktanalyse, Selbstbewertung, Beurteilung durch Fachkollegen, Verhältnismäßigkeit der Ergebnisse und Anstrengungen sowie professionelle Nutzung der Zeit [2]. Diese Techniken können in objektive (z. B. wie viele Codezeilen pro Woche geschrieben werden) und subjektive (z. B. Selbsteinschätzung oder Peer Review) unterteilt werden.
Keine der beiden Techniken wird bevorzugt, beide Kategorien haben Nachteile. Objektive Messungen sind nicht flexibel und verspielt. Nehmen wir die Anzahl der Codezeilen pro Woche. Ein produktiver Entwickler kann eine einzeilige Korrektur für einen schwer zu findenden Fehler schreiben. Und ein unproduktiver Entwickler kann die Anzahl der Zeilen leicht erhöhen. Andererseits können subjektive Messungen aufgrund kognitiver Verzerrungen ungenau sein. Nehmen Sie Peer-Bewertungen: Sie mögen einen produktiven Entwickler möglicherweise nicht und erhalten daher schlechtere Bewertungen, selbst wenn Peers nach Objektivität streben.
Wie das Forscherteam unter der Leitung von Meyer, das die Produktivität von Softwareentwicklern analysierte [3], verwendeten wir unsere Forschungsfragen als subjektives Maß für die Produktivität. Es gibt zwei Hauptgründe. Erstens ist Forschung, wie Ramirez und Nembhardt feststellten, "eine einfache und beliebte Methode, um die Produktivität [von Wissensarbeitern] zu messen". Zweitens liefert die Forschung Antworten von Entwicklern in unterschiedlichen Rollen und ermöglicht es den Befragten, ihren Leistungsbewertungen unterschiedliche Informationen hinzuzufügen.
Zahl: 1. Forschungsmethodik:

Wir haben die Befragten gefragt, inwieweit sie der Aussage zustimmen:
Ich erreiche regelmäßig eine hohe Produktivität.
Damit wollten wir die Produktivität so breit wie möglich messen. Wir haben zunächst acht Optionen für die Frage formuliert und sie dann auf das oben Gesagte reduziert, indem wir informell mit fünf Google-Entwicklern über ihre Interpretation des Ausdrucks gesprochen haben (Abbildung 1, unten links). Wir haben der Frage aus drei Gründen die Wörter „hoch“ und „regelmäßig“ hinzugefügt. Zunächst wollten wir einen Zustand erfassen, mit dem sich die Menschen vergleichen können. Zweitens wollten wir, dass dieser Zustand hoch ist, um zu vermeiden, dass die Antworten der Befragten die Obergrenze erreichen. Drittens wollten wir, dass sich die Befragten auf zwei spezifische Maßstäbe für die Produktivität konzentrieren - Intensität und Häufigkeit. In Zukunft können Forscher detailliertere Maßnahmen anwenden, indem sie Intensität und Häufigkeit auf zwei verschiedene Themen verteilen.
Wir haben es getestet, indem wir drei Führungskräfte bei Google gebeten haben, es an ihre Teams zu senden und zu fragen: "Was haben Sie bei der Beantwortung einer Produktivitätserklärung berücksichtigt?" Wir haben Antworten von 23 Entwicklern erhalten (Abbildung 1, unten in der Mitte). Die Option wurde für unsere Zwecke als akzeptabel angesehen, da die Überlegungen der Befragten unseren Erwartungen hinsichtlich des Werts der Produktivität entsprachen. Diese Überlegungen betrafen Workflow-Probleme, Arbeitsergebnisse, das Vorhandensein in der Zone oder im Flow, Zufriedenheit, erreichte Ziele, Programmiereffizienz, Fortschritt und die Minimierung von unnötigem Aufwand. Wir haben diese Antworten in diesem Artikel nicht analysiert, aber die Studie umfasste vier zusätzliche, verfeinerte Produktivitätsmaße aus früheren Arbeiten [2], [4], [5].
Wir haben zwei bequeme Produktivitätsmaße ausgewählt, um objektive Daten hinzuzufügen, um das Selbstwertgefühl zu kontextualisieren, und sie dann bei Google miteinander korreliert. Die erste objektive Maßnahme war die Anzahl der von einem Entwickler pro Woche geänderten Codezeilen - ein beliebtes, aber schwieriges Maß für die Produktivität [6] [7]. Die zweite Maßnahme war die Anzahl der Änderungen, die der Entwickler pro Zeiteinheit an der Haupt-Google-Codebasis vorgenommen hat. Dies entspricht fast der monatlichen Pull-Anfrage des von Vasilescu geleiteten Teams [8]. Um unsere Produktivität zu bewerten, haben wir Antworten auf eine ähnliche Umfrage bei Google verwendet (n = 3344 Antworten). Wir konnten keine Daten aus unserer Studie für diese Analyse verwenden, da die Antworten keine Teilnehmer-IDs enthielten.anhand derer objektive Produktivitätsmaße verglichen werden könnten. In dieser Studie stellten sie eine ähnliche Frage: "Wie oft fühlen Sie sich bei der Arbeit sehr produktiv?" Die Teilnehmer konnten mit "Selten oder nie", "Manchmal", "Etwa die Hälfte der Zeit", "Meistens" und "Immer oder fast immer" antworten. Wir haben dann eine lineare Regression mit selbstberichteter Produktivität als ordinale abhängige Variable erstellt (codiert 1, 2, 3, 4 bzw. 5). Die lineare Regression setzt einen gleichen Abstand zwischen den Produktivitätsbewertungen voraus. Angesichts der in der Frage verwendeten Wörter halten wir diese Annahme für gerechtfertigt. Für eine geordnete logistische Regression ist diese Annahme nicht erforderlich. Die Anwendung dieser Technik liefert hier zuverlässige Ergebnisse: Die gleichen Koeffizienten sind in einer linearen,und in einem bestellten Modell.
Wir verwenden logarithmische Zielmaße als unabhängige Variablen, da beide positiv verzerrt sind. Zur Kontrolle haben wir den Jobcode (z. B. Softwareentwickler, Forschungsingenieur usw.) als kategoriale Variable sowie den Rang (Junior, Middle, Senior usw.) als Zahl (z. B. 3 für Software) verwendet Einsteiger bei Google). Der Jobcode war für zwei Arbeiterrollen in jedem linearen Modell statistisch signifikant. Insgesamt gab es drei Modelle: zwei mit einer der objektiven Maßnahmen und eines mit beiden objektiven Maßnahmen.

Zahl: 2: Modelle zur Vorhersage subjektiver Leistungsschätzungen basierend auf zwei objektiven Maßnahmen. ns bedeutet einen statistisch nicht signifikanten Faktor mit p> 0,05, ** bedeutet p <0,01, *** bedeutet p <0,001. Eine vollständige Beschreibung der Modelle finden Sie in den ergänzenden Materialien.
Die Kontextualisierungsergebnisse sind in Abb. 2 dargestellt. 2. Jedes Modell weist ein statistisch signifikantes Niveau mit einer negativen Bewertung auf, die wir wie folgt interpretierten: Höherrangige Entwickler bewerten sich tendenziell als etwas weniger produktiv. Dies ist ein starkes Argument für die Rangkontrolle (Abschnitt 3.7.). Die ersten beiden Modelle zeigen eine wichtige positive Beziehung zwischen objektiven und subjektiven Produktivitätsmessungen. Das heißt, je mehr Codezeilen geschrieben oder Änderungen vorgenommen werden, desto produktiver betrachtet sich ein Entwickler. Das resultierende kombinierte Modell und die Schätzungen aus den ersten beiden Modellen legen nahe, dass die Anzahl der vorgenommenen Änderungen ein wichtigerer Indikator für die Produktivität ist als die Anzahl der geschriebenen Zeilen. Beachten Sie jedoch, dass in allen Modellen der Parameter R 2Der Anteil der erklärten Varianz ist eher gering - weniger als 3% für jedes Modell.
Im Allgemeinen zeigen die erhaltenen Ergebnisse, dass die Anzahl der Codezeilen und die vorgenommenen Änderungen die Bewertung der Produktivität durch die Entwickler beeinflussen, jedoch nicht wesentlich.
3.2. Produktivitätsfaktoren
Anschließend haben wir im Verlauf der Studie die Teilnehmer nach Faktoren befragt, die in anderen Studien als mit der Produktivität verbunden angesehen werden. Wir haben Fragen aus vier Quellen gesammelt (Abbildung 1, Mitte links). Diese Quellen werden verwendet, weil sie unseres Wissens die umfassendsten Übersichten über einzelne Produktivitätsfaktoren bei der Forschung von Programmierern und anderen Wissensarbeitern darstellen.
Erste QuelleIst ein Tool, das von einem von Palvalin geleiteten Team erstellt wurde, um Produktivitätsmaßnahmen für Wissensarbeiter zu überprüfen [4]. Das Tool namens SmartWoW wurde von vier Unternehmen verwendet und deckt Aspekte des physischen, virtuellen und sozialen Arbeitsbereichs, der persönlichen Arbeitspraktiken und des Wohlbefindens bei der Arbeit ab. Wir haben einige der Fragen geändert, um die aktuelle Entwicklerterminologie besser widerzuspiegeln und das amerikanische Englisch besser anzupassen. Zum Beispiel fragt SmartWoW:
Ich mache oft Telearbeit, um Aufgaben zu erledigen, die eine ununterbrochene Konzentration erfordern.
Wir haben umschrieben:
Ich arbeite oft remote, um Aufgaben auszuführen, die eine ununterbrochene Konzentration erfordern.
Aus SmartWoW haben wir zunächst 38 Fragen für unsere Studie ausgewählt.
Eine zweite Quelle ist eine Übersicht von Hernaus und Mikulić über die Auswirkungen von Arbeitsumgebungsmerkmalen auf die Produktivität von Wissensarbeitern [9]. Ihre nachgewiesene Arbeit spiegelt frühere Produktivitätsstudien wider: einen Fragebogen zur Gestaltung des Arbeitsumfelds [10], eine diagnostische Studie zum Arbeitsumfeld [11], eine Bewertung der Gruppenzusammenarbeit [12] und eine Bewertung der „Art der Aufgaben“ [13]. Wir haben die Fragen so geändert, dass sie kurz und konsistent sind. Aus dem gleichen Grund haben wir Fragen direkt aus der Arbeit [12] beantwortet, die sich Arbeitsgruppen widmet, die wenig über die persönliche Produktivität nachdenken.
Dritte Quelle- eine strukturierte Überprüfung von Wagner und Ruhe der Produktivitätsfaktoren in der Softwareentwicklung [14]. Im Gegensatz zu anderen Quellen wurde diese Arbeit von der wissenschaftlichen Gemeinschaft nicht gründlich überprüft und enthält keine originalen empirischen Untersuchungen. Nach unserem besten Wissen ist dies jedoch die umfassendste Übersicht über die Programmierproduktivitätsforschung. Die von Wagner und Rouet formulierten Faktoren werden in technische und nicht quantifizierbare Faktoren unterteilt. Anschließend werden die Faktoren Umwelt, Unternehmenskultur, Projekt-, Produkt- und Entwicklungsumgebung, Fähigkeiten und Erfahrung zusätzlich hervorgehoben.
Die vierte QuelleIst eine Microsoft-Entwicklerstudie, die von einem Team unter der Leitung von Meyer geleitet wird. Daraus ermittelten wir fünf Hauptgründe für produktive Arbeitstage, darunter Zielsetzung, Arbeitstreffen und Arbeitspausen [15].
Wir haben außerdem drei Faktoren hinzugefügt, die unserer Meinung nach in früheren Arbeiten nicht angemessen berücksichtigt wurden, sich jedoch im Kontext von Google als wichtig erwiesen haben. Eine davon ist die Produktivitätsbewertung von Wissensarbeitern [16], einem unveröffentlichten Vorläufer von SmartWoW. Wir haben es so angepasst:
Die mir zur Verfügung gestellten Informationen (Fehlerberichte, Benutzerskripte usw.) sind korrekt.
Der zweite Faktor wird aus dem Fragebogen zur Gestaltung der Arbeitsumgebung entnommen und wie folgt angepasst:
Ich bekomme nützliches Feedback zu meiner Arbeitsproduktivität.
Und wir haben einen dritten Faktor geschaffen, der im ABB-Umfeld wichtig war:
Ich benötige direkten Zugriff auf bestimmte Hardware, um meine Software zu testen.
Zuerst haben wir 127 Faktoren ausgewählt. Um sie auf eine solche Anzahl von Fragen zu reduzieren, die die Befragten ohne nennenswerte Ermüdung beantworten können [17], haben wir die in der Mitte von Abb. 1 dargestellten Kriterien verwendet. 1:
- Duplikate entfernt. Beispielsweise wird in SmartWoW [4] und Meyer et al. [15] die Zielsetzung als wichtiger Produktivitätsfaktor angesehen.
- Ähnliche Faktoren kombiniert. Zum Beispiel beschreiben Hernaus und Mikulich verschiedene Aspekte der Interaktion zwischen Arbeitsgruppen, die die Produktivität steigern, aber wir haben sie auf einen Faktor reduziert [9].
- Faktoren mit offensichtlichem Nutzen wurden bevorzugt. Zum Beispiel hat SmartWoW [4] einen solchen Faktor:
Die Mitarbeiter haben die Möglichkeit, sich gegenseitig ihre Kalender anzusehen.
Bei Google gilt dies überall und es ist unwahrscheinlich, dass sich dies ändert. Daher ist der Faktor von geringem Nutzen.
Wir haben diese Kriterien zusammen und iterativ angewendet. Zunächst wurde ein großes Poster mit allen Kandidatenfragen zur Verwendung in der Studie gedruckt. Dann haben wir ein Google-Poster neben unserem Büro angebracht. Dann analysierte jeder von uns unabhängig die Fragen anhand der oben genannten Kriterien. Das Plakat hing mehrere Wochen, wir ergänzten und überarbeiteten die Liste regelmäßig erneut. Am Ende wurde eine endgültige Liste von Fragen erstellt.
Unsere Studie umfasste 48 Faktoren in Form von Aussagen (Abb. 4, linke Spalte). Die Befragten gaben auf einer Fünf-Punkte-Skala an, inwieweit sie diesen Aussagen zustimmen, von „trifft überhaupt nicht zu“ bis „trifft voll zu“. Faktoren können in Blöcke gruppiert werden, die sich auf Methodik, Fokus, Erfahrung, Job, Gelegenheit, Personen, Projekt, Software und Kontext beziehen. Wir haben auch eine offene Frage zu Faktoren gestellt, die die Befragten möglicherweise übersehen haben. Der vollständige Fragebogen aus unserer Studie ist in den ergänzenden Materialien enthalten.

Zahl: 3: Beispielfrage aus der Forschung.
3.3. Demographie
Wir haben Fragen zu verschiedenen demografischen Faktoren gestellt, wie in Abbildung 1 dargestellt:
- Fußboden.
- Position.
- Rang.
Frühere Autoren haben vorgeschlagen, dass das Geschlecht mit den Produktivitätsfaktoren von Softwareentwicklern zusammenhängt, beispielsweise mit dem Erfolg beim Debuggen [18]. Daher hatte die Studie eine optionale Frage zum Geschlecht (männlich, weiblich, nicht zu beantworten, meine eigene). Die Befragten, die die Frage nicht beantworteten, wurden der Gruppe „Antwort verweigern“ zugeordnet (Google n = 26 [6%], ABB n = 4 [3%], National Instruments n = 5 [6%]). Wir haben diese Daten als kategorisch behandelt.
Für die Position haben wir unser Dienstalter bei Google von der Personalabteilung übernommen. Dies war mit ABB und National Instruments nicht möglich, daher haben wir der Studie eine optionale Frage hinzugefügt. Bei ABB haben wir mangels Antworten (n = 4 [3%]) 12 Jahre Erfahrung gesammelt, dies ist der Durchschnitt der gesammelten Daten. Bei National Instruments haben wir aus demselben Grund 9 Jahre gebraucht (n = 1 [1%]). Sie können es beispielsweise schwieriger machen [19], Substitutionen zu verwenden, um fehlende Werte basierend auf den verfügbaren Daten vorherzusagen. Angenommen, die fehlenden Ranginformationen können je nach Position und Geschlecht ziemlich genau ausgefüllt werden. Wir haben jedoch nur durchschnittliche statistische Werte ersetzt, da demografische Faktoren für uns nicht von vorrangiger Bedeutung waren, sondern nur Begleitinformationen zur Kontrolle waren. Wir haben diese Daten als Zahlen verarbeitet.
In Bezug auf den Rang haben wir die Teilnehmer bei Google gebeten, ihr Niveau als Zahl anzugeben. Die fehlenden Antworten (n = 26 [6%]) haben wir auf den häufigsten Wert bezogen.
Bei ABB könnten Mitwirkende optional "Junior- oder Senior-Softwareentwickler" angeben, obwohl viele "unterschiedliche" Titel angaben. Wenn die Antwort die Wörter enthielt:
- älter
- führen
- Manager
- Architekt
- Forscher
- Main
- Wissenschaftler
dann haben wir solche Antworten an "ältere" weitergeleitet. Der Rest wurde als "Junior" bezeichnet. Die fehlenden Antworten (n = 4 [3%]) haben wir der häufigsten Bedeutung zugeschrieben - „Senior“.
National Instruments hatte Optionen:
- Herausforderer
- Mitarbeiter
- älter
- Hauptarchitekt / Ingenieur
- Chefarchitekt / Ingenieur
- geehrter Ingenieur
- Teilnehmer
- andere
Es stellte sich heraus, dass der einzige „andere“ ein Praktikant war, den wir an die „Bewerber“ übertragen haben. Die fehlenden Antworten (n = 3 [4%]) haben wir der häufigsten Bedeutung zugeschrieben - „Senior“.
Wir haben die Ränge in allen Unternehmen nach Zahlen kodiert.
3.4. Vergleich mit Nichtentwicklern
Als nächstes waren wir daran interessiert, was genau es uns ermöglicht, vorherzusagen, wie Entwickler ihre Produktivität bewerten. Zum Beispiel gingen wir davon aus, dass die Produktivität durch Abwesenheit von der Arbeit beeinflusst wurde, aber das könnte für jeden Wissensarbeiter gesagt werden. Daher stellt sich natürlich die Frage: Beeinflusst dies die Entwicklerproduktivität in besonderer Weise?
Um diese Frage zu beantworten, haben wir Berufe ausgewählt, die mit Softwareentwicklern vergleichbar sind. Zuerst haben wir versucht, basierend auf Positionen in Google auszuwählen. Obwohl einige Positionen angaben, Wissensarbeiter zu sein, war das Vorhandensein des Wortes "Analyst" in der Position der häufigste und unserer Meinung nach zuverlässigste Indikator für einen geeigneten Nichtentwickler. Wir haben uns entschieden, Google-Analysten und -Entwickler zu vergleichen, anstatt Google-Analysten mit Entwicklern aller drei Unternehmen zu vergleichen. Wir haben beschlossen, dass wir so die Merkmale des Unternehmens kontrollieren können (zum Beispiel, wenn Google-Mitarbeiter plötzlich statistisch mehr oder weniger empfindlich auf Unterbrechungen reagieren als Mitarbeiter anderer Unternehmen).
Wir haben dann unsere Forschung für Analysten angepasst. Es wurden Fragen entfernt, die eindeutig mit der Softwareentwicklung zusammenhängen, z. B. "Meine Softwareanforderungen ändern sich häufig." Wir haben andere Fragen speziell für Analysten neu gestellt. Anstelle von "Ich verwende die besten Tools und Techniken zur Entwicklung von Software" haben wir beispielsweise geschrieben: "Ich verwende die besten Tools und Ansätze, um meine Arbeit zu erledigen."
Die Produktivitätswerte wurden auf die gleiche Weise wie bei Entwicklern gemessen. Gleiches gilt für die Beurteilung von Geschlecht, Position und Rang. Wir haben die „analytische“ Version der Studie an einer geeigneten Stichprobe von fünf Analysten getestet, die sagten, die Studie sei im Allgemeinen klar und nahmen einige geringfügige Änderungen vor. Wir haben sie akzeptiert und eine umfassende Studie mit Nicht-Entwicklern durchgeführt.

3.5. Kontrollfrage
Um Antworten auszuschließen, die gedankenlos gegeben wurden, haben wir nach etwa 70% des Beginns der Studie eine Frage zur Aufmerksamkeit eingefügt [20]: "Beantworten Sie diese Frage," ich bin eher anderer Meinung. " Wir haben die Formulare, die keine solche Antwort auf diese Frage enthielten, nicht berücksichtigt.
3.6. Anteil der Antworten
Bei Google haben wir 1.000 zufällige Vollzeitmitarbeiter aus der Personalabteilung ausgewählt, die Softwareentwicklungsrollen hatten. Wir haben 436 ausgefüllte Formulare von ihnen erhalten, dh die Rücklaufquote betrug 44%, was ein sehr hoher Indikator für die Forschung unter Entwicklern ist [21]. Nach dem Löschen der Formulare mit der falschen Antwort auf die Sicherheitsfrage (n = 29 [7%]) blieben 407 Antworten übrig.
Für eine Umfrage unter Wissensarbeitern haben wir 200 zufällige Vollzeit-Google-Mitarbeiter ausgewählt, deren Berufsbezeichnung das Wort "Analyst" enthält. Wir haben beschlossen, nicht zu viele Analysten zu recherchieren, da unser Ziel Softwareentwickler waren. 94 Personen, 47%, beantworteten unsere Fragen. Nach dem Löschen von Fragebögen mit einer fehlerhaften Antwort auf die Sicherheitsfrage (n = 6 [6%]) blieben 88 übrig.
Wir haben unsere Fragebögen an ungefähr 2.200 zufällig ausgewählte Softwareentwickler bei ABB gesendet und 176 Antworten erhalten. Dies sind 8% an der Untergrenze für solche Studien [21]. Nach dem Löschen der falschen Fragebögen (n = 39 [22%]) blieben 137 übrig.
Schließlich haben wir die Fragebögen an etwa 350 Softwareentwickler bei National Instruments gesendet und 91 Antworten erhalten (26%). Nach dem Löschen der falschen Fragebögen (n = 13 [14%]) blieben 78 übrig.
3.7. Analyse
Für jeden Faktor in jedem Unternehmen haben wir individuelle lineare Regressionsmodelle angewendet, wobei der Faktor als unabhängige Variable (z. B. "Mein Projektzeitplan ist eng") und die Schätzung unserer Produktivität als abhängige Variable verwendet wurden. Aus Datenschutzgründen haben wir für jedes Unternehmen separate Modelle ausgeführt, damit die Rohdaten verschiedener Unternehmen nicht gemischt wurden. Um den Effekt von Sicherheitenvariablen zu verringern, haben wir jedem Regressionsmodell vorhandene demografische Variablen hinzugefügt. Bei der Interpretation der Ergebnisse haben wir uns auf drei Aspekte des Produktivitätsfaktorverhältnisses konzentriert:
- Bewertung . Gibt den Grad des Einflusses jedes Faktors an, während eine demografische Konstante beibehalten wird. Je höher der Wert, desto höher die Auswirkung.
- . . , .
- . p < 0,05. 48 , p -, [22].
Bei der Interpretation der Ergebnisse haben wir uns mehr auf den Grad des Einflusses (Bewertung) und weniger auf die statistische Signifikanz konzentriert, da diese aus ausreichend großen Datensätzen extrahiert werden kann, auch wenn die praktische Signifikanz gering ist. Wie wir weiter unten sehen werden, wurden bei Google am häufigsten statistisch signifikante Ergebnisse mit der höchsten Rücklaufquote gefunden. am allerwenigsten - in National Instruments, wo die Rücklaufquote niedriger war. Wir waren der Meinung, dass dieser Unterschied zu einem großen Teil auf die statistische Aussagekraft zurückzuführen ist. Wir bitten Sie dringend, sich auf statistisch signifikante Ergebnisse zu verlassen.
Um den Kontext bereitzustellen, haben wir auch analysiert, wie demografische Faktoren mit Leistungsbewertungen korrelieren. Zu diesem Zweck haben wir für jedes Unternehmen mehrere lineare Regressionen mit demografischen Variablen als unabhängigen Variablen und einer Schätzung unserer Produktivität als abhängige Variable durchgeführt. Anschließend analysierten wir den prädiktiven Gesamtwert des resultierenden Modells sowie die Auswirkungen jeder erklärenden Variablen.
3.8. Über Kausalität
Unsere Methodik ermöglicht es uns, die Beziehung zwischen den Produktivitätsfaktoren und der Bewertung ihrer Produktivität zu bewerten, obwohl wir im Wesentlichen am Grad des Einflusses jedes Faktors auf die Änderung der Produktivität interessiert sind. Wie richtig ist es zu glauben, dass es einen kausalen Zusammenhang zwischen Faktoren und Produktivität gibt?
Die Richtigkeit hängt hauptsächlich von der Stärke der Beweise für die Verursachung in früheren Arbeiten ab. Und diese Kraft ist für verschiedene Faktoren unterschiedlich. Beispielsweise führte ein von Guzzo geführtes Team eine Metaanalyse von 26 Artikeln zu Bewertung und Feedback durch. Die Ergebnisse liefern hervorragende Beweise dafür, dass Feedback die Produktivität am Arbeitsplatz erhöht [23]. Die Ermittlung der Beweiskraft für jeden untersuchten Faktor erfordert jedoch viel Arbeit, die über den Rahmen dieses Artikels hinausgeht.
Zusammenfassend lässt sich sagen: Obwohl unsere Studie keinen Kausalzusammenhang zulässt, sondern auf früheren Arbeiten basiert, können wir zuversichtlich glauben, dass diese Faktoren die Produktivität beeinflussen, aber unsere Ergebnisse mit einiger Vorsicht interpretieren.

4. Ergebnisse
Zunächst beschreiben wir die Beziehung zwischen allen Produktivitätsfaktoren und die Bewertung ihrer Produktivität bei der Kontrolle der demografischen Merkmale. Diese Daten werden verwendet, um jede Umfrageantwort zu beantworten, gefolgt von einer Diskussion der Ergebnisse. Wir werden dann die Beziehung zwischen demografischen Merkmalen und Leistungsmessung diskutieren. Lassen Sie uns abschließend die Auswirkungen und Risiken diskutieren.
4.1. Produktivitätsfaktoren
In Abb. 4 zeigt die Ergebnisse unserer Analyse, die in Abschnitt 3.7 beschrieben sind. In der ersten Spalte sind die Faktoren aufgeführt, die den Teilnehmern in Form von Aussagen vorgeschlagen wurden. gefolgt von den Faktorbezeichnungen (F1, F2 usw.), die wir nach Abschluss der Analyse zugewiesen haben. Der Mangel an Daten bedeutet, dass diese Faktoren für Entwickler spezifisch sind und Analysten nicht vorgeschlagen wurden (z. B. F10).
Zahl: 4: Beziehungen zwischen 48 Faktoren und wie Entwickler und Analysten ihre eigene Produktivität in drei Unternehmen bewerten:
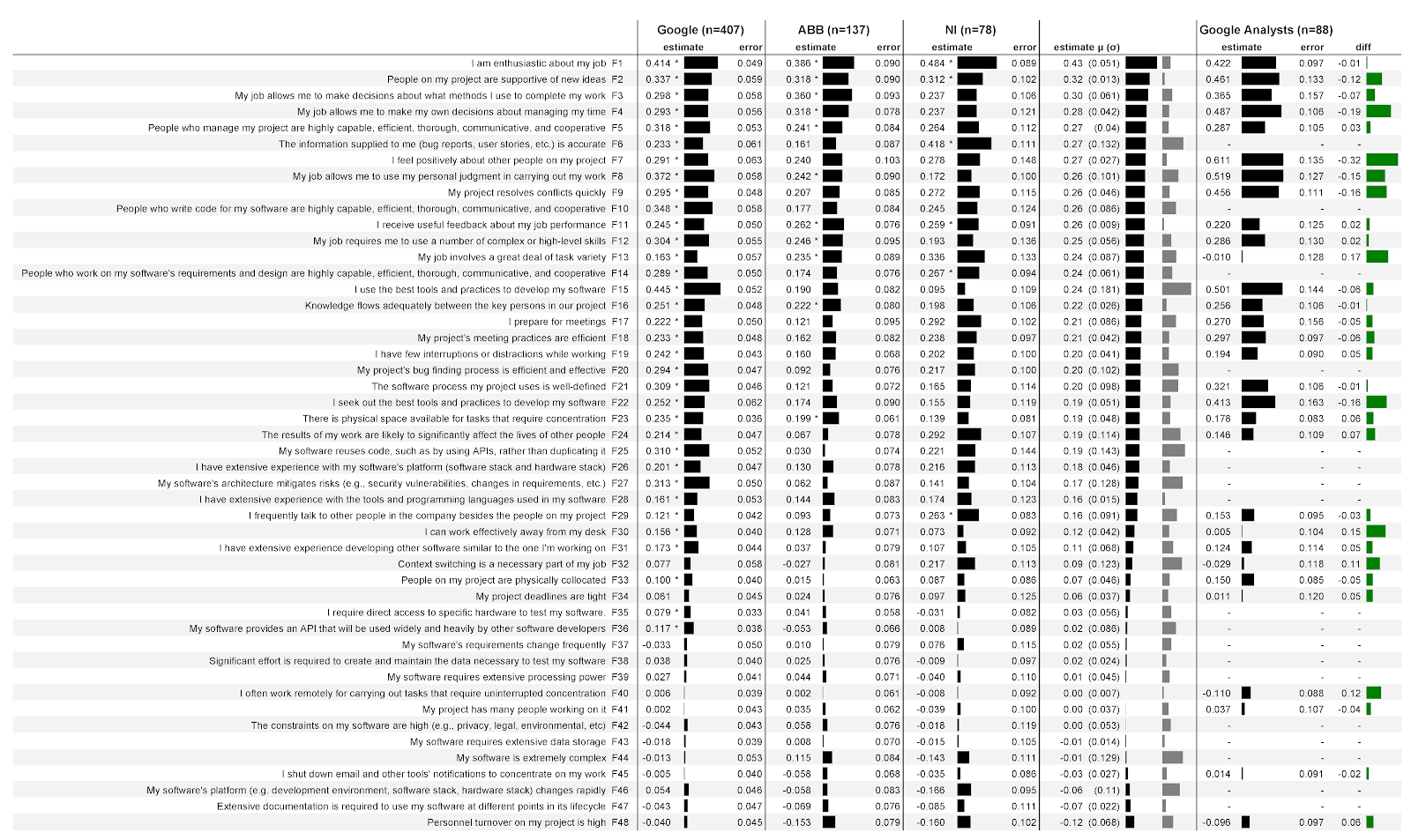
In den folgenden drei Spalten werden Daten von drei Unternehmen sowie Daten von Google-Analysten angezeigt. Jede dieser Spalten ist in zwei Unterspalten unterteilt.
Unterspalte Schätzung(Score) enthält Regressionskoeffizienten, die die Stärke der Assoziation eines Faktors mit einer Schätzung seiner Produktivität quantifizieren. Je größer die Zahl, desto stärker die Assoziation. In der ersten Spalte von Google beträgt die Schätzung beispielsweise 0,414. In diesem Fall bedeutet dies, dass das Modell für jeden Punkt zunehmender Übereinstimmung mit der Aussage über die Begeisterung für die Arbeit (F1) eine Erhöhung der Produktivitätsbewertung des Befragten um 0,414 Punkte unter Kontrolle der demografischen Variablen vorhersagt. Die Bewertungen können negativ sein. Beispielsweise ist in allen drei Unternehmen die Bewertung der Produktivität umso geringer, je mehr Mitarbeiter im Team (F48) beschäftigt sind. Neben jeder Punktzahl befindet sich ein Indikator, der die Punktzahl deutlich widerspiegelt.
Bitte beachten Sie, dass die Bewertungen keine höheren Bewertungen von Faktoren bedeuten, sondern eine höhere Korrelation zwischen dem Faktor und der Bewertung Ihrer Produktivität. Zum Beispiel punktet National Instruments (F1) bei der Begeisterung höher als andere Unternehmen. Dies bedeutet nicht, dass die Entwickler dort begeisterter sind: In diesem Unternehmen ist er ein stärkerer Prädiktor für die Bewertung ihrer Produktivität. Wir geben die Bewertungen nicht selbst ab, da dies unter den Bedingungen der Zusammenarbeit verboten ist. Ohne vollständigen Kontext können Bewertungen falsch interpretiert werden. Wenn wir beispielsweise berichten, dass Entwickler in einem Unternehmen weniger von ihrer Arbeit begeistert sind als Entwickler in einem anderen Unternehmen, haben Sie möglicherweise den Eindruck, dass es besser ist, nicht in diesem anderen Unternehmen zu arbeiten.
Zweite Unterspalte Fehler(Fehler) enthält die Standardfehler des Modells für jeden Faktor. Je niedriger der Wert, desto besser. Intuitiv scheinen niedrigere Werte darauf hinzudeuten, dass das Modell seine Leistung zuverlässiger vorhersagt, wenn sich Faktoren ändern. Die Gesamtfehlerwerte sind von Faktor zu Faktor ziemlich stabil, insbesondere bei Google mit einer großen Anzahl von Befragten.
Ein Sternchen (*) zeigt an, dass dieser Faktor im Modell statistisch signifikant war. Beispielsweise ist die Begeisterung für die Arbeit (F1) in allen drei Unternehmen statistisch signifikant, während die Vorbereitung auf Besprechungen (F17) nur bei Google von Bedeutung ist.
Die nächste Spalte enthält den Durchschnittswert ( μ ) für alle drei Unternehmen mit Standardabweichung in Klammern ( σ)). Der erste Indikator zeigt deutlich den Wert der Durchschnittspunktzahl, der zweite Indikator - den Wert der Standardabweichung. Beispielsweise betrug die durchschnittliche Punktzahl für die Begeisterung bei der Arbeit (F1) 0,43, die Standardabweichung 0,051. Die Tabelle ist nach Durchschnittsbewertung sortiert.
Die letzte Spalte enthält die Unterschiede zwischen den Bewertungen von Softwareentwicklern und Analysten bei Google. Positive Werte bedeuten höhere Entwicklerbewertungen, negative bedeuten höhere Analystenbewertungen. In Bezug auf die Begeisterung (F1) haben Analysten beispielsweise etwas niedrigere Bewertungen als Entwickler.
4.2. Welche Faktoren sagen am besten voraus, wie Entwickler ihre Produktivität bewerten werden?
Die stärksten Vorhersagefaktoren sind Aussagen mit der höchsten absoluten Durchschnittsbewertung. Die schwächsten Vorhersagefaktoren sind diejenigen mit der niedrigsten absoluten Durchschnittsbewertung. Mit anderen Worten, die Faktoren oben in der Tabelle in Fig. 4 sind die besten Prädiktoren. Um zu verstehen, welcher Faktor das größte Vertrauen in das Ergebnis bietet, haben wir Ergebnisse hervorgehoben, die für alle drei Unternehmen statistisch signifikant sind:
- Begeisterung für die Arbeit (F1)
- Peer-Unterstützung für neue Ideen (F2)
- Nützliches Feedback zur Arbeitsleistung (F11)
Diskussion . Bitte beachten Sie, dass die ersten 10 Produktivitätsfaktoren nicht technisch sind. Dies ist insofern überraschend, als nach unserer Einschätzung der größte Teil der Forschung von Softwareentwicklern auf technische Aspekte ausgerichtet ist. Eine aktive Neuorientierung in Richtung des menschlichen Faktors kann daher zu einer signifikanten Zunahme des Einflusses von Forschern auf die Industrie führen. Beispielsweise können Antworten auf folgende Fragen besonders fruchtbar sein:
- Was begeistert Softwareentwickler von ihrer Arbeit? Was erklärt den Unterschied in der Begeisterung? Welche Interventionen können die Begeisterung steigern? Dieser Artikel kann die Forschung zu Glück [24] und Motivation [25] ergänzen.
- ? , ? ?
- , ? ? ?
Ein weiteres wichtiges Merkmal ist die Rangfolge der Faktoren aus der COCOMO II-Forschungslinie. Diese Faktoren, die im Rahmen empirischer Studien zu Industrie-Softwareprojekten ermittelt und durch numerische Analyse von 83 Projekten verifiziert wurden [26], wurden ursprünglich formuliert, um die Kosten der Softwareentwicklung abzuschätzen. Zu den Produktivitätsfaktoren von COCOMO II gehören beispielsweise die Volatilität der Basisplattform und die Produktkomplexität. Es ist merkwürdig, dass die in unserer Studie berücksichtigten Faktoren COCOMO II (F5, F10, F14, F16, F24, F26, F28, F32, F33, F34, F36, F38, F39, F43, F44, F46, F47, F48) niedriger ausfielen Werte. Es ist davon auszugehen, dass sie es ermöglichen, die Produktivität schlechter vorherzusagen. Die obere Hälfte der Vorhersagefaktoren (F1 - F24) enthielt nur 5 von COCOMO II und die untere Hälfte - 14 Faktoren. Wir können zwei verschiedene Interpretationen anbieten. Zuerst:COCOMO II fehlen mehrere wichtige Produktivitätsfaktoren, und zukünftige Iterationen von COCOMO II können prädiktiver sein, wenn mehr der von uns untersuchten Faktoren, wie die Unterstützung der Autonomie von Arbeitsansätzen, im Unternehmen eingeführt werden. Eine andere Interpretation: COCOMO II ist an die aktuelle Aufgabe angepasst - Produktivitätsfixierung auf Projektebene [6], [27], [28], [29], [30], [31] - aber weniger geeignet, die Produktivität auf der Ebene der einzelnen Entwickler zu fixieren. Diese Interpretation unterstreicht die Bedeutung und Neuheit unserer Ergebnisse.COCOMO II ist für die aktuelle Aufgabe angepasst - Produktivitätsfixierung auf Projektebene [6], [27], [28], [29], [30], [31] - aber weniger geeignet, die Produktivität auf der Ebene der einzelnen Entwickler zu fixieren. Diese Interpretation unterstreicht die Bedeutung und Neuheit unserer Ergebnisse.COCOMO II ist für die aktuelle Aufgabe angepasst - Produktivitätsfixierung auf Projektebene [6], [27], [28], [29], [30], [31] - aber weniger geeignet, die Produktivität auf der Ebene der einzelnen Entwickler zu fixieren. Diese Interpretation unterstreicht die Bedeutung und Neuheit unserer Ergebnisse.
Darüber hinaus waren alle COCOMO II-Faktoren in allen drei Unternehmen relativ niedrig und statistisch nicht signifikante Prognosefaktoren für die Produktivität. Zum Beispiel:
- Meine Software benötigt viel Rechenleistung (F39).
- Meine Software benötigt einen großen Datenspeicher (F43).
- Meine Softwareplattform (z. B. Entwicklungsumgebung, Software- oder Hardware-Stack) ändert sich schnell (F46).
Eine Erklärung: In den 20 Jahren seit der Erstellung und Erprobung von COCOMO II sind Plattformen hinsichtlich der Produktivität weniger vielfältig geworden. Es ist wahrscheinlich, dass standardisierte Betriebssysteme Entwickler jetzt vor Produktivitätsverlusten aufgrund von Hardwareänderungen schützen (z. B. Android in der mobilen Entwicklung). Ebenso können Cloud-Plattformen Entwickler vor Produktivitätsverlusten aufgrund von Prozessskalierung und Speicheranforderungen schützen. Ganz zu schweigen davon, dass moderne Frameworks und Cloud-Plattformen einfach zu bedienen sind. Darüber hinaus ist der Produktivitätsunterschied bei der Verarbeitung großer und kleiner Datenmengen möglicherweise seit der Erstellung von COCOMO II verschwunden.
4.3. Wie unterscheiden sich diese Faktoren von Unternehmen zu Unternehmen?
Um diese Frage zu beantworten, können Sie die Standardabweichung in den Schätzungen für die drei Unternehmen betrachten. Hier sind die drei Faktoren mit der geringsten Variabilität, dh mit den stabilsten Werten zwischen Unternehmen:
- Verwenden der Telearbeit als Fokus (F40).
- Nützliches Feedback zur Arbeitsleistung (F4).
- Peer-Unterstützung für neue Ideen (F2).
Wir glauben, dass die Stabilität dieser Faktoren sie zu guten Kandidaten für die Generalisierbarkeit macht. Andere Unternehmen dürften ähnliche Ergebnisse für diese Faktoren erzielen.
Und hier sind die drei Faktoren mit der größten Variabilität, dh mit der größten Wertverteilung zwischen Unternehmen:
- Verwendung der besten Werkzeuge und Ansätze (F15).
- Wiederverwendung des Codes (F25).
- Genauigkeit eingehender Informationen (F6).
Diskussion . Die drei am wenigsten variablen Faktoren (F40, F4 und F2) haben ein gemeinsames Merkmal: Sie beziehen sich nicht auf Technologie, sondern auf Gesellschaft und Umwelt. Vielleicht deutet dies darauf hin, dass Entwickler überall dort, wo sie arbeiten, gleichermaßen von Remote-Arbeit, Feedback und Peer-Support für neue Ideen betroffen sind. Das Ändern dieser drei Faktoren kann sich als die größte Auswirkung erweisen.
Warum sind die Faktoren F15, F25 und F6 in verschiedenen Unternehmen so unterschiedlich? Für jeden von ihnen haben wir eine mögliche Erklärung basierend auf dem, was wir über diese Unternehmen wissen.
Die Verwendung besserer Tools und Ansätze (F15) ist am stärksten mit dem Leistungsfaktor von Google verbunden, jedoch nicht signifikant mit National Instruments. Mögliche Erklärung: Die Codebasis von Google ist viel größer. Die effizientere Verwendung besserer Tools und Ansätze zum effizienten Navigieren und Verstehen der größeren Codebasis hat daher erhebliche Auswirkungen auf die Produktivität. Bei National Instruments ist die Produktivität weniger werkzeugabhängig, da die Codebasis kleiner und klarer ist.
Die Wiederverwendung von Code (F25) hängt stark mit dem Leistungsfaktor von Google zusammen, jedoch nicht wesentlich mit ABB. Mögliche Erklärung: Google erleichtert die Wiederverwendung von Code. Die Codebasis ist monolithisch, und alle Entwickler können praktisch jede Codezeile im Unternehmen untersuchen, sodass die Wiederverwendung keinen großen Aufwand erfordert. Und ABB verfügt über viele Repositorys, auf die Sie zugreifen müssen. Und in diesem Unternehmen können Produktivitätsgewinne (durch Wiederverwendung) durch Produktivitätsverluste (durch das Finden und Erhalten des richtigen Codes) ausgeglichen werden.
Die Informationsgenauigkeit (F6) hängt stark mit den Leistungswerten von National Instruments zusammen, jedoch nicht wesentlich mit ABB. Mögliche Erklärung: Entwickler bei ABB sind besser gegen den Einfluss ungenauer Informationen isoliert. Insbesondere bei ABB sind mehrere Ebenen des Supportteams bestrebt, die richtigen Informationen über Fehler von Kunden zu erhalten. Wenn der Entwickler ungenaue Informationen erhält, kann seine Produktivität sinken, da er die Aufgabe der Verfeinerung der Daten an das Support-Team zurück delegieren muss.
4.4. Was ermöglicht es, die Einschätzung eines Entwicklers hinsichtlich seiner Produktivität insbesondere im Vergleich zu anderen Wissensarbeitern vorherzusagen?
Um diese Frage zu beantworten, wenden Sie sich an die letzte Spalte in Abb. 4. Wenn wir uns mehrere Beziehungen zwischen Maximalbewertungen ansehen, werden wir feststellen, dass die Einschätzung der Analysten zu ihrer Produktivität stärker mit Folgendem verbunden ist:
- Positive Wahrnehmung ihrer Teamkollegen (F7).
- Autonomie bei der Organisation der Arbeitszeit (F4).
Andererseits hängt die Einschätzung der Entwickler ihrer Produktivität stärker zusammen mit:
- Ausführen verschiedener Aufgaben innerhalb der Arbeit (F13).
- Effektiv außerhalb ihrer Arbeitsplätze arbeiten (F30).
Diskussion . Insgesamt deuten die Ergebnisse darauf hin, dass Entwickler anderen Wissensarbeitern etwas ähnlich und etwas anders sind. Zum Beispiel lässt sich die Produktivität von Entwicklern am besten durch die Begeisterung bei der Arbeit vorhersagen, und Analysten haben das Gleiche. Wir glauben, dass Unternehmen unsere Erkenntnisse nutzen können, um entwicklerspezifische Produktivitätsinitiativen oder umfassendere Initiativen auszuwählen.
Das Unified Development Toolkit von Google erklärt möglicherweise, warum eine zunehmende Aufgabenvielfalt mit höheren Produktivitätsbewertungen bei Entwicklern und nicht bei Analysten verbunden ist. Die Vielfalt der Aufgaben kann die Langeweile verringern und die Produktivität für beide Gruppen steigern. Mit den einheitlichen Entwicklungstools von Google können Entwickler jedoch dieselben Tools für verschiedene Aufgaben verwenden. Und Analysten müssen möglicherweise unterschiedliche Tools für unterschiedliche Aufgaben verwenden, was den kognitiven Aufwand beim Kontextwechsel erhöht.
Abwesenheitsarbeit kann erklären, warum die Verbesserung der Arbeitseffizienz außerhalb des Arbeitsplatzes für Entwickler stärker mit Produktivitätssteigerungen verbunden ist als für Analysten. Wir glauben, dass eine Arbeitspause während der Programmierung schädlicher ist als während der analytischen Arbeit.
Parnin und Rugaber stellten fest, dass die Rückkehr zur Arbeit nach einer Unterbrechung ein häufiges und anhaltendes Problem für Entwickler ist [32], was dazu führte, dass bessere Tools benötigt wurden, um wieder an einem Problem arbeiten zu können [33].

4.5. Andere Produktivitätsfaktoren
Am Ende des Fragebogens könnten die Befragten zusätzliche Faktoren angeben, die ihrer Meinung nach die Produktivität beeinflussen. Diese Ergänzungen waren größtenteils die gleichen oder verfeinerten Beschreibungen unserer 48 Faktoren. Wir haben solche Ergänzungen verworfen, aber bei Bedarf neue Faktoren geschaffen. Die ergänzenden Materialien enthalten Beschreibungen neuer Faktoren sowie aktualisierte Beschreibungen der ursprünglich vorgeschlagenen Faktoren. Potenzielle Forscher haben möglicherweise eine neue gemischte Teamfrage, um an einem Projekt zu arbeiten, oder verfeinern oder schlagen spezifischere Fragenaufschlüsselungen für die Faktoren F15, F16 und F19 vor.
4.6. Demographie
Bei Google und National Instruments waren weder allgemeine demografische Modelle noch einzelne Begleitvariablen statistisch signifikante Prädiktoren für ihre Leistungswerte.
Für ABB erwies sich das demografische Modell als signifikant ( F = 3 , 406 , df = (5 , 131) , p <0,007). Das Geschlecht erwies sich ebenfalls als statistisch signifikanter Faktor ( p = 0,007): Frauen schätzen ihre Produktivität um 0,83 Punkte höher als Männer. Teilnehmer anderer Geschlechter („andere“) zeigten eine um 1,6 Punkte höhere Punktzahl als Männer ( p = 0,03). Die Position ( S.= 0,04), jedes weitere Jahr erhöhte das Unternehmen seine Leistungsschätzung um 0,02 Punkte. Soweit wir wissen, erklären die Unterschiede zwischen ABB und den beiden anderen Unternehmen nicht, warum diese demografischen Faktoren nur in ABB und nirgendwo anders als signifikant vorhergesagt wurden.
4.7. Anwendung in der Praxis und in der Forschung
Wie können wir unsere Ergebnisse in die Praxis umsetzen? Wir haben eine Rangliste der wichtigsten Faktoren für die Vorhersage der Produktivität bereitgestellt, anhand derer Initiativen priorisiert werden können. Beispiele für Initiativen finden sich in früheren Forschungsarbeiten.
Um beispielsweise die Begeisterung bei der Arbeit zu steigern, schlugen Markos und Sridevi vor, den Arbeitnehmern durch Workshops zu Technologie und zwischenmenschlicher Kommunikation zu helfen, professionell zu wachsen [34]. Außerdem schlugen die Forscher vor, die Praxis der Wertschätzung für gute Arbeit einzuführen. Zum Beispiel experimentiert ABB mit der öffentlichen Wertschätzung für Entwickler, die Tools und Techniken für die Navigation in strukturiertem Code implementiert haben [35].
Um die Unterstützung für neue Ideen zu erhöhen, haben Brown und Duguid formelle und informelle Wege vorgeschlagen, um bewährte Verfahren auszutauschen [36]. Bei Google erfolgt die einseitige Verbreitung von Wissen über die Initiative "Toilettentests": Entwickler schreiben kurze Nachrichten über Tests oder einen anderen Bereich, und diese Notizen werden dann in Toiletten im gesamten Unternehmen veröffentlicht.
Um die Qualität des Feedbacks zur Arbeitsproduktivität zu verbessern, schlagen London und Smither vor, sich auf Feedback zu konzentrieren, das nicht wertend, verhaltensbasiert, interpretierbar und ergebnisorientiert ist [37]. Bei Google kann ein solches Feedback durch harmlose Obduktionen eingeholt werden: Nach wichtigen negativen Ereignissen wie einem Leistungsabfall schreiben Ingenieure gemeinsam einen Bericht über die Maßnahmen, die die ursprüngliche Ursache des Problems beeinflusst haben, ohne bestimmte Mitarbeiter zu beschuldigen.
Basierend auf unserer Arbeit sehen wir verschiedene Richtungen für zukünftige Forschung.
Erstens wird eine systematische Überprüfung von Artikeln, die die Auswirkungen und den Kontext von Beweisen für jeden hier diskutierten Produktivitätsfaktor charakterisieren, die Benutzerfreundlichkeit unserer Arbeit verbessern, indem kausale Zusammenhänge geschaffen werden. Wenn sie schwach sind, kann die Anwendbarkeit verbessert werden, indem eine Reihe von Experimenten durchgeführt wird, um die Ursache festzustellen.
Zweitens können angehende Forscher, wie in den Abschnitten 4.5 und 4.6 erwähnt, zusätzliche Faktoren verwenden, die von unseren Befragten vorgeschlagen wurden, und den Einfluss des Geschlechts und anderer demografischer Faktoren auf die Entwicklerproduktivität untersuchen.
Drittens kann der Einfluss der Produktivitätsforschung auf die Softwareentwicklung durch einen mehrdimensionalen Satz von Metriken und Werkzeugen verbessert werden, die durch empirische Forschung und Triangulation validiert wurden.
Viertens können Unternehmen intelligentere Investitionsentscheidungen treffen, wenn Forscher die Kosten für sich ändernde Faktoren berechnen können, die sich auf die Produktivität auswirken.
4.8. Risiken
Bei der Interpretation der Ergebnisse dieser Studie müssen verschiedene Risiken für ihre Gültigkeit berücksichtigt werden.
4.8.1. Risiken für die Datengenauigkeit
Zunächst haben wir nur über eine Messung gesprochen - die Bewertung Ihrer Produktivität. Es gibt andere Dimensionen, einschließlich objektiver Maßnahmen, wie beispielsweise die Anzahl der pro Tag geschriebenen Codezeilen, ein Ansatz, der von Facebook verwendet wird [38]. Wie wir in Abschnitt 3.1 ausgeführt haben, weisen alle Produktivitätsmetriken Fehler auf, einschließlich der Messung Ihrer eigenen Produktivität. Beispielsweise können Entwickler bei der Bewertung ihrer Produktivität zu leichtfertig sein oder ihre Bewertung aufgrund von Vorurteilen in der Gesellschaft künstlich überschätzen [39]. Trotz dieser Mängel baut das von Zelenski geleitete Team auf früheren Arbeiten auf, um die Gültigkeit der Leistungsbewertung [40] zu argumentieren, die auch in diesem Artikel verwendet wird.
Zweitens haben wir unsere Produktivität mit einer einzigen Frage gemessen, die kaum das gesamte Spektrum der Entwicklerproduktivität abdeckt. Zum Beispiel konzentriert sich die Frage auf Frequenz und Intensität, berücksichtigt jedoch nicht die Qualität. Wir haben die Befragten auch nicht gebeten, ihre Antworten auf einen bestimmten Zeitraum zu beschränken, sodass einige Teilnehmer möglicherweise auf der Grundlage ihrer Erfahrungen in der letzten Woche antworten, während andere ihre Erfahrungen im letzten Jahr bewerteten. Rückblickend sollte die Studie mit einem festen Zeitintervall durchgeführt werden.
Drittens haben wir uns aufgrund der begrenzten Anzahl von Fragen nur auf die Faktoren gestützt, die in früheren Arbeiten untersucht wurden. Die 48 von uns ausgewählten Fragen decken möglicherweise nicht alle Aspekte des produktivitätsbezogenen Verhaltens ab. Oder die von uns gewählten Faktoren sind in bestimmten Fällen zu allgemein. Rückblickend könnte beispielsweise der Faktor, der sich auf die besten „Werkzeuge und Ansätze“ (F14) bezieht, stärker sein, wenn wir Werkzeuge von Methoden trennen.
4.8.2. Interne Risiken für die Zuverlässigkeit
Viertens haben wir, wie in Abschnitt 3.8 erwähnt, auf frühere Arbeiten zurückgegriffen, um kausale Beziehungen zwischen Faktoren und Produktivität herzustellen, aber die Stärke der Beweise für Beziehungen kann variieren. Es kann sich herausstellen, dass einige Faktoren die Bewertung ihrer Produktivität nur indirekt durch andere Faktoren beeinflussen oder dass ihre Verbindung im Allgemeinen die entgegengesetzte Richtung hat. Zum Beispiel ist es wahrscheinlich, dass ein Hauptfaktor für die Produktivität, eine erhöhte Begeisterung für die Arbeit (F1), tatsächlich auf eine erhöhte Produktivität zurückzuführen ist.
4.8.3. Externe Zuverlässigkeitsrisiken
Fünftens ist die Generalisierbarkeit mit anderen Unternehmenstypen, anderen Organisationen und anderen Arten von Wissensarbeitern begrenzt, obwohl wir drei ziemlich unterschiedliche Unternehmen untersucht haben. In diesem Artikel haben wir Analysten als Vertreter von Nichtentwicklern ausgewählt. Diese Kategorie umfasst jedoch verschiedene Arten von Wissensarbeitern - Ärzte, Architekten und Anwälte. Ein weiteres Risiko für die Zuverlässigkeit ist die Voreingenommenheit aufgrund fehlender Antworten: Die Personen, die die Fragebögen beantworteten, wurden selbst ausgewählt.
Sechstens haben wir jeden Produktivitätsfaktor separat analysiert, aber viele Faktoren können sich gegenseitig begleiten. Dies ist kein Analyseproblem, sondern die Anwendbarkeit der Ergebnisse. Wenn Faktoren codependent sind, kann sich eine Änderung des einen nachteilig auf den anderen auswirken.
4.8.4. Risiken für die konstruktive
Glaubwürdigkeit Siebtens waren wir bei der Erstellung dieser Studie besorgt über die Möglichkeit, dass die Befragten unsere Analysemethode erkennen und nicht wahrheitsgemäß antworten könnten. Wir haben versucht, diese Wahrscheinlichkeit zu verringern, indem wir das Problem der Produktivität von seinen Faktoren getrennt haben. Die Befragten konnten jedoch möglicherweise Schlussfolgerungen zu unserer Analysemethode ziehen.
Schließlich haben wir einige der Fragen umformuliert, um die Studie auf Analysten zuzuschneiden, was die Bedeutung der Fragen unerwünscht verändern könnte. Infolgedessen können sich Unterschiede zwischen Entwicklern und Analysten eher aus Fragen als aus beruflichen Gründen ergeben haben.
5. Verwandte Arbeiten
Viele Forscher haben individuelle Produktivitätsfaktoren für Softwareentwickler untersucht. Zum Beispiel analysierten Moser und Nierstrasz 36 Softwareentwicklungsprojekte und untersuchten die möglichen Auswirkungen objektorientierter Technologien auf die Verbesserung der Entwicklerproduktivität [41].
Ein weiteres Beispiel ist die Studie von DeMarco und Lister mit 166 Programmierern aus 35 Organisationen, die eine eintägige Programmierübung durchführen. Die Autoren stellten fest, dass Arbeitsplatz und Organisation mit Produktivität verbunden sind [42].
Ein drittes Beispiel ist ein Laborexperiment von Kersten und Murphy mit 16 Entwicklern. Es stellte sich heraus, dass diejenigen, die das Tool verwendeten, um sich auf die Aufgabe zu konzentrieren, viel produktiver waren als andere [43].
Darüber hinaus liefert die systematische Analyse von Wagner und Rouet eine gute Vorstellung von der Beziehung zwischen einzelnen Faktoren und Produktivität [14]. Das von Mayer geleitete Team bot eine noch aktuellere Analyse des Überblicks über Produktivitätsfaktoren an [3]. Im Allgemeinen basiert unsere Arbeit auf diesen Untersuchungen einzelner Faktoren mit einer breiteren Untersuchung ihrer Vielfalt.
Petersens systematischer Überblick besagt, dass sieben Artikel Faktoren quantifizieren, die die Produktivität von Softwareentwicklern vorhersagen [44]. In jeder Arbeit werden numerische Methoden zur Vorhersage verwendet. In der Regel handelt es sich dabei um eine Regression, die wir auch in unserer Forschung verwendet haben. Die häufigsten Faktoren hängen mit der Projektgröße zusammen, und 6 von 7 Faktoren werden explizit auf der Grundlage der COCOMO II-Produktivitätstreiber formuliert ([6], [27], [28], [29], [30], [31]). Das komplexeste Prognosemodell in Petersens Studie verwendet 16 Faktoren [6].
Unsere Arbeit hat zwei Hauptunterschiede. Erstens schätzen wir im Vergleich zu früheren Arbeiten mehr Faktoren (48), und ihre Vielfalt ist größer. Wir haben Faktoren ausgewählt, die auf der Arbeits- und Organisationspsychologie basieren. Zweitens hatten wir ein anderes Thema für die Analyse: Frühere Forscher untersuchten, was die Produktivität im Rahmen des Projekts vorhersagen kann, und wir waren an der persönlichen Produktivität der Menschen interessiert.
In früheren Studien wurden neben der Softwareentwicklung Faktoren verglichen, die die Produktivität in anderen Berufen vorhersagen, insbesondere im Bereich der Arbeits- und Organisationspsychologie. Obwohl sich solche Studien auf die Produktivität auf Unternehmensebene [45] und körperliche Arbeit wie das verarbeitende Gewerbe [46] konzentriert haben, ist die Produktivität der Wissensarbeiter der am engsten verwandte Bereich. Das heißt, Menschen, die Wissen und Informationen in ihrer Arbeit aktiv nutzen, normalerweise mit einem Computer [47]. Der Vergleich der Faktoren für solche Berufe wird in zwei Hauptwerken vorgestellt. Die erste ist eine von Palwalin geleitete Teamstudie, in der 38 Faktoren untersucht werden, die in früheren Studien mit der Produktivität verglichen wurden. Diese Faktoren umfassen den physischen, virtuellen und sozialen Arbeitsbereich,persönliche Arbeitsansätze und Wohlbefinden bei der Arbeit [4]. Die zweite Arbeit ist eine Studie von Hernaus und Mikulich über 512 Wissensarbeiter. Die Autoren untersuchten 14 Faktoren, die in drei Kategorien unterteilt waren [9]. Wir haben uns bei der Vorbereitung unserer Studie auf beide Arbeiten gestützt (Abschnitt 3.2).
Studien, in denen Produktivitätsfaktoren für Wissensarbeiter verglichen wurden, haben Softwareentwicklern jedoch keine Beachtung geschenkt. Dafür gibt es zwei Hauptgründe. Erstens ist unklar, inwieweit die erzielten Gesamtergebnisse auf Entwickler projiziert werden. Zweitens werden solche Studien normalerweise von entwicklerspezifischen Faktoren wie der Wiederverwendung von Software und der Komplexität der Codebasis abstrahiert [48]. Daher gibt es in der Literatur eine Lücke beim Verständnis der Faktoren, die eine Vorhersage der Entwicklerproduktivität ermöglichen. Diese Lücke zu schließen ist praktisch. Wir haben drei Forschungsteams in drei Unternehmen zusammengestellt, um die Produktivität zu verbessern. Die Überbrückung dieser Wissenslücke hilft unseren Teams bei der Recherche und Unternehmen bei der Investition in die Entwicklerproduktivität.
6. Fazit
Viele Faktoren wirken sich auf die Entwicklerproduktivität aus, aber Unternehmen verfügen nur über begrenzte Ressourcen, um sich auf die Verbesserung der Produktivität zu konzentrieren. Wir haben in drei Unternehmen eine Studie erstellt und durchgeführt, um verschiedene Faktoren zu bewerten und zu vergleichen. Entwickler und Führungskräfte können unsere Erkenntnisse nutzen, um ihre Bemühungen zu priorisieren. Um es einfach auszudrücken: In früheren Veröffentlichungen wurden viele Möglichkeiten zur Verbesserung der Produktivität von Softwareentwicklern vorgeschlagen, und wir haben vorgeschlagen, wie Sie diese Möglichkeiten priorisieren können.

Block von Fragen
Was macht einen Entwickler produktiv?
Diese einseitige, anonyme Recherche dauert 15 Minuten und hilft uns, besser zu verstehen, was die Entwicklerproduktivität beeinflusst. Bitte antworten Sie offen und ehrlich.
Die Forschung wird Fragen zu Ihnen, Ihrem Projekt und Ihrer Software stellen. Bitte denken Sie daran:
Meine Software bezieht sich auf die Kernsoftware, die Sie bei ABB entwickeln, einschließlich Produkte und Infrastruktur. Wenn Sie an verschiedenen Programmen arbeiten, antworten Sie nur auf das Hauptprogramm.
Mein Projekt gehört zu dem Team, mit dem Sie Software erstellen. Bitte beantworten Sie verwandte Fragen zu anderen Softwareentwicklern bei ABB.
Einige Fragen betreffen potenziell sensible Themen. Füllen Sie die Antworten aus, damit niemand über Ihre Schulter gucken kann, und löschen Sie den Browserverlauf und die Cookies, nachdem Sie den Fragebogen ausgefüllt haben.
Bitte bewerten Sie Ihre Zustimmung mit den folgenden Aussagen.
Liste der Forschungsfragen





Diese Fragen sollen eine umfassende Bewertung der Faktoren ermöglichen, die die Produktivität beeinflussen können. Vermissen wir etwas?
Geschlecht (optional)
Wie lautet Ihr Titel? (optional) In
welchem Jahr sind Sie zu ABB gekommen?
Zusätzliche Materialien
Von den Befragten festgestellte Produktivitätsfaktoren
In diesem Abschnitt listen wir die Faktoren auf, die die Befragten in ihren Antworten auf die offene Frage beschrieben haben. Zuerst werden wir einige neue Faktoren beschreiben und dann werden wir Faktoren beschreiben, die mit den bereits in der Studie verfügbaren Faktoren zusammenhängen. Wir haben die Kommentare der Befragten anhand unserer Faktoren durch Codes ergänzt. Hier diskutieren oder bewerten wir nicht die Antworten von Menschen, wir ergänzen nicht die bestehenden Beschreibungen unserer Faktoren.
Neue Faktoren
In den Kommentaren wurden 4 Themen angesprochen, die in unserer Studie nicht berücksichtigt wurden. In sechs Antworten wurden Themen des gemischten Projektteams angesprochen, insbesondere das Verhältnis von Managern zu Entwicklern. die Anwesenheit einer ausreichenden Anzahl von Mitarbeitern im Projekt; und ob das Management in der Lage ist, ein starkes Eigentum an dem Produkt aufrechtzuerhalten. Ein Befragter stellte fest, dass sich die Art der Software (Server, Client, Handy usw.) auf die Produktivität auswirkt. Ein anderer bemerkte den Einfluss physiologischer Faktoren wie der Anzahl der Schlafstunden. Ein anderer erwähnte die Möglichkeiten für persönliches Wachstum.
Verfügbare Faktoren
F1. Fünf Befragte erwähnten Faktoren, die mit der Begeisterung bei der Arbeit zusammenhängen: zwei erwähnten die Motivation und Anerkennung der Arbeit, eine - Moral und eine - ein deprimierendes Bürogebäude.
F3. Vier der Befragten gaben Faktoren an, die mit der Autonomie bei der Auswahl der Arbeitsmethoden zusammenhängen. Einer erwähnte die Autonomie auf Teamebene, ein anderer die Politik, die die Verwendung eines guten Open-Source-Systems verhindert, der dritte die Prioritäten des Unternehmens, die den Einsatz bestimmter Techniken in Teams einschränken.
F4. Ein Befragter stellte fest, dass die Arbeitszeit autonom ist und sich auf Prioritäten beschränkt, die durch die Notwendigkeit einer Beförderung vorgegeben sind.
F5. Drei Befragte gaben Führungskompetenz an. Eine erwähnte Führung mit einer kohärenten Strategie, die zweite - widersprüchliche Prioritäten, die vom Management weitergegeben wurden, die dritte - Management der Mitarbeiterproduktivität.
F6. Acht Befragte gaben an, genaue Informationen zu liefern. Drei erwähnten die teamübergreifende Kommunikation über Dokumentation (und andere Kanäle) und zwei erwähnten die klare Definition der Ziele und Pläne des Teams.
F7. Zwei Befragte äußerten positive Gefühle gegenüber Kollegen angesichts des Teams und des Teamzusammenhalts.
F8. Ein Befragter bemerkte Autonomie bei der Arbeit: Die Unternehmensrichtlinien bestimmen, welche Ressourcen verwendet werden können.
F9. Ein Befragter bemerkte eine Konfliktlösung, die darauf hinwies, dass die persönlichen Gewohnheiten der Teamkollegen gegen soziale Normen verstießen.
F10. Vier Befragte wiesen auf die Kompetenz der Entwickler hin. Der eine erwähnte die Schwierigkeiten beim Verständnis des Codes, der andere - die Kenntnis des Themenbereichs, der dritte - die Ernsthaftigkeit der Einstellung zum Testen.
F11. Ein Befragter bemerkte ein Feedback zur Arbeitsproduktivität: Anerkennung durch Kollegen und Management, Beförderung.
F12. Ein Befragter bemerkte die Komplexität der Software-Implementierung „von meinem Gehirn in das ausgelieferte Produkt“.
F13. Zwei Befragte wiesen auf die Vielfalt der Aufgaben hin, insbesondere das Abfangen von Aufgaben im Namen ihres Teams und das Wechseln des Kontexts.
F14 Vier Befragte bewerteten die Anforderungen und die Architektur als kompetent. Einer erwähnte die unzureichende Berücksichtigung von Problemen, ein anderer - die Lesbarkeit von Architekturdokumenten, der dritte - die Qualität der Projektpläne, der vierte - das Vorhandensein einer "angemessenen Unterstützung bei der Entwicklung von Anforderungen".
F15. 32 Befragte gaben an, die besten Tools und Ansätze zu verwenden. Zwölf erwähnten die Leistung der Tools, insbesondere die Geschwindigkeits- und Latenzprobleme beim Erstellen und Testen. Fünf Personen erwähnten die verfügbaren Funktionen, drei erwähnten Kompatibilitäts- und Migrationsprobleme, zwei erwähnten, dass selbst das beste verfügbare Tool möglicherweise nicht den Anforderungen entspricht. In anderen Kommentaren zu Tools und Vorgehensweisen wurde der Automatisierungsgrad von Tools erwähnt. spezialisierte Debugger und Simulatoren; Agile Ansätze; Flockentests und verwandte Werkzeuge; Tools, die aus der Ferne gut funktionieren; Wahl der Programmiersprachen; veraltete Tools; Trennung der persönlichen Präferenzen in Tools von denen, die im Unternehmen übernommen wurden.
F 16. Neunzehn Befragte stellten einen angemessenen Wissenstransfer zwischen Menschen fest. Neun Personen erwähnten die Schwierigkeiten bei der Kommunikation mit anderen Teams: drei - Ziele zwischen Teams vereinbaren, eines - Ziele innerhalb eines großen Teams vereinbaren, das andere - eine Einigung zwischen Teams erzielen. Zwei wiesen auf die Schwierigkeit hin, die Arbeit in einem internationalen Team oder einem Zeitzonenteam zu koordinieren. Zwei weitere erwähnten die Notwendigkeit, sich auf die Dokumentation anderer Teams zu verlassen. Zwei äußerten sich zur Dauer der Codeüberprüfung. Zwei andere erwähnten das Bewusstsein für die Arbeitsmöglichkeiten der Teamkollegen. Einer erwähnte die Suche nach der richtigen Person, ein anderer - Verzögerungen bei der Interaktion, der dritte - die Kommunikation zwischen Ingenieuren und Spezialisten auf dem Fachgebiet. Schließlich erwähnte man die Wichtigkeit, es klar zu machenWelche Kommunikationskanäle sind in bestimmten Situationen besser zu nutzen?
F18. Zwei Befragte gaben Ansätze für die Abhaltung von Besprechungen an, einer erwähnte, dass die Wirksamkeit von Besprechungen von der Verfügbarkeit von Besprechungsräumen abhängt.
F19. Vierundzwanzig Befragte stellten Unterbrechungen und Ablenkungen von der Arbeit fest. Zehn erwähnten laute Umgebungen und sieben gaben an, dass offene Büros die Produktivität verringern. Vier erwähnten Schwierigkeiten beim Multitasking und beim Kontextwechsel. Weitere vier berichteten, dass sie sich entweder auf ihre Hauptaufgabe oder auf „optionale“ Aufgaben wie Interviews konzentrieren müssen. Zwei erwähnten Konzentrationsschwierigkeiten beim Pendeln zur und von der Arbeit.
F25. Ein Befragter bemerkte die Wiederverwendung von Code und wies darauf hin, dass 2-3-Zeilen-APIs die Komplexität bei minimalem Beitrag zur Reduzierung von Duplikaten erhöhen.
F26. Ein Befragter kommentierte die Erfahrungen mit der Softwareplattform und gab an, dass sich die Probleme verschlimmern, wenn ein Entwickler zwischen Projekten wechselt.
F27. Drei Befragte gaben die Softwarearchitektur und die Risikominderung an. Einer wies darauf hin, "wie bekannt die Produktarchitektur ist, wie miteinander verbunden sie ist und wie sie Menschen unterstützt, die ihre Rollen kennen und sich konzentrieren können, die ihre Verantwortlichkeiten und Grenzen kennen und wissen, was sie besitzen." Ein anderer stellte fest, dass Architektur durch Modularität den Austausch zwischen Softwarekomponenten erleichtern kann. Der dritte schlug vor, dass die Architektur mit der Struktur der Organisation übereinstimmen sollte.
F32. Vier Befragte erwähnten die Notwendigkeit eines Kontextwechsels. Zwei erwähnten, dass beim Wechsel zwischen Projekten ein Wechsel erforderlich ist. Man erklärte, dass sich die Notwendigkeit der Kontextumschaltung von der Freude am Umschalten unterscheidet. Ein anderer erwähnte, dass „Produktivitätsprojekte“ an und für sich die Produktivität verringern können.
F34. Fünf Befragte gaben enge Fristen an. Der eine wies darauf hin, dass dies zum Wachstum der technischen Verschuldung beiträgt, der andere - dass solche Fristen zu einer Verschwendung von Ressourcen führen können.
F42. Drei Befragte stellten Software-Einschränkungen fest. Zwei wiesen auf Datenschutzbeschränkungen und einer auf kritische Sicherheitsbeschränkungen hin.
F44. Elf Befragte wiesen auf die Komplexität der Software hin. Zwei erwähnten die besondere Komplexität des Legacy-Codes, zwei bezogen sich auf technische Schulden und jeweils auf Versionierung, Softwarewartung und
Code-Verständnis.
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.786969 0.111805 24.927 < 0.0000000000000002 ***
log(lines_changed + 1) 0.045189 0.009296 4.861 0.00000122 ***
level -0.050649 0.015833 -3.199 0.00139 **
job_codeENG_TYPE2 0.194108 0.172096 1.128 0.25944
job_codeENG_TYPE3 0.034189 0.076718 0.446 0.65589
job_codeENG_TYPE4 -0.185930 0.084484 -2.201 0.02782 *
job_codeENG_TYPE5 -0.375294 0.085896 -4.369 0.00001285 ***
---
Signif. codes: 0 `***` 0.001 `**` 0.01 `*` 0.05 `.` 0.1 ` ` 1
Residual standard error: 0.8882 on 3388 degrees of freedom
Multiple R-squared: 0.01874, Adjusted R-squared: 0.017
F-statistic: 10.78 on 6 and 3388 DF, p-value: 0.000000000006508
Zahl: 5: Modell 1: Vollständige Ergebnisse der linearen Regression
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.74335 0.09706 28.265 < 0.0000000000000002
log(changelists_created + 1) 0.11220 0.01608 6.977 0.00000000000362
level -0.04999 0.01574 -3.176 0.00151
job_codeENG_TYPE2 0.27044 0.17209 1.571 0.11616
job_codeENG_TYPE3 0.02451 0.07644 0.321 0.74847
job_codeENG_TYPE4 -0.21640 0.08411 -2.573 0.01013
job_codeENG_TYPE5 -0.40194 0.08559 -4.696 0.00000275538534
(Intercept) ***
log(changelists_created + 1) ***
level **
job_codeENG_TYPE2
job_codeENG_TYPE3
job_codeENG_TYPE4 *
job_codeENG_TYPE5 ***
---
Signif. codes: 0 `***` 0.001 `**` 0.01 `*` 0.05 `.` 0.1 ` ` 1
Residual standard error: 0.885 on 3388 degrees of freedom
Multiple R-squared: 0.02589, Adjusted R-squared: 0.02416
F-statistic: 15.01 on 6 and 3388 DF, p-value: < 0.00000000000000022
Zahl: 6: Modell 2: Vollständige Ergebnisse der linearen Regression
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.79676 0.11141 25.102 < 0.0000000000000002
log(lines_changed + 1) -0.01462 0.01498 -0.976 0.32897
log(changelists_created + 1) 0.13215 0.02600 5.082 0.000000394
level -0.05099 0.01578 -3.233 0.00124
job_codeENG_TYPE2 0.27767 0.17226 1.612 0.10706
job_codeENG_TYPE3 0.02226 0.07647 0.291 0.77102
job_codeENG_TYPE4 -0.22446 0.08452 -2.656 0.00795
job_codeENG_TYPE5 -0.40819 0.08583 -4.756 0.000002057
(Intercept) ***
log(lines_changed + 1)
log(changelists_created + 1) ***
level **
job_codeENG_TYPE2
job_codeENG_TYPE3
job_codeENG_TYPE4 **
job_codeENG_TYPE5 ***
---
Signif. codes: 0 `***` 0.001 `**` 0.01 `*` 0.05 `.` 0.1 ` ` 1
Residual standard error: 0.885 on 3387 degrees of freedom
Multiple R-squared: 0.02616, Adjusted R-squared: 0.02415
F-statistic: 13 on 7 and 3387 DF, p-value: < 0.00000000000000022
Zahl: 7: Modell 3: Vollständige Ergebnisse der linearen Regression.
Referenzliste
[1] R. S. Nickerson, “Confirmation bias: A ubiquitous phenomenon in many guises.” Review of general psychology, vol. 2, no. 2, p. 175, 1998.
[2] Y. W. Ramírez and D. A. Nembhard, “Measuring knowledge worker productivity: A taxonomy,” Journal of Intellectual Capital, vol. 5, no. 4, pp. 602–628, 2004.
[3] A. N. Meyer, L. E. Barton, G. C. Murphy, T. Zimmermann, and T. Fritz, “The work life of developers: Activities, switches and perceived productivity,” IEEE Transactions on Software Engineering, 2017.
[4] M. Palvalin, M. Vuolle, A. Jääskeläinen, H. Laihonen, and A. Lönnqvist, “Smartwow–constructing a tool for knowledge work performance analysis,” International Journal of Productivity and Performance Management, vol. 64, no. 4, pp. 479–498, 2015.
[5] C. H. C. Duarte, “Productivity paradoxes revisited,” Empirical Software Engineering, pp. 1–30, 2016.
[6] K. D. Maxwell, L. VanWassenhove, and S. Dutta, “Software development productivity of european space, military, and industrial applications,” IEEE Transactions on Software Engineering, vol. 22, no. 10, pp. 706–718, 1996.
[7] J. D. Blackburn, G. D. Scudder, and L. N. Van Wassenhove, “Improving speed and productivity of software development: a global survey of software developers,” IEEE transactions on software engineering, vol. 22, no. 12, pp. 875–885, 1996.
[8] B. Vasilescu, Y. Yu, H.Wang, P. Devanbu, and V. Filkov, “Quality and productivity outcomes relating to continuous integration in github,” in Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering. ACM, 2015, pp. 805–816.
[9] T. Hernaus and J. Mikulic, “Work characteristics and work performance of knowledge workers,” EuroMed Journal of Business, vol. 9, no. 3, pp. 268–292, 2014.
[10] F. P. Morgeson and S. E. Humphrey, “The work design questionnaire (wdq): developing and validating a comprehensive measure for assessing job design and the nature of work.” Journal of applied psychology, vol. 91, no. 6, p. 1321, 2006.
[11] J. R. Idaszak and F. Drasgow, “A revision of the job diagnostic survey: Elimination of a measurement artifact.” Journal of Applied Psychology, vol. 72, no. 1, p. 69, 1987.
[12] M. A. Campion, G. J. Medsker, and A. C. Higgs, “Relations between work group characteristics and effectiveness: Implications for designing effective work groups,” Personnel psychology, vol. 46, no. 4, pp. 823–847, 1993.
[13] T. Hernaus, “Integrating macro-and micro-organizational variables through multilevel approach,” Unpublished doctoral thesis). Zagreb: University of Zagreb, 2010.
[14] S. Wagner and M. Ruhe, “A systematic review of productivity factors in software development,” in Proceedings of 2nd International Workshop on Software Productivity Analysis and Cost Estimation, 2008.
[15] A. N. Meyer, T. Fritz, G. C. Murphy, and T. Zimmermann, “Software developers’ perceptions of productivity,” in Proceedings of the International Symposium on Foundations of Software Engineering. ACM, 2014, pp. 19–29.
[16] R. Antikainen and A. Lönnqvist, “Knowledge work productivity assessment,” Tampere University of Technology, Tech. Rep., 2006.
[17] M. Galesic and M. Bosnjak, “Effects of questionnaire length on participation and indicators of response quality in a web survey,” Public opinion quarterly, vol. 73, no. 2, pp. 349–360, 2009.
[18] L. Beckwith, C. Kissinger, M. Burnett, S. Wiedenbeck, J. Lawrance, A. Blackwell, and C. Cook, “Tinkering and gender in end-user programmers’ debugging,” in Proceedings of the SIGCHI conference on Human Factors in computing systems. ACM, 2006, pp. 231–240.
[19] D. B. Rubin, Multiple imputation for nonresponse in surveys. John Wiley & Sons, 2004, vol. 81.
[20] A. W. Meade and S. B. Craig, “Identifying careless responses in survey data.” Psychological methods, vol. 17, no. 3, p. 437, 2012.
[21] E. Smith, R. Loftin, E. Murphy-Hill, C. Bird, and T. Zimmermann, “Improving developer participation rates in surveys,” in Proceedings of Cooperative and Human Aspects on Software Engineering, 2013.
[22] Y. Benjamini and Y. Hochberg, “Controlling the false discovery rate: a practical and powerful approach to multiple testing,” Journal of the royal statistical society. Series B (Methodological),
pp. 289–300, 1995.
[23] R. A. Guzzo, R. D. Jette, and R. A. Katzell, “The effects of psychologically based intervention programs on worker productivity: A meta-analysis,” Personnel psychology, vol. 38, no. 2, pp.
275–291, 1985.
[24] D. Graziotin, X. Wang, and P. Abrahamsson, “Happy software developers solve problems better: psychological measurements in empirical software engineering,” PeerJ, vol. 2, p. e289, 2014.
[25] J. Noll, M. A. Razzak, and S. Beecham, “Motivation and autonomy in global software development: an empirical study,” in Proceedings of the 21st International Conference on Evaluation
and Assessment in Software Engineering. ACM, 2017, pp. 394–399.
[26] B. Clark, S. Devnani-Chulani, and B. Boehm, “Calibrating the cocomo ii post-architecture model,” in Proceedings of the International Conference on Software Engineering. IEEE, 1998, pp. 477–480.
[27] B. Kitchenham and E. Mendes, “Software productivity measurement using multiple size measures,” IEEE Transactions on Software Engineering, vol. 30, no. 12, pp. 1023–1035, 2004.
[28] S. L. Pfleeger, “Model of software effort and productivity,” Information and Software Technology, vol. 33, no. 3, pp. 224–231, 1991.
[29] G. Finnie and G. Wittig, “Effect of system and team size on 4gl software development productivity,” South African Computer Journal, pp. 18–18, 1994.
[30] D. R. Jeffery, “A software development productivity model for mis environments,” Journal of Systems and Software, vol. 7, no. 2, pp. 115–125, 1987.
[31] L. R. Foulds, M. Quaddus, and M. West, “Structural equation modelling of large-scale information system application development productivity: the hong kong experience,” in Computer and Information Science, 2007. ICIS 2007. 6th IEEE/ACIS International Conference on. IEEE, 2007, pp. 724–731.
[32] C. Parnin and S. Rugaber, “Resumption strategies for interrupted programming tasks,” Software Quality Journal, vol. 19, no. 1, pp. 5–34, 2011.
[33] C. Parnin and R. DeLine, “Evaluating cues for resuming interrupted programming tasks,” in Proceedings of the SIGCHI conference on human factors in computing systems. ACM, 2010, pp. 93–102.
[34] S. Markos and M. S. Sridevi, “Employee engagement: The key to improving performance,” International Journal of Business and Management, vol. 5, no. 12, pp. 89–96, 2010.
[35] W. Snipes, A. R. Nair, and E. Murphy-Hill, “Experiences gamifying developer adoption of practices and tools,” in Companion Proceedings of the 36th International Conference on Software Engineering. ACM, 2014, pp. 105–114.
[36] J. S. Brown and P. Duguid, “Balancing act: How to capture knowledge without killing it.” Harvard business review, vol. 78, no. 3, pp. 73–80, 1999.
[37] M. London and J. W. Smither, “Feedback orientation, feedback culture, and the longitudinal performance management process,” Human Resource Management Review, vol. 12, no. 1,
pp. 81–100, 2002.
[38] T. Savor, M. Douglas, M. Gentili, L. Williams, K. Beck, and M. Stumm, “Continuous deployment at facebook and oanda,” in Proceedings of the 38th International Conference on Software Engineering Companion. ACM, 2016, pp. 21–30.
[39] R. J. Fisher, “Social desirability bias and the validity of indirect questioning,” Journal of consumer research, vol. 20, no. 2, pp. 303–315, 1993.
[40] J. M. Zelenski, S. A. Murphy, and D. A. Jenkins, “The happyproductive worker thesis revisited,” Journal of Happiness Studies, vol. 9, no. 4, pp. 521–537, 2008.
[41] S. Moser and O. Nierstrasz, “The effect of object-oriented frameworks on developer productivity,” Computer, vol. 29, no. 9, pp. 45–51, 1996.
[42] T. DeMarco and T. Lister, “Programmer performance and the effects of the workplace,” in Proceedings of the International Conference on Software Engineering. IEEE Computer Society
Press, 1985, pp. 268–272.
[43] M. Kersten and G. C. Murphy, “Using task context to improve programmer productivity,” in Proceedings of the 14th ACM SIGSOFT international symposium on Foundations of software engineering. ACM, 2006, pp. 1–11.
[44] K. Petersen, “Measuring and predicting software productivity: A systematic map and review,” Information and Software Technology, vol. 53, no. 4, pp. 317–343, 2011.
[45] M. J. Melitz, “The impact of trade on intra-industry reallocations and aggregate industry productivity,” Econometrica, vol. 71, no. 6, pp. 1695–1725, 2003.
[46] M. N. Baily, C. Hulten, D. Campbell, T. Bresnahan, and R. E. Caves, “Productivity dynamics in manufacturing plants,” Brookings papers on economic activity. Microeconomics, vol. 1992, pp. 187–267, 1992.
[47] A. Kidd, “The marks are on the knowledge worker,” in Proceedings of the SIGCHI conference on Human factors in computing systems. ACM, 1994, pp. 186–191.
[48] G. K. Gill and C. F. Kemerer, “Cyclomatic complexity density and software maintenance productivity,” IEEE transactions on software engineering, vol. 17, no. 12, pp. 1284–1288, 1991.
[2] Y. W. Ramírez and D. A. Nembhard, “Measuring knowledge worker productivity: A taxonomy,” Journal of Intellectual Capital, vol. 5, no. 4, pp. 602–628, 2004.
[3] A. N. Meyer, L. E. Barton, G. C. Murphy, T. Zimmermann, and T. Fritz, “The work life of developers: Activities, switches and perceived productivity,” IEEE Transactions on Software Engineering, 2017.
[4] M. Palvalin, M. Vuolle, A. Jääskeläinen, H. Laihonen, and A. Lönnqvist, “Smartwow–constructing a tool for knowledge work performance analysis,” International Journal of Productivity and Performance Management, vol. 64, no. 4, pp. 479–498, 2015.
[5] C. H. C. Duarte, “Productivity paradoxes revisited,” Empirical Software Engineering, pp. 1–30, 2016.
[6] K. D. Maxwell, L. VanWassenhove, and S. Dutta, “Software development productivity of european space, military, and industrial applications,” IEEE Transactions on Software Engineering, vol. 22, no. 10, pp. 706–718, 1996.
[7] J. D. Blackburn, G. D. Scudder, and L. N. Van Wassenhove, “Improving speed and productivity of software development: a global survey of software developers,” IEEE transactions on software engineering, vol. 22, no. 12, pp. 875–885, 1996.
[8] B. Vasilescu, Y. Yu, H.Wang, P. Devanbu, and V. Filkov, “Quality and productivity outcomes relating to continuous integration in github,” in Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering. ACM, 2015, pp. 805–816.
[9] T. Hernaus and J. Mikulic, “Work characteristics and work performance of knowledge workers,” EuroMed Journal of Business, vol. 9, no. 3, pp. 268–292, 2014.
[10] F. P. Morgeson and S. E. Humphrey, “The work design questionnaire (wdq): developing and validating a comprehensive measure for assessing job design and the nature of work.” Journal of applied psychology, vol. 91, no. 6, p. 1321, 2006.
[11] J. R. Idaszak and F. Drasgow, “A revision of the job diagnostic survey: Elimination of a measurement artifact.” Journal of Applied Psychology, vol. 72, no. 1, p. 69, 1987.
[12] M. A. Campion, G. J. Medsker, and A. C. Higgs, “Relations between work group characteristics and effectiveness: Implications for designing effective work groups,” Personnel psychology, vol. 46, no. 4, pp. 823–847, 1993.
[13] T. Hernaus, “Integrating macro-and micro-organizational variables through multilevel approach,” Unpublished doctoral thesis). Zagreb: University of Zagreb, 2010.
[14] S. Wagner and M. Ruhe, “A systematic review of productivity factors in software development,” in Proceedings of 2nd International Workshop on Software Productivity Analysis and Cost Estimation, 2008.
[15] A. N. Meyer, T. Fritz, G. C. Murphy, and T. Zimmermann, “Software developers’ perceptions of productivity,” in Proceedings of the International Symposium on Foundations of Software Engineering. ACM, 2014, pp. 19–29.
[16] R. Antikainen and A. Lönnqvist, “Knowledge work productivity assessment,” Tampere University of Technology, Tech. Rep., 2006.
[17] M. Galesic and M. Bosnjak, “Effects of questionnaire length on participation and indicators of response quality in a web survey,” Public opinion quarterly, vol. 73, no. 2, pp. 349–360, 2009.
[18] L. Beckwith, C. Kissinger, M. Burnett, S. Wiedenbeck, J. Lawrance, A. Blackwell, and C. Cook, “Tinkering and gender in end-user programmers’ debugging,” in Proceedings of the SIGCHI conference on Human Factors in computing systems. ACM, 2006, pp. 231–240.
[19] D. B. Rubin, Multiple imputation for nonresponse in surveys. John Wiley & Sons, 2004, vol. 81.
[20] A. W. Meade and S. B. Craig, “Identifying careless responses in survey data.” Psychological methods, vol. 17, no. 3, p. 437, 2012.
[21] E. Smith, R. Loftin, E. Murphy-Hill, C. Bird, and T. Zimmermann, “Improving developer participation rates in surveys,” in Proceedings of Cooperative and Human Aspects on Software Engineering, 2013.
[22] Y. Benjamini and Y. Hochberg, “Controlling the false discovery rate: a practical and powerful approach to multiple testing,” Journal of the royal statistical society. Series B (Methodological),
pp. 289–300, 1995.
[23] R. A. Guzzo, R. D. Jette, and R. A. Katzell, “The effects of psychologically based intervention programs on worker productivity: A meta-analysis,” Personnel psychology, vol. 38, no. 2, pp.
275–291, 1985.
[24] D. Graziotin, X. Wang, and P. Abrahamsson, “Happy software developers solve problems better: psychological measurements in empirical software engineering,” PeerJ, vol. 2, p. e289, 2014.
[25] J. Noll, M. A. Razzak, and S. Beecham, “Motivation and autonomy in global software development: an empirical study,” in Proceedings of the 21st International Conference on Evaluation
and Assessment in Software Engineering. ACM, 2017, pp. 394–399.
[26] B. Clark, S. Devnani-Chulani, and B. Boehm, “Calibrating the cocomo ii post-architecture model,” in Proceedings of the International Conference on Software Engineering. IEEE, 1998, pp. 477–480.
[27] B. Kitchenham and E. Mendes, “Software productivity measurement using multiple size measures,” IEEE Transactions on Software Engineering, vol. 30, no. 12, pp. 1023–1035, 2004.
[28] S. L. Pfleeger, “Model of software effort and productivity,” Information and Software Technology, vol. 33, no. 3, pp. 224–231, 1991.
[29] G. Finnie and G. Wittig, “Effect of system and team size on 4gl software development productivity,” South African Computer Journal, pp. 18–18, 1994.
[30] D. R. Jeffery, “A software development productivity model for mis environments,” Journal of Systems and Software, vol. 7, no. 2, pp. 115–125, 1987.
[31] L. R. Foulds, M. Quaddus, and M. West, “Structural equation modelling of large-scale information system application development productivity: the hong kong experience,” in Computer and Information Science, 2007. ICIS 2007. 6th IEEE/ACIS International Conference on. IEEE, 2007, pp. 724–731.
[32] C. Parnin and S. Rugaber, “Resumption strategies for interrupted programming tasks,” Software Quality Journal, vol. 19, no. 1, pp. 5–34, 2011.
[33] C. Parnin and R. DeLine, “Evaluating cues for resuming interrupted programming tasks,” in Proceedings of the SIGCHI conference on human factors in computing systems. ACM, 2010, pp. 93–102.
[34] S. Markos and M. S. Sridevi, “Employee engagement: The key to improving performance,” International Journal of Business and Management, vol. 5, no. 12, pp. 89–96, 2010.
[35] W. Snipes, A. R. Nair, and E. Murphy-Hill, “Experiences gamifying developer adoption of practices and tools,” in Companion Proceedings of the 36th International Conference on Software Engineering. ACM, 2014, pp. 105–114.
[36] J. S. Brown and P. Duguid, “Balancing act: How to capture knowledge without killing it.” Harvard business review, vol. 78, no. 3, pp. 73–80, 1999.
[37] M. London and J. W. Smither, “Feedback orientation, feedback culture, and the longitudinal performance management process,” Human Resource Management Review, vol. 12, no. 1,
pp. 81–100, 2002.
[38] T. Savor, M. Douglas, M. Gentili, L. Williams, K. Beck, and M. Stumm, “Continuous deployment at facebook and oanda,” in Proceedings of the 38th International Conference on Software Engineering Companion. ACM, 2016, pp. 21–30.
[39] R. J. Fisher, “Social desirability bias and the validity of indirect questioning,” Journal of consumer research, vol. 20, no. 2, pp. 303–315, 1993.
[40] J. M. Zelenski, S. A. Murphy, and D. A. Jenkins, “The happyproductive worker thesis revisited,” Journal of Happiness Studies, vol. 9, no. 4, pp. 521–537, 2008.
[41] S. Moser and O. Nierstrasz, “The effect of object-oriented frameworks on developer productivity,” Computer, vol. 29, no. 9, pp. 45–51, 1996.
[42] T. DeMarco and T. Lister, “Programmer performance and the effects of the workplace,” in Proceedings of the International Conference on Software Engineering. IEEE Computer Society
Press, 1985, pp. 268–272.
[43] M. Kersten and G. C. Murphy, “Using task context to improve programmer productivity,” in Proceedings of the 14th ACM SIGSOFT international symposium on Foundations of software engineering. ACM, 2006, pp. 1–11.
[44] K. Petersen, “Measuring and predicting software productivity: A systematic map and review,” Information and Software Technology, vol. 53, no. 4, pp. 317–343, 2011.
[45] M. J. Melitz, “The impact of trade on intra-industry reallocations and aggregate industry productivity,” Econometrica, vol. 71, no. 6, pp. 1695–1725, 2003.
[46] M. N. Baily, C. Hulten, D. Campbell, T. Bresnahan, and R. E. Caves, “Productivity dynamics in manufacturing plants,” Brookings papers on economic activity. Microeconomics, vol. 1992, pp. 187–267, 1992.
[47] A. Kidd, “The marks are on the knowledge worker,” in Proceedings of the SIGCHI conference on Human factors in computing systems. ACM, 1994, pp. 186–191.
[48] G. K. Gill and C. F. Kemerer, “Cyclomatic complexity density and software maintenance productivity,” IEEE transactions on software engineering, vol. 17, no. 12, pp. 1284–1288, 1991.