Die Aufgabe, früher oder später IT-Plattformen für die Akkumulation und Analyse von Daten aufzubauen, stellt sich für jedes Unternehmen, dessen Geschäft auf einem intellektuell geladenen Service Delivery-Modell oder der Erstellung technisch komplexer Produkte basiert. Das Erstellen von Analyseplattformen ist eine schwierige und zeitaufwändige Aufgabe. Jede Aufgabe kann jedoch vereinfacht werden. In diesem Artikel möchte ich meine Erfahrungen mit der Verwendung von Low-Code-Tools zur Erstellung analytischer Lösungen teilen. Diese Erfahrung wurde bei der Umsetzung einer Reihe von Projekten in Richtung Big Data Solutions von Neoflex gesammelt. Seit 2005 befasst sich die Big Data Solutions-Leitung von Neoflex mit den Problemen des Aufbaus von Datenspeichern und Seen, der Lösung von Problemen bei der Optimierung der Geschwindigkeit der Informationsverarbeitung und der Erarbeitung einer Methodik zur Verwaltung der Datenqualität.
Niemand wird in der Lage sein, die absichtliche Anhäufung von schwach und / oder stark strukturierten Daten zu vermeiden. Vielleicht sogar, wenn es sich um ein kleines Unternehmen handelt. In der Tat wird ein vielversprechender Unternehmer bei der Skalierung eines Unternehmens mit den Problemen der Entwicklung eines Treueprogramms konfrontiert sein, die Effektivität von Verkaufsstellen analysieren, über gezielte Werbung nachdenken und sich über die Nachfrage nach Begleitprodukten wundern wollen. In erster Näherung kann das Problem am Knie gelöst werden. Mit dem Wachstum eines Unternehmens ist es jedoch immer noch unvermeidlich, auf eine Analyseplattform zuzugreifen.
In welchem Fall können Datenanalyse-Aufgaben jedoch zu Aufgaben der Klasse "Rocket Science" werden? Vielleicht in diesem Moment, wenn es um wirklich große Datenmengen geht.
Um die Rocket Science-Aufgabe zu vereinfachen, können Sie den Elefanten Stück für Stück essen.
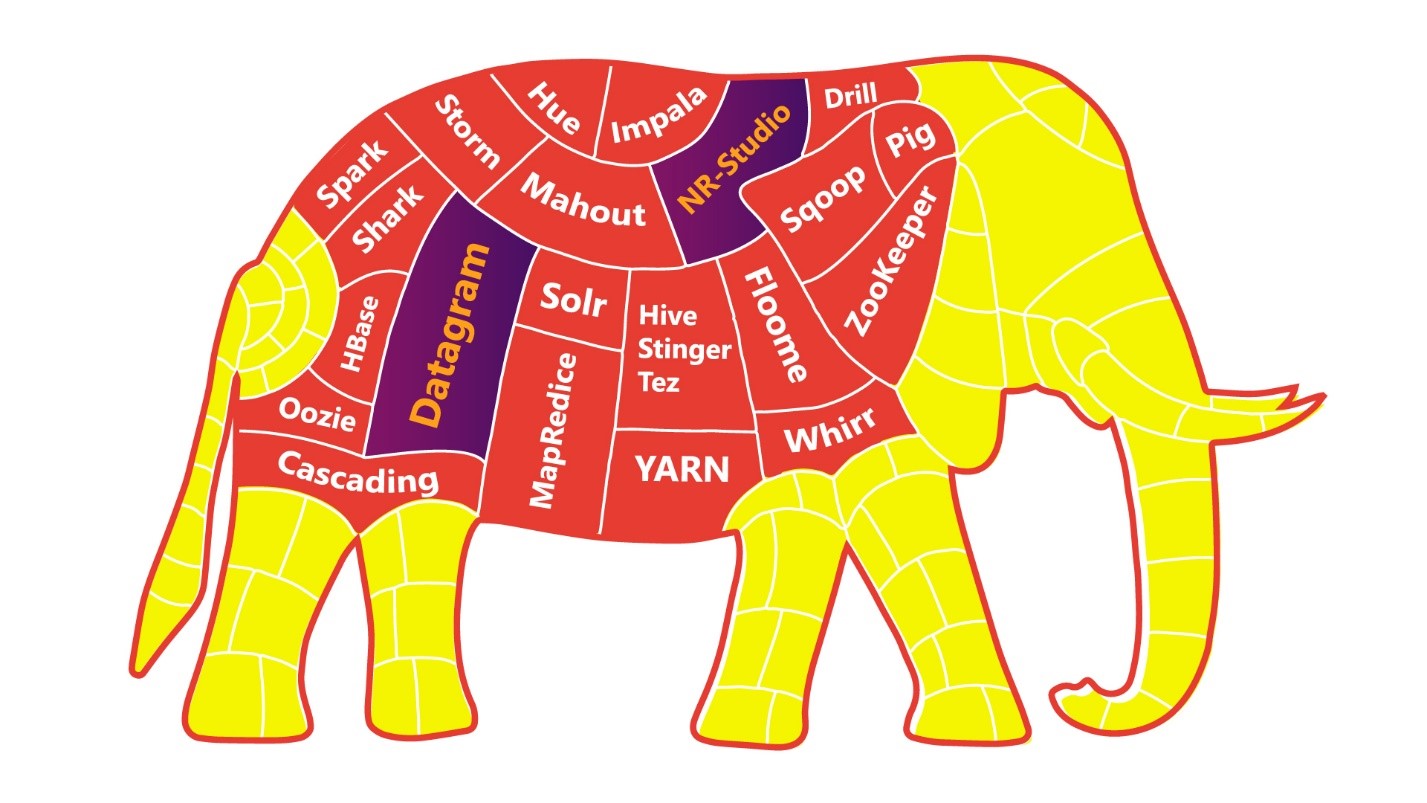
Je mehr Diskretion und Autonomie Ihre Anwendungen / Dienste / Mikrodienste haben, desto einfacher ist es für Sie, Ihre Kollegen und das gesamte Unternehmen, einen Elefanten zu verdauen.
Fast alle unsere Kunden kamen zu diesem Postulat und bauten die Landschaft auf der Grundlage der Konstruktionspraktiken der DevOps-Teams neu auf.
Aber selbst bei einer "Split-Elephant" -Diät haben wir gute Chancen auf eine "Übersättigung" der IT-Landschaft. An dieser Stelle lohnt es sich anzuhalten, auszuatmen und auf die Low-Code-Engineering-Plattform zu schauen .
Viele Entwickler sind von der Aussicht auf eine Sackgasse in ihrer Karriere eingeschüchtert, wenn sie vom direkten Schreiben von Code zum "Ziehen und Ablegen" von Pfeilen in UI-Schnittstellen von Low-Code-Systemen übergehen. Das Erscheinen von Werkzeugmaschinen führte jedoch nicht zum Verschwinden der Ingenieure, sondern brachte ihre Arbeit auf ein neues Niveau!
Lassen Sie uns herausfinden, warum.
Die Analyse von Daten im Bereich der Logistik, der Telekommunikationsindustrie, im Bereich der Medienforschung und des Finanzsektors ist immer mit folgenden Fragen verbunden:
- Automatisierte Analysegeschwindigkeit;
- Die Fähigkeit, Experimente durchzuführen, ohne den Hauptfluss der Datenproduktion zu beeinträchtigen;
- Die Zuverlässigkeit der vorbereiteten Daten;
- Verfolgung von Änderungen und Versionierung;
- Datenprovenienz, Datenherkunft, CDC;
- Schnelle Bereitstellung neuer Funktionen für die Produktionsumgebung;
- Und das Sprichwort: Entwicklungs- und Supportkosten.
Das heißt, Ingenieure haben eine große Anzahl von Aufgaben auf hoher Ebene, die nur dann mit ausreichender Effizienz ausgeführt werden können, wenn sie sich von Entwicklungsaufgaben auf niedriger Ebene befreien.
Die Entwicklung und Digitalisierung des Geschäfts wurde zur Voraussetzung für den Übergang der Entwickler auf eine neue Ebene. Der Wert der Entwickler ändert sich ebenfalls: Es gibt einen erheblichen Mangel an Entwicklern, die tief in die Konzepte der Automatisierung des Geschäfts eintauchen können.
Machen wir eine Analogie mit Programmiersprachen auf niedriger und hoher Ebene. Der Übergang von Niedrigsprachen zu Hochsprachen ist ein Übergang vom Schreiben von "Direktiven in der Sprache des Eisens" zu "Direktiven in der Sprache der Menschen". Das heißt, eine gewisse Abstraktionsebene hinzufügen. In diesem Fall ist der Übergang von High-Level-Programmiersprachen zu Low-Code-Plattformen ein Übergang von „Direktiven in der Sprache der Menschen“ zu „Direktiven in der Sprache der Unternehmen“. Wenn es Entwickler gibt, die von dieser Tatsache traurig sind, dann sind sie traurig, vielleicht sogar von dem Moment an, als Java Script geboren wurde, das Array-Sortierfunktionen verwendet. Und diese Funktionen haben natürlich eine Software-Implementierung unter der Haube durch andere Mittel der gleichen High-Level-Programmierung.
Low-Code ist daher nur die Entstehung einer weiteren Abstraktionsebene.
Angewandte Erfahrung im Umgang mit Low-Code
Das Thema Low-Code ist ziemlich weit gefasst, aber jetzt möchte ich am Beispiel eines unserer Projekte über die angewandte Anwendung von "Low-Code-Konzepten" sprechen.
Der Geschäftsbereich Big Data Solutions von Neoflex ist stärker auf den Finanzsektor spezialisiert, baut Speicher- und Datenseen und automatisiert verschiedene Berichte. In dieser Nische ist die Verwendung von Low-Code längst zum Standard geworden. Andere Low-Code-Tools umfassen Tools zum Organisieren von ETL-Prozessen: Informatica Power Center, IBM Datastage, Pentaho Data Integration. Oder Oracle Apex, das als Umgebung für die schnelle Entwicklung von Schnittstellen für den Zugriff auf und die Bearbeitung von Daten dient. Die Verwendung von Low-Code-Entwicklungstools ist jedoch nicht immer mit der Erstellung zielgerichteter Anwendungen auf einem kommerziellen Technologie-Stack mit einer klaren Lieferantenabhängigkeit verbunden.
Mithilfe von Low-Code-Plattformen können Sie auch die Orchestrierung von Datenströmen organisieren, Data-Science-Plattformen erstellen oder beispielsweise Datenqualitätskontrollmodule erstellen.
Eines der angewandten Beispiele für die Erfahrung mit Low-Code-Entwicklungstools ist die Zusammenarbeit zwischen Neoflex und Mediascope, einem der führenden Unternehmen auf dem russischen Markt für Medienforschung. Eines der Geschäftsziele dieses Unternehmens ist die Erstellung von Daten, auf deren Grundlage Werbetreibende, Internetseiten, Fernsehkanäle, Radiosender, Werbeagenturen und Marken beschließen, Werbung zu kaufen und ihre Marketingkommunikation zu planen.

Medienforschung ist ein technologieintensives Geschäftsfeld. Erkennen von Videosequenzen, Sammeln von Daten von Geräten, die das Anzeigen analysieren, Messen der Aktivität auf Webressourcen - all dies setzt voraus, dass ein Unternehmen über ein großes IT-Personal und eine enorme Erfahrung beim Erstellen von Analyselösungen verfügt. Das exponentielle Wachstum der Informationsmenge, der Anzahl und Vielfalt ihrer Quellen lässt die IT-Datenbranche jedoch ständig Fortschritte machen. Die einfachste Lösung zur Skalierung der bereits funktionierenden Analyseplattform Mediascope könnte eine Aufstockung des IT-Personals sein. Eine viel effizientere Lösung besteht jedoch darin, den Entwicklungsprozess zu beschleunigen. Einer der Schritte in diese Richtung kann die Verwendung von Low-Code-Plattformen sein.
Zum Zeitpunkt des Projektstarts verfügte das Unternehmen bereits über eine funktionierende Produktlösung. Die Implementierung der Lösung in MSSQL konnte jedoch die Erwartungen an die Skalierung der Funktionalität unter Beibehaltung akzeptabler Revisionskosten nicht vollständig erfüllen.
Die vor uns liegende Aufgabe war wirklich ehrgeizig: Neoflex und Mediascope mussten in weniger als einem Jahr eine industrielle Lösung entwickeln, vorausgesetzt, der MVP wurde innerhalb des ersten Quartals ab dem Datum des Arbeitsbeginns veröffentlicht.
Der Hadoop-Technologie-Stack wurde als Grundlage für den Aufbau einer neuen Datenplattform auf der Basis von Low-Code-Computing ausgewählt. HDFS ist zum Standard für die Datenspeicherung mit Parkettdateien geworden. Für den Zugriff auf die Daten auf der Plattform wurde Hive verwendet, in dem alle verfügbaren Storefronts als externe Tabellen dargestellt werden. Das Laden von Daten in den Speicher wurde mit Kafka und Apache NiFi implementiert.
Das Low-Code-Tool in diesem Konzept wurde verwendet, um die arbeitsintensivste Aufgabe beim Aufbau einer Analyseplattform zu optimieren - die Aufgabe der Datenberechnung.

Das Low-Code-Datagramm-Tool wurde als Hauptmechanismus für die Datenzuordnung ausgewählt. Neoflex Datagram ist ein Tool zum Entwerfen von Transformationen und Datenströmen.
Mit diesem Tool können Sie vermeiden, Scala-Code "von Hand" zu schreiben. Scala-Code wird automatisch mithilfe des Ansatzes der modellgesteuerten Architektur generiert.
Ein offensichtliches Plus dieses Ansatzes ist die Beschleunigung des Entwicklungsprozesses. Neben der Geschwindigkeit gibt es jedoch auch folgende Vorteile:
- Inhalt und Struktur von Quellen / Zielen anzeigen;
- Verfolgung des Ursprungs von Datenflussobjekten zu einzelnen Feldern (Abstammung);
- Teilausführung von Transformationen mit Anzeige von Zwischenergebnissen;
- Anzeigen des Quellcodes und Korrigieren vor der Ausführung;
- Automatische Validierung von Transformationen;
- Automatisches Laden von Daten 1 in 1.
Der Schwellenwert für die Eingabe von Low-Code-Lösungen zum Generieren von Transformationen ist recht niedrig: Der Entwickler muss SQL kennen und Erfahrung mit ETL-Tools haben. Es ist zu beachten, dass codegesteuerte Transformationsgeneratoren keine ETL-Tools im weiteren Sinne des Wortes sind. Low-Code-Tools verfügen möglicherweise nicht über eine eigene Code-Ausführungsumgebung. Das heißt, der generierte Code wird in der Umgebung ausgeführt, die sich bereits vor der Installation der Low-Code-Lösung im Cluster befand. Und dies ist vielleicht ein weiteres Plus im Low-Code-Karma. Da parallel zum Low-Code-Befehl ein „klassischer“ Befehl funktionieren kann, der die Funktionalität beispielsweise in reinem Scala-Code implementiert. Die Arbeit beider Teams in die Produktion zu bringen, wird einfach und nahtlos sein.
Vielleicht ist es erwähnenswert, dass es neben Low-Code auch No-Code-Lösungen gibt. Und in ihrem Wesen sind sie verschiedene Dinge. Mit Low-Code kann der Entwickler den generierten Code stärker stören. Im Fall von Datagram ist es möglich, den generierten Scala-Code anzuzeigen und zu bearbeiten. Kein Code bietet möglicherweise keine solche Möglichkeit. Dieser Unterschied ist nicht nur in Bezug auf die Lösungsflexibilität von großer Bedeutung, sondern auch in Bezug auf Komfort und Motivation bei der Arbeit von Dateningenieuren.
Lösungsarchitektur
Versuchen wir herauszufinden, wie genau ein Low-Code-Tool zur Lösung des Problems der Optimierung der Entwicklungsgeschwindigkeit der Datenberechnungsfunktion beiträgt. Schauen wir uns zunächst die funktionale Architektur des Systems an. Ein Beispiel ist in diesem Fall das Datenproduktionsmodell für die Medienforschung.

Datenquellen sind in unserem Fall sehr heterogen und vielfältig:
- (-) — - , – , , . – . Data Lake , , , . , , ;
- ;
- web-, site-centric, user-centric . Data Lake research bar VPN.
- , - ;
- -.
Die Implementierung des Ladens von Quellsystemen in das primäre Staging von Rohdaten kann auf verschiedene Arten organisiert werden. Wenn für diese Zwecke Low-Code verwendet wird, können automatisch Boot-Skripte basierend auf Metadaten generiert werden. In diesem Fall ist es nicht erforderlich, den Entwicklungsstand der Quelle für die Zielzuordnungen zu bestimmen. Um das automatische Laden zu implementieren, müssen wir eine Verbindung mit der Quelle herstellen und dann in der Ladeschnittstelle eine Liste der zu ladenden Entitäten definieren. Die Erstellung der Verzeichnisstruktur in HDFS erfolgt automatisch und entspricht der Datenspeicherstruktur im Quellsystem.
Im Rahmen dieses Projekts haben wir uns jedoch entschieden, diese Gelegenheit der Low-Code-Plattform nicht zu nutzen, da Mediascope bereits unabhängig mit der Produktion eines ähnlichen Dienstes für die Nifi + Kafka-Verbindung begonnen hat.
Es ist sofort zu beachten, dass diese Werkzeuge nicht austauschbar sind, sondern sich gegenseitig ergänzen. Nifi und Kafka können sowohl in direkten (Nifi -> Kafka) als auch in umgekehrten (Kafka -> Nifi) Bündeln arbeiten. Für die Medienforschungsplattform wurde der erste Link verwendet.

In unserem Fall musste ich verschiedene Arten von Daten aus Quellsystemen verarbeiten und an den Kafka-Broker senden. Gleichzeitig wurde die Richtung der Nachrichten zu einem bestimmten Kafka-Thema mithilfe der PublishKafka Nifi-Prozessoren ausgeführt. Die Orchestrierung und Wartung dieser Pipelines erfolgt über eine visuelle Oberfläche. Das Nifi-Tool und die Verwendung des Nifi + Kafka-Bundles können auch als Low-Code-Entwicklungsansatz bezeichnet werden, der einen niedrigen Schwellenwert für den Einstieg in Big Data-Technologien aufweist und den Anwendungsentwicklungsprozess beschleunigt.
Die nächste Stufe bei der Umsetzung des Projekts war die Reduktion auf das Format einer einzelnen semantischen Schicht detaillierter Daten. Wenn eine Entität historische Attribute hat, wird die Berechnung im Kontext der betreffenden Partition durchgeführt. Wenn die Entität nicht historisch ist, ist es optional möglich, entweder den gesamten Inhalt des Objekts neu zu berechnen oder die Neuberechnung dieses Objekts überhaupt abzulehnen (da keine Änderungen vorgenommen wurden). Zu diesem Zeitpunkt werden Schlüssel für alle Entitäten generiert. Die Schlüssel werden in den Hbase-Verzeichnissen gespeichert, die den Master-Objekten entsprechen und die Entsprechung zwischen den Schlüsseln in der Analyseplattform und den Schlüsseln aus den Quellsystemen enthalten. Die Konsolidierung atomarer Einheiten geht mit einer Anreicherung mit den Ergebnissen der vorläufigen Berechnung der Analysedaten einher. Der Rahmen für die Datenberechnung war Spark.Die beschriebene Funktionalität zum Konvertieren von Daten in eine einzelne Semantik wurde ebenfalls auf der Grundlage von Zuordnungen des Low-Code-Tools Datagram implementiert.
Die Zielarchitektur erforderte die Bereitstellung des SQL-Datenzugriffs für Geschäftsbenutzer. Hive wurde für diese Option verwendet. Objekte werden automatisch in Hive registriert, wenn die Option „Hive-Tabelle registrieren“ im Low-Code-Instrument aktiviert ist.

Zahlungsflusskontrolle
Datagram verfügt über eine Schnittstelle zum Erstellen von Workflow-Designs. Zuordnungen können mit dem Oozie-Scheduler gestartet werden. In der Schnittstelle des Entwicklers von Streams ist es möglich, Schemata parallel, sequentiell oder abhängig von den angegebenen Bedingungen für die Ausführung von Datentransformationen zu erstellen. Shell-Skripte und Java-Programme werden unterstützt. Es ist auch möglich, den Apache Livy-Server zu verwenden. Apache Livy wird verwendet, um Anwendungen direkt aus der Entwicklungsumgebung auszuführen.
Wenn das Unternehmen bereits über einen eigenen Prozess-Orchestrator verfügt, können Sie mithilfe der REST-API Zuordnungen in einen vorhandenen Stream einbetten. Zum Beispiel hatten wir eine ziemlich erfolgreiche Erfahrung mit der Einbettung von Scala-Mappings in Orchestratoren, die in PLSQL und Kotlin geschrieben wurden. Die REST-API eines Low-Code-Tools impliziert das Vorhandensein von Vorgängen wie das Generieren eines ausführbaren Jahres basierend auf dem Mapping-Design, das Aufrufen eines Mappings, das Aufrufen einer Folge von Mappings und natürlich das Übergeben von Parametern an die URL zum Starten von Mappings.
Zusammen mit Oozie ist es möglich, einen Berechnungsfluss mit Airflow zu organisieren. Vielleicht werde ich mich nicht lange mit dem Vergleich von Oozie und Airflow befassen, aber ich werde einfach sagen, dass im Rahmen der Arbeit an einem Medienforschungsprojekt die Wahl auf Airflow fiel. Die Hauptargumente waren diesmal eine aktivere Community, die das Produkt entwickelt, und eine weiterentwickelte Schnittstelle + API.
Der Luftstrom ist auch gut, weil er den geliebten Python verwendet, um die Berechnungsprozesse zu beschreiben. Im Allgemeinen gibt es nicht so viele Open Source-Workflow-Management-Plattformen. Das Starten und Überwachen der Ausführung von Prozessen (einschließlich solcher mit einem Gantt-Diagramm) fügt dem Karma von Airflow nur Punkte hinzu.
Das Format der Konfigurationsdatei zum Ausführen von Low-Code-Lösungszuordnungen ist Spark-Submit. Dies geschah aus zwei Gründen. Erstens können Sie mit spark-submit die JAR-Datei direkt von der Konsole aus ausführen. Zweitens kann es alle Informationen enthalten, die Sie zum Konfigurieren des Workflows benötigen (was das Schreiben von Skripten, die den Dag bilden, erleichtert).
Das in unserem Fall am häufigsten verwendete Element des Airflow-Workflows ist der SparkSubmitOperator.
Mit SparkSubmitOperator können Sie jar`niks - gepackte Datagram-Zuordnungen mit vorgeformten Eingabeparametern für diese ausführen.
Es sollte erwähnt werden, dass jede Airflow-Aufgabe in einem separaten Thread ausgeführt wird und nichts über die anderen Aufgaben weiß. In diesem Zusammenhang wird die Interaktion zwischen Aufgaben mit Steuerungsoperatoren wie DummyOperator oder BranchPythonOperator ausgeführt.
Insgesamt hat die Verwendung der Low-Code-Lösung von Datagram in Verbindung mit der Universalisierung von Konfigurationsdateien (Bildung von Dag) zu einer erheblichen Beschleunigung und Vereinfachung des Prozesses der Entwicklung von Daten-Download-Streams geführt.
Showcase-Berechnung
Die vielleicht intelligenteste Phase bei der Erstellung von Analysedaten ist der Schritt zum Aufbau der Storefront. Im Rahmen eines der Datenflüsse des Forschungsunternehmens erfolgt derzeit eine Umstellung auf eine Referenzsendung unter Berücksichtigung der Korrektur für Zeitzonen in Bezug auf das Rundfunknetz. Es ist auch möglich, das lokale Rundfunknetz (lokale Nachrichten und Werbung) anzupassen. In diesem Schritt werden unter anderem die kontinuierlichen Betrachtungsintervalle von Medienprodukten anhand der Analyse der Betrachtungsintervalle aufgeschlüsselt. Sofort werden die Betrachtungswerte anhand von Informationen über ihre Signifikanz "gewichtet" (Berechnung des Korrekturfaktors).

Die Datenvalidierung ist ein separater Schritt bei der Vorbereitung von Data Marts. Der Validierungsalgorithmus verwendet eine Reihe mathematisch-wissenschaftlicher Modelle. Durch die Verwendung einer Low-Code-Plattform kann ein komplexer Algorithmus jedoch in mehrere separate, visuell lesbare Zuordnungen unterteilt werden. Jede der Zuordnungen führt eine enge Aufgabe aus. Dadurch ist ein zwischenzeitliches Debuggen, Protokollieren und Visualisieren von Datenvorbereitungsphasen möglich.
Es wurde beschlossen, den Validierungsalgorithmus in die folgenden Teilstufen zu diskretisieren:
- Zeichnen von Regressionen von Abhängigkeiten beim Ansehen eines Fernsehsenders in einer Region, wobei alle Netze in der Region 60 Tage lang angesehen werden.
- Berechnung der studentisierten Residuen (Abweichungen der tatsächlichen Werte von den vom Regressionsmodell vorhergesagten) für alle Regressionspunkte und für den berechneten Tag.
- Eine Stichprobe abnormaler Region-Netzwerk-Paare, bei denen der studentisierte Rest des geschätzten Tages die Norm überschreitet (angegeben durch die Betriebseinstellung).
- Neuberechnung des korrigierten studentisierten Restes für anomale Region-Netzwerk-Paare für jeden Befragten, der das Netzwerk in der Region mit der Bestimmung des Beitrags dieses Befragten (des Werts der Änderung des studentisierten Restes) betrachtet hat, als dieser Befragte aus der Stichprobe ausgeschlossen wurde.
- Suche nach Kandidaten, deren Ausschluss den studentisierten Saldo des Abrechnungstages wieder normalisiert.
Das obige Beispiel bestätigt die Hypothese, dass ein Dateningenieur sowieso zu viel im Kopf haben sollte ... Und wenn dies wirklich ein "Ingenieur" ist, kein "Codierer", dann die Angst vor einer professionellen Verschlechterung bei der Verwendung von Low-Code-Tools er muss sich endlich zurückziehen.
Was kann Low-Code noch tun?
Der Umfang eines Low-Code-Tools zum Stapeln und Streamen von Daten ohne manuelles Schreiben von Scala-Code endet hier nicht.
Die Verwendung von Low-Code bei der Entwicklung von Datenkuchen ist für uns bereits zum Standard geworden. Vielleicht können wir sagen, dass Lösungen auf dem Hadoop-Stack dem Entwicklungspfad des klassischen DWH auf Basis von RDBMS folgen. Low-Code-Tools auf dem Hadoop-Stack können sowohl Datenverarbeitungsaufgaben als auch Aufgaben zum Erstellen endgültiger BI-Schnittstellen lösen. Darüber hinaus sollte beachtet werden, dass BI nicht nur die Darstellung von Daten bedeuten kann, sondern auch deren Bearbeitung durch die Kräfte der Geschäftsbenutzer. Wir verwenden diese Funktionalität häufig beim Aufbau von Analyseplattformen für den Finanzsektor.

Unter anderem mit Low-Code und insbesondere Datagram ist es möglich, das Problem der Rückverfolgung des Ursprungs von Datenflussobjekten mit Atomizität auf einzelne Felder (Abstammungslinie) zu lösen. Zu diesem Zweck implementiert das Low-Code-Tool eine Schnittstelle mit Apache Atlas und Cloudera Navigator. Tatsächlich muss der Entwickler eine Reihe von Objekten in den Atlas-Wörterbüchern registrieren und beim Erstellen von Zuordnungen auf die registrierten Objekte verweisen. Der Mechanismus zum Verfolgen des Datenursprungs oder zum Analysieren der Abhängigkeiten von Objekten spart viel Zeit, wenn Verbesserungen an den Berechnungsalgorithmen erforderlich sind. Mit dieser Funktion können Sie beispielsweise bei der Erstellung von Abschlüssen die Zeit der Gesetzesänderungen bequemer überstehen. Denn je besser wir die Abhängigkeit zwischen den Formen im Kontext der Objekte der detaillierten Ebene verstehen, desto besser.desto weniger werden wir auf "plötzliche" Mängel stoßen und die Anzahl der Nacharbeiten reduzieren.

Datenqualität & Low-Code
Eine weitere Aufgabe, die vom Low-Code-Tool im Mediascope-Projekt implementiert wird, ist die Aufgabe der Data Quality-Klasse. Die Besonderheit bei der Implementierung der Datenverifizierungspipeline für das Projekt des Forschungsunternehmens war die mangelnde Auswirkung auf die Leistung und Geschwindigkeit des Hauptdatenflusses. Der bekannte Apache Airflow wurde verwendet, um die Orchestrierung der Datenvalidierung durch unabhängige Threads zu ermöglichen. Als jeder Schritt der Datenproduktion fertig war, wurde parallel ein separater Teil der DQ-Pipeline gestartet.
Es wird empfohlen, die Qualität der Daten von Anfang an auf der Analyseplattform zu überwachen. Mit Informationen zu den Metadaten können wir ab dem Moment, in dem die Informationen in die primäre Ebene gelangen, überprüfen, ob die Grundbedingungen erfüllt sind - nicht Null, Einschränkungen, Fremdschlüssel. Diese Funktionalität wird basierend auf automatisch generierten Zuordnungen der Datenqualitätsfamilie in Datagram implementiert. Die Codegenerierung basiert in diesem Fall auch auf Modellmetadaten. Im Mediascope-Projekt wurde die Schnittstelle mit den Metadaten des Enterprise Architect-Produkts ausgeführt.
Durch das Koppeln des Low-Code-Tools und Enterprise Architect wurden die folgenden Überprüfungen automatisch generiert:
- Überprüfen des Vorhandenseins von "Null" -Werten in Feldern mit dem Modifikator "Nicht Null";
- Überprüfen, ob Duplikate des Primärschlüssels vorhanden sind;
- Fremdschlüsselüberprüfung der Entität;
- Überprüfen der Eindeutigkeit einer Zeichenfolge anhand einer Reihe von Feldern.
Für komplexere Datenverfügbarkeits- und Gültigkeitsprüfungen wurde eine Scala Expression-Zuordnung erstellt, die einen externen Spark SQL-Prüfcode akzeptiert, der von Analysten in Zeppelin erstellt wurde.

Natürlich ist es notwendig, schrittweise zur automatischen Generierung von Schecks zu gelangen. Im Rahmen des beschriebenen Projekts gingen folgende Schritte voraus:
- DQ in Zeppelin-Notebooks implementiert;
- DQ eingebautes Mapping;
- DQ in Form von separaten massiven Zuordnungen, die eine ganze Reihe von Prüfungen für eine bestimmte Entität enthalten;
- Universelle parametrisierte DQ-Zuordnungen, die Metadaten und Geschäftsvalidierungsinformationen als Eingabe akzeptieren.
Möglicherweise liegt der Hauptvorteil der Erstellung eines Dienstes für parametrisierte Prüfungen in der Verkürzung der Lieferzeit der Funktionalität für die Produktionsumgebung. Neue Qualitätsprüfungen können das klassische Muster der indirekten Bereitstellung von Code in Entwicklungs- und Testumgebungen umgehen:
- Alle Metadatenprüfungen werden automatisch generiert, wenn sich das Modell in EA ändert.
- Datenverfügbarkeitsprüfungen (Bestimmen des Vorhandenseins von Daten zu einem bestimmten Zeitpunkt) können basierend auf einem Verzeichnis generiert werden, in dem der erwartete Zeitpunkt für das Erscheinen des nächsten Datenelements im Kontext von Objekten gespeichert ist.
- Die Validierung von Geschäftsdaten wird von Analysten in Zeppelin-Notebooks erstellt. Von dort gelangen sie direkt zu den DQ-Modul-Setup-Tabellen in der Produktionsumgebung.
Es besteht kein Risiko des direkten Versands von Skripten an die Produktion als solche. Selbst bei einem Syntaxfehler besteht das Maximum, das uns bedroht, darin, dass keine Prüfung durchgeführt wird, da der Datenflussberechnungsfluss und der Ablauf der Startqualitätsprüfungen voneinander getrennt sind.
Tatsächlich wird der DQ-Dienst permanent in der Produktionsumgebung ausgeführt und ist bereit, seine Arbeit aufzunehmen, wenn die nächsten Daten angezeigt werden.
Anstelle einer Schlussfolgerung
Der Vorteil der Verwendung von Low-Code liegt auf der Hand. Entwickler müssen eine Anwendung nicht von Grund auf neu entwickeln. Ein Programmierer, der von zusätzlichen Aufgaben befreit ist, liefert schneller Ergebnisse. Die Geschwindigkeit wiederum spart zusätzliche Zeit, um Optimierungsprobleme zu lösen. In diesem Fall können Sie sich daher auf eine bessere und schnellere Lösung verlassen.
Low-Code ist natürlich kein Allheilmittel, und Magie wird nicht von alleine geschehen:
- Die Low-Code-Industrie befindet sich in einer Phase des "Wachstums", und bisher gibt es keine einheitlichen Industriestandards.
- Viele Low-Code-Lösungen sind nicht kostenlos, und der Kauf sollte ein bewusster Schritt sein, der mit vollem Vertrauen in die finanziellen Vorteile ihrer Verwendung erfolgen sollte.
- GIT / SVN. ;
- – , , « » low-code-.
- , low-code-. . / IT- .

Wenn Sie jedoch alle Mängel des gewählten Systems kennen und die Vorteile seiner Verwendung dennoch in der überwiegenden Mehrheit liegen, gehen Sie ohne Angst zum kleinen Code. Darüber hinaus ist der Übergang dorthin unvermeidlich - da jede Entwicklung unvermeidlich ist.
Wenn ein Entwickler auf einer Low-Code-Plattform seine Arbeit schneller erledigen kann als zwei Entwickler ohne Low-Code, hat das Unternehmen in jeder Hinsicht einen Vorsprung. Die Schwelle für die Eingabe von Low-Code-Lösungen ist niedriger als bei "traditionellen" Technologien, was sich positiv auf das Problem des Personalmangels auswirkt. Bei Verwendung von Low-Code-Tools ist es möglich, die Interaktion zwischen Funktionsteams zu beschleunigen und schnellere Entscheidungen über die Richtigkeit des gewählten datenwissenschaftlichen Forschungspfads zu treffen. Low-Level-Plattformen können die digitale Transformation eines Unternehmens vorantreiben, da die erstellten Lösungen von nichttechnischen Spezialisten (insbesondere Geschäftsanwendern) verstanden werden können.
Wenn Sie eine enge Frist, eine geschäftige Geschäftslogik, einen Mangel an technologischem Fachwissen haben und die Markteinführungszeit verkürzen müssen, ist Low-Code eine der Möglichkeiten, Ihre Anforderungen zu erfüllen.
Es ist nicht zu leugnen, wie wichtig traditionelle Entwicklungstools sind, aber in vielen Fällen ist die Verwendung von Low-Code-Lösungen der beste Weg, um die Effizienz der zu lösenden Probleme zu verbessern.