Ich setze meine Geschichte fort, wie man Exchange- und ELK-Freunde findet ( hier beginnen ). Ich möchte Sie daran erinnern, dass diese Kombination ohne zu zögern eine sehr große Anzahl von Protokollen verarbeiten kann. Dieses Mal werden wir darüber sprechen, wie Exchange mit den Komponenten Logstash und Kibana funktioniert.
Logstash im ELK-Stack wird verwendet, um Protokolle intelligent zu verarbeiten und für die Platzierung in Elastic in Form von Dokumenten vorzubereiten, auf deren Grundlage verschiedene Visualisierungen in Kibana erstellt werden können.
Installation
Besteht aus zwei Stufen:
- Installieren und Konfigurieren des OpenJDK-Pakets.
- Installieren und Konfigurieren des Logstash-Pakets.
Installieren und Konfigurieren des OpenJDK-
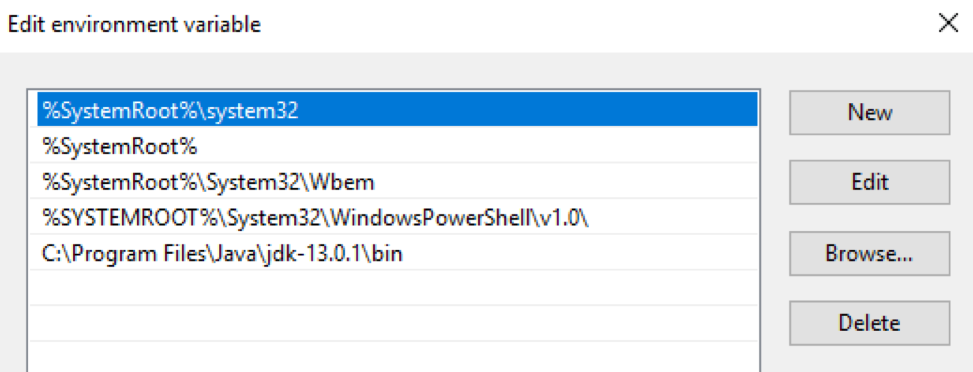
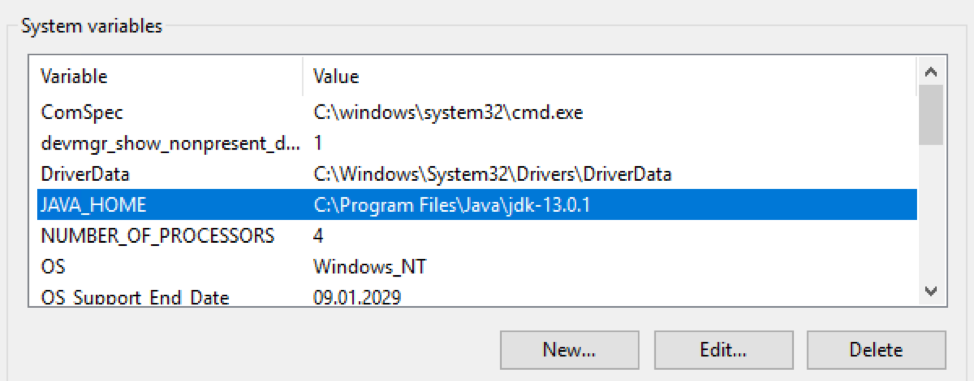
Pakets Das OpenJDK- Paket muss heruntergeladen und in ein bestimmtes Verzeichnis entpackt werden. Dann muss der Pfad zu diesem Verzeichnis in die Variablen $ env: Path und $ env: JAVA_HOME des Windows-Betriebssystems eingegeben werden:
Überprüfen Sie die Java-Version:
PS C:\> java -version
openjdk version "13.0.1" 2019-10-15
OpenJDK Runtime Environment (build 13.0.1+9)
OpenJDK 64-Bit Server VM (build 13.0.1+9, mixed mode, sharing)
Installieren und Konfigurieren des Logstash-Pakets
Laden Sie die Archivdatei mit der Logstash Verteilung von hier . Das Archiv muss im Stammverzeichnis der Festplatte entpackt werden.
C:\Program FilesSie sollten es nicht in einen Ordner entpacken, da Logstash den normalen Start verweigert. Anschließend müssen Sie jvm.optionsÄnderungen an der Datei vornehmen , die für die Zuweisung von RAM für den Java-Prozess verantwortlich sind. Ich empfehle, die Hälfte des Arbeitsspeichers des Servers anzugeben. Wenn er 16 GB RAM an Bord hat, sind die Standardschlüssel:
-Xms1g
-Xmx1g
muss ersetzt werden durch:
-Xms8g
-Xmx8g
Darüber hinaus ist es ratsam, die Zeile auskommentieren
-XX:+UseConcMarkSweepGC. Lesen Sie mehr dazu hier . Der nächste Schritt besteht darin, eine Standardkonfiguration in der Datei logstash.conf zu erstellen:
input {
stdin{}
}
filter {
}
output {
stdout {
codec => "rubydebug"
}
}
Bei dieser Konfiguration liest Logstash Daten von der Konsole, leitet sie durch einen leeren Filter und druckt sie zurück an die Konsole. Durch Anwenden dieser Konfiguration wird die Funktionalität von Logstash getestet. Führen Sie es dazu interaktiv aus:
PS C:\...\bin> .\logstash.bat -f .\logstash.conf
...
[2019-12-19T11:15:27,769][INFO ][logstash.javapipeline ][main] Pipeline started {"pipeline.id"=>"main"}
The stdin plugin is now waiting for input:
[2019-12-19T11:15:27,847][INFO ][logstash.agent ] Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
[2019-12-19T11:15:28,113][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
Logstash wurde erfolgreich auf Port 9600 gestartet.
Der letzte Schritt der Installation besteht darin, Logstash als Windows-Dienst zu starten. Dies kann beispielsweise mit dem NSSM- Paket erfolgen :
PS C:\...\bin> .\nssm.exe install logstash
Service "logstash" installed successfully!
Fehlertoleranz
Der Mechanismus für persistente Warteschlangen gewährleistet die Sicherheit von Protokollen während der Übertragung vom Quellserver.
Wie funktioniert es
Das Layout der Warteschlangen während der Protokollverarbeitung: Eingabe → Warteschlange → Filter + Ausgabe.
Das Eingabe-Plugin empfängt Daten von der Protokollquelle, schreibt sie in die Warteschlange und sendet eine Bestätigung des Empfangs der Daten an die Quelle.
Nachrichten aus der Warteschlange werden von Logstash verarbeitet, übergeben den Filter und das Ausgabe-Plugin. Nach Erhalt der Bestätigung von der Ausgabe zum Senden des Protokolls entfernt Logstash das verarbeitete Protokoll aus der Warteschlange. Wenn Logstash gestoppt wird, bleiben alle unverarbeiteten Nachrichten und Nachrichten, die keine Bestätigung des Sendens erhalten haben, in der Warteschlange, und Logstash verarbeitet sie beim nächsten Start weiter.
Anpassung
Reguliert durch Schlüssel in der Datei
C:\Logstash\config\logstash.yml:
queue.type: (mögliche Werte sindpersistedundmemory (default)).path.queue: (Pfad zum Ordner mit Warteschlangendateien, die standardmäßig in C: \ Logstash \ queue gespeichert sind).queue.page_capacity: (Die maximale Seitengröße der Warteschlange, die Standardeinstellung ist 64 MB).queue.drain: (true / false - Aktiviert / Deaktiviert das Stoppen der Warteschlangenverarbeitung vor dem Deaktivieren von Logstash. Ich empfehle das Aktivieren nicht, da dies die Geschwindigkeit beim Herunterfahren des Servers direkt beeinflusst.)queue.max_events: (maximale Anzahl von Ereignissen in der Warteschlange, Standard - 0 (unbegrenzt)).queue.max_bytes: (maximale Warteschlangengröße in Bytes, Standard ist 1024 MB (1 GB)).
Wenn
queue.max_eventsund konfiguriert sind queue.max_bytes, werden keine Nachrichten mehr in der Warteschlange empfangen, wenn der Wert einer dieser Einstellungen erreicht ist. Weitere Informationen zu persistenten Warteschlangen finden Sie hier .
Ein Beispiel für den Teil von logstash.yml, der für das Einrichten einer Warteschlange verantwortlich ist:
queue.type: persisted
queue.max_bytes: 10gb
Anpassung
Die Logstash-Konfiguration besteht normalerweise aus drei Teilen, die für verschiedene Phasen der Verarbeitung eingehender Protokolle verantwortlich sind: Empfangen (Eingabeabschnitt), Parsen (Filterabschnitt) und Senden an Elastic (Ausgabeabschnitt). Im Folgenden werden wir uns jeden einzelnen genauer ansehen.
Eingang
Der eingehende Stream mit Rohprotokollen wird von den Filebeat-Agenten empfangen. Es ist dieses Plugin, das wir im Eingabeabschnitt angeben:
input {
beats {
port => 5044
}
}
Nach dieser Einstellung beginnt Logstash, Port 5044 abzuhören, und verarbeitet sie beim Empfang von Protokollen gemäß den Einstellungen im Filterabschnitt. Bei Bedarf können Sie den Kanal für den Empfang von Protokollen vom Dateibit in SSL umbrechen. Lesen Sie mehr über die Beats Plugin - Einstellungen hier .
Filter
Alle interessanten Textprotokolle, die Exchange zur Verarbeitung generiert, sind im CSV-Format mit den in der Protokolldatei selbst beschriebenen Feldern. Csv Datensätze für die Analyse, bietet Logstash uns drei Plugins: sezieren , csv und grok. Der erste ist der schnellste , kann jedoch nur die einfachsten Protokolle analysieren.
Beispielsweise wird der folgende Datensatz zweigeteilt (aufgrund des Vorhandenseins eines Kommas im Feld), wodurch das Protokoll falsch analysiert wird:
…,"MDB:GUID1, Mailbox:GUID2, Event:526545791, MessageClass:IPM.Note, CreationTime:2020-05-15T12:01:56.457Z, ClientType:MOMT, SubmissionAssistant:MailboxTransportSubmissionEmailAssistant",…
Es kann beim Parsen von Protokollen verwendet werden, z. B. IIS. In diesem Fall könnte der Filterabschnitt folgendermaßen aussehen:
filter {
if "IIS" in [tags] {
dissect {
mapping => {
"message" => "%{date} %{time} %{s-ip} %{cs-method} %{cs-uri-stem} %{cs-uri-query} %{s-port} %{cs-username} %{c-ip} %{cs(User-Agent)} %{cs(Referer)} %{sc-status} %{sc-substatus} %{sc-win32-status} %{time-taken}"
}
remove_field => ["message"]
add_field => { "application" => "exchange" }
}
}
}
Die Logstash-Konfiguration erlaubt bedingte Anweisungen , sodass wir nur Protokolle an das Dissektions-Plugin senden können, die mit einem Filebeat-Tag versehen wurden
IIS. Innerhalb des Plugins stimmen wir die Feldwerte mit ihren Namen ab, löschen das ursprüngliche Feld message, das den Eintrag enthält, aus dem Protokoll und können ein beliebiges Feld hinzufügen, das beispielsweise den Namen der Anwendung enthält, von der wir Protokolle sammeln.
Bei der Verfolgung von Protokollen ist es besser, das CSV-Plugin zu verwenden, da es komplexe Felder korrekt verarbeiten kann:
filter {
if "Tracking" in [tags] {
csv {
columns => ["date-time","client-ip","client-hostname","server-ip","server-hostname","source-context","connector-id","source","event-id","internal-message-id","message-id","network-message-id","recipient-address","recipient-status","total-bytes","recipient-count","related-recipient-address","reference","message-subject","sender-address","return-path","message-info","directionality","tenant-id","original-client-ip","original-server-ip","custom-data","transport-traffic-type","log-id","schema-version"]
remove_field => ["message", "tenant-id", "schema-version"]
add_field => { "application" => "exchange" }
}
}
Innerhalb des Plugins ordnen wir die Feldwerte ihren Namen zu, entfernen das ursprüngliche Feld
message(sowie die Felder tenant-idund schema-version), die den Eintrag enthalten, aus dem Protokoll und können ein beliebiges Feld hinzufügen, das beispielsweise den Namen der Anwendung enthält, von der wir Protokolle sammeln.
Am Ende der Filterphase erhalten wir Dokumente in erster Näherung, die in Kibana gerendert werden können. Wir werden folgendes vermissen:
- Numerische Felder werden als Text erkannt, wodurch verhindert wird, dass Operationen an ihnen ausgeführt werden. Das heißt, die
time-takenIIS-Protokollfelder sowie die Verfolgungsfelderrecipient-countund dastotal-bitesProtokoll. - Der Standarddokumentzeitstempel enthält die Protokollverarbeitungszeit und nicht die serverseitige Aufzeichnungszeit.
- Das Feld
recipient-addresssieht aus wie eine einzelne Konstruktion, die keine Analyse mit Zählung der Empfänger von Buchstaben ermöglicht.
Jetzt ist es an der Zeit, dem Protokollverarbeitungsprozess etwas Magie hinzuzufügen.
Numerische Felder konvertieren
Das Dissektions-Plugin verfügt über eine Option
convert_datatype, mit der Sie ein Textfeld in ein digitales Format konvertieren können. Zum Beispiel so:
dissect {
…
convert_datatype => { "time-taken" => "int" }
…
}
Es sei daran erinnert, dass diese Methode nur geeignet ist, wenn das Feld definitiv eine Zeichenfolge enthält. Die Option verarbeitet keine Nullwerte aus den Feldern und wird in eine Ausnahme ausgelöst.
Für die Verfolgung von Protokollen ist es besser, keine ähnliche Konvertierungsmethode zu verwenden, da die Felder
recipient-countund total-bitesleer sein können. Es ist besser, das Mutate- Plugin zu verwenden, um diese Felder zu konvertieren :
mutate {
convert => [ "total-bytes", "integer" ]
convert => [ "recipient-count", "integer" ]
}
Empfänger_Adresse in einzelne Empfänger aufteilen
Diese Aufgabe kann auch mit dem Mutate Plugin gelöst werden:
mutate {
split => ["recipient_address", ";"]
}
Ändern des Zeitstempels
Im Fall von Tracking-Protokollen wird die Aufgabe sehr einfach durch das Datums- Plugin gelöst , mit dessen Hilfe
timestampDatum und Uhrzeit im Feld im erforderlichen Format aus dem Feld geschrieben werden können date-time:
date {
match => [ "date-time", "ISO8601" ]
timezone => "Europe/Moscow"
remove_field => [ "date-time" ]
}
Bei IIS-Protokollen müssen wir die Felddaten kombinieren
dateund timemithilfe des Mutate-Plugins die benötigte Zeitzone registrieren und diesen Zeitstempel timestampmithilfe des Datums-Plugins einfügen:
mutate {
add_field => { "data-time" => "%{date} %{time}" }
remove_field => [ "date", "time" ]
}
date {
match => [ "data-time", "YYYY-MM-dd HH:mm:ss" ]
timezone => "UTC"
remove_field => [ "data-time" ]
}
Ausgabe
Der Ausgabeabschnitt wird verwendet, um verarbeitete Protokolle an den Protokollempfänger zu senden. Beim direkten Senden an Elastic wird das Elasticsearch- Plugin verwendet , das die Serveradresse und die Vorlage für den Indexnamen zum Senden des generierten Dokuments angibt:
output {
elasticsearch {
hosts => ["127.0.0.1:9200", "127.0.0.2:9200"]
manage_template => false
index => "Exchange-%{+YYYY.MM.dd}"
}
}
Endgültige Konfiguration
Die endgültige Konfiguration sieht folgendermaßen aus:
input {
beats {
port => 5044
}
}
filter {
if "IIS" in [tags] {
dissect {
mapping => {
"message" => "%{date} %{time} %{s-ip} %{cs-method} %{cs-uri-stem} %{cs-uri-query} %{s-port} %{cs-username} %{c-ip} %{cs(User-Agent)} %{cs(Referer)} %{sc-status} %{sc-substatus} %{sc-win32-status} %{time-taken}"
}
remove_field => ["message"]
add_field => { "application" => "exchange" }
convert_datatype => { "time-taken" => "int" }
}
mutate {
add_field => { "data-time" => "%{date} %{time}" }
remove_field => [ "date", "time" ]
}
date {
match => [ "data-time", "YYYY-MM-dd HH:mm:ss" ]
timezone => "UTC"
remove_field => [ "data-time" ]
}
}
if "Tracking" in [tags] {
csv {
columns => ["date-time","client-ip","client-hostname","server-ip","server-hostname","source-context","connector-id","source","event-id","internal-message-id","message-id","network-message-id","recipient-address","recipient-status","total-bytes","recipient-count","related-recipient-address","reference","message-subject","sender-address","return-path","message-info","directionality","tenant-id","original-client-ip","original-server-ip","custom-data","transport-traffic-type","log-id","schema-version"]
remove_field => ["message", "tenant-id", "schema-version"]
add_field => { "application" => "exchange" }
}
mutate {
convert => [ "total-bytes", "integer" ]
convert => [ "recipient-count", "integer" ]
split => ["recipient_address", ";"]
}
date {
match => [ "date-time", "ISO8601" ]
timezone => "Europe/Moscow"
remove_field => [ "date-time" ]
}
}
}
output {
elasticsearch {
hosts => ["127.0.0.1:9200", "127.0.0.2:9200"]
manage_template => false
index => "Exchange-%{+YYYY.MM.dd}"
}
}
Nützliche Links:
- Wie installiere ich OpenJDK 11 unter Windows?
- Laden Sie Logstash herunter
- Elastic verwendet die Option UseConcMarkSweepGC # 36828
- NSSM
- Dauerhafte Warteschlangen
- Beats Input Plugin
- Logstash Dude, wo ist meine Kettensäge? Ich muss meine Protokolle zerlegen
- Filter-Plugin zerlegen
- Bedingungen
- Filter-Plugin mutieren
- Datumsfilter-Plugin
- Elasticsearch-Ausgabe-Plugin