Ich hatte das Gefühl, dass alles für mich klappen würde, und machte mich auf eine Reise durch die Linux-Welt. In dieser Ausgabe von #IBelieveinDoing gab es Tutorials nicht nur unter Linux, sondern auch auf Git. Zwischen diesen Systemen können einige Parallelen gezogen werden. Linux ist ein Open-Source-Betriebssystem, das von Programmierern verwendet wird, und Git ist ein Versionskontrollsystem, mit dem Änderungen am Quellcode bei der Entwicklung von Programmen verfolgt werden. Es sollte beachtet werden, dass das Erlernen von Linux und Git eine sehr aufregende Erfahrung war. Aber Git ist ein ziemlich komplexes System, daher waren die Grundlagen schwerer zu beherrschen als die Grundlagen von Linux. In diesem Artikel möchte ich Ihnen mitteilen, was ich beim Beherrschen von Linux und Git gelernt habe.

Grundlegende Linux-Befehle
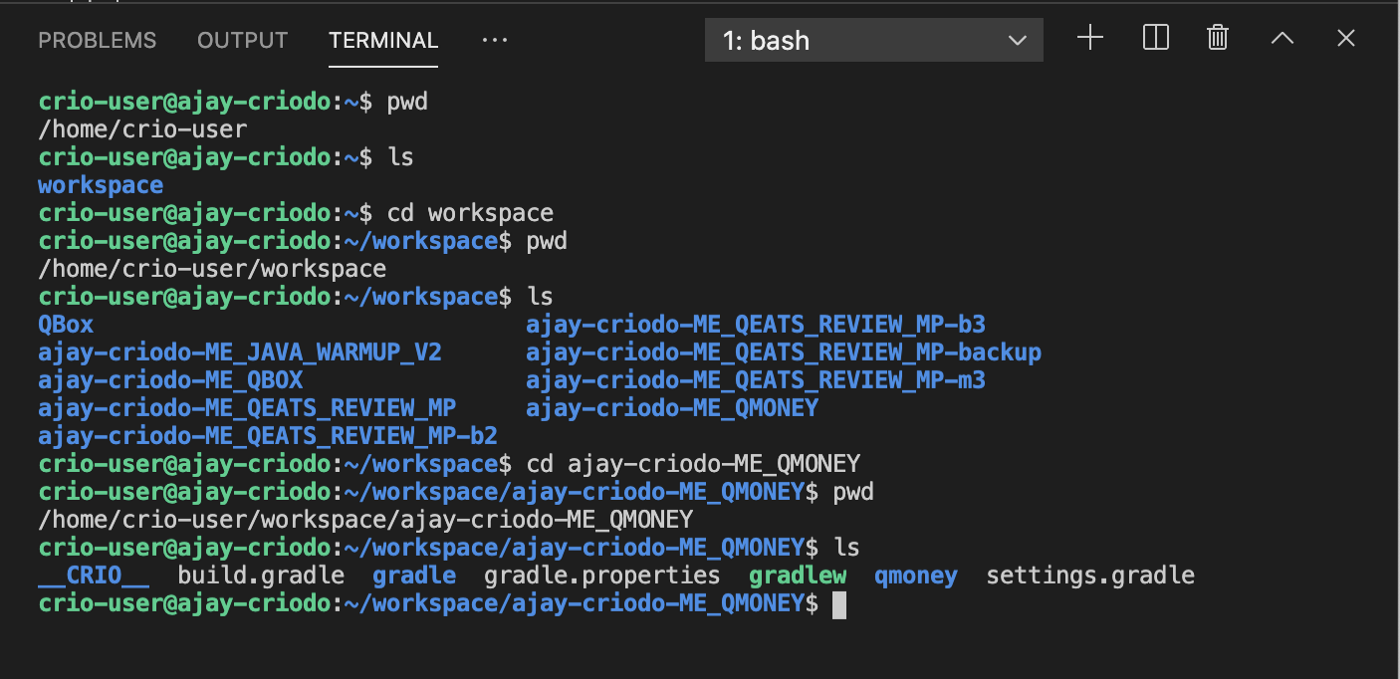
pwd: Mit diesem Befehl werden Informationen zum Arbeitsverzeichnis angezeigt.
ls: Mit diesem Befehl können Sie Informationen zum Inhalt eines Verzeichnisses anzeigen. Wenn es in dieser Form ohne Befehlszeilenargumente ausgeführt wird, werden Informationen im Standardformat angezeigt.
cd: Dieser Befehl dient zum Wechseln des Verzeichnisses.
Experimentieren mit Linux-Befehlen
cp : Dieser Befehl dient zum Kopieren von Dateien und Ordnern.
mv: Mit diesem Befehl können Sie Dateien und Ordner umbenennen oder verschieben.
touch: Mit diesem Befehl werden leere Dateien erstellt und der Zeitstempel der Dateien geändert.
cat: Mit diesem Befehl können Sie den Inhalt von Dateien anzeigen. Mit seiner Hilfe können Sie Kopien von Dateien erstellen und den Inhalt einiger Dateien an andere anhängen.
tree: Mit diesem Befehl können Sie Verzeichnisinformationen in einem baumartigen Format anzeigen. Der Befehl zeigt standardmäßig Informationen zu Ordnern und Dateien sowie Informationen zur Anzahl der Dateien und Ordner in seiner Ausgabestruktur an. Hier ist ein Beispiel für seine Verwendung
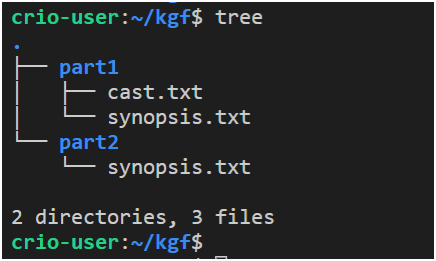
Beispiel für die Verwendung des Befehls tree
Hier werden Ordnernamen blau hervorgehoben, Dateinamen weiß. In den von diesem Befehl angezeigten Strukturen werden andere Farben verwendet.
echo: Mit diesem Befehl werden die an ihn übergebenen Daten auf dem Bildschirm angezeigt.
grep: Dieser Befehl dient zum Arbeiten mit Textdaten. Insbesondere können Sie damit nach Zeichenfolgen suchen.
tail: Dieser Befehl druckt die letzten 10 Zeilen einer Datei.
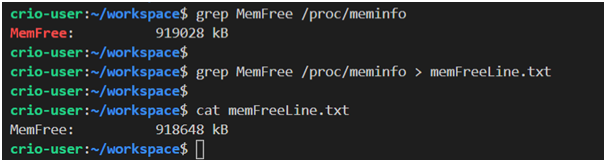
Beispiele für die Verwendung von Befehlen grep und cat
awk : Dieser Befehl soll mit dem entsprechenden Dienstprogramm zusammenarbeiten, das leistungsstarke Tools für die Verarbeitung von Zeichenfolgen bietet, deren Funktionen mit denen in vollwertigen Programmiersprachen vergleichbar sind.
Unter Linux können Sie Pipelines verwenden. Hierbei handelt es sich um Einweg-Pipelines, mit denen Sie zwischen Prozessen kommunizieren können. Bei der Beschreibung von Pipelines wird das Symbol (
|) verwendet. Mit diesem Symbol können Sie beispielsweise die Ausgabe eines Befehls an die Eingabe eines anderen Befehls weiterleiten.

Ein Beispiel für die Verwendung der Pipeline
ssh : Mit diesem Befehl können Sie mit einem SSH-Client arbeiten, mit dem eine Verbindung zu Remote-Systemen hergestellt und Befehle auf diesen ausgeführt werden. Das SSH-Protokoll zielt darauf ab, die sichere Interaktion von Computern zu organisieren.
rm: Mit diesem Befehl werden Dateien und Ordner gelöscht. Zum Beispiel führt das Aufrufen im Formularrm filezum Löschen der Datei und im Formularrm -r directory zum Löschen des Verzeichnisses und seines gesamten Inhalts.
Linux-Verzeichnisstruktur
Linux verwendet eine baumartige Verzeichnisstruktur. Der Anfang dieser hierarchischen Struktur befindet sich im Stammverzeichnis. Alle anderen Verzeichnisse sind in diesem Verzeichnis verschachtelt. Der Schrägstrich (
/) wird verwendet, um Verzeichnisnamen zu trennen, wenn Pfade zu Dateien und Ordnern angegeben werden .
So könnte die Dateisystemstruktur auf einem Linux-System aussehen.
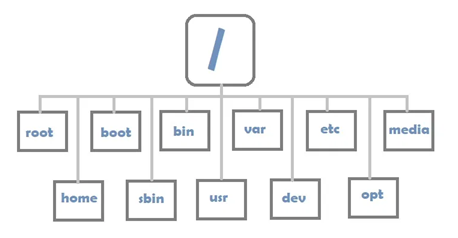
Verzeichnisstruktur unter Linux
Dies sind die Merkmale einiger wichtiger Ordner.
| Verzeichnispfad | Anmerkungen |
|
Wurzelverzeichnis. |
|
Das Verzeichnis, in dem die Materialien des Benutzers gespeichert sind. |
|
Hier werden die zum Ausführen von Linux erforderlichen Dateien gespeichert. |
|
Die ausführbaren Dateien befinden sich hier. |
|
Enthält verschiedene Dateien, die vom System und den installierten Programmen verwendet werden. Dies können Protokolldateien, Datenbanken und zwischengespeicherte Webseiteninhalte sein. |
Absolute und relative Adressierung
Absolute Dateipfade enthalten immer den vollständigen Pfad vom Stammverzeichnis zu den Verzeichnissen, die die erforderlichen Dateien enthalten.
Relative Pfade sind relativ zum aktuellen Verzeichnis.
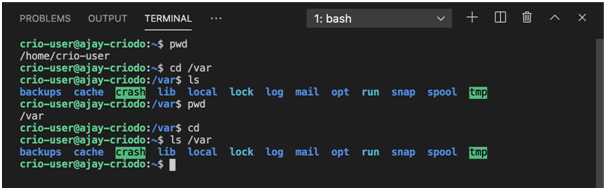
Experimentieren mit Pfaden
Es gibt spezielle relative Pfade, die in der folgenden Tabelle beschrieben werden.
| Relativer Pfad | Beschreibung | Beispiel | Beispielnotizen |
|
Aktuelles Arbeitsverzeichnis. | |
Zeigt Informationen zum Inhalt des aktuellen Verzeichnisses an. |
|
Übergeordnetes Verzeichnis. | |
Gehen Sie eine Ebene höher zum übergeordneten Verzeichnis. |
|
Vorheriges Arbeitsverzeichnis. | |
Kehren Sie zum vorherigen Arbeitsverzeichnis zurück. |
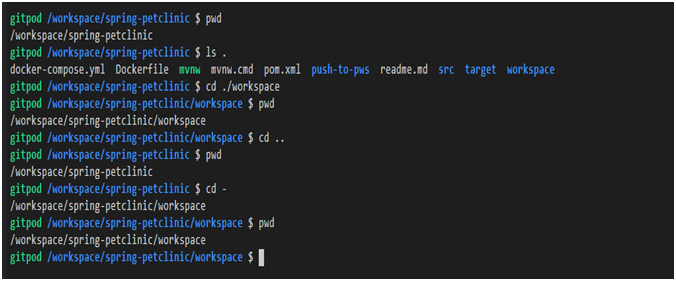
Beispiele für die Verwendung spezieller relativer Pfade
Weiche und harte Links zu Dateien
Ein weicher (symbolischer) Dateilink enthält einen Zeiger auf den Dateinamen. Diese Links ähneln Verknüpfungen, mit denen schnell aus verschiedenen Verzeichnissen auf eine Datei zugegriffen werden kann. Wenn eine Datei mit einem Softlink gelöscht wird, bleibt der Link erhalten, funktioniert jedoch nicht mehr.
Ein fester Link ist ein Link zu dem Speicherort auf der Festplatte, an dem sich die Datei befindet. Das System betrachtet die Datei als vorhanden, solange mindestens eine feste Verknüpfung besteht. Wenn eine Datei mehrere feste Links enthält, kann sie mit einer Datei mit mehreren Namen verglichen werden.
Der Befehl wird verwendet, um Hard- und Softlinks zu Dateien zu erstellen
ln. Hier ist ein Beispiel für das Erstellen einer symbolischen Verknüpfung:
ln -s /path/to/file linkname
Befehlsverhaltenskontrolle
Das Verhalten von Linux-Befehlen kann gesteuert werden, indem Befehlszeilenargumente (Schalter, Optionen, Flags) beim Aufrufen an sie übergeben werden. Sie sehen normalerweise wie ein Bindestrich (
-) gefolgt vom Namen des Schlüssels mit einem Buchstaben aus (eine solche Konstruktion könnte beispielsweise so aussehen -a). Sie können auch wie zwei Bindestriche ( --) aussehen, gefolgt von einem längeren Schlüsselnamen (Art --all).
Um mehr über Linux-Befehle zu erfahren, können Sie das integrierte Hilfesystem verwenden, auf das über den Befehl zugegriffen wird
man. Mit lsdem Befehl können Sie beispielsweise Hilfe zu einem Befehl abrufen man ls. Unten ist das Ergebnis eines ähnlichen Befehls.
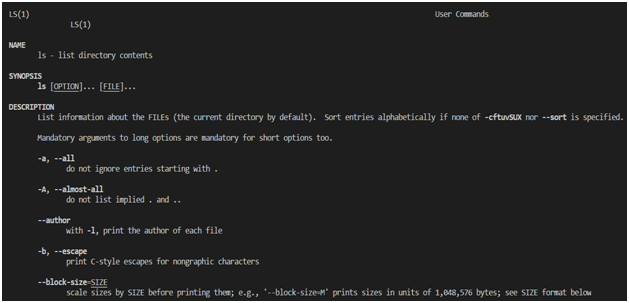
Ls-Befehlsreferenz Die
Befehlsreferenzseiten sind in mehrere Abschnitte unterteilt. Unter ihnen sind die folgenden:
NAME(Name). Dieser enthält den Namen des Befehls und eine kurze Beschreibung seiner Funktionsweise.SYNOPSIS(Befehlssyntaxzusammenfassung). Hier ist ein Diagramm zur Verwendung des Befehls.DESCRIPTION(Beschreibung). Dieser Abschnitt enthält eine detaillierte Beschreibung des Befehls und der von ihm unterstützten Befehlszeilenoptionen.
Beispielsweise wird der Befehl
lshäufig mit einer Option verwendet -l, mit der Sie Details zum Inhalt eines Verzeichnisses anzeigen können.
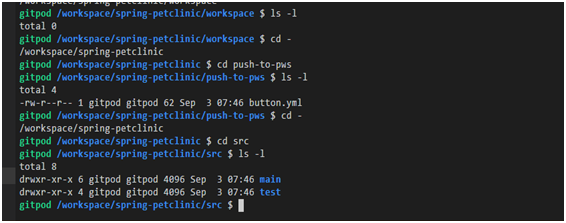
Verwenden des Befehls ls -l
Im vorherigen Bild haben Sie möglicherweise die Ansichtskonstrukte bemerkt
drwxr-xr-x. Dies ist eine Beschreibung der Dateiberechtigungen.
Dateiberechtigungen
Angenommen, wir haben die folgende Konstruktion, die Dateiberechtigungen beschreibt:
- rwx r-- r--
Bitte beachten Sie, dass darin vier Gruppen von Symbolen unterschieden werden können:
- Das erste Symbol zeigt an, womit wir es genau zu tun haben. Wenn es hier nämlich ein (
-) Zeichen gibt , stehen wir vor einer Datei. Der Buchstabe (d) gibt ein Verzeichnis an. Der Buchstabe (l) steht für einen Link. - Die folgenden drei Symbole zeigen an, welche Berechtigungen der Eigentümer für die Arbeit mit einer bestimmten Datei hat:
r- Lesen,w- Schreiben,x- Ausführen. Der vollständige Satz von Berechtigungen wird durch eine Sequenz dargestelltrwx. Wenn eine bestimmte Berechtigung fehlt, wird stattdessen ein Symbol (-) an der entsprechenden Position platziert . - , ( , ). , .
- , , , , .
Der Befehl wird zum Verwalten von Dateiberechtigungen verwendet
chmod. Um beispielsweise die aktuellen Zugriffsregeln auf die Dateiberechtigung für die Ausführung zu erweitern, können Sie das folgende aufgerufene Schema verwenden : chmod +x <filename>. Das Design +xgibt an, dass diese Berechtigung für alle Benutzer hinzugefügt wurde.
Lassen Sie uns über einige Besonderheiten der Konfiguration von Dateiberechtigungen mit sprechen
chmod. Um allen Benutzern eine bestimmte Berechtigung zuzuweisen, werden Konstruktionen verwendet, die der oben beschriebenen ähnlich sind +x. Mit dem Operator +( -) können Berechtigungen hinzugefügt werden. Mit dem Operator ( ) können Sie Berechtigungen entfernen. Mit dem Operator ( =) werden bestimmte Rechte für den Benutzer festgelegt, dem die Datei ( u, der Benutzer) gehört, für die Gruppe (g, Gruppe), für andere Benutzer ( o, andere) und für alle Benutzer ( a, alle). Dies erfolgt in Ansichtskonstrukten chmod u=rwx,g=rx,o=rx filename.
Wenn Sie Berechtigungen zuweisen, werden diese häufig in numerischer Form geschrieben. Oktalcodes entsprechen bestimmten Rechten. Somit der
xentsprechende Code 1, wder entsprechende Code 2und rder entsprechende Code 4. Der Code0entspricht dem völligen Fehlen von Berechtigungen zum Arbeiten mit der Datei. Die Rechte an der Datei werden durch eine dreistellige Nummer beschrieben, deren Reihenfolge der oben beschriebenen Reihenfolge der Berechtigungsgruppen entspricht. Das heißt, die erste Nummer beschreibt die Berechtigungen des Eigentümers der Datei, die zweite die Gruppenberechtigungen und die dritte die Berechtigungen anderer Benutzer. Jede dieser Zahlen ist die Summe des Autorisierungscodes r, wund x.
Beispielsweise bedeutet ein Befehl des Formulars
chmod 444 filename, dass jeder nur das Recht hat, die Datei zu lesen ( r--r--r--), und ein Befehl des Formulars chmod 700 filenamegibt an, dass der Eigentümer das Recht hat, die Datei zu lesen, zu schreiben und auszuführen ( rwx, 4+2+1), und niemand anderes hat das Recht, Aktionen mit der Datei auszuführen. ( rwx------).
Arbeiten mit Git
Bei der Arbeit mit Git wird normalerweise die folgende Abfolge von Aktionen verwendet:
- Ändern einer Datei im lokalen Arbeitsverzeichnis.
- Dateiindizierung (Befehl
git add). - Speichern eines Snapshots der indizierten Daten in der internen Datenbank (
git commit). - Übertragen von Änderungen vom lokalen Repository auf die Remote-Datei (
git push). - Laden von Änderungen aus einem Remote-Repository in ein lokales (
git pull).
Hier ist ein Diagramm, das diese Abfolge von Schritten veranschaulicht.
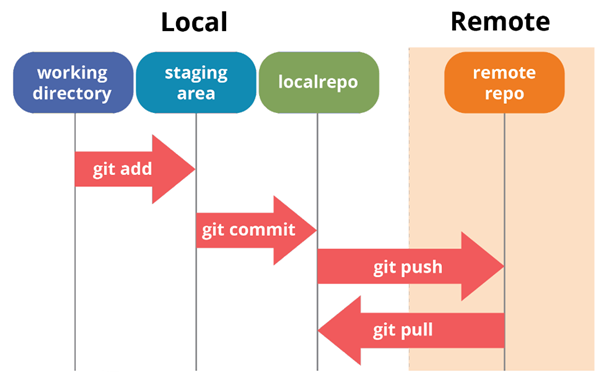
Typische Git-Workflow-
Dateien können sich bei der Arbeit mit Git in verschiedenen Zuständen befinden.
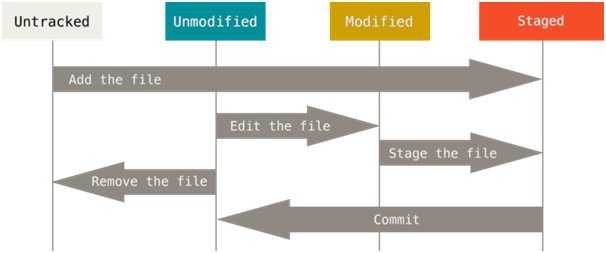
Dateistatus
- Untracked ist eine Datei, die Git nicht auf Änderungen überwacht. Diese Datei kann dem Index hinzugefügt werden und befindet sich in einem bereitgestellten Zustand.
- Nicht geändert - Eine Datei, die überwacht wurde, deren Inhalt sich jedoch nicht geändert hat. Wenn Sie diese Datei löschen, wird sie nicht mehr überwacht. Wenn Sie es ändern, wird es in den geänderten Zustand versetzt.
- Geändert - Die Datei, die überwacht wird und deren Inhalt sich geändert hat. Es kann indiziert und in den Status "Bereitgestellt" versetzt werden.
- Staged ist die Datei, die überwacht und in den Index aufgenommen wird. Die entsprechenden Änderungen können in die Git-Datenbank übernommen werden.
Schauen wir uns einige der Git-Befehle an.
git init: Dieser Befehl erstellt ein leeres Git-Repository im Verzeichnis. Dies ist der erste Schritt beim Erstellen eines neuen Repositorys. Nachdem Sie diesen Befehl ausgeführt haben, können Sie die Befehle git addund verwenden git commit.

Git init-
git add Befehl: Dieser Befehl fügt dem Index Dateien hinzu. Es unterstützt im Formular dasgit add .Hinzufügen aller nicht indizierten Dateien zum Index, im Formulargit add filename- Hinzufügen einer bestimmten Datei zum Index, im Formulargit add dirname- Hinzufügen eines Verzeichnisses zum Index.

Git add
git commit Befehl: Dieser Befehl schreibt Änderungen in das lokale Repository. Diese Änderungen werden analog zum Befehlsnamen "Commits" genannt. Jedes Commit verfügt über eine eindeutige Kennung, die die Arbeit mit Commits erleichtert.

Git-Commit-
git status Befehl: Mit diesem Befehl können Sie Informationen zum aktuellen Status des Repositorys abrufen.
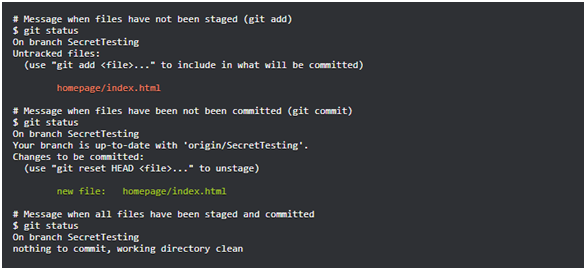
Git-Statusbefehl
git config : Mit diesem Befehl können Sie Git anpassen. Unter den Einstellungen kann Git notiert werdenuser.nameunduser.email. Sie enthalten den Namen und die E-Mail-Adresse des Benutzers, die in den Commits verwendet wurden, und geben an, wer sie erstellt hat. Wenn beim Aufrufen des Befehls eingit configFlag--globalverwendet wird, werden dieEinstellungen auf alle lokalen Repositorys angewendet. Ohne dieses Flag gelten die Einstellungen nur für das aktuelle Repository.

Git-Konfigurationsbefehl
git checkout : Mit diesem Befehl wird zwischen Zweigen des Repositorys (asgit checkout <branch_name>)gewechselt. Mit seiner Hilfe können Sie einen neuen Zweig erstellen und zu diesem wechseln (git checkout -b <new_branch>).
git merge: Mit diesem Befehl können Sie die Zweige des Repositorys zusammenführen. Es nimmt die Änderungen in einem Zweig und führt sie in den anderen Zweig ein. Beispielsweise gibt es einen Zweig, der an einer neuen Projektfunktion arbeitet. Nachdem diese Funktion abgeschlossen ist, werden die Änderungen in den Zweig verschoben, in dem die stabilen Funktionen gespeichert sind.
git clone: Mit diesem Befehl wird eine lokale Arbeitskopie eines Remote-Repositorys erstellt. Bei der Ausführung werden die Materialien des Remote-Repositorys auf den Computer heruntergeladen. Das Klonen eines vorhandenen Repositorys ist vergleichbar mit dem Erstellen eines neuen Repositorys mit dem Befehlgit init... Beim Klonen steht uns jedoch ein Repository zur Verfügung, in dem sich bereits etwas befindet, und wenn der Befehl ausgeführt wird git init, ein leeres Repository.
git pull: Dieser Befehl dient zum Herunterladen neuer Daten aus einem Remote-Repository.
git push: Mit diesem Befehl können lokale Commits in das Remote-Repository übertragen werden. Wenn Sie diesen Befehl aufrufen, müssen Sie ihm Informationen zum Remote-Repository und zum Zweig des lokalen Repositorys übergeben, der an das Remote-Repository gesendet werden muss.
Ergebnis
Ich habe dir alles erzählt, was ich auf meiner Reise in die Welt von Linux und Git gelernt habe. Es war sehr aufregend. Hoffentlich möchten Sie etwas Ähnliches tun und etwas Neues lernen, etwas, das Ihren beruflichen Horizont erweitert.
Wenn Sie kürzlich etwas Interessantes gemeistert haben, erzählen Sie uns bitte davon.

