Was aber, wenn Sie ein Nicht-SAP- und vorzugsweise OpenSource-Produkt als Speicher verwenden? Wir von der X5 Retail Group haben uns für GreenPlum entschieden. Dies löst natürlich das Kostenproblem, aber gleichzeitig stellen sich sofort Fragen, die bei Verwendung von SAP BW fast standardmäßig gelöst wurden.

Wie kann man insbesondere Daten aus Quellsystemen abrufen, bei denen es sich hauptsächlich um SAP-Lösungen handelt?
HR Metrics war das erste Projekt, das sich mit diesem Problem befasste. Unser Ziel war es, ein Lager für HR-Daten zu erstellen und analytische Berichte im Bereich der Arbeit mit Mitarbeitern zu erstellen. In diesem Fall ist die Hauptdatenquelle das SAP-HCM-Transaktionssystem, in dem alle Personal-, Organisations- und Gehaltsaktivitäten durchgeführt werden.
Datenextraktion
Im SAP BW gibt es Standard-Datenextraktoren für SAP-Systeme. Diese Extraktoren können automatisch die erforderlichen Daten erfassen, ihre Integrität verfolgen und die Deltas von Änderungen bestimmen. Hier ist beispielsweise eine Standarddatenquelle für Mitarbeiterattribute. 0EMPLOYEE_ATTR:

Ergebnis der Datenextraktion jeweils für einen Mitarbeiter:
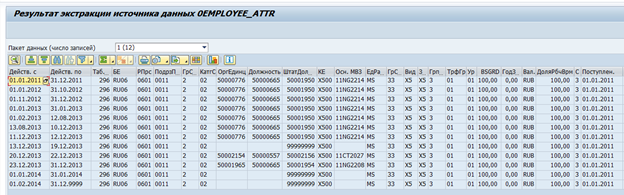
Bei Bedarf kann ein solcher Extraktor an Ihre eigenen Anforderungen angepasst oder ein eigener Extraktor erstellt werden.
Die erste Idee entstand über die Möglichkeit ihrer Wiederverwendung. Dies erwies sich leider als unmögliche Aufgabe. Der größte Teil der Logik ist auf der SAP-BW-Seite implementiert, und es war nicht möglich, den Extraktor an der Quelle schmerzlos vom SAP-BW zu trennen.
Es wurde klar, dass es notwendig sein würde, einen benutzerdefinierten Mechanismus zum Extrahieren von Daten aus SAP-Systemen zu entwickeln.
Datenspeicherstruktur in SAP HCM
Um die Anforderungen für einen solchen Mechanismus zu verstehen, müssen Sie zunächst bestimmen, welche Art von Daten wir benötigen.
Die meisten Daten in SAP HCM werden in flachen SQL-Tabellen gespeichert. Basierend auf diesen Daten visualisieren SAP-Anwendungen dem Benutzer Organisationsstrukturen, Mitarbeiter und andere HR-Informationen. So sieht beispielsweise eine Organisationsstruktur in SAP HCM aus:
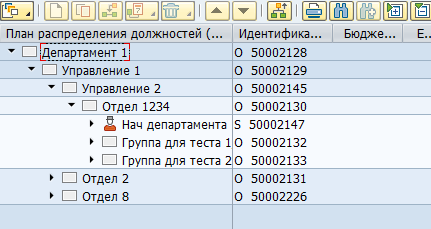
Physisch wird ein solcher Baum in zwei Tabellen gespeichert - in hrp1000-Objekten und in hrp1001 die Verknüpfungen zwischen diesen Objekten.
Objekte "Abteilung 1" und "Büro 1":

Kommunikation zwischen Objekten:

Es kann eine große Anzahl von Objekten und Kommunikationstypen zwischen ihnen geben. Es gibt sowohl Standardverknüpfungen zwischen Objekten als auch maßgeschneiderte für Ihre spezifischen Anforderungen. Beispielsweise gibt die Standard-B012-Beziehung zwischen einer Organisationseinheit und einer Vollzeitstelle den Abteilungsleiter an.
Manager-Mapping in SAP:
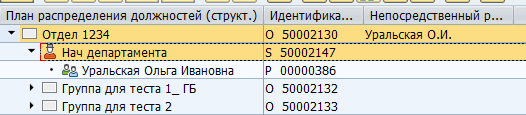
Speicherung in DB-Tabelle:

Mitarbeiterdaten werden in Pa * -Tabellen gespeichert. Beispielsweise werden Daten zu Personalaktivitäten für einen Mitarbeiter in der Tabelle pa0000 gespeichert.
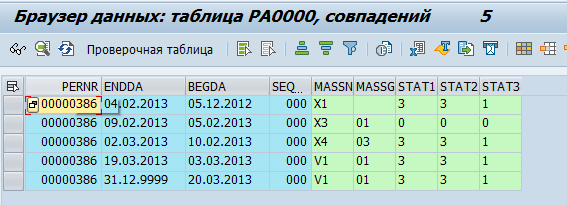
Wir haben entschieden, dass GreenPlum "Rohdaten" verwendet, d. H. Kopieren Sie sie einfach aus SAP-Tabellen. Und bereits direkt in GreenPlum werden sie verarbeitet und in physische Objekte (z. B. Abteilung oder Mitarbeiter) und Metriken (z. B. durchschnittliche Mitarbeiterzahl) konvertiert.
Es wurden ca. 70 Tabellen definiert, von denen Daten an GreenPlum übertragen werden müssen. Danach haben wir begonnen, einen Weg zu finden, um diese Daten zu übertragen.
SAP bietet eine relativ große Anzahl von Integrationsmechanismen. Am einfachsten ist jedoch der direkte Zugriff auf die Datenbank aufgrund von Lizenzbeschränkungen. Daher müssen alle Integrationsabläufe auf Anwendungsserverebene implementiert werden.
Das nächste Problem war das Fehlen von Daten zu gelöschten Datensätzen in der SAP-Datenbank. Wenn eine Zeile in der Datenbank gelöscht wird, wird sie physisch gelöscht. Jene. Die Bildung eines Delta von Veränderungen über den Zeitpunkt der Veränderung war nicht möglich.
Natürlich verfügt SAP HCM über Mechanismen zum Festschreiben von Datenänderungen. Beispielsweise verfügen Empfänger für die nachfolgende Übertragung an Systeme über Änderungszeiger, die alle Änderungen aufzeichnen und auf deren Grundlage ein Idoc gebildet wird (ein Objekt für die Übertragung an externe Systeme).
Beispiel eines IDocs zum Ändern des Infotyps 0302 für Mitarbeiter mit der Personalnummer 1251445:
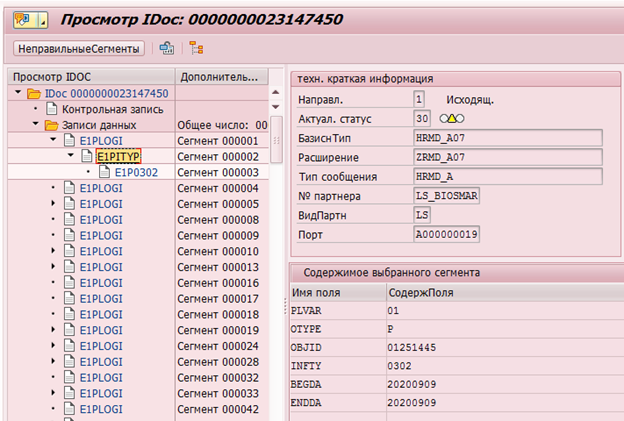
Oder Verwalten von Datenänderungsprotokollen in der Tabelle DBTABLOG.
Ein Beispiel für ein Protokoll zum Löschen eines Eintrags mit dem Schlüssel QK53216375 aus der Tabelle hrp1000:

Diese Mechanismen sind jedoch nicht für alle erforderlichen Daten verfügbar, und ihre Verarbeitung auf Anwendungsserverebene kann viele Ressourcen verbrauchen. Daher kann die massive Einbeziehung der Protokollierung in alle erforderlichen Tabellen zu einer spürbaren Verschlechterung der Systemleistung führen.
Clustered-Tabellen waren das nächste große Problem. Zeitschätzungs- und Abrechnungsdaten in der RDBMS-Version von SAP HCM werden als Satz logischer Tabellen pro Mitarbeiter und Abrechnung gespeichert. Diese logischen Tabellen werden als Binärdaten in der Tabelle pcl2 gespeichert.
Payroll Cluster:
Daten aus Clustertabellen können nicht per SQL-Befehl gelesen werden und erfordern die Verwendung von SAP HCM-Makros oder speziellen Funktionsbausteinen. Dementsprechend ist die Lesegeschwindigkeit solcher Tabellen ziemlich gering. Andererseits speichern solche Cluster Daten, die nur einmal im Monat benötigt werden - die endgültige Gehaltsabrechnung und Zeitschätzung. Die Geschwindigkeit ist in diesem Fall also nicht so kritisch.
Bei der Bewertung der Optionen unter Bildung eines Deltas der Datenänderung haben wir beschlossen, die Option auch beim vollständigen Entladen in Betracht zu ziehen. Die Option, jeden Tag Gigabyte unveränderter Daten zwischen Systemen zu übertragen, kann nicht besonders gut aussehen. Es hat jedoch auch eine Reihe von Vorteilen: Es ist nicht erforderlich, entweder das Delta auf der Quellenseite oder die Einbettung dieses Deltas auf der Empfängerseite zu implementieren. Dementsprechend werden die Kosten und die Implementierungszeit reduziert und die Integrationszuverlässigkeit erhöht. Gleichzeitig wurde festgestellt, dass fast alle Änderungen in SAP HR innerhalb von drei Monaten vor dem aktuellen Datum erfolgen. Daher wurde beschlossen, den täglichen vollständigen Download von Daten aus SAP HR N Monate vor dem aktuellen Datum und den monatlichen vollständigen Download zu beenden. Der N-Parameter hängt von der spezifischen Tabelle ab
und reicht von 1 bis 15.
Für die Datenextraktion wurde das folgende Schema vorgeschlagen:

Das externe System generiert eine Anforderung und sendet sie an SAP HCM, wo diese Anforderung auf Vollständigkeit der Daten und Berechtigung zum Zugriff auf Tabellen überprüft wird. Wenn die Prüfung erfolgreich ist, führt SAP HCM ein Programm aus, das die erforderlichen Daten sammelt und an die Fuse-Integrationslösung überträgt. Fuse definiert das erforderliche Thema in Kafka und leitet dort Daten weiter. Als nächstes werden Daten von Kafka an den Stage Area GP übertragen.
In dieser Kette interessiert uns das Thema des Extrahierens von Daten aus SAP HCM. Lassen Sie uns näher darauf eingehen.
SAP HCM-FUSE Interaktionsdiagramm.
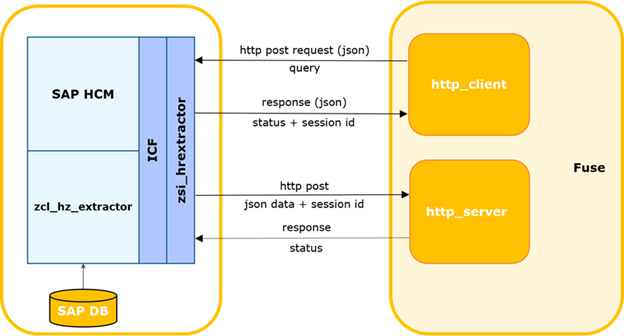
Das externe System ermittelt den Zeitpunkt der letzten erfolgreichen Anforderung an SAP.
Der Prozess kann durch einen Timer oder ein anderes Ereignis gestartet werden, einschließlich einer Zeitüberschreitung für das Warten auf eine Antwort mit Daten von SAP und das Einleiten einer wiederholten Anforderung. Anschließend wird eine Delta-Anfrage generiert und an SAP gesendet.
Anforderungsdaten werden im Text im JSON-Format übergeben.
Die http: POST-Methode.
Beispielanforderung:

Der SAP-Service überprüft die Anforderung auf Vollständigkeit, Übereinstimmung mit der aktuellen SAP-Struktur und Verfügbarkeit der Berechtigung zum Zugriff auf die angeforderte Tabelle.
Im Fehlerfall gibt der Service eine Antwort mit dem entsprechenden Code und der entsprechenden Beschreibung zurück. Wenn das Steuerelement erfolgreich ist, wird ein Hintergrundprozess zum Generieren einer Auswahl erstellt, eine eindeutige Sitzungs-ID generiert und synchron zurückgegeben.
Das externe System protokolliert es im Fehlerfall. Bei einer erfolgreichen Antwort werden die Sitzungs-ID und der Name der Tabelle übertragen, für die die Anforderung gestellt wurde.
Das externe System registriert die aktuelle Sitzung als offen. Wenn für diese Tabelle andere Sitzungen vorhanden sind, werden diese mit einer protokollierten Warnung geschlossen.
Der SAP-Hintergrundjob generiert einen Cursor gemäß den angegebenen Parametern und ein Datenpaket der angegebenen Größe. Paketgröße - Die maximale Anzahl von Datensätzen, die der Prozess aus der Datenbank liest. Standardmäßig wird 2000 angenommen. Wenn das Datenbankbeispiel mehr Datensätze als die verwendete Paketgröße enthält, wird nach der Übertragung des ersten Pakets der nächste Block mit dem entsprechenden Versatz und der inkrementierten Paketnummer gebildet. Die Zahlen werden um 1 erhöht und streng nacheinander gesendet.
Als nächstes übergibt SAP das Paket als Eingabe an den externen System-Webdienst. Und es ist das System, das das eingehende Paket steuert. Eine Sitzung mit der empfangenen ID muss im System registriert und geöffnet sein. Wenn die Paketnummer> 1 ist, muss das System den erfolgreichen Empfang des vorherigen Pakets (package_id-1) aufzeichnen.
Bei erfolgreicher Steuerung analysiert und speichert das externe System die Tabellendaten.
Wenn das letzte Flag im Paket vorhanden ist und die Serialisierung erfolgreich war, wird das Integrationsmodul über den erfolgreichen Abschluss der Sitzungsverarbeitung benachrichtigt und das Modul aktualisiert den Sitzungsstatus.
Im Falle eines Steuerungs- / Analysefehlers wird der Fehler protokolliert und Pakete für diese Sitzung werden vom externen System zurückgewiesen.
Ebenso wird im umgekehrten Fall, wenn das externe System einen Fehler zurückgibt, dieser protokolliert und die Übertragung von Paketen gestoppt.
Ein Integrationsservice wurde implementiert, um Daten auf der SAP-HM-Seite anzufordern. Der Service ist im ICF-Framework implementiert (SAP Internet Communication Framework - help.sap.com/viewer/6da7259a6c4b1014b7d5e759cc76fd22/7.01.22/en-US/488d6e0ea6ed72d5e10000000a42189c.html ). Sie können damit Daten aus dem SAP-HCM-System für bestimmte Tabellen abfragen. Beim Bilden einer Datenanforderung kann eine Liste bestimmter Felder und Filterparameter angegeben werden, um die erforderlichen Daten zu erhalten. Gleichzeitig impliziert die Implementierung des Dienstes keine Geschäftslogik. Algorithmen zur Berechnung von Delta, Anforderungsparametern, Integritätskontrolle usw. sind ebenfalls auf der Seite des externen Systems implementiert.
Mit diesem Mechanismus können Sie alle erforderlichen Daten in wenigen Stunden erfassen und übertragen. Diese Geschwindigkeit ist fast akzeptabel, daher betrachten wir diese Lösung als vorübergehend, wodurch es möglich wurde, den Bedarf an einem Extraktionswerkzeug für das Projekt zu decken.
Im Zielbild zur Lösung des Datenextraktionsproblems werden die Optionen für die Verwendung von CDC-Systemen wie Oracle Golden Gate oder ETL-Tools wie SAP DS erarbeitet.