
Mein Name ist Ilya Gulyaev. Ich bin Testautomatisierungsingenieur im Team zur Überprüfung nach der Bereitstellung bei DINS.
In DINS verwenden wir Jenkins in vielen Prozessen: vom Erstellen von Builds bis zum Ausführen von Bereitstellungen und Autotests. In meinem Team verwenden wir Jenkins als Plattform für den einheitlichen Start von Rauchprüfungen, nachdem jeder unserer Services von der Entwicklungsumgebung bis zur Produktion bereitgestellt wurde.
Vor einem Jahr haben andere Teams beschlossen, unsere Pipelines zu verwenden, um nicht nur einen Dienst nach der Aktualisierung zu überprüfen, sondern auch den Status der gesamten Umgebung zu überprüfen, bevor große Teststapel ausgeführt werden. Die Belastung unserer Plattform hat sich verzehnfacht, und Jenkins hat die anstehende Aufgabe nicht mehr bewältigt und begann gerade zu fallen. Wir haben schnell erkannt, dass das Hinzufügen von Ressourcen und das Optimieren des Garbage Collectors das Problem möglicherweise nur verzögern, aber nicht vollständig lösen. Aus diesem Grund haben wir uns entschlossen, Jenkins-Engpässe zu finden und zu optimieren.
In diesem Artikel werde ich erklären, wie die Jenkins-Pipeline funktioniert, und meine Erkenntnisse mitteilen, die Ihnen dabei helfen können, Ihre Pipelines schneller zu machen. Das Material ist nützlich für Ingenieure, die bereits mit Jenkins gearbeitet haben und das Werkzeug besser kennenlernen möchten.
Was für ein Jenkins Pipeline Beast
Jenkins Pipeline ist ein leistungsstarkes Tool, mit dem Sie verschiedene Prozesse automatisieren können. Jenkins Pipeline ist eine Reihe von Plugins, mit denen Sie Aktionen in Form eines Groovy DSL beschreiben können, und ist der Nachfolger des Build Flow-Plugins.
Das Skript für das Build Flow-Plugin wurde direkt auf dem Master in einem separaten Java-Thread ausgeführt, der Groovy-Code ohne Hindernisse ausführte, die den Zugriff auf die interne Jenkins-API verhinderten. Dieser Ansatz stellte ein Sicherheitsrisiko dar, das später zu einem der Gründe für die Aufgabe von Build Flow wurde und als Voraussetzung für die Erstellung eines sicheren und skalierbaren Tools zum Ausführen von Skripten diente - Jenkins Pipeline.
Weitere Informationen zur Geschichte der Jenkins-Pipeline-Erstellung finden Sie im Artikel Build Flow oder des AutorsOleg Nenashevs Vortrag über Groovy DSL in Jenkins .
So funktioniert die Jenkins-Pipeline
Lassen Sie uns nun herausfinden, wie Pipelines von innen funktionieren. Sie sagen normalerweise, dass Jenkins Pipeline eine völlig andere Art von Jobs in Jenkins ist, im Gegensatz zu den guten alten Freestyle-Jobs, die über die Weboberfläche angeklickt werden können. Aus Sicht des Benutzers mag dies so aussehen, aber von Jenkins Seite sind Pipelines eine Reihe von Plugins, mit denen Sie die Beschreibung von Aktionen in den Code übertragen können.
Ähnlichkeiten zwischen Pipeline- und Freestyle-Jobs
- Die Jobbeschreibung (keine Schritte) wird in der Datei config.xml gespeichert
- Parameter werden in der Datei config.xml gespeichert
- Trigger werden auch in der Datei config.xml gespeichert
- Und sogar einige Optionen sind in config.xml gespeichert
Damit. Halt. Die offizielle Dokumentation besagt, dass Parameter, Trigger und Optionen direkt in der Pipeline eingestellt werden können. Wo ist die Wahrheit?
Die Wahrheit ist, dass die in Pipeline beschriebenen Parameter beim Start des Jobs automatisch zum Konfigurationsabschnitt in der Weboberfläche hinzugefügt werden. Sie können mir vertrauen, weil ich diese Funktionalität in der neuesten Ausgabe geschrieben habe , aber mehr dazu im zweiten Teil des Artikels.
Unterschiede zwischen Pipeline- und Freestyle-Jobs
- Zum Zeitpunkt des Starts des Jobs weiß Jenkins nichts über den Agenten, der den Job ausführen soll
- Die Aktionen werden in einem groovigen Skript beschrieben.
Starten der deklarativen Jenkins-Pipeline
Der Startvorgang der Jenkins-Pipeline besteht aus den folgenden Schritten:
- Laden Sie die Jobbeschreibung aus der Datei config.xml
- Starten eines separaten Threads (Lightweight Performer), um die Aufgabe abzuschließen
- Laden des Pipeline-Skripts
- Erstellen und Überprüfen eines Syntaxbaums
- Aktualisierungen der Jobkonfiguration
- Kombinieren von Parametern und Eigenschaften, die in der Jobbeschreibung und im Skript angegeben sind
- Speichern von Jobbeschreibungen im Dateisystem
- Ausführen eines Skripts in einer groovigen Sandbox
- Agentenanforderung für einen gesamten Job oder einen einzelnen Schritt
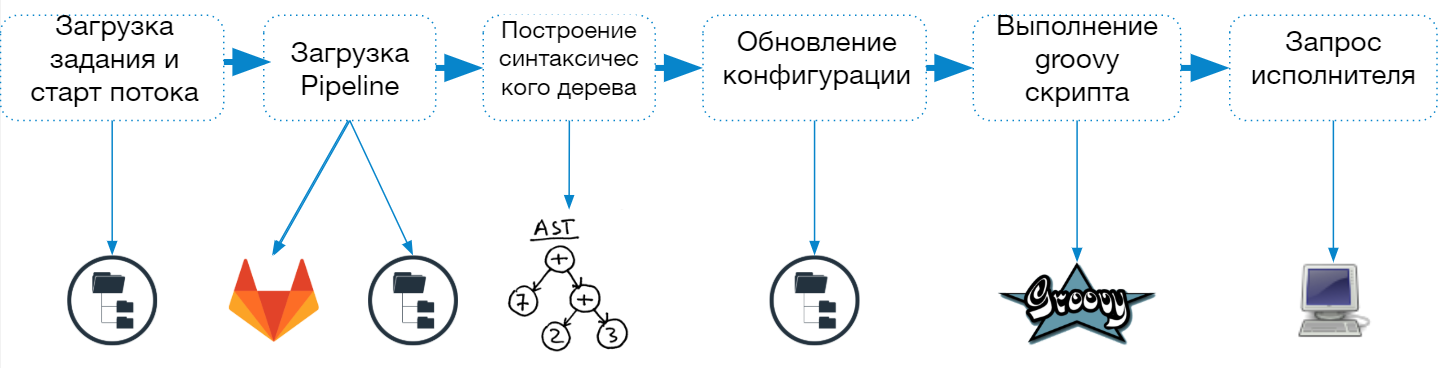
Wenn ein Pipeline-Job gestartet wird, erstellt Jenkins einen separaten Thread und sendet den Job zur Ausführung an die Warteschlange. Nach dem Laden des Skripts wird bestimmt, welcher Agent zum Abschließen der Aufgabe benötigt wird.
Um diesen Ansatz zu unterstützen, wird ein spezieller Jenkins-Thread-Pool (Lightweight Executors) verwendet. Sie können sehen, dass sie auf dem Master ausgeführt werden, haben jedoch keinen Einfluss auf den üblichen Pool von Executoren: Die
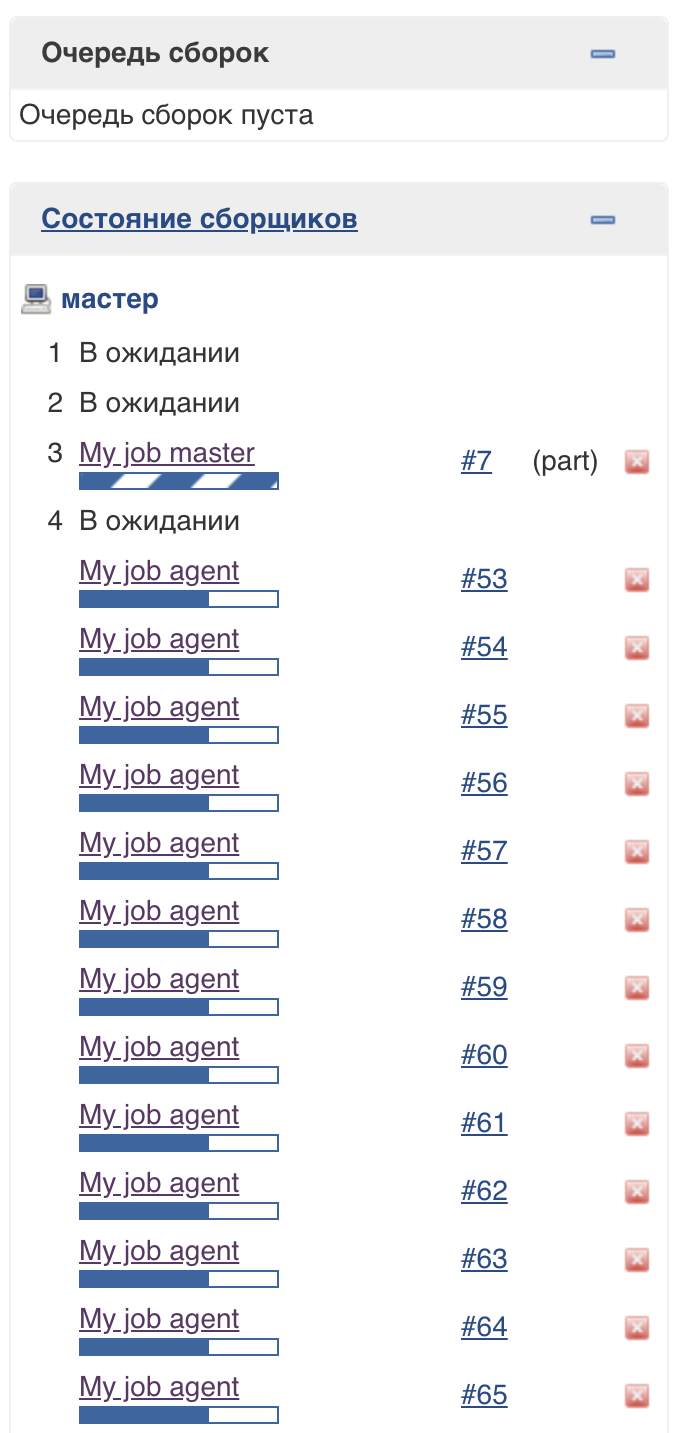
Anzahl der Threads in diesem Pool ist (zum Zeitpunkt dieses Schreibens) nicht begrenzt.
Arbeitsparameter in der Pipeline. Sowie Trigger und einige Optionen
Die Parameterverarbeitung kann durch die Formel beschrieben werden:

Aus den Jobparametern, die beim Start angezeigt werden, werden zuerst die Pipeline-Parameter aus dem vorherigen Start entfernt und erst dann die in der Pipeline des aktuellen Starts angegebenen Parameter hinzugefügt. Dadurch können Parameter aus dem Job entfernt werden, wenn sie aus der Pipeline entfernt wurden.
Wie funktioniert es von innen nach außen?
Schauen wir uns ein Beispiel config.xml an (die Datei, in der die Konfiguration des Jobs gespeichert ist):
<?xml version='1.1' encoding='UTF-8'?>
<flow-definition plugin="workflow-job@2.35">
<actions>
<org.jenkinsci.plugins.pipeline.modeldefinition.actions.DeclarativeJobAction plugin="pipeline-model-definition@1.5.0"/>
<org.jenkinsci.plugins.pipeline.modeldefinition.actions.DeclarativeJobPropertyTrackerAction plugin="pipeline-model-definition@1.5.0">
<jobProperties>
<string>jenkins.model.BuildDiscarderProperty</string>
</jobProperties>
<triggers/>
<parameters>
<string>parameter_3</string>
</parameters>
</org.jenkinsci.plugins.pipeline.modeldefinition.actions.DeclarativeJobPropertyTrackerAction>
</actions>
<description></description>
<keepDependencies>false</keepDependencies>
<properties>
<hudson.model.ParametersDefinitionProperty>
<parameterDefinitions>
<hudson.model.StringParameterDefinition>
<name>parameter_1</name>
<description></description>
<defaultValue></defaultValue>
<trim>false</trim>
</hudson.model.StringParameterDefinition>
<hudson.model.StringParameterDefinition>
<name>parameter_2</name>
<description></description>
<defaultValue></defaultValue>
<trim>false</trim>
</hudson.model.StringParameterDefinition>
<hudson.model.StringParameterDefinition>
<name>parameter_3</name>
<description></description>
<defaultValue></defaultValue>
<trim>false</trim>
</hudson.model.StringParameterDefinition>
</parameterDefinitions>
</hudson.model.ParametersDefinitionProperty>
<jenkins.model.BuildDiscarderProperty>
<strategy class="org.jenkinsci.plugins.BuildRotator.BuildRotator" plugin="buildrotator@1.2">
<daysToKeep>30</daysToKeep>
<numToKeep>10000</numToKeep>
<artifactsDaysToKeep>-1</artifactsDaysToKeep>
<artifactsNumToKeep>-1</artifactsNumToKeep>
</strategy>
</jenkins.model.BuildDiscarderProperty>
<com.sonyericsson.rebuild.RebuildSettings plugin="rebuild@1.28">
<autoRebuild>false</autoRebuild>
<rebuildDisabled>false</rebuildDisabled>
</com.sonyericsson.rebuild.RebuildSettings>
</properties>
<definition class="org.jenkinsci.plugins.workflow.cps.CpsScmFlowDefinition" plugin="workflow-cps@2.80">
<scm class="hudson.plugins.filesystem_scm.FSSCM" plugin="filesystem_scm@2.1">
<path>/path/to/jenkinsfile/</path>
<clearWorkspace>true</clearWorkspace>
</scm>
<scriptPath>Jenkinsfile</scriptPath>
<lightweight>true</lightweight>
</definition>
<triggers/>
<disabled>false</disabled>
</flow-definition>
Der Eigenschaftenbereich enthält Parameter, Trigger und Optionen, mit denen der Job gestartet wird. In einem zusätzlichen Abschnitt, DeclarativeJobPropertyTrackerAction, werden nur in der Pipeline festgelegte Parameter gespeichert.
Wenn ein Parameter aus der Pipeline entfernt wird, wird er sowohl aus DeclarativeJobPropertyTrackerAction als auch aus den Eigenschaften entfernt , da Jenkins weiß, dass der Parameter nur in der Pipeline definiert wurde.
Beim Hinzufügen eines Parameters wird die Situation umgekehrt. Dem Parameter werden DeclarativeJobPropertyTrackerAction und Eigenschaften hinzugefügt , jedoch nur zum Zeitpunkt der Pipeline-Ausführung.
Wenn Sie die Parameter nur in der Pipeline festlegen, werden sie daher angezeigtwird beim ersten Start nicht verfügbar sein .
Jenkins Pipeline-Ausführung
Sobald das Pipeline-Skript heruntergeladen und kompiliert wurde, beginnt der Ausführungsprozess. Aber dieser Prozess beinhaltet nicht nur Groovy. Ich habe die wichtigsten Schwergewichtsoperationen hervorgehoben, die zum Zeitpunkt der
Jobausführung
ausgeführt werden : Ausführen von Groovy-Code Das Pipeline-Skript wird immer auf dem Master ausgeführt - wir dürfen dies nicht vergessen, um Jenkins nicht unnötig zu belasten. Auf dem Agenten werden nur Schritte ausgeführt, die mit dem Dateisystem oder den Systemaufrufen des Agenten interagieren.
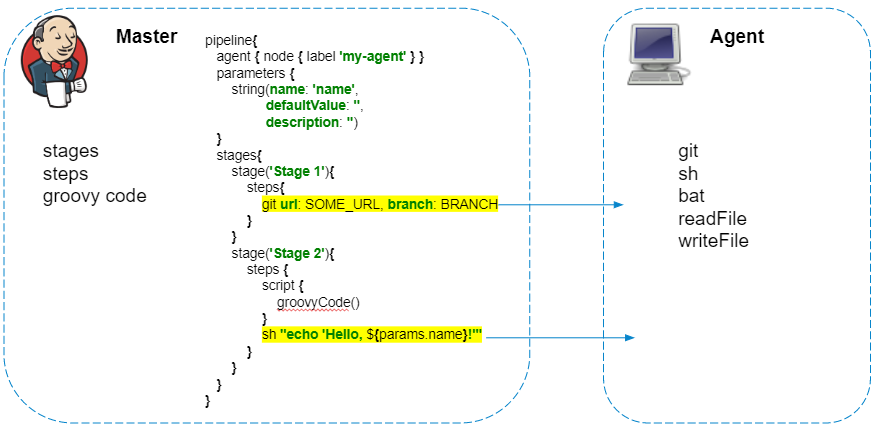
Die Pipelines haben ein großartiges Plugin, mit dem Sie HTTP-Anfragen stellen können . Außerdem kann die Antwort in einer Datei gespeichert werden.
httpRequest url: 'http://localhost:8080/jenkins/api/json?pretty=true', outputFile: 'result.json'
Zunächst scheint es, dass dieser Code vollständig auf dem Agenten ausgeführt werden sollte, eine Anfrage vom Agenten senden und die Antwort in der Datei result.json speichern sollte. Aber alles passiert umgekehrt, und die Anfrage wird von Jenkins selbst ausgeführt, und um den Inhalt der Datei zu speichern, wird sie auf den Agenten kopiert. Wenn keine zusätzliche Verarbeitung der Antwort in der Pipeline erforderlich ist, empfehle ich Ihnen, solche Anforderungen durch curl zu ersetzen:
sh 'curl "http://localhost:8080/jenkins/api/json?pretty=true" -o "result.json"'
Arbeiten mit Protokollen und Artefakten
Unabhängig vom Agenten, auf dem Befehle ausgeführt werden, werden Protokolle und Artefakte verarbeitet und in Echtzeit im Master-Dateisystem gespeichert.
Wenn die Pipeline Anmeldeinformationen verwendet, werden die Protokolle vor dem Speichern zusätzlich auf dem Master gefiltert .
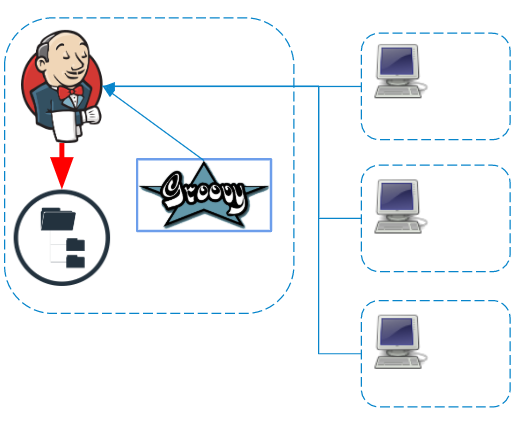
Schritte speichern (Pipeline-Haltbarkeit)
Jenkins Pipeline positioniert sich als eine Aufgabe, die aus separaten Teilen besteht, die unabhängig sind und reproduziert werden können, wenn der Master abstürzt. Sie müssen dies jedoch mit zusätzlichen Schreibvorgängen auf der Festplatte bezahlen, da abhängig von den Einstellungen der Aufgabe Schritte mit unterschiedlichem Detaillierungsgrad serialisiert und auf der Festplatte gespeichert werden.
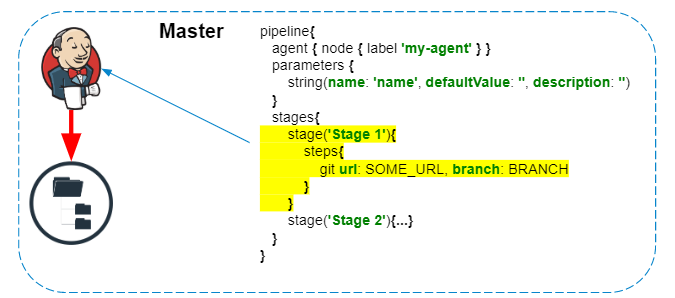
Abhängig von der Dauerhaftigkeit der Pipeline werden die Schritte im Pipeline-Diagramm für jeden Joblauf in einer oder mehreren Dateien gespeichert. Auszug aus der Dokumentation :
Das Workflow-Support-Plugin zum Speichern von Schritten (FlowNode) verwendet die FlowNodeStorage-Klasse und ihre Implementierungen SimpleXStreamFlowNodeStorage und BulkFlowNodeStorage.
- FlowNodeStorage verwendet speicherinternes Caching, um Festplattenschreibvorgänge zu aggregieren. Der Puffer wird zur Laufzeit automatisch geschrieben. Sie müssen sich im Allgemeinen keine Sorgen machen, aber denken Sie daran, dass das Speichern eines FlowNode nicht garantiert, dass er sofort auf die Festplatte geschrieben wird.
- SimpleXStreamFlowNodeStorage verwendet eine kleine XML-Datei für jeden FlowNode. Obwohl wir einen In-Memory-Cache mit weichen Referenzen für Knoten verwenden, führt dies zu einer wesentlich schlechteren Leistung beim ersten Durchlaufen der FlowNodes.
- BulkFlowNodeStorage verwendet eine größere XML-Datei mit allen darin enthaltenen FlowNodes. Diese Klasse wird im PERFORMANCE_OPTIMIZED-Lebendigkeitsmodus verwendet, der viel seltener schreibt. Dies ist im Allgemeinen viel effizienter, da ein großer Streaming-Datensatz schneller als ein Haufen kleiner Datensätze ist und die Belastung des Betriebssystems für die Verwaltung aller kleinen Dateien minimiert.
Original
Storage: in the workflow-support plugin, see the 'FlowNodeStorage' class and the SimpleXStreamFlowNodeStorage and BulkFlowNodeStorage implementations.
- FlowNodeStorage uses in-memory caching to consolidate disk writes. Automatic flushing is implemented at execution time. Generally, you won't need to worry about this, but be aware that saving a FlowNode does not guarantee it is immediately persisted to disk.
- The SimpleXStreamFlowNodeStorage uses a single small XML file for every FlowNode — although we use a soft-reference in-memory cache for the nodes, this generates much worse performance the first time we iterate through the FlowNodes (or when)
- The BulkFlowNodeStorage uses a single larger XML file with all the FlowNodes in it. This is used in the PERFORMANCE_OPTIMIZED durability mode, which writes much less often. It is generally much more efficient because a single large streaming write is faster than a bunch of small writes, and it minimizes the system load of managing all the tiny files.
Die gespeicherten Schritte finden Sie im Verzeichnis:
$JENKINS_HOME/jobs/$JOB_NAME/builds/$BUILD_ID/workflow/
Beispieldatei:
<?xml version='1.1' encoding='UTF-8'?>
<Tag plugin="workflow-support@3.5">
<node class="cps.n.StepStartNode" plugin="workflow-cps@2.82">
<parentIds>
<string>4</string>
</parentIds>
<id>5</id>
<descriptorId>org.jenkinsci.plugins.workflow.support.steps.StageStep</descriptorId>
</node>
<actions>
<s.a.LogStorageAction/>
<cps.a.ArgumentsActionImpl plugin="workflow-cps@2.82">
<arguments>
<entry>
<string>name</string>
<string>Declarative: Checkout SCM</string>
</entry>
</arguments>
<isUnmodifiedBySanitization>true</isUnmodifiedBySanitization>
</cps.a.ArgumentsActionImpl>
<wf.a.TimingAction plugin="workflow-api@2.40">
<startTime>1600855071994</startTime>
</wf.a.TimingAction>
</actions>
</Tag>
Ergebnis
Ich hoffe, dieses Material war interessant und hat dazu beigetragen, besser zu verstehen, was Pipelines sind und wie sie von innen funktionieren. Wenn Sie noch Fragen haben - teilen Sie diese unten, ich werde gerne antworten!
Im zweiten Teil des Artikels werde ich separate Fälle betrachten, die Ihnen helfen, Probleme mit der Jenkins-Pipeline zu finden und Ihre Aufgaben zu beschleunigen. Wir werden lernen, wie Sie Probleme beim gleichzeitigen Start lösen, die Überlebensmöglichkeiten untersuchen und diskutieren, warum Jenkins profiliert werden sollte.