
In letzter Zeit suchen große russische Unternehmen zunehmend nach erschwinglichen Speicherlösungen. Open Source DBMS werden zu Konkurrenten von Oracle, SAP HANA, Sybase, Informix: PostgreSQL, MySQL, MariaDB usw. Westliche Giganten - Alibaba, Instagram, Skype - setzen sie seit langem in ihren IT-Landschaften ein.
In dem Projekt für die Russische Union der Autoversicherer (RSA), in dem Jet Infosystems die IT-Infrastruktur für das neue AIS OSAGO aufbaute, verwendeten die Entwickler das PostgreSQL-DBMS. Und wir haben darüber nachgedacht, wie wir bei Hardwarefehlern maximale Datenbankverfügbarkeit und minimalen Datenverlust sicherstellen können. Und diese "auf Papier" -Beschreibung der Lösung scheint so einfach wie 2 + 2 zu sein. Tatsächlich musste unser Team hart arbeiten, um Fehlertoleranz zu erreichen.
Es gibt mehrere Failover-Clustering-Tools für PostgreSQL. Dies sind Stolon, Patroni, Repmgr, Schrittmacher + Corosync usw.
Wir haben uns für Patroni entschieden, weil sich dieses Projekt im Gegensatz zu ähnlichen Projekten aktiv entwickelt, über eine klare Dokumentation verfügt und zunehmend zur Wahl der Datenbankadministratoren wird.
Die Zusammensetzung des "Suppensets"
Patroni ist eine Reihe von Python-Skripten zur Automatisierung des Wechsels der führenden Rolle des PostgreSQL-Datenbankservers zum Replikat. Es kann auch Parameter des PostgreSQL-DBMS selbst speichern, ändern und anwenden. Es stellt sich heraus, dass die PostgreSQL-Konfigurationsdateien auf jedem Server nicht separat auf dem neuesten Stand gehalten werden müssen.
PostgreSQL ist eine relationale Open Source-Datenbank. Es hat sich im Umgang mit großen und komplexen Analyseprozessen bewährt.
Keepalived - In einer Konfiguration mit mehreren Knoten wird eine dedizierte IP-Adresse auf dem Knoten des Clusters aktiviert, auf dem derzeit die Rolle des primären PostgreSQL-Knotens verwendet wird. Die IP-Adresse dient als Einstiegspunkt für Anwendungen und Benutzer.
DCS ist ein verteilter Konfigurationsspeicher. Patroni verwendet es, um Informationen über die Zusammensetzung des Clusters, die Rollen der Cluster-Server sowie seine eigenen und PostgreSQL-Konfigurationsparameter zu speichern. Dieser Artikel konzentriert sich auf etcd.
Experimente mit Nuancen
Auf der Suche nach der optimalen Fehlertoleranzlösung und um unsere Hypothesen über den Betrieb verschiedener Optionen zu testen, haben wir mehrere Prüfstände erstellt. Zunächst haben wir Lösungen in Betracht gezogen, die sich von der Zielarchitektur unterscheiden: Beispielsweise haben wir Haproxy als primären Knoten von PostgreSQL verwendet, oder DCS befand sich auf denselben Servern wie PostgreSQL. Wir organisierten interne Hackathons und untersuchten, wie sich Patroni bei Ausfall von Serverkomponenten, Nichtverfügbarkeit des Netzwerks, Überlauf des Dateisystems usw. verhalten würde. Das heißt, sie haben verschiedene Fehlerszenarien ausgearbeitet. Als Ergebnis dieser "wissenschaftlichen Studien" wurde die endgültige Architektur der fehlertoleranten Lösung gebildet.
Gourmet IT Gericht
In PostgreSQL gibt es Serverrollen: Primär - eine Instanz mit der Fähigkeit, Daten zu schreiben / lesen; Replikat - eine schreibgeschützte Instanz, die ständig mit der primären Instanz synchronisiert wird. Diese Rollen sind statisch, wenn PostgreSQL ausgeführt wird. Wenn ein Server mit der primären Rolle ausfällt, muss der DBA die Replikatrolle manuell auf die primäre Rolle erhöhen.
Patroni erstellt Failover-Cluster, dh es kombiniert Server mit den primären und Replikatrollen. Im Falle eines Fehlers erfolgt ein automatischer Rollenwechsel zwischen ihnen.

Die obige Abbildung zeigt, wie die Anwendungsserver eine Verbindung zu einem der Server im Patroni-Cluster herstellen. Diese Konfiguration verwendet einen Primärknoten und zwei Replikate, von denen eines synchron ist. Bei der synchronen Replikation funktioniert PostgreSQL so, dass der primäre Server immer darauf wartet, dass Änderungen in das Replikat geschrieben werden. Wenn das synchrone Replikat nicht verfügbar ist, schreibt das primäre Replikat keine Änderungen in sich selbst, es ist schreibgeschützt. Dies ist die Architektur von PostgreSQL. Um "seine Natur zu ändern", wird das zweite Replikat verwendet - asynchron (wenn keine synchrone Replikation erforderlich ist, können Sie sich auf ein Replikat beschränken).
Wenn Sie zwei oder mehr Replikate verwenden und die synchrone Replikation aktivieren, erstellt Patroni immer nur ein synchrones Replikat. Wenn der primäre Knoten ausfällt, erhöht Patroni die Ebene des synchronen Replikats.
Die folgende Abbildung zeigt zusätzliche Patroni-Funktionen, die für industrielle Unternehmenslösungen von entscheidender Bedeutung sind - die Datenreplikation auf einen Sicherungsstandort.
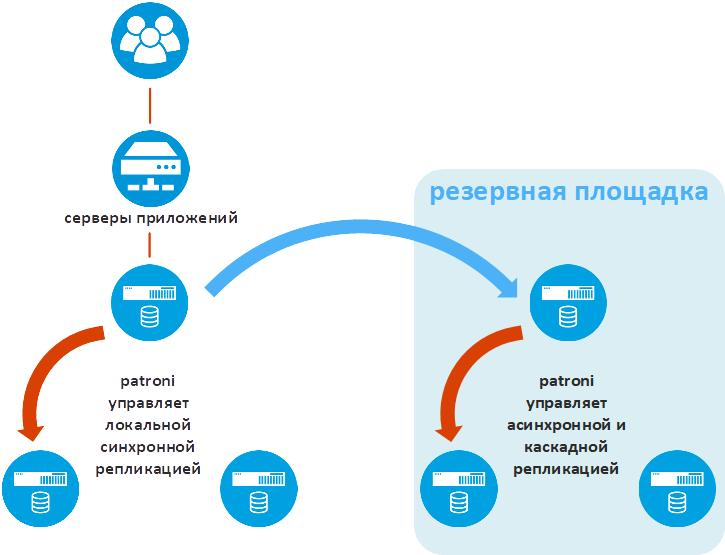
Patroni nennt diese Funktionalität standby_cluster. Damit kann ein Ratroni-Cluster an einem Remotestandort als asynchrones Replikat verwendet werden. Wenn der Hauptstandort verloren geht, funktioniert der Sicherungscluster Patroni so, als wäre er der Hauptstandort.
Einer der Knoten des Sicherungsstandortclusters heißt Standby Leader. Es ist eine asynchrone Replik des Primärknotens des Hauptstandorts. Die beiden verbleibenden Knoten des Sicherungsstandortclusters empfangen Daten vom Standby-Leader. Auf diese Weise wird die kaskadierende Replikation implementiert, wodurch das Verkehrsaufkommen zwischen technologischen Standorten verringert wird.
Zusammensetzung der Patroni-Cluster-Anwendungen
Nach dem Start erstellt Patroni einen separaten TCP-Port. Nachdem Sie eine HTTP-Anforderung an diesen Port gesendet haben, können Sie nachvollziehen, welcher Knoten des Clusters primär und welcher Replikat ist.

In keepalived haben wir ein kleines selbst erstelltes Skript als Überwachungsobjekt angegeben, das den Patroni-TCP-Port abfragt. Das Skript erwartet eine HTTP GET 200-Antwort. Der antwortende Clusterknoten ist der Primärknoten, auf dem keepalived die IP-Adresse startet, die für die Verbindung mit dem Cluster vorgesehen ist.
Wenn Sie die zweite Keepalived-Instanz so konfigurieren, dass sie auf eine HTTP GET 200-Antwort von einem synchronen Replikat wartet, startet Keepalived auf demselben Clusterknoten eine weitere dedizierte IP-Adresse. Diese Adresse kann von der Anwendung zum Lesen von Daten aus der Datenbank verwendet werden. Diese Option ist beispielsweise zum Erstellen von Berichten nützlich.
Da es sich bei Patroni um eine Reihe von Skripten handelt, "kommunizieren" die Instanzen auf jedem Knoten nicht direkt miteinander, sondern verwenden hierfür den Konfigurationsspeicher. Wir verwenden etcd als es, was für Patroni selbst ein Quorum ist - der aktuelle Primärknoten aktualisiert ständig den Schlüssel im etcd-Speicher und zeigt damit an, dass er der führende ist. Der Rest der Clusterknoten liest ständig diesen Schlüssel und "versteht", dass es sich um Replikate handelt. Der etcd-Dienst befindet sich auf dedizierten Servern in Höhe von 3 oder 5. Die Synchronisation der Daten im etcd-Speicher zwischen diesen Servern erfolgt über den etcd-Dienst.
Im Verlauf unserer Experimente haben wir festgestellt, dass der etcd-Dienst auf separate Server verschoben werden muss. Erstens ist etcd äußerst empfindlich gegenüber Netzwerklatenz und der Reaktionsfähigkeit des Festplattensubsystems, und dedizierte Server werden nicht geladen. Zweitens kann bei einer möglichen Netzwerktrennung der Knoten des Patroni-Clusters eine "Gehirnspaltung" auftreten - es erscheinen zwei Primärknoten, die nichts voneinander wissen, da der etcd-Cluster ebenfalls "zerfällt".
Übungscheck
Im Rahmen eines Projekts zum Aufbau einer IT-Infrastruktur für AIS OSAGO ist das Erreichen der Fehlertoleranz von PostgreSQL eine der Aufgaben beim "Implantieren" eines offenen DBMS in die IT-Unternehmenslandschaft. Daneben gibt es verwandte Themen wie die Integration des PostgreSQL-Clusters in Sicherungssysteme, die Überwachung der Infrastruktur und die Informationssicherheit sowie die zuverlässige Datensicherheit am Sicherungsstandort. Jede dieser Richtungen hat ihre eigenen Fallstricke und Möglichkeiten, sie zu umgehen. Wir haben bereits über einen von ihnen geschrieben - wir haben über PostgreSQL-Backups mit Unternehmenslösungen gesprochen .

Die von uns an den Ständen durchdachte und getestete Fehlertoleranzarchitektur von PostgreSQL hat sich in der Praxis bewährt. Die Lösung ist bereit, verschiedene System- und logische Fehler zu "übertragen". Jetzt läuft es auf 10 hoch geladenen Patroni-Clustern und hält PostgreSQL-Verarbeitungslasten von Hunderten von Gigabyte Daten pro Stunde stand.
Autor: Dmitry Erykin und Ingenieur-Designer von Computersystemen von Jet Infosystems