Seit etwa einem Jahr migriert unsere Infrastrukturabteilung alle auf GitLab.com ausgeführten Dienste nach Kubernetes. In dieser Zeit hatten wir nicht nur Probleme mit der Verlagerung von Diensten nach Kubernetes, sondern auch mit der Verwaltung der Hybridbereitstellung während des Übergangs. Die wertvollen Lektionen, die wir gelernt haben, werden in diesem Artikel besprochen.
Von Anfang an liefen die Server von GitLab.com auf virtuellen Maschinen in der Cloud. Diese virtuellen Maschinen werden von Chef verwaltet und mit unserem offiziellen Linux-Paket installiert . Die Bereitstellungsstrategie für den Fall, dass eine Anwendung aktualisiert werden muss, besteht darin, die Serverflotte mithilfe der CI-Pipeline einfach koordiniert und sequentiell zu aktualisieren. Diese Methode ist zwar langsam und etwas langweilig, stellt jedoch sicher, dass GitLab.com dieselben Installations- und Konfigurationsmethoden verwendet wie Benutzer von selbstverwalteten GitLab-Installationen, die unsere Linux-Pakete verwenden.
Wir verwenden diese Methode, weil es äußerst wichtig ist, all die Traurigkeit und Freude zu erleben, die normale Mitglieder der Community bei der Installation und Konfiguration ihrer GitLab-Kopien erleben. Dieser Ansatz hat einige Zeit gut funktioniert, aber als die Anzahl der Projekte auf GitLab 10 Millionen überstieg, stellten wir fest, dass er unsere Skalierungs- und Bereitstellungsanforderungen nicht mehr erfüllte.
Erste Schritte in Richtung Kubernetes und Cloud-natives GitLab
2017 wurde das GitLab Charts- Projekt erstellt , um GitLab für die Bereitstellung in der Cloud vorzubereiten und Benutzern die Installation von GitLab auf Kubernetes-Clustern zu ermöglichen. Wir wussten damals, dass die Verlagerung von GitLab auf Kubernetes die Skalierbarkeit der SaaS-Plattform erhöhen, die Bereitstellung vereinfachen und die Recheneffizienz verbessern würde. Gleichzeitig hingen viele Funktionen unserer Anwendung von bereitgestellten NFS-Partitionen ab, was den Übergang von virtuellen Maschinen verlangsamte.
Das Streben nach Cloud Native und Kubernetes ermöglichte es unseren Ingenieuren, einen schrittweisen Übergang zu planen, bei dem wir einige der NAS-Abhängigkeiten der Anwendung aufgaben und gleichzeitig neue Funktionen entwickelten. Seit wir im Sommer 2019 mit der Planung der Migration begonnen haben, wurden viele dieser Einschränkungen aufgehoben, und die Migration von GitLab.com auf Kubernetes ist jetzt in vollem Gange!
Funktionen der Arbeit von GitLab.com in Kubernetes
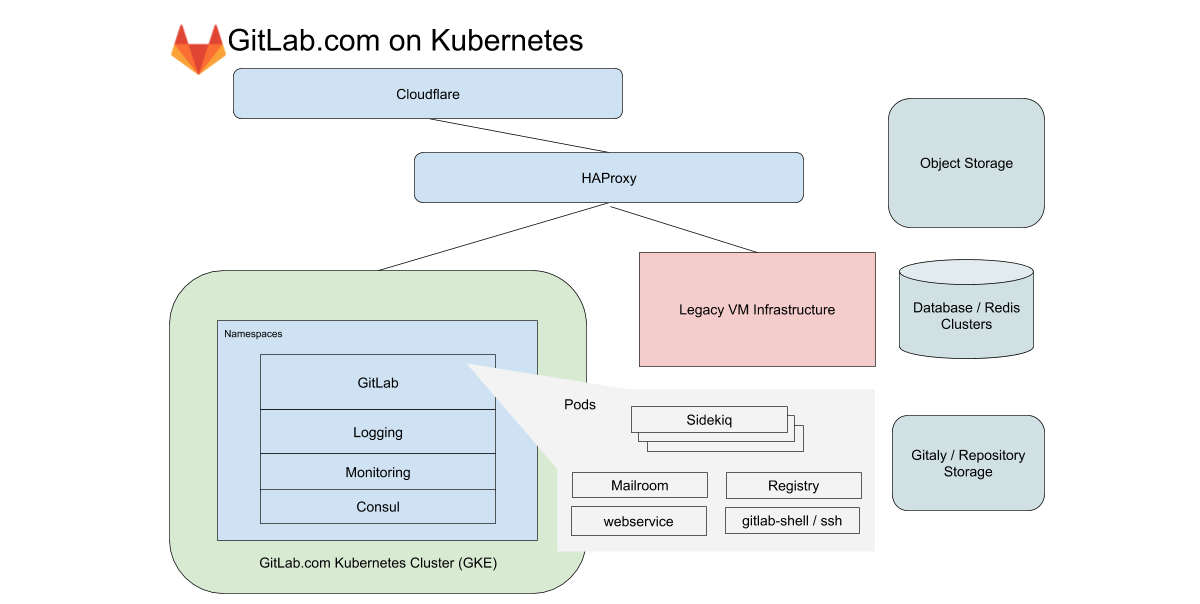
Für GitLab.com verwenden wir einen einzelnen regionalen GKE-Cluster, der den gesamten Anwendungsverkehr verarbeitet. Um die Komplexität der (bereits schwierigen) Migration zu minimieren, konzentrieren wir uns auf Dienste, die nicht auf lokalem Speicher oder NFS basieren. GitLab.com verwendet eine überwiegend monolithische Rails-Codebasis, und wir leiten den Datenverkehr basierend auf den Merkmalen der Arbeitslast an verschiedene Endpunkte weiter, die in unseren eigenen Knotenpools isoliert sind.
Im Fall des Frontends sind diese Typen in Anforderungen an das Web, die API, Git SSH / HTTPS und die Registrierung unterteilt. Im Backend stellen wir Jobs in Abhängigkeit von vordefinierten Ressourcengrenzen nach unterschiedlichen Merkmalen in die Warteschlange, sodass wir Service-Level-Ziele (SLOs) für unterschiedliche Workloads festlegen können.
Alle diese GitLab.com-Dienste werden mithilfe eines unveränderten GitLab Helm-Diagramms konfiguriert. Die Konfiguration erfolgt in Unterdiagrammen, die selektiv aktiviert werden können, wenn Dienste schrittweise in den Cluster migriert werden. Obwohl beschlossen wurde, einige unserer Stateful Services wie Redis, Postgres, GitLab Pages und Gitaly nicht in die Migration einzubeziehen, reduziert Kubernetes die Anzahl der derzeit von Chefkoch verwalteten VMs drastisch.
Kubernetes Transparenz- und Konfigurationsmanagement
Alle Einstellungen werden von GitLab selbst gesteuert. Hierzu werden drei Konfigurationsprojekte auf Basis von Terraform und Helm verwendet. Wir versuchen, GitLab selbst zu verwenden, wann immer dies möglich ist, um GitLab auszuführen, aber für betriebliche Aufgaben haben wir eine separate GitLab-Installation. Es muss unabhängig von der Verfügbarkeit von GitLab.com für GitLab.com-Bereitstellungen und -Updates sein.
Obwohl unsere Pipelines für den Kubernetes-Cluster auf einer separaten GitLab-Installation ausgeführt werden, sind in den Code-Repositorys Spiegel unter den folgenden Adressen öffentlich verfügbar:
- k8s-workloads / gitlab-com - GitLab.com- Konfigurationsbindung für das GitLab- Helmdiagramm ;
- k8s-workloads/gitlab-helmfiles — , GitLab . , PlantUML;
- Gitlab-com-infrastructure — Terraform Kubernetes (legacy) VM-. , , , , , IP-.

Wenn Änderungen vorgenommen werden, wird eine öffentlich verfügbare kurze Zusammenfassung mit einem Link zu einem detaillierten Diff angezeigt , den SRE analysiert, bevor Änderungen am Cluster vorgenommen werden.
Bei SREs verweist der Link auf einen detaillierten Unterschied in der GitLab-Installation, der für die Produktion verwendet wird, und der Zugriff ist eingeschränkt. Auf diese Weise können Mitarbeiter und die Community ohne Zugriff auf das Betriebsprojekt (es steht nur dem SRE offen) die vorgeschlagenen Konfigurationsänderungen anzeigen. Durch die Kombination einer öffentlichen Instanz von GitLab für Code mit einer privaten Instanz für CI-Pipelines erhalten wir einen einzigen Workflow und gewährleisten gleichzeitig die Unabhängigkeit von GitLab.com für Konfigurationsaktualisierungen.
Was wir während der Migration herausgefunden haben
Während des Umzugs wurden Erfahrungen gesammelt, die wir auf neue Migrationen und Bereitstellungen in Kubernetes anwenden.
1. -

Tägliche Ausgangsstatistiken (Bytes pro Tag) für den Git-Repository-Park auf GitLab.com
Google unterteilt sein Netzwerk in Regionen. Diese wiederum sind in Verfügbarkeitszonen (AZ) unterteilt. Git-Hosting ist mit großen Datenmengen verbunden, daher ist es für uns wichtig, den Netzwerkausgang zu kontrollieren. Für den internen Verkehr ist der Austritt nur dann kostenlos, wenn er innerhalb derselben AZ verbleibt. Zum Zeitpunkt dieses Schreibens stellen wir an einem typischen Geschäftstag ungefähr 100 TB Daten bereit (und das nur für Git-Repositories). Dienste, die sich in unserer alten VM-basierten Topologie auf denselben virtuellen Maschinen befanden, werden jetzt in verschiedenen Kubernetes-Pods ausgeführt. Dies bedeutet, dass ein Teil des zuvor für die VM lokalen Datenverkehrs möglicherweise außerhalb der Verfügbarkeitszonen liegen kann.
Mit regionalen GKE-Clustern können Sie aus Verfügbarkeitsgründen mehrere Verfügbarkeitszonen überspannen. Wir erwägen , den regionalen GKE-Cluster für Dienste, die viel Verkehr erzeugen, in Einzelzonencluster aufzuteilen . Dies reduziert die Ausgangskosten bei gleichzeitiger Aufrechterhaltung der Clusterredundanz.
2. Grenzen, Ressourcenanforderungen und Skalierung

Die Anzahl der Replikate, die den Produktionsverkehr unter registry.gitlab.com verarbeiten. Verkehrsspitzen um ~ 15:00 UTC.
Unsere Migrationsgeschichte begann im August 2019, als wir den ersten Dienst, die GitLab Container Registry, auf Kubernetes migrierten. Dieser geschäftskritische Dienst mit hohem Datenverkehr war für die erste Migration gut geeignet, da es sich um eine zustandslose Anwendung mit wenigen externen Abhängigkeiten handelt. Das erste Problem, auf das wir stießen, war die große Anzahl von vorab freigegebenen Pods aufgrund des unzureichenden Speichers auf den Knoten. Aus diesem Grund mussten wir Anforderungen und Grenzen ändern.
Es wurde festgestellt, dass im Fall einer Anwendung, bei der der Speicherverbrauch mit der Zeit zunimmt, niedrige Werte für request'ov (für jeden redundanten Speicher-Pod'a) in Verbindung mit einer "großzügigen" starren Grenze zur Verwendung zu Sättigungseinheiten (Sättigungseinheiten) und führen ein hohes Maß an Verschiebung. Um dieses Problem zu lösen, wurde beschlossen, die Anforderungen zu erhöhen und die Grenzwerte zu senken . Dies entlastete die Knoten und stellte einen Pod-Lebenszyklus sicher, der nicht zu viel Druck auf den Knoten ausübte. Wir starten Migrationen jetzt mit großzügigen (und nahezu identischen) Anforderungs- und Grenzwerten und passen sie nach Bedarf an.
3. Metriken und Protokolle

Die Infrastruktur konzentriert sich auf Latenz, Fehlerraten und Sättigung mit festgelegten Service Level-Zielen (SLOs), die an die Gesamtverfügbarkeit unseres Systems gebunden sind .
Im vergangenen Jahr war eine der wichtigsten Entwicklungen im Bereich Infrastruktur die Verbesserung der Überwachung und der Zusammenarbeit mit SLOs. Mit SLOs konnten wir Ziele für einzelne Services festlegen, die wir während der Migration genau überwacht haben. Aber selbst bei einer derart verbesserten Beobachtbarkeit ist es nicht immer möglich, Probleme mithilfe von Metriken und Warnungen sofort zu erkennen. Wenn wir uns beispielsweise auf Latenz und Fehlerraten konzentrieren, werden nicht alle Anwendungsfälle für einen Dienst, der einer Migration unterzogen wird, vollständig abgedeckt.
Dieses Problem wurde fast unmittelbar nach dem Verschieben einiger Workloads in den Cluster entdeckt. Besonders akut wurde es, wenn Funktionen überprüft werden mussten, deren Anzahl gering ist, für die jedoch sehr spezifische Konfigurationsabhängigkeiten bestehen. Eine der wichtigsten Lehren aus den Migrationsergebnissen war die Notwendigkeit, bei der Überwachung nicht nur Metriken, sondern auch Protokolle und den "langen Schwanz" zu berücksichtigen (wir sprechen über deren Verteilung in der Grafik - ca. übersetzt) . Jetzt enthalten wir für jede Migration eine detaillierte Liste von Protokollabfragen und planen eindeutige Rollback-Verfahren, die bei Problemen von einer Schicht zur anderen übergeben werden können.
Es war eine einzigartige Herausforderung, dieselben Anforderungen parallel für die alte und die neue VM-Infrastruktur auf Kubernetes-Basis zu bearbeiten. Im Gegensatz zur Lift-and-Shift- Migration (schnelle Übertragung von Anwendungen "wie sie ist" in eine neue Infrastruktur; lesen Sie beispielsweise hier mehr - ca. Übersetzung) erfordert die parallele Arbeit an "alten" VMs und Kubernetes Tools für Überwachungssysteme waren mit beiden Umgebungen kompatibel und konnten Metriken in einer Ansicht kombinieren. Es ist wichtig, dass wir dieselben Dashboards und Protokollabfragen verwenden, um eine konsistente Beobachtbarkeit während des Übergangs zu erreichen.
4. Umschalten des Datenverkehrs auf einen neuen Cluster
Für GitLab.com sind einige der Server für die kanarische Phase reserviert . Canary Park kümmert sich um unsere internen Projekte und kann auch von Benutzern aktiviert werden . In erster Linie sollen jedoch Änderungen an der Infrastruktur und der Anwendung validiert werden. Der erste migrierte Dienst begann mit der Annahme einer begrenzten Menge an internem Datenverkehr. Wir verwenden diese Methode weiterhin, um sicherzustellen, dass das SLO erfüllt ist, bevor der gesamte Datenverkehr an den Cluster weitergeleitet wird.
Bei der Migration bedeutet dies, dass zuerst Anforderungen an interne Projekte an Kubernetes gesendet werden. Anschließend wird der Rest des Datenverkehrs schrittweise auf den Cluster umgeschaltet, indem das Gewicht für das Backend über HAProxy geändert wird. Beim Wechsel von VM zu Kubernetes wurde deutlich, dass es sehr vorteilhaft war, den Datenverkehr zwischen der alten und der neuen Infrastruktur auf einfache Weise umzuleiten und die alte Infrastruktur in den ersten Tagen nach der Migration für den Rollback bereit zu halten.
5. Reservekraft der Kapseln und deren Verwendung
Fast sofort wurde das folgende Problem festgestellt: Die Pods für den Registrierungsdienst wurden schnell gestartet, aber der Start der Pods für Sidekiq dauerte bis zu zwei Minuten . Lang laufende Pods für Sidekiq wurden zu einem Problem, als wir mit der Migration von Workloads auf Kubernetes für Mitarbeiter begannen, die Aufträge schnell verarbeiten und schnell skalieren müssen.
In diesem Fall war die Lehre, dass der horizontale Pod-Autoscaler (HPA) in Kubernetes zwar das Verkehrswachstum gut handhabt, es jedoch wichtig ist, die Merkmale der Workloads zu berücksichtigen und freie Pod-Kapazität zuzuweisen (insbesondere in einer Umgebung mit ungleichmäßiger Nachfrageverteilung). In unserem Fall kam es zu einem plötzlichen Anstieg der Jobs, was zu einer schnellen Skalierung führte, die zu einer Sättigung der CPU-Ressourcen führte, bevor wir Zeit hatten, den Knotenpool zu skalieren.
Es besteht immer die Versuchung, so viel wie möglich aus dem Cluster herauszuholen. Wir, die anfangs mit Leistungsproblemen konfrontiert waren, beginnen jetzt mit einem großzügigen Pod-Budget und reduzieren es anschließend, wobei wir den SLO im Auge behalten. Das Starten von Pods für den Sidekiq-Dienst hat sich erheblich beschleunigt und dauert jetzt durchschnittlich etwa 40 Sekunden.Sowohl GitLab.com als auch unsere Benutzer von selbstverwalteten Installationen, die mit der offiziellen GitLab Helm-Tabelle arbeiten, haben von der Verkürzung der Pod-Startzeiten profitiert.
Fazit
Nach der Migration jedes Dienstes konnten wir die Vorteile der Verwendung von Kubernetes in der Produktion nutzen: schnellere und sicherere Anwendungsbereitstellung, Skalierung und effizientere Ressourcenzuweisung. Darüber hinaus gehen die Vorteile der Migration über den GitLab.com-Dienst hinaus. Jede Verbesserung der offiziellen Helmkarte kommt auch den Nutzern zugute.
Ich hoffe, Ihnen hat die Geschichte unserer Kubernetes-Migrationsabenteuer gefallen. Wir migrieren weiterhin alle neuen Dienste in den Cluster. Weitere Informationen erhalten Sie aus folgenden Publikationen:
- « Warum migrieren wir zu Kubernetes? ";
- " GitLab.com auf Kubernetes ";
- Epos zur Migration von GitLab.com auf Kubernetes .
PS vom Übersetzer
Lesen Sie auch in unserem Blog: