
Eine der ersten Ermahnungen, die ein junger Padawan zusammen mit dem Zugang zu Git-Repositories erhält, lautet: "
git push -f." Da dies eine der Hunderten von Maximen ist, die ein unerfahrener Softwareentwickler lernen muss, nimmt sich niemand die Zeit, um zu klären, warum dies nicht getan werden sollte. Es ist wie bei Babys und Feuer: „Streichhölzer sind kein Spielzeug für Kinder“ und das war's. Aber wir wachsen und entwickeln uns als Menschen und als Profis und eines Tages die Frage "Warum eigentlich?" steigt in vollem Wachstum. Dieser Artikel basiert auf unserem internen Treffen zum Thema: "Wann können und sollten Sie die Geschichte der Commits neu schreiben?"

Ich habe gehört, dass die Fähigkeit, diese Frage in einem Interview in einigen Unternehmen zu beantworten, ein Kriterium für das Interview für leitende Positionen ist. Aber um die Antwort darauf besser zu verstehen, müssen Sie herausfinden, warum das Umschreiben der Geschichte überhaupt schlecht ist.
Dazu benötigen wir wiederum einen kurzen Ausflug in die physische Struktur des Git-Repositorys. Wenn Sie sicher sind, dass Sie alles über das Repo-Gerät wissen, können Sie diesen Teil überspringen, aber selbst als ich es herausfand, habe ich eine Menge neuer Dinge für mich selbst gelernt, und etwas Altes hat sich als nicht ganz relevant herausgestellt.
Auf der untersten Ebene ist ein Git-Repo eine Sammlung von Objekten und Zeigern auf diese. Jedes Objekt verfügt über einen eigenen 40-stelligen Hash (20 hexadezimale Bytes), der basierend auf dem Inhalt des Objekts berechnet wird.
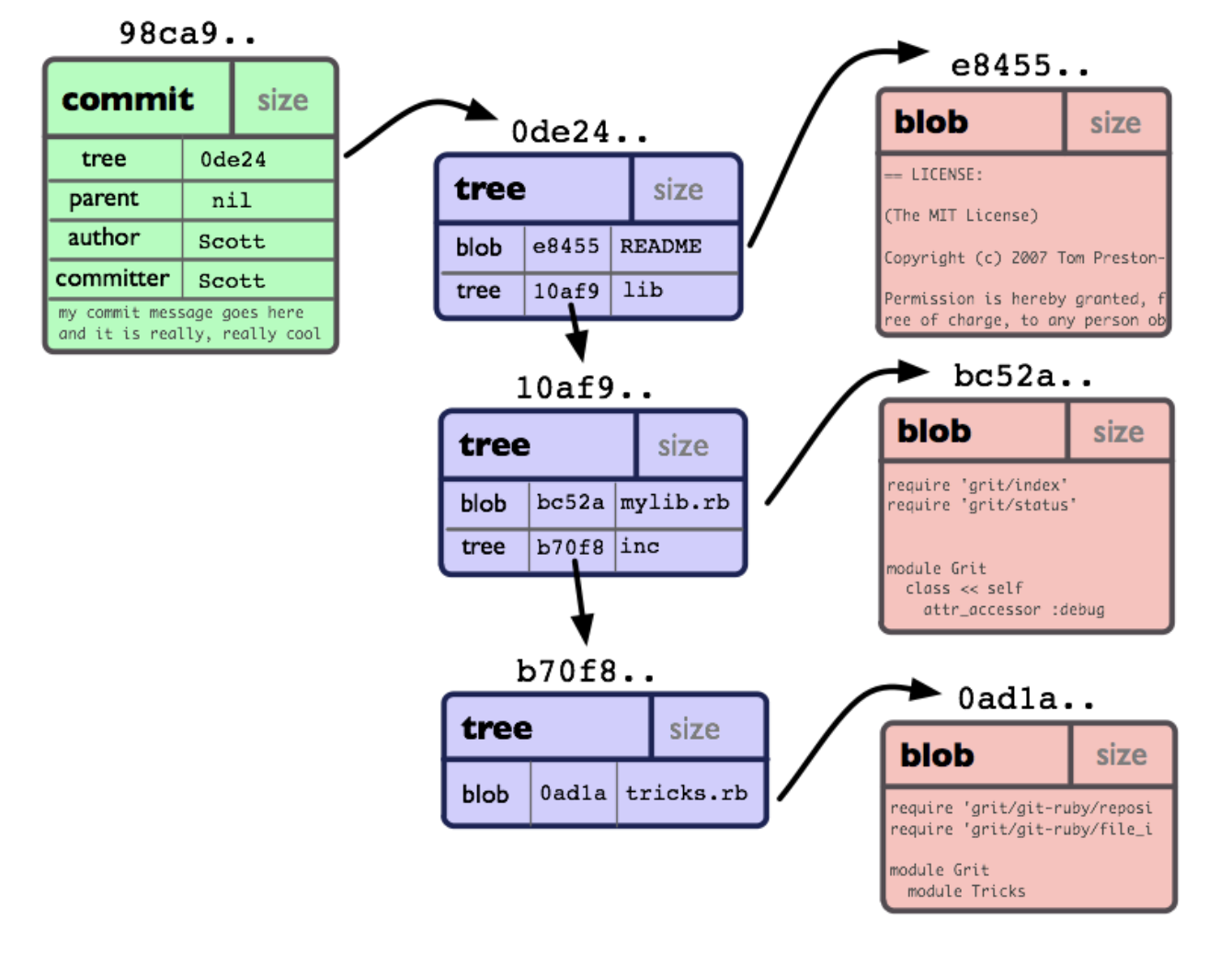
Abbildung aus dem Git Community Book
Die Hauptobjekttypen sind Blob (nur der Inhalt einer Datei), Tree (eine Sammlung von Zeigern auf Blobs und andere Bäume) und Commit. Ein Objekt vom Typ Commit ist nur ein Zeiger auf den Baum, auf das vorherige Commit und auf Serviceinformationen: Datum / Uhrzeit, Autor und Kommentar.
Wo sind die Zweige und Tags, mit denen wir gewohnt sind? Und sie sind keine Objekte, sie sind nur Zeiger: Ein Zweig zeigt auf das letzte Commit darin, ein Tag zeigt auf ein beliebiges Commit im Repo. Das heißt, wenn wir im IDE- oder GUI-Client wunderschön gezeichnete Zweige mit Festschreibungskreisen sehen, werden diese im laufenden Betrieb erstellt und verlaufen entlang der Festschreibungsketten von den Enden der Zweige bis zur "Wurzel". Das allererste Commit im Repo hat kein vorheriges, anstelle eines Zeigers gibt es null.
Ein wichtiger Punkt, den Sie verstehen sollten: Das gleiche Commit kann in mehreren Zweigen gleichzeitig angezeigt werden. Die Commits werden nicht kopiert, wenn ein neuer Zweig erstellt wird. Er "wächst" nur an der Stelle, an der sich HEAD zum Zeitpunkt der Befehlsausgabe befand
git checkout -b <branch-name>.
Warum ist das Umschreiben des Verlaufs eines Repositorys schädlich?

Erstens, und dies ist offensichtlich, wenn Sie eine neue Story in das Repository hochladen, mit dem das Engineering-Team arbeitet, verlieren andere Personen möglicherweise nur ihre Änderungen. Der Befehl
git push -f entfernt alle Commits, die nicht in der lokalen Version enthalten sind, aus dem Zweig auf dem Server und schreibt neue.
Aus irgendeinem Grund wissen nur wenige, dass das Team lange Zeit
git pusheinen "sicheren" Schlüssel hat--force-with-leaseDies führt dazu, dass der Befehl fehlschlägt, wenn Commits von anderen Benutzern zum Remote-Repository hinzugefügt werden. Ich empfehle immer, es stattdessen zu verwenden -f/--force.
Der zweite Grund, warum der Befehl
git push -fals schädlich eingestuft wird, besteht darin, dass beim Versuch, einen Zweig mit dem umgeschriebenen Verlauf mit den Zweigen zusammenzuführen, in denen er aufbewahrt wurde (genauer gesagt, die aus dem umgeschriebenen Verlauf entfernten Commits wurden beibehalten), eine verdammt große Anzahl von Konflikten auftritt (anhand der Anzahl) begeht eigentlich). Darauf gibt es eine einfache Antwort: Wenn Sie Gitflow oder Gitlab Flow genau befolgen, treten solche Situationen höchstwahrscheinlich nicht einmal auf.
Und schließlich gibt es eine unangenehme Seite beim Umschreiben der Geschichte: Die Commits, die sozusagen aus dem Zweig entfernt werden, verschwinden tatsächlich nirgendwo und bleiben einfach für immer im Repo hängen. Eine Kleinigkeit, aber unangenehm. Glücklicherweise haben die Git-Entwickler dieses Problem auch mit dem Befehl garbage collection behoben
git gc --prune. Die meisten Git-Hosts, zumindest GitHub und GitLab, tun dies von Zeit zu Zeit im Hintergrund.
Nachdem wir die Befürchtungen zerstreut haben, die Geschichte des Endlagers zu ändern, können wir endlich zur Hauptfrage übergehen: Warum wird es benötigt und wann ist es gerechtfertigt?
Tatsächlich bin ich mir sicher, dass fast jeder mehr oder weniger aktive Git-Benutzer den Verlauf mindestens einmal geändert hat, als sich plötzlich herausstellte, dass beim letzten Commit etwas schief gelaufen ist: Ein nerviger Tippfehler hat sich in den Code eingeschlichen und das Commit falsch gemacht Benutzer (aus persönlicher E-Mail statt Arbeit oder umgekehrt) hat vergessen, eine neue Datei hinzuzufügen (wenn Sie, wie ich, gerne verwenden
git commit -a). Selbst das Ändern der Beschreibung eines Commits führt dazu, dass es neu geschrieben werden muss, da der Hash auch aus der Beschreibung gezählt wird!
Dies ist jedoch ein trivialer Fall. Schauen wir uns interessantere an.
Angenommen, Sie haben eine große Funktion erstellt, die Sie mehrere Tage lang gesägt haben, indem Sie die täglichen Arbeitsergebnisse an das Repository auf dem Server gesendet haben (4-5 Commits) und Ihre Änderungen zur Überprüfung gesendet haben. Zwei oder drei unermüdliche Rezensenten haben Sie mit großen und kleinen Empfehlungen für Änderungen überschüttet oder sogar Pfosten gefunden (4-5 weitere Commits). Dann fand die Qualitätssicherung mehrere Randfälle, für die ebenfalls Korrekturen erforderlich sind (2-3 weitere Commits). Und schließlich wurden während der Integration einige Inkompatibilitäten festgestellt oder Autotests durchgeführt, die ebenfalls behoben werden müssen.
Wenn Sie jetzt die Schaltfläche "Zusammenführen" drücken, ohne zu schauen, werden dem Hauptzweig anderthalb Dutzend Commits wie "Meine Funktion, Tag 1", "Tag 2", "Fix-Tests" und "Fix-Überprüfung" hinzugefügt (für viele wird es auf altmodische Weise als Master bezeichnet). usw. Dies hilft natürlich dem Squash-Modus, der jetzt sowohl in GitHub als auch in GitLab verfügbar ist, aber Sie müssen vorsichtig damit sein: Erstens kann die Commit-Beschreibung durch etwas Unvorhersehbares ersetzt werden, und zweitens kann der Autor der Funktion ersetzt werden auf denjenigen, der die Schaltfläche "Zusammenführen" gedrückt hat (wir haben im Allgemeinen einen Roboter, der dem Release-Ingenieur hilft, den heutigen Einsatz zusammenzubauen). Daher ist es am einfachsten, vor der endgültigen Integration in das Release alle Commits des Zweigs mit einem zu einem einzigen zusammenzufassen
git rebase.
Es kommt aber auch vor, dass Sie sich der Codeüberprüfung bereits mit einer Repo-Historie genähert haben, die an Olivier-Salat erinnert. Dies geschieht, wenn ein Feature mehrere Wochen lang gesägt wurde, weil es schlecht zerlegt wurde, oder obwohl anständige Teams dafür mit einem Kandelaber geschlagen werden, haben sich die Anforderungen während des Entwicklungsprozesses geändert. Hier ist zum Beispiel eine echte Zusammenführungsanforderung, die ich vor zwei Wochen zur Überprüfung erhalten habe:
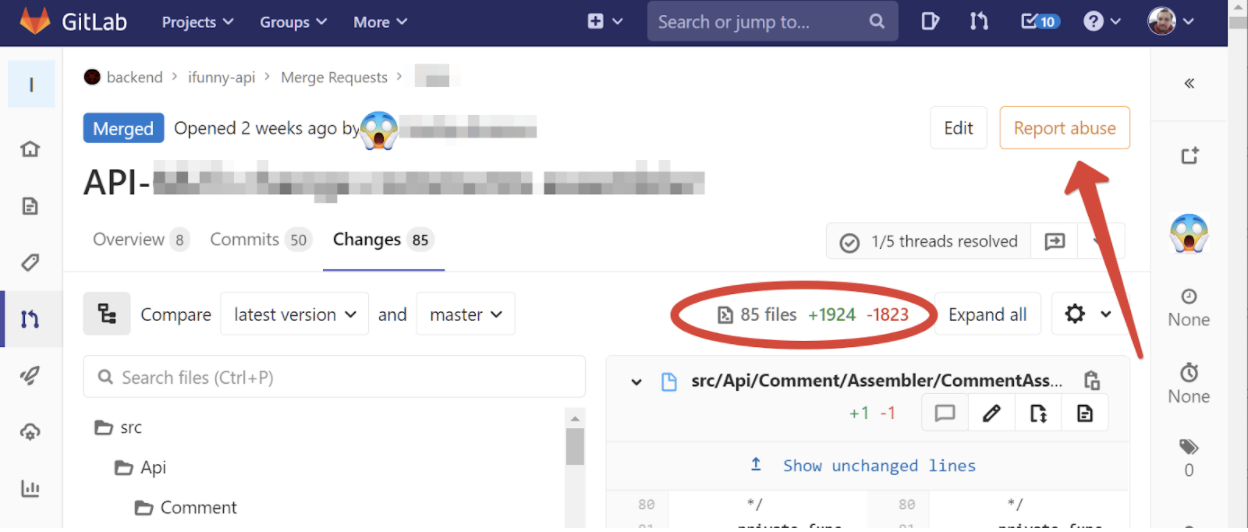
Meine Hand griff automatisch nach der Schaltfläche "Missbrauch melden". Wie sonst können Sie eine Anforderung von 50 Commits mit fast 2000 geänderten Zeilen charakterisieren? Und wie, fragt man sich, kann man das überprüfen?
Um ehrlich zu sein, habe ich zwei Tage gebraucht, um mich zu zwingen, mit dieser Überprüfung zu beginnen. Und das ist eine normale Reaktion für einen Ingenieur. Jemand in einer ähnlichen Situation, nur ohne hinzuschauen, drückt auf Genehmigen und stellt fest, dass er in angemessener Zeit immer noch nicht in der Lage sein wird, diese Änderung mit ausreichender Qualität zu überprüfen.
Aber es gibt eine Möglichkeit, einem Freund das Leben zu erleichtern. Zusätzlich zu den Vorarbeiten zur besseren Zerlegung des Problems können Sie nach Abschluss des Schreibens des Hauptcodes die Geschichte seines Schreibens in eine logischere Form bringen und es in atomare Commits mit jeweils grünen Tests aufteilen: "Einen neuen Dienst und eine Transportschicht dafür erstellen", "Modelle erstellen und schreiben" Überprüfen von Invarianten "," Validierung und Ausnahmebehandlung hinzugefügt "," Tests geschrieben ".
Jedes dieser Commits kann separat überprüft werden (sowohl GitHub als auch GitLab können dies tun) und dies bei Raids beim Wechsel zwischen Aufgaben oder in Pausen.
Das gleiche
git rebasemit dem Schlüssel wird uns dabei helfen --interactive. Als Parameter müssen Sie den Hash des Commits übergeben, aus dem Sie den Verlauf neu schreiben müssen. Wenn es sich um die letzten 50 Commits handelt, wie im Beispiel auf dem Bild, können Sie schreiben git rebase --interactive HEAD~50(ersetzen Sie „50“ durch Ihre Nummer).
Übrigens, wenn Sie den Master-Zweig während der Arbeit an einer Aufgabe zu sich selbst hinzugefügt haben, müssen Sie diesen Zweig zunächst neu gründen, damit Zusammenführungs-Commits und Commits vom Master nicht unter Ihren Füßen verwechselt werden.
Mit dem Wissen über die Interna eines Git-Repositorys sollte es leicht zu verstehen sein, wie Rebase auf Master funktioniert. Dieser Befehl übernimmt alle Festschreibungen in unserer Verzweigung und ändert die übergeordnete Festschreibung der ersten in die letzte Festschreibung in der Hauptverzweigung. Siehe Abbildung:
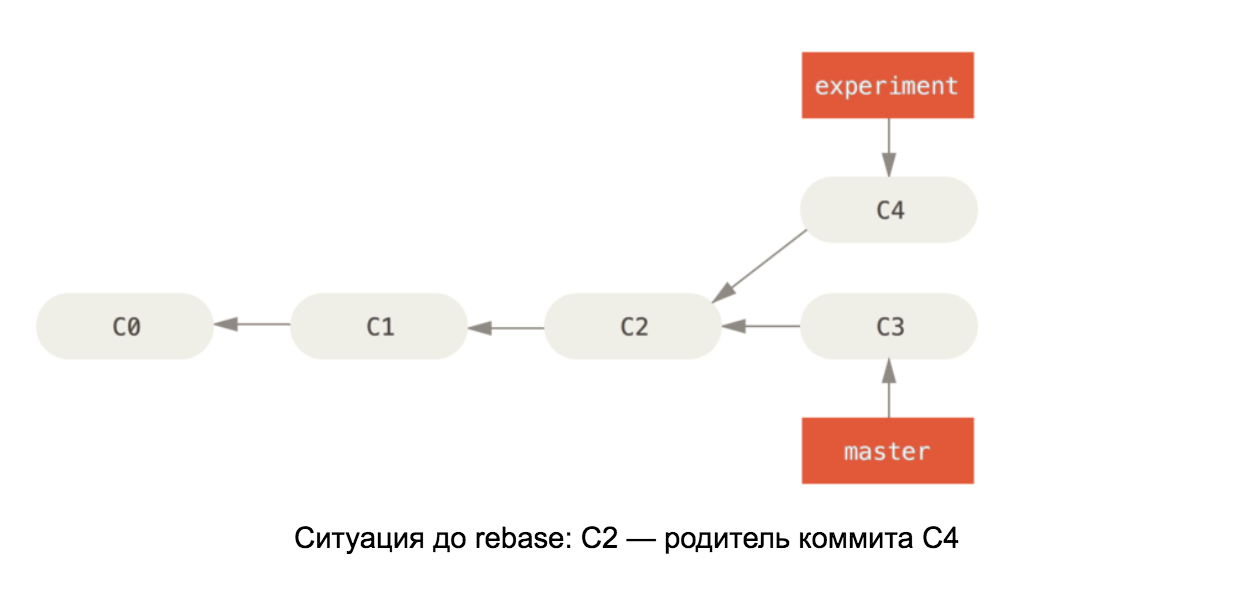
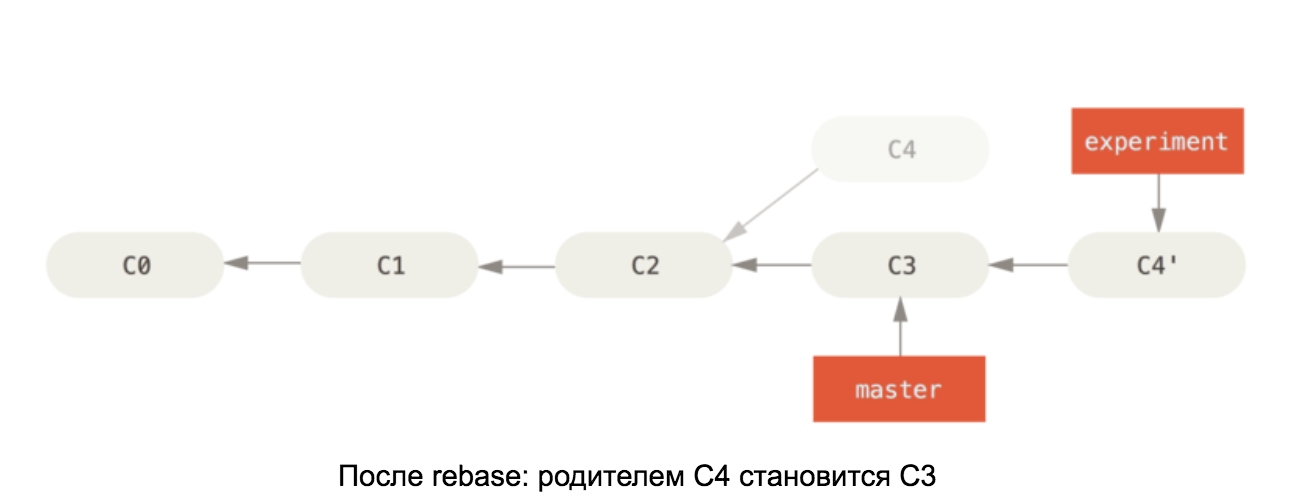
Abbildungen stammen aus dem Buch Pro Git.
Wenn sich der C4- und C3-Konflikt ändert, ändert Commit C4 nach Behebung des Konflikts seinen Inhalt, sodass er im zweiten Diagramm in C4 'umbenannt wird.
Auf diese Weise erhalten Sie einen Zweig, der nur aus Ihren Änderungen besteht und von der Spitze des Masters wächst. Natürlich muss der Master auf dem neuesten Stand sein. Sie können einfach die Version vom Server verwenden:
git pull --rebase origin/master(Wie Sie wissen, ist dies git pulläquivalent git fetch && git merge, und der Schlüssel --rebaseerzwingt, dass git neu zusammengesetzt wird, anstatt zusammengeführt zu werden).
Kehren wir endlich zurück zu
git rebase --interactive... Es wurde von Programmierern für Programmierer erstellt. Als wir erkannten, welchen Stress die Menschen in diesem Prozess erleben werden, versuchten wir, die Nerven des Benutzers so weit wie möglich zu erhalten und ihn vor der Notwendigkeit zu bewahren, sich übermäßig anzustrengen. Folgendes sehen Sie auf dem Bildschirm:
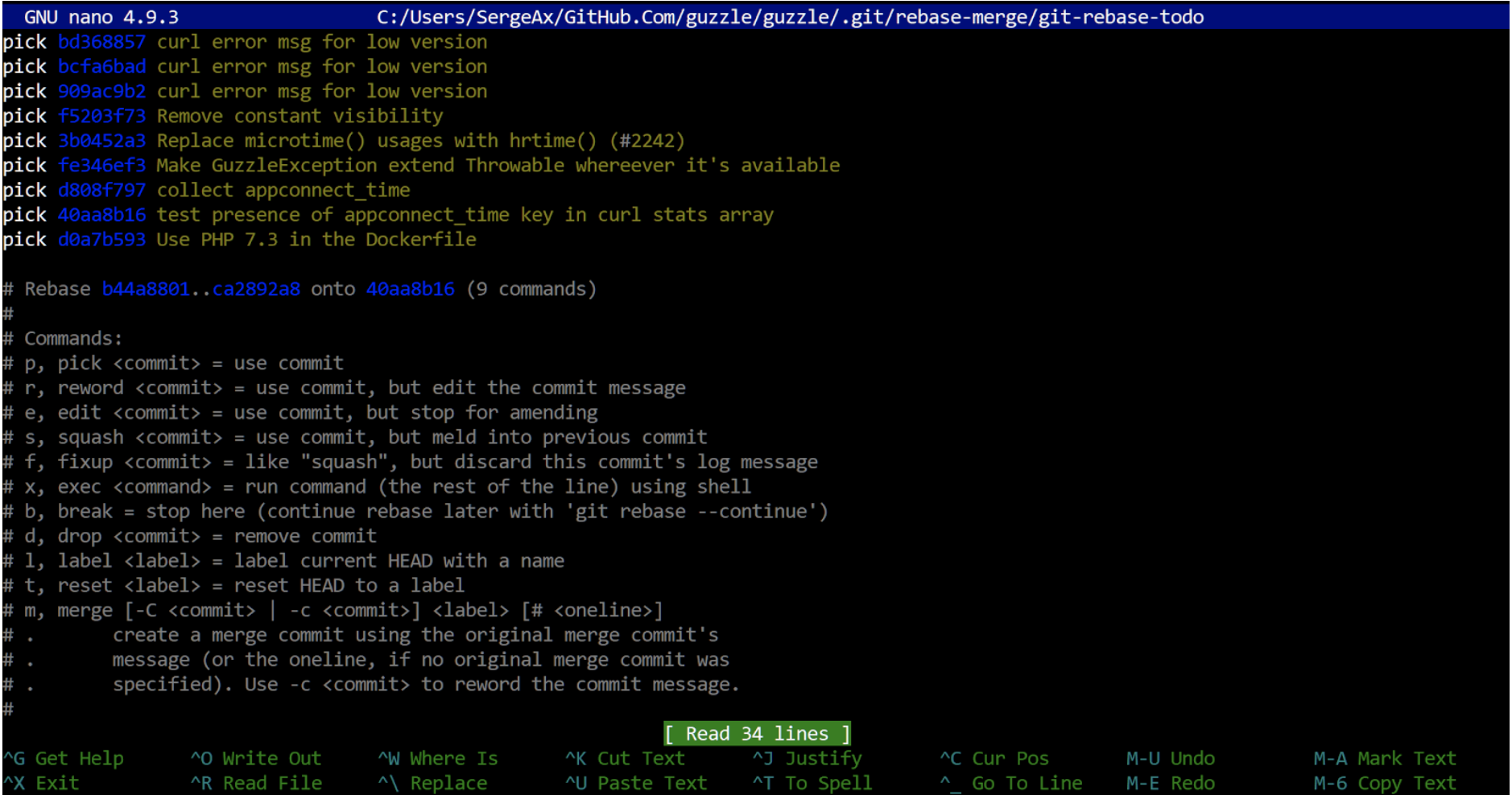
Dies ist das Repository des beliebten Guzzle-Pakets. Es sieht so aus, als könnte er eine Rebase gebrauchen ...
Die generierte Datei wird in einem Texteditor geöffnet. Nachfolgend finden Sie detaillierte Informationen dazu, was zu tun ist. Als Nächstes entscheiden Sie im einfachen Bearbeitungsmodus, was mit den Commits in Ihrer Branche geschehen soll. Alles ist so einfach wie ein Stick: auswählen - belassen, wie es ist, umformulieren - Commit-Beschreibung ändern, Squash-Merge mit dem vorherigen (der Vorgang funktioniert von unten nach oben, dh der vorherige ist die Zeile darunter), ablegen - löschen, zusammen bearbeiten - und das ist Das Interessante ist, anzuhalten und einzufrieren. Nachdem git auf den Bearbeitungsbefehl gestoßen ist, nimmt es die Position ein, an der die Änderungen im Commit bereits zum Staged-Modus hinzugefügt wurden. Sie können alles in diesem Commit ändern, ein paar weitere hinzufügen und dann befehlen
git rebase --continue, den Rebase-Prozess fortzusetzen.
Oh, und übrigens, Sie können Commits tauschen. Dies kann zu Konflikten führen, aber im Allgemeinen ist der Rebase-Prozess selten vollständig konfliktfrei. Wie sie sagen, nachdem sie ihren Kopf abgenommen haben, weinen sie nicht um ihre Haare.
Wenn Sie verwirrt sind und es den Anschein hat, dass alles weg ist, haben Sie einen Notauswurfknopf
git rebase --abort, der sofort alles zurückgibt.
Sie können die Rebase mehrmals wiederholen, indem Sie nur Teile der Geschichte berühren und den Rest unberührt lassen, um Ihrer Geschichte ein immer fertigeres Aussehen zu verleihen, wie bei einem Töpferkrug. Wie ich oben geschrieben habe, ist es eine gute Praxis, sicherzustellen, dass die Tests in jedem Commit grün sind (hierfür hilft die Bearbeitung perfekt und beim nächsten Durchgang - Squash).
Ein weiterer Kunstflug, der nützlich ist, wenn Sie mehrere Änderungen in derselben Datei in verschiedene Commits zerlegen müssen -
git add --patch. Es kann für sich genommen nützlich sein, aber in Kombination mit der Bearbeitungsanweisung können Sie ein Commit in mehrere aufteilen und dies auf der Ebene einzelner Zeilen tun, was, wenn ich mich nicht irre, kein GUI-Client und keine IDE nicht zulässt.
Wenn Sie wieder sicherstellen, dass alles in Ordnung ist, können Sie endlich beruhigt etwas tun, was dieses Tutorial gestartet hat :
git push --force. Oh, das ist natürlich --force-with-lease!

Zuerst werden Sie höchstwahrscheinlich eine Stunde für diesen Prozess aufwenden (einschließlich der anfänglichen Rebase auf dem Master) oder sogar zwei, wenn sich die Funktion wirklich ausbreitet. Aber selbst das ist viel besser, als zwei Tage darauf zu warten, dass sich der Rezensent zwingt, Ihre Anfrage endgültig anzunehmen, und noch ein paar Tage, bis er fertig ist. In Zukunft werden Sie höchstwahrscheinlich in 30-40 Minuten passen. Besonders hilfreich sind dabei IntelliJ-Produkte mit integriertem Konfliktlösungstool (vollständige Offenlegung: FunCorp zahlt diese Produkte an seine Mitarbeiter).
Das Letzte, vor dem ich Sie warnen möchte, ist, den Zweigverlauf während der Codeüberprüfung nicht neu zu schreiben. Denken Sie daran, dass ein gewissenhafter Prüfer Ihren Code möglicherweise lokal klonen kann, um ihn über die IDE anzeigen und Tests ausführen zu können.
Vielen Dank für Ihre Aufmerksamkeit an alle, die bis zum Ende gelesen haben! Ich hoffe, dass dieser Artikel nicht nur für Sie nützlich ist, sondern auch für Kollegen, die Ihren Code zur Überprüfung erhalten. Wenn Sie einige coole Git-Hacks haben - teilen Sie sie in den Kommentaren!