
Seit der Erfindung seiner ersten GPU im Jahr 1999 ist NVIDIA führend in der Entwicklung von 3D-Grafiken und GPU-beschleunigtem Computing. Jede NVIDIA-Architektur wurde sorgfältig entwickelt, um ein revolutionäres Maß an Leistung und Effizienz zu erzielen.
Die A100, die erste GPU mit NVIDIA Ampere-Architektur, wurde im Mai 2020 veröffentlicht. Es bietet eine enorme Beschleunigung für KI-Training, HPC und Datenanalyse. Der A100 basiert auf dem GA100-Chip, der rein rechnerisch ist und im Gegensatz zum GA102 noch nicht spielt.
GA10x-GPUs basieren auf der NVIDIA Turing-GPU-Architektur. Turing ist die erste Architektur der Welt, die leistungsstarkes Echtzeit-Raytracing, AI-beschleunigte Grafiken und professionelles Grafik-Rendering bietet - alles in einem Gerät.
In diesem Artikel werden die wichtigsten Änderungen in der Architektur der neuen NVIDIA-Grafikkarten im Vergleich zum Vorgänger analysiert.

Abbildung 1. Ampere GA10x-Architektur
Hauptmerkmale von GA102
GA102 wird mit NVIDIA-eigener 8-nm-Technologie hergestellt - 8N NVIDIA Custom. Der Chip enthält 28,3 Milliarden Transistoren auf einem 628,4 mm2 Chip. Wie bei allen GeForce RTXs basiert der GA102 auf einem Prozessor, der drei verschiedene Arten von Computerressourcen enthält:
- CUDA-Kernel für programmierbares Shading;
- RT-, (BVH) ;
- , .
Ampere
GPC, TPC SM
Wie seine Vorgänger besteht der GA102 aus Grafikverarbeitungsclustern (GPCs), Texturverarbeitungsclustern (TPCs), Streaming-Multiprozessoren (SM), Rasteroperator-ROPs (ROPs) und Speichercontrollern. Der komplette Chip verfügt über sieben GPC-Einheiten, 42 TPCs und 84 SMs.
Der GPC ist der dominierende High-Level-Block, der alle wichtigen Grafiken enthält. Jeder GPC verfügt über eine dedizierte Raster-Engine und verfügt nun auch über zwei ROP-Abschnitte mit jeweils acht Blöcken. Dies ist eine Innovation in der Ampere-Architektur. Darüber hinaus enthält die GPC sechs TPCs mit jeweils zwei Multiprozessoren und einer PolyMorph-Engine.
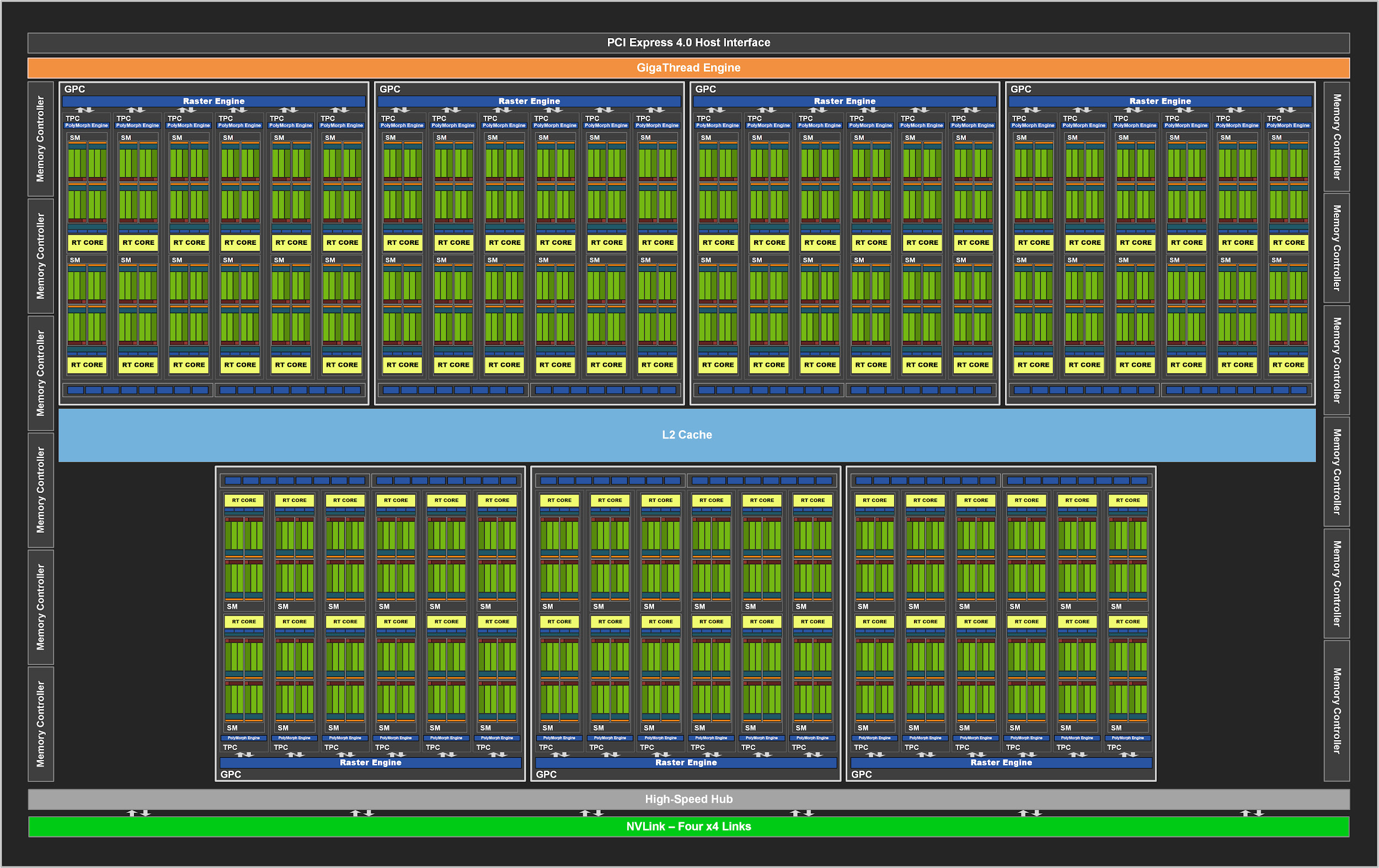
Abbildung 2. Vervollständigen Sie die GPU GA102 mit 84 SM-Blöcken
Jeder SM im GA10x enthält wiederum 128 CUDA-Kerne, vier Tensorkerne der dritten Generation, eine 256-KB-Registerdatei, vier Textureinheiten, einen Raytracing-Kern der zweiten Generation und 128 KB L1 / Shared Memory, die für unterschiedliche Kapazitäten konfiguriert werden können. abhängig von den Anforderungen von Computer- oder Grafikaufgaben.
ROP-Optimierung
In früheren NVIDIA-GPUs waren ROPs an einen Speichercontroller und einen L2-Cache gebunden. Ab GA10x sind sie Teil des GPC, der die Rasterleistung verbessert, indem die Gesamtzahl der ROPs erhöht wird.
Insgesamt besteht die GA102-GPU mit sieben GPCs und 16 ROPs in jeder GPC aus 112 ROPs anstelle von 96, beispielsweise in der TU102. Dies alles wirkt sich positiv auf das Multisample-Anti-Aliasing, die Pixelfüllrate und das Mischen aus.
NVLink dritte Generation
Die GA102-GPUs unterstützen NVIDIA NVLink der dritten Generation, der vier x4-Lanes umfasst und jeweils eine Bandbreite von 14,0625 GB / s zwischen zwei GPUs in beide Richtungen bietet. Die vier Kanäle zusammen ergeben eine Bandbreite von 56,25 GB / s in jede Richtung und insgesamt 112,5 GB / s zwischen den beiden GPUs. Mit NVLink können also zwei RTX 3090-GPUs verbunden werden.
PCIe Gen 4
Die GA10x-GPUs sind mit PCI Express 4.0 ausgestattet, das die doppelte Bandbreite von PCIe 3.0, Übertragungsraten von bis zu 16GTransfers pro Sekunde und dank des x16 PCIe 4.0-Steckplatzes eine Spitzenbandbreite von 64 GB / s bietet.
GA10x Multiprozessor-Architektur
Die Turing-Multiprozessor-Architektur war die erste bei NVIDIA, die über separate Kerne verfügte, um Raytracing-Vorgänge zu beschleunigen. Dann führte Volta die ersten Tensorkerne ein, und Turing führte fortschrittliche Tensorkerne der zweiten Generation ein. Eine weitere Innovation bei Turing und Volta ist die Möglichkeit, FP32- und INT32-Operationen gleichzeitig auszuführen. Der Multiprozessor in GA10x unterstützt alle oben genannten Funktionen und verfügt über eine Reihe eigener Verbesserungen.
Im Gegensatz zur TU102 mit acht Tensorkernen der zweiten Generation verfügt der GA10x-Multiprozessor über vier Tensorkerne der dritten Generation, wobei jeder GA10x-Tensorkern doppelt so leistungsstark ist wie Turing.
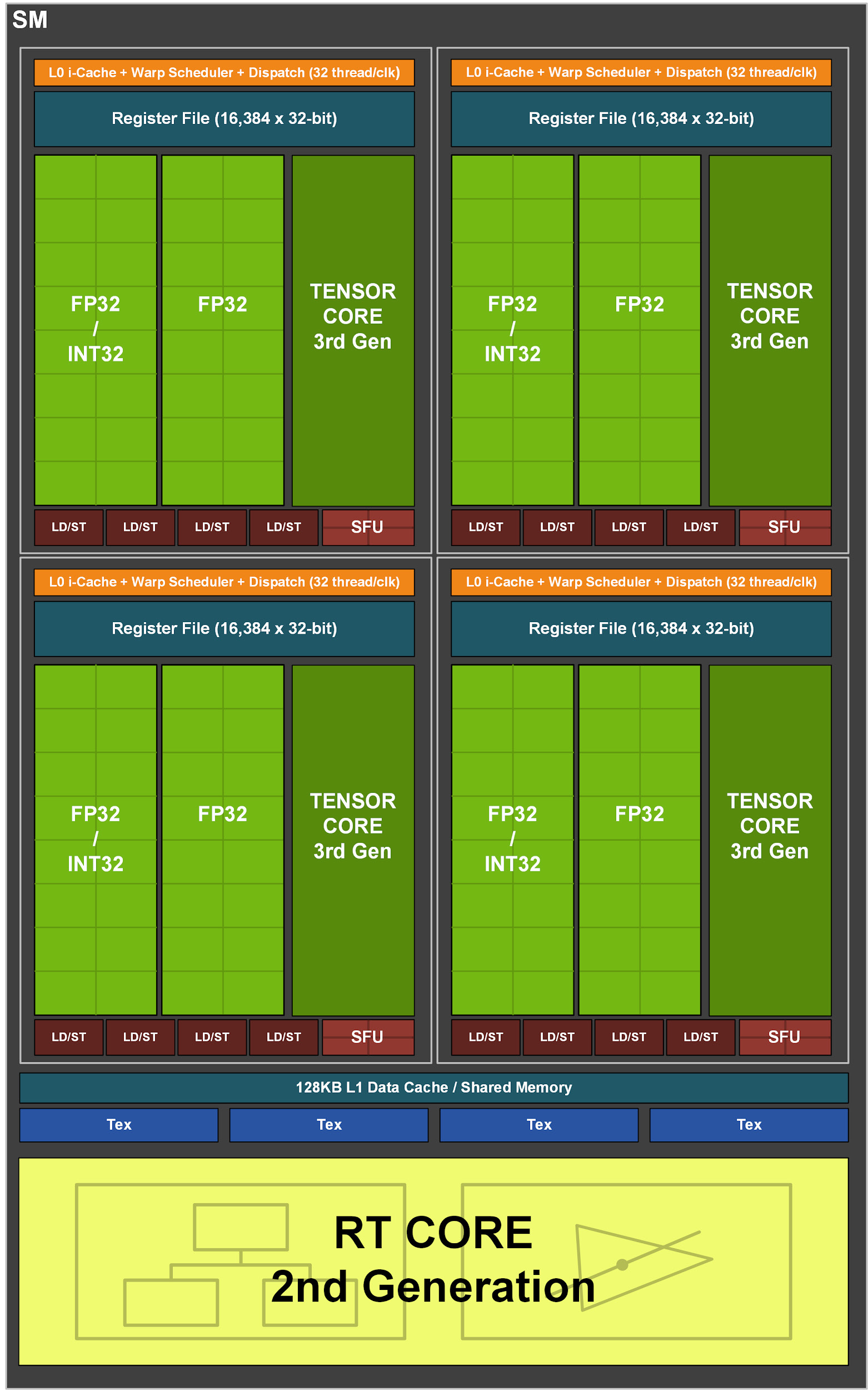
Abbildung 3. GA10x-Streaming-Multiprozessor
Verdoppeln Sie die Geschwindigkeit des FP32-Computing
Die meisten Grafikberechnungen sind 32-Bit-Gleitkommaoperationen (FP32). Der Ampere GA10x Streaming Multiprocessor bietet auf beiden Datenkanälen die doppelte Geschwindigkeit von FP32-Operationen. Infolgedessen bietet die GeForce RTX 3090 im Kontext von FP32 mehr als 35 Teraflops, was mehr als dem Zweifachen der Fähigkeiten von Turing entspricht.
Der GA10X kann 128 FP32-Operationen oder 64 FP32-Operationen und 64 INT32-Operationen pro Takt ausführen, was der doppelten Geschwindigkeit von Turing-Berechnungen entspricht.
Moderne Spieleaufgaben haben ein breites Spektrum an Verarbeitungsanforderungen. Viele Berechnungen erfordern eine Reihe von FP32-Operationen (wie FFMA, Gleitkommaaddition (FADD) oder Gleitkommamultiplikation (FMUL)) sowie viele einfachere Ganzzahlberechnungen.
GA10x-Multiprozessoren unterstützen weiterhin FP16-Vorgänge (Dual Speed FP16), die auch in Turing unterstützt wurden. Ähnlich wie bei den GPUs TU102, TU104 und TU106 werden beim GA10x auch Standard-FP16-Operationen von Tensorkernen ausgeführt.
Shared Memory und L1-Datencache
GA10x verfügt über eine einheitliche Architektur für gemeinsam genutzten Speicher, L1-Datencache und Texturcache. Dieses einheitliche Design kann je nach Arbeitslast und Anforderungen geändert werden.
Der GA102-Chip enthält 10.752 KB L1-Cache (im Vergleich zu 6912 KB in der TU102). Abgesehen davon hat der GA10x im Vergleich zu Turing die Bandbreite des gemeinsam genutzten Speichers verdoppelt (128 Byte / Zyklus gegenüber 64 Byte / Zyklus). Die gesamte L1-Bandbreite für die GeForce RTX 3080 beträgt 219 GB / s gegenüber 116 GB / s für die GeForce RTX 2080 Super.
Leistung pro Watt
Die gesamte NVIDIA Ampere-Architektur ist auf Effizienz ausgelegt - von Logik-, Speicher-, Strom- und Wärmemanagement bis hin zu PCB-Design, Software und Algorithmen. Bei gleichem Leistungsniveau sind Ampere-GPUs bis zu 1,9-mal energieeffizienter als vergleichbare Turing-Geräte.
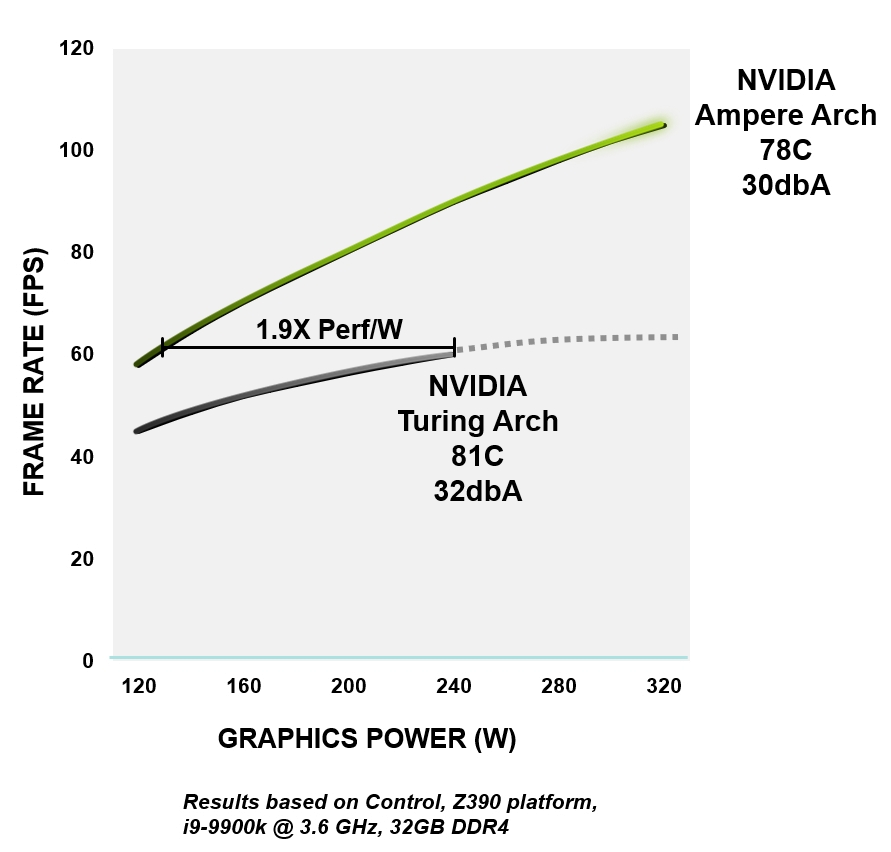
Abbildung 4. Energieeffizienz des RTX 3080 im Vergleich zur GeForce RTX 2080 Super-Architektur
RT-Kerne der zweiten Generation
Die neuen RT-Kerne verfügen über eine Reihe von Verbesserungen, die in Kombination mit aktualisierten Caching-Systemen die Raytracing-Leistung von Ampere-Prozessoren gegenüber Turing effektiv verdoppeln. Darüber hinaus ermöglicht der GA10x die gleichzeitige Ausführung anderer Prozesse mit RT-Computing, wodurch viele Aufgaben erheblich beschleunigt werden.
Raytracing der zweiten Generation in GA10x
GeForce RTX basierend auf der Turing-Architektur waren die ersten GPUs, mit denen die Verfolgung von Filmstrahlen in PC-Spielen Realität wurde. Der GA10x ist mit der Raytracing-Technologie der zweiten Generation ausgestattet. Wie Turing verfügen auch die Multiprozessoren des GA10x über spezielle Hardwareblöcke, um nach Strahlschnittpunkten mit BVHs und Dreiecken zu suchen. Gleichzeitig haben die Kerne der Ampere-Multiprozessoren im Vergleich zu Turing die doppelte Geschwindigkeit, um den Schnittpunkt von Strahlen und Dreiecken zu testen.
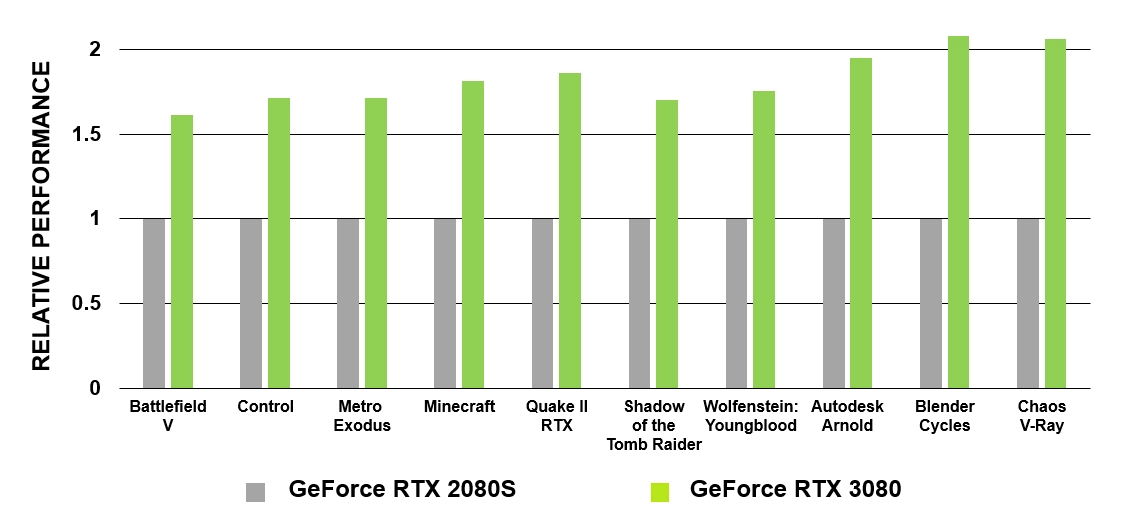
Abbildung 5. Vergleich der Leistung von RT-Kernen von GeForce RTX 3080 und GeForce RTX 2080 Super
Der GA10x-Multiprozessor kann Operationen gleichzeitig ausführen und ist nicht auf Berechnungen und Grafiken beschränkt, wie dies bei früheren GPU-Generationen der Fall war. So kann beispielsweise in GA10x der Rauschreduzierungsalgorithmus gleichzeitig mit der Strahlverfolgung ausgeführt werden.

Abbildung 6. RT Core der zweiten Generation in GA10x-GPUs
Beachten Sie, dass RT-intensive Workloads die Belastung der Multiprozessorkerne nicht wesentlich erhöhen, sodass die Multiprozessor-Verarbeitungsleistung für andere Aufgaben verwendet werden kann. Dies ist ein großer Vorteil gegenüber anderen konkurrierenden Architekturen, die keine dedizierten RT-Kerne haben und daher ihre Bausteine sowohl für Grafiken als auch für Raytracing verwenden müssen.
Ampere RTX-Prozessoren in Aktion
Raytracing und Shader sind rechenintensiv. Es wäre jedoch viel teurer, alles nur mit CUDA-Kernen zu betreiben, sodass die Einbeziehung von Tensor- und RT-Kernen die Verarbeitung erheblich beschleunigt. Abbildung 7 zeigt ein Beispiel für Wolfenstein: Jungblut mit aktivierter Raytracing-Funktion in verschiedenen Szenarien.
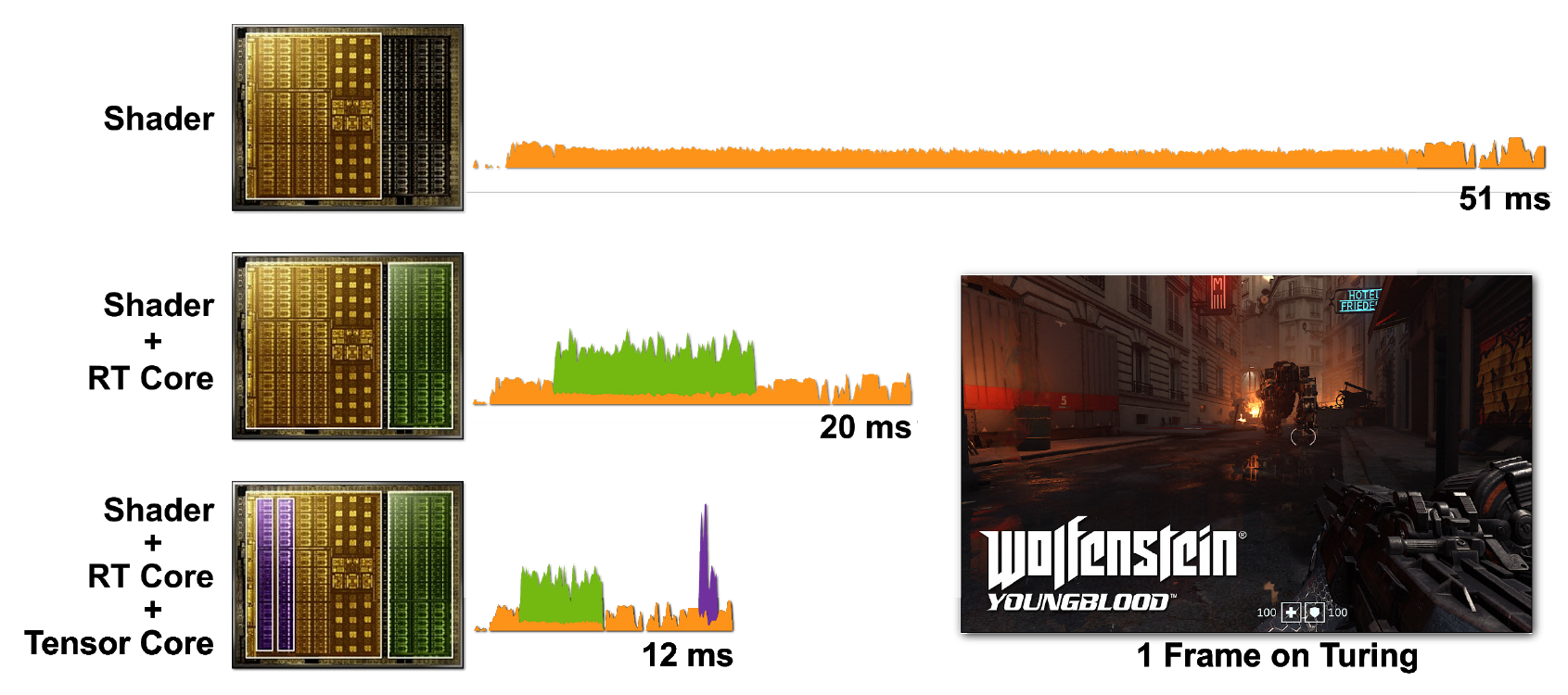
Abbildung 7. Rendern eines einzelnen Wolfenstein-Frames: Youngblood auf einer RTX 2080 Super-GPU mit a) Shader-Kernen (CUDA), b) Shader-Kernen und RT-Kernen, c) Shader-Kernen, Tensorkernen und RT-Kernen. Beachten Sie die zunehmend kürzeren Frame-Zeiten, wenn Sie die Leistung der verschiedenen RTX-Prozessorkerne hinzufügen.
Im ersten Fall dauert es 51 ms (~ 20 fps), um einen Frame zu starten. Wenn RT-Kerne eingeschaltet sind, wird der Frame viel schneller gerendert - in 20 ms (50 fps). Die Verwendung von DLSS auf Tensorkernen reduziert die Frame-Zeit auf 12 ms (~ 83 fps).
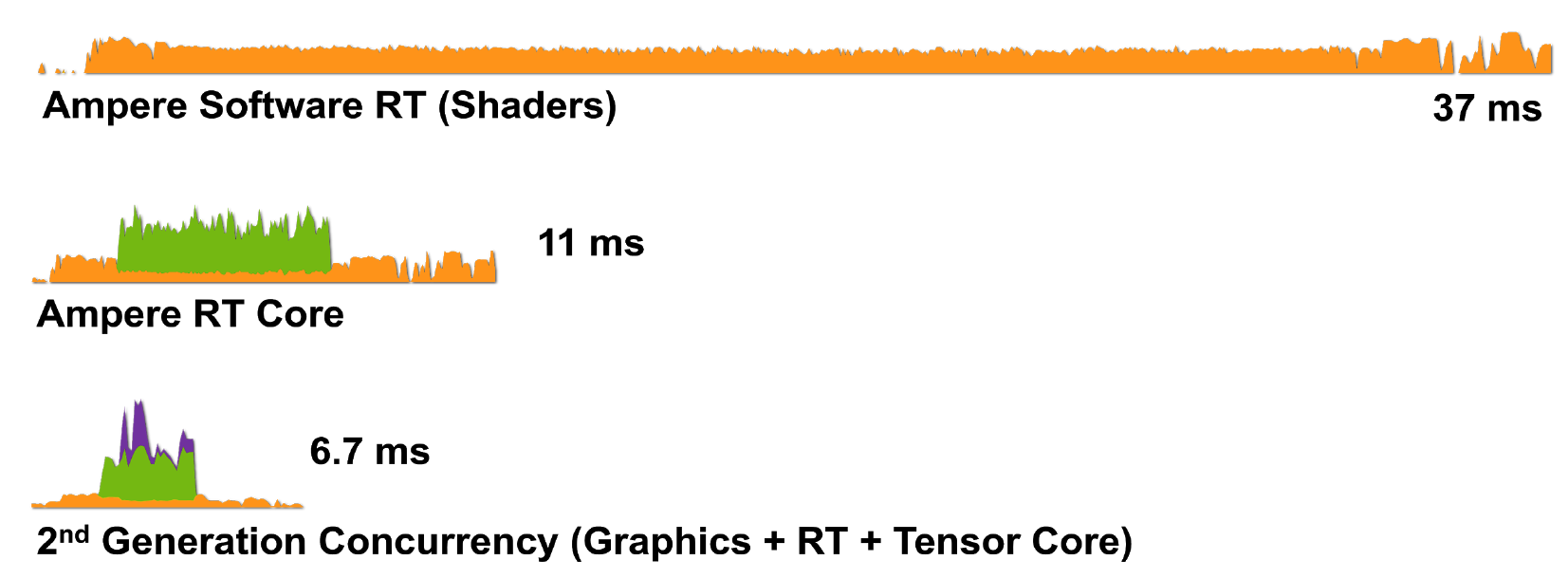
Abbildung 8. Rendern eines einzelnen Frames von Wolfenstein: Youngblood auf einem RTX 3080 mit a) Shader-Kernen (CUDA), b) Shader-Kernen und RT-Kernen, c) Shader-Kernen, Tensorkernen und RT-Kernen.
Die RTX-Technologie mit Ampere-Architektur erledigt Rendering-Aufgaben noch effizienter: Der RTX 3080 rendert einen Frame in 6,7 ms (150 fps), was eine enorme Verbesserung gegenüber dem RTX 2080 darstellt.
Hardwarebeschleunigte Raytracing-Funktion mithilfe von Bewegungsunschärfe
Bewegungsunschärfe ist eine Bewegung, die häufig in der Computergrafik verwendet wird. Ein fotografisches Bild wird nicht sofort erstellt, sondern indem der Film für einen begrenzten Zeitraum Licht ausgesetzt wird. Motive, die sich im Vergleich zur Belichtungszeit der Kamera schnell genug bewegen, werden auf dem Foto als Streifen oder Flecken angezeigt. Damit die GPU eine realistisch aussehende Bewegungsunschärfe erzeugt, wenn sich Objekte in einer Szene schnell vor einer statischen Kamera bewegen, muss sie simulieren können, wie Kamera und Film mit solchen Szenen funktionieren. Bewegungsunschärfe ist beim Filmemachen besonders wichtig, da Filme mit 24 Bildern pro Sekunde wiedergegeben werden und eine Szene ohne Bewegungsunschärfe scharf und abgehackt erscheint.
Turing-GPUs beschleunigen die Bewegungsunschärfe im Allgemeinen recht gut. Bei bewegter Geometrie kann die Aufgabe jedoch schwieriger sein, da sich die Informationen über den BVH mit der Position von Objekten im Raum ändern.
Wie Sie in Abbildung 9 sehen können, führt der Turing RT-Kern eine Hardware-Durchquerung der BVH-Hierarchie durch und überprüft den Schnittpunkt von Strahlen mit BBox und Dreiecken. Der GA10x kann das Gleiche, verfügt jedoch zusätzlich über einen neuen Block zum Interpolieren der Dreiecksposition, der die Bewegungsunschärfe bei der Strahlverfolgung beschleunigt.
Sowohl Turing- als auch GA10x RT-Kerne implementieren die MIMD-Architektur (Multiple Instruction Multiple Data), mit der mehrere Strahlen gleichzeitig verarbeitet werden können.
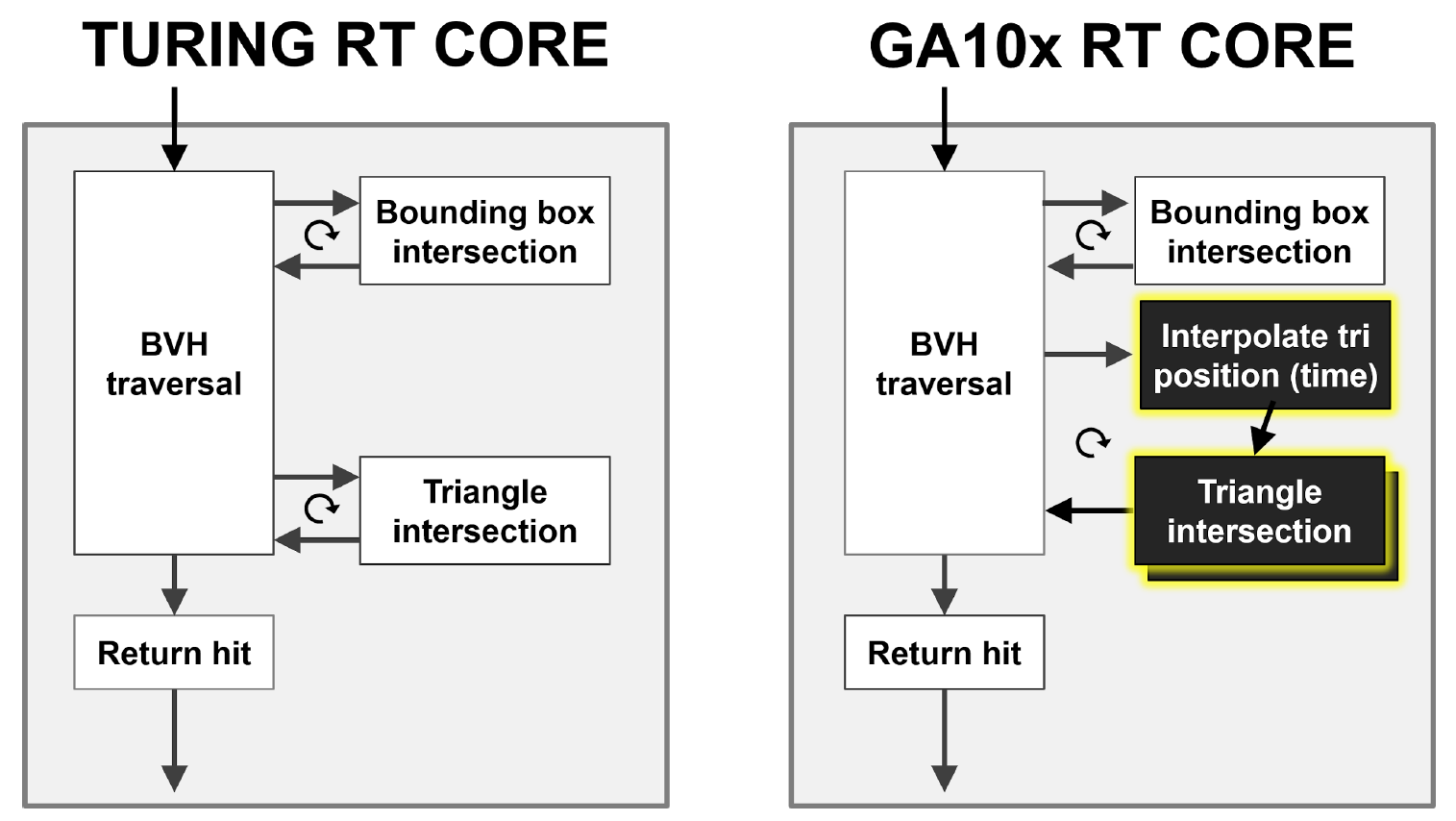
Abbildung 9. Vergleich der Hardwarebeschleunigung von Bewegungsunschärfe bei Turing und Ampere
Das Hauptproblem bei Bewegungsunschärfe besteht darin, dass die Dreiecke in der Szene nicht zeitlich festgelegt sind. Bei der grundlegenden Strahlverfolgung werden statische Schnittpunkttests durchgeführt, und wenn ein Strahl auf ein Dreieck trifft, werden Informationen über diesen Treffer zurückgegeben. Wie in Abbildung 10 gezeigt, hat bei Bewegungsunschärfe keines der Dreiecke feste Koordinaten. Jeder Strahl wird mit einem Zeitstempel versehen, um seine Verfolgungszeit anzuzeigen, und die Position des Dreiecks und der Schnittpunkt des Strahls werden aus der BVH-Gleichung bestimmt.
Wenn dieser Prozess nicht durch Hardware beschleunigt wird, kann er viele Probleme verursachen, auch aufgrund seiner Nichtlinearität.
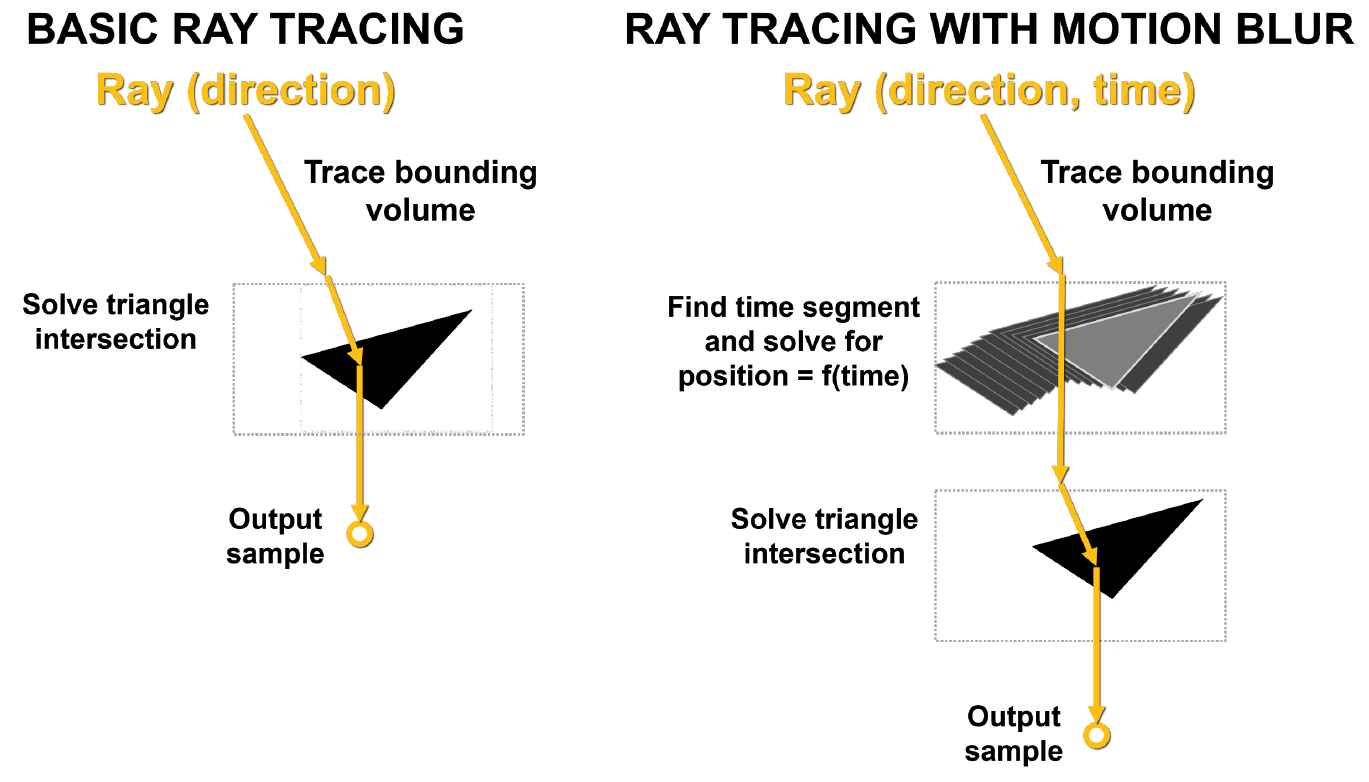
Zeichnung. 10. Grundlegende Strahlverfolgung und Strahlverfolgung mit Bewegungsunschärfe
Auf der linken Seite von Abbildung 11 treffen Strahlen, die an eine statische Szene gesendet werden, gleichzeitig auf dasselbe Dreieck. Weiße Punkte zeigen den Ort des Aufpralls an, dieses Ergebnis wird zurückgegeben. Bei Bewegungsunschärfe existiert jeder Strahl zu seinem eigenen Zeitpunkt. Jedem Strahl wird zufällig ein anderer Zeitstempel zugewiesen. Zum Beispiel versuchen die orangefarbenen Strahlen gleichzeitig, die orangefarbenen Dreiecke zu kreuzen, und dann tun die grünen und blauen Strahlen dasselbe. Am Ende werden die Proben gemischt, wodurch ein mathematisch korrekteres verschwommenes Ergebnis erzielt wird.
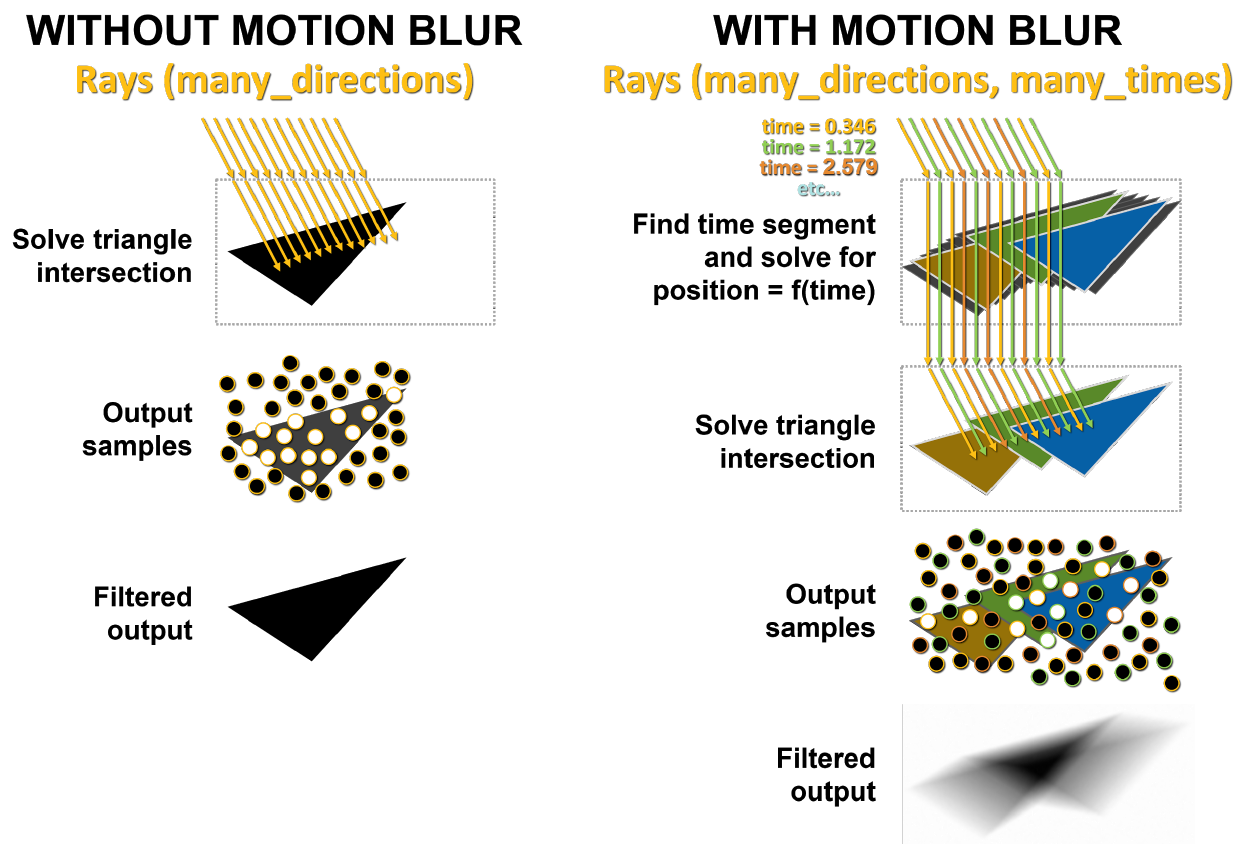
Abbildung 11. Rendern ohne Bewegungsunschärfe und mit Unschärfe in GA10x
Der Block Dreiecksposition interpolieren interpoliert die Dreiecke in BVH zwischen den bereits vorhandenen Dreiecken basierend auf der Bewegung des Objekts, so dass die Strahlen sie an den erwarteten Stellen zu den durch die Strahlzeitstempel angegebenen Momenten schneiden. Dieser Ansatz ermöglicht eine genaue Wiedergabe von Ray-Traced-Bewegungsunschärfe bis zu achtmal schneller als Turing.
GA10x-Hardware-beschleunigte Bewegungsunschärfe wird von Blender 2.90, Chaos V-Ray 5.0, Autodesk Arnold und Redshift Renderer 3.0.X unter Verwendung der NVIDIA OptiX 7.0-API unterstützt.
Die Rendergeschwindigkeit von Bewegungsunschärfe ist beim RTX 3080 bis zu 5-mal höher als beim RTX 2080 Super.
Tensorkerne der 3. Generation in GA10x-GPUs
Der GA10x enthält neue NVIDIA-Tensorkerne der dritten Generation, die Unterstützung für neue Datentypen, verbesserte Leistung, Effizienz und Programmierflexibilität bieten. Die neue Sparsity-Funktion verdoppelt die Leistung von Tensorkernen gegenüber der Turing-Generation der vorherigen Generation. AI-Funktionen wie NVIDIA DLSS für AI-Superauflösung (jetzt mit 8K-Unterstützung), NVIDIA Broadcast für die Sprach- und Videoverarbeitung und NVIDIA Canvas für das Zeichnen sind ebenfalls schneller.
Tensorkerne sind spezialisierte Ausführungseinheiten, die zur Ausführung von Tensor / Matrix-Operationen entwickelt wurden - die Hauptberechnungsfunktion beim Deep Learning. Sie werden benötigt, um die Grafikqualität mit DLSS (Deep Learning Super Sampling), AI-basierter Geräuschunterdrückung, Entfernung von Hintergrundgeräuschen in Sprach-Chats mit RTX Voice und vielen weiteren Anwendungen zu verbessern.
Die Einführung von Tensor Cores in GeForce-Gaming-GPUs hat erstmals ein tiefes Lernen in Echtzeit in Gaming-Anwendungen ermöglicht. Das Tensorkern-Design der dritten Generation in GA10x-GPUs erhöht die Rohleistung weiter und nutzt neue rechnerische Präzisionsmodi wie TF32 und BFloat16. Dies spielt eine große Rolle in AI-basierten NVIDIA NGX-Anwendungen für neuronale Dienste, um Grafiken, Rendering und andere Funktionen zu verbessern.
Vergleich von Turing- und Ampere-Tensorkernen
Ampere-Tensorkerne wurden gegenüber Turing neu organisiert, um die Effizienz zu verbessern und den Stromverbrauch zu senken. Die Ampere SM-Kernarchitektur hat weniger Tensorkerne, aber jeder ist leistungsfähiger.
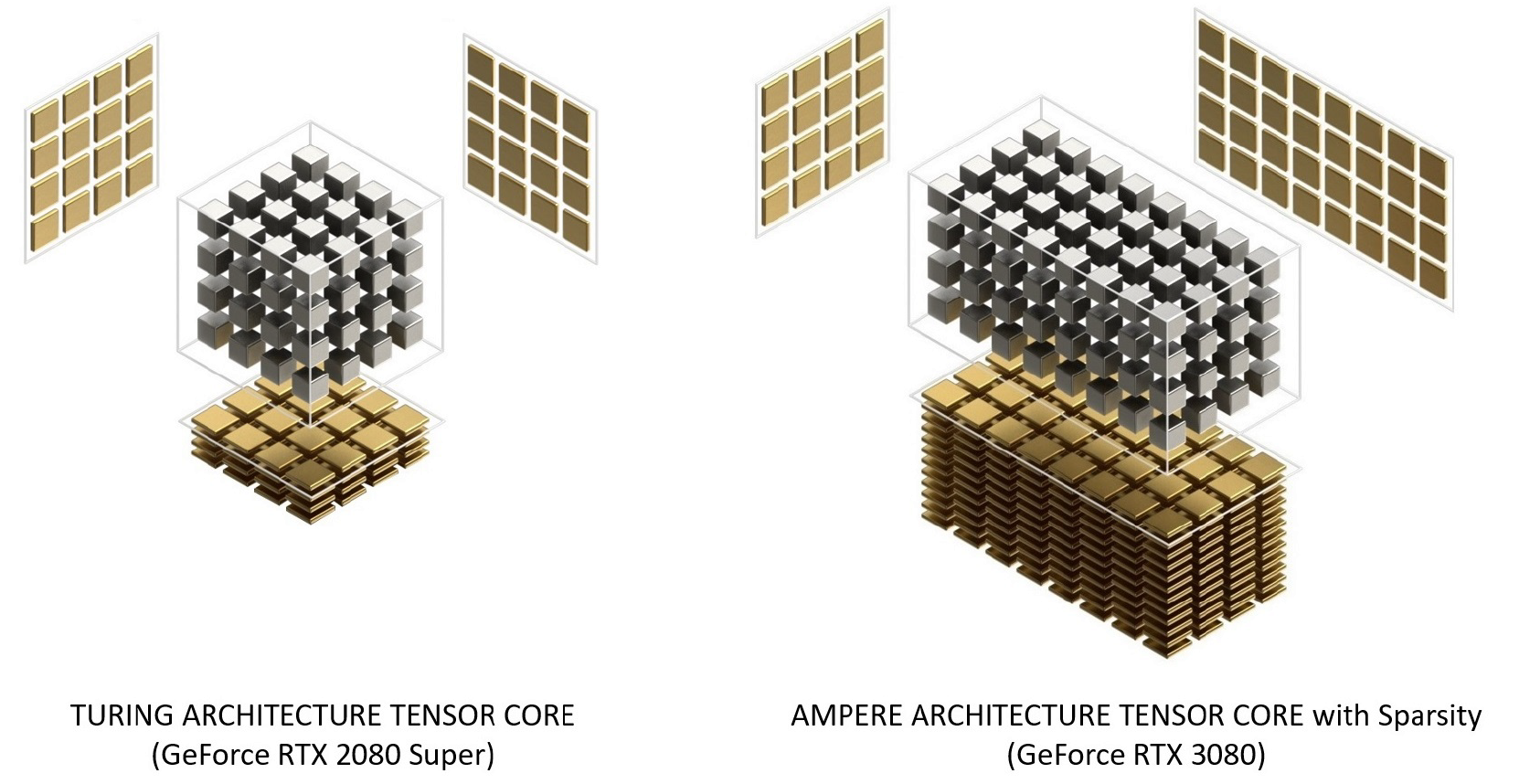
Abbildung 12. Tensorkerne mit Turing- und Ampere-Architektur. GeForce RTX 3080 bietet eine 2,7-mal schnellere FP16-Tensor-Core-Bandbreite als GeForce RTX 2080 Super
Feinkörnige strukturierte Sparsamkeit
Mit der A100-GPU führt NVIDIA die feinkörnige strukturierte Sparsity ein, einen neuen Ansatz zur Verdoppelung der Rechenbandbreite für tiefe neuronale Netze. Diese Funktion wird auch von GA10x-GPUs unterstützt und beschleunigt einige AI-basierte Grafik-Rendering-Vorgänge.
Da Deep-Learning-Netzwerke Gewichte durch Feedback-Lernen anpassen können, wirken sich strukturelle Einschränkungen im Allgemeinen nicht auf die Genauigkeit trainierter Modelle aus.
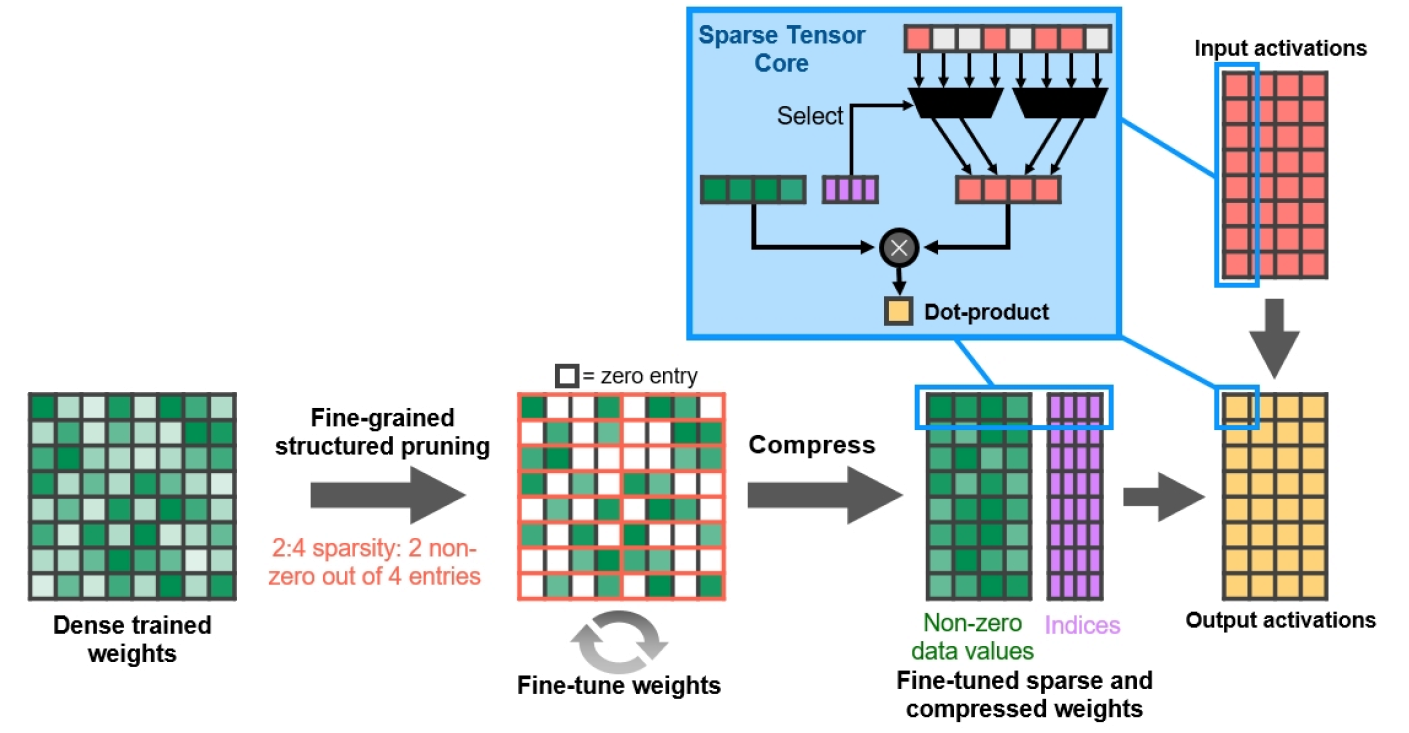
Abbildung 13. Feinkörnige strukturierte Sparsity
NVIDIA hat einen einfachen und vielseitigen Algorithmus für die Spärlichkeit von tiefen neuronalen Netzen entwickelt, der ein strukturiertes 2: 4-Sparsity-Muster verwendet. Das Netzwerk wird zuerst mit dichten Gewichten trainiert, dann erfolgt ein feinkörniges strukturiertes Beschneiden, wonach Nullwerte verworfen werden können, und die verbleibende Mathematik wird komprimiert, um den Durchsatz zu erhöhen. Der Algorithmus beeinflusst die Genauigkeit des trainierten Netzwerks für Inferenzen nicht, sondern beschleunigt sie nur.
NVIDIA DLSS 8K
Das Rendern eines Bildes mit Raytracing mit einer hohen Bildrate ist äußerst rechenintensiv. Vor dem Aufkommen von NVIDIA Turing wurde angenommen, dass die Implementierung Jahre dauern würde. Um dieses Problem zu lösen, hat NVIDIA Deep Learning Supersampling (DLSS) erstellt.

Abbildung 14. Wachhunde: Legion mit DLSS bei 1080p, 4K und 8K. Beachten Sie, dass der von DLSS in 8K bereitgestellte gestochen
scharfe Text und die Details auf dem NVIDIA Ampere nur durch die Verwendung von Tensorkernen der dritten Generation und einem 9-fachen Skalierungsfaktor mit Superauflösung besser werden. Damit ist es erstmals möglich, ein Raytrace-Spiel mit 8K und 60 fps auszuführen.
15. GeForce RTX 3090 60 fps 8K DLSS . , . Core i9-10900K
GDDR6X
Moderne PC-Spiele und kreative Anwendungen erfordern erheblich mehr Speicherbandbreite, um immer komplexere Szenengeometrien, detailliertere Texturen, Raytracing, KI-Inferenz und natürlich Schattierung und Supersampling zu verarbeiten.
GDDR6X ist der erste Grafikspeicher mit mehr als 900 GB / s. Um dies zu erreichen, wurden eine innovative Signalisierungstechnologie und eine vierstufige Pulsamplitudenmodulation (PAM4) eingesetzt, die gemeinsam die Art und Weise revolutionieren, wie Daten im Speicher verschoben werden. Mit dem PAM4-Algorithmus überträgt GDDR6X mehr Daten mit einer viel schnelleren Rate, wobei zwei Datenbits gleichzeitig verschoben werden, wodurch sich die E / A-Datenrate des vorherigen PAM2 / NRZ-Schemas verdoppelt.
Die GDDR6X unterstützt derzeit 19,5 Gbit / s für die GeForce RTX 3090 und 19 Gbit / s für die GeForce RTX 3080. Dank dieser Funktion bietet die GeForce RTX 3080 die 1,5-fache Speicherleistung ihres Vorgängers, der RTX 2080 Super. ...
Abbildung 16 zeigt einen Vergleich der Struktur von GDDR6 (links) und GDDR6X (rechts). GDDR6X überträgt dieselben Daten mit der halben Frequenz von GDDR6. Alternativ kann GDDR6X seine effektive Bandbreite verdoppeln, während die gleiche Frequenz beibehalten wird.

Abbildung 16. GDDR6X mit PAM4-Signalen zeigt eine bessere Leistung und Effizienz als GDDR6
Um die bei der PAM4-Signalisierung auftretenden SNR-Probleme zu beheben, wurde ein neues MTA-Codierungsschema (Maximum Transition Prevention) entwickelt. Der MTA verhindert, dass Hochgeschwindigkeitssignale vom höchsten zum niedrigsten und umgekehrt gelangen.

Abbildung 17. Neue Codierung in GDDR6X GDDR6X
unterstützt Datenraten von bis zu 19,5 Gbit / s auf GA10x-Chips und bietet eine maximale Speicherbandbreite von bis zu 936 GB / s, 52% mehr als die in GeForce RTX verwendete TU102-GPU 2080 Ti. GDDR6X hat nach den GPUs der GeForce 200-Serie den größten Bandbreitensprung seit 10 Jahren.
RTX IO
Moderne Spiele enthalten riesige Welten. Mit der Entwicklung von Technologien wie der Photogrammetrie ahmen sie zunehmend die Realität nach und sind daher in Dateien mit zunehmendem Volumen enthalten. Die größten Gaming-Projekte beanspruchen mehr als 200 GB, was dreimal so viel ist wie vor vier Jahren, und diese Zahl wird nur mit der Zeit zunehmen.
Spieler wenden sich zunehmend SSDs zu, um die Ladezeiten von Spielen zu verkürzen: Während Festplatten auf eine Bandbreite von 50 bis 100 MB / s begrenzt sind, lesen die neuesten M.2 PCIe Gen4-SSDs Daten mit bis zu 7 GB / s.
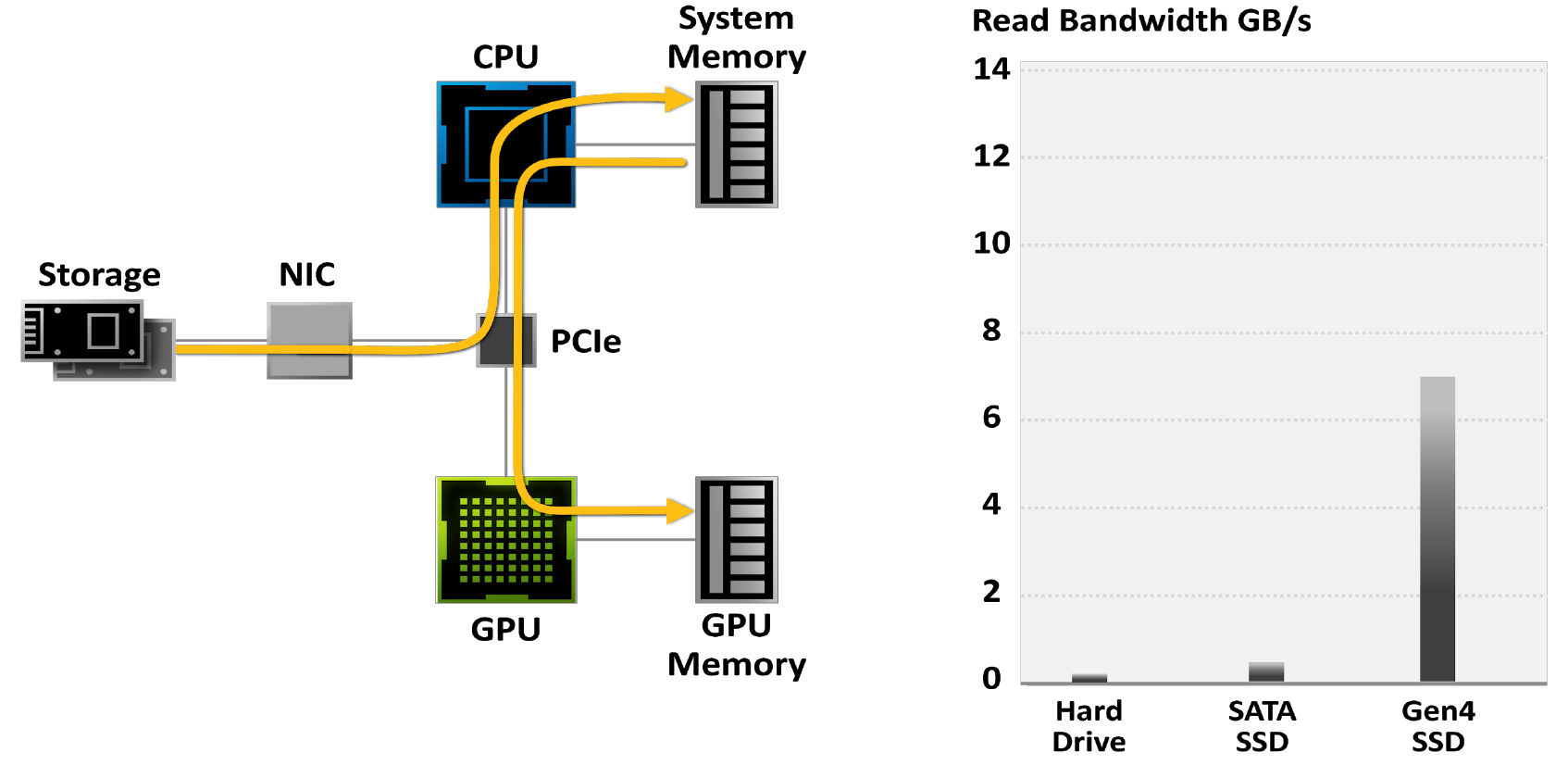
Abbildung 18. Spiele, die durch herkömmliche E / A-Systeme eingeschränkt sind

Abbildung 19. Mit dem herkömmlichen Speichermodell können beim Entpacken eines Spiels alle 24 Prozessorkerne belegt werden. Moderne Spiele-Engines haben die Fähigkeiten herkömmlicher Speicher-APIs übertroffen. Aus diesem Grund wird eine neue Generation von E / A-Architekturen benötigt. Hier zeigen graue Balken die Datenübertragungsrate, schwarze und blaue Blöcke - die dafür erforderlichen CPU-Kerne.
NVIDIA RTX IO ist eine Reihe von Technologien, die das schnelle Laden und Entpacken von GPU-basierten Assets ermöglichen und eine bis zu 100-mal schnellere E / A-Leistung bieten als Festplatten und herkömmliche Speicher-APIs.
NVIDIA RTX IO wird von der Microsoft DirectStorage-API unterstützt, einem Speicher der nächsten Generation, der speziell für die heutigen NVMe-SSD-Gaming-PCs entwickelt wurde. NVIDIA RTX IO bietet eine verlustfreie Dekomprimierung, sodass Daten in komprimierter Form über DirectStorage gelesen und an die GPU übermittelt werden können. Dadurch wird die CPU-Last entlastet, indem Daten in einer effizienteren komprimierten Form vom Speicher auf die GPU verschoben und die E / A-Leistung verdoppelt werden.

Abbildung 20. RTX IO liefert 100-mal mehr Durchsatz und 20-mal weniger CPU-Auslastung. Graue und grüne Balken zeigen die Baudrate an. Für diesen CPU-Kern sind schwarze und blaue Blöcke erforderlich.
Display- und Video-Engine
DisplayPort 1.4a mit DSC 1.2a
Der Marsch zu immer höheren Auflösungen und höheren Bildraten geht weiter, und NVIDIA Ampere-GPUs sind bestrebt, an der Spitze der Branche zu bleiben, um beides zu liefern. Spieler können jetzt auf 4K-Displays (3820 x 2160) mit 120 Hz und 8K-Displays (7680 x 4320) mit 60 Hz spielen - das Vierfache der Pixelanzahl von 4K.
Die Ampere Architecture Engine wurde entwickelt, um viele der neuen Technologien zu unterstützen, die in den schnellsten heute verfügbaren Display-Schnittstellen enthalten sind. Dies schließt DisplayPort 1.4a ein, das 8K bei 60 Hz mit VESA Display Stream Compression (DSC) 1.2a liefert. Die neuen Ampere-GPUs können mit nur einem Kabel pro Display an zwei 8K-60-Hz-Displays angeschlossen werden.
HDMI 2.1 mit DSC 1.2a
Die NVIDIA Ampere-Architektur unterstützt erstmals HDMI 2.1, das neueste Update der HDMI-Spezifikation, für diskrete GPUs. HDMI hat die maximale Bandbreite auf 48 Gbit / s erhöht, was auch dynamische HDR-Formate ermöglicht. Die Unterstützung von 8K @ 60Hz mit HDR erfordert eine DSC 1.2a-Komprimierung oder ein 4: 2: 0-Pixelformat.
NVDEC der 5. Generation - Hardwarebeschleunigte Videodecodierung
Zu den NVIDIA-GPUs gehört die Hardware-Accelerated Video Decoding (NVDEC) der 5. Generation, die eine vollständige Hardware-Videodecodierung für eine Vielzahl gängiger Codecs bietet.

Abbildung 21. Von GA10x-
GPUs unterstützte Videokodierungs- und -decodierungsformate Der NVIDIA-Decoder der fünften Generation in GA10x unterstützt die hardwarebeschleunigte Decodierung der folgenden Videocodecs auf Windows- und Linux-Plattformen: MPEG-2, VC-1, H.264 (AVCHD), H.265 (HEVC), VP8, VP9 und AV1.
NVIDIA ist der erste GPU-Hersteller, der Hardware-Unterstützung für die AV1-Decodierung bietet.
AV1-Hardware-Decodierung
Obwohl AV1 beim Komprimieren von Videos sehr effizient ist, ist das Decodieren rechenintensiv. Moderne Software-Decoder verursachen eine hohe CPU-Auslastung und erschweren die Wiedergabe von Ultra-High-Definition-Videos. In NVIDIA-Tests erzielte der Intel i9 9900K-Prozessor auf YouTube in 8K60 HDR durchschnittlich 28 Bilder pro Sekunde, wobei die CPU-Auslastung 85% überstieg. GA10x-GPUs können AV1 abspielen, indem sie die Decodierung an NVDEC übergeben, das bis zu 8K60 HDR-Inhalte mit sehr geringer CPU-Auslastung wiedergeben kann (~ 4% auf derselben CPU wie im vorherigen Test).
NVENC der 7. Generation - Hardwarebeschleunigte Videokodierung
Das Codieren von Videos kann eine komplexe Rechenaufgabe sein. Wenn Sie sie jedoch auf NVENC hochladen, werden die Grafik-Engine und die CPU für andere Vorgänge freigegeben. Wenn Sie beispielsweise Spiele mit Open Broadcaster Software (OBS) auf Twitch.tv streamen, wird durch das Auslagern der Videokodierung in NVENC die Grafik-Engine der GPU zum Rendern des Spiels und die CPU für andere Benutzeraufgaben zugewiesen.
NVENC ermöglicht:
- Hochwertige Codierung und Streaming von Spielen und Anwendungen mit extrem geringer Latenz ohne Verwendung der CPU;
- sehr hochwertige Codierung für Archivierung, OTT-Streaming, Webvideo;
- Codierung mit extrem geringem Stromverbrauch pro Stream (W / Stream).
Mit gemeinsam genutzten Streaming-Einstellungen für Twitch und YouTube übertrifft die NVENC-basierte Hardware-Codierung in GA10x-GPUs die x264-Software-Encoder mit der Fast-Voreinstellung und entspricht x264 Medium, einer Voreinstellung, die normalerweise die Leistung von zwei Computern erfordert. Dadurch wird die CPU-Auslastung drastisch reduziert. 4K-Codierung ist zu viel Arbeitsaufwand für eine typische CPU-Konfiguration, aber der GA10x NVENC-Encoder bietet nahtlose hochauflösende Codierung von bis zu 4K in H.264 und sogar 8K in HEVC.
Fazit
Mit jeder neuen Prozessorarchitektur ist NVIDIA bestrebt, der nächsten Generation eine revolutionäre Leistung zu bieten und gleichzeitig neue Funktionen einzuführen, die die Bildqualität verbessern. Turing war die erste GPU, die hardwarebeschleunigtes Raytracing einführte, eine Funktion, die einst als der heilige Gral der Computergrafik galt. Heutzutage werden vielen neuen AAA-PC-Spielen unglaublich realistische und physikalisch genaue Raytracing-Effekte hinzugefügt, und GPU-beschleunigtes Raytracing wird für die meisten PC-Spieler als ein Muss angesehen. Die neuen NVIDIA GA10x Ampere-GPUs bieten die Funktionen und die Leistung, die Sie benötigen, um diese neuen Raytrace-Spiele mit bis zu 2x schnelleren Bildraten als derzeit verfügbar zu genießen.Ein weiteres Merkmal von Turing - eine verbesserte CPU-beschleunigte KI-Verarbeitung, die die Rauschunterdrückung, das Rendern und andere Grafikanwendungen verbessert - wird dank der Ampere-Architektur ebenfalls auf die nächste Stufe gebracht.
Zum Schluss noch ein Link zum vollständigen Dokument .