Leider konnte ich kein besseres kostenloses Modell finden, aber ich bedanke mich immer noch bei dem Bildhauer aus Übersee, der mich digital erfasst hat! Und wie Sie vielleicht erraten haben, werden wir über das Schreiben eines CPU-Renderings sprechen.
Idee
Mit der Entwicklung von Shader-Sprachen und der Erhöhung der GPU-Leistung interessieren sich immer mehr Menschen für Grafikprogrammierung. Es sind neue Richtungen aufgetaucht, wie zum Beispiel Ray, der mit einer schnell wachsenden Popularität marschiert .
In Erwartung der Veröffentlichung eines neuen Monsters von NVidia habe ich beschlossen, einen eigenen Artikel (Tube und Old School) über die Grundlagen des Renderns auf einer CPU zu schreiben. Es ist ein Spiegelbild meiner persönlichen Erfahrung beim Schreiben eines Renderings, und darin werde ich versuchen, die Konzepte und Algorithmen zu vermitteln, auf die ich während des Codierungsprozesses gestoßen bin. Es versteht sich, dass die Leistung dieser Software aufgrund der Ungeeignetheit des Prozessors zur Ausführung solcher Aufgaben sehr gering sein wird.
Die Wahl der Sprache fiel anfangs auf c ++ oder Rost , aber ich entschied mich für c #Aufgrund der einfachen Schreibbarkeit von Code und der zahlreichen Optimierungsmöglichkeiten. Das Endprodukt dieses Artikels ist ein Rendering, mit dem Bilder wie folgt erzeugt werden können:


Alle Modelle, die ich hier verwendet habe, sind gemeinfrei, keine Piraten und respektieren die Arbeit von Künstlern!
Mathe
Es versteht sich von selbst, wo Renderings geschrieben werden sollen, ohne ihre mathematischen Grundlagen zu verstehen. In diesem Abschnitt werde ich nur die Konzepte behandeln, die ich im Code verwendet habe. Ich rate denjenigen, die sich nicht sicher sind, diesen Abschnitt zu überspringen, ohne diese Grundlagen zu verstehen, wird es schwierig sein, die weitere Präsentation zu verstehen. Ich erwarte auch, dass diejenigen, die sich für das Studium der Berechnungsgeometrie entscheiden, über Grundkenntnisse in linearer Algebra, Geometrie sowie Trigonometrie (Winkel, Vektoren, Matrizen, Punktprodukt) verfügen. Für diejenigen, die die Computergeometrie besser verstehen wollen, kann ich das Buch von E. Nikulin "Computer Geometry and Computer Graphics Algorithms" empfehlen .
Vektor dreht sich. Rotationsmatrix
Die Rotation ist eine der grundlegenden linearen Transformationen des Vektorraums. Es ist auch eine orthogonale Transformation, da die Längen der transformierten Vektoren erhalten bleiben. Es gibt zwei Arten von Rotationen im 2D-Raum:
- Drehung relativ zum Ursprung
- Drehung um einen Punkt
Hier werde ich nur den ersten Typ betrachten, da Die zweite ist eine Ableitung der ersten und unterscheidet sich nur in der Änderung des Rotationskoordinatensystems (wir werden das Koordinatensystem weiter analysieren).
Lassen Sie uns Formeln zum Drehen eines Vektors im zweidimensionalen Raum ableiten. Bezeichnen wir die Koordinaten des ursprünglichen Vektors - {x, y} . Die um den Winkel f gedrehten Koordinaten des neuen Vektors werden mit {x 'y'} bezeichnet .
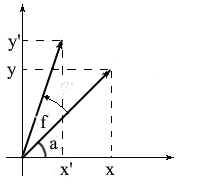
Wir wissen, dass die Länge dieser Vektoren üblich ist, und können daher die Konzepte von Cosinus und Sinus verwenden, um diese Vektoren in Bezug auf Länge und Winkel um die OX- Achse auszudrücken :

Beachten Sie, dass wir die Summen- und Kosinusformeln verwenden können, um die x'- und y'- Werte zu erweitern . Für diejenigen, die vergessen haben, werde ich diese Formeln erinnern:
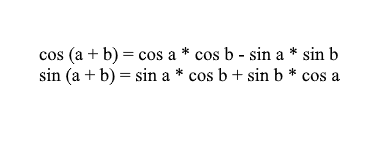
Wenn wir die Koordinaten des gedrehten Vektors durch sie erweitern, erhalten wir:

Hier ist leicht zu erkennen, dass die Faktoren l * cos a und l * sin a die Koordinaten des ursprünglichen Vektors sind: x = l * cos a, y = l * sin a . Ersetzen wir sie durch x und y :

Daher haben wir den gedrehten Vektor durch die Koordinaten des ursprünglichen Vektors und den Drehwinkel ausgedrückt. Als Matrix sieht dieser Ausdruck folgendermaßen aus:
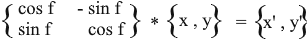
Multiplizieren Sie und überprüfen Sie, ob das Ergebnis dem entspricht, was wir abgeleitet haben.
Im 3D-Raum drehen
Wir haben die Rotation im zweidimensionalen Raum betrachtet und auch eine Matrix dafür abgeleitet. Nun stellt sich die Frage, wie solche Transformationen für drei Dimensionen erhalten werden können. Im zweidimensionalen Fall haben wir Vektoren auf einer Ebene gedreht, aber hier gibt es unendlich viele Ebenen, relativ zu denen wir dies tun können. Es gibt jedoch drei grundlegende Arten von Rotationen, mit denen Sie jede Rotation eines Vektors im dreidimensionalen Raum ausdrücken können - dies sind XY- , XZ- und YZ- Rotationen.
XY- Drehung.
Bei dieser Drehung drehen wir den Vektor um die OZ- Achse des Koordinatensystems. Stellen Sie sich vor, die Vektoren sind die Hubschrauberblätter und die OZ- Achse ist der Mast, an dem sie festhalten. Mit XYDie Drehung des Vektors dreht sich um die OZ- Achse , wie die Blätter eines Hubschraubers relativ zum Mast.

Beachten Sie, dass sich bei dieser Drehung die z- Koordinaten der Vektoren nicht ändern, aber die x- und x- Koordinaten ändern - deshalb wird dies als XY- Drehung bezeichnet.
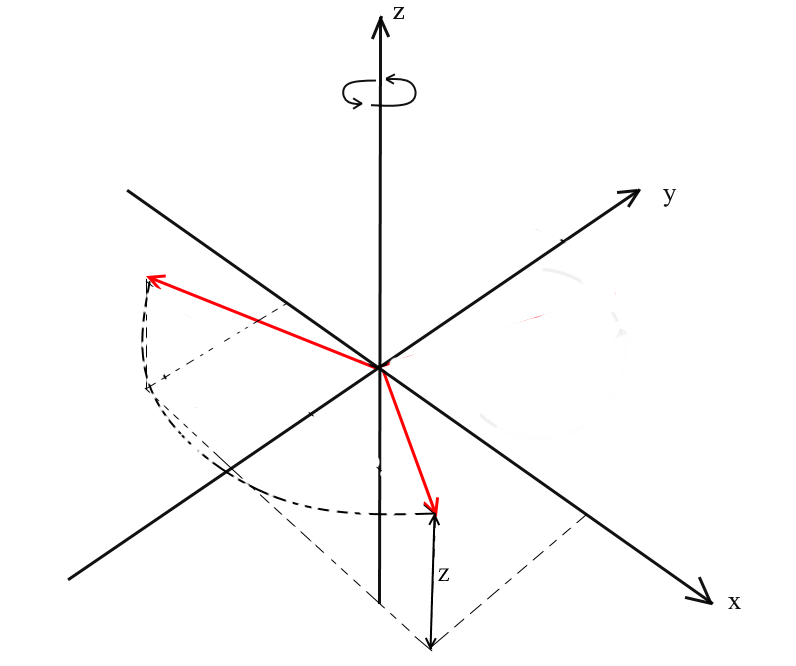
Es ist nicht schwierig, Formeln für eine solche Drehung abzuleiten: z - Die Koordinate bleibt gleich, und x und y ändern sich nach denselben Prinzipien wie bei der 2D-Drehung.
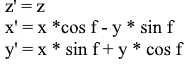
Das gleiche in Form einer Matrix:
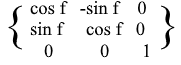
Bei XZ- und YZ- Rotationen ist alles gleich:


Projektion
Das Konzept der Projektion kann je nach Kontext variieren. Viele haben wahrscheinlich von Konzepten wie Projektion auf eine Ebene oder Projektion auf eine Koordinatenachse gehört.
Nach dem hier verwendeten Verständnis ist die Projektion auf einen Vektor auch ein Vektor. Seine Koordinaten sind der Schnittpunkt der Senkrechten, die mit dem Vektor b von Vektor a nach b fallen .
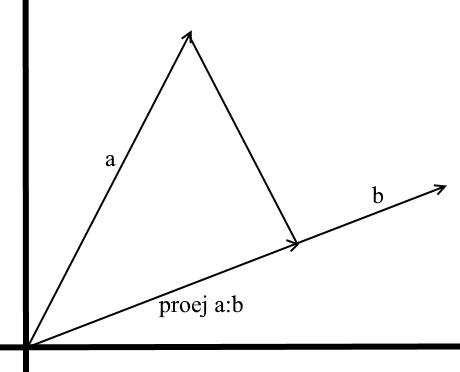
Um einen solchen Vektor zu definieren, müssen wir seine Länge und Richtung kennen . Wie wir wissen, hängen das benachbarte Bein und die Hypotenuse in einem rechtwinkligen Dreieck durch das Kosinusverhältnis zusammen. Daher verwenden wir es, um die Länge des Projektionsvektors auszudrücken:
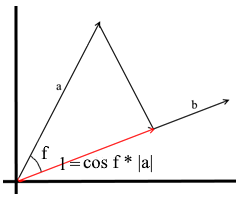
Die Richtung des Projektionsvektors stimmt per Definition mit dem Vektor b überein , was bedeutet, dass die Projektion durch die Formel bestimmt wird:
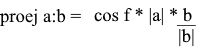
Hier erhalten wir die Richtung der Projektion als Einheitsvektor und multiplizieren sie mit der Länge der Projektion. Es ist nicht schwer zu verstehen, dass das Ergebnis genau das ist, wonach wir suchen.
Lassen Sie uns nun alles in Bezug auf das Punktprodukt darstellen :

Wir erhalten eine bequeme Formel zum Finden der Projektion:
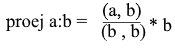
Koordinatensystem. Basen
Viele sind es gewohnt, im Standard- XYZ- Koordinatensystem zu arbeiten , in dem zwei beliebige Achsen senkrecht zueinander stehen und die Koordinatenachsen als Einheitsvektoren dargestellt werden können:

Tatsächlich gibt es unendlich viele Koordinatensysteme, von denen jedes eine Basis ist . Die Basis des n- dimensionalen Raums ist eine Menge von Vektoren {v1, v2 …… vn}, durch die alle Vektoren dieses Raums dargestellt werden. In diesem Fall wird kein Vektor von der Basis kann dargestellt werden durch die anderen Vektoren. Tatsächlich ist jede Basis ein separates Koordinatensystem, in dem die Vektoren ihre eigenen, eindeutigen Koordinaten haben.
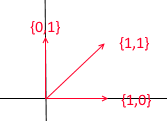
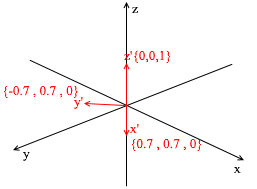
Schauen wir uns an, was eine Basis für den zweidimensionalen Raum ist. Nehmen wir zum Beispiel das bekannte kartesische Koordinatensystem der Vektoren X {1, 0} , Y {0, 1} , das eine der Grundlagen für einen zweidimensionalen Raum darstellt:
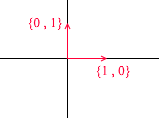
Jeder Vektor in einer Ebene kann als Summe von Vektoren dieser Basis mit bestimmten Koeffizienten oder als lineare Kombination dargestellt werden . Denken Sie daran, was Sie tun, wenn Sie die Koordinaten eines Vektors aufschreiben - Sie schreiben x - die Koordinate und dann - y . So bestimmen Sie tatsächlich die Expansionskoeffizienten anhand der Basisvektoren.

Nehmen wir nun eine andere Grundlage:
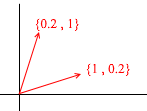
Jeder 2D-Vektor kann auch durch seine Vektoren dargestellt werden:

Ein solcher Satz von Vektoren ist jedoch nicht die Grundlage eines zweidimensionalen Raums:

Darin liegen zwei Vektoren {1,1} und {2,2} auf einer geraden Linie. Unabhängig von ihren Kombinationen erhalten Sie nur Vektoren, die auf der gemeinsamen Geraden y = x liegen . Für unsere Zwecke werden solche fehlerhaften nicht nützlich sein, ich denke jedoch, dass es sich lohnt, den Unterschied zu verstehen. Per Definition sind alle Basen durch eine Eigenschaft vereint - keiner der Basisvektoren kann als Summe anderer Basisvektoren mit Koeffizienten dargestellt werden, oder keiner der Basisvektoren ist eine lineare Kombination anderer. Hier ist ein Beispiel für einen Satz von 3 Vektoren, der ebenfalls keine Basis darstellt :
Jeder Vektor einer zweidimensionalen Ebene kann durch sie ausgedrückt werden , aber der Vektor {1, 1} darin ist überflüssig, da er selbst durch die Vektoren {1, 0} und {0,1} als {1,0} + {0,1 ausgedrückt werden kann } .
Im Allgemeinen enthält jede Basis eines n- dimensionalen Raums genau n Vektoren, für 2e ist dieses n jeweils gleich 2.
Wenden wir uns 3d zu. Die dreidimensionale Basis enthält 3 Vektoren:
Wenn für eine zweidimensionale Basis zwei Vektoren ausreichen, die nicht auf einer geraden Linie liegen, dann ist in einem dreidimensionalen Raum die Menge der Vektoren eine Basis, wenn:
- 1) 2 Vektoren liegen nicht auf einer geraden Linie
- 2) der dritte liegt nicht auf der Ebene, die von den beiden anderen gebildet wird.
Von nun an sind die Basen, mit denen wir arbeiten, orthogonal (jeder ihrer Vektoren ist senkrecht) und normalisiert (die Länge eines Basisvektors beträgt 1). Wir werden einfach keine anderen brauchen. Zum Beispiel die Standardbasis
erfüllt diese Kriterien.
Übergang zu einer anderen Basis
Bisher haben wir die Zerlegung eines Vektors als Summe von Basisvektoren mit Koeffizienten geschrieben:

Betrachten Sie noch einmal die Standardbasis - der darin enthaltene Vektor {1, 3, 6} kann wie folgt geschrieben werden:
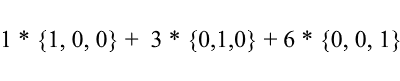
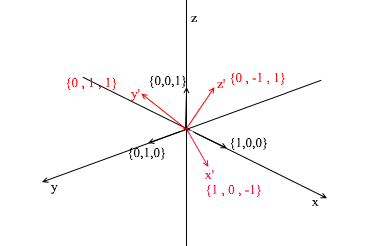
Wie Sie sehen können, sind die Expansionskoeffizienten eines Vektors in der Basis seine Koordinaten auf dieser Basis . Schauen wir uns das folgende Beispiel an:
Diese Basis wird aus dem Standard abgeleitet, indem eine 45-Grad- XY- Drehung darauf angewendet wird . Nehmen Sie einen Vektor a im Standardsystem mit den Koordinaten {0, 1, 1}
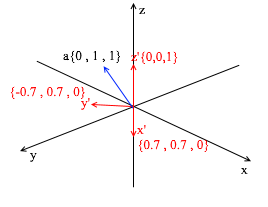
Durch die Vektoren der neuen Basis kann sie wie folgt erweitert werden:
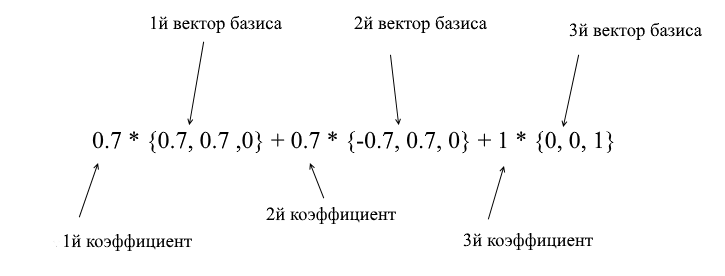
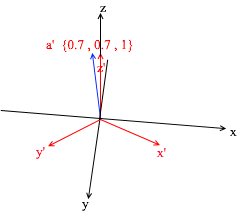
Wenn Sie diesen Betrag berechnen, erhalten Sie {0, 1, 1} - den Vektor a in der Standardbasis. Basierend auf diesem Ausdruck in der neuen Basis hat der Vektor a die Koordinaten {0,7, 0,7, 1} - die Expansionskoeffizienten. Dies wird besser sichtbar, wenn Sie es aus einem anderen Blickwinkel betrachten:
Aber wie finden Sie diese Koeffizienten? Im Allgemeinen ist eine universelle Methode die Lösung eines ziemlich komplexen linearen Gleichungssystems. Wie ich bereits sagte, werden wir jedoch nur orthogonale und normalisierte Basen verwenden, und für sie gibt es einen sehr betrügerischen Weg. Es besteht darin, Projektionen auf die Basisvektoren zu finden. Verwenden wir es, um die Zerlegung des Vektors a in der Basis X {0,7, 0,7, 0} Y {-0,7, 0,7, 0} Z {0, 0, 1} zu finden
Lassen Sie uns zuerst den Koeffizienten für y 'finden . Der erste Schritt besteht darin, die Projektion des Vektors a auf den Vektor y 'zu finden (ich habe oben diskutiert, wie das geht):
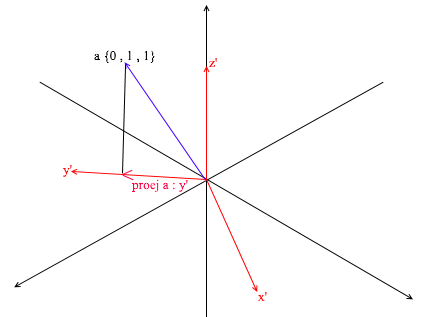
Der zweite Schritt: Wir teilen die Länge der gefundenen Projektion durch die Länge des Vektors y ' und finden dabei heraus, „wie viele Vektoren y' in den Projektionsvektor passen“ - diese Zahl ist der Koeffizient für y ' und auch y - die Koordinate des Vektors a in der neuen Basis! Wiederholen Sie für x ' und z' ähnliche Operationen:

Jetzt haben wir Formeln für den Übergang von der Standardbasis zur neuen:
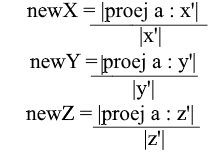
Nun, da wir nur normalisierte Basen verwenden und die Längen ihrer Vektoren gleich 1 sind, besteht keine Notwendigkeit, in der Übergangsformel durch die Länge des Vektors zu dividieren:
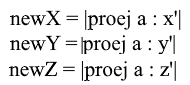
Erweitern Sie die x- Koordinate durch die Projektionsformel:

Es ist zu beachten, dass der Nenner (x ', x') und der Vektor x ' im Fall einer normalisierten Basis ebenfalls 1 sind und verworfen werden können. Wir bekommen:

Wir sehen, dass die x- Koordinate in der Basis als Punktprodukt (a, x ') ausgedrückt wird , die y- Koordinate jeweils als (a, y') , die z- Koordinate ist (a, z ') . Jetzt können Sie eine Matrix für den Übergang zu neuen Koordinaten erstellen :

Offset-Koordinatensysteme
Alle oben betrachteten Koordinatensysteme hatten den Ursprung des Punktes {0,0,0} . Darüber hinaus gibt es auch Systeme mit einem verschobenen Ursprungspunkt:
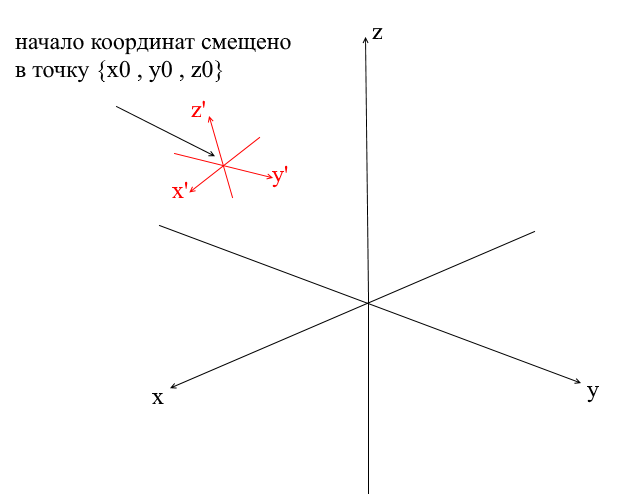
Um einen Vektor in ein solches System zu übersetzen, müssen Sie ihn zunächst relativ zum neuen Koordinatenzentrum ausdrücken. Dies ist einfach - subtrahieren Sie dieses Zentrum vom Vektor. Auf diese Weise "verschieben" Sie das Koordinatensystem selbst in ein neues Zentrum, während der Vektor an Ort und Stelle bleibt. Als nächstes können Sie die uns bereits bekannte Übergangsmatrix verwenden.
Schreiben einer Geometrie-Engine. Erstellen Sie einen drahtähnlichen Render.
Nun, ich denke, jemand, der den Abschnitt mit Mathematik durchgearbeitet und den Artikel nicht geschlossen hat, kann mit interessanteren Dingen einer Gehirnwäsche unterzogen werden! In diesem Abschnitt werden die Grundlagen einer 3D-Engine und des Renderns beschrieben. Im Allgemeinen ist das Rendern ein ziemlich kompliziertes Verfahren, das viele verschiedene Vorgänge umfasst: Abschneiden unsichtbarer Kanten, Rastern, Berechnen von Licht, Verarbeiten verschiedener Effekte, Materialien (manchmal sogar Physik). Wir werden teilweise all dies in der Zukunft, analysieren , aber jetzt werden wir einfache Dinge tun - wir schreiben ein Draht machen. Sein Kern ist, dass es ein Objekt in Form von Linien zeichnet, die seine Eckpunkte verbinden, sodass das Ergebnis wie ein Netzwerk von Drähten aussieht:

Polygonale Grafiken
In der Computergrafik werden traditionell polygonale Darstellungen von 3D-Objektdaten verwendet. Somit werden Daten in OBJ, 3DS, FBX und vielen anderen dargestellt. In einem Computer werden solche Daten in Form von zwei Sätzen gespeichert: einem Satz von Eckpunkten und einem Satz von Flächen (Polygonen). Jeder Scheitelpunkt eines Objekts wird durch seine Position im Raum dargestellt - ein Vektor, und jede Fläche (Polygon) wird durch drei Ganzzahlen dargestellt, die Indizes der Scheitelpunkte dieses Objekts sind. Die einfachsten Objekte (Würfel, Kugeln usw.) bestehen aus solchen Polygonen und werden als Grundelemente bezeichnet.
In unserer Engine ist das Grundelement das Hauptobjekt der 3D-Geometrie - alle anderen Objekte erben davon. Beschreiben wir die primitive Klasse:
abstract class Primitive
{
public Vector3[] Vertices { get; protected set; }
public int[] Indexes { get; protected set; }
}
Bisher ist alles einfach - es gibt Eckpunkte des Grundelements und Indizes zur Bildung von Polygonen. Jetzt können Sie diese Klasse verwenden, um einen Würfel zu erstellen:
public class Cube : Primitive
{
public Cube(Vector3 center, float sideLen)
{
var d = sideLen / 2;
Vertices = new Vector3[]
{
new Vector3(center.X - d , center.Y - d, center.Z - d) ,
new Vector3(center.X - d , center.Y - d, center.Z) ,
new Vector3(center.X - d , center.Y , center.Z - d) ,
new Vector3(center.X - d , center.Y , center.Z) ,
new Vector3(center.X + d , center.Y - d, center.Z - d) ,
new Vector3(center.X + d , center.Y - d, center.Z) ,
new Vector3(center.X + d , center.Y + d, center.Z - d) ,
new Vector3(center.X + d , center.Y + d, center.Z + d) ,
};
Indexes = new int[]
{
1,2,4 ,
1,3,4 ,
1,2,6 ,
1,5,6 ,
5,6,8 ,
5,7,8 ,
8,4,3 ,
8,7,3 ,
4,2,8 ,
2,8,6 ,
3,1,7 ,
1,7,5
};
}
}
int Main()
{
var cube = new Cube(new Vector3(0, 0, 0), 2);
}

Koordinatensysteme implementieren
Es reicht nicht aus, ein Objekt mit einer Reihe von Polygonen festzulegen. Um komplexe Szenen zu planen und zu erstellen, müssen Objekte an verschiedenen Orten angeordnet, gedreht, verkleinert oder vergrößert werden. Zur Vereinfachung dieser Operationen werden die sogenannten lokalen und globalen Koordinatensysteme verwendet. Jedes Objekt in der Szene hat ein eigenes Koordinatensystem - sowohl lokal als auch einen eigenen Mittelpunkt.
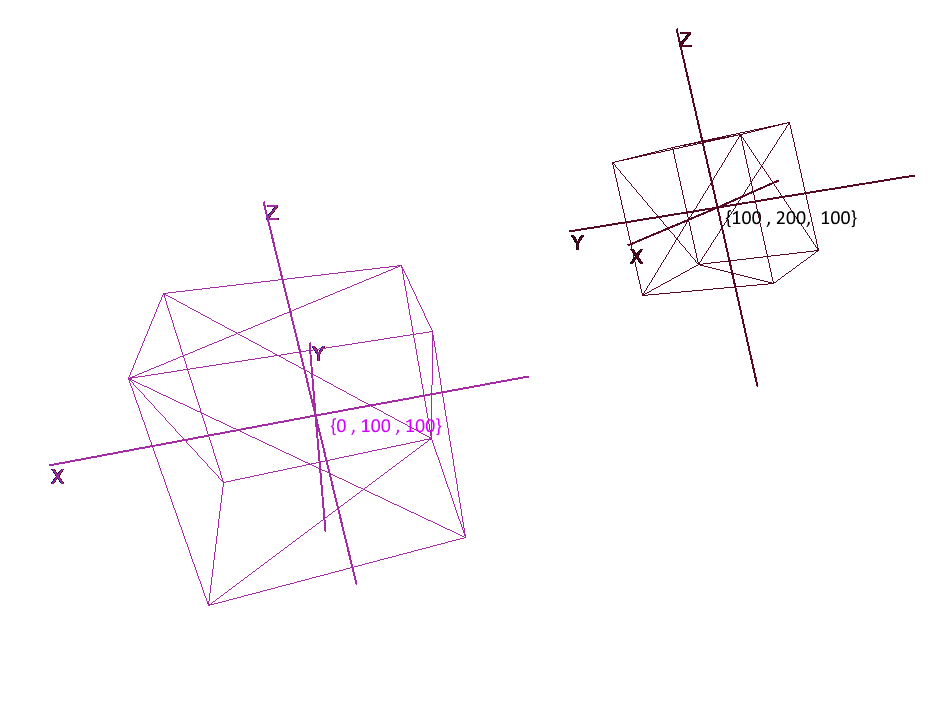
Durch die Darstellung eines Objekts in lokalen Koordinaten können Sie problemlos Operationen damit ausführen. Um beispielsweise ein Objekt um den Vektor a zu bewegen , reicht es aus, den Mittelpunkt seines Koordinatensystems um diesen Vektor zu verschieben, ein Objekt zu drehen - seine lokalen Koordinaten zu drehen.
Wenn Sie mit einem Objekt arbeiten, führen wir Operationen mit seinen Scheitelpunkten im lokalen Koordinatensystem aus. Während des Renderns übersetzen wir zunächst alle Objekte in der Szene in ein einziges Koordinatensystem - das globale. Fügen wir dem Code Koordinatensysteme hinzu. Erstellen Sie dazu ein Objekt der Pivot-Klasse (Pivot, Pivot-Punkt), das die lokale Basis des Objekts und seinen Mittelpunkt darstellt. Das Konvertieren eines Punkts in ein von Pivot dargestelltes Koordinatensystem erfolgt in zwei Schritten:
- 1) Darstellung eines Punktes relativ zum Zentrum neuer Koordinaten
- 2) Erweiterung der neuen Basis in Vektoren
Um den lokalen Scheitelpunkt eines Objekts in globalen Koordinaten darzustellen, müssen Sie im Gegenteil die folgenden Aktionen in umgekehrter Reihenfolge ausführen:
- 1) Expansion in Vektoren der globalen Basis
- 2) Darstellung relativ zum globalen Zentrum
Schreiben wir eine Klasse zur Darstellung von Koordinatensystemen:
public class Pivot
{
//
public Vector3 Center { get; private set; }
// -
public Vector3 XAxis { get; private set; }
public Vector3 YAxis { get; private set; }
public Vector3 ZAxis { get; private set; }
//
public Matrix3x3 LocalCoordsMatrix => new Matrix3x3
(
XAxis.X, YAxis.X, ZAxis.X,
XAxis.Y, YAxis.Y, ZAxis.Y,
XAxis.Z, YAxis.Z, ZAxis.Z
);
//
public Matrix3x3 GlobalCoordsMatrix => new Matrix3x3
(
XAxis.X , XAxis.Y , XAxis.Z,
YAxis.X , YAxis.Y , YAxis.Z,
ZAxis.X , ZAxis.Y , ZAxis.Z
);
public Vector3 ToLocalCoords(Vector3 global)
{
//
return LocalCoordsMatrix * (global - Center);
}
public Vector3 ToGlobalCoords(Vector3 local)
{
// -
return (GlobalCoordsMatrix * local) + Center;
}
public void Move(Vector3 v)
{
Center += v;
}
public void Rotate(float angle, Axis axis)
{
XAxis = XAxis.Rotate(angle, axis);
YAxis = YAxis.Rotate(angle, axis);
ZAxis = ZAxis.Rotate(angle, axis);
}
}
Fügen Sie nun mit dieser Klasse die Funktionen Rotation, Bewegung und Erhöhung zu den Grundelementen hinzu:
public abstract class Primitive
{
//
public Pivot Pivot { get; protected set; }
//
public Vector3[] LocalVertices { get; protected set; }
//
public Vector3[] GlobalVertices { get; protected set; }
//
public int[] Indexes { get; protected set; }
public void Move(Vector3 v)
{
Pivot.Move(v);
for (int i = 0; i < LocalVertices.Length; i++)
GlobalVertices[i] += v;
}
public void Rotate(float angle, Axis axis)
{
Pivot.Rotate(angle , axis);
for (int i = 0; i < LocalVertices.Length; i++)
GlobalVertices[i] = Pivot.ToGlobalCoords(LocalVertices[i]);
}
public void Scale(float k)
{
for (int i = 0; i < LocalVertices.Length; i++)
LocalVertices[i] *= k;
for (int i = 0; i < LocalVertices.Length; i++)
GlobalVertices[i] = Pivot.ToGlobalCoords(LocalVertices[i]);
}
}
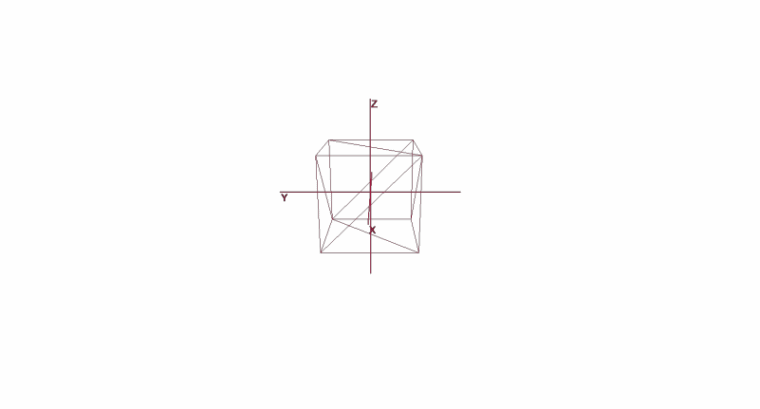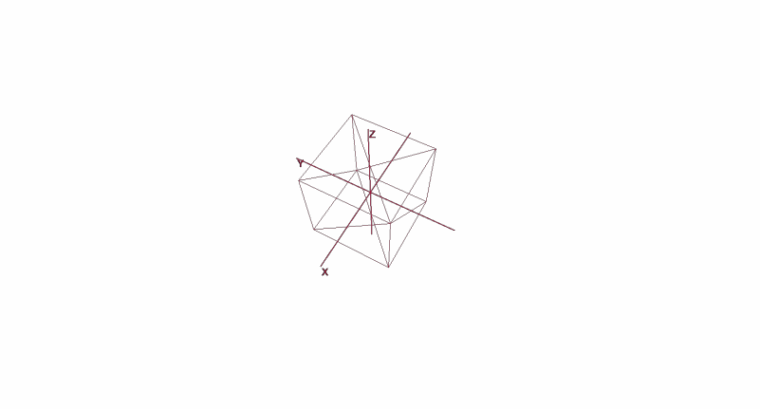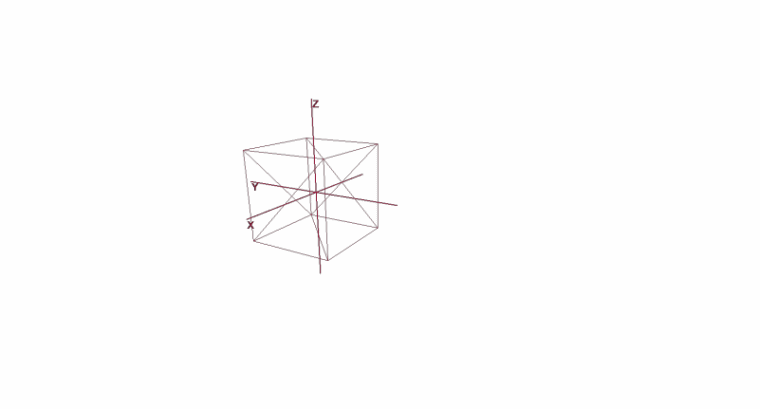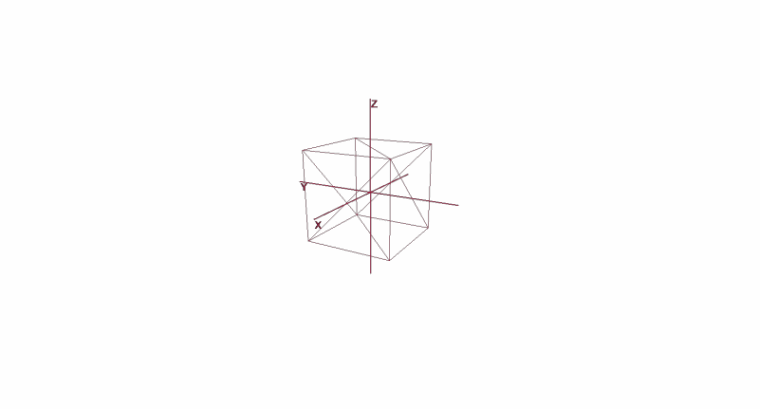
Drehen und Verschieben eines Objekts mithilfe lokaler Koordinaten
Polygone zeichnen. Kamera
Das Hauptobjekt der Szene wird die Kamera sein - mit ihrer Hilfe werden Objekte auf dem Bildschirm gezeichnet. Die Kamera hat wie alle Objekte in der Szene lokale Koordinaten in Form eines Objekts der Pivot-Klasse - durch sie bewegen und drehen wir die Kamera:

Um das Objekt auf dem Bildschirm anzuzeigen, verwenden wir eine einfache perspektivische Projektionsmethode . Das Prinzip, auf dem diese Methode basiert, ist, dass das Objekt umso kleiner erscheint , je weiter wir von uns entfernt sind . Wahrscheinlich haben viele in der Schule das Problem gelöst, die Höhe eines Baumes in einem bestimmten Abstand vom Beobachter zu messen:
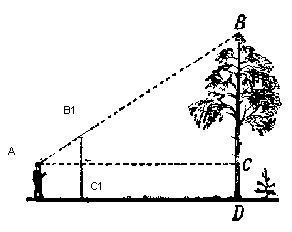
Stellen Sie sich vor, ein Strahl vom oberen Punkt eines Baumes fällt auf eine bestimmte Projektionsebene in einem Abstand C1 vom Beobachter und zeichnet einen Punkt darauf. Der Betrachter sieht diesen Punkt und möchte daraus die Höhe des Baumes bestimmen. Wie Sie sehen können, hängen die Höhe des Baums und die Höhe eines Punktes auf der Projektionsebene durch das Verhältnis ähnlicher Dreiecke zusammen. Dann kann der Beobachter die Höhe des Punktes unter Verwendung dieses Verhältnisses bestimmen:
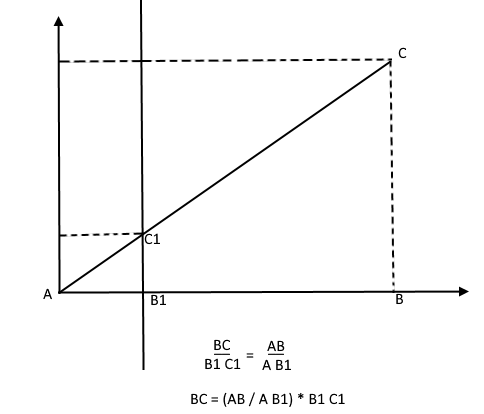
Im Gegenteil, wenn er die Höhe des Baumes kennt, kann er die Höhe eines Punktes auf der Projektionsebene finden:

Gehen wir jetzt zurück zu unserer Kamera. Vorstellen , dass es eine Projektionsebene angebracht ist , um die z- Achse der Kamera in einem Abstand z ' vom Ursprung. Die Formel für eine solche Ebene lautet z = z ' , sie kann durch eine Zahl gegeben werden - z' . Strahlen von den Eckpunkten verschiedener Objekte fallen auf diese Ebene. Wenn der Strahl auf das Flugzeug trifft, hinterlässt er einen Punkt darauf. Durch Verbinden solcher Punkte können Sie ein Objekt zeichnen.

Diese Ebene repräsentiert den Bildschirm. Wir finden die Koordinate der Projektion des Scheitelpunkts des Objekts auf dem Bildschirm in zwei Schritten:
- 1) Wir übersetzen den Scheitelpunkt in die lokalen Koordinaten der Kamera
- 2) Finden Sie die Projektion eines Punktes durch das Verhältnis ähnlicher Dreiecke

Die Projektion ist ein zweidimensionaler Vektor, dessen x'- und y'- Koordinaten die Position des Punkts auf dem Computerbildschirm definieren.
Kammerklasse 1
public class Camera
{
//
public Pivot Pivot { get; private set; }
//
public float ScreenDist { get; private set; }
public Camera(Vector3 center, float screenDist)
{
Pivot = new Pivot(center);
ScreenDist = screenDist;
}
public void Move(Vector3 v)
{
Pivot.Move(v);
}
public void Rotate(float angle, Axis axis)
{
Pivot.Rotate(angle, axis);
}
public Vector2 ScreenProection(Vector3 v)
{
var local = Pivot.ToLocalCoords(v);
//
var delta = ScreenDist / local.Z;
var proection = new Vector2(local.X, local.Y) * delta;
return proection;
}
}
Dieser Code weist mehrere Fehler auf, über deren Behebung wir später sprechen werden.
Schneiden Sie unsichtbare Polygone ab
Nachdem wir auf diese Weise drei Punkte des Polygons auf den Bildschirm projiziert haben, erhalten wir die Koordinaten des Dreiecks, die der Anzeige des Polygons auf dem Bildschirm entsprechen. Auf diese Weise verarbeitet die Kamera jedoch alle Scheitelpunkte, einschließlich derer, deren Projektionen über den Bildschirmbereich hinausgehen. Wenn Sie versuchen, einen solchen Scheitelpunkt zu zeichnen, besteht eine hohe Wahrscheinlichkeit, dass Fehler erkannt werden. Die Kamera verarbeitet auch die dahinter liegenden Polygone (die z- Koordinaten ihrer Punkte in der lokalen Kamerabasis sind kleiner als z ' ) - wir brauchen auch keine solche "okzipitale" Sicht.
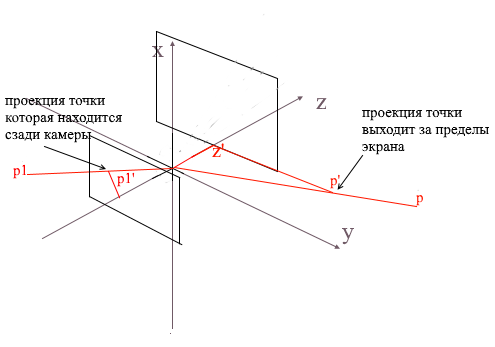
Zum Abschneiden unsichtbarer Scheitelpunkte in offenem gl wird die Methode der Kürzungspyramide verwendet. Es besteht darin, zwei Ebenen einzustellen - nahe (nahe Ebene) und fern (ferne Ebene). Alles, was zwischen diesen beiden Ebenen liegt, wird weiter verarbeitet. Ich benutze eine vereinfachte Version mit einer Schnittebene - z ' . Alle Eckpunkte dahinter sind unsichtbar.
Fügen wir der Kamera zwei neue Felder hinzu - Bildschirmbreite und -höhe.
Jetzt überprüfen wir jeden projizierten Punkt auf den Bildschirmbereich. Schneiden wir auch die Punkte hinter der Kamera ab. Wenn der Punkt dahinter liegt oder seine Projektion nicht auf den Bildschirm fällt, gibt die Methode den Punkt {float.NaN, float.NaN} zurück .
Kameracode 2
public Vector2 ScreenProection(Vector3 v)
{
var local = Pivot.ToLocalCoords(v);
//
if (local.Z < ScreenDist)
{
return new Vector2(float.NaN, float.NaN);
}
//
var delta = ScreenDist / local.Z;
var proection = new Vector2(local.X, local.Y) * delta;
// -
if (proection.X >= 0 && proection.X < ScreenWidth && proection.Y >= 0 && proection.Y < ScreenHeight)
{
return proection;
}
return new Vector2(float.NaN, float.NaN);
}
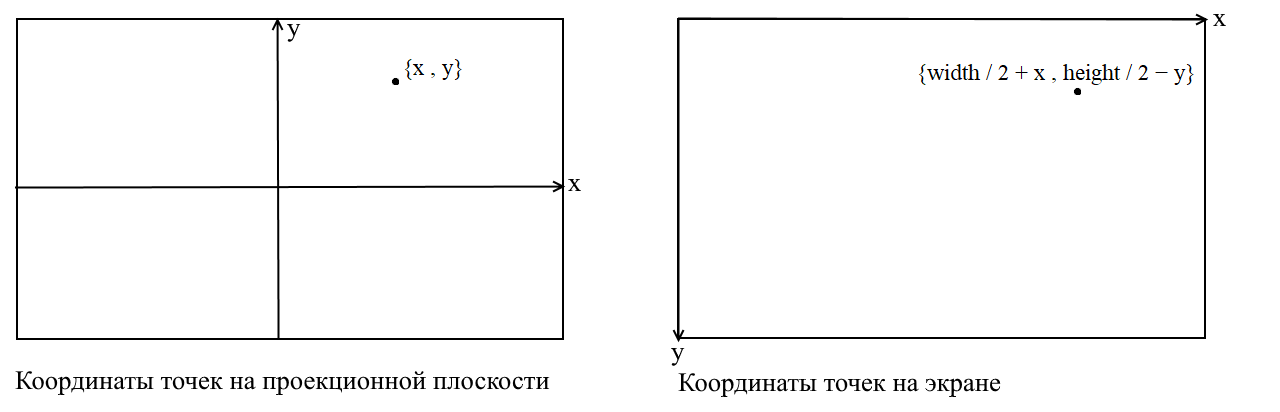
In Bildschirmkoordinaten übersetzen
Hier werde ich einen Punkt klarstellen. Dies hängt mit der Tatsache zusammen, dass in vielen Grafikbibliotheken das Zeichnen im Bildschirmkoordinatensystem erfolgt. In solchen Koordinaten ist der Ursprung der obere linke Punkt des Bildschirms, x nimmt zu, wenn Sie sich nach rechts bewegen, und y, wenn Sie sich nach unten bewegen. In unserer Projektionsebene werden Punkte in gewöhnlichen kartesischen Koordinaten dargestellt. Vor dem Zeichnen müssen diese Koordinaten in Bildschirmkoordinaten konvertiert werden. Dies ist nicht schwierig. Sie müssen lediglich den Ursprung in die obere linke Ecke verschieben und y umkehren :
Kameracode 3
public Vector2 ScreenProection(Vector3 v)
{
var local = Pivot.ToLocalCoords(v);
//
if (local.Z < ScreenDist)
{
return new Vector2(float.NaN, float.NaN);
}
//
var delta = ScreenDist / local.Z;
var proection = new Vector2(local.X, local.Y) * delta;
//
var screen = proection + new Vector2(ScreenWidth / 2, -ScreenHeight / 2);
var screenCoords = new Vector2(screen.X, -screen.Y);
// -
if (screenCoords.X >= 0 && screenCoords.X < ScreenWidth && screenCoords.Y >= 0 && screenCoords.Y < ScreenHeight)
{
return screenCoords;
}
return new Vector2(float.NaN, float.NaN);
}
Anpassen der Größe des projizierten Bildes
Wenn Sie den vorherigen Code zum Zeichnen eines Objekts verwenden, erhalten Sie Folgendes:

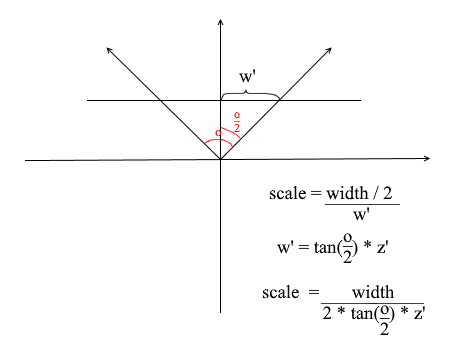
Aus irgendeinem Grund sind alle Objekte sehr klein gezeichnet. Um den Grund zu verstehen, denken Sie daran, wie wir die Projektion berechnet haben - wir haben die x- und y- Koordinaten mit dem Delta des z '/ z- Verhältnisses multipliziert . Dies bedeutet, dass die Größe des Objekts auf dem Bildschirm vom Abstand zur Projektionsebene z ' abhängt . Aber wir können z ' so klein setzen, wie wir wollen. Dies bedeutet, dass wir die Projektionsgröße abhängig vom aktuellen z'- Wert anpassen müssen . Fügen Sie dazu der Kamera ein weiteres Feld hinzu - den Blickwinkel .

Wir brauchen es, um die Winkelgröße des Bildschirms an seine Breite anzupassen. Der Winkel wird auf diese Weise an die Breite des Bildschirms angepasst: Der maximale Winkel, in den die Kamera schaut, ist der linke oder rechte Rand des Bildschirms. Dann wird der maximale Winkel von der z- Achse der Kamera ist o / 2 . Die Projektion, die auf den rechten Bildschirmrand trifft, sollte die Koordinate x = width / 2 und die linke Koordinate x = -width / 2 haben . In diesem Wissen leiten wir die Formel zum Ermitteln des Projektionsdehnungskoeffizienten ab:
Kameracode 4
public float ObserveRange { get; private set; }
public float Scale => ScreenWidth / (float)(2 * ScreenDist * Math.Tan(ObserveRange / 2));
public Vector2 ScreenProection(Vector3 v)
{
var local = Pivot.ToLocalCoords(v);
//
if (local.Z < ScreenDist)
{
return new Vector2(float.NaN, float.NaN);
}
//
var delta = ScreenDist / local.Z * Scale;
var proection = new Vector2(local.X, local.Y) * delta;
//
var screen = proection + new Vector2(ScreenWidth / 2, -ScreenHeight / 2);
var screenCoords = new Vector2(screen.X, -screen.Y);
// -
if (screenCoords.X >= 0 && screenCoords.X < ScreenWidth && screenCoords.Y >= 0 && screenCoords.Y < ScreenHeight)
{
return screenCoords;
}
return new Vector2(float.NaN, float.NaN);
}
Hier ist ein einfacher Rendering-Code, den ich für den Test verwendet habe:
Objektzeichnungscode
public DrawObject(Primitive primitive , Camera camera)
{
for (int i = 0; i < primitive.Indexes.Length; i+=3)
{
var color = randomColor();
//
var i1 = primitive.Indexes[i];
var i2 = primitive.Indexes[i+ 1];
var i3 = primitive.Indexes[i+ 2];
//
var v1 = primitive.GlobalVertices[i1];
var v2 = primitive.GlobalVertices[i2];
var v3 = primitive.GlobalVertices[i3];
//
DrawPolygon(v1,v2,v3 , camera , color);
}
}
public void DrawPolygon(Vector3 v1, Vector3 v2, Vector3 v3, Camera camera , color)
{
//
var p1 = camera.ScreenProection(v1);
var p2 = camera.ScreenProection(v2);
var p3 = camera.ScreenProection(v3);
//
DrawLine(p1, p2 , color);
DrawLine(p2, p3 , color);
DrawLine(p3, p2 , color);
}
Lassen Sie uns das Rendern der Szene und der Würfel überprüfen:
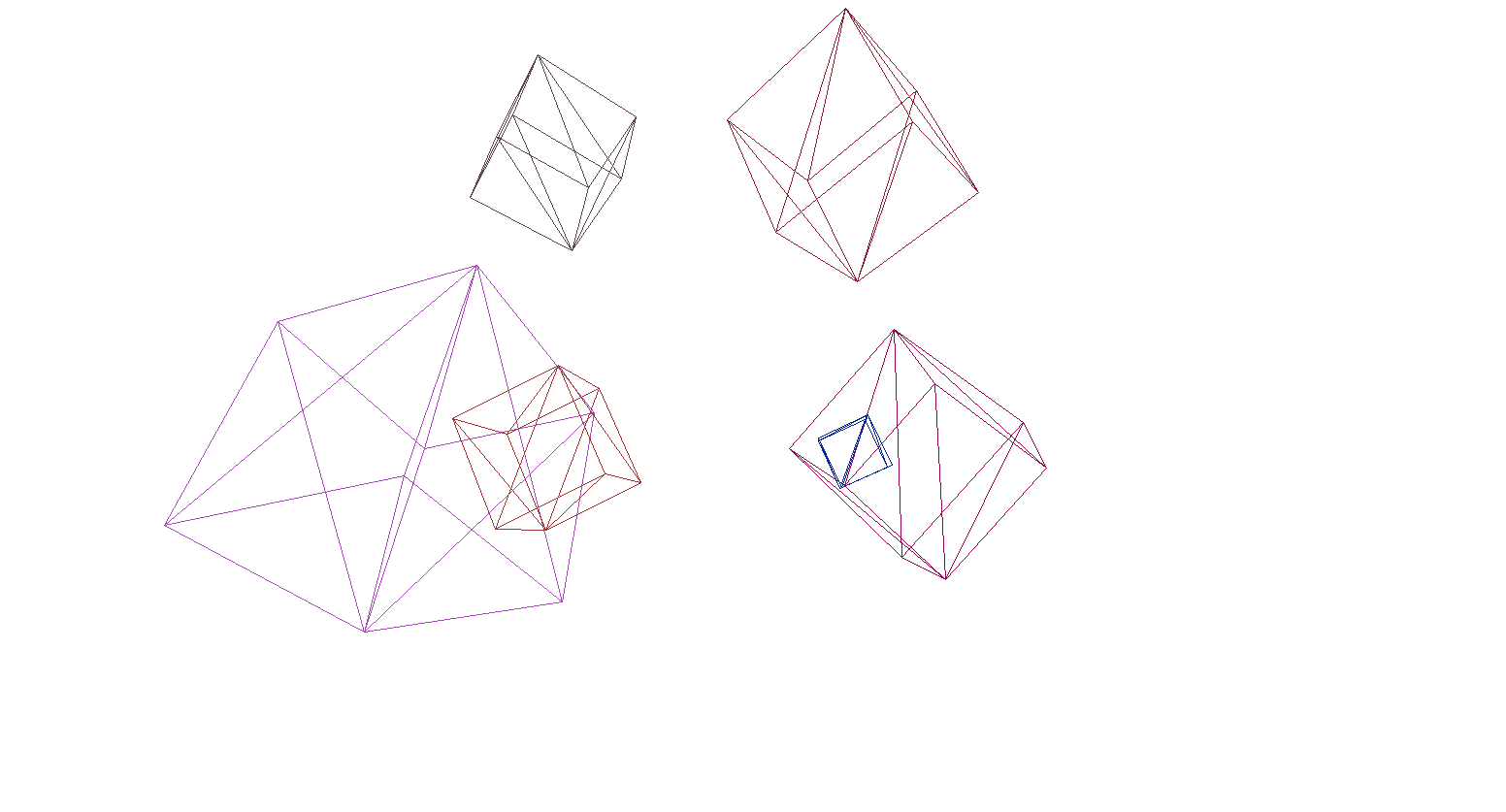
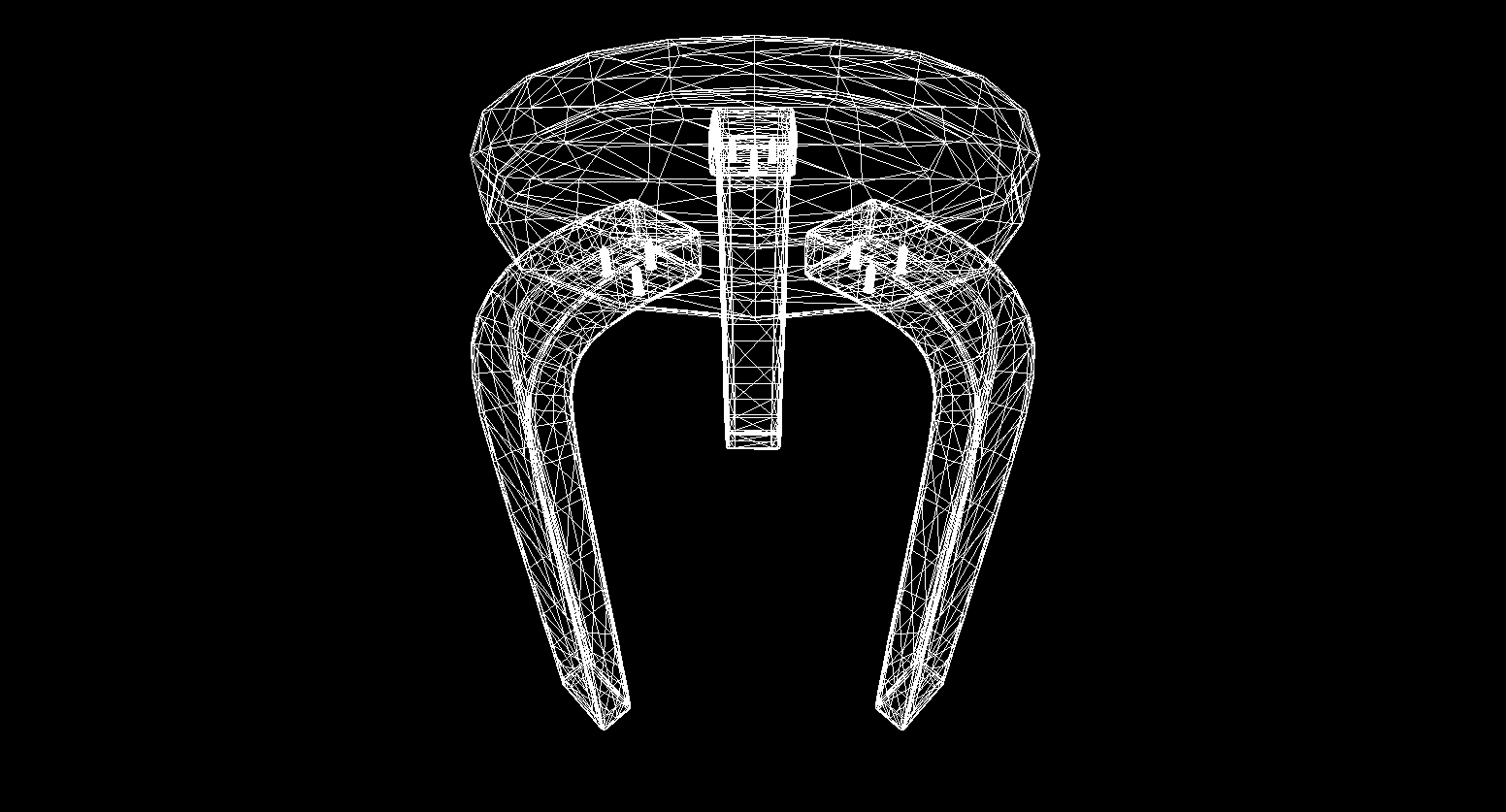
Und ja, alles funktioniert super. Für diejenigen, die bunte Würfel nicht als anmaßend empfinden, habe ich eine Funktion zum Parsen von Modellen im OBJ-Format in primitive Objekte geschrieben, den Hintergrund mit Schwarz gefüllt und mehrere Modelle gerendert:
Das Ergebnis des Renderns

Rasterisierung von Polygonen. Wir bringen Schönheit.
Im letzten Abschnitt haben wir ein Drahtgitter-Rendering geschrieben. Jetzt werden wir uns mit seiner Modernisierung befassen - wir werden die Rasterisierung von Polygonen implementieren. Ein Polygon
einfach zu rastern bedeutet, es zu übermalen . Es scheint, warum man ein Fahrrad schreibt, wenn es bereits vorgefertigte Dreiecksrasterfunktionen gibt. Folgendes passiert, wenn Sie alles mit den Standardwerkzeugen zeichnen:

Zeitgenössische Kunst, Polygone hinter den vorderen, wurden in einem Wortbrei gezeichnet. Wie kann man Objekte auf diese Weise texturieren? Ja, auf keinen Fall. Wir müssen also unseren eigenen Imba-Rasterizer schreiben, der unsichtbare Punkte , Texturen und sogar Shader abschneiden kann ! Um dies zu tun, lohnt es sich jedoch zu verstehen, wie man Dreiecke im Allgemeinen malt.
Bresenhams Algorithmus zum Strichzeichnen.
Beginnen wir mit den Zeilen. Wenn jemand den Bresenham-Algorithmus nicht kannte, ist dies der Hauptalgorithmus zum Zeichnen von geraden Linien in Computergrafiken. Er oder seine Modifikationen werden buchstäblich überall verwendet: Zeichnen von Linien, Segmenten, Kreisen usw. Wer an einer detaillierteren Beschreibung interessiert ist - lesen Sie das Wiki. Bresenhams Algorithmus
Es gibt ein Liniensegment, das die Punkte {x1, y1} und {x2, y2} verbindet . Um ein Segment zwischen ihnen zu zeichnen, müssen Sie alle Pixel übermalen, die darauf fallen. Für zwei Punkte des Segments finden Sie die x- Koordinaten der Pixel, in denen sie liegen: Sie müssen nur ganze Teile der Koordinaten x1 und x2 nehmen . Um die Pixel auf das Segment zu malen, starten wir den Zyklus von x1 bis x2 und berechnen bei jeder Iterationy - Koordinate des Pixels, das auf die Linie fällt. Hier ist der Code:
void Brezenkhem(Vector2 p1 , Vector2 p2)
{
int x1 = Floor(p1.X);
int x2 = Floor(p2.X);
if (x1 > x2) {Swap(x1, x2); Swap(p1 , p2);}
float d = (p2.Y - p1.Y) / (x2 - x1);
float y = p1.Y;
for (int i = x1; i <= x2; i++)
{
int pixelY = Floor(y);
FillPixel(i , pixelY);
y += d;
}
}

Bild aus dem Wiki
Rasterisieren Sie ein Dreieck. Füllalgorithmus
Wir wissen, wie man Linien zeichnet, aber mit Dreiecken wird es etwas schwieriger (nicht viel)! Das Zeichnen eines Dreiecks reduziert sich auf mehrere Aufgaben des Zeichnens von Linien. Teilen wir zunächst das Dreieck in zwei Teile, nachdem wir zuvor die Punkte in aufsteigender Reihenfolge x sortiert haben :
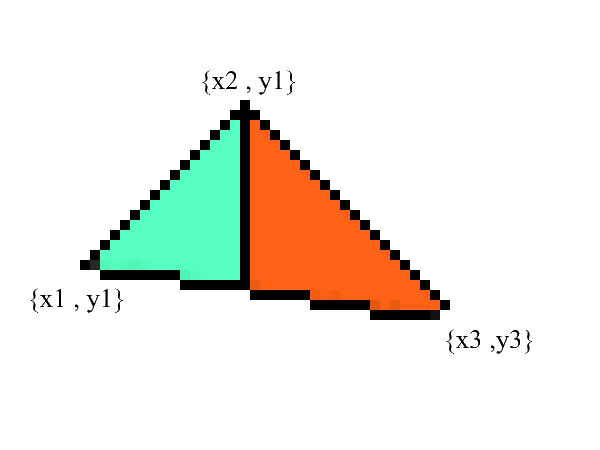
Beachten Sie - jetzt haben wir zwei Teile, in denen der untere und obere Rand klar ausgedrückt werden . Alles was bleibt ist, alle Pixel dazwischen auszufüllen! Dies kann in 2 Zyklen erfolgen: von x1 bis x2 und von x3 bis x2 .
void Triangle(Vector2 v1 , Vector2 v2 , Vector2 v3)
{
// BubbleSort x
if (v1.X > v2.X) { Swap(v1, v2); }
if (v2.X > v3.X) { Swap(v2, v3); }
if (v1.X > v2.X) { Swap(v1, v2); }
// y x
// 0: x1 == x2 -
var steps12 = max(v2.X - v1.X , 1);
var steps13 = max(v3.X - v1.X , 1);
var upDelta = (v2.Y - v1.Y) / steps12;
var downDelta = (v3.Y - v1.Y) / steps13;
//
if (upDelta < downDelta) Swap(upDelta , downDelta);
// y1
var up = v1.Y;
var down = v1.Y;
for (int i = (int)v1.X; i <= (int)v2.X; i++)
{
for (int g = (int)down; g <= (int)up; g++)
{
FillPixel(i , g);
}
up += upDelta;
down += downDelta;
}
//
var steps32 = max(v2.X - v3.X , 1);
var steps31 = max(v1.X - v3.X , 1);
upDelta = (v2.Y - v3.Y) / steps32;
downDelta = (v1.Y - v3.Y) / steps31;
if (upDelta < downDelta) Swap(upDelta, downDelta);
up = v3.Y;
down = v3.Y;
for (int i = (int)v3.X; i >=(int)v2.X; i--)
{
for (int g = (int)down; g <= (int)up; g++)
{
FillPixel(i, g);
}
up += upDelta;
down += downDelta;
}
}
Zweifellos kann dieser Code überarbeitet werden, um die Schleife nicht zu duplizieren:
void Triangle(Vector2 v1 , Vector2 v2 , Vector2 v3)
{
if (v1.X > v2.X) { Swap(v1, v2); }
if (v2.X > v3.X) { Swap(v2, v3); }
if (v1.X > v2.X) { Swap(v1, v2); }
var steps12 = max(v2.X - v1.X , 1);
var steps13 = max(v3.X - v1.X , 1);
var steps32 = max(v2.X - v3.X , 1);
var steps31 = max(v1.X - v3.X , 1);
var upDelta = (v2.Y - v1.Y) / steps12;
var downDelta = (v3.Y - v1.Y) / steps13;
if (upDelta < downDelta) Swap(upDelta , downDelta);
TrianglePart(v1.X , v2.X , v1.Y , upDelta , downDelta);
upDelta = (v2.Y - v3.Y) / steps32;
downDelta = (v1.Y - v3.Y) / steps31;
if (upDelta < downDelta) Swap(upDelta, downDelta);
TrianglePart(v3.X, v2.X, v3.Y, upDelta, downDelta);
}
void TrianglePart(float x1 , float x2 , float y1 , float upDelta , float downDelta)
{
float up = y1, down = y1;
for (int i = (int)x1; i <= (int)x2; i++)
{
for (int g = (int)down; g <= (int)up; g++)
{
FillPixel(i , g);
}
up += upDelta; down += downDelta;
}
}
Unsichtbare Punkte abschneiden.
Denken Sie zuerst darüber nach, wie Sie sehen. Jetzt befindet sich ein Bildschirm vor Ihnen, und was sich dahinter befindet, ist vor Ihren Augen verborgen. Beim Rendern funktioniert ein ähnlicher Mechanismus: Wenn ein Polygon ein anderes überlappt, wird es beim Rendern über das überlappende gezogen. Im Gegenteil, der geschlossene Teil des Polygons wird nicht gezeichnet:
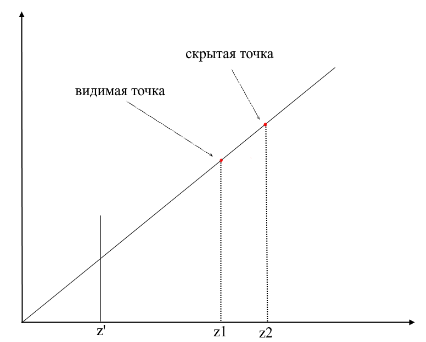
Um zu verstehen, ob die Punkte sichtbar sind oder nicht, wird beim Rendern der Z- Puffer- Mechanismus ( Tiefenpuffer ) verwendet . zbuffer kann als zweidimensionales Array (kann eindimensional komprimiert werden) mit Breite * Höhe betrachtet werden . Für jedes Pixel auf dem Bildschirm wird ein Z- Wert gespeichert - die Koordinaten auf dem ursprünglichen Polygon, von dem aus dieser Punkt projiziert wurde. Je näher der Punkt dem Betrachter ist, desto kleiner ist dementsprechend seine z- Koordinate. Wenn die Projektionen mehrerer Punkte zusammenfallen, müssen Sie den Punkt mit der minimalen z-Koordinate rastern :
Nun stellt sich die Frage - wie die finden z- Koordinaten der Punkte auf dem ursprünglichen Polygon? Dies kann auf verschiedene Arten erfolgen. Sie können beispielsweise einen Strahl vom Ursprung der Kamera aufnehmen, indem Sie durch einen Punkt auf der Projektionsebene {x, y, z '} laufen und dessen Schnittpunkt mit dem Polygon finden. Das Suchen nach Kreuzungen ist jedoch eine extrem teure Operation, daher werden wir eine andere Methode anwenden. Um ein Dreieck zu zeichnen, haben wir die Koordinaten seiner Projektionen interpoliert. Zusätzlich dazu interpolieren wir jetzt auch die Koordinaten des ursprünglichen Polygons . Um unsichtbare Punkte auszuschneiden, verwenden wir den zbuffer- Status für den aktuellen Frame in der Rasterisierungsmethode .
Mein zbuffer wird so aussehenVector3 [] - enthält nicht nur Z-Koordinaten , sondern auch interpolierte Werte von Polygonpunkten (Fragmenten) für jedes Bildschirmpixel. Dies geschieht, um Speicherplatz zu sparen, da wir diese Werte auch in Zukunft zum Schreiben von Shadern benötigen werden ! In der Zwischenzeit haben wir den folgenden Code , um die sichtbaren Eckpunkte (Fragmente) zu bestimmen :
Der Code
public void ComputePoly(Vector3 v1, Vector3 v2, Vector3 v3 , Vector3[] zbuffer)
{
//
var v1p = Camera.ScreenProection(v1);
var v2p = Camera.ScreenProection(v2);
var v3p = Camera.ScreenProection(v3);
// x -
//, -
if (v1p.X > v2p.X) { Swap(v1p, v2p); Swap(v1p, v2p); }
if (v2p.X > v3p.X) { Swap(v2p, v3p); Swap(v2p, v3p); }
if (v1p.X > v2p.X) { Swap(v1p, v2p); Swap(v1p, v2p); }
//
int x12 = Math.Max((int)v2p.X - (int)v1p.X, 1);
int x13 = Math.Max((int)v3p.X - (int)v1p.X, 1);
//
float dy12 = (v2p.Y - v1p.Y) / x12; var dr12 = (v2 - v1) / x12;
float dy13 = (v3p.Y - v1p.Y) / x13; var dr13 = (v3 - v1) / x13;
Vector3 deltaUp, deltaDown; float deltaUpY, deltaDownY;
if (dy12 > dy13) { deltaUp = dr12; deltaDown = dr13; deltaUpY = dy12; deltaDownY = dy13;}
else { deltaUp = dr13; deltaDown = dr12; deltaUpY = dy13; deltaDownY = dy12;}
TrianglePart(v1 , deltaUp , deltaDown , x12 , 1 , v1p , deltaUpY , deltaDownY , zbuffer);
// -
}
public void ComputePolyPart(Vector3 start, Vector3 deltaUp, Vector3 deltaDown,
int xSteps, int xDir, Vector2 pixelStart, float deltaUpPixel, float deltaDownPixel , Vector3[] zbuffer)
{
int pixelStartX = (int)pixelStart.X;
Vector3 up = start - deltaUp, down = start - deltaDown;
float pixelUp = pixelStart.Y - deltaUpPixel, pixelDown = pixelStart.Y - deltaDownPixel;
for (int i = 0; i <= xSteps; i++)
{
up += deltaUp; pixelUp += deltaUpPixel;
down += deltaDown; pixelDown += deltaDownPixel;
int steps = ((int)pixelUp - (int)pixelDown);
var delta = steps == 0 ? Vector3.Zero : (up - down) / steps;
Vector3 position = down - delta;
for (int g = 0; g <= steps; g++)
{
position += delta;
var proection = new Point(pixelStartX + i * xDir, (int)pixelDown + g);
int index = proection.Y * Width + proection.X;
//
if (zbuffer[index].Z == 0 || zbuffer[index].Z > position.Z)
{
zbuffer[index] = position;
}
}
}
}

Animation von Rasterizer-Schritten (beim Umschreiben der Tiefe in zbuffer wird das Pixel rot hervorgehoben): Der Einfachheit halber habe
ich den gesamten Code in ein separates Rasterizer-Modul verschoben:
Rasterizer-Klasse
public class Rasterizer
{
public Vertex[] ZBuffer;
public int[] VisibleIndexes;
public int VisibleCount;
public int Width;
public int Height;
public Camera Camera;
public Rasterizer(Camera camera)
{
Shaders = shaders;
Width = camera.ScreenWidth;
Height = camera.ScreenHeight;
Camera = camera;
}
public Bitmap Rasterize(IEnumerable<Primitive> primitives)
{
var buffer = new Bitmap(Width , Height);
ComputeVisibleVertices(primitives);
for (int i = 0; i < VisibleCount; i++)
{
var vec = ZBuffer[index];
var proec = Camera.ScreenProection(vec);
buffer.SetPixel(proec.X , proec.Y);
}
return buffer.Bitmap;
}
public void ComputeVisibleVertices(IEnumerable<Primitive> primitives)
{
VisibleCount = 0;
VisibleIndexes = new int[Width * Height];
ZBuffer = new Vertex[Width * Height];
foreach (var prim in primitives)
{
foreach (var poly in prim.GetPolys())
{
MakeLocal(poly);
ComputePoly(poly.Item1, poly.Item2, poly.Item3);
}
}
}
public void MakeLocal(Poly poly)
{
poly.Item1.Position = Camera.Pivot.ToLocalCoords(poly.Item1.Position);
poly.Item2.Position = Camera.Pivot.ToLocalCoords(poly.Item2.Position);
poly.Item3.Position = Camera.Pivot.ToLocalCoords(poly.Item3.Position);
}
}
Lassen Sie uns nun die Renderarbeit überprüfen. Dafür benutze ich Sylvanas 'Modell aus dem berühmten Rollenspiel "WOW":

Nicht sehr klar, oder? Dies liegt daran, dass hier keine Texturen oder Beleuchtung vorhanden sind. Aber wir werden es bald beheben.
Texturen! Normal! Beleuchtung! Motor!
Warum habe ich alles in einem Abschnitt zusammengefasst? Und weil Texturierung und Berechnung von Normalen im Wesentlichen absolut identisch sind und Sie dies bald verstehen werden.
Schauen wir uns zunächst die Texturierungsaufgabe für ein Polygon an. Zusätzlich zu den üblichen Koordinaten der Eckpunkte des Polygons werden nun auch dessen Texturkoordinaten gespeichert . Die Texturkoordinate des Scheitelpunkts wird als 2D-Vektor dargestellt und zeigt auf ein Pixel im Texturbild. Ich habe im Internet ein gutes Bild gefunden, um dies zu zeigen:

Beachten Sie, dass der Anfang der Textur ( Pixel unten links ) in Texturkoordinaten {0, 0} und das Ende ( Pixel oben rechts ) {1, 1} ist . Berücksichtigen Sie das Texturkoordinatensystem und die Möglichkeit, bei einer Texturkoordinate von 1 über die Bildgrenzen hinauszugehen.
Erstellen Sie eine Klasse, um die Scheitelpunktdaten sofort darzustellen:
public class Vertex
{
public Vector3 Position { get; set; }
public Color Color { get; set; }
public Vector2 TextureCoord { get; set; }
public Vector3 Normal { get; set; }
public Vertex(Vector3 pos , Color color , Vector2 texCoord , Vector3 normal)
{
Position = pos;
Color = color;
TextureCoord = texCoord;
Normal = normal;
}
}
Ich werde später erklären, warum Normalen benötigt werden. Im Moment wissen wir nur, dass Eckpunkte sie haben können. Um das Polygon zu texturieren, müssen wir den Farbwert von der Textur auf ein bestimmtes Pixel abbilden . Erinnerst du dich, wie wir die Eckpunkte interpoliert haben? Mach das gleiche hier! Ich werde den Rasterisierungscode nicht erneut schreiben, aber ich schlage vor, dass Sie die Texturierung in Ihrem Rendering selbst implementieren. Das Ergebnis sollte die korrekte Anzeige von Texturen auf dem Modell sein. Folgendes habe ich bekommen:
strukturiertes Modell

Alle Informationen zu den Texturkoordinaten des Modells befinden sich in der OBJ-Datei. Um dies zu verwenden, lernen Sie das Format: OBJ-Format.
Beleuchtung
Mit Texturen hat alles viel mehr Spaß gemacht, aber es wird wirklich Spaß machen, wenn wir die Beleuchtung für die Szene implementieren. Um "billige" Beleuchtung zu simulieren, werde ich das Phong-Modell verwenden .
Phong Modell
Im Allgemeinen simuliert diese Methode das Vorhandensein von drei Beleuchtungskomponenten: Hintergrund (Umgebung), Streuung (diffus) und Spiegel (Reflexion). Die Summe dieser drei Komponenten simuliert schließlich das physikalische Verhalten von Licht.

Phong Modell
Um die Phong berechnen Beleuchtung Wir brauchen Oberflächennormalen , dafür ich sie in der VertexKlasse hinzugefügt. Woher können wir die Werte dieser Normalen bekommen? Nein, wir müssen nichts berechnen. Tatsache ist, dass großzügige 3D-Editoren sie häufig selbst betrachten und Modelle zusammen mit den Daten im Kontext des OBJ-Formatsbereitstellen. Nachdem wir die Modelldatei analysiert haben, erhalten wir den Normalwert für 3 Eckpunkte jedes Polygons.
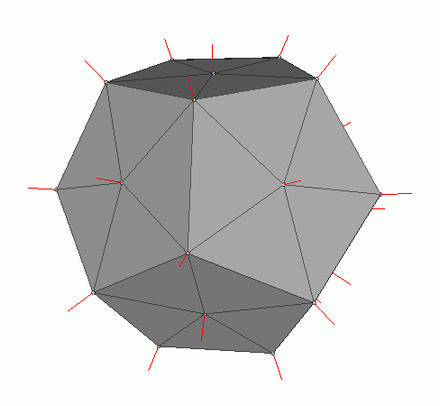
Bild aus dem Wiki
Um die Normalen an jedem Punkt des Polygons zu berechnen, müssen Sie diese Werte interpolieren. Wir wissen bereits, wie das geht. Schauen wir uns nun alle Komponenten zur Berechnung der Phong-Beleuchtung an.
Hintergrundlicht (Umgebungslicht)
Zunächst stellen wir die konstante Hintergrundbeleuchtung ein . Für nicht strukturierte Objekte können Sie eine beliebige Farbe für Objekte mit Texturen auswählen. Ich teile jede der RGB-Komponenten in einem Verhältnis der Grundschattierung (baseShading).
Diffuses Licht
Wenn Licht auf die Oberfläche des Polygons trifft, wird es gleichmäßig gestreut. Um den diffusen Wert bei einem bestimmten Pixel zu berechnen , wird der Winkel berücksichtigt, unter dem das Licht auf die Oberfläche trifft. Um diesen Winkel zu berechnen, können Sie das Punktprodukt des einfallenden Strahls und der Normalen anwenden (natürlich müssen die Vektoren vorher normalisiert werden). Dieser Winkel wird mit einem Lichtintensitätsfaktor multipliziert. Wenn das Punktprodukt negativ ist, bedeutet dies, dass der Winkel zwischen den Vektoren größer als 90 Grad ist. In diesem Fall beginnen wir damit, nicht die Aufhellung, sondern im Gegenteil die Schattierung zu berechnen. Es lohnt sich, diesen Punkt zu vermeiden. Sie können dies mit der Max- Funktion tun .
Der Code
public interface IShader
{
void ComputeShader(Vertex vertex, Camera camera);
}
public struct Light
{
public Vector3 Pos;
public float Intensivity;
}
public class PhongModelShader : IShader
{
public static float DiffuseCoef = 0.1f;
public Light[] Lights { get; set; }
public PhongModelShader(params Light[] lights)
{
Lights = lights;
}
public void ComputeShader(Vertex vertex, Camera camera)
{
if (vertex.Normal.X == 0 && vertex.Normal.Y == 0 && vertex.Normal.Z == 0)
{
return;
}
var gPos = camera.Pivot.ToGlobalCoords(vertex.Position);
foreach (var light in Lights)
{
var ldir = Vector3.Normalize(light.Pos - gPos);
var diffuseVal = Math.Max(VectorMath.Cross(ldir, vertex.Normal), 0) * light.Intensivity;
vertex.Color = Color.FromArgb(vertex.Color.A,
(int)Math.Min(255, vertex.Color.R * diffuseVal * DiffuseCoef),
(int)Math.Min(255, vertex.Color.G * diffuseVal * DiffuseCoef,
(int)Math.Min(255, vertex.Color.B * diffuseVal * DiffuseCoef));
}
}
}
Wenden wir diffuses Licht an und zerstreuen die Dunkelheit:

Spiegellicht (Reflect)
Um die Spiegelkomponente zu berechnen, müssen Sie den Punkt berücksichtigen , von dem aus wir das Objekt betrachten . Nun nehmen wir dem Betrachter das Punktprodukt des Strahls und den von der Oberfläche reflektierten Strahl multipliziert mit dem Lichtintensitätsfaktor.
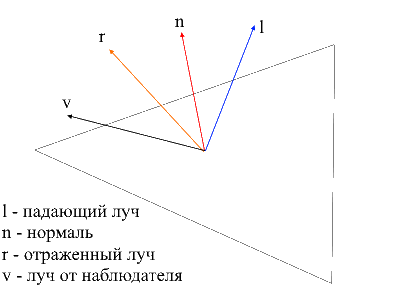
Es ist leicht, den Strahl vom Beobachter zur Oberfläche zu finden - es ist einfach die Position des verarbeiteten Scheitelpunkts in lokalen Koordinaten . Um den reflektierten Strahl zu finden, habe ich die folgende Methode verwendet. Der einfallende Strahl kann in zwei Vektoren zerlegt werden: seine Projektion auf den Normalen und den zweiten Vektor, die durch Subtrahieren dieser Projektion vom einfallenden Strahl gefunden werden können. Um den reflektierten Strahl zu finden, müssen Sie den Wert des zweiten Vektors von der Projektion auf die Normalen subtrahieren.
der Code
public class PhongModelShader : IShader
{
public static float DiffuseCoef = 0.1f;
public static float ReflectCoef = 0.2f;
public Light[] Lights { get; set; }
public PhongModelShader(params Light[] lights)
{
Lights = lights;
}
public void ComputeShader(Vertex vertex, Camera camera)
{
if (vertex.Normal.X == 0 && vertex.Normal.Y == 0 && vertex.Normal.Z == 0)
{
return;
}
var gPos = camera.Pivot.ToGlobalCoords(vertex.Position);
foreach (var light in Lights)
{
var ldir = Vector3.Normalize(light.Pos - gPos);
//
var proection = VectorMath.Proection(ldir, -vertex.Normal);
var d = ldir - proection;
var reflect = proection - d;
var diffuseVal = Math.Max(VectorMath.Cross(ldir, -vertex.Normal), 0) * light.Intensivity;
//
var eye = Vector3.Normalize(-vertex.Position);
var reflectVal = Math.Max(VectorMath.Cross(reflect, eye), 0) * light.Intensivity;
var total = diffuseVal * DiffuseCoef + reflectVal * ReflectCoef;
vertex.Color = Color.FromArgb(vertex.Color.A,
(int)Math.Min(255, vertex.Color.R * total),
(int)Math.Min(255, vertex.Color.G * total),
(int)Math.Min(255, vertex.Color.B * total));
}
}
}
Jetzt sieht das Bild so aus:

Schatten
Der Endpunkt meiner Präsentation wird die Implementierung von Schatten zum Rendern sein. Die erste Sackgasse, die aus meinem Schädel stammt, besteht darin, für jeden Punkt zu überprüfen, ob sich zwischen ihm und dem Licht ein Polygon befindet . Wenn dies der Fall ist, müssen Sie das Pixel nicht beleuchten. Das Modell von Sylvanas enthält mehr als 220.000 Polygone. Wenn dies für jeden Punkt der Fall ist, um den Schnittpunkt mit all diesen Polygonen zu überprüfen, müssen Sie maximal 220.000 * 1920 * 1080 * 219999 Aufrufe der Schnittpunktmethode ausführen ! In 10 Minuten konnte mein Computer den 10. Teil aller Berechnungen (2600 Polygone von 220.000) beherrschen. Danach hatte ich eine Schicht und machte mich auf die Suche nach einer neuen Methode.
Im Internet bin ich auf eine sehr einfache und schöne Art und Weise gestoßen, die dieselben Berechnungen durchführttausende Male schneller . Es heißt Shadow Mapping . Denken Sie daran, wie wir die für den Beobachter sichtbaren Punkte bestimmt haben - wir haben zbuffer verwendet . Shadow Mapping macht das Gleiche! Im ersten Durchgang befindet sich unsere Kamera in der Lichtposition und schaut auf das Objekt. Dadurch wird eine Tiefenkarte für die Lichtquelle erstellt. Die Tiefenkarte ist der bekannte Z-Puffer. Im zweiten Durchgang verwenden wir diese Karte, um zu bestimmen, welche Scheitelpunkte beleuchtet werden sollen. Jetzt werde ich die Regeln für guten Code brechen und den Cheat-Pfad beschreiten. Ich gebe dem Shader einfach ein neues Rasterizer-Objekt und erstelle damit eine Tiefenkarte für uns.
Der Code
public class ShadowMappingShader : IShader
{
public Enviroment Enviroment { get; set; }
public Rasterizer Rasterizer { get; set; }
public Camera Camera => Rasterizer.Camera;
public Pivot Pivot => Camera.Pivot;
public Vertex[] ZBuffer => Rasterizer.ZBuffer;
public float LightIntensivity { get; set; }
public ShadowMappingShader(Enviroment enviroment, Rasterizer rasterizer, float lightIntensivity)
{
Enviroment = enviroment;
LightIntensivity = lightIntensivity;
Rasterizer = rasterizer;
// ,
// /
Camera.OnRotate += () => UpdateDepthMap(Enviroment.Primitives);
Camera.OnMove += () => UpdateDepthMap(Enviroment.Primitives);
Enviroment.OnChange += () => UpdateDepthMap(Enviroment.Primitives);
UpdateVisible(Enviroment.Primitives);
}
public void ComputeShader(Vertex vertex, Camera camera)
{
//
var gPos = camera.Pivot.ToGlobalCoords(vertex.Position);
//
var lghDir = Pivot.Center - gPos;
var distance = lghDir.Length();
var local = Pivot.ToLocalCoords(gPos);
var proectToLight = Camera.ScreenProection(local).ToPoint();
if (proectToLight.X >= 0 && proectToLight.X < Camera.ScreenWidth && proectToLight.Y >= 0
&& proectToLight.Y < Camera.ScreenHeight)
{
int index = proectToLight.Y * Camera.ScreenWidth + proectToLight.X;
if (ZBuffer[index] == null || ZBuffer[index].Position.Z >= local.Z)
{
vertex.Color = Color.FromArgb(vertex.Color.A,
(int)Math.Min(255, vertex.Color.R + LightIntensivity / distance),
(int)Math.Min(255, vertex.Color.G + LightIntensivity / distance),
(int)Math.Min(255, vertex.Color.B + LightIntensivity / distance));
}
}
else
{
vertex.Color = Color.FromArgb(vertex.Color.A,
(int)Math.Min(255, vertex.Color.R + (LightIntensivity / distance) / 15),
(int)Math.Min(255, vertex.Color.G + (LightIntensivity / distance) / 15),
(int)Math.Min(255, vertex.Color.B + (LightIntensivity / distance) / 15));
}
}
public void UpdateDepthMap(IEnumerable<Primitive> primitives)
{
Rasterizer.ComputeVisibleVertices(primitives);
}
}
Für eine statische Szene reicht es aus, die Konstruktion der Tiefenkarte einmal aufzurufen und dann in allen Frames zu verwenden. Als Test verwende ich ein weniger polygonales Modell der Waffe. Dies ist das Ausgabebild:

Viele von Ihnen haben wahrscheinlich die Artefakte dieses Shaders bemerkt (schwarze Punkte, die nicht vom Licht verarbeitet wurden). Als ich mich wieder dem allwissenden Netzwerk zuwandte, fand ich eine Beschreibung dieses Effekts mit dem bösen Namen "Schattenakne" (vergib mir Menschen mit einem komplexen Erscheinungsbild). Das Wesentliche an solchen "Lücken" ist, dass wir die begrenzte Auflösung der Tiefenkarte verwenden, um den Schatten zu definieren. Dies bedeutet, dass mehrere Scheitelpunkte beim Rendern einen Wert aus der Tiefenkarte erhalten. Am anfälligsten für dieses Artefakt sind Oberflächen, auf die Licht in einem sanften Winkel fällt . Der Effekt kann durch Erhöhen der Renderauflösung der Lichter korrigiert werden, es gibt jedoch einen eleganteren Weg . Es besteht im Hinzufügeneine spezifische Verschiebung der Tiefe in Abhängigkeit vom Winkel zwischen dem Lichtstrahl und der Oberfläche . Dies kann mit dem Punktprodukt erfolgen.
Verbesserte Schatten

public class ShadowMappingShader : IShader
{
public Enviroment Enviroment { get; set; }
public Rasterizer Rasterizer { get; set; }
public Camera Camera => Rasterizer.Camera;
public Pivot Pivot => Camera.Pivot;
public Vertex[] ZBuffer => Rasterizer.ZBuffer;
public float LightIntensivity { get; set; }
public ShadowMappingShader(Enviroment enviroment, Rasterizer rasterizer, float lightIntensivity)
{
Enviroment = enviroment;
LightIntensivity = lightIntensivity;
Rasterizer = rasterizer;
// ,
// /
Camera.OnRotate += () => UpdateDepthMap(Enviroment.Primitives);
Camera.OnMove += () => UpdateDepthMap(Enviroment.Primitives);
Enviroment.OnChange += () => UpdateDepthMap(Enviroment.Primitives);
UpdateVisible(Enviroment.Primitives);
}
public void ComputeShader(Vertex vertex, Camera camera)
{
//
var gPos = camera.Pivot.ToGlobalCoords(vertex.Position);
//
var lghDir = Pivot.Center - gPos;
var distance = lghDir.Length();
var local = Pivot.ToLocalCoords(gPos);
var proectToLight = Camera.ScreenProection(local).ToPoint();
if (proectToLight.X >= 0 && proectToLight.X < Camera.ScreenWidth && proectToLight.Y >= 0
&& proectToLight.Y < Camera.ScreenHeight)
{
int index = proectToLight.Y * Camera.ScreenWidth + proectToLight.X;
var n = Vector3.Normalize(vertex.Normal);
var ld = Vector3.Normalize(lghDir);
//
float bias = (float)Math.Max(10 * (1.0 - VectorMath.Cross(n, ld)), 0.05);
if (ZBuffer[index] == null || ZBuffer[index].Position.Z + bias >= local.Z)
{
vertex.Color = Color.FromArgb(vertex.Color.A,
(int)Math.Min(255, vertex.Color.R + LightIntensivity / distance),
(int)Math.Min(255, vertex.Color.G + LightIntensivity / distance),
(int)Math.Min(255, vertex.Color.B + LightIntensivity / distance));
}
}
else
{
vertex.Color = Color.FromArgb(vertex.Color.A,
(int)Math.Min(255, vertex.Color.R + (LightIntensivity / distance) / 15),
(int)Math.Min(255, vertex.Color.G + (LightIntensivity / distance) / 15),
(int)Math.Min(255, vertex.Color.B + (LightIntensivity / distance) / 15));
}
}
public void UpdateDepthMap(IEnumerable<Primitive> primitives)
{
Rasterizer.ComputeVisibleVertices(primitives);
}
}
Bonus
, , 3 . , .

:

:
FPS 1-2 /. realtime. , , .. cpu.
, , 3 . , .
:
float angle = (float)Math.PI / 90;
var shader = (preparer.Shaders[0] as PhongModelShader);
for (int i = 0; i < 180; i+=2)
{
shader.Lights[0] = = new Light()
{
Pos = shader.Lights[0].Pos.Rotate(angle , Axis.X) ,
Intensivity = shader.Lights[0].Intensivity
};
Draw();
}
:
- : 220 .
- : 1920x1080.
- : Phong model shader
- : cpu — core i7 4790, 8 gb ram
FPS 1-2 /. realtime. , , .. cpu.
Fazit
Ich betrachte mich als Anfänger in 3D-Grafiken und schließe die Fehler, die ich im Verlauf der Präsentation gemacht habe, nicht aus. Das einzige, worauf ich mich verlasse, ist das praktische Ergebnis, das im Schöpfungsprozess erzielt wird. Sie können alle Korrekturen und Optimierungen (falls vorhanden) in den Kommentaren hinterlassen, ich werde sie gerne lesen. Link zum Projekt-Repository .