
Stellen Sie sich ein 2,5-Gigabyte-Protokoll nach einem fehlgeschlagenen Build vor. Das sind drei Millionen Zeilen. Sie suchen nach einem Fehler oder einer Regression, die in der millionsten Zeile angezeigt wird. Es ist wahrscheinlich einfach unmöglich, eine solche Zeile manuell zu finden. Eine Option ist ein Unterschied zwischen den letzten erfolgreichen und fehlgeschlagenen Builds in der Hoffnung, dass der Fehler ungewöhnliche Zeilen in die Protokolle schreibt. Die Lösung von Netflix ist schneller und genauer als LogReduce - unter dem Strich.
Netflix und die Zeile im Protokollstapel
Das Standard- MD5- Diff ist schnell, druckt jedoch mindestens Hunderttausende von Kandidatenzeilen zur Anzeige, da es Linienunterschiede anzeigt. Eine Variation von logreduce ist ein Fuzzy-Diff unter Verwendung einer Suche nach k-nächsten Nachbarn, bei der etwa 40.000 Kandidaten gefunden werden. Dies dauert jedoch eine Stunde. Die folgende Lösung findet 20.000 Kandidatenzeichenfolgen in 20 Minuten. Dank der Magie von Open Source sind dies nur etwa hundert Zeilen Python-Code.
Lösung - eine Kombination aus Vektorwortdarstellungen , die die semantische Information von Wörtern und Sätzen codieren, und einem ortsbezogenen Hash(LSH - Local Sensitive Hash), das ungefähr nahe Elemente effektiv in einige Gruppen und entfernte Elemente in andere Gruppen verteilt. Vektordarstellungen von Worten und LSH zu verbinden , ist eine großartige Idee , weniger als zehn Jahre vor .
Hinweis: Wir haben Tensorflow 2.2 auf der CPU und mit sofortiger Ausführung zum Transferlernen und Scikit-LernenNearestNeighborfür k nächste Nachbarn ausgeführt. Es gibt komplexe Annäherungen an die nächsten Nachbarn , die zur Lösung des modellbasierten Problems der nächsten Nachbarn besser geeignet wären.
Vektorwortdarstellung: Was ist das und warum?
Das Erstellen einer Worttasche mit k Kategorien (k-Hot-Codierung, Verallgemeinerung der einheitlichen Codierung) ist ein typischer (und nützlicher) Ausgangspunkt für Deduplizierungs-, Such- und Ähnlichkeitsprobleme zwischen unstrukturiertem und halbstrukturiertem Text. Diese Art der Codierung von Wörtern sieht aus wie ein Wörterbuch mit einzelnen Wörtern und deren Anzahl. Beispiel mit dem Satz "Anmeldefehler, Log prüfen".
{"log": 2, "in": 1, "error": 1, "check": 1}
Diese Codierung wird auch durch einen Vektor dargestellt, wobei der Index einem Wort und der Wert der Anzahl der Wörter entspricht. Im Folgenden wird der Ausdruck "Anmeldefehler, Protokoll prüfen" als Vektor angezeigt, wobei der erste Eintrag für das Zählen der Wörter "log", der zweite für das Zählen der Wörter "in" usw. reserviert ist:
[2, 1, 1, 1, 0, 0, 0, 0, 0, ...]
Bitte beachten Sie: Der Vektor besteht aus vielen Nullen. Nullen sind alle anderen Wörter im Wörterbuch, die nicht in diesem Satz enthalten sind. Die Gesamtzahl der möglichen Vektoreinträge oder die Dimension eines Vektors entspricht der Größe des Wortschatzes Ihrer Sprache, der häufig aus Millionen von Wörtern oder mehr besteht, aber mit cleveren Tricks auf Hunderttausende komprimiert wird .
Schauen wir uns das Wörterbuch und die Vektordarstellungen des Ausdrucks "Problemauthentifizierung" an. Wörter, die mit den ersten fünf Vektoreinträgen übereinstimmen, werden im neuen Satz überhaupt nicht angezeigt.
{"problem": 1, "authenticating": 1}
Es stellt sich heraus:
[0, 0, 0, 0, 1, 1, 0, 0, 0, ...]
Die Sätze "Problemauthentifizierung" und "Anmeldefehler, Prüfprotokoll" sind semantisch ähnlich. Das heißt, sie sind im Wesentlichen dasselbe, aber lexikalisch so unterschiedlich wie möglich. Sie haben keine gemeinsamen Worte. In Bezug auf Fuzzy Diff könnten wir sagen, dass sie zu ähnlich sind, um sie zu unterscheiden, aber die md5-Codierung und das von k-hot mit kNN verarbeitete Dokument unterstützen dies nicht.
Die Dimensionsreduktion verwendet lineare Algebra oder künstliche neuronale Netze, um semantisch ähnliche Wörter, Sätze oder Protokollzeilen in einem neuen Vektorraum nebeneinander zu platzieren. Vektordarstellungen werden verwendet. In unserem Beispiel kann "Anmeldefehler, Prüfprotokoll" einen fünfdimensionalen Vektor haben, der Folgendes darstellt:
[0.1, 0.3, -0.5, -0.7, 0.2]
Der Ausdruck "Problemauthentifizierung" kann sein
[0.1, 0.35, -0.5, -0.7, 0.2]
Diese Vektoren sind in der Nähe zueinander in Bezug auf Maßnahmen wie Kosinusähnlichkeit , hinsichtlich ihrer wordbag Vektoren entgegengesetzt. Dichte Ansichten mit geringer Größe sind sehr nützlich für kurze Dokumente wie Fließbänder oder Syslog.
Tatsächlich würden Sie Tausende oder mehr der Dimensionen des Wörterbuchs durch eine 100-dimensionale Darstellung ersetzen, die reich an Informationen ist (nicht fünf). Moderne Ansätze zur Dimensionsreduktion umfassen die Singularwertzerlegung der Wortkoexistenzmatrix ( GloVe ) und spezialisierter neuronaler Netze ( word2vec , BERT , ELMo ).
Was ist mit Clustering? Kehren wir zum Build-Protokoll zurück
Wir scherzen, dass Netflix ein Protokollproduktionsdienst ist, der gelegentlich Videos streamt. Protokollierung, Streaming, Ausnahmebehandlung - das sind Hunderttausende von Anforderungen pro Sekunde. Daher ist eine Skalierung erforderlich, wenn wir angewandte ML in der Telemetrie und Protokollierung anwenden möchten. Aus diesem Grund achten wir darauf, die Text-Deduplizierung zu skalieren, nach semantischen Ähnlichkeiten zu suchen und Text-Ausreißer zu erkennen. Wenn geschäftliche Probleme in Echtzeit gelöst werden, gibt es keinen anderen Weg.
Unsere Lösung besteht darin, jede Zeile in einem niedrigdimensionalen Vektor darzustellen und optional das Einbettungsmodell zu "optimieren" oder gleichzeitig zu aktualisieren, es einem Cluster zuzuweisen und die Linien in verschiedenen Clustern als "unterschiedlich" zu definieren. Standortbezogenes Hashing- Ein probabilistischer Algorithmus, mit dem Sie Cluster in konstanter Zeit zuweisen und in nahezu konstanter Zeit nach nächsten Nachbarn suchen können.
LSH ordnet eine Vektordarstellung einer Reihe von Skalaren zu. Standard-Hashing-Algorithmen neigen dazu, Kollisionen zwischen zwei übereinstimmenden Eingaben zu vermeiden . LSH versucht, Kollisionen zu vermeiden, wenn die Eingaben weit voneinander entfernt sind, und fördert sie, wenn sie unterschiedlich sind, aber im Vektorraum nahe beieinander liegen.
Der Vektor, der den Ausdruck "Anmeldefehler, Fehler überprüfen" darstellt, kann mit einer Binärzahl abgeglichen werden
01. Dann01repräsentiert einen Cluster. Der Vektor "Problemauthentifizierung" mit hoher Wahrscheinlichkeit kann auch in 01 angezeigt werden. LSH liefert also einen Fuzzy-Vergleich und löst das inverse Problem - einen Fuzzy-Unterschied. Frühe Anwendungen von LSH betrafen mehrdimensionale Vektorräume aus einer Reihe von Wörtern. Wir konnten uns keinen einzigen Grund vorstellen, warum er nicht mit Räumen der Vektordarstellung von Wörtern arbeiten würde. Es gibt Hinweise darauf, dass andere dasselbe dachten .

Das Obige zeigt die Verwendung von LSH, wenn Zeichen in derselben Gruppe platziert werden, jedoch verkehrt herum.
Die Arbeit, die wir geleistet haben, um LSH- und Vektor-Cutaways durch Erkennen von Textausreißern in Build-Protokollen anzuwenden, ermöglicht es dem Techniker nun, einen kleinen Teil der Protokollzeilen anzuzeigen, um potenzielle geschäftskritische Fehler zu identifizieren und zu beheben. Außerdem können Sie nahezu jede Protokollzeile in Echtzeit semantisch gruppieren.
Dieser Ansatz funktioniert jetzt in jedem Build von Netflix. Mit dem semantischen Teil können Sie scheinbar unterschiedliche Elemente anhand ihrer Bedeutung gruppieren und in Emissionsberichten anzeigen.
Einige Beispiele
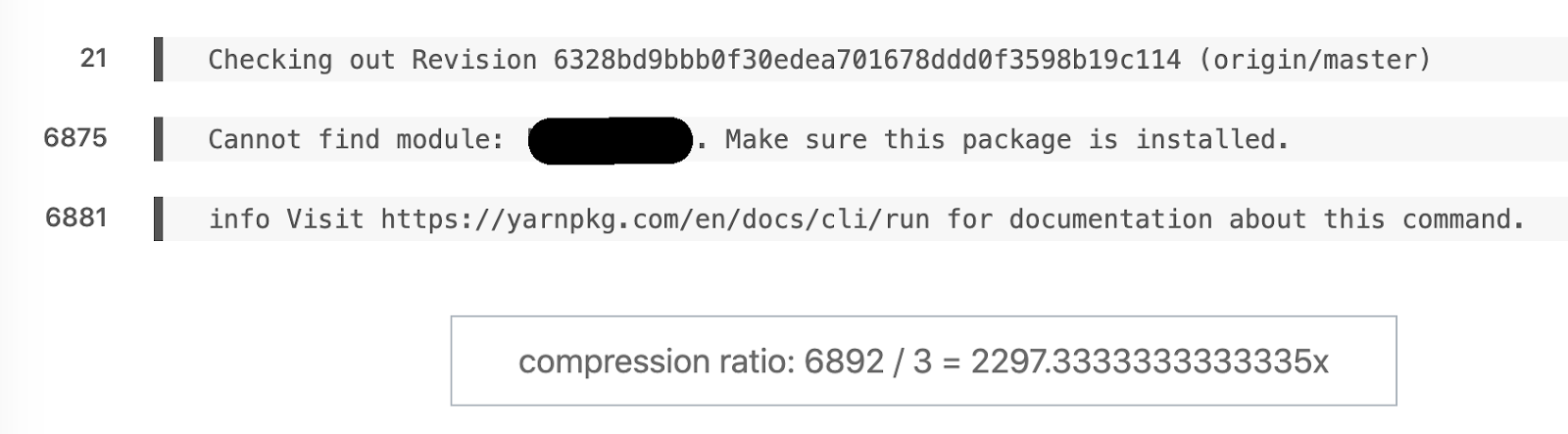
Lieblingsbeispiel für semantisches Diff. Aus 6892 Zeilen wurde 3.
Ein weiteres Beispiel: Diese Baugruppe zeichnete 6044 Zeilen auf, aber 171 blieben im Bericht. Das Hauptproblem trat fast sofort in Zeile 4036 auf.

Natürlich ist es schneller, 171 Zeilen zu analysieren als 6044. Aber wie haben wir so große Baugruppenprotokolle erhalten? Einige der Tausenden von Build-Aufgaben, bei denen es sich um Stresstests für die Unterhaltungselektronik handelt, werden im Trace-Modus ausgeführt. Es ist schwierig, mit einem solchen Datenvolumen ohne vorherige Verarbeitung zu arbeiten.

Kompressionsverhältnis: 91366/455 = 205,3.
Es gibt verschiedene Beispiele, die die semantischen Unterschiede zwischen Frameworks, Sprachen und Build-Skripten widerspiegeln.
Fazit
Die Reife der Open-Source-Transfer-Lernprodukte und des SDK hat das Problem der semantischen Suche nach nächsten Nachbarn mit LSH in sehr wenigen Codezeilen gelöst. Wir waren an den besonderen Vorteilen interessiert, die Transferlernen und Feinabstimmung für die App bringen. Wir freuen uns, solche Probleme lösen zu können und Menschen dabei zu helfen, das zu tun, was sie besser und schneller tun.
Wir hoffen, Sie erwägen, Netflix beizutreten und einer der großartigen Kollegen zu werden, deren Leben wir durch maschinelles Lernen erleichtern. Engagement ist der Kernwert von Netflix, und wir sind besonders daran interessiert, unterschiedliche Perspektiven für Technologieteams zu fördern. Wenn Sie in den Bereichen Analytik, Ingenieurwesen, Datenwissenschaft oder einem anderen Bereich tätig sind und einen branchenüblichen Hintergrund haben, würden wir uns besonders freuen, von Ihnen zu hören!
Wenn Sie Fragen zu den Netflix-Funktionen haben, wenden Sie sich bitte an die LinkedIn- Mitarbeiter : Stanislav Kirdey , William High Wie lösen Sie das Problem bei der Protokollsuche
?
Erfahren Sie in Online-Kursen zu SkillFactory, wie Sie einen hochkarätigen Beruf von Grund auf neu aufbauen oder Ihre Fähigkeiten und Ihr Gehalt verbessern können:
- Machine Learning (12 )
- «Machine Learning Pro + Deep Learning» (20 )
- « Machine Learning Data Science» (20 )
- Data Science (12 )
E
