
Ich schreibe viel über die Erforschung kniffliger Fehler - CPU-Fehler, Kernel-Fehler, mittlere Speicherzuweisung von 4 GB, aber die meisten Fehler sind nicht so exotisch. Um einen Fehler zu finden, müssen Sie manchmal nur das Server-Dashboard überprüfen, einige Minuten im Profiler verbringen oder die Compiler-Warnungen lesen.
In diesem Artikel werde ich drei Hauptfehler behandeln, die ich gefunden und behoben habe. Alle versteckten sich überhaupt nicht und warteten nur darauf, dass jemand sie bemerkte.
Überraschung im Serverprozessor

Vor einigen Jahren habe ich einige Wochen damit verbracht, das Speicherverhalten auf Live-Spieleservern zu untersuchen. Auf den Servern wurde Linux in Remote-Rechenzentren ausgeführt, sodass die meiste Zeit damit verbracht wurde, die erforderlichen Berechtigungen zu erhalten, damit ich zu den Servern tunneln und lernen konnte, wie man effektiv mit perf und anderen Linux-Diagnosetools arbeitet. Ich habe eine Reihe von Fehlern entdeckt, die dazu geführt haben, dass der Speicherverbrauch dreimal höher als erforderlich war, und diese behoben:
- Ich fand eine Nichtübereinstimmung in der Karten-ID, die dazu führte, dass jedes Spiel nicht dieselbe Kopie von ungefähr 20 MB Daten verwendete, sondern eine neue lud.
- Ich habe eine unbenutzte (!) 50-MB-globale Variable (!!) gefunden, für die null Memset (!!!) festgelegt wurde, wodurch bei jedem Prozess physischer RAM belegt wurde.
- Verschiedene weniger schwerwiegende Fehler.
Aber in unserer Geschichte geht es nicht darum.
Nachdem ich mir die Zeit genommen hatte, um zu lernen, wie man unsere Spieleserver profiliert, wurde mir klar, dass ich dies etwas genauer untersuchen konnte. Deshalb habe ich perf auf den Servern eines unserer Spiele ausgeführt. Der erste Serverprozess, den ich profiliert habe, war ... seltsam. Als ich die abgetasteten Prozessordaten „live“ beobachtete, stellte ich fest, dass eine einzelne Funktion 100% der CPU-Zeit beanspruchte. In dieser Funktion wurden jedoch nur vierzehn Anweisungen ausgeführt. Es ergab keinen Sinn.
Zuerst nahm ich an, dass ich perf falsch verwendeteoder Fehlinterpretation der Daten. Ich habe mir einige der anderen Serverprozesse angesehen und festgestellt, dass sich etwa die Hälfte in einem seltsamen Zustand befindet. Die zweite Hälfte hatte ein normaleres CPU-Profil.
Die für uns interessante Funktion ging durch die verknüpfte Liste der Navigationsknoten. Ich fragte meine Kollegen und fand einen Programmierer, der sagte, dass Gleitkommapräzisionsprobleme dazu führen könnten, dass das Spiel Navigationslisten mit Schleifen generiert. Sie wollten immer die maximale Anzahl von Knoten begrenzen, die umgangen werden konnten, kamen aber nie dazu.
Also ist das Rätsel gelöst? Die Instabilität von Gleitkommaberechnungen führt zu Schleifen in den Navigationslisten, wodurch das Spiel sie endlos umgeht - das ist es, das Verhalten wird erklärt.
Aber ... eine solche Erklärung würde bedeuten, dass in diesem Fall der Serverprozess in eine Endlosschleife eintritt, alle Spieler die Verbindung trennen müssen und der Serverprozess den gesamten Prozessorkern endlos verbraucht. Wenn dies der Fall wäre, würden uns dann nicht irgendwann die Ressourcen auf unseren Servern ausgehen? Hätte das niemand bemerkt?
Ich habe nach Serverüberwachungsdaten gesucht und Folgendes gefunden:
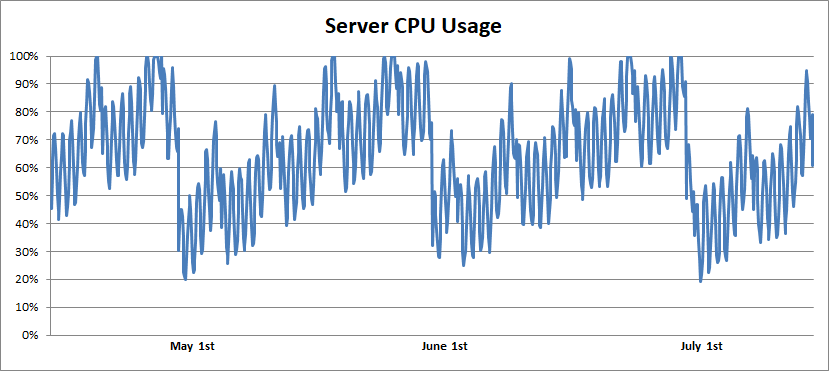
Während der gesamten Dauer der Überwachung (ein bis zwei Jahre) beobachtete ich tägliche und wöchentliche Schwankungen der Serverlast, denen das monatliche Muster auferlegt wurde. Die Prozessorauslastung stieg allmählich an und fiel dann auf Null. Nachdem ich ein bisschen mehr nachgefragt hatte, stellte ich fest, dass die Server einmal im Monat neu gestartet wurden. Und schließlich erschien Logik in all dem:
- , .
- , , .
- CPU , 50%.
- .
Der Fehler wurde durch Hinzufügen einiger Codezeilen behoben, die das Durchlaufen der Liste nach zwanzig Navigationsknoten stoppten und vermutlich mehrere Millionen Dollar an Server- und Stromkosten einsparten. Ich habe diesen Fehler nicht durch Betrachten der Überwachungsdiagramme gefunden, aber jeder, der sie betrachtete, konnte es tun.
Ich liebe die Tatsache, dass die Häufigkeit des Fehlers perfekt mit der Maximierung der Kosten zusammenfiel; Gleichzeitig verursachte er nie genug ernsthafte Probleme, um gefunden zu werden. Dies ähnelt der Wirkung eines Virus, der sich entwickelt, um Menschen zum Niesen zu bringen, nicht um sie zu töten.
Langsames Laden
Die Produktivität von Softwareentwicklern hängt eng mit der Geschwindigkeit des Bearbeitungs- / Kompilierungs- / Link- / Debug-Zyklus zusammen. Mit anderen Worten, es hängt davon ab, wie lange es nach einer Änderung an der Quelldatei dauert, bis die neue Binärdatei mit der vorgenommenen Änderung ausgeführt wird. Ich habe im Laufe der Jahre großartige Arbeit geleistet, um die Kompilierungs- / Linkzeiten zu verkürzen, aber auch Ladezeiten sind wichtig. Einige Spiele leisten bei jedem Start eine Menge Arbeit. Ich bin ungeduldig und daher oft der Erste, der Stunden oder Tage damit verbringt, das Spiel ein paar Sekunden schneller zu laden.
In diesem Fall habe ich meinen Lieblingsprofiler ausgeführt und mir während der anfänglichen Ladephase des Spiels das Diagramm zur CPU-Auslastung angesehen. Ein Schritt sah am vielversprechendsten aus: Es dauerte ungefähr zehn Sekunden, um einige Beleuchtungsdaten zu initialisieren. Ich hatte gehofft, dass ein Weg gefunden werden könnte, um diese Berechnungen zu beschleunigen, indem fünf Sekunden in der Startphase eingespart werden. Bevor ich in die Studie eintauchte, habe ich mich mit einem Grafikspezialisten beraten. Er sagte:
„Wir verwenden diese Beleuchtungsdaten nicht im Spiel. Entferne einfach diese Herausforderung. "
Oh toll. Es war einfach.
Durch eine halbe Stunde Profilerstellung und Ändern einer Zeile konnte ich die Ladezeit des Hauptmenüs halbieren, und es war kein außergewöhnlicher Aufwand erforderlich.
Vorzeitige Abreise
Aufgrund der willkürlichen Anzahl von Argumenten in der Formatierung ist es
printfsehr leicht, einen Typinkongruenzfehler zu erhalten. In der Praxis können die Ergebnisse stark variieren:
- printf ("0x% 08lx", p); // Den Zeiger als int - Kürzung oder schlechter auf 64 Bit drucken
- printf ("% d,% f", f, i); // Das Ändern der Orte von float und int - kann Unsinn anzeigen oder es kann funktionieren (!)
- printf ("% s% d", i, s); // Das Ändern der Reihenfolge von Zeichenfolge und int führt höchstwahrscheinlich zu einem Absturz
Der Standard besagt, dass solche Typinkongruenzen ein undefiniertes Verhalten sind und einige Compiler Code generieren, der absichtlich mit einer dieser Fehlpaarungen abstürzt. In der obigen Liste sind jedoch die wahrscheinlichsten Ergebnisse aufgeführt (Hinweis: Die Frage, warum der zweite Absatz häufig die gewünschten Ergebnisse liefert, ist gut ABI- Wissenspuzzle ).
Solche Fehler sind sehr einfach zu machen, so dass alle modernen Compiler Entwickler warnen können, dass eine Nichtübereinstimmung aufgetreten ist. Sowohl gcc als auch clang verfügen über Funktionsanmerkungen im printf-Stil und können vor Fehlanpassungen warnen (Anmerkungen funktionieren jedoch leider nicht mit Funktionen im wprintf-Stil). VC ++ enthält Anmerkungen (leider andere), mit denen / analyse vor Fehlanpassungen warnen kann. Wenn Sie jedoch / analyse nicht verwenden, wird nur vor CRT-Funktionen im printf / wprintf-Stil gewarnt, nicht vor Ihren benutzerdefinierten Funktionen ...
Die Firma, für die ich gearbeitet habe, hat ihre Funktionen im printf-Stil kommentiert, damit gcc / clang Warnungen ausgibt, aber später beschlossen, die Warnungen zu ignorieren. Dies ist eine seltsame Entscheidung, da solche Warnungen absolut genaue Indikatoren für Fehler sind - das Signal-Rausch-Verhältnis ist unendlich.
Ich habe beschlossen, diese Fehler mit VC ++ zu bereinigen und / oder Anmerkungen zu analysieren, um alle Fehler genau zu finden. Ich habe die meisten Fehler durchgearbeitet und eine große Änderung vorgenommen, bis der Code überprüft wurde, bevor ich ihn abschickte.

An diesem Wochenende gab es einen Stromausfall im Rechenzentrum und alle unsere Server fielen aus (wahrscheinlich aufgrund von Fehlern in der Stromkonfiguration). Das Notfallpersonal beeilte sich, alles wiederherzustellen und zu reparieren, bevor zu viel Geld verloren ging.
Der lustige Aspekt von printf-Fehlern ist, dass sie sich 100% der Zeit schlecht benehmen. Das heißt, wenn sie falsche Daten anzeigen oder das Programm zum Absturz bringen, geschieht dies jedes Mal. Daher können sie nur dann im Programm verbleiben, wenn sie sich in Protokollcode befinden, der nie gelesen wird, oder in Code zur Fehlerbehandlung, der selten ausgeführt wird.
Es stellte sich heraus, dass das Ereignis "gleichzeitiger Neustart aller Server" dazu führte, dass sich der Code auf Pfaden bewegte, die normalerweise nicht ausgeführt wurden. Das Starten von Servern suchte nach anderen Servern, konnte diese nicht finden und zeigte etwa die folgende Meldung an:
fprintf (Protokoll, "Server% s kann nicht gefunden werden. Fehlercode% d. \ n", err, Servername);
Hoppla. Geben Sie Mismatch für eine beliebige Anzahl von Argumenten ein. Und Abfahrt.
Die Einsatzkräfte haben ein zusätzliches Problem. Die Server mussten neu gestartet werden, dies konnte jedoch nicht durchgeführt werden, bevor Absturzabbilder untersucht, ein Fehler entdeckt, die Server-Binärdateien nicht neu erstellt und ein neuer Build veröffentlicht wurden. Es war ein ziemlich schneller Prozess - es scheint, nicht länger als ein paar Stunden, aber es war ziemlich vermeidbar.
Ich dachte, diese Geschichte zeigt perfekt, warum wir Zeit damit verbringen sollten, die Ursachen dieser Warnungen zu beheben - warum sollten wir Warnungen ignorieren, die ihnen sagen, dass der Code bei seiner Ausführung definitiv abstürzt oder sich schlecht verhält? Es störte jedoch niemanden, dass durch das Eliminieren dieser Klasse von Warnungen mehrere Stunden Ausfallzeit eingespart werden könnten. In der Tat schien die Kultur des Unternehmens nicht zu kümmern jede dieser Fehlerbehebung. Aber es war dieser letzte Fehler, der mir klar machte, dass es Zeit war, zu einer anderen Firma zu wechseln.
Welche Lehren können daraus gezogen werden?
Wenn alle Beteiligten hart an Produktfunktionen arbeiten und bekannte Fehler beheben, gibt es wahrscheinlich sehr einfache Fehler, die öffentlich angezeigt werden. Verbringen Sie ein wenig Zeit damit, die Protokolle zu studieren und Compiler-Warnungen zu bereinigen (obwohl es sich wahrscheinlich lohnt, die Entscheidungen, die Sie im Leben getroffen haben, zu überdenken, wenn Sie Compiler-Warnungen haben), und führen Sie den Profiler einige Minuten lang aus. Sie erhalten zusätzliche Punkte, wenn Sie Ihr eigenes Protokollierungssystem hinzufügen, neue Warnungen aktivieren oder einen Profiler verwenden, den nur Sie verwenden.
Wenn Sie hervorragende Korrekturen vornehmen, die die Speicher- / CPU-Nutzung oder -Stabilität verbessern, und sich niemand darum kümmert, finden Sie ein Unternehmen, das dies zu schätzen weiß.
Hacker News Diskussion hier , Reddit Diskussion hier , Twitter Diskussion hier .
Werbung
Ein zuverlässiger Server zur Miete und die richtige Wahl eines Tarifplans lassen Sie weniger von unangenehmen Überwachungsbenachrichtigungen abgelenkt werden - alles funktioniert reibungslos und mit einer sehr hohen Verfügbarkeit!
