Einführung
Ein Speicherverlust wird normalerweise als eine Situation bezeichnet, in der die Menge des belegten Speichers im Heap während des Langzeitbetriebs der Anwendung zunimmt und nach dem Beenden des Garbage Collector nicht abnimmt. Wie Sie wissen, ist der JVM-Speicher in Heap und Stack unterteilt. Der Stapel speichert die Werte von Variablen einfachen Typs und Verweise auf Objekte im Kontext des Streams, und der Heap speichert die Objekte selbst. Außerdem befindet sich im Heap ein Bereich namens Metaspace, in dem Daten zu geladenen Klassen und Daten, die an die Klassen selbst gebunden sind, und nicht deren Instanzen, insbesondere die Werte statischer Variablen, gespeichert werden. Der Garbage Collector (im Folgenden als GC bezeichnet), der regelmäßig von der Java-Maschine gestartet wird, findet Objekte im Heap, auf die nicht mehr verwiesen wird, und gibt den von diesen Objekten belegten Speicher frei. GC-Arbeitsalgorithmen sind unterschiedlich und insbesondere komplex, insbesondereWenn der GC das nächste Mal gestartet wird, "untersucht" er nicht jedes Mal den gesamten Heap, um nicht verwendete Objekte zu finden. Es lohnt sich daher nicht, sich darauf zu verlassen, dass nach einem GC-Start weitere nicht verwendete Objekte aus dem Speicher entfernt werden, aber wenn die von der Anwendung verwendete Speichermenge konstant ist wächst lange ohne ersichtlichen Grund, dann ist es Zeit darüber nachzudenken, was zu einer solchen Situation hätte führen können.
Die JVM enthält ein multifunktionales Dienstprogramm Visual VM (im Folgenden als VM bezeichnet). Mit VM können Sie die Dynamik der Schlüsselindikatoren von jvm in den Diagrammen visuell beobachten, insbesondere die Menge an freiem und belegtem Speicher im Heap, die Anzahl der geladenen Klassen, Threads usw. Darüber hinaus können Sie mithilfe der VM Speicherabbilder erstellen und untersuchen. Natürlich ermöglicht die VM auch Thread-Dumping und Anwendungsprofilerstellung, aber eine Übersicht über diese Funktionen würde den Rahmen dieses Artikels sprengen. In diesem Beispiel benötigen wir von der VM lediglich eine Verbindung zur virtuellen Maschine und sehen uns zunächst das allgemeine Bild der Speichernutzung an. Ich möchte darauf hinweisen, dass zum Verbinden einer VM mit einem Remote-Server die Parameter jmxremote darauf konfiguriert werden müssen, da die Verbindung über jmx erfolgt.Eine Beschreibung dieser Parameter finden Sie in der offiziellen Oracle-Dokumentation oder in zahlreichen Artikeln zu Habré.
Nehmen wir also an, dass wir über die VM erfolgreich eine Verbindung zum Anwendungsserver hergestellt haben, und sehen wir uns die Diagramme an.
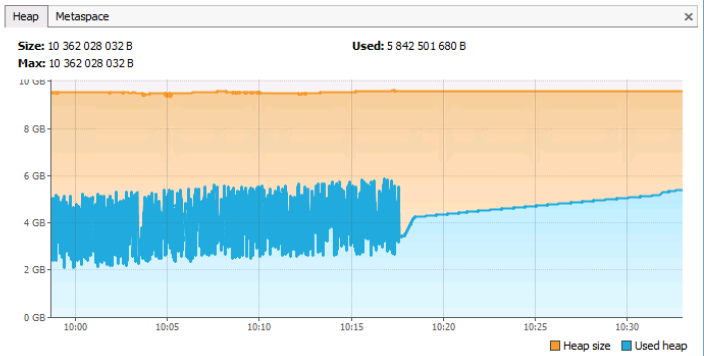
Auf der Registerkarte Heap sehen Sie den gesamten und verwendeten Speicher von jvm. Es sollte beachtet werden, dass diese Registerkarte auch den Speicher des Metaspace-Typs berücksichtigt (na ja, wie sonst, da dies auch ein Heap ist). Auf der Registerkarte Metaspace werden nur Informationen zum Speicher angezeigt, den die Metadaten belegen (von den Klassen selbst und den daran gebundenen Objekten).
In der Grafik sehen wir, dass der gesamte Heap-Speicher ~ 10 GB und der derzeit belegte Speicherplatz ~ 5,8 GB beträgt. Die Grate in der Grafik entsprechen GC-Aufrufen. Eine fast gerade Linie (keine Grate) ab 10:18 kann (aber nicht unbedingt!) Anzeigen, dass der Anwendungsserver ab diesem Zeitpunkt fast außer Betrieb war, da keine aktive Zuordnung und Freigabe erfolgte Erinnerung. Im Allgemeinen entspricht dieses Diagramm dem normalen Betrieb des Anwendungsservers (wenn natürlich nur die Arbeit aus dem Speicher beurteilt werden soll). Das Problemdiagramm wäre eines, bei dem sich eine gerade horizontale blaue Linie ohne Rippen ungefähr um die orange Linie befindet, die die maximale Speichermenge im Heap darstellt.
Schauen wir uns nun ein anderes Diagramm an.
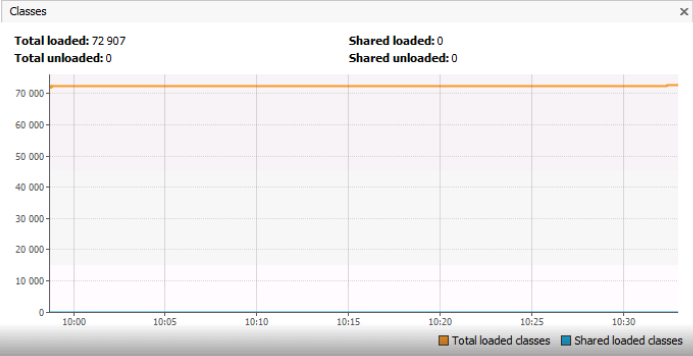
Hier kommen wir direkt zur Analyse des Beispiels, das das Hauptthema dieses Artikels ist. Das Klassendiagramm zeigt die Anzahl der in Metaspace geladenen Klassen und ~ 73.000 Objekte. Ich möchte Ihre Aufmerksamkeit auf die Tatsache lenken, dass es sich nicht um Klasseninstanzen handelt, sondern um die Klassen selbst, dh Objekte vom Typ Klasse <?>. Aus dem Diagramm ist nicht ersichtlich, wie viele Instanzen jedes einzelnen Typs ClassA oder ClassB in den Speicher geladen werden. Vielleicht vervielfacht sich aus irgendeinem Grund die Anzahl identischer Klassen vom Typ ClassA? Ich muss sagen, dass in dem unten beschriebenen Beispiel 73.000 eindeutige Klassen eine absolut normale Situation waren.
Tatsache ist, dass in einem der Projekte, an denen der Autor dieses Artikels teilgenommen hat, ein Mechanismus zur universellen Beschreibung von Domänenentitäten (wie in 1C) entwickelt wurde, der als Wörterbuchsystem bezeichnet wird, und Analysten, die das System für einen bestimmten Kunden oder für einen bestimmten Geschäftsbereich anpassen. hatte die Möglichkeit, über einen speziellen Editor ein Geschäftsmodell zu modellieren, indem neue und vorhandene Entitäten erstellt wurden, die nicht auf Tabellenebene, sondern mit Konzepten wie "Dokument", "Konto", "Mitarbeiter" usw. betrieben wurden. Der Systemkern erstellte Tabellen in einem relationalen DBMS für Entitätsdaten, und es konnten mehrere Tabellen für jede Entität erstellt werden, da das universelle System das historische Speichern von Attributwerten ermöglichte und vieles mehr die Erstellung zusätzlicher Servicetabellen in der Datenbank erforderte.
Ich glaube, dass diejenigen, die mit ORM-Frameworks arbeiten mussten, bereits erraten haben, worum es beim Autor ging, und vom Hauptthema des Artikels abgelenkt wurden, indem sie über Tabellen sprachen. Das Projekt verwendete Hibernate und für jede Tabelle musste eine Entity-Bean-Klasse vorhanden sein. Da neue Tabellen während der Arbeit des Systems von Analysten dynamisch erstellt wurden, wurden gleichzeitig die Hibernate-Bean-Klassen generiert und von den Entwicklern nicht manuell geschrieben. Und mit jeder nächsten Generation wurden ungefähr 50-60.000 neue Klassen geschaffen. Es gab signifikant weniger Tabellen im System (ungefähr 5-6 Tausend), aber für jede Tabelle wurde nicht nur die Entity-Bean-Klasse generiert, sondern auch viel mehr Hilfsklassen, was letztendlich zu einer gemeinsamen Zahl führte.
Der Arbeitsmechanismus war wie folgt. Zu Beginn des Systems wurden Entity-Bean-Klassen und Hilfsklassen (im Folgenden einfach Bean-Klassen) basierend auf Metadaten in der Datenbank generiert. Während das System ausgeführt wurde, erstellte die Hibernate-Sitzungsfactory Sitzungen und Sitzungen Instanzen von Bean-Klassenobjekten. Beim Ändern der Struktur (Hinzufügen, Ändern von Tabellen) wurden die Bean-Klassen neu generiert und eine neue Sitzungsfactory erstellt. Nach der Regeneration erstellte die neue Factory neue Sitzungen, in denen die neuen Bean-Klassen verwendet wurden. Die alte Factory und die Sitzungen wurden geschlossen, und die alten Bean-Klassen wurden vom GC entladen, da sie nicht mehr von den Hibernate-Infrastrukturobjekten referenziert wurden.
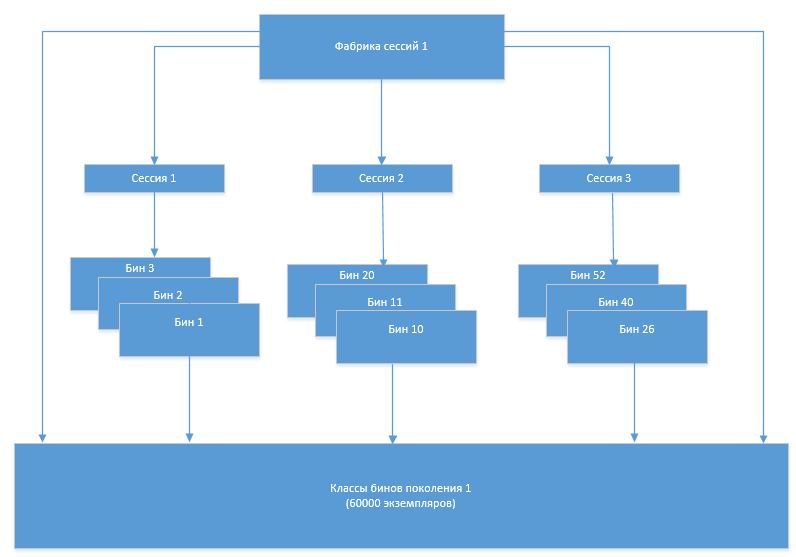
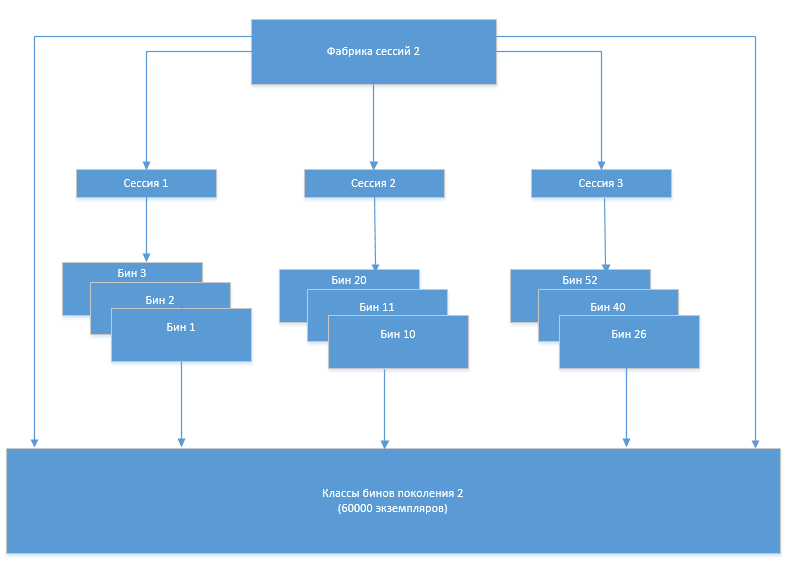
Irgendwann trat das Problem auf, dass die Anzahl der Bin-Klassen nach jeder nächsten Regeneration zuzunehmen begann. Dies lag offensichtlich daran, dass der alte Satz von Klassen, der aus irgendeinem Grund nicht mehr verwendet werden sollte, nicht aus dem Speicher entladen wurde. Um die Gründe für dieses Verhalten des Systems zu verstehen, hat uns der Eclipse Memory Analizer (MAT) geholfen.
Einen Speicherverlust finden
MAT ist in der Lage, mit Speicherauszügen zu arbeiten und potenzielle Probleme darin zu finden. Zuerst müssen Sie diesen Speicherauszug herunterladen, aber in realen Umgebungen gibt es bestimmte Nuancen beim Abrufen eines Speicherauszugs.
Speicherauszug entfernen
Wie oben erwähnt, kann der Speicherauszug direkt von der VM entfernt werden, indem die Schaltfläche "
But" gedrückt wird. Aufgrund der Größe des Speicherauszugs kann die VM diese Aufgabe möglicherweise einfach nicht bewältigen und einige Zeit nach dem Drücken der Schaltfläche "Heap Dump" einfrieren. Darüber hinaus ist es keineswegs möglich, über jmx eine Verbindung zum für die VM erforderlichen Produktanwendungsserver herzustellen. In diesem Fall hilft uns ein anderes JVM-Dienstprogramm namens jMap. Es wird in der Befehlszeile direkt auf dem Server ausgeführt, auf dem jvm ausgeführt wird, und ermöglicht das
Festlegen zusätzlicher Speicherauszugsparameter : jmap -dump: live, format = b, file = / tmp / heapdump.bin 14616
Der Parameter –dump : live ist äußerst wichtig, da Mit dieser Option können Sie die Größe erheblich reduzieren und Objekte ausschließen, auf die nicht mehr verwiesen wird.
Eine andere häufige Situation ist, wenn manuelles Dumping nicht möglich ist, da jvm selbst mit einem OutOfMemoryError abstürzt. In dieser Situation wird die Option -XX: + HeapDumpOnOutOfMemoryError zur Rettung und zusätzlich -XX: HeapDumpPath verwendet , mit der Sie den Pfad zum erfassten Speicherauszug angeben können.
Öffnen Sie als Nächstes den erfassten Speicherauszug mit dem Eclipse Memory Analizer. Die Datei kann groß sein (mehrere Gigabyte), daher müssen Sie in der Datei
MemoryAnalyzer.ini genügend Speicher bereitstellen: -Xmx4096m
Lokalisieren des Problems mit MAT
Betrachten wir also eine Situation, in der sich die Anzahl der geladenen Klassen im Vergleich zur ursprünglichen Ebene vervielfacht und auch nach einem erzwungenen Aufruf der Speicherbereinigung nicht abnimmt (dies kann durch Drücken der entsprechenden Schaltfläche in der VM erfolgen).
Oben wurde der Prozess der Regeneration der Bohnenklassen und ihre Verwendung konzeptionell beschrieben. Auf technischer Ebene sah es so aus:
- Alle Hibernate-Sitzungen sind geschlossen (SessionImpl-Klasse)
- Die alte Session Factory (SessionFactoryImpl) wird geschlossen und der Verweis darauf aus der LocalSessionFactoryBean zurückgesetzt
- ClassLoader wird neu erstellt
- Verweise auf alte Bean-Klassen in der Generator-Klasse werden ungültig
- Bean-Klassen werden regeneriert
Wenn keine Verweise auf alte Bean-Klassen vorhanden sind, sollte sich die Anzahl der Klassen nach der Speicherbereinigung nicht erhöhen.
Führen Sie MAT aus und öffnen Sie die zuvor erhaltene Speicherauszugsdatei. Nach dem Öffnen des Speicherauszugs zeigt MAT die größten Objektketten im Speicher an.
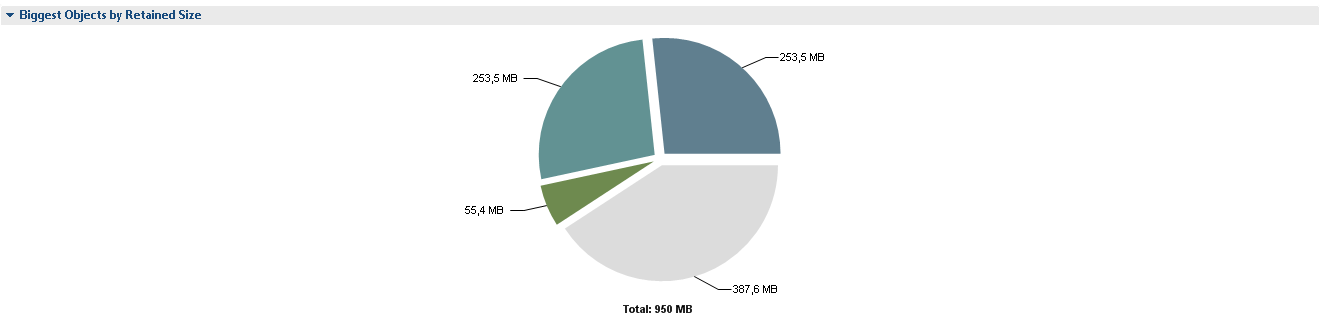
Nachdem Sie auf Leak Suspects geklickt haben, sehen wir die Details:
2 Kreissegmente mit jeweils 265 M sind 2 Instanzen von SessionFactoryImpl. Es ist nicht klar, warum es zwei Instanzen von ihnen gibt, und höchstwahrscheinlich enthält jede der Instanzen Verweise auf den vollständigen Satz von Entity-Bean-Klassen. MAT informiert uns wie folgt über mögliche Probleme.

Ich stelle sofort fest, dass Problemverdächtiger 3 kein wirkliches Problem ist. Das Projekt hat einen Parser seiner eigenen Sprache implementiert, der ein Multiplattform-Add-On über SQL ist und es Ihnen ermöglicht, nicht mit Tabellen, sondern mit Systementitäten zu arbeiten, und 121M belegt seinen Abfragecache.
Kehren wir zu zwei Instanzen von SessionFactoryImpl zurück. Klicken Sie auf Klassen duplizieren, und stellen Sie sicher, dass jede Entity-Bean-Klasse tatsächlich zwei Instanzen enthält. Das heißt, die Links zu den alten Klassen der Entity-Beans bleiben erhalten, und dies sind höchstwahrscheinlich Links von der SesssionFactoryImpl. Basierend auf dem Quellcode dieser Klasse sollten Verweise auf Bean-Klassen im Feld classMetaData gespeichert werden.
Klicken Sie auf Problemverdächtiger 1, dann auf die SessionFactoryImpl-Klasse und wählen Sie im Kontextmenü Liste Objekte-> Mit auslaufenden Referenzen. Auf diese Weise können wir alle Objekte sehen, auf die SessionFactoryImpl verweist.
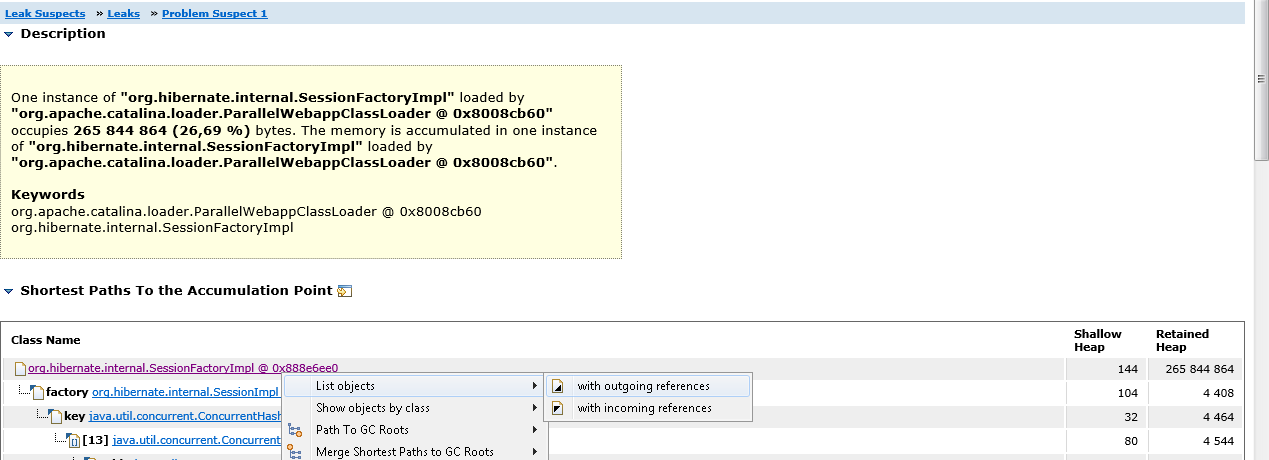
Erweitern Sie das classMetaData-Objekt und stellen Sie sicher, dass tatsächlich ein Array von Entity-Bean-Klassen gespeichert ist.
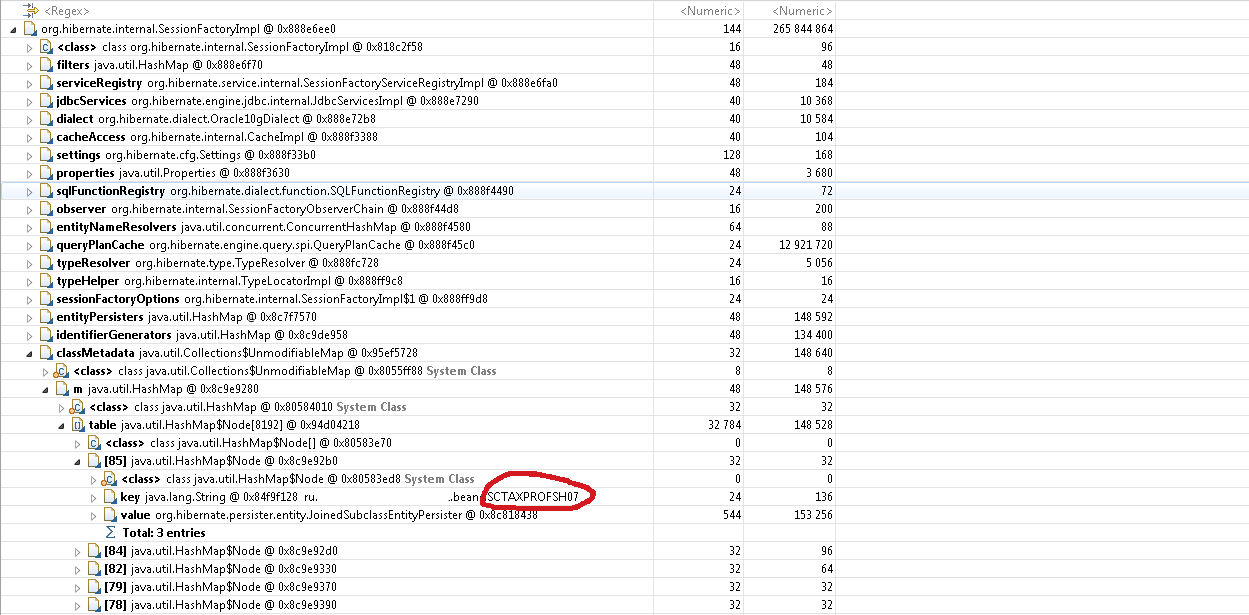
Jetzt müssen wir verstehen, was den Garbage Collector daran hindert, eine einzelne Instanz von SessionFactoryImpl zu entsorgen. Wenn wir zu Leak Suspects-> Leaks-> Problem Suspect 1 zurückkehren, sehen wir einen Stapel von Links, der zu einem Link zu SessionFactoryImpl führt.
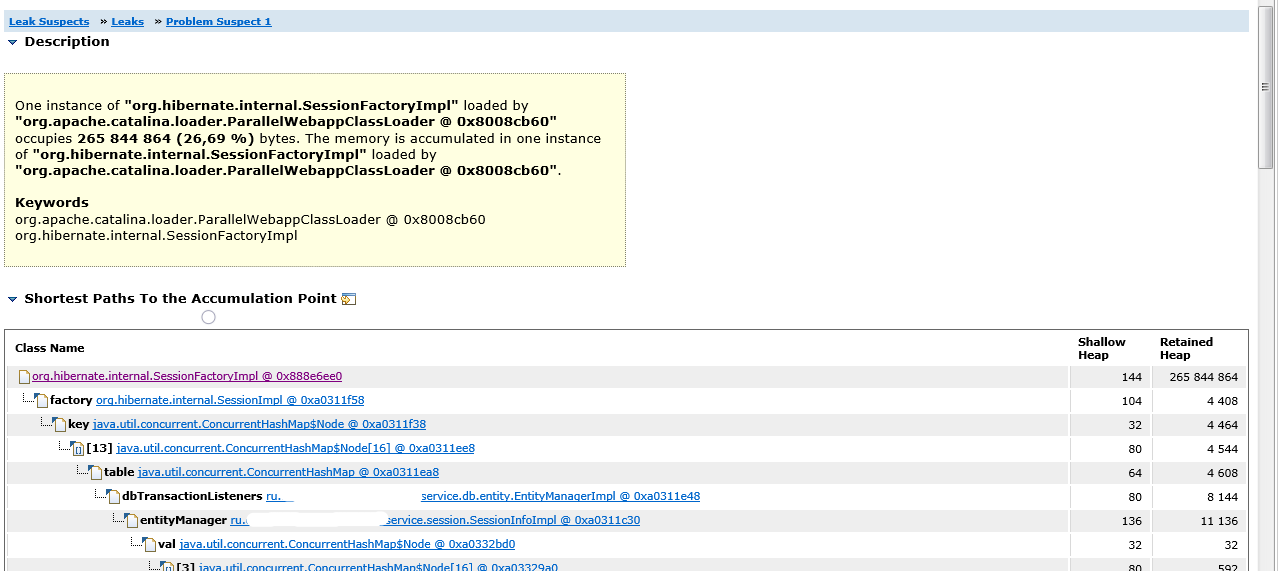
Wir sehen, dass die entityManager-Variable der SessionInfoImpl-Bean, die den Kontext der HTTP-Sitzung enthält, ein Array dbTransactionListeners hat, das Hibernate SessionImpl-Objekte als Schlüssel verwendet, und Sitzungen auf SessionFactoryImpl verweisen.
Tatsache ist, dass Sitzungsobjekte für bestimmte Zwecke in dbTransactionListeners zwischengespeichert wurden. Bevor die Bean-Klassen neu generiert wurden, konnten Verweise auf sie in diesem Array verbleiben. Sitzungen wiederum verwiesen auf die Sitzungsfactory, in der eine Reihe von Verweisen auf alle Bean-Klassen gespeichert waren. Darüber hinaus behielten Sitzungen Verweise auf Instanzen von Entitätsklassen bei und verwiesen auf die Bean-Klassen selbst.
Somit wurde der Einstiegspunkt in das Problem gefunden. Es stellte sich heraus, dass es sich um Verweise auf alte Sitzungen von dbTransactionListeners handelte. Nachdem der Fehler behoben und das Array dbTransactionListeners gelöscht wurde, wurde das Problem behoben.
Funktionen des Eclipse Memory Analizer
Mit Eclipse Memory Analyzer können Sie also:
- Finden Sie heraus, welche Objektketten die maximale Speicherkapazität belegen, und bestimmen Sie die Einstiegspunkte in diese Ketten (Leak Suspects).
- Zeigen Sie einen Baum aller eingehenden Objektreferenzen an (kürzeste Pfade zum Akkumulationspunkt)
- Zeigen Sie einen Baum aller auslaufenden Referenzen eines Objekts an (Objekt-> Objekte auflisten-> Mit auslaufenden Referenzen).
- Siehe doppelte Klassen, die von verschiedenen ClassLoadern geladen wurden (doppelte Klassen)