Dieser Artikel ist eine Übersetzung eines der Beiträge von neptune.ai und hebt die interessantesten Deep-Learning-Tools hervor, die auf der ICLR 2020- Konferenz für maschinelles Lernen vorgestellt wurden .

Wo wird fortgeschrittenes tiefes Lernen geschaffen und diskutiert?
Einer der Hauptdiskussionsorte für Deep Learning ist ICLR - die führende Konferenz zum Thema Deep Learning, die vom 27. bis 30. April 2020 stattfand. Mit über 5.500 Teilnehmern und fast 700 Präsentationen und Vorträgen ist dies ein großer Erfolg für eine vollständig online stattfindende Veranstaltung. Umfassende Informationen zur Konferenz finden Sie hier , hier oder hier .
Virtuelle soziale Treffen waren einer der Höhepunkte des ICLR 2020. Die Organisatoren beschlossen, ein Projekt mit dem Titel „Open Source-Tools und -Praktiken in der DL-Forschung auf dem neuesten Stand der Technik“ zu starten. Das Thema wurde aufgrund der Tatsache ausgewählt, dass das entsprechende Toolkit ein unvermeidlicher Bestandteil der Arbeit eines Deep-Learning-Forschers ist. Fortschritte in diesem Bereich haben zur Verbreitung großer Ökosysteme geführt (TensorFlow , PyTorch , MXNet) sowie kleinere zielgerichtete Tools, die auf die spezifischen Bedürfnisse von Forschern zugeschnitten sind.
Ziel der genannten Veranstaltung war es, sich mit den Entwicklern und Anwendern von Open Source-Tools zu treffen und Erfahrungen und Eindrücke in der Deep Learning-Community auszutauschen. Insgesamt wurden mehr als 100 Personen zusammengebracht, darunter die Hauptinspiratoren und Projektleiter, denen wir kurze Zeit gaben, um ihre Arbeit vorzustellen. Teilnehmer und Organisatoren waren überrascht von der Vielfalt und Kreativität der vorgestellten Tools und Bibliotheken.
Dieser Artikel enthält helle Projekte, die von einer virtuellen Bühne aus präsentiert werden.
Werkzeuge und Bibliotheken
Im Folgenden sind acht Tools aufgeführt, die am ICLR mit einem detaillierten Überblick über die Funktionen demonstriert wurden.
Jeder Abschnitt enthält sehr prägnante Antworten auf eine Reihe von Punkten:
- Welches Problem löst das Tool / die Bibliothek?
- Wie kann ich einen minimalen Anwendungsfall ausführen oder erstellen?
- Externe Ressourcen für einen tieferen Einblick in die Bibliothek / das Tool.
- Profil der Projektvertreter für den Fall, dass der Wunsch besteht, sie zu kontaktieren.
Sie können zu einem bestimmten Abschnitt unten springen oder alle nacheinander durchsuchen. Viel Spaß beim Lesen!
AmpliGraph
Thema: Wissensgraph-basierte Einbettungsmodelle.
Programmiersprache: Python
Von: Luca Costabello
Twitter | LinkedIn | GitHub | Website-
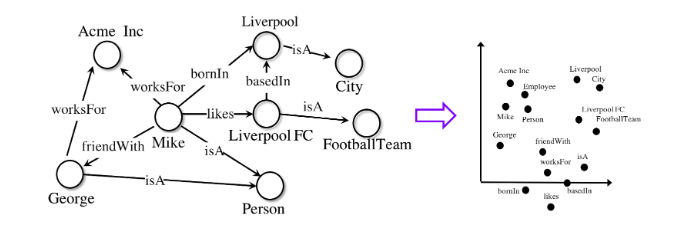
Wissensdiagramme sind ein vielseitiges Werkzeug zur Darstellung komplexer Systeme. Unabhängig davon, ob es sich um ein soziales Netzwerk, einen Bioinformatik-Datensatz oder Einzelhandelskaufdaten handelt, können Unternehmen mithilfe der grafischen Wissensmodellierung wichtige Verbindungen identifizieren, die sonst übersehen würden.
Um die Beziehungen zwischen Daten aufzudecken, sind spezielle Modelle für maschinelles Lernen erforderlich, die speziell für die Arbeit mit Diagrammen entwickelt wurden.
AmpliGraphIst eine Reihe von unter Apache2 lizenzierten Modellen für maschinelles Lernen zum Extrahieren von Einbettungen aus Wissensgraphen. Solche Modelle codieren die Knoten und Kanten des Graphen in einer Vektorform und kombinieren sie, um fehlende Fakten vorherzusagen. Diagrammeinbettungen werden in Aufgaben wie dem oberen Rand des Wissensdiagramms, der Wissenserkennung, dem linkbasierten Clustering und anderen verwendet.
AmpliGraph senkt die Eintrittsbarriere für das Thema der Einbettung von Graphen für Forscher, indem diese Modelle unerfahrenen Benutzern zur Verfügung gestellt werden. Das Projekt nutzt die Open-Source-API und unterstützt eine Community von Enthusiasten, die Grafiken beim maschinellen Lernen verwenden. In diesem Projekt lernen Sie, wie Sie Einbettungen aus Wissensgraphen auf der Grundlage realer Daten erstellen und visualisieren und diese für nachfolgende maschinelle Lernaufgaben verwenden.
Im Folgenden finden Sie zunächst einen minimalen Code, der ein Modell in einem der Referenzdatensätze trainiert und fehlende Links vorhersagt:


AmpliGraph wurde ursprünglich bei Accenture Labs Dublin entwickelt und wird dort in verschiedenen Industrieprojekten eingesetzt.
Automunge
Tabellarische Datenaufbereitungsplattform
Programmiersprache: Python
Gepostet von Nicholas Teague
Twitter | LinkedIn | GitHub | Automunge- Website
Ist eine Python-Bibliothek zur Vorbereitung von Tabellendaten für das maschinelle Lernen. Durch das Toolkit des Pakets sind einfache Transformationen für das Engeenering von Features möglich, um die Lücken zu normalisieren, zu codieren und zu füllen. Die Transformationen werden auf die Trainingsunterprobe angewendet und dann auf ähnliche Weise wie die Daten aus der Testunterprobe angewendet. Konvertierungen können automatisch durchgeführt, aus einer internen Bibliothek zugewiesen oder vom Benutzer flexibel konfiguriert werden. Zu den Populationsoptionen gehört die auf maschinellem Lernen basierende Füllung, bei der Modelle trainiert werden, um fehlende Informationen für jede Datenspalte vorherzusagen.
Einfach ausgedrückt:
automunge (.) Bereitet Tabellendaten für das maschinelle Lernen vor,
postmunge (.)zusätzliche Daten werden nacheinander und mit hoher Effizienz verarbeitet.
Automunge kann über pip installiert werden:

Importieren Sie nach der Installation einfach die Bibliothek zur Initialisierung in Jupyter Notebook:

Um Daten aus dem Trainingsbeispiel automatisch mit Standardparametern zu verarbeiten, reicht es aus, den folgenden Befehl zu verwenden:

Für die nachfolgende Verarbeitung von Daten aus dem Test-Teilbeispiel reicht es außerdem aus, einen Befehl unter Verwendung des Wörterbuchs postprocess_dict auszuführen, das durch Aufrufen von automunge (.) Erhalten wird.

Die Parameter assigncat und assigninfill im Aufruf automunge (.) Können verwendet werden, um Konvertierungsdetails und Datentypen zu definieren, um die Lücken zu füllen. Beispielsweise kann einem Datensatz mit den Spalten 'column1' und 'column2' eine Skalierung basierend auf Minimal- und Maximalwerten ('mnmx') mit ML-Padding für Spalte1 und One-Hot-Codierung ('text') mit Padding basierend auf zugewiesen werden der häufigste Wert für Spalte2. Daten aus anderen Spalten, die nicht explizit angegeben wurden, werden automatisch verarbeitet.

Ressourcen und Links
Website | GitHub | Kurze Präsentation
DynaML
Maschinelles Lernen für Scala
Programmiersprache: Scala
Gepostet von: Mandar Chandorkar
Twitter | LinkedIn | GitHub
DynaML ist eine Scala-basierte Toolbox für Forschung und maschinelles Lernen. Ziel ist es, dem Benutzer eine End-to-End-Umgebung bereitzustellen, die Folgendes unterstützen kann:
- Entwicklung / Prototyping von Modellen,
- Arbeiten mit sperrigen und komplexen Rohrleitungen,
- Visualisierung von Daten und Ergebnissen,
- Wiederverwendung von Code in Form von Skripten und Notizbüchern.
DynaML nutzt die Stärken der Scala-Sprache und des Ökosystems, um eine Umgebung zu schaffen, die Leistung und Flexibilität bietet. Es basiert auf exzellenten Projekten wie Ammonite Scala, Tensorflow-Scala und der Breeze High Performance Numerical Computation Library .
Die Schlüsselkomponente von DynaML ist die REPL / Shell mit Syntaxhervorhebung und einem fortschrittlichen Autocomplete-System.
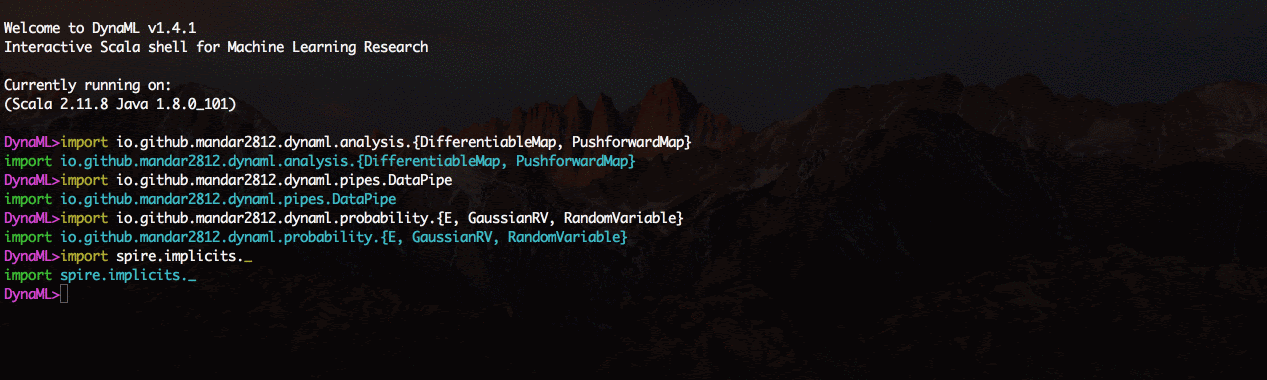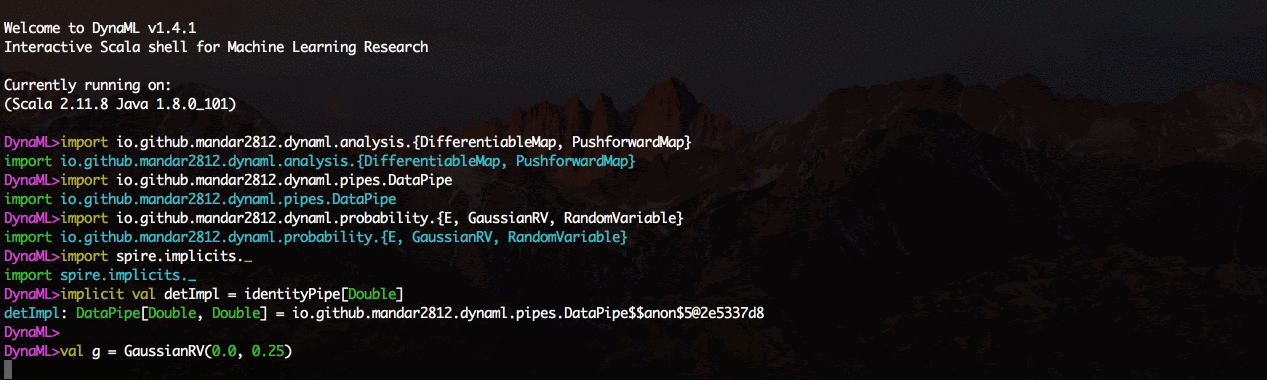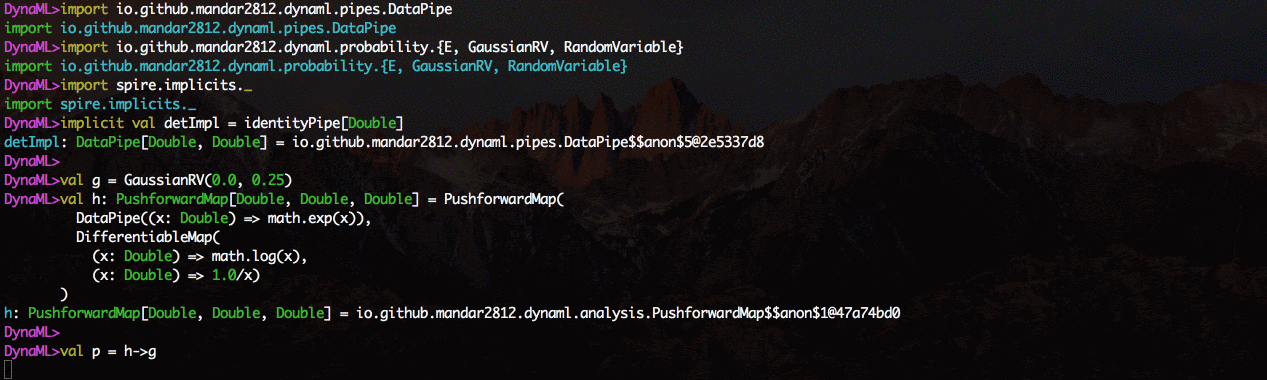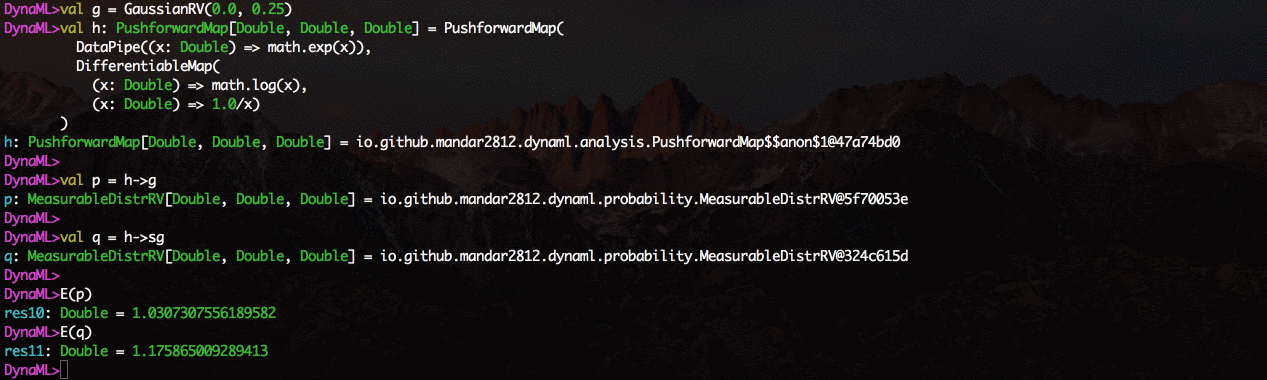
Die Umgebung bietet Unterstützung für 2D- und 3D-Visualisierung. Die Ergebnisse können direkt über die Befehlsshell angezeigt werden.

Mit dem Datenleitungsmodul können Sie auf einfache Weise Datenverarbeitungs-Pipelines auf layoutfreundliche, modulare Weise erstellen. Erstellen Sie Funktionen, schließen Sie sie mit dem DataPipe-Konstruktor ein und erstellen Sie Funktionsblöcke mit dem Operator>.
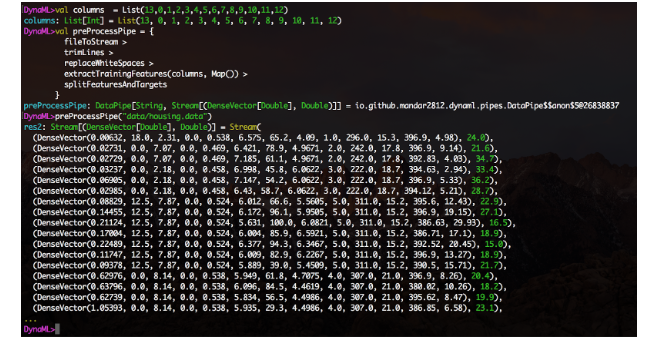
Eine experimentelle Integrationsfunktion für Jupyter-Notebooks ist ebenfalls verfügbar. Das Notebooks-Verzeichnis im Repository enthält mehrere Beispiele für die Verwendung des DynaML-Scala Jupyter-Kerns.

Das Benutzerhandbuch enthält umfangreiche Referenzen und Dokumentationen, mit denen Sie die DynaML-Umgebung besser beherrschen und optimal nutzen können.
Im Folgenden finden Sie einige interessante Anwendungen, die die Stärken von DynaML hervorheben:
- Die Physik inspirierte neuronale Netze zur Lösung der Burger-Gleichung und des Fokker-Planck-Systems .
- Deep Learning Training,
- Gaußsche Prozessmodelle für die autoregressive Zeitreihenprognose.
GitHub Ressourcen und Links | Handbuch
Hydra
Konfigurations- und Parametermanager
Programmiersprache: Python
Gepostet von Omry Yadan
Twitter | GitHub
Hydra wurde von Facebook AI entwickelt und ist eine Python-Plattform, die die Entwicklung von Forschungsanwendungen vereinfacht, indem sie die Möglichkeit bietet, Konfigurationen mithilfe von Konfigurationsdateien und der Befehlszeile zu erstellen und zu überschreiben. Die Plattform bietet außerdem Unterstützung für die automatische Parametererweiterung, die Remote- und Parallelausführung über Plug-Ins, die automatische Verwaltung von Arbeitsverzeichnissen und das dynamische Vorschlagen von Abschlussoptionen durch Drücken der TAB-Taste.
Durch die Verwendung von Hydra wird Ihr Code auch in verschiedenen maschinellen Lernumgebungen portabler. Ermöglicht den Wechsel zwischen persönlichen Arbeitsstationen, öffentlichen und privaten Clustern, ohne den Code zu ändern. Das Obige wird durch eine modulare Architektur erreicht.
Grundlegendes Beispiel In
diesem Beispiel wird eine Datenbankkonfiguration verwendet. Sie können sie jedoch problemlos durch Modelle, Datasets oder andere Elemente ersetzen.
config.yaml:

my_app.py:

Sie können alles in der Konfiguration über die Befehlszeile überschreiben:

Kompositionsbeispiel:
Möglicherweise möchten Sie zwischen zwei verschiedenen Datenbankkonfigurationen wechseln.
Erstellen Sie diese Verzeichnisstruktur:

config.yaml:
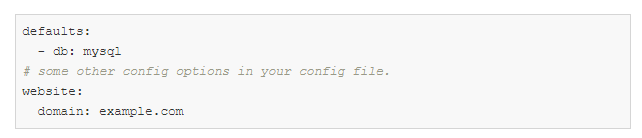
Defaults ist eine spezielle Anweisung, die Hydra anweist, beim Erstellen eines Konfigurationsobjekts db / mysql.yaml zu verwenden.
Jetzt können Sie auswählen, welche Datenbankkonfiguration verwendet werden soll, und Parameterwerte über die Befehlszeile überschreiben:

Weitere Informationen finden Sie im Tutorial .
Darüber hinaus stehen in Kürze neue interessante Funktionen zur Verfügung:
- stark typisierte Konfigurationen (strukturierte Konfigurationsdateien),
- Optimierung von Hyperparametern mit Ax- und Nevergrad-Plugins,
- Starten von AWS mit dem Ray Launcher-Plugin,
- lokaler paralleler Start über das Joblib-Plugin und vieles mehr.
Larq
Binarisierte Neuronale Netze
Programmiersprache: Python Gepostet
von: Lucas Geiger
Twitter | LinkedIn | GitHub
Larq ist ein Open-Source-Python-Paket-Ökosystem zum Erstellen, Trainieren und Bereitstellen von binärisierten neuronalen Netzen (BNNs). BNNs sind Deep-Learning-Modelle, bei denen Aktivierungen und Gewichte nicht mit 32, 16 oder 8 Bit, sondern nur mit 1 Bit codiert werden. Dies kann die Inferenzzeit erheblich verkürzen und den Stromverbrauch senken, wodurch BNN ideal für mobile und periphere Anwendungen ist.
Das Open-Source-Larq-Ökosystem besteht aus drei Hauptkomponenten.
- Larq — , . API, TensorFlow Keras. . Larq BNNs, .
- Larq Zoo BNNs, . Larq Zoo , BNN .
- Larq Compute Engine — BNNs. TensorFlow Lite MLIR Larq FlatBuffer, TF Lite. ARM64, , Android Raspberry Pi, , , BNN.
Die Autoren des Projekts erstellen ständig schnellere Modelle und erweitern das Larq-Ökosystem auf neue Hardwareplattformen und Deep-Learning-Anwendungen. Derzeit wird beispielsweise daran gearbeitet, die 8-Bit-Quantisierung Ende-zu-Ende zu integrieren, um Kombinationen von Binär- und 8-Bit-Netzwerken mit Larq trainieren und bereitstellen zu können.
Ressourcen und Links
Website | GitHub larq / larq | GitHub larq / zoo | GitHub larq / compute-engine | Lehrbücher | Blog | Twitter
McKernel
Nukleare Methoden in logarithmisch linearer Zeit
Programmiersprache: C / C ++
Gepostet von J. de Curtó i Díaz
Twitter | Website
Die erste Open-Source-C ++ - Bibliothek, die sowohl eine zufällige Annäherung an Kernelmethoden als auch ein vollwertiges Deep-Learning-Framework bietet.
McKernel bietet vier verschiedene Anwendungen.
- In sich geschlossener blitzschneller Open-Source-Hadamard-Code. Zur Verwendung in Bereichen wie Komprimierung, Verschlüsselung oder Quantencomputer.
- Extrem schnelle Kerntechniken. Kann überall dort verwendet werden, wo SVM-Methoden (Support Vector Method: ru.wikipedia.org/wiki/%D0%9C%D0%B5%D1%82%D0%BE%D0%B4_%D0%BE%D0%BF%D0) % BE% D1% 80% D0% BD% D1% 8B% D1% 85_% D0% B2% D0% B5% D0% BA% D1% 82% D0% BE% D1% 80% D0% BE% D0% B2 ) sind Deep Learning überlegen. Einige Robotikanwendungen und einige Anwendungsfälle für maschinelles Lernen im Gesundheitswesen und in anderen Bereichen umfassen beispielsweise Federated Learning und Kanalauswahl.
- Die Integration von Deep-Learning-Methoden und Nuklearmethoden ermöglicht die Entwicklung einer Deep-Learning-Architektur in einer a priori anthropomorphen / mathematischen Richtung.
- Deep Learning-Forschungsrahmen zur Lösung einer Reihe offener Fragen im maschinellen Lernen.
Die Gleichung, die alle Berechnungen beschreibt, sieht folgendermaßen aus:

Hier erklärten die Autoren als Pionierformalismus mit zufälligen Symptomen als Methoden Deep Learning und Kerntechniken . Die theoretische Grundlage basiert auf vier Giganten: Gauß, Wiener, Fourier und Kalman. Den Grundstein dafür legten Rahimi und Rekht (NIPS 2007) sowie Le et al. (ICML 2013).
Den typischen Benutzer ansprechen
Das Hauptpublikum von McKernel sind Forscher und Praktiker in den Bereichen Robotik, maschinelles Lernen für das Gesundheitswesen, Signalverarbeitung und Kommunikation, die eine effiziente und schnelle Implementierung in C ++ benötigen. In diesem Fall erfüllen die meisten Deep Learning-Bibliotheken die angegebenen Bedingungen nicht, da sie hauptsächlich auf Python-Implementierungen auf hoher Ebene basieren. Darüber hinaus kann das Publikum Vertreter der breiteren Community für maschinelles Lernen und Deep Learning sein, die auf der Suche nach einer Verbesserung der Architektur neuronaler Netze mithilfe nuklearer Methoden sind.
Ein supereinfaches visuelles Beispiel für das Ausführen einer Bibliothek ohne Zeitaufwand sieht folgendermaßen aus:

Was weiter?
End-to-End-Lernen, selbstüberwachtes Lernen, Meta-Lernen, Integration in evolutionäre Strategien, deutliche Reduzierung des Suchraums mit NAS, ...
Ressourcen und Links
GitHub | Vollständige Präsentation
SCCH Training Engine
Automatisierungsroutinen für Deep Learning
Programmiersprache: Python
Gepostet von: Natalya Shepeleva
Twitter | LinkedIn | Website Die
Entwicklung einer typischen Pipeline für Deep Learning ist Standard: Datenvorverarbeitung, Aufgabendesign / -implementierung, Modelltraining und Ergebnisbewertung. Dennoch erfordert seine Verwendung von Projekt zu Projekt die Beteiligung eines Ingenieurs in jeder Entwicklungsphase, was zur Wiederholung derselben Aktionen, zur Vervielfältigung von Code und letztendlich zu Fehlern führt.
Ziel der SCCH Training Engine ist es, den Deep Learning-Entwicklungsprozess für die beiden beliebtesten Frameworks PyTorch und TensorFlow zu vereinheitlichen und zu automatisieren. Die Single-Entry-Architektur minimiert die Entwicklungszeit und schützt vor Fehlern.
Für wen?
Die flexible Architektur der SCCH Training Engine bietet zwei Ebenen der Benutzererfahrung.
Main. Auf dieser Ebene muss der Benutzer Daten für das Training bereitstellen und die Trainingsparameter des Modells in die Konfigurationsdatei schreiben. Danach werden alle Prozesse, einschließlich Datenverarbeitung, Modelltraining und Validierung der Ergebnisse, automatisch durchgeführt. Als Ergebnis wird ein trainiertes Modell innerhalb eines der Hauptrahmen erhalten.
Fortgeschrittene.Dank des modularen Komponentenkonzepts kann der Benutzer die Module entsprechend seinen Anforderungen modifizieren, eigene Modelle bereitstellen und verschiedene Verlustfunktionen und Qualitätsmetriken verwenden. Diese modulare Architektur ermöglicht es Ihnen, zusätzliche Funktionen hinzuzufügen, ohne den Betrieb der Hauptpipeline zu beeinträchtigen.
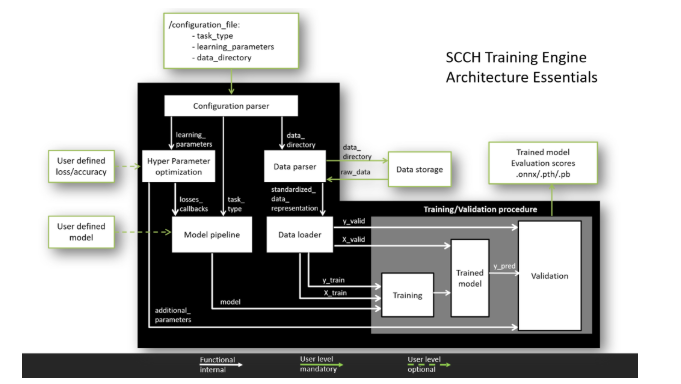
Was kann er tun?
Aktuelle Funktionen:
- Arbeit mit TensorFlow und PyTorch,
- eine standardisierte Pipeline zum Parsen von Daten aus verschiedenen Formaten,
- eine standardisierte Pipeline für das Modelltraining und die Validierung von Ergebnissen,
- Unterstützung für Klassifizierungs-, Segmentierungs- und Erkennungsaufgaben,
- Kreuzvalidierungsunterstützung.
Features in Entwicklung:
- Suche nach optimalen Modellhyperparametern,
- Laden von Modellgewichten und Training von einem bestimmten Kontrollpunkt aus,
- Unterstützung der GAN-Architektur.
Wie es funktioniert?
Um die SCCH Training Engine in ihrer ganzen Pracht zu sehen, müssen Sie zwei Schritte ausführen.
- Kopieren Sie einfach das Repository und installieren Sie die erforderlichen Pakete mit dem folgenden Befehl: pip install require.txt.
- Führen Sie python main.py aus , um eine MNIST-Fallstudie mit Verarbeitung und Schulung für ein LeNet-5-Modell anzuzeigen.
Alle Informationen zum Erstellen einer Konfigurationsdatei und zur Verwendung erweiterter Funktionen finden Sie auf der GitHub- Seite .
Stabile Version mit Kernfunktionen: geplant für Ende Mai 2020.
Ressourcen und Links
GitHub | Webseite
Tokenizer
Text Tokenizer
Programmiersprache: Rust with Python API
Gepostet von: Anthony Mua
Twitter | LinkedIn | GitHub
huggingface / tokenizers bietet Zugriff auf die modernsten Tokenizer mit Schwerpunkt auf Leistung und Mehrzwecknutzung. Mit Tokenizers können Sie Tokenizer mühelos trainieren und verwenden. Tokenizer können Ihnen helfen, unabhängig davon, ob Sie ein Gelehrter oder ein Praktiker im NLP-Bereich sind.
Hauptmerkmale
- Extreme Geschwindigkeit: Tokenisierung sollte kein Engpass in Ihrer Pipeline sein, und Sie müssen Ihre Daten nicht vorverarbeiten. Dank der nativen Rust-Implementierung dauert die Tokenisierung von Gigabyte Text nur wenige Sekunden.
- Offsets / Alignment: Bietet Offset-Kontrolle auch bei der Verarbeitung von Text mit komplexen Normalisierungsverfahren. Dies erleichtert das Extrahieren von Text für Aufgaben wie NER oder das Beantworten von Fragen.
- Vorverarbeitung: Erledigt alle erforderlichen Vorverarbeitungen, bevor Daten in Ihr Sprachmodell eingegeben werden (Abschneiden, Auffüllen, Hinzufügen spezieller Token usw.).
- Einfaches Lernen: Trainieren Sie einen beliebigen Tokenizer auf einem neuen Gehäuse. Das Erlernen eines Tokenizers für BERT in einer neuen Sprache war beispielsweise nie einfacher.
- Mehrsprachig: Ein Paket mit mehreren Sprachen. Sie können es jetzt mit Python, Node.js oder Rust verwenden. Die Arbeit in diese Richtung geht weiter!
Beispiel:

Und so weiter:
- Serialisierung in eine einzelne Datei und Laden in einer Zeile für einen beliebigen Tokenizer,
- Unigramm-Unterstützung.
Hugging Face sieht ihre Mission darin, NLP zu fördern und zu demokratisieren. GitHub
Ressourcen und Links
huggingface / transformers | GitHub huggingface / tokenizers | Twitter
Fazit
Zusammenfassend sollte angemerkt werden, dass es eine große Anzahl von Bibliotheken gibt, die für Deep Learning und maschinelles Lernen im Allgemeinen nützlich sind, und es gibt keine Möglichkeit, alle in einem Artikel zu beschreiben. Einige der oben beschriebenen Projekte werden in bestimmten Fällen nützlich sein, andere sind bereits bekannt, und einige wunderbare Projekte haben es leider nicht in den Artikel geschafft.
Wir bei CleverDATA sind bestrebt, uns über neue Tools und nützliche Bibliotheken auf dem Laufenden zu halten und in unserer Arbeit im Zusammenhang mit dem Einsatz von Deep Learning und Machine Learning aktiv neue Ansätze anzuwenden. Ich für meinen Teil möchte die Leser auf diese beiden Bibliotheken aufmerksam machen, die nicht im Hauptartikel enthalten sind, aber bei der Arbeit mit neuronalen Netzen erheblich helfen: Catalyst (https://catalyst-team.com ) und Albumentation ( https://albumentations.ai/ ).
Ich bin sicher, dass jeder praktizierende Spezialist seine eigenen Lieblingswerkzeuge und -bibliotheken hat, einschließlich derer, die einem breiten Publikum wenig bekannt sind. Wenn es Ihnen so vorkommt, als ob nützliche Werkzeuge in Ihrer Arbeit vergeblich ignoriert wurden, schreiben Sie sie bitte in die Kommentare: Selbst wenn Sie sie in der Diskussion erwähnen, können vielversprechende Projekte dazu beitragen, neue Follower zu gewinnen, und die zunehmende Beliebtheit führt wiederum zu einer Verbesserung der Funktionalität und der Entwicklung ihrer eigenen Bibliotheken.
Vielen Dank für Ihre Aufmerksamkeit und ich hoffe, dass die vorgestellten Bibliotheken für Ihre Arbeit nützlich sind!