Die beschriebene Geschichte ist keine Fantasie, sondern eine kollektive Beschreibung einiger Ereignisse im Jahr 2020. In großen Unternehmen ist für diesen Fall immer ein Disaster Recovery Plan (DRP) verfügbar. In Unternehmen sind Business Continuity-Spezialisten dafür verantwortlich. In mittleren und kleinen Unternehmen liegt die Lösung solcher Probleme jedoch bei der IT-Abteilung. Sie müssen die Geschäftslogik selbst verstehen, verstehen, was fallen kann und wo, Schutz finden und implementieren.
Es ist großartig, wenn es dem IT-Experten gelingt, mit dem Unternehmen zu verhandeln und die Notwendigkeit eines Schutzes zu erörtern. Aber ich habe mehr als einmal gesehen, wie das Unternehmen von einer Disaster Recovery (DR) -Lösung gespart hat, die es für überflüssig hielt. Bei einem Unfall drohte eine lange Erholung mit Verlusten, und das Geschäft war noch nicht fertig. Sie können so oft wiederholen, wie Sie möchten: „Aber ich habe es Ihnen gesagt“ - der IT-Service muss die Services noch wiederherstellen.

Aus der Sicht eines Architekten werde ich Ihnen sagen, wie Sie diese Situation vermeiden können. Im ersten Teil des Artikels werde ich die vorbereitenden Arbeiten zeigen: Wie können drei Fragen mit dem Kunden zur Auswahl von Schutzwerkzeugen besprochen werden:
- Was schützen wir?
- Wovor schützen wir uns?
- Wie stark schützen wir?
Im zweiten Teil werden wir über die Möglichkeiten zur Beantwortung der Frage sprechen: Womit soll man sich verteidigen? Ich werde Beispiele für Fälle geben, in denen verschiedene Kunden ihren Schutz aufbauen.
Was wir schützen: Klärung kritischer Geschäftsfunktionen
Beginnen Sie am besten mit der Vorbereitung, indem Sie den Katastrophenplan mit dem Geschäftskunden besprechen. Die Hauptschwierigkeit besteht darin, eine gemeinsame Sprache zu finden. Dem Kunden ist es normalerweise egal, wie die IT-Lösung funktioniert. Er kümmert sich darum, ob der Dienst Geschäftsfunktionen ausführen und Geld verdienen kann. Beispiel: Wenn die Site funktioniert und das Zahlungssystem „lügt“, gibt es keine Belege von Kunden, und die „extremen“ sind immer noch IT-Spezialisten.
Ein IT-Experte kann aus mehreren Gründen Schwierigkeiten haben, zu verhandeln:
- Der IT-Service ist sich der Rolle des Informationssystems im Geschäftsleben nicht vollständig bewusst. Zum Beispiel, wenn keine Beschreibung von Geschäftsprozessen oder ein transparentes Geschäftsmodell verfügbar ist.
- Nicht der gesamte Prozess hängt von der IT-Abteilung ab. Zum Beispiel, wenn ein Teil der Arbeit von Auftragnehmern ausgeführt wird und die IT-Spezialisten keinen direkten Einfluss auf sie haben.
Ich würde das Gespräch so strukturieren:
- Wir erklären Unternehmen, dass Unfälle bei jedem passieren und die Wiederherstellung Zeit braucht. Am besten zeigen Sie die Situation, wie es passiert und welche Konsequenzen möglich sind.
- Wir zeigen, dass nicht alles vom IT-Service abhängt, aber Sie sind bereit, mit einem Aktionsplan in Ihrem Verantwortungsbereich zu helfen.
- Wir bitten den Geschäftskunden zu antworten: Wenn eine Apokalypse auftritt, welcher Prozess sollte zuerst wiederhergestellt werden? Wer nimmt daran teil und wie?
Das Unternehmen benötigt eine einfache Antwort, zum Beispiel: Das Call Center muss weiterhin rund um die Uhr Anfragen registrieren.
- - .
, .
: - , . 1 -, .
- , . :
- ( ),
- , ( ),
- ( ).
- ( ),
- Wir finden die möglichen Fehlerquellen heraus: die Knoten des Systems, von denen die Serviceleistung abhängt. Separat markieren wir die Knoten, die von anderen Unternehmen unterstützt werden: Telekommunikationsbetreiber, Hosting-Anbieter, Rechenzentren usw. Damit können Sie für den nächsten Schritt zum Geschäftskunden zurückkehren.
Wovor wir schützen: Risiken
Dann erfahren wir vom Geschäftskunden, vor welchen Risiken wir uns überhaupt schützen. Wir werden alle Risiken bedingt in zwei Gruppen einteilen:
- Zeitverlust aufgrund von Ausfallzeiten;
- Datenverlust aufgrund physischer Auswirkungen, menschlicher Faktoren usw.
Unternehmen haben Angst, sowohl Daten als auch Zeit zu verlieren - all dies führt zu einem Geldverlust. Also stellen wir wieder Fragen zu jeder Risikogruppe:
- Können wir für diesen Prozess abschätzen, wie viel Datenverlust und Zeitverschwendung wert sind?
- Welche Daten können wir nicht verlieren?
- Wo können wir keine Ausfallzeiten zulassen?
- Welche Ereignisse sind für uns am wahrscheinlichsten und bedrohlichsten?
Nach der Diskussion werden wir verstehen, wie Fehlerstellen priorisiert werden.
Wie stark wir schützen: RPO und RTO
Wenn die kritischen Fehlerpunkte verstanden sind, berechnen wir die RTO- und RPO-Metriken.
Ich möchte Sie daran erinnern, dass RTO (Recovery Time Objective) die zulässige Zeit vom Zeitpunkt des Unfalls bis zur vollständigen Wiederherstellung des Dienstes ist. In der Geschäftssprache ist dies die akzeptable Ausfallzeit. Wenn wir wissen, wie viel Geld der Prozess eingebracht hat, können wir die Verluste aus jeder Minute Ausfallzeit berechnen und den zulässigen Verlust berechnen.
RPO (Recovery Point Objective) ist ein gültiger Datenwiederherstellungspunkt. Es bestimmt die Zeit, in der wir Daten verlieren können. Aus geschäftlicher Sicht kann Datenverlust beispielsweise zu Geldstrafen führen. Solche Verluste können auch in Geld umgewandelt werden.
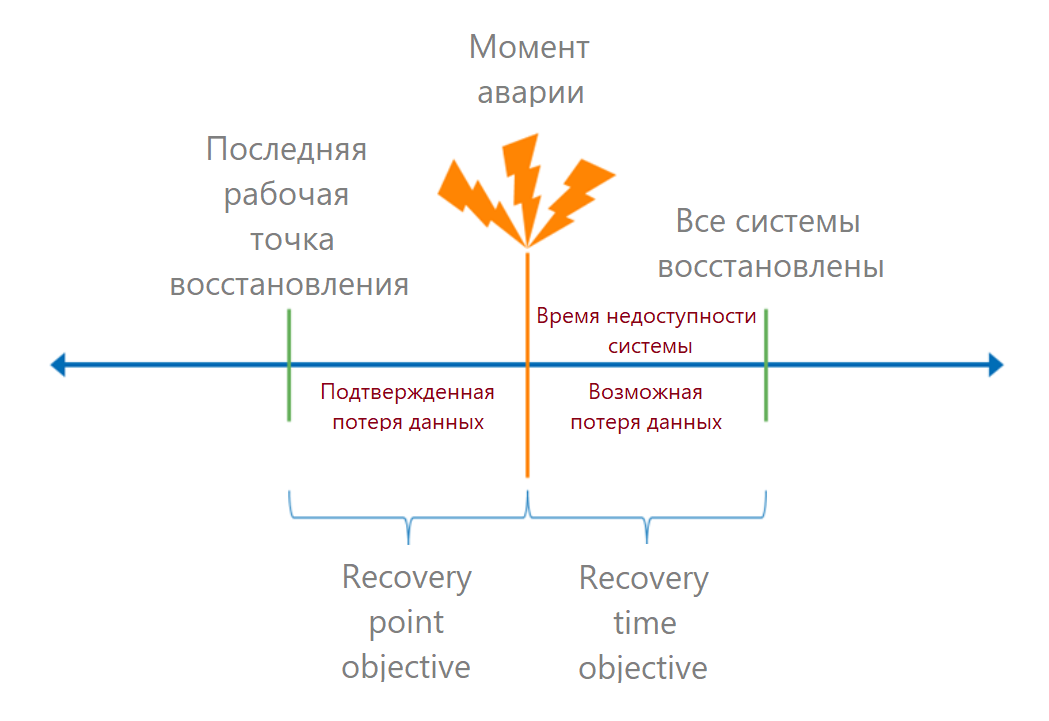
Die Wiederherstellungszeit sollte für den Endbenutzer berechnet werden: Wie lange dauert die Anmeldung am System? Also addieren wir zuerst die Wiederherstellungszeiten aller Glieder in der Kette. Hier machen sie oft einen Fehler: Sie nehmen den RTO-Anbieter aus dem SLA und vergessen die anderen Begriffe.
Schauen wir uns ein konkretes Beispiel an. Der Benutzer gibt 1C ein, das System wird mit einem Datenbankfehler geöffnet. Er kontaktiert den Systemadministrator. Die Basis befindet sich in der Cloud. Der Systemadministrator meldet das Problem dem Dienstanbieter. Angenommen, die gesamte Kommunikation dauert 15 Minuten. In der Cloud wird eine Datenbank dieser Größe in einer Stunde aus einem Backup wiederhergestellt, daher RTO auf der Seite des Dienstanbieters - eine Stunde. Dies ist jedoch nicht die letzte Frist, da dem Benutzer 15 Minuten hinzugefügt wurden, um das Problem zu erkennen.Diese Berechnungen zeigen dem Unternehmen, von welchen externen Faktoren die Erholungsphase abhängt. Wenn das Büro beispielsweise überflutet ist, müssen Sie zuerst das Leck erkennen und beheben. Es wird Zeit brauchen, die nicht von der IT abhängt.
Als Nächstes muss der Systemadministrator überprüfen, ob die Datenbank korrekt ist, eine Verbindung zu 1C herstellen und die Dienste starten. Es dauert eine weitere Stunde, was bedeutet, dass die RTO auf der Administratorseite bereits 2 Stunden 15 Minuten beträgt. Der Benutzer benötigt weitere 15 Minuten: Melden Sie sich an und überprüfen Sie, ob die erforderlichen Transaktionen angezeigt wurden. 2 Stunden 30 Minuten ist in diesem Beispiel die gesamte Wiederherstellungszeit für den Dienst.
Wie wir schützen: Auswahl von Werkzeugen für verschiedene Risiken
Nachdem alle Punkte besprochen wurden, versteht der Kunde bereits die Unfallkosten für das Unternehmen. Jetzt können Sie Tools auswählen und das Budget besprechen. Ich werde anhand von Beispielen von Kundenfällen zeigen, welche Tools wir für verschiedene Aufgaben anbieten.
Beginnen wir mit der ersten Gruppe von Risiken: Verluste aufgrund von Ausfallzeiten. Die Lösungen für diese Aufgabe sollten eine gute RTO bieten.
-
— . , , , - .
, . . , 2 . , .
RTO: . .
: .
: , , - .
-
RTO, .
active-passive active-active. , . . , .
RTO: .
: , .
: - . .
: - . . DR , . .
. . -
, , 2 -. - , --. , .
RTO: 0.
: .
: , , .
: . :
- .
- . : «» «». «» , . «» . . .
, . . - .
-
, : . , . DR: VMware vCloud Availability (vCAV). on-premise . vCAV .
RPO RTO: 5 .
: , , . vCAV, , PAYG (10% ).
: 6 . : , — . , .
VMware vCloud Availability. - 5 . , - .
Alle in Betracht gezogenen Lösungen bieten eine hohe Verfügbarkeit, schützen Sie jedoch nicht vor Datenverlust aufgrund eines Verschlüsselungsvirus oder eines versehentlichen Mitarbeiterfehlers. In diesem Fall benötigen wir Backups, die das erforderliche RPO bereitstellen.
5. Backups nicht vergessen
Jeder weiß, dass Sie Backups erstellen müssen, auch wenn Sie die coolste Disaster Recovery-Lösung haben. Ich werde mich also kurz an einige Punkte erinnern.
Genau genommen ist Backup kein DR. Und deshalb:
- Das ist lang. Wenn die Daten in Terabyte gemessen werden, dauert die Wiederherstellung mehr als eine Stunde. Sie müssen wiederherstellen, ein Netzwerk zuweisen, überprüfen, was eingeschaltet ist, und sicherstellen, dass die Daten in Ordnung sind. Sie können also nur dann eine gute RTO erzielen, wenn nur wenige Daten vorhanden sind.
- Daten werden möglicherweise nicht beim ersten Mal wiederhergestellt, und Sie müssen Zeit für eine zweite Aktion einplanen. Es gibt zum Beispiel Zeiten, in denen wir nicht genau wissen, wann die Daten verloren gegangen sind. Angenommen, der Verlust wurde um 15.00 Uhr festgestellt, und es werden stündlich Kopien erstellt. Ab 15.00 Uhr beobachten wir alle Wiederherstellungspunkte: 14:00, 13:00 und so weiter. Wenn das System kritisch ist, versuchen wir, das Alter des Wiederherstellungspunkts zu minimieren. Wenn die erforderlichen Daten jedoch nicht in der neuen Sicherung gefunden wurden, nehmen wir den nächsten Punkt - dies ist zusätzliche Zeit.
Abgesehen davon kann der Sicherungsplan das erforderliche RPO bereitstellen . Für Backups ist es wichtig, bei Problemen mit dem Hauptstandort Geo-Redundanz bereitzustellen. Es wird empfohlen, einige der Sicherungen separat aufzubewahren.
Der endgültige Disaster Recovery-Plan sollte mindestens zwei Tools enthalten:
- Eine der Optionen 1 bis 4, die Systeme vor Abstürzen und Abstürzen schützt.
- Backup zum Schutz der Daten vor Verlust.
Es lohnt sich auch, sich um einen Backup-Kommunikationskanal zu kümmern, falls der Haupt-Internetprovider abstürzt. Und voila! - DR auf Mindestgehälter ist bereits fertig.