Hallo! Mein Name ist Igor Narazin, ich bin der Teamleiter des Logistik-Teams des Delivery Club. Ich möchte Ihnen sagen, wie wir unsere Architektur aufbauen und transformieren und wie sie sich auf unsere Entwicklungsprozesse auswirkt.
Jetzt wächst der Delivery Club (wie der gesamte Foodtech-Markt) sehr schnell, was das technische Team vor eine Vielzahl von Herausforderungen stellt, die sich anhand von zwei der wichtigsten Kriterien zusammenfassen lassen:
- Es ist notwendig, eine hohe Stabilität und Verfügbarkeit aller Teile der Plattform sicherzustellen.
- Halten Sie gleichzeitig ein hohes Tempo bei der Entwicklung neuer Funktionen ein.
Es scheint, dass sich diese beiden Probleme gegenseitig ausschließen: Wir transformieren entweder die Plattform und versuchen, neue Änderungen so wenig wie möglich vorzunehmen, bis wir fertig sind, oder wir entwickeln schnell neue Funktionen ohne drastische Änderungen im System.
Aber wir haben (bisher) beides geschafft. Wie wir das machen, wird weiter besprochen.
Zunächst möchte ich Ihnen etwas über unsere Plattform erzählen : Wie wir sie unter Berücksichtigung des stetig wachsenden Datenvolumens transformieren, welche Kriterien wir für unsere Dienste anwenden und mit welchen Problemen wir unterwegs konfrontiert sind.
Zweitens werde ich erläutern, wie wir das Problem der Bereitstellung von Funktionen lösen , ohne Konflikte mit Änderungen an der Plattform und ohne unnötige Verschlechterung des Systems zu verursachen.
Beginnen wir mit der Plattform.
Am Anfang war ein Monolith
Die ersten Zeilen des Delivery Club-Codes wurden vor 11 Jahren geschrieben, und in den besten Traditionen des Genres war die Architektur ein Monolith in PHP. 7 Jahre lang war es mit immer mehr Funktionen gefüllt, bis es sich den klassischen Problemen der monolithischen Architektur stellte.
Zunächst waren wir voll und ganz zufrieden: Es war einfach zu warten, zu testen und bereitzustellen. Und er hat die anfänglichen Belastungen problemlos bewältigt. Aber wie gewöhnlich haben wir irgendwann solche Wachstumsraten erreicht, dass unser Monolith zu einem sehr gefährlichen Engpass wurde:
- Jeder Ausfall oder jedes Problem im Monolithen wirkt sich auf absolut alle unsere Prozesse aus.
- Der Monolith ist fest an einen bestimmten Stapel gebunden, der nicht geändert werden kann.
- Angesichts des Wachstums des Entwicklungsteams wird es schwierig, Änderungen vorzunehmen: Die hohe Konnektivität der Komponenten ermöglicht keine schnelle Bereitstellung von Funktionen.
- Der Monolith kann nicht flexibel skaliert werden.
Dies führte uns zu der (Überraschungs-) Microservice-Architektur - es wurde viel über ihre Vor- und Nachteile gesagt und geschrieben. Die Hauptsache ist, dass es eines unserer Hauptprobleme löst und es uns ermöglicht, maximale Verfügbarkeit und Fehlertoleranz des gesamten Systems zu erreichen. Ich werde in diesem Artikel nicht darauf eingehen, sondern Ihnen anhand von Beispielen erläutern, wie wir es gemacht haben und warum.
Unser Hauptproblem war die Größe der Monolith-Codebasis und das schlechte Fachwissen des Teams darin (die Plattform ist das, was wir als alt bezeichnen). Natürlich wollten wir zuerst nur den Monolithen nehmen und schneiden, um das Problem vollständig zu lösen. Wir haben jedoch sehr schnell erkannt, dass es mehr als ein Jahr dauern wird, und die Anzahl der Änderungen, die dort vorgenommen werden, wird dies niemals zulassen.
Deshalb gingen wir den anderen Weg: Wir ließen es so wie es ist und beschlossen, den Rest der Dienste um den Monolithen herum aufzubauen. Es ist weiterhin der Hauptpunkt der Auftragsverarbeitungslogik und des Datenmasters, beginnt jedoch mit dem Streaming von Daten für andere Dienste.
Ökosystem
Wie Andrey Evsyukov in einem Artikel über unsere Teams sagte , haben wir die Hauptbereiche der Domänenbereiche hervorgehoben: F & E, Logistik, Verbraucher, Anbieter, Intern, Plattform. Innerhalb dieser Bereiche sind die Hauptdomänenbereiche, mit denen die Dienstleistungen arbeiten, bereits konzentriert: Für die Logistik sind dies beispielsweise Kuriere und Bestellungen sowie für Lieferanten - Restaurants und Positionen.
Als nächstes müssen wir auf eine höhere Ebene aufsteigen und ein Ökosystem unserer Services rund um die Plattform aufbauen: Die Auftragsabwicklung steht im Mittelpunkt und ist der Datenmaster, der Rest der Services basiert darauf. Gleichzeitig ist es wichtig, dass wir unsere Anweisungen autonom machen: Wenn ein Teil ausfällt, funktioniert der Rest weiterhin.
Bei geringer Belastung ist der Aufbau des erforderlichen Ökosystems recht einfach: Unsere Verarbeitungsprozesse und -speicherdaten sowie Überweisungsdienste gelten für sie nach Bedarf.
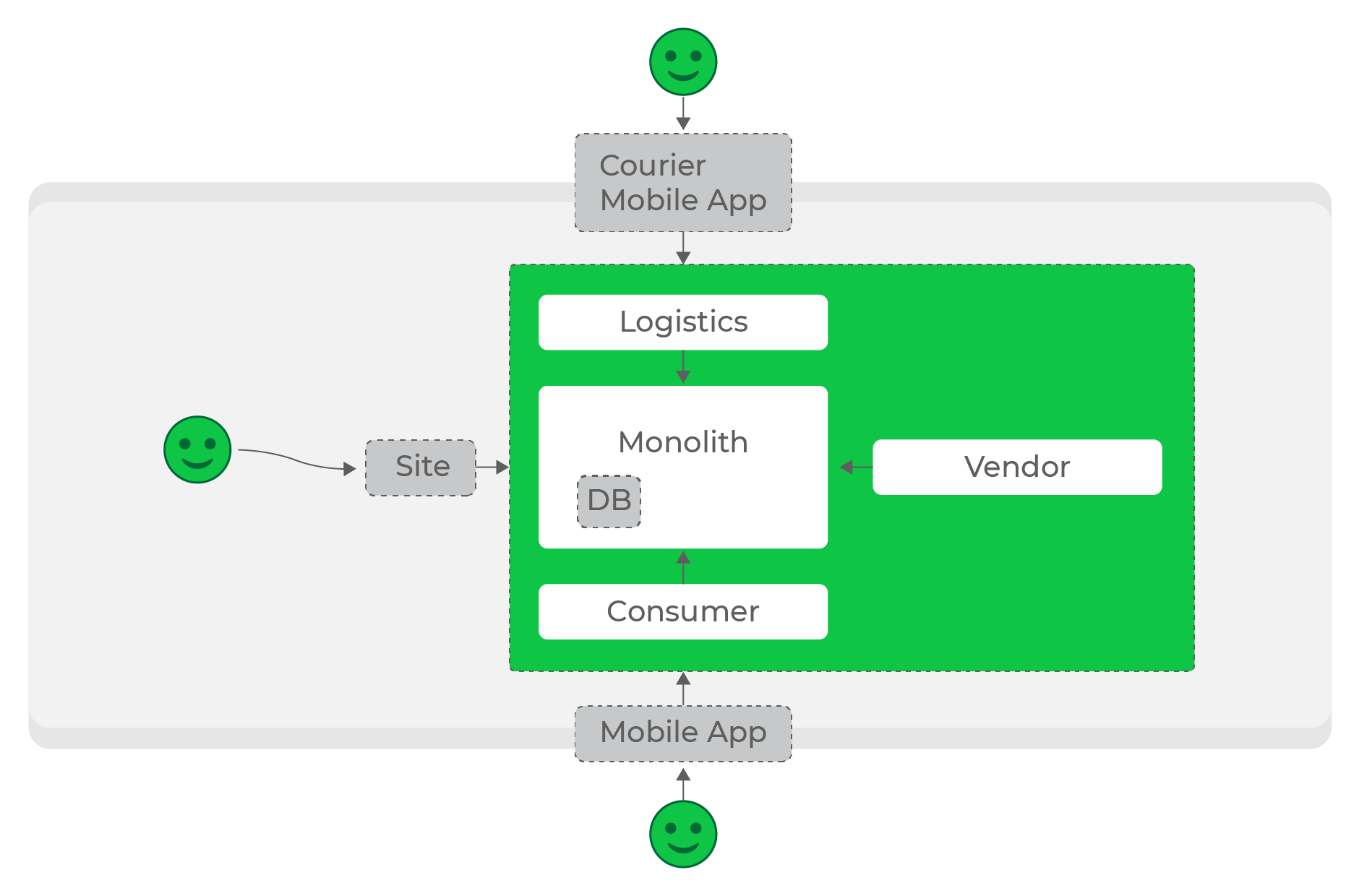 Geringe Lasten, synchrone Anforderungen, alles funktioniert super.
Geringe Lasten, synchrone Anforderungen, alles funktioniert super.
In den ersten Phasen haben wir genau das getan: Die meisten Dienste haben über synchrone HTTP-Anforderungen miteinander kommuniziert. Unter einer bestimmten Last war dies zulässig, aber je mehr das Projekt und die Anzahl der Dienste zunahmen, desto größer wurde das Problem.
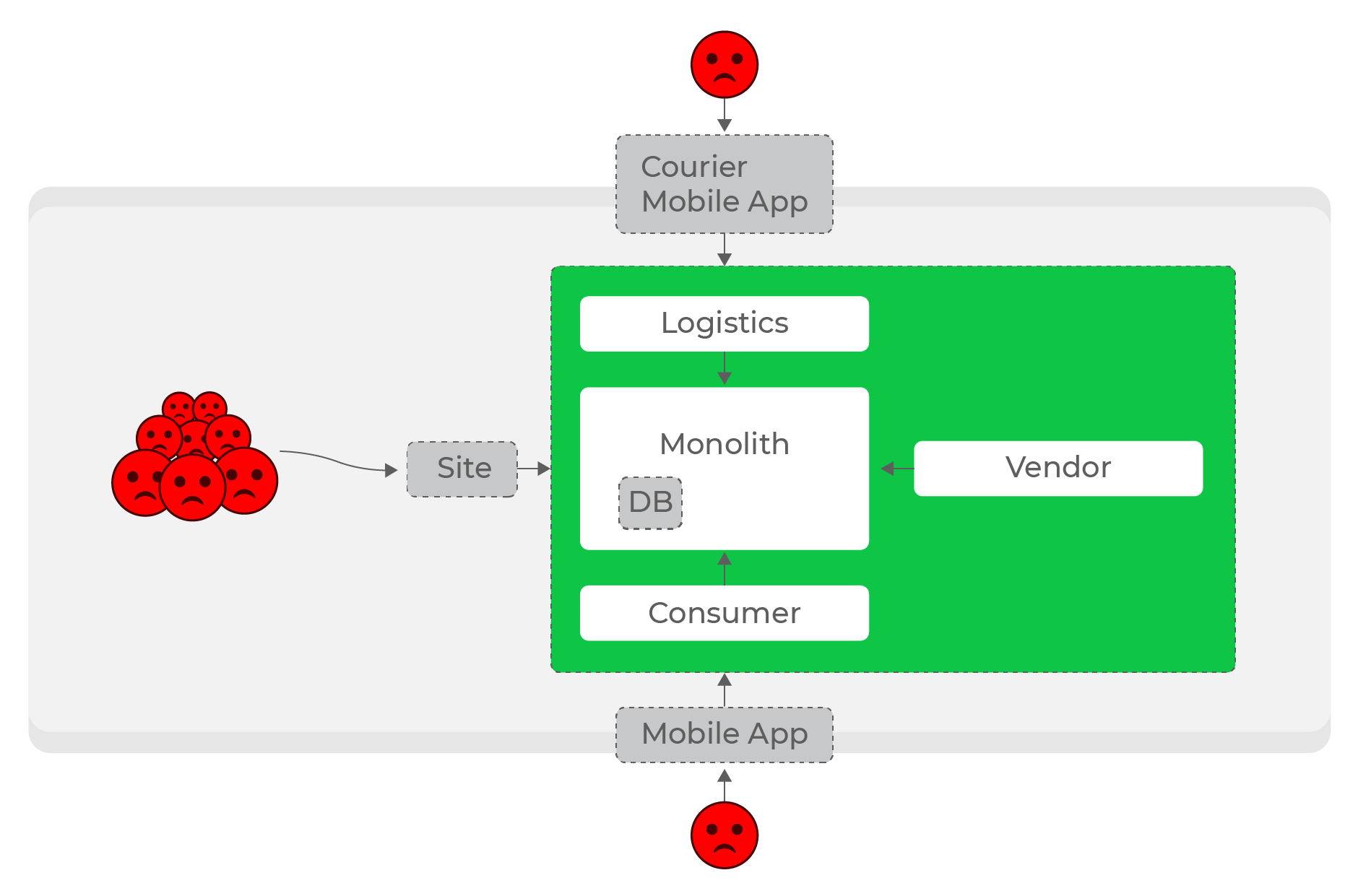
Hohe Lasten, synchrone Anforderungen: Jeder leidet, auch Benutzer völlig unterschiedlicher Domänen - Kuriere.
Es ist noch schwieriger, Dienste innerhalb von Richtungen autonom zu machen: Beispielsweise sollte eine Erhöhung der Belastung der Logistik den Rest des Systems nicht beeinträchtigen. Bei einer beliebigen Anzahl synchroner Anforderungen ist dies ein unlösbares Problem. Offensichtlich war es notwendig, synchrone Anforderungen aufzugeben und zur asynchronen Kommunikation überzugehen.
Datenbus
Daher gab es viele Engpässe, bei denen wir synchron auf Daten zugegriffen haben. Diese Orte waren im Hinblick auf die erhöhte Belastung sehr gefährlich.
Hier ist ein Beispiel. Wer mindestens einmal über Delivery Club bestellt hat, weiß, dass die Karte sichtbar wird, nachdem der Kurier die Bestellung abgeholt hat. Darauf können Sie die Bewegung des Kuriers in Echtzeit verfolgen. Für diese Funktion sind mehrere Mikrodienste beteiligt, die wichtigsten sind:
mobile-gatewayDies ist ein Backend für das Frontend für eine mobile Anwendung.courier-tracker, die die Logik des Empfangens und Sendens von Koordinaten speichert;logistics-courierswelches diese Koordinaten speichert. Sie werden von mobilen Kurieranwendungen gesendet.
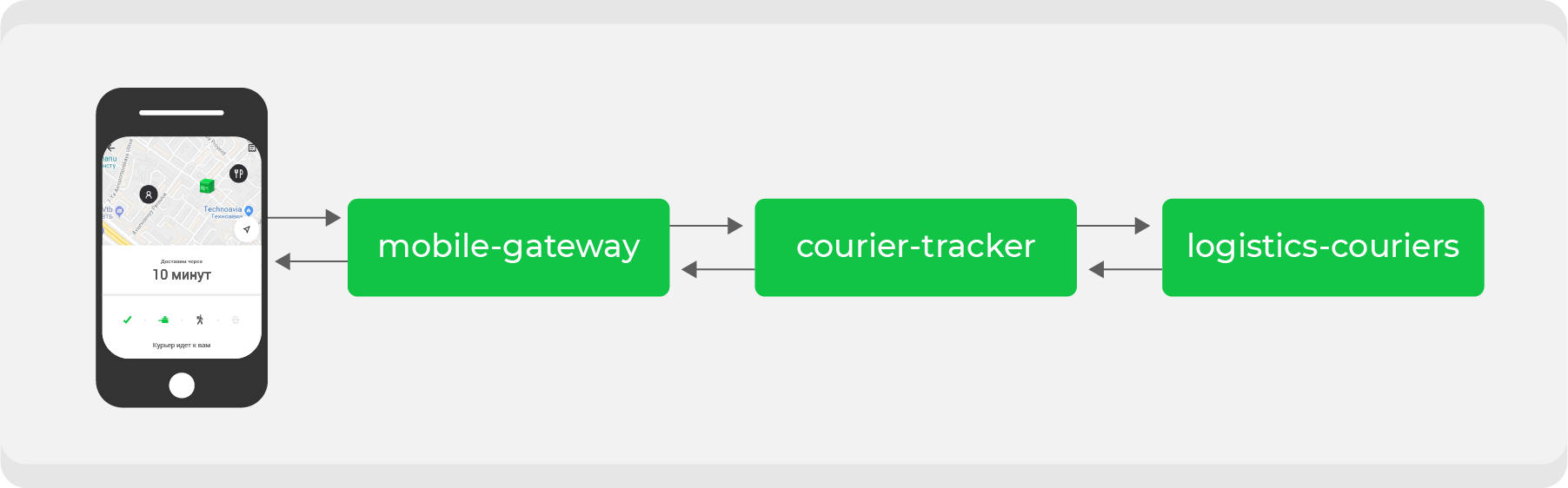
Im ursprünglichen Schema funktionierte dies alles synchron: Anfragen von der mobilen Anwendung gingen einmal pro Minute
mobile-gatewayan den Dienst courier-tracker, der auf logistics-couriersKoordinaten zugegriffen und diese empfangen hat. Natürlich war es in diesem Schema nicht so einfach, aber am Ende lief alles auf eine einfache Schlussfolgerung hinaus: Je aktiver Bestellungen wir haben, desto mehr Anfragen nach Koordinaten gingen ein logistics-couriers.
Unser Wachstum ist manchmal unvorhersehbar und vor allem schnell - eine Frage der Zeit, bis ein solches System scheitert. Dies bedeutet, dass wir den Prozess für die asynchrone Interaktion wiederholen müssen: um die Anforderung von Koordinaten so billig wie möglich zu gestalten. Dazu müssen wir unsere Datenströme transformieren.
Transport
Wir haben RabbitMQ bereits verwendet, auch für die Kommunikation zwischen Diensten. Als Haupttransportmittel haben wir uns jedoch für das bereits bewährte Tool Apache Kafka entschieden. Wir werden einen separaten ausführlichen Artikel darüber schreiben, aber jetzt möchte ich kurz darüber sprechen, wie wir es verwenden.
Als wir anfingen, Kafka als Transportmittel zu implementieren, verwendeten wir es in seiner Rohform, stellten eine direkte Verbindung zu Brokern her und sendeten Nachrichten an diese. Dieser Ansatz ermöglichte es uns, Kafka schnell im Kampf zu testen und zu entscheiden, ob wir es weiterhin als unser primäres Transportmittel verwenden möchten.
Dieser Ansatz hat jedoch einen erheblichen Nachteil: Nachrichten haben keine Typisierung und Validierung - wir wissen nicht genau, welches Nachrichtenformat wir aus dem Thema lesen.
Dies erhöht das Risiko von Fehlern und Inkonsistenzen zwischen den Diensten, die die Daten bereitstellen, und denen, die sie verbrauchen.
Um dieses Problem zu lösen, haben wir einen Wrapper geschrieben - einen Microservice in Go, der Kafka hinter seiner API verbirgt. Dies fügte zwei Vorteile hinzu:
- Datenvalidierung zum Zeitpunkt des Sendens und Empfangens. Tatsächlich handelt es sich hierbei um dieselben DTOs, sodass wir immer auf das Format der erwarteten Daten vertrauen können.
- schnelle Integration unserer Dienstleistungen in diesen Transport.
Daher ist die Arbeit mit Kafka für unsere Dienste so abstrakt wie möglich geworden: Sie arbeiten nur mit der Top-Level-API dieses Wrappers.
Kehren wir zum Beispiel zurück
Durch die Übertragung der synchronen Kommunikation auf den Ereignisbus müssen wir den Datenfluss invertieren: Was wir angefordert haben, sollte uns jetzt über Kafka selbst erreichen. Im Beispiel sprechen wir über die Koordinaten des Kuriers, für die wir nun ein spezielles Thema erstellen und diese erstellen, sobald wir sie vom Dienst von den Kurieren erhalten
logistics-couriers.
Der Dienst muss
courier-trackernur Koordinaten in der erforderlichen Menge und für den erforderlichen Zeitraum akkumulieren. Dadurch wird unser Endpunkt so einfach wie möglich: Nehmen Sie Daten aus der Servicedatenbank und geben Sie sie an eine mobile Anwendung weiter. Die Erhöhung der Belastung ist jetzt für uns sicher.
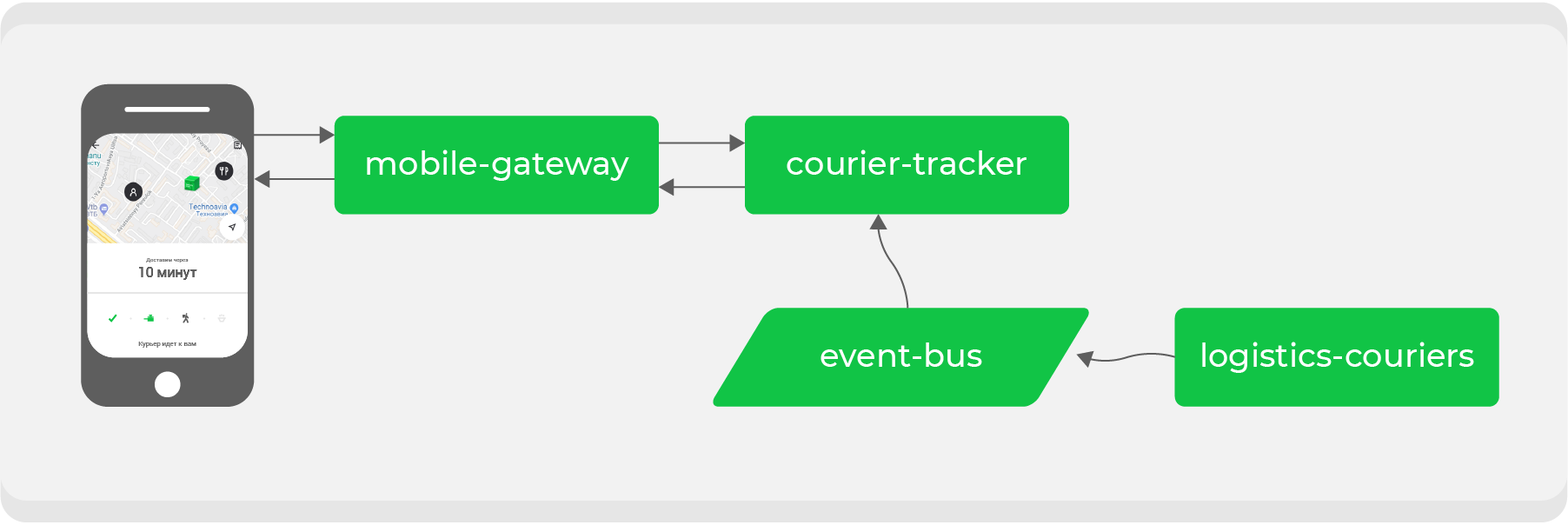
Zusätzlich zur Lösung eines bestimmten Problems erhalten wir am Ende ein Datenthema mit den tatsächlichen Koordinaten der Kuriere, das jeder unserer Dienste für seine eigenen Zwecke verwenden kann.
Schließlich Konsistenz
In diesem Beispiel funktioniert alles cool, außer dass die Koordinaten der Kuriere im Vergleich zur synchronen Option nicht immer aktuell sind: In einer Architektur, die auf asynchroner Interaktion basiert, stellt sich die Frage nach der Relevanz der Daten zu einem bestimmten Zeitpunkt. Wir haben jedoch nicht viele kritische Daten, die wir immer auf dem neuesten Stand halten müssen. Daher ist dieses Schema ideal für uns: Wir opfern die Relevanz einiger Informationen, um die Systemverfügbarkeit zu erhöhen. Wir garantieren jedoch, dass am Ende in allen Teilen des Systems alle Daten relevant und konsistent sind (eventuell Konsistenz).
Diese Denormalisierung von Daten ist erforderlich, wenn es um eine Hochlast-System- und Microservice-Architektur geht: Jeder Service selbst stellt die Speicherung der Daten sicher, die für die Arbeit benötigt werden. Eine der Hauptentitäten unserer Domain ist beispielsweise der Kurier. Viele Dienste arbeiten damit, aber alle benötigen unterschiedliche Daten: Jemand benötigt persönliche Daten, und jemand benötigt nur Informationen über die Art der Bewegung. Der Datenmaster dieser Domäne erzeugt die gesamte Entität im Stream, und die Dienste sammeln die erforderlichen Teile:
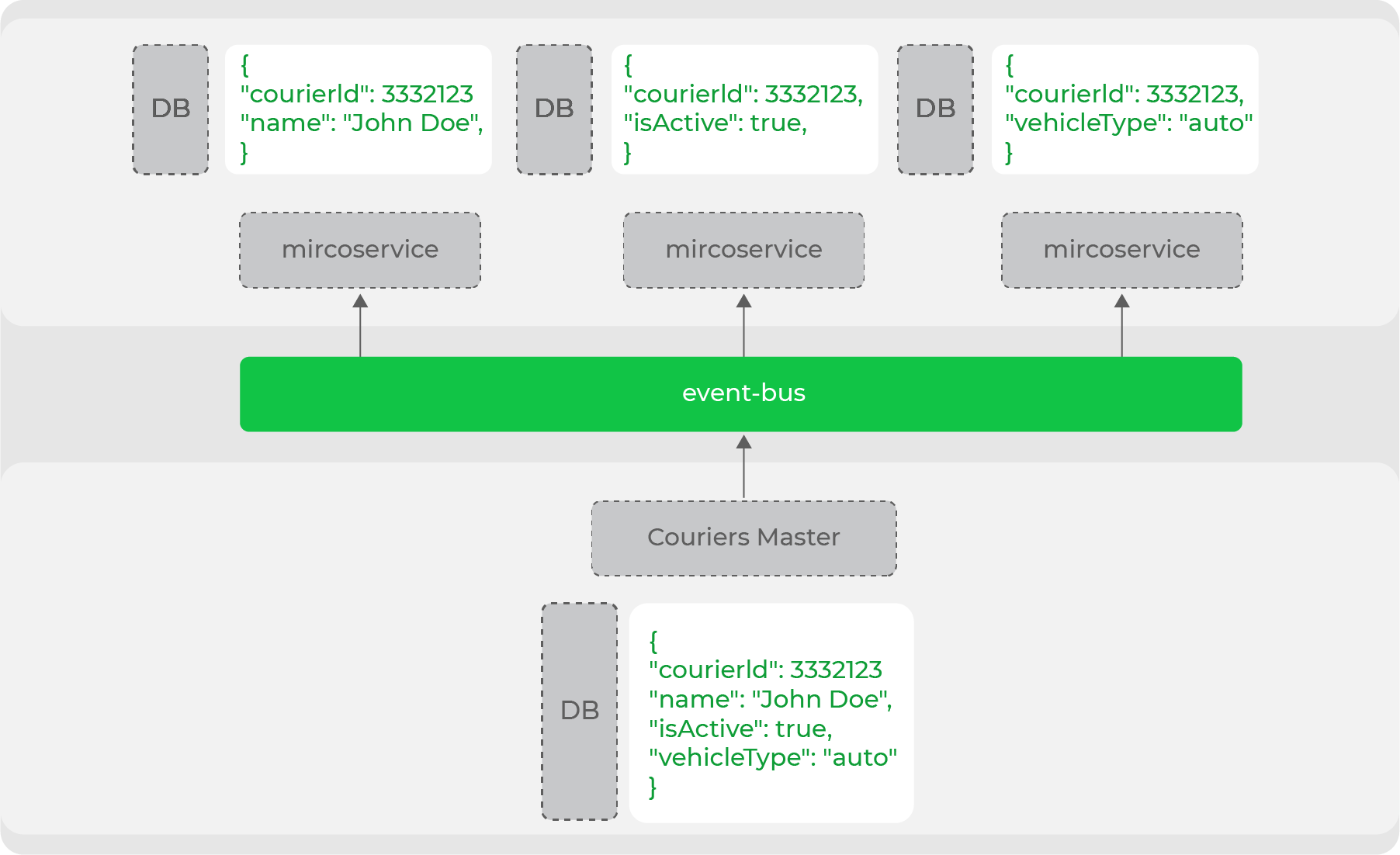
Daher teilen wir unsere Dienste klar in diejenigen auf, die Datenmaster sind, und diejenigen, die diese Daten verwenden. Tatsächlich ist dies ein kopfloser Handel aus der Evolutionsarchitektur - wir haben alle "Schaufenster" (Website, mobile Anwendungen) klar von den Herstellern dieser Daten getrennt.
Denormalisierung
Ein weiteres Beispiel: Wir haben einen Mechanismus für gezielte Benachrichtigungen an Kuriere - dies sind Nachrichten, die in der Anwendung an sie gesendet werden. Auf der Backend-Seite gibt es eine leistungsstarke API zum Senden solcher Benachrichtigungen. Darin können Sie Mailing-Filter konfigurieren: von einem bestimmten Kurier zu Gruppen von Kurieren nach bestimmten Kriterien.
Der Dienst ist für diese Benachrichtigungen verantwortlich
logistics-courier-notifications. Nachdem er eine Anfrage zum Senden erhalten hat, besteht seine Aufgabe darin, Nachrichten für die gezielten Kuriere zu generieren. Dazu muss er die erforderlichen Informationen zu allen Kurieren des Delivery Club kennen. Wir haben zwei Möglichkeiten, um dieses Problem zu lösen:
- Erstellen Sie einen Endpunkt auf der Serviceseite - den Kurierdaten-Assistenten (
logistics-couriers), der die erforderlichen Kuriere nach den übertragenen Feldern filtern und zurückgeben kann. - Speichern Sie alle erforderlichen Informationen direkt im Service, verwenden Sie sie aus dem relevanten Thema und speichern Sie die Daten, nach denen wir in Zukunft filtern müssen.
Ein Teil der Logik zum Generieren von Nachrichten und Filtern von Kurieren wird nicht geladen, sondern im Hintergrund ausgeführt, sodass keine Frage der Dienstauslastung besteht
logistics-couriers. Wenn wir uns jedoch für die erste Option entscheiden, stehen wir vor einer Reihe von Problemen:
- Sie müssen einen hochspezialisierten Endpunkt in einem Drittanbieter-Service unterstützen, den höchstwahrscheinlich nur wir benötigen.
- Wenn Sie einen zu breiten Filter auswählen, werden alle Kuriere, die einfach nicht in die HTTP-Antwort passen, in das Beispiel aufgenommen, und Sie müssen die Paginierung implementieren (und beim Abrufen des Dienstes darüber iterieren).
Offensichtlich haben wir aufgehört, Daten im Dienst selbst zu speichern. Er führt die gesamte Arbeit autonom und isoliert aus, greift nirgendwo hin, sondern sammelt nur alle notwendigen Daten aus seinem Kafka-Thema. Es besteht das Risiko, dass wir später eine Nachricht über die Erstellung eines neuen Kuriers erhalten, die in einigen Auswahlen nicht enthalten ist. Dieser Nachteil einer asynchronen Architektur ist jedoch unvermeidlich.
Infolgedessen haben wir mehrere wichtige Prinzipien für die Gestaltung von Diensten formuliert:
- Der Dienst muss eine bestimmte Verantwortung haben. Wenn ein Dienst weiterhin für seine vollständige Funktionsweise benötigt wird, handelt es sich um einen Entwurfsfehler. Er muss entweder kombiniert oder die Architektur überarbeitet werden.
- Wir betrachten alle synchronen Anrufe kritisch. Für Dienste in eine Richtung ist dies akzeptabel, für die Kommunikation zwischen Diensten in verschiedene Richtungen jedoch nicht
- Teile nichts. Wir gehen nicht zur Datenbank der Dienste, die diese umgehen. Alle Anfragen nur über die API.
- Spezifikation zuerst. Zunächst beschreiben und genehmigen wir die Protokolle.
Durch iterative Transformation unseres Systems gemäß den akzeptierten Prinzipien und Ansätzen kamen wir zu folgender Architektur:
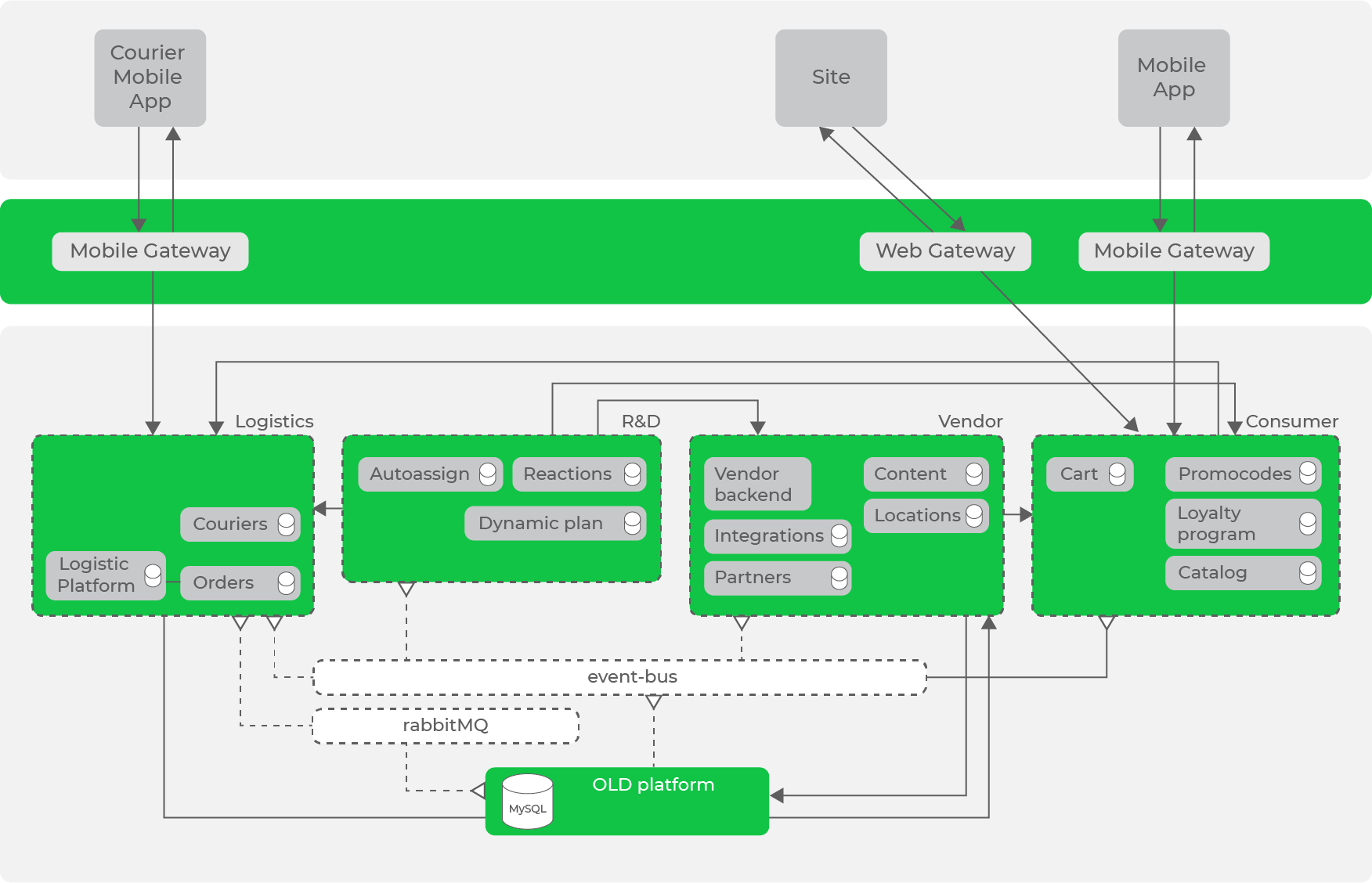
Wir haben bereits einen Datenbus in Form von Kafka, der bereits eine erhebliche Anzahl von Datenströmen aufweist, aber es gibt immer noch synchrone Anforderungen zwischen Richtungen.
Wie wir unsere Architektur entwickeln wollen
Der Delivery Club wächst, wie ich zu Beginn sagte, rasant, wir bringen eine Vielzahl neuer Funktionen in die Produktion. Und wir experimentieren noch mehr ( Nikolay Arkhipov sprach ausführlich darüber ) und testen Hypothesen. Dies schafft eine große Anzahl von Datenquellen und noch mehr Optionen für deren Verwendung. Und die korrekte Verwaltung der Datenflüsse, die für die korrekte Erstellung sehr wichtig ist - das ist unsere Aufgabe.
Von nun an werden wir die entwickelten Ansätze für alle Delivery Club-Dienste weiter implementieren: Aufbau von Service-Ökosystemen um eine Plattform mit Transport in Form eines Datenbusses.
Die Hauptaufgabe besteht darin, sicherzustellen, dass Informationen zu allen Domänen im System an den Datenbus geliefert werden. Für neue Dienste mit neuen Daten ist dies kein Problem: In der Phase der Vorbereitung des Dienstes muss er seine Domain-Daten an Kafka streamen.
Neben den neuen verfügen wir über umfangreiche Legacy-Services mit Daten zu unseren Hauptdomänen: Bestellungen und Kuriere. Es ist problematisch, diese Daten "wie sie sind" zu streamen, da sie über Dutzende von Tabellen verteilt gespeichert sind und es sehr teuer ist, die endgültige Entität so zu erstellen, dass jedes Mal alle Änderungen vorgenommen werden.
Aus diesem Grund haben wir uns entschlossen, Debezium für alte Dienste zu verwenden .Hiermit können Sie Informationen direkt aus Tabellen streamen, die auf bin-log basieren. Als Ergebnis erhalten Sie ein vorgefertigtes Thema mit Rohdaten aus der Tabelle. Sie sind jedoch für die Verwendung in ihrer ursprünglichen Form ungeeignet. Durch Transformatoren auf Kafka-Ebene werden sie in ein für Verbraucher verständliches Format konvertiert und in ein neues Thema verschoben. Daher werden wir eine Reihe privater Themen mit Rohdaten aus Tabellen haben, die in ein praktisches Format umgewandelt und zur Verwendung durch die Verbraucher an ein öffentliches Thema gesendet werden.
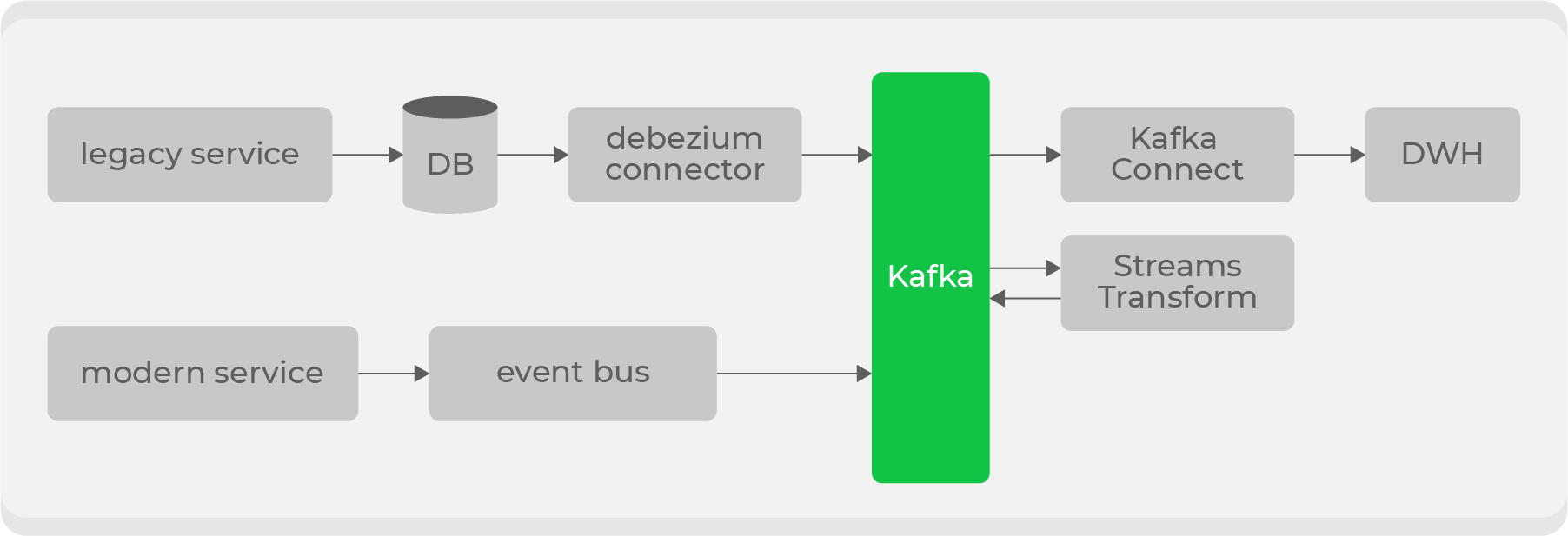
Es wird mehrere Einstiegspunkte für das Schreiben an Kafka und verschiedene Arten von Themen geben. Außerdem werden wir Zugriffsrechte nach Rollen auf der Speicherseite implementieren und die Schemaüberprüfung auf der Datenbusseite über Confluent hinzufügen .
Weiter vom Datenbus entfernt verbrauchen Dienste Daten aus den erforderlichen Themen. Und wir selbst werden diese Daten für unsere Systeme verwenden: zum Beispiel über Kafka Connect zu ElasticSearch oder DWH streamen. Mit letzterem wird der Prozess komplizierter: Damit die darin enthaltenen Informationen für alle verfügbar sind, müssen alle personenbezogenen Daten gelöscht werden.
Wir müssen auch das Problem mit dem Monolithen endlich lösen: Es gibt noch kritische Prozesse, die wir in naher Zukunft durchstehen werden. In jüngerer Zeit haben wir bereits einen separaten Service eingeführt, der sich mit der ersten Phase der Auftragserstellung befasst: Bildung eines Warenkorbs, Quittung und Zahlung. Dann sendet er diese Daten zur weiteren Verarbeitung an den Monolithen. Nun, alle anderen Operationen erfordern keine Synchronisation mehr.
So führen Sie dieses Refactoring für Kunden transparent durch
Ich erzähle Ihnen noch ein Beispiel: einen Restaurantkatalog. Offensichtlich ist dies ein sehr belebter Ort, und wir haben beschlossen, ihn auf einen separaten Dienst für unterwegs zu verlegen. Um die Entwicklung zu beschleunigen, haben wir den Imbiss in zwei Phasen unterteilt:
- Zunächst gehen wir innerhalb des Dienstes direkt zu einer Replik der Basis unseres Monolithen und erhalten von dort Daten.
- Dann beginnen wir, die benötigten Daten über Debezium zu streamen und in der Datenbank des Dienstes selbst zu sammeln.
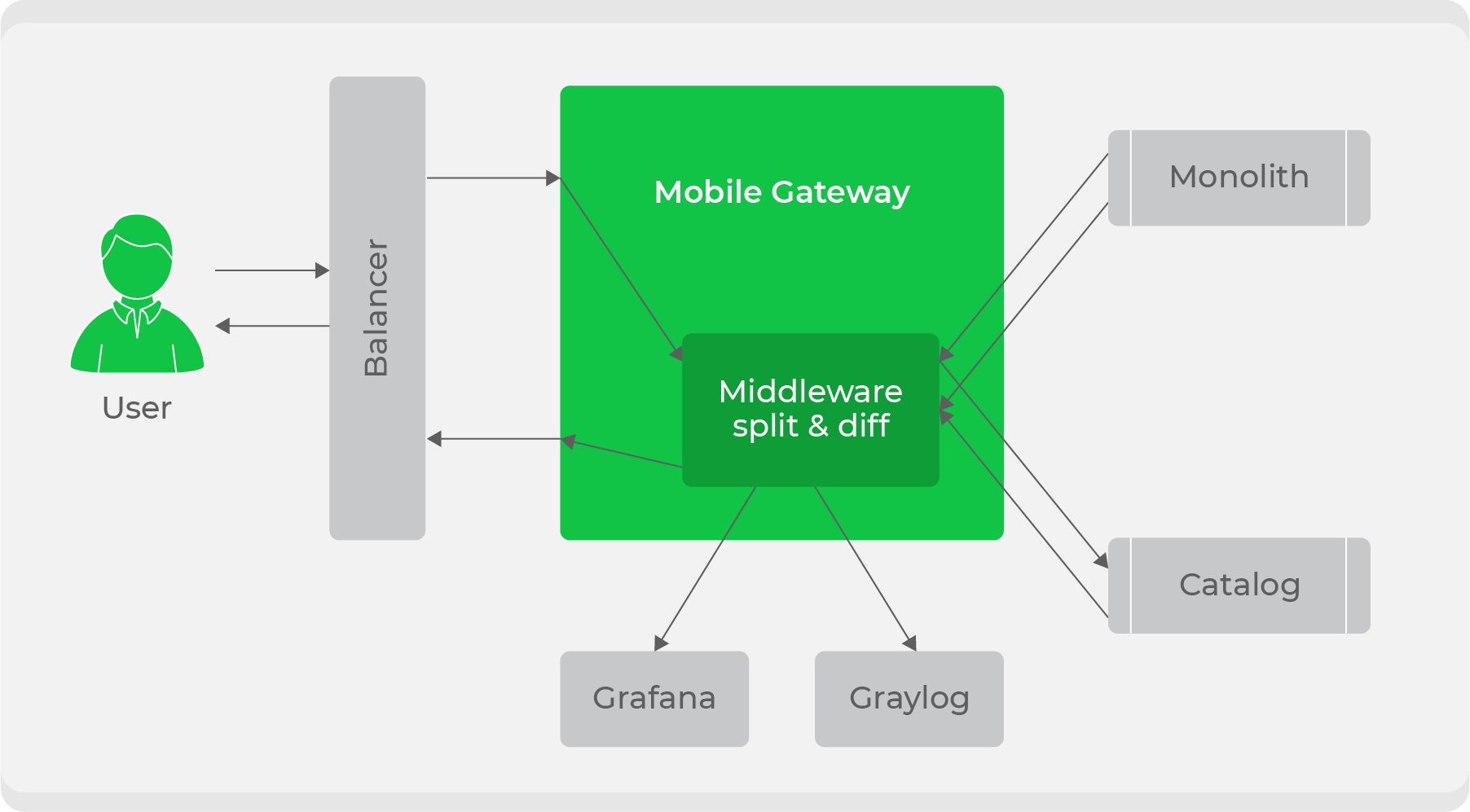
Wenn der Dienst bereit ist, stellt sich die Frage, wie er transparent in den aktuellen Workflow integriert werden kann. Wir haben ein Verkehrsaufteilungsschema verwendet: Der gesamte Verkehr von Clients ging an den Dienst
mobile-gateway, und dann wurde er zwischen dem Monolithen und dem neuen Dienst aufgeteilt. Anfangs haben wir den gesamten Datenverkehr durch den Monolithen weiter verarbeitet, einige davon jedoch in einen neuen Dienst dupliziert, ihre Antworten verglichen und Protokolle über Diskrepanzen in unseren Metriken aufgeschrieben. Damit haben wir die Transparenz des Testens des Dienstes unter Kampfbedingungen sichergestellt. Danach musste nur noch schrittweise umgeschaltet und der Verkehr erhöht werden, bis der neue Dienst den Monolithen vollständig ersetzt.
Im Allgemeinen haben wir viele ehrgeizige Pläne und Ideen. Wir stehen erst am Anfang der Entwicklung unserer weiteren Strategie, obwohl die endgültige Form nicht klar ist und nicht bekannt ist, ob alles wie erwartet funktionieren wird. Sobald wir umsetzen und Schlussfolgerungen ziehen, werden wir die Ergebnisse definitiv teilen.
Zusammen mit all diesen konzeptionellen Änderungen entwickeln und entwickeln wir weiterhin aktiv Funktionen für das Produkt, was die meiste Zeit in Anspruch nimmt. Hier kommen wir zu dem zweiten Problem, über das ich am Anfang gesprochen habe: Unter Berücksichtigung der Anzahl der Entwickler (180 Personen) stellt sich das Problem der Validierung der Architektur und Qualität neuer Dienste. Das neue sollte das System nicht beeinträchtigen, es sollte von Anfang an korrekt eingebaut sein. Aber wie kann man das im industriellen Maßstab kontrollieren?
Architekturkomitee
Die Notwendigkeit dafür entstand nicht sofort. Als das Entwicklungsteam klein war, waren alle Änderungen am System leicht zu kontrollieren. Aber je mehr Leute es gibt, desto schwieriger ist es, dies zu tun.
Dies führt sowohl zu echten Problemen (der Service konnte der Last aufgrund eines unsachgemäßen Designs nicht standhalten) als auch zu konzeptionellen Problemen („Gehen wir hier synchron, die Last ist klein“).
Es ist klar, dass die meisten Probleme auf Teamebene gelöst werden. Wenn es sich jedoch um eine komplexe Integration in das aktuelle System handelt, verfügt das Team möglicherweise einfach nicht über genügend Fachwissen. Deshalb wollte ich eine Art Vereinigung von Menschen aus allen Richtungen schaffen, auf die man mit jeder Frage zur Architektur kommen und eine erschöpfende Antwort bekommen kann.
So kamen wir zur Schaffung eines Architekturkomitees, dem Teamleiter, Richtungsleiter und CTOs angehören. Wir treffen uns alle zwei Wochen und besprechen die geplanten wesentlichen Änderungen im System oder lösen nur bestimmte Probleme.
Infolgedessen haben wir das Problem mit der Kontrolle großer Änderungen geschlossen. Die Frage nach dem allgemeinen Ansatz für die Qualität des Codes im Delivery Club bleibt bestehen: Spezifische Probleme des Codes oder Frameworks in verschiedenen Teams können auf unterschiedliche Weise gelöst werden. Wir sind zu Gilden nach dem Spotify-Modell gekommen: Dies sind Gewerkschaften von Menschen, denen eine Technologie nicht gleichgültig ist. Zum Beispiel gibt es Gilden Go, PHP und Frontend.
Sie entwickeln einheitliche Programmierstile, Design- und Architekturansätze, tragen zur Bildung und Aufrechterhaltung einer Ingenieurkultur beiauf höchstem Niveau. Sie haben auch einen eigenen Rückstand, in dem sie interne Tools verbessern, zum Beispiel unsere Go-Vorlage für Microservices.
Produktcode
Neben der Tatsache, dass wichtige Änderungen durch das Architekturkomitee vorgenommen werden und Gilden die Kultur des Codes im Allgemeinen überwachen, haben wir noch eine wichtige Phase bei der Vorbereitung des Dienstes für die Produktion: die Erstellung einer Checkliste in Confluence. Bei der Erstellung einer Checkliste bewertet der Entwickler zunächst erneut seine Entscheidung. Zweitens ist dies eine betriebliche Anforderung, da sie verstehen müssen, welche Art von neuem Service in der Produktion erscheint.
Die Checkliste zeigt normalerweise:
- verantwortlich für den Service (dies ist normalerweise der technische Leiter des Service);
- Links zum Dashboard mit benutzerdefinierten Warnungen;
- Servicebeschreibung und Link zu Swagger;
- eine Beschreibung der Dienste, mit denen es interagieren wird;
- geschätzte Belastung des Dienstes;
- health-check. URL, . Health-check - : 200, , - . , health check URL’ , , , PostgreSQL Redis.
Servicewarnungen werden in der Phase der Genehmigung durch die Architektur erstellt. Es ist wichtig, dass der Entwickler versteht, dass der Service aktiv ist und nicht nur technische, sondern auch Produktmetriken berücksichtigt. Dies bedeutet keine Geschäftskonvertierungen, sondern Metriken, die zeigen, dass der Service ordnungsgemäß funktioniert.
Sie können beispielsweise den oben bereits beschriebenen Dienst nutzen
courier-tracker, der Kuriere auf der Karte verfolgt. Eine der wichtigsten Metriken ist die Anzahl der Kuriere, deren Koordinaten aktualisiert werden. Wenn plötzlich einige Routen längere Zeit nicht aktualisiert werden, wird der Alarm "Etwas ist schief gelaufen" angezeigt. Vielleicht haben sie irgendwo nicht nach den Daten gesucht, oder sie haben die Datenbank falsch eingegeben, oder ein anderer Dienst ist ausgefallen. Dies ist keine technische oder Produktmetrik, sondern zeigt die Rentabilität des Dienstes.
Für Metriken verwenden wir Graylog und Prometheus, erstellen Dashboards und richten Warnungen in Grafana ein.
Trotz des Vorbereitungsaufwands ist die Bereitstellung von Services für die Produktion recht schnell: Alle Services werden zunächst in Docker verpackt, nach der Erstellung des typisierten Diagramms für Kubernetes automatisch auf die Bühne gebracht, und dann wird in Jenkins alles über einen Button entschieden.
Die Einführung eines neuen Dienstes für die Produktherstellung besteht darin, Administratoren in Jira eine Aufgabe zuzuweisen, die alle Informationen enthält, die wir zuvor vorbereitet haben.
Unter der Haube
Wir haben jetzt 162 Microservices in PHP und Go geschrieben. Sie wurden zwischen den Diensten zu etwa 50% bis 50% verteilt. Zunächst haben wir einige Hochlastdienste in Go neu geschrieben. Dann wurde klar, dass Go in der Produktion einfacher zu warten und zu überwachen ist und eine niedrige Einstiegsschwelle hat. Daher haben wir in letzter Zeit nur Services darin geschrieben. Es hat keinen Zweck, die verbleibenden PHP-Dienste in Go neu zu schreiben: Es kommt mit seinen Funktionen recht erfolgreich zurecht.
In PHP-Diensten haben wir Symfony, auf dem wir unser eigenes kleines Framework verwenden. Es legt den Diensten eine gemeinsame Architektur auf, dank derer wir den Schwellenwert für die Eingabe des Quellcodes der Dienste senken: Unabhängig davon, welchen Dienst Sie öffnen, ist immer klar, was sich darin befindet und wo. Das Framework kapselt auch die Transportschicht der Kommunikation zwischen Diensten. Für den Entwickler sieht eine Anforderung an einen Drittanbieter-Dienst einen hohen Abstraktionsgrad vor:
Hier bilden wir das DTO der request ($courierResponse = $this->courierProtocol->get($courierRequest);
$courierRequest), rufen die Methode des Protokollobjekts eines bestimmten Dienstes auf, der ein Wrapper über einen bestimmten Endpunkt ist. Unter der Haube wird unser Objekt $courierRequestin ein Anforderungsobjekt konvertiert, das mit Feldern aus dem DTO gefüllt ist. Dies ist alles flexibel: Felder können sowohl in die Header als auch in die Anforderungs-URL selbst eingefügt werden. Als nächstes wird die Anfrage über cURL gesendet, wir erhalten das Antwortobjekt und wandeln es wieder in das erwartete Objekt um $courierResponse.
Dies ermöglicht Entwicklern, sich auf die Geschäftslogik zu konzentrieren, ohne Interaktionsdetails auf niedriger Ebene. Objekte von Protokollen, Anforderungen und Antworten von Diensten befinden sich in einem separaten Repository - dem SDK dieses Dienstes. Dank dessen erhält jeder Dienst, der seine Protokolle verwenden möchte, nach dem Import des SDK das gesamte typisierte Protokollpaket.
Dieser Prozess hat jedoch einen großen Nachteil: Repositorys mit dem SDK sind schwierig zu warten, da alle DTOs manuell geschrieben werden und die bequeme Codegenerierung nicht einfach ist: Es gab Versuche, aber am Ende haben sie angesichts des Übergangs zu Go keine Zeit investiert.
Infolgedessen können Änderungen am Dienstprotokoll zu mehreren Pull-Anforderungen führen: zum Dienst selbst, zum SDK und zu einem Dienst, der dieses Protokoll benötigt. In letzterem Fall müssen wir die Version des importierten SDK erhöhen, damit die Änderungen dort ankommen. Dies wirft häufig Fragen von neuen Entwicklern auf: "Ich habe gerade den Parameter geändert. Warum muss ich drei Anfragen an drei verschiedene Repositorys stellen ?!"
In Go ist alles viel einfacher: Wir haben einen hervorragenden Codegenerator (Sergey Popov hat einen ausführlichen Artikel darüber geschrieben), dank dessen das gesamte Protokoll eingegeben wird, und jetzt wird sogar die Möglichkeit diskutiert, alle Spezifikationen in einem separaten Repository zu speichern. Wenn also jemand die Spezifikation ändert, werden alle davon abhängigen Dienste sofort die aktualisierte Version verwenden.
Technisches Radar
Neben dem bereits erwähnten Go und PHP verwenden wir eine Vielzahl anderer Technologien. Sie variieren von Richtung zu Richtung und hängen von bestimmten Aufgaben ab. Grundsätzlich verwenden wir im Backend:
Python, über die das Data Science-Team schreibt.KotlinundSwift- für die Entwicklung mobiler Anwendungen.PostgreSQLals Datenbank, aber einige ältere Dienste führen immer noch MySQL aus. In Microservices verwenden wir verschiedene Ansätze: Jeder Dienst verfügt über eine eigene Datenbank und teilt nichts - wir gehen nicht zu Datenbanken, die Dienste umgehen, sondern nur über deren API.ClickHouse- für hochspezialisierte Dienstleistungen im Zusammenhang mit Analysen.RedisundMemcachedals In-Memory-Speicher.
Bei der Auswahl einer Technologie orientieren wir uns an speziellen Prinzipien . Eine der Hauptanforderungen ist die Benutzerfreundlichkeit: Wir verwenden die einfachste und verständlichste Technologie für den Entwickler, wobei der akzeptierte Stapel so weit wie möglich eingehalten wird. Für diejenigen, die den gesamten Stapel spezifischer Technologien kennenlernen möchten, haben wir ein sehr detailliertes technisches Radar zusammengestellt .
Um es kurz zu machen
Infolgedessen sind wir von einer monolithischen Architektur zu einer Microservice-Architektur übergegangen, und jetzt haben wir bereits Gruppen von Diensten, die durch Richtungen (Domänenbereiche) um die Plattform, die den Kern und den Datenmaster darstellt, vereint sind.
Wir haben eine Vision davon, wie wir unsere Datenströme neu organisieren und wie wir dies tun können, ohne die Geschwindigkeit der Entwicklung neuer Funktionen zu beeinträchtigen. In Zukunft werden wir Ihnen auf jeden Fall mitteilen, wohin uns dies geführt hat.
Dank des aktiven Wissenstransfers und eines formalisierten Änderungsprozesses können wir eine Vielzahl von Funktionen bereitstellen, die den Transformationsprozess unserer Architektur nicht verlangsamen.
Das ist alles für mich, danke fürs Lesen!