
Einführung einer anpassbaren und interaktiven Entscheidungsbaumstruktur in Python. Diese Implementierung eignet sich zum Extrahieren von Wissen aus Daten, zum Testen der Intuition, zum Verbessern des Verständnisses des Innenlebens von Entscheidungsbäumen und zum Erforschen alternativer Ursache-Wirkungs-Beziehungen für Ihr Lernproblem. Es kann als Teil komplexerer Algorithmen, Visualisierungen und Berichte für jeden Forschungszweck und als zugängliche Plattform verwendet werden, um Ihre Ideen für Entscheidungsbaumalgorithmen einfach zu testen.
TL; DR
- HDTree-Repository
- Komplementäres Notizbuch im Inneren
examples. Das Repository-Verzeichnis befindet sich hier (jede Abbildung, die Sie hier sehen, wird im Editor generiert). Sie können selbst Illustrationen erstellen.
Worum geht es in der Post?
Eine weitere Implementierung von Entscheidungsbäumen, die ich im Rahmen meiner Diplomarbeit geschrieben habe. Die Arbeit gliedert sich wie folgt in drei Teile:
- Ich werde versuchen zu erklären, warum ich mich Zeit genommen habe, um meine eigene Implementierung von Entscheidungsbäumen zu entwickeln. Ich werde einige seiner Funktionen auflisten , aber auch die Nachteile der aktuellen Implementierung.
- Ich zeige Ihnen die grundlegende Verwendung von HDTree mit einigen Codefragmenten und einigen Details, die auf dem Weg erklärt werden.
- Tipps zum Anpassen und Erweitern von HDTree mit Ihren Ideen.
Motivation und Hintergrund
Für meine Dissertation begann ich mit Entscheidungsbäumen zu arbeiten. Mein Ziel ist es nun, ein menschenzentriertes ML-Modell zu implementieren, bei dem HDTree (Human Decision Tree) eine zusätzliche Zutat ist, die als Teil der realen Benutzeroberfläche für dieses Modell angewendet wird. Obwohl es in dieser Geschichte ausschließlich um HDTree geht, könnte ich eine Fortsetzung schreiben, in der die anderen Komponenten detailliert beschrieben werden.
HDTree-Funktionen und Vergleich mit Scikit-Lernentscheidungsbäumen
Natürlich bin ich auf eine Implementierung des Entscheidungsbaums gestoßen
scikit-learn[4]. Die Implementierung sckit-learnhat viele Vorteile:
- Es ist schnell und rationalisiert;
- Geschrieben im Cython-Dialekt. Cython kompiliert zu C-Code (der wiederum zu Binärcode kompiliert wird), wobei die Fähigkeit zur Interaktion mit dem Python-Interpreter erhalten bleibt.
- Einfach und bequem;
- Viele Menschen in ML wissen, wie man mit Modellen arbeitet
scikit-learn. Dank seiner Benutzerbasis erhalten Sie überall Hilfe. - Es wurde unter Kampfbedingungen getestet (es wird von vielen verwendet);
- Es funktioniert einfach;
- Es unterstützt eine Vielzahl von Vor- und Nachtrimmtechniken [6] und bietet viele Funktionen (z. B. Trimmen mit minimalen Kosten und Probengewichten).
- Unterstützt das grundlegende Rendern [7].
Es hat jedoch sicherlich einige Nachteile:
- Es ist nicht trivial, sich zu ändern, auch wegen des eher ungewöhnlichen Cython-Dialekts (siehe Vorteile oben);
- Es gibt keine Möglichkeit, das Wissen der Benutzer über den Themenbereich zu berücksichtigen oder den Lernprozess zu ändern.
- Die Visualisierung ist recht minimalistisch;
- Keine Unterstützung für kategoriale Funktionen;
- Keine Unterstützung für fehlende Werte;
- Die Schnittstelle für den Zugriff auf Knoten und das Durchlaufen des Baums ist umständlich und nicht intuitiv.
- Keine Unterstützung für fehlende Werte;
- Nur binäre Partitionen (siehe unten);
- Es gibt keine multivariaten Partitionen (siehe unten).
HDTree-Funktionen
HDTree bietet eine Lösung für die meisten dieser Probleme, opfert jedoch viele der Vorteile der Implementierung von scikit-learn. Wir werden später auf diese Punkte zurückkommen. Machen Sie sich also keine Sorgen, wenn Sie die gesamte folgende Liste noch nicht verstanden haben:
- Interagiert mit dem Lernverhalten;
- Die Hauptkomponenten sind modular aufgebaut und relativ einfach zu erweitern (Implementierung einer Schnittstelle).
- Geschrieben in reinem Python (mehr verfügbar)
- Hat reichhaltige Visualisierung;
- Unterstützt kategoriale Daten;
- Unterstützt fehlende Werte;
- Unterstützt multivariate Aufteilung;
- Verfügt über eine praktische Oberfläche zum Navigieren in der Baumstruktur.
- Unterstützt n-ary Partitionierung (mehr als 2 untergeordnete Knoten);
- Textdarstellungen von Lösungen;
- Fördert die Erklärbarkeit durch Drucken von lesbarem Text.
Minuspunkte:
- Langsam;
- Nicht in Schlachten getestet;
- Die Qualität der Software ist mittelmäßig;
- Nicht viele Zuschneideoptionen. Die Implementierung unterstützt jedoch einige grundlegende Parameter.
Es gibt nicht viele Nachteile, aber sie sind kritisch. Lassen Sie uns gleich klar sein: Geben Sie dieser Implementierung keine Big Data. Du wirst für immer warten. Verwenden Sie es nicht in einer Produktionsumgebung. Es kann unerwartet brechen. Du wurdest gewarnt! Einige der oben genannten Probleme können im Laufe der Zeit behoben werden. Es ist jedoch wahrscheinlich, dass die Lernrate niedrig bleibt (obwohl die Schlussfolgerung gültig ist). Sie müssen eine bessere Lösung finden, um dies zu beheben. Ich lade Sie ein, einen Beitrag zu leisten. Was sind jedoch die möglichen Anwendungen?
- Wissen aus Daten extrahieren;
- Überprüfen der intuitiven Ansicht der Daten;
- Das Innenleben von Entscheidungsbäumen verstehen;
- Erforschen Sie alternative kausale Zusammenhänge in Bezug auf Ihr Lernproblem.
- Verwendung als Teil komplexerer Algorithmen;
- Erstellung von Berichten und Visualisierung;
- Verwendung für Forschungszwecke;
- Als zugängliche Plattform zum einfachen Testen Ihrer Ideen für Entscheidungsbaumalgorithmen.
Entscheidungsbaumstruktur
Obwohl Entscheidungsbäume in diesem Dokument nicht im Detail behandelt werden, werden wir ihre Grundbausteine zusammenfassen. Dies bietet eine Grundlage für das spätere Verständnis der Beispiele und hebt auch einige der Funktionen von HDTree hervor. Die folgende Abbildung zeigt die tatsächliche Ausgabe von HDTree (ohne Marker).
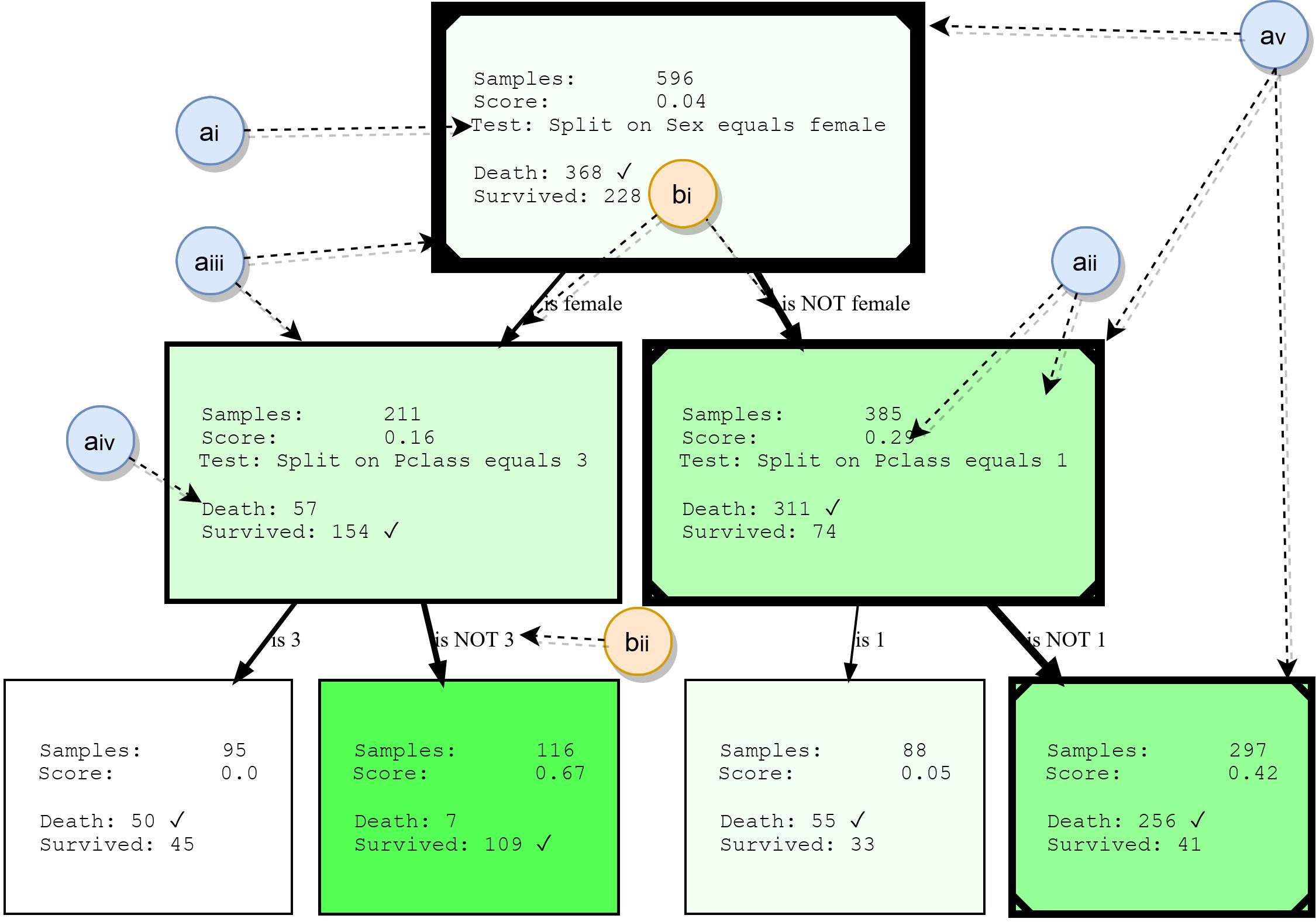
Knoten
- ai: , . . * * . . 3.
- aii: , , , , . , . . , ( , .. ). HDTree.
- aiii: Der Rand der Knoten gibt an, wie viele Datenpunkte diesen Knoten durchlaufen. Je dicker der Rand, desto mehr Daten fließen durch den Knoten.
- aiv: Liste der Vorhersageziele und Beschriftungen, bei denen Datenpunkte durch diesen Knoten verlaufen. Die häufigste Klasse ist markiert.
- av: Optional kann die Visualisierung den Pfad markieren, dem einzelne Datenpunkte folgen (um die Entscheidung zu veranschaulichen, die getroffen wird, wenn der Datenpunkt den Baum durchquert). Dies ist mit einer Linie in der Ecke des Entscheidungsbaums gekennzeichnet.
Rippen
- bi: Ein Pfeil verbindet jedes mögliche Teilungsergebnis (ai) mit seinen untergeordneten Knoten. Je mehr Daten relativ zum übergeordneten Element um die Kante "fließen", desto dicker werden sie angezeigt.
- bii: Jede Kante hat eine für Menschen lesbare Textdarstellung des entsprechenden Split-Ergebnisses.
Woher kommen die unterschiedlichen Trennungen von Sätzen und Tests?
An diesem Punkt fragen Sie sich möglicherweise bereits, wie sich HDTree von einem Baum
scikit-learn(oder einer anderen Implementierung) unterscheidet und warum wir möglicherweise verschiedene Arten von Partitionen haben möchten. Versuchen wir dies zu klären. Möglicherweise haben Sie ein intuitives Verständnis des Funktionsbereichs . Alle Daten, mit denen wir arbeiten, befinden sich in einem bestimmten mehrdimensionalen Bereich, der durch die Anzahl und Art der Features in Ihren Daten bestimmt wird. Die Aufgabe des Klassifizierungsalgorithmus besteht nun darin , diesen Raum in nicht überlappende Bereiche zu unterteilen und zuzuweisenDiese Bereiche sind Klasse. Lassen Sie uns dies visualisieren. Da es unserem Gehirn schwer fällt, an hoher Dimensionalität zu basteln, bleiben wir bei einem 2D-Beispiel und einem sehr einfachen Zwei-Klassen-Problem wie dem folgenden:

Sie sehen einen sehr einfachen Datensatz, der aus zwei Dimensionen (Merkmalen / Attributen) und zwei Klassen besteht. Die generierten Datenpunkte wurden normalerweise in der Mitte verteilt. Eine Straße, die nur eine lineare Funktion ist,
f(x) = ytrennt die beiden Klassen: Klasse 1 (unten rechts) und Klasse 2 (oben links). Es wurde auch ein zufälliges Rauschen hinzugefügt (blaue Datenpunkte in Orange und umgekehrt), um die Auswirkungen einer späteren Überanpassung zu veranschaulichen. Die Aufgabe eines Klassifizierungsalgorithmus wie HDTree (obwohl er auch für Regressionsprobleme verwendet werden kann ) besteht darin, herauszufinden, zu welcher Klasse jeder Datenpunkt gehört. Mit anderen Worten, gegeben ein Paar von Koordinaten (x, y)wie(6, 2)... Ziel ist es herauszufinden, ob diese Koordinate zur orangefarbenen Klasse 1 oder zur blauen Klasse 2 gehört. Das Diskriminanzmodell versucht, den Objektraum (hier sind dies die (x, y) -Achsen) in blaue bzw. orangefarbene Gebiete zu unterteilen.
Angesichts dieser Daten erscheint die Entscheidung (Regeln) über die Klassifizierung der Daten sehr einfach. Eine vernünftige Person würde sagen "Denken Sie zuerst selbst"."Dies ist Klasse 1, wenn x> y, sonst Klasse 2." Die
y=xgepunktete Funktion erzeugt eine perfekte Trennung . In der Tat würde ein Maximum-Margin-Klassifikator wie Support Vector Machines [8] eine ähnliche Lösung vorschlagen. Aber mal sehen, welche Entscheidungsbäume die Frage anders lösen:

Das Bild zeigt die Bereiche, in denen ein Standardentscheidungsbaum mit zunehmender Tiefe einen Datenpunkt als Klasse 1 (orange) oder Klasse 2 (blau) klassifiziert.
Ein Entscheidungsbaum approximiert eine lineare Funktion unter Verwendung einer Schrittfunktion.Dies liegt an der Art der Validierungs- und Partitionierungsregel, die Entscheidungsbäume verwenden. Sie alle arbeiten in einem Muster
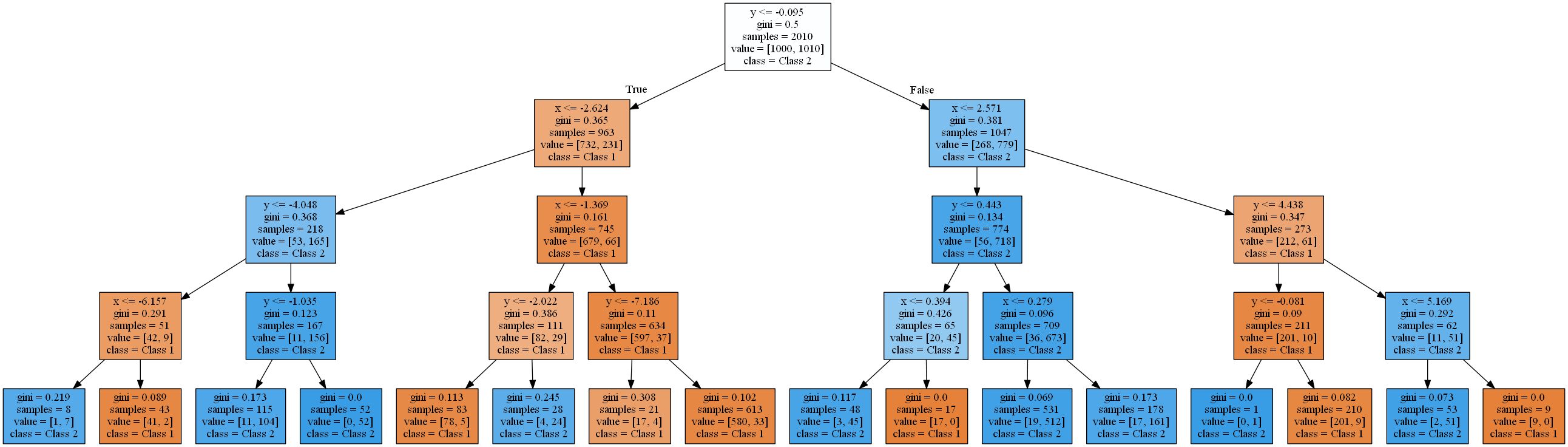
attribute < threshold, das zu Hyperebenen führt, die parallel zu den Achsen sind . Im 2D-Raum werden Rechtecke "ausgeschnitten". In 3D wären dies Quader und so weiter. Darüber hinaus beginnt der Entscheidungsbaum mit der Modellierung des Rauschens in den Daten, wenn bereits 8 Ebenen vorhanden sind, dh eine Überanpassung auftritt. Es findet jedoch nie eine gute Annäherung an eine echte lineare Funktion. Um dies zu überprüfen, habe ich eine typische 2-zu-1-Aufteilung der Trainings- und Testdaten verwendet und die Genauigkeit der Bäume berechnet. Es ist 93.84%, 93,03%, 90,81% für das Test - Set und 94,54%, 96,57%, 98,81% für den Trainingssatz(geordnet nach Baumtiefe 4, 8, 16). Während die Genauigkeit im Test abnimmt , nimmt die Trainingsgenauigkeit zu .
Eine Steigerung der Trainingseffizienz und eine Abnahme der Testergebnisse ist ein Zeichen für Übertraining.Die resultierenden Entscheidungsbäume sind für eine so einfache Funktion ziemlich komplex. Die einfachste davon (Tiefe 4), die mit Scikit Learn gerendert wurde, sieht bereits so aus:
Ich werde dich schwieriger von den Bäumen befreien. Im nächsten Abschnitt lösen wir dieses Problem zunächst mit dem HDTree-Paket. Mit HDTree kann der Benutzer das Wissen über die Daten anwenden (genau wie das Wissen über die lineare Trennung im Beispiel). Außerdem können Sie alternative Lösungen für das Problem finden.
Anwendung des HDTree-Pakets
Dieser Abschnitt führt Sie in die Grundlagen von HDTree ein. Ich werde versuchen, einige Teile der API zu berühren. Bitte zögern Sie nicht, in den Kommentaren zu fragen oder mich zu kontaktieren, wenn Sie Fragen dazu haben. Gerne beantworte ich den Artikel und ergänze ihn gegebenenfalls. Die Installation von HDTree ist etwas komplizierter als
pip install hdtree. Entschuldigung. Zuerst benötigen Sie Python 3.5 oder neuer.
- Erstellen Sie ein leeres Verzeichnis und darin einen Ordner mit dem Namen hdtree (
your_folder/hdtree) - Klonen Sie das Repository in das Verzeichnis hdtree (kein anderes Unterverzeichnis).
- Installieren Sie die erforderlichen Abhängigkeiten:
numpy,pandas,graphviz,sklearn. - Hinzufügen
your_folderzuPYTHONPATH. Dies schließt das Verzeichnis in die Python-Import-Engine ein. Sie können es wie ein normales Python-Paket verwenden.
Alternativ fügen Sie
hdtreezu site-packagesIhrem Installationsordner python. Ich kann die Installationsdatei später hinzufügen. Zum Zeitpunkt des Schreibens ist der Code nicht im Pip-Repository verfügbar. Der gesamte Code, der die folgenden Grafiken und Ausgaben generiert (sowie zuvor gezeigt), befindet sich im Repository und wird direkt hier veröffentlicht . Lösen eines linearen Problems mit einem Geschwisterbaum
Beginnen wir sofort mit dem Code:
from hdtree import HDTreeClassifier, SmallerThanSplit, EntropyMeasure
hdtree_linear = HDTreeClassifier(allowed_splits=[SmallerThanSplit.build()], # Split rule in form a < b
information_measure=EntropyMeasure(), # Use Information Gain for the scores attribute_names=['x', 'y' ]) # give the
attributes some interpretable names # standard sklearn-like interface hdtree_linear.fit(X_street_train,
y_street_train) # create tree graph hdtree_linear.generate_dot_graph() 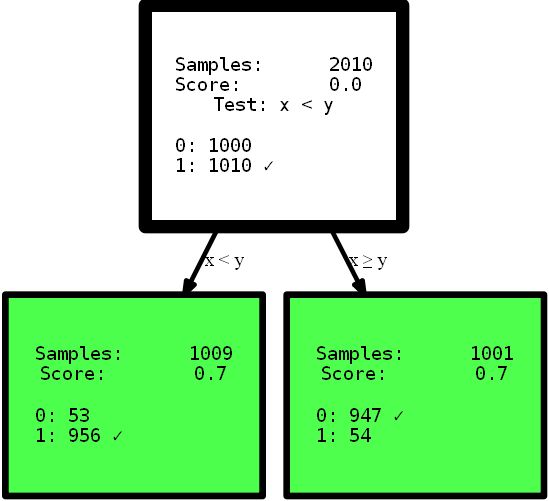
Ja, der resultierende Baum ist nur eine Ebene hoch und bietet die perfekte Lösung für dieses Problem. Dies ist ein künstliches Beispiel, um den Effekt zu zeigen. Ich hoffe jedoch, dass es klarer wird: Sie haben eine intuitive Ansicht der Daten oder stellen einfach einen Entscheidungsbaum mit verschiedenen Optionen zum Teilen des Funktionsbereichs bereit, was eine einfachere und manchmal sogar genauere Lösung bietet . Stellen Sie sich vor, Sie müssen die Regeln der hier dargestellten Bäume interpretieren, um nützliche Informationen zu finden. Welche Interpretation können Sie zuerst verstehen und welcher vertrauen Sie mehr?? Eine komplexe Interpretation mit mehrstufigen Funktionen oder ein kleiner präziser Baum? Ich denke, die Antwort ist ziemlich einfach. Aber lassen Sie uns etwas tiefer in den Code selbst eintauchen. Bei der Initialisierung ist das
HDTreeClassifierWichtigste, was Sie angeben müssen allowed_splits. Hier stellen Sie eine Liste mit den möglichen Partitionierungsregeln bereit, die der Algorithmus während des Trainings für jeden Knoten versucht, um eine gute lokale Partitionierung der Daten zu finden. In diesem Fall haben wir ausschließlich zur Verfügung gestellt SmallerThanSplit. Diese Aufteilung macht genau das, was Sie sehen: Sie benötigt zwei Attribute (versucht eine beliebige Kombination) und teilt die Daten gemäß dem Schema auf a_i < a_j. Was (nicht zu zufällig) so gut wie möglich zu unseren Daten passt.
Diese Art der Aufteilung wird als multivariate Aufteilung bezeichnetDies bedeutet, dass bei der Trennung mehr als ein Merkmal verwendet wird , um eine Entscheidung zu treffen. Dies entspricht nicht der Einwegpartitionierung, die in den meisten anderen Bäumen verwendet wird, z. B.
scikit-tree(siehe oben für weitere Details), die genau ein Attribut berücksichtigen . Natürlich gibt es HDTreeauch Optionen, um eine "normale Aufteilung" wie bei Scikit-Bäumen zu erreichen - die Familie QuantileSplit. Ich werde Ihnen im Verlauf des Artikels mehr zeigen. Eine andere ungewohnte Sache, die Sie möglicherweise im Code sehen, ist der Hyperparameter information_measure. Der Parameter stellt eine Dimension dar, mit der der Wert eines einzelnen Knotens oder einer vollständigen Aufteilung (übergeordneter Knoten mit seinen untergeordneten Knoten) ausgewertet wird. Die gewählte Option basiert auf Entropie [10]. Sie haben vielleicht auch schon davon gehörtder Gini-Koeffizient , der eine weitere gültige Option wäre. Natürlich können Sie Ihre eigene Dimension bereitstellen, indem Sie einfach die entsprechende Schnittstelle implementieren. Wenn Sie möchten , implementieren Sie einen Gini-Index , den Sie im Baum verwenden können, ohne etwas anderes erneut zu implementieren . Einfach kopieren EntropyMeasure()und selbst anpassen. Lassen Sie uns tiefer in die Titanic-Katastrophe eintauchen . Ich liebe es, aus meinen eigenen Beispielen zu lernen. Jetzt sehen Sie einige weitere HDTree-Funktionen mit einem bestimmten Beispiel, nicht für die generierten Daten.
Datensatz
Wir werden mit dem berühmten Datensatz für maschinelles Lernen für den Kurs für junge Kämpfer arbeiten: dem Titanic-Katastrophen-Datensatz. Dies ist eine ziemlich einfache Menge, die nicht zu groß ist, aber verschiedene Datentypen und fehlende Werte enthält, obwohl sie nicht ganz trivial ist. Darüber hinaus ist es für den Menschen verständlich, und viele Menschen haben bereits damit gearbeitet. Die Daten sehen folgendermaßen aus:

Sie können sehen, dass es alle Arten von Attributen gibt. Numerische, kategoriale, ganzzahlige Typen und sogar fehlende Werte (siehe Spalte Cabin). Die Herausforderung besteht darin, anhand der verfügbaren Passagierinformationen vorherzusagen, ob ein Passagier die Titanic-Katastrophe überlebt hat. Eine Beschreibung der Wertattribute finden Sie hier . Indem Sie ML-Tutorials studieren und diesen Datensatz anwenden, machen Sie alle Arten vonVorverarbeitung , um mit gängigen maschinellen Lernmodellen arbeiten zu können, z. B. Entfernen fehlender Werte
NaNdurch Ersetzen von Werten [12] , Löschen von Zeilen / Spalten, einheitliche Codierung [13] kategorialer Daten (z. B. Embarkedund SexGruppieren von Daten, um einen gültigen Datensatz zu erhalten) Diese Art der Bereinigung wird von HDTree technisch nicht benötigt. Sie können die Daten so bereitstellen, wie sie sind, und das Modell akzeptiert sie gerne. Ändern Sie die Daten nur beim Entwerfen realer Objekte. Ich habe alles vereinfacht, um zu beginnen.
Training des ersten HDTree auf Titanic-Daten
Nehmen wir einfach die Daten so wie sie sind und geben sie an das Modell weiter. Der Basiscode ähnelt dem obigen Code, dieses Beispiel ermöglicht jedoch viel mehr Datenaufteilungen.
hdtree_titanic = HDTreeClassifier(allowed_splits=[FixedValueSplit.build(), # e.g., Embarked = 'C'
SingleCategorySplit.build(), # e.g., Embarked -> ['C', 'Q', 'S']
TwentyQuantileRangeSplit.build(), # e.g., IN Quantile 3-5
TwentyQuantileSplit.build()], # e.g., BELOW Quantile 7
information_measure=EntropyMeasure(),
attribute_names=col_names,
max_levels=3) # restrict to grow to a max of 3 levels
hdtree_titanic.fit(X_titanic_train.values, y_titanic_train.values)
hdtree_titanic.generate_dot_graph()
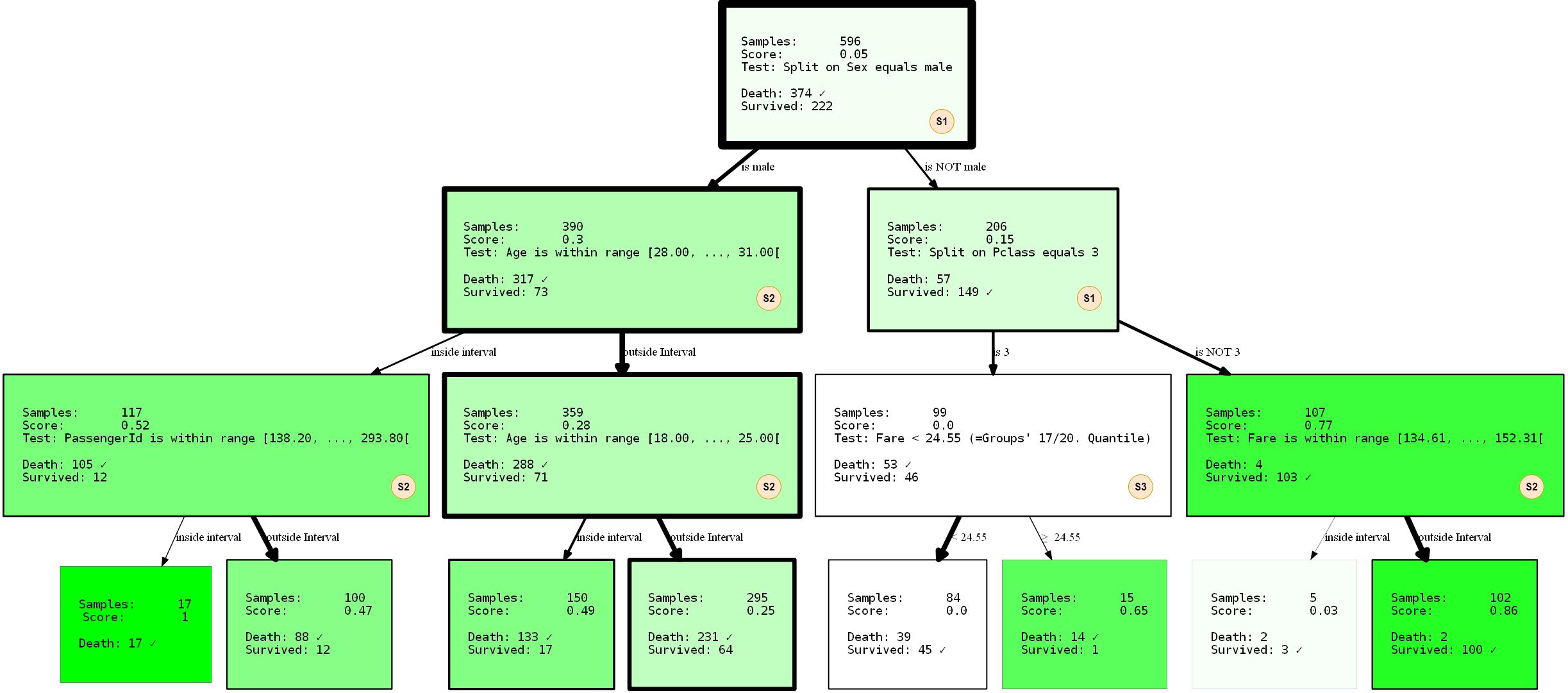
Schauen wir uns genauer an, was passiert. Wir haben einen Entscheidungsbaum mit drei Ebenen erstellt, für den wir 3 von 4 möglichen SplitRules verwendet haben. Sie sind mit den Buchstaben S1, S2, S3 gekennzeichnet. Ich werde kurz erklären, was sie tun.
- Der S1 :
FixedValueSplit. Diese Unterteilung arbeitet mit kategorialen Daten und wählt einen der möglichen Werte aus. Die Daten werden dann in einen Teil mit diesem Wert und einen anderen Teil ohne festgelegten Wert aufgeteilt. Zum Beispiel PClass = 1 und Pclass ≠ 1 . - S2: ()
QuantileRangeSplit. . , . 1 5 . ( ) (measure_information). (i) (ii) — . . - S3: (zwanzig)
QuantileSplit. Ähnlich wie Split Range (S2), jedoch werden die Daten nach Schwellenwerten aufgeteilt. Dies ist im Grunde das, was reguläre Entscheidungsbäume tun, außer dass sie normalerweise alle möglichen Schwellenwerte anstelle einer festen Zahl ausprobieren.
Möglicherweise haben Sie bemerkt, dass Sie
SingleCategorySplitnicht beteiligt sind. Ich werde trotzdem die Gelegenheit nutzen, dies zu klären, da die Auslassung dieser Unterteilung später erfolgen wird:
- S4: Funktioniert
SingleCategorySplitähnlichFixedValueSplit, erstellt jedoch für jeden möglichen Wert einen untergeordneten Knoten. Beispiel: Für das PClass- Attribut sind es 3 untergeordnete Knoten (jeweils für Klasse 1, Klasse 2 und Klasse 3 ). Beachten Sie, dass esFixedValueSplitidentisch ist,SingleValueSplitwenn es nur zwei mögliche Kategorien gibt.
Einzelne Abteilungen sind in Bezug auf die Datentypen / Werte, die "akzeptieren", etwas "klug". Bis zu einer gewissen Verlängerung wissen sie, unter welchen Umständen sie sich bewerben und welche nicht. Der Baum wurde auch mit einer 2-zu-1-Aufteilung der Trainings- und Testdaten trainiert. Die Leistung betrug 80,37% Genauigkeit bei Trainingsdaten und 81,69% bei Testdaten. Nicht so schlecht.
Splits begrenzen
Nehmen wir an, Sie sind aus irgendeinem Grund mit den gefundenen Lösungen nicht zufrieden. Vielleicht entscheiden Sie, dass die allererste Aufteilung oben im Baum zu trivial ist (Aufteilung nach Attributen
sex). HDTree löst das Problem. Die einfachste Lösung wäre, zu verhindern, dass FixedValueSplit(und im Übrigen das Äquivalent SingleCategorySplit) oben erscheint. Es ist ziemlich einfach. Ändern Sie die Initialisierung der Teilungen wie folgt:
- SNIP -
...allowed_splits=[FixedValueSplit.build_with_restrictions(min_level=1),
SingleCategorySplit.build_with_restrictions(min_level=1),...],
- SNIP -
Ich werde den resultierenden HDTree in seiner Gesamtheit präsentieren, da wir den fehlenden Split (S4) innerhalb des neu generierten Baums beobachten können.
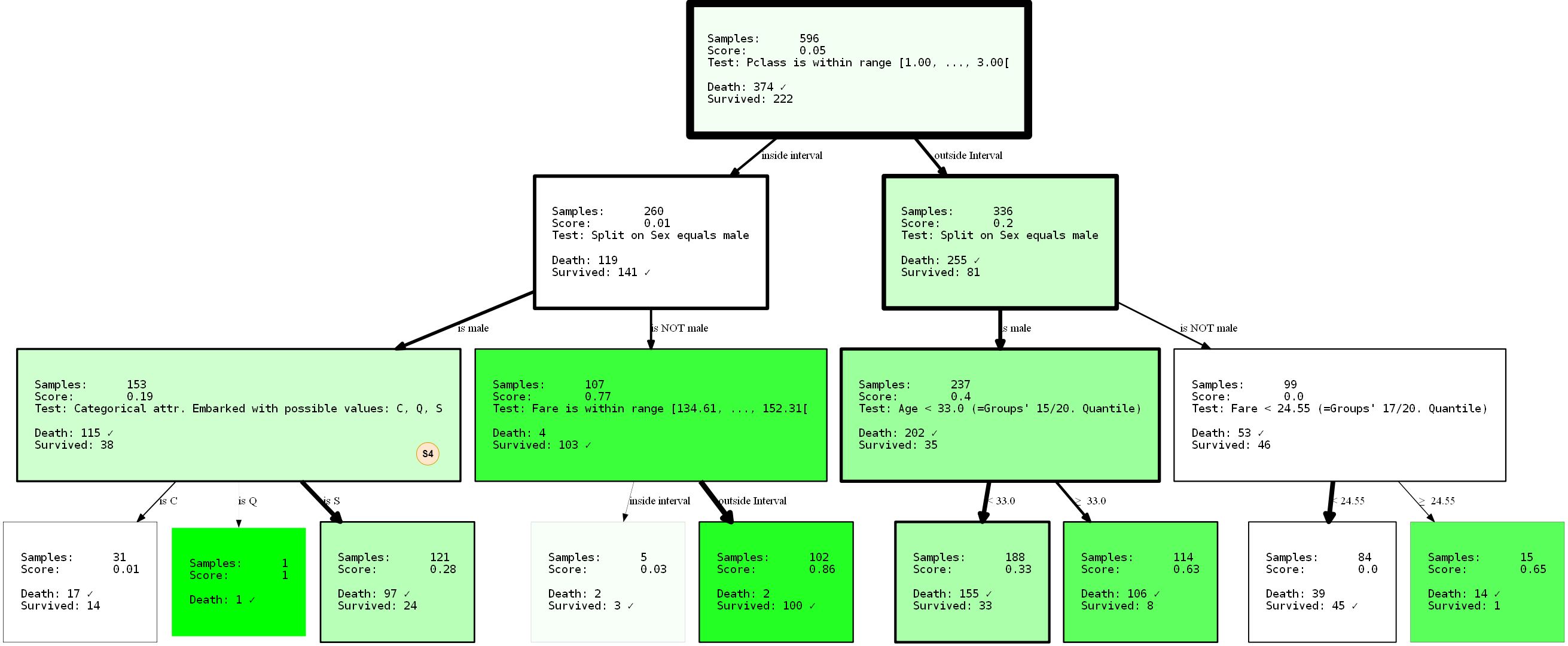
Indem wir verhindern, dass die Aufteilung
sexdank eines Parameters im Stammverzeichnis angezeigt wird min_level=1(Hinweis: Natürlich können Sie dies auch angeben max_level), haben wir den Baum vollständig umstrukturiert. Seine Leistung beträgt jetzt 80,37% und 81,69% (Training / Test). Es hat sich überhaupt nicht geändert, auch wenn wir die angeblich bessere Trennung am Wurzelknoten vorgenommen haben.
Da Entscheidungsbäume gierig sind, finden sie nur die lokale _ beste Partition für jeden Knoten, was nicht unbedingt die _ beste _ Option überhaupt ist. Tatsächlich ist das Finden einer idealen Lösung für ein Entscheidungsbaumproblem ein NP-vollständiges Problem, wie in [15] bewiesen wurde.Das Beste, was wir verlangen können, sind Heuristiken. Kehren wir zum Beispiel zurück: Beachten Sie, dass wir bereits eine nicht triviale Darstellung der Daten haben? Es ist jedoch trivial. Um zu sagen, dass Männer nur eine geringe Überlebenschance haben, kann in geringerem Maße der Schluss gezogen werden, dass eine Person der ersten oder zweiten Klasse,
PClassdie aus Cherbourg ( Embarked=C) herausfliegt, Ihre Überlebenschancen erhöhen kann. Oder was ist, wenn Sie ein Mann PClass 3unter 33 sind, erhöhen sich auch Ihre Chancen? Denken Sie daran: Frauen und Kinder zuerst. Eine gute Übung besteht darin, diese Schlussfolgerungen selbst zu ziehen, indem Sie die Visualisierung interpretieren. Diese Schlussfolgerungen waren nur aufgrund der Begrenzung des Baumes möglich. Wer weiß, was durch die Anwendung anderer Einschränkungen noch offenbart werden kann? Versuch es!
Als letztes Beispiel dieser Art möchte ich Ihnen zeigen, wie Sie die Partitionierung auf bestimmte Attribute beschränken können. Dies gilt nicht nur Baum Lernen auf unerwünschten Korrelationen oder zu verhindern gezwungen Alternativen , sondern auch verengt den Suchraum. Der Ansatz kann die Ausführungszeit erheblich verkürzen, insbesondere bei Verwendung einer multivariaten Partitionierung. Wenn Sie zum vorherigen Beispiel zurückkehren, finden Sie möglicherweise einen Knoten, der nach einem Attribut sucht
PassengerId. Vielleicht wollen wir es nicht modellieren, da es zumindest nicht zur Information über das Überleben beitragen sollte . Die Überprüfung des Passagierausweises kann ein Zeichen für Übertraining sein. Lassen Sie uns die Situation mit einem Parameter ändern blacklist_attribute_indices.
- SNIP -
...allowed_splits=[TwentyQuantileRangeSplit.build_with_restrictions(blacklist_attribute_indices=['PassengerId']),
FixedValueSplit.build_with_restrictions(blacklist_attribute_indices=['Name Length']),
...],
- SNIP -
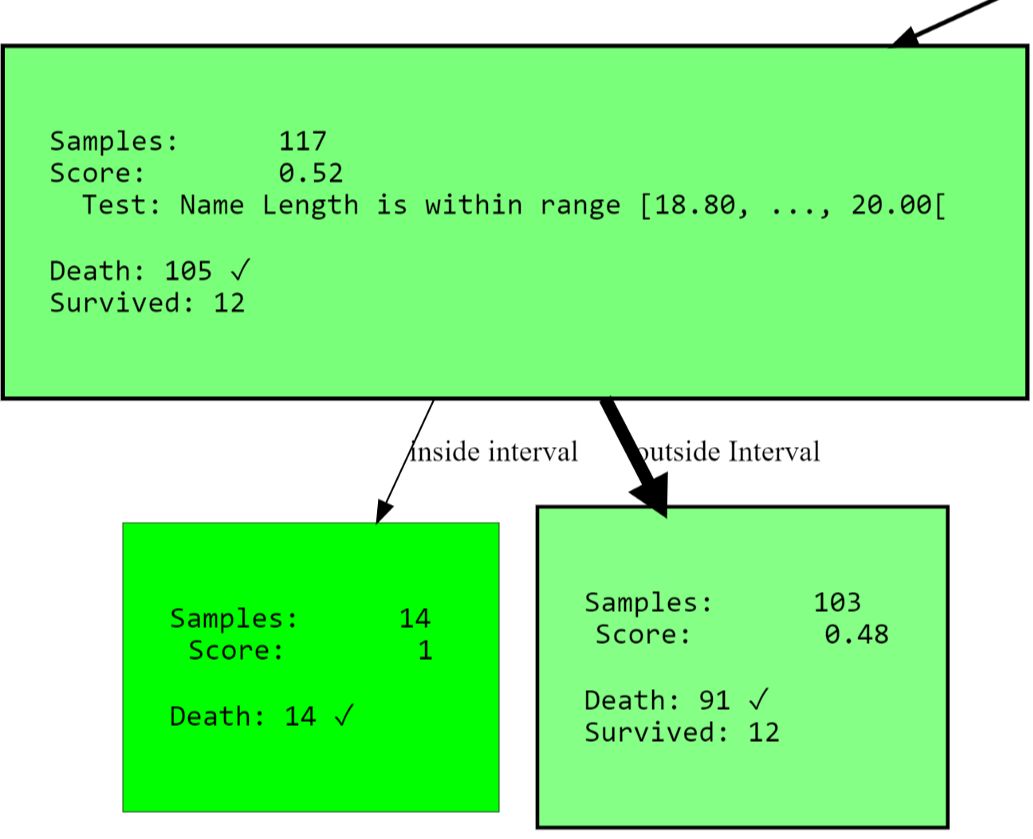
Sie können fragen, warum
name lengthes überhaupt erscheint. Beachten Sie, dass lange Namen (Doppelnamen oder [edle] Titel) auf eine reiche Vergangenheit hinweisen und Ihre Überlebenschancen erhöhen können.
Zusätzlicher Tipp: Sie können immerSplitRulezweimal dasselbe hinzufügen . Wenn Sie nur ein Attribut für bestimmte HDTree-Ebenen auf die schwarze Liste setzen möchten, fügen Sie einfachSplitRulekeine Ebenenbegrenzung hinzu .
Datenpunktvorhersage
Wie Sie vielleicht bereits bemerkt haben, kann die gemeinsame Schnittstelle zum Scikit-Lernen zur Vorhersage verwendet werden. Dies
predict(), predict_proba()wie auch score(). Aber du kannst noch weiter gehen. Es gibt explain_decision()eine, die eine Textdarstellung der Lösung anzeigt.
print(hdtree_titanic_3.explain_decision(X_titanic_train[42]))
Dies wird als letzte Änderung am Baum angenommen. Der Code gibt Folgendes aus:
Query:
Query:
{'PassengerId': 273, 'Pclass': 2, 'Sex': 'female', 'Age': 41.0, 'SibSp': 0, 'Parch': 1, 'Fare': 19.5, 'Cabin': nan, 'Embarked': 'S', 'Name Length': 41}
Predicted sample as "Survived" because of:
Explanation 1:
Step 1: Sex doesn't match value male
Step 2: Pclass doesn't match value 3
Step 3: Fare is OUTSIDE range [134.61, ..., 152.31[(19.50 is below range)
Step 4: Leaf. Vote for {'Survived'}
Dies funktioniert auch bei fehlenden Daten. Setzen wir den Index von Attribut 2 (
Sex) auf fehlt (None):
passenger_42 = X_titanic_train[42].copy()
passenger_42[2] = None
print(hdtree_titanic_3.explain_decision(passenger_42))
Query:
{'PassengerId': 273, 'Pclass': 2, 'Sex': None, 'Age': 41.0, 'SibSp': 0, 'Parch': 1, 'Fare': 19.5, 'Cabin': nan, 'Embarked': 'S', 'Name Length': 41}
Predicted sample as "Death" because of:
Explanation 1:
Step 1: Sex has no value available
Step 2: Age is OUTSIDE range [28.00, ..., 31.00[(41.00 is above range)
Step 3: Age is OUTSIDE range [18.00, ..., 25.00[(41.00 is above range)
Step 4: Leaf. Vote for {'Death'}
---------------------------------
Explanation 2:
Step 1: Sex has no value available
Step 2: Pclass doesn't match value 3
Step 3: Fare is OUTSIDE range [134.61, ..., 152.31[(19.50 is below range)
Step 4: Leaf. Vote for {'Survived'}
---------------------------------
Dadurch werden alle Entscheidungspfade gedruckt (es gibt mehrere, da auf einigen Knoten die Entscheidung nicht getroffen werden kann!). Das Endergebnis wird die häufigste Klasse aller Blätter sein.
... andere nützliche Dinge
Sie können fortfahren und die Baumansicht als Text abrufen:
Level 0, ROOT: Node having 596 samples and 2 children with split rule "Split on Sex equals male" (Split Score:
0.251)
-Level 1, Child #1: Node having 390 samples and 2 children with split rule "Age is within range [28.00, ..., 31.00["
(Split Score: 0.342)
--Level 2, Child #1: Node having 117 samples and 2 children with split rule "Name Length is within range [18.80,
..., 20.00[" (Split Score: 0.543)
---Level 3, Child #1: Node having 14 samples and no children with
- SNIP -
Oder greifen Sie auf alle sauberen Knoten zu (mit einer hohen Punktzahl):
[str(node) for node in hdtree_titanic_3.get_clean_nodes(min_score=0.5)]
['Node having 117 samples and 2 children with split rule "Name Length is within range [18.80, ..., 20.00[" (Split
Score: 0.543)',
'Node having 14 samples and no children with split rule "no split rule" (Node Score: 1)',
'Node having 15 samples and no children with split rule "no split rule" (Node Score: 0.647)',
'Node having 107 samples and 2 children with split rule "Fare is within range [134.61, ..., 152.31[" (Split Score:
0.822)',
'Node having 102 samples and no children with split rule "no split rule" (Node Score: 0.861)']
HDTree-Erweiterung
Das Wichtigste, was Sie dem System hinzufügen möchten, ist Ihr eigenes
SplitRule. Die Partitionierungsregel kann wirklich alles tun, was sie partitionieren möchte ... Implementierung SplitRuledurch Implementierung AbstractSplitRule. Dies ist etwas schwierig, da Sie die Datenaufnahme, die Leistungsbewertung und all diese Dinge selbst erledigen müssen. Aus diesen Gründen enthält das Paket Mixins, die Sie je nach Split-Typ zur Implementierung hinzufügen können. Die Mixins erledigen den größten Teil des schwierigen Teils für Sie.
Literaturverzeichnis
- [1] Wikipedia article on Decision Trees
- [2] Medium 101 article on Decision Trees
- [3] Breiman, Leo, Joseph H Friedman, R. A. Olshen and C. J. Stone. “Classification and Regression Trees.” (1983).
- [4] scikit-learn documentation: Decision Tree Classifier
- [5] Cython project page
- [6] Wikipedia article on pruning
- [7] sklearn documentation: plot a Decision Tree
- [8] Wikipedia article Support Vector Machine
- [9] MLExtend Python library
- [10] Wikipedia Article Entropy in context of Decision Trees
- [12] Wikipedia Article on imputing
- [13] Hackernoon article about one-hot-encoding
- [14] Wikipedia Article about Quantiles
- [15] Hyafil, Laurent; Rivest, Ronald L. “Constructing optimal binary decision trees is NP-complete” (1976)
- [16] Hackernoon Article on Decision Trees
Erfahren Sie in Online-Kursen zu SkillFactory, wie Sie einen hochkarätigen Beruf von Grund auf neu aufbauen oder Ihre Fähigkeiten und Ihr Gehalt verbessern können:
- Kurs für maschinelles Lernen (12 Wochen)
- Fortgeschrittenenkurs "Maschinelles Lernen Pro + Deep Learning" (20 Wochen)
- « Machine Learning Data Science» (20 )
- «Python -» (9 )
E
