In Surf haben wir unseren eigenen Interpreter geschrieben und ihn auf dem Client der mobilen Anwendung verwendet - obwohl dies anfangs anscheinend wenig mit der mobilen Entwicklung zu tun hat. In der Tat sind Interpreter und Compiler Werkzeuge zur Lösung von Problemen, die überall zu finden sind. Daher ist es hilfreich zu verstehen, wie es funktioniert, und in der Lage zu sein, eigene zu schreiben.
Am Beispiel der Übersetzung von Masken von einem Format in ein anderes werden wir uns heute mit den Grundlagen der Konstruktion von Interpreten vertraut machen und lernen, wie man formale Grammatiken, einen abstrakten Syntaxbaum und Übersetzungsregeln verwendet - auch um geschäftliche Probleme zu lösen.

Ein wenig über Masken: Was sie sind und warum Sie sie brauchen
. , , - — , . -: , , .
, . , . , API - , : 9161234567 — 8, .
, , :
, , . , , , — . ? — .
— , . , .
, :

, , : . .
, . , . , API - , : 9161234567 — 8, .
, , :
- , , .
- : , , , .
- , .
, , . , , , — . ? — .
— , . , .
, :
- . , , .
- « »: -, .
- .
, , : . .
— UX-
Warum kannst du die Maske nicht einfach aufheben und beschreiben?
Masken sind cool und bequem. Es gibt jedoch ein Problem, das unter bestimmten Bedingungen unvermeidlich ist: Wenn der Client ein Maskenformat hat und der Server viele verschiedene Datenanbieter hat und jeder sein eigenes Format hat. Wir können uns nicht darauf verlassen, dass wir das gleiche Format haben werden. Fragen Sie den Server: "Passen Sie Masken für uns an, wie wir möchten" - auch. Sie müssen damit leben können.
Das Problem tritt auf: Es gibt eine Backend-Spezifikation, Sie müssen ein Frontend schreiben - eine mobile Anwendung. Sie können alle Masken für die Anwendung manuell schreiben - und dies ist eine gute Option, wenn es nur einen Anbieter und nur wenige Masken gibt. Der Programmierer muss natürlich Zeit aufwenden, um mindestens zwei Spezifikationen für Masken zu verstehen: Backend und Front. Dann muss er bestimmte Backend-Masken in entsprechende Frontend-Masken übersetzen. Es braucht auch Zeit, es gibt einen menschlichen Faktor - Sie können sich irren. Es ist keine leichte Aufgabe, die Übersetzung ist schwierig: Einige Maskensprachen sind hauptsächlich für Computer geschrieben, nicht für Menschen.
Wenn sich plötzlich die Maske auf dem Server geändert hat oder eine neue angezeigt wurde, funktioniert die Anwendung möglicherweise erst einmal nicht mehr. Zweitens muss die harte Arbeit der Übersetzung erneut erledigt werden, eine neue Anwendung muss freigegeben werden, dies kostet Zeit, Mühe und Geld. Es stellt sich die Frage, wie die Arbeit des Programmierers minimiert werden kann. Es scheint, dass all dies von einer Maschine erledigt werden sollte, aber aus irgendeinem Grund ist eine Person beschäftigt.
Die Antwort lautet: Ja, wir haben eine Lösung. Masken sind in der Sprache von Computern geschrieben - und dies ist einer der Gründe, warum es für eine Person schwierig ist, mit ihm zu arbeiten und von einer Sprache in eine andere zu übersetzen. Wir müssen diese Arbeit auf den Computer übertragen. Da die Maske eine formale Grammatik zu sein scheint , ist der sicherste Weg, eine Grammatik in eine andere zu übersetzen ,:
- die Regeln für die Erstellung der ursprünglichen Grammatik verstehen,
- die Regeln für die Erstellung der Zielgrammatik verstehen,
- Schreiben Sie Übersetzungsregeln von der Quellgrammatik zum Ziel.
- Implementieren Sie all dies in Code.
Dafür sind Compiler und Übersetzer geschrieben.
Schauen wir uns nun unsere Lösung an, die auf formalen Grammatiken basiert.
Hintergrund
In unserer Anwendung gibt es einige verschiedene Bildschirme, die nach dem Backend-Prinzip erstellt werden: Eine vollständige Beschreibung des Bildschirms sowie der Daten stammt vom Server.

Die meisten Bildschirme enthalten verschiedene Eingabeformulare. Der Server bestimmt, welche Felder sich im Formular befinden und wie sie formatiert werden sollen. Zur Beschreibung dieser Anforderungen werden auch Masken verwendet.
Mal sehen, wie die Masken funktionieren.
Beispiele für Masken in verschiedenen Formaten
Nehmen wir als erstes Beispiel die gleiche Form der Eingabe einer Telefonnummer. Die Maske für eine solche Form könnte so aussehen.

Einerseits fügt die Maske selbst Trennzeichen und Klammern hinzu und verhindert die Eingabe falscher Zeichen. Andererseits extrahiert dieselbe Maske nützliche Informationen aus der formatierten Eingabe, die an den Server gesendet werden soll.
Der als Konstante bezeichnete Teil wird rot hervorgehoben. Dies sind Symbole, die automatisch angezeigt werden - der Benutzer sollte sie nicht eingeben:

Als nächstes kommt der dynamische Teil - er ist immer in spitzen Klammern eingeschlossen:

Weiter im Text werde ich diesen Ausdruck "dynamischer Ausdruck" nennen - oder kurz DW
Hier ist der Ausdruck, mit dem wir unsere Eingabe formatieren:

Teile, die für den Inhalt des dynamischen Teils verantwortlich sind, werden rot hervorgehoben.
\\ d - eine beliebige Ziffer.
+ - regulärer Repeater: mindestens einmal wiederholen.
$ {3} ist ein Meta-Informationssymbol, das die Anzahl der Wiederholungen angibt. In diesem Fall sollten drei Zeichen vorhanden sein.
Dann bedeutet der Ausdruck \\ d + $ {3}, dass es drei Ziffern geben muss.
In diesem Maskenformat kann es nur einen Repeater innerhalb des dynamischen Teils geben:

Diese Einschränkung trat aus einem Grund auf - jetzt werde ich erklären, warum.
Nehmen wir an, wir haben einen DV, bei dem die Größe fest codiert ist: 4 Elemente. Und wir geben ihm 2 Elemente mit einem Repeater: `<! ^ \\ d + \\ v + $ {4}>`. Die folgenden Kombinationen fallen unter einen solchen DV:
- 1abc
- 12ab
- 123a
Es stellt sich heraus, dass ein solcher DV uns keine eindeutige Antwort gibt, was anstelle des zweiten Zeichens zu erwarten ist: eine Zahl oder ein Buchstabe.
Nehmen Sie die Maske und fügen Sie sie mit Benutzereingaben hinzu. Wir erhalten die formatierte Telefonnummer:

Auf dem Client kann das Format der Masken anders aussehen. In der Eingabemaskenbibliothek von Redmadrobot

sieht die Maske für die Telefonnummer beispielsweise folgendermaßen aus : Sie sieht besser aus und ist leichter zu verstehen.
Es stellt sich heraus, dass die Maske für den Server und die Maske für den Client unterschiedlich geschrieben sind, aber dasselbe tun.

Lassen Sie uns das Problem neu formulieren: Wie man Masken verschiedener Formate kombiniert
Wir müssen diese Masken miteinander kombinieren - oder irgendwie die zweite von einer bekommen.
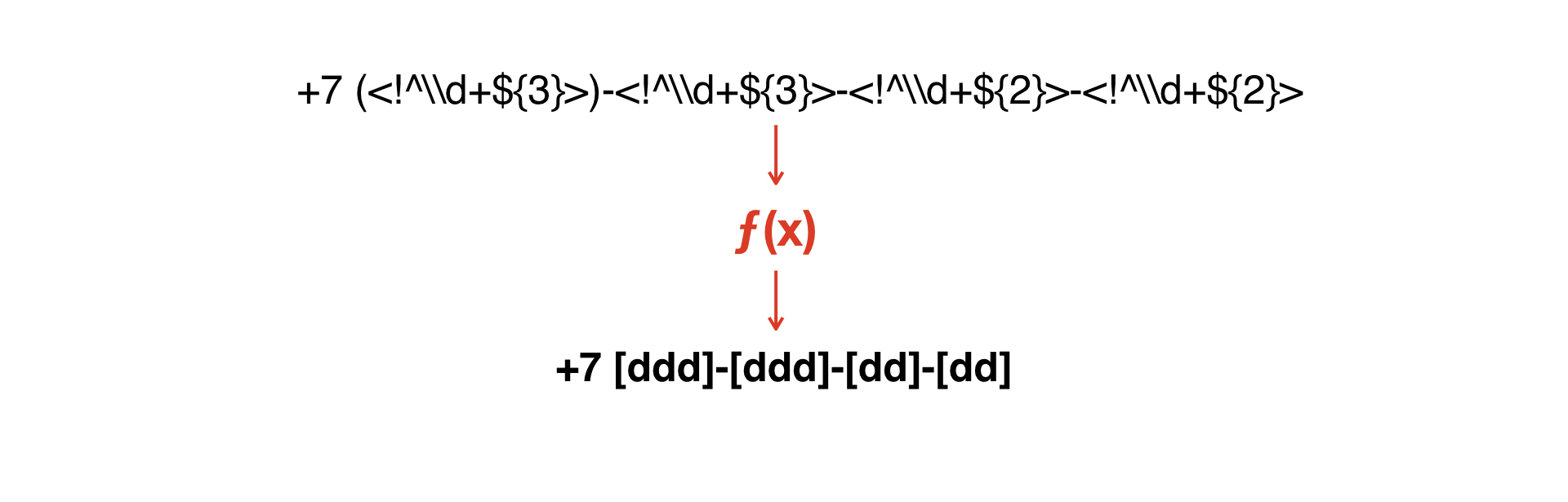
Wir müssen eine Funktion erstellen, die eine Maske in die zweite konvertiert.
Und hier kam die Idee, einen sehr einfachen Interpreter zu schreiben, der es ermöglicht, eine zweite Grammatik aus einer Grammatik zu erhalten.
Lassen Sie uns über Grammatiken sprechen, seit wir beim Dolmetscher angekommen sind.
Wie wird analysiert?
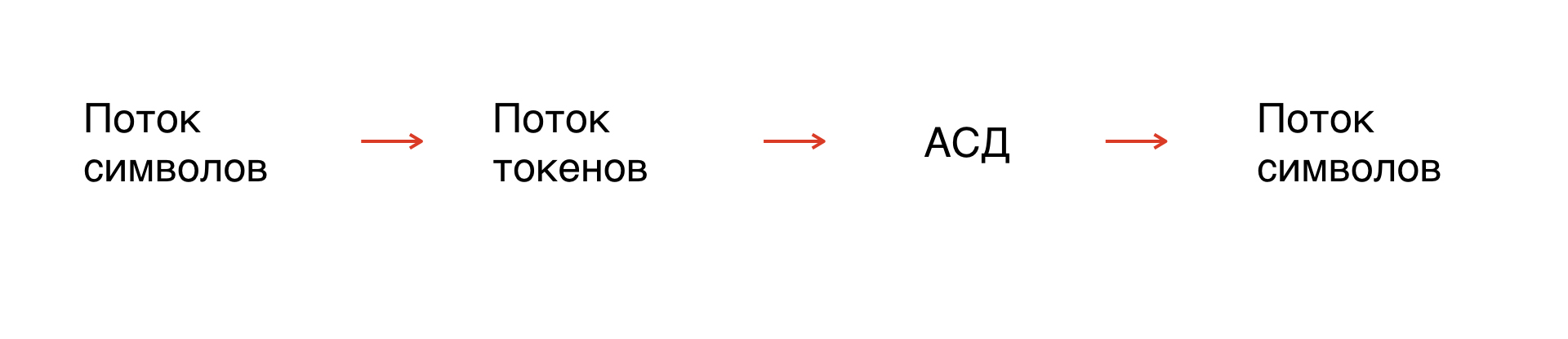
Erstens haben wir einen Strom von Charakteren - unsere Maske. Tatsächlich ist dies die Zeichenfolge, mit der wir arbeiten. Da die Symbole jedoch nicht formalisiert sind, müssen Sie die Zeichenfolge formalisieren: Teilen Sie sie in Elemente auf, die für den Interpreter verständlich sind.
Dieser Vorgang wird als Tokenisierung bezeichnet: Aus einem Strom von Symbolen wird ein Strom von Token. Die Anzahl der Token ist begrenzt, sie sind formalisiert und können daher analysiert werden.
Basierend auf den Grammatikregeln erstellen wir einen abstrakten Syntaxbaum entlang des Token-Flusses. Vom Baum erhalten wir einen Strom von Symbolen in der Grammatik, die wir brauchen.
Es gibt einen Ausdruck. Wir schauen es uns an und sehen, dass wir eine Konstante haben, über die ich oben gesprochen habe: Wir

repräsentieren alle Konstanten als CS-Token, dessen Argument die Konstante selbst ist:

Die nächste Art von Token ist der Anfang des DW:

Ferner werden alle diese Token als Sonderzeichen interpretiert. In unserem Beispiel gibt es nicht viele von ihnen, in echten Masken kann es viel mehr von ihnen geben.

Dann haben wir einen Repeater.
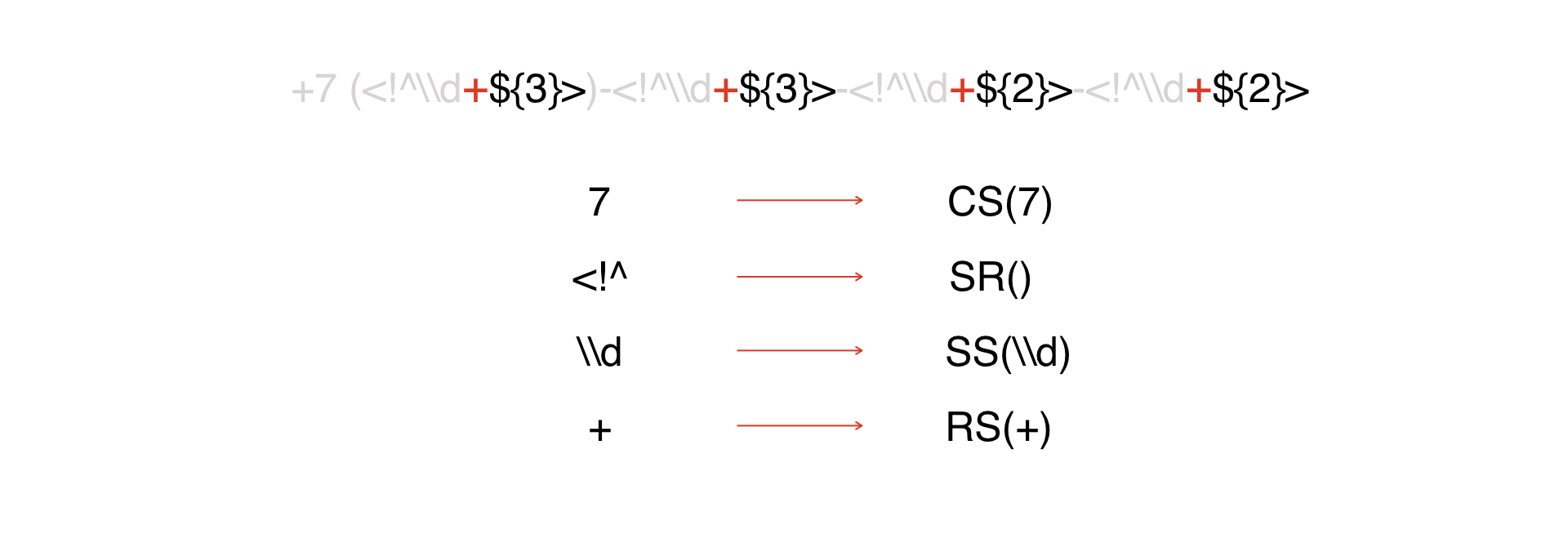
Dann - ein paar Zeichen, die als Metadaten gelten. Wir werden sie betrügen und als ein Zeichen darstellen, weil es auf diese Weise einfacher ist.

Ende des Fernen Ostens. So haben wir alles in Token zerlegt.

Ein Beispiel für das Tokenisieren einer Maske für eine Telefonnummer
Um zu sehen, wie der Tokenisierungsprozess im Prinzip abläuft und wie der Interpreter funktioniert, nehmen wir eine Maske für eine Telefonnummer und wandeln sie in einen Strom von Token um.

Zuerst das + Symbol. In Konstante + konvertieren. Dann machen wir dasselbe für die 7 und für alle anderen Symbole. Wir bekommen eine Reihe von Token. Dies ist noch keine Struktur - wir werden dieses Array weiter analysieren.
Lexer und Gebäude ASD
Jetzt ist der schwierige Teil der Lexer.

Links wird eine Legende beschrieben - Sonderzeichen, mit denen lexikalische Regeln beschrieben werden. Rechts sind die Regeln selbst.
Die symbolRule beschreibt ein Symbol. Wenn diese Regel zutrifft, bedeutet dies, dass wir entweder auf ein Sonderzeichen oder ein konstantes Zeichen gestoßen sind. Wir können sagen, dass dies eine Funktion ist.
Als nächstes kommt repeaterRule. Diese Regel beschreibt eine Situation, in der ein Zeichen angetroffen wird, gefolgt von einem Repeater-Token.
Dann sieht alles ähnlich aus. Wenn es LW ist, ist es entweder ein Symbol oder ein Repeater. In unserem Fall ist diese Regel weiter gefasst. Und am Ende muss es ein Token mit Metadaten geben.
Die letzte Regel ist maskRule. Dies ist eine Folge von Symbolen und DV.
Jetzt bauen wirEin abstrakter Syntaxbaum (AST) aus einem Array von Token.
Hier ist eine Liste von Token. Der erste Knoten des Baums ist der Wurzelknoten, von dem aus wir mit dem Aufbau beginnen werden. Es macht keinen Sinn, es braucht nur eine Wurzel.

Wir haben das erste Token +, was bedeutet, dass wir nur einen untergeordneten Knoten hinzufügen und das wars.

Wir machen dasselbe mit allen anderen konstanten Symbolen, aber dann ist es komplizierter. Wir sind auf einen DV-Token gestoßen.

Dies ist nicht nur eine reguläre Website - wir wissen, dass sie Inhalte enthalten muss.

Der Inhaltsknoten ist nur ein technischer Knoten, zu dem wir in Zukunft navigieren können. Es hat seine eigenen untergeordneten Knoten und welchen Knoten wird es als nächstes haben? Das nächste Token in unserem Stream ist ein Sonderzeichen. Wird es ein untergeordneter Knoten sein?

Eigentlich in diesem Fall nein. Wir werden einen Repeater als untergeordneten Knoten haben.

Warum? Weil es in Zukunft bequemer ist, mit Holz zu arbeiten. Angenommen, wir möchten diesen Baum analysieren und daraus eine Art Grammatik erstellen. Beim Parsen eines Baums betrachten wir die Knotentypen. Wenn wir einen CS-Knoten haben, analysieren wir ihn in denselben CS-Knoten, jedoch für eine andere Grammatik. Konventionell iterieren wir über die Baumkronen und führen eine Art Logik aus.
Die Logik hängt vom Knotentyp ab - oder vom Token-Typ, der im Knoten liegt. Zum Parsen ist es viel bequemer, sofort zu verstehen, welches Token vor Ihnen liegt: Composite wie ein Repeater oder einfach wie CS. Dies ist erforderlich, damit keine doppelten Interpretationen oder ständigen Suchen nach untergeordneten Knoten erfolgen.
Dies würde sich insbesondere bei Zeichengruppen bemerkbar machen: zum Beispiel [abcde]. In diesem Fall muss es offensichtlich eine Art übergeordneten GROUP-Knoten geben, der eine Liste der untergeordneten Knoten CS (a) CS (b) usw. enthält.
Zurück zum Token mit Metadaten. Es ist nicht im Inhalt enthalten, es ist auf der Seite.

Dies ist notwendig, um die Arbeit mit dem Baum zu vereinfachen, damit wir diesen Knoteninhalt nicht berücksichtigen - da er tatsächlich nicht dazu gehört.
Der DV wurde beendet, und wir betrachten ihn nicht als eine Art Knoten: Es war ein Token, der jetzt weggeworfen werden kann. Wir werden es nicht in einen Baumknoten verwandeln.
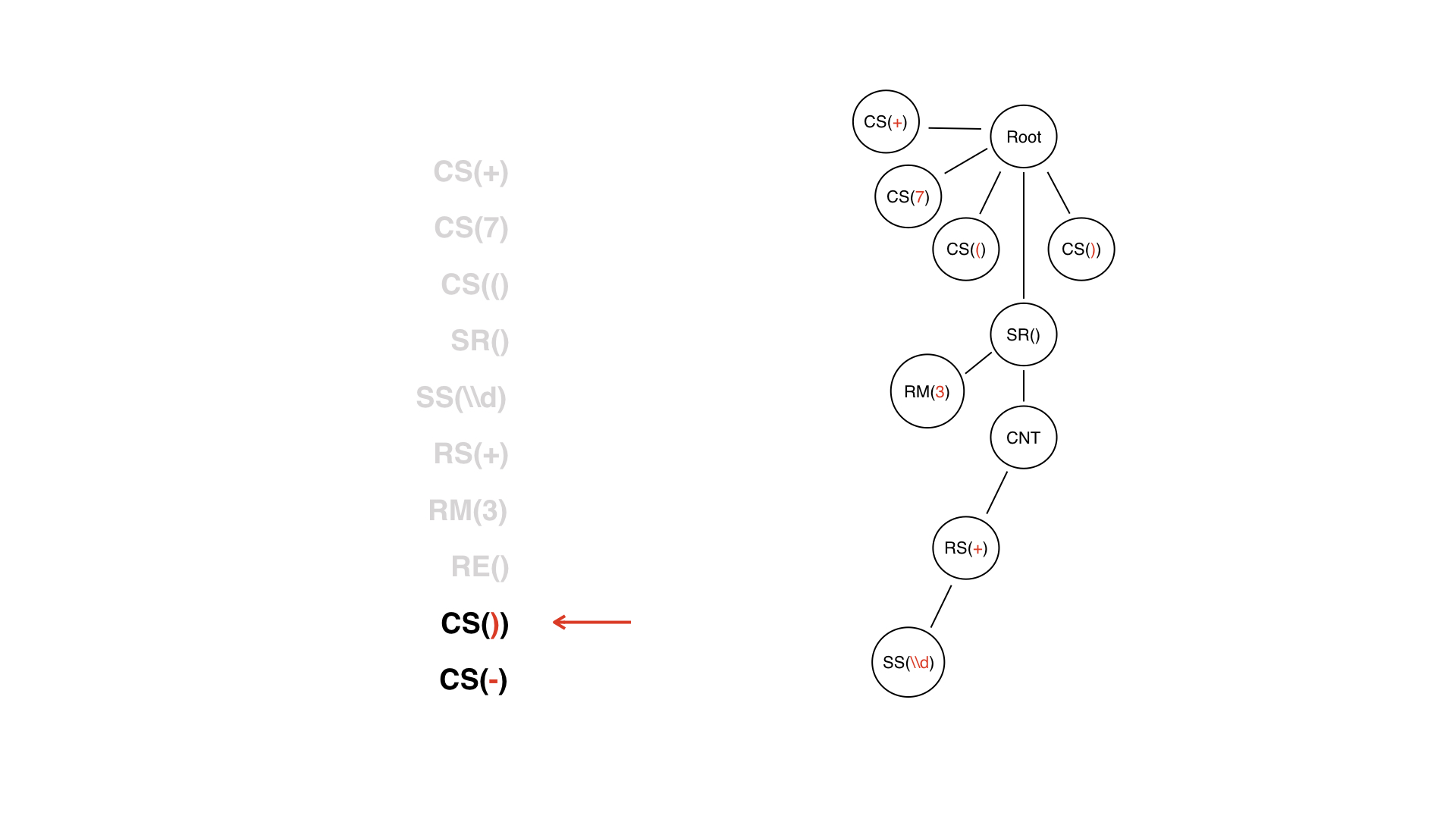
Wir haben bereits einen Teilbaum, dessen Wurzel der SR-Knoten ist - das heißt der sehr dynamische Teil. Das LW-End-Token hilft uns sehr beim Erstellen von Bäumen - wir können verstehen, wann der Teilbaum für LW fertig ist. Dieses Token hat jedoch keinen Wert für die Logik: Wenn wir uns einen zeilenweisen Baum ansehen, wissen wir bereits, wann der DW enden wird, da er sozusagen vom SR-Knoten geschlossen wird.
Weiter - nur gewöhnliche konstante Symbole.

Wir haben einen Baum. Lassen Sie uns nun diesen Baum ausführlich durchgehen und auf seiner Grundlage eine andere Grammatik erstellen: Sie müssen in einen Knoten gehen, sehen, um welche Art von Knoten es sich handelt, und aus diesem Knoten ein Element einer anderen Grammatik generieren.
Syntax der InputMask-Bibliothek von Redmadrobot
Schauen wir uns die Syntax der Redmadrobot-Bibliothek an.

Hier ist der gleiche Ausdruck. +7 ist eine Konstante, die automatisch hinzugefügt wird. In den geschweiften Klammern wird der DV beschrieben - der dynamische Teil. Im DV befindet sich ein Sonderzeichen d. Redmadrobot hat diese Standardnotation, die eine Ziffer bezeichnet.
So sieht die Notation aus:

Die Notation besteht aus drei Teilen:
- Zeichen ist das Zeichen, mit dem wir die Maske schreiben. Woraus das Maskenalphabet besteht. Zum Beispiel d.
- CharacterSet - Welche vom Benutzer eingegebenen Zeichen stimmen mit dieser Notation überein. Zum Beispiel 0, 1, 2, 3, 4 und so weiter.
- isOptional - Gibt an, ob der Benutzer eines der Zeichen setzen muss oder nicht.
Schauen Sie, wir werden jetzt eine solche Maske haben.

- Das Zeichen "b" hat eine spezielle Ziffernschreibweise und ist nicht optional.
- Zeichen "c" hat eine andere Notation - CharacterSet ist anders. Es ist auch nicht optional.
- Und das Zeichen "C" ist dasselbe wie "c", nur ist es optional. Dies ist notwendig, damit wir in der Maske die Metadaten betrachten und feststellen, dass es keine feste, sondern eine schwache Grenze gibt.
Wenn Sie eine Regel schreiben müssen, wenn ein bis zehn Zeichen vorhanden sein können, ist ein Zeichen nicht optional. Und neun Zeichen sind optional. Das heißt, in der Notation aus dem Beispiel werden sie in Großbuchstaben geschrieben. Infolgedessen sieht diese Regel folgendermaßen aus: [cCCCCCCCCC]
Beispiel: Übersetzen der Telefonnummernmaske vom Backend-Format in das InputMask-Format
Hier ist der Baum, den wir im letzten Schritt bekommen haben. Wir müssen darauf gehen. Das erste, was wir erreichen, ist die Wurzel.

Weiter von der Wurzel entfernt befinden wir uns im konstanten Symbol + - wir erzeugen sofort +. Rechts wird eine Maske im InputMask-Format geschrieben.

Das nächste Zeichen ist verständlich - nur 7, gefolgt von einer offenen Klammer.
Dann wird ein Teil des dynamischen Teils erzeugt, der jedoch noch nicht gefüllt ist.

Wir gehen hinein, wir haben Inhalt, dies ist ein technischer Knoten. Wir schreiben nirgendwo etwas.

Hier haben wir einen Repeater, wir schreiben auch nirgendwo etwas, weil es kein solches Symbol in der Maske gibt. Eine solche Regel kann nicht niedergeschrieben werden.

Schließlich kommen wir zu einer Art Inhaltssymbol.
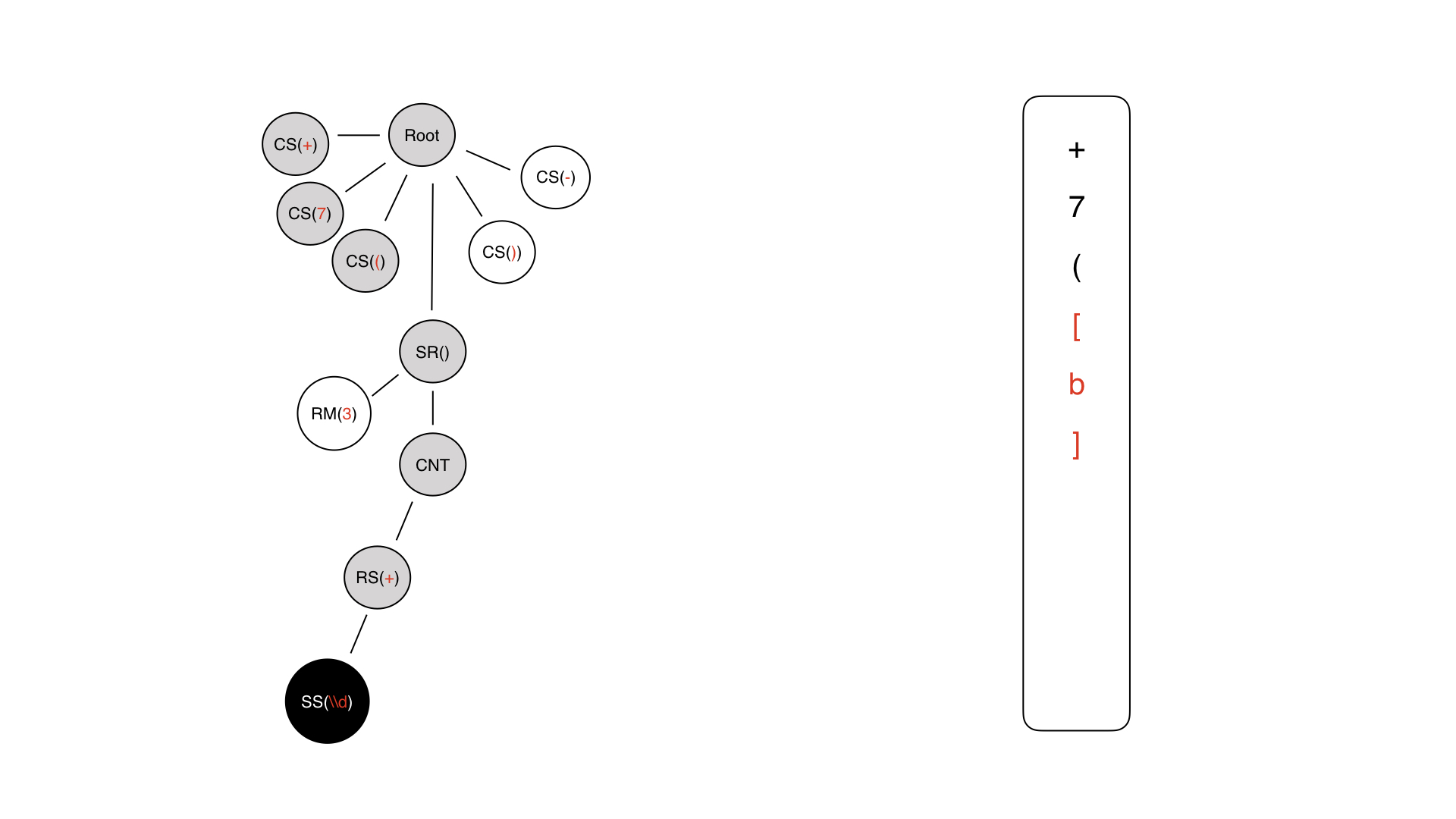
Das Inhaltssymbol kann entweder ein konstantes Symbol oder ein spezielles Symbol sein. In diesem Fall wird eine spezielle verwendet, da nur diese eine semantische Last für die Eingabe trägt.
Also haben wir es geschrieben, wir kommen zurück und gehen nur für die Metainformationen.

Mal sehen, dass wir dort einen Repeater hatten und hier haben wir 3 - eine harte Grenze. Deshalb wiederholen wir es dreimal und erhalten ein so dynamisches Stück. Als nächstes fügen wir unsere konstanten Symbole hinzu.

Als Ergebnis erhalten wir eine Maske, die im Roboterformat wie eine Maske aussieht.
In der Praxis haben wir eine Grammatik genommen und daraus eine andere Grammatik generiert.
Regeln zum Generieren der clientseitigen Grammatik vom Server
Nun ein wenig zu den Generierungsregeln. Es ist wichtig.
Es kann so schwierige Fälle geben: Innerhalb des dynamischen Teils gibt es mehrere verschiedene Teile von DW. In geschweiften Klammern: Dies ist das gleiche wie bei DV - eine von vielen. Mal sehen, wie der Dolmetscher mit dieser Situation umgeht.

Zuerst kommt der Zeichensatz, und wir müssen ihn in eine Art Notation in Bezug auf InputMask konvertieren. Warum? Weil dies eine Art begrenzter Zeichensatz ist, den wir abgleichen müssen. Wir müssen Benutzereingaben und Zeichen kombinieren, daher werden wir hier eine bestimmte Notation schreiben.
Als nächstes haben wir das Zeichen \\ d.
Weiter - DV mit optionaler Größe.

Das erste ist, wie sich herausstellt, ein Zeichen b. Es wird einen Zeichensatz mit abcd haben.
Außerdem ist klar, dass es bereits ein anderes Symbol gibt, da Sie es nicht anders oder falsch patchen. Und dann haben wir diesen Ausdruck, der sich in so etwas verwandelt.
Der letzte Teil muss mindestens ein Symbol enthalten. Bezeichnen wir diese Anforderung als d. Der Benutzer kann aber auch zwei zusätzliche Zeichen eingeben, die dann als DD bezeichnet werden.
Alles zusammenfügen.

Hier ist ein Beispiel für die generierten Zeichensätze. Es ist ersichtlich, dass b dem Zeichensatz abcd für Zahlen entspricht - dem entsprechenden voreingestellten Zeichensatz. Für d und D enthält der entsprechende Zeichensatz 12vf.
Ergebnis
Wir haben gelernt, eine Grammatik automatisch in eine andere zu konvertieren: Jetzt arbeiten Masken gemäß der Serverspezifikation in unserer Anwendung.
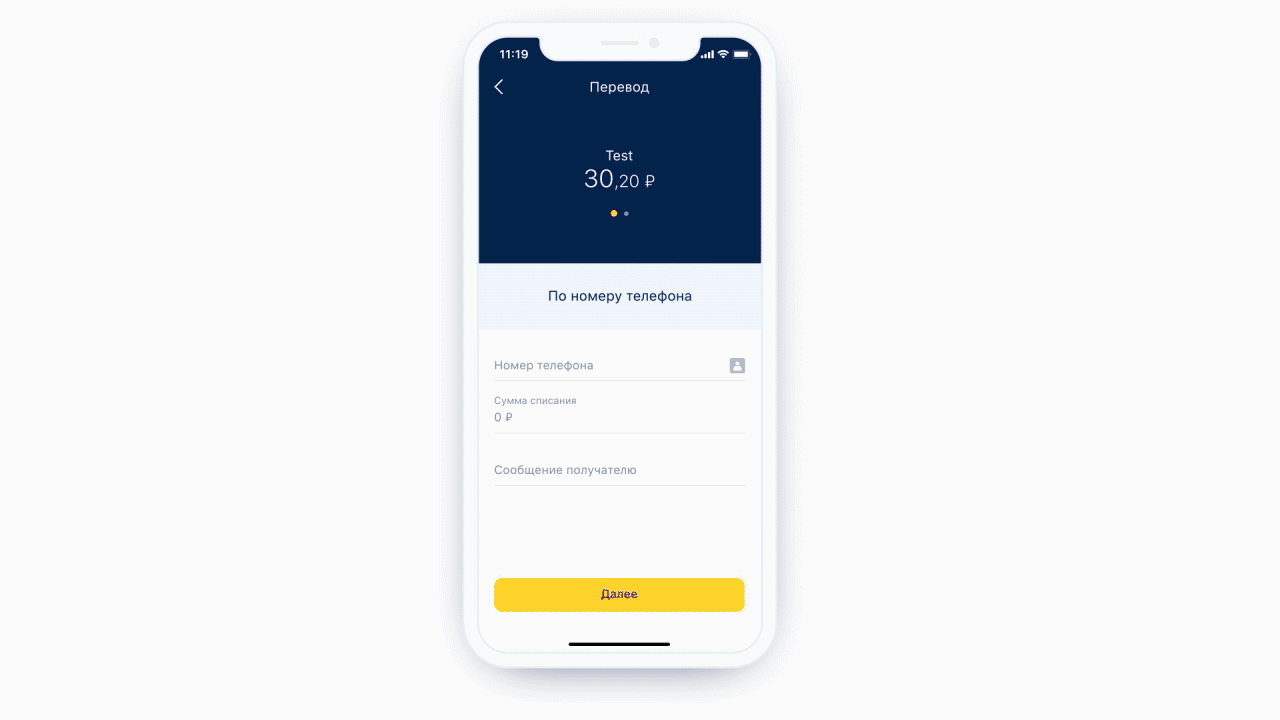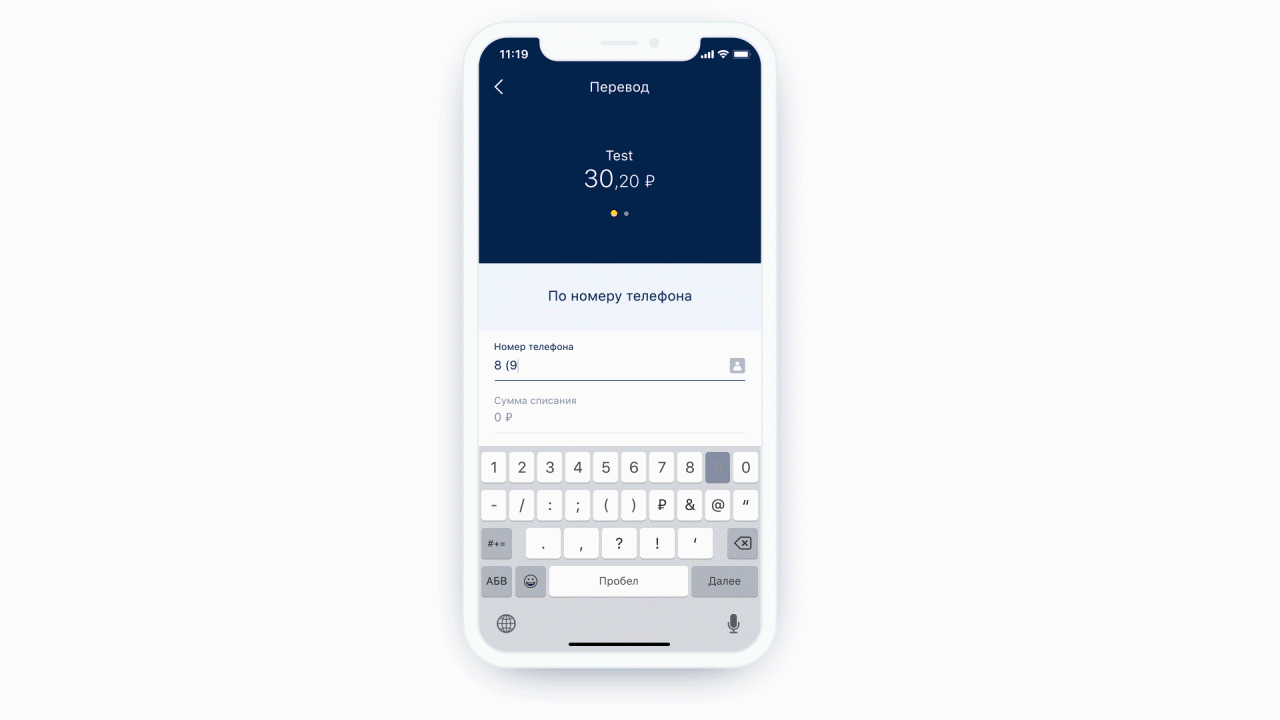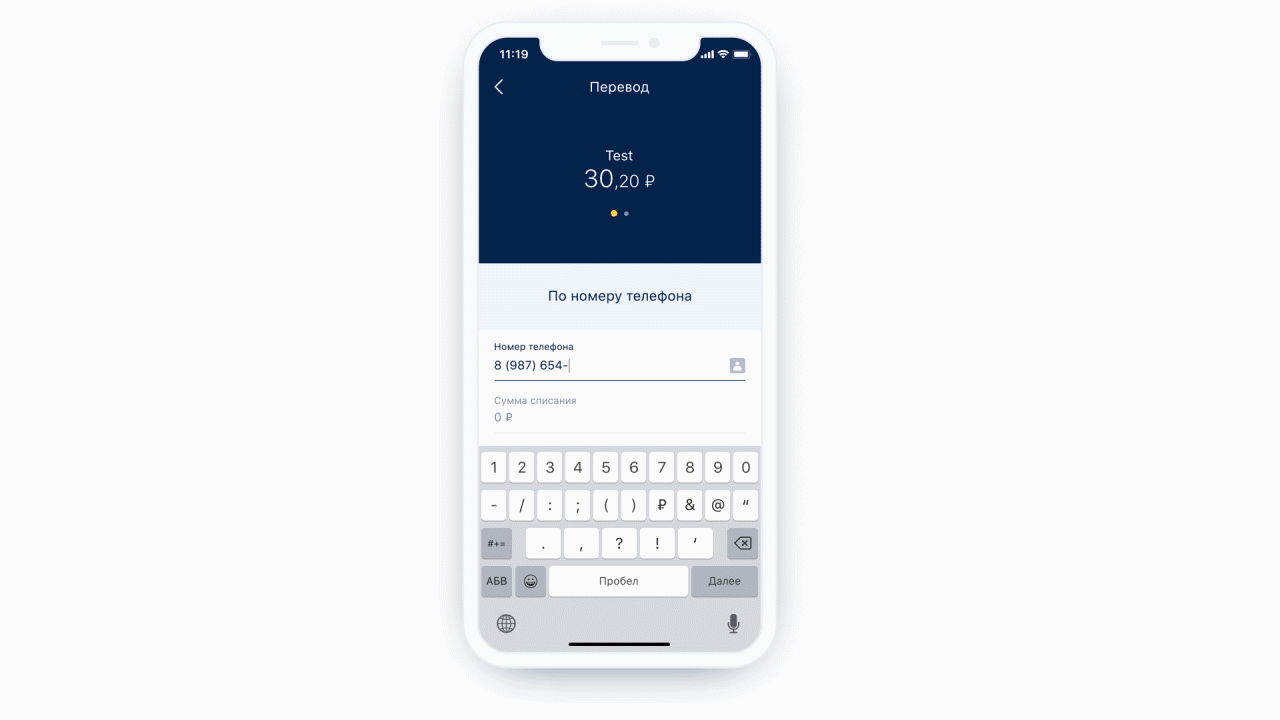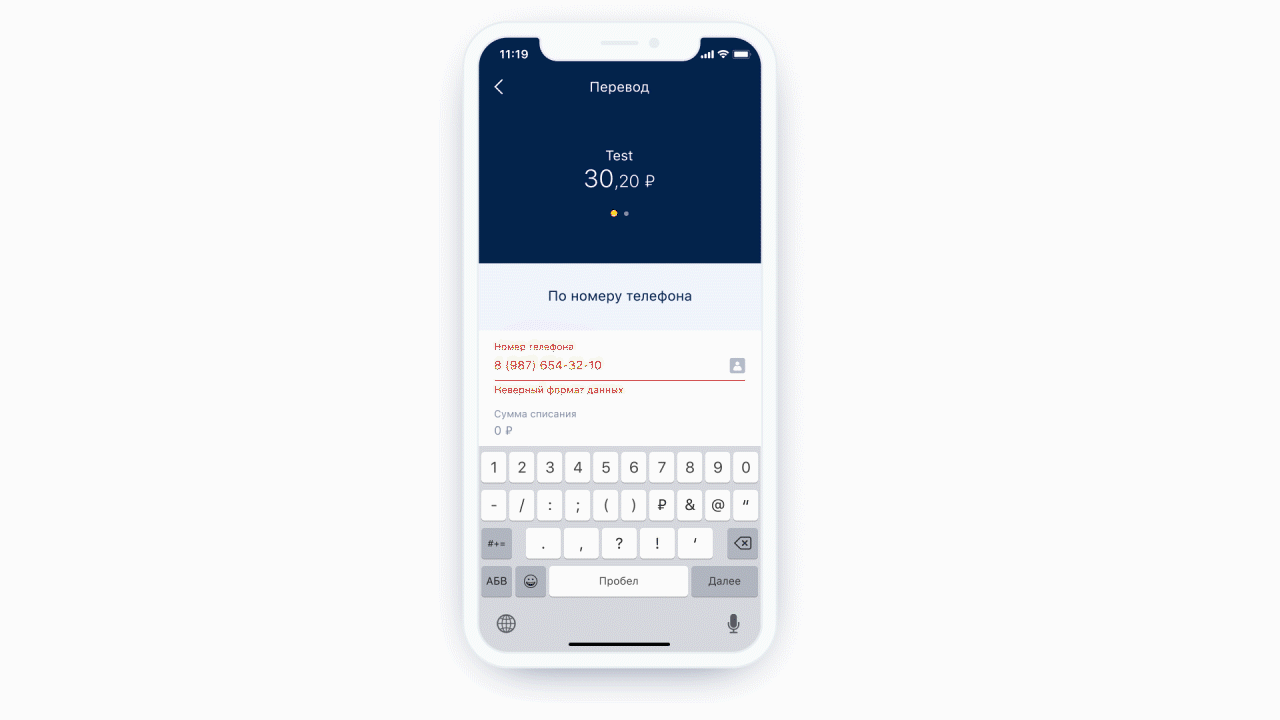
Ein weiteres kostenloses Feature ist die Möglichkeit, eine statische Analyse der Maske durchzuführen, die zu uns gekommen ist. Das heißt, wir können verstehen, welcher Tastaturtyp für diese Maske benötigt wird und wie viele Zeichen maximal in dieser Maske enthalten sein können. Und es ist noch cooler, weil wir jetzt nicht immer die gleiche Tastatur für jedes Formularelement anzeigen - wir zeigen die erforderliche Tastatur unter dem erforderlichen Formularelement. Außerdem können wir unter bestimmten Bedingungen genau definieren, dass ein Feld ein Telefoneingabefeld ist.
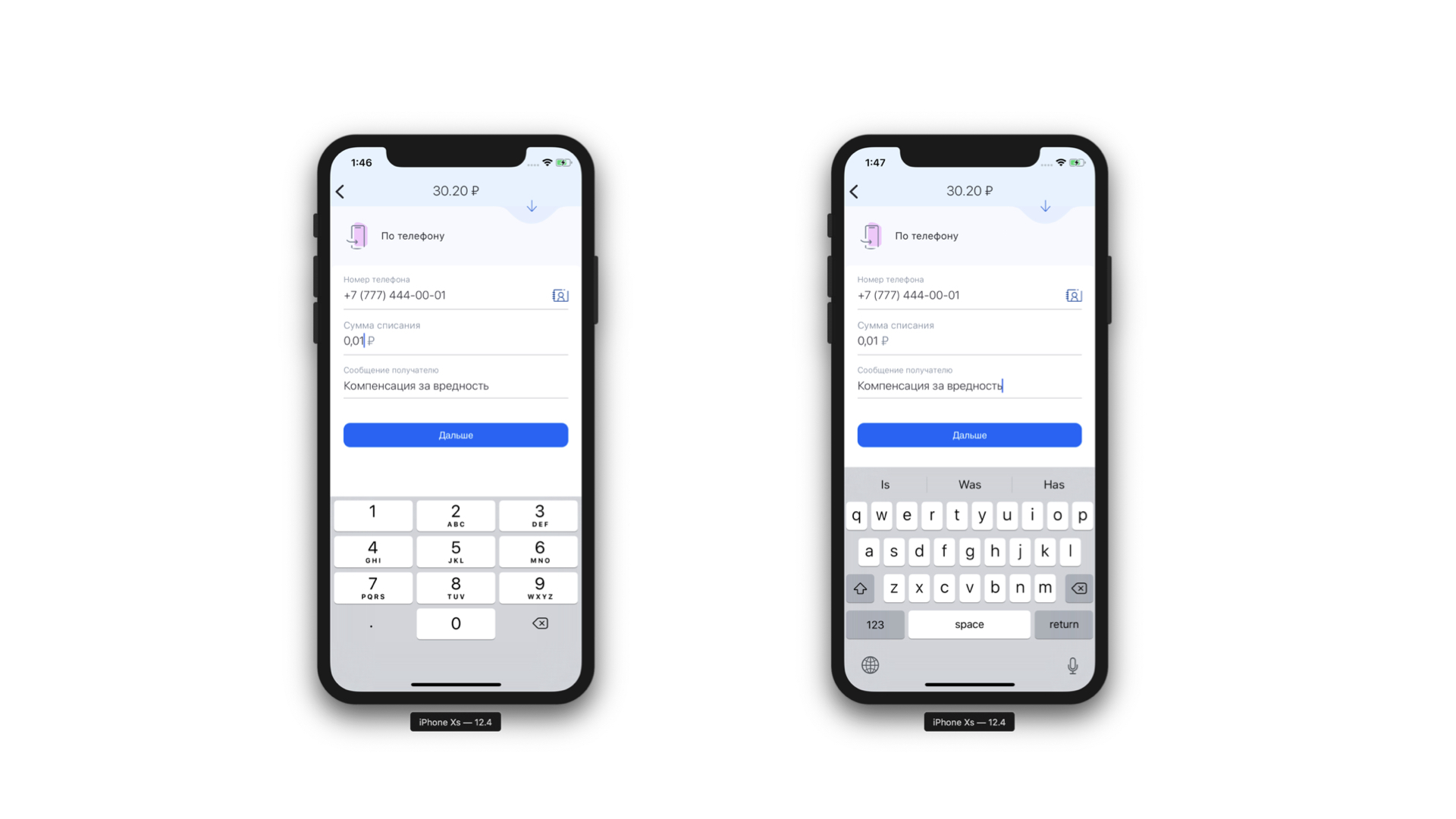
Links: Oben im Eingabefeld des Telefons befindet sich ein Symbol (eigentlich eine Schaltfläche), das den Benutzer zur Kontaktliste sendet. Rechts: Beispiel einer Tastatur für eine normale Textnachricht.
Arbeitsbibliothek zum Übersetzen von Masken
Sie können sich ansehen, wie wir den oben genannten Ansatz umgesetzt haben. Die Bibliothek befindet sich auf Github .
Beispiele für die Übersetzung verschiedener Masken
Dies ist die erste Maske, die wir uns am Anfang angesehen haben. Es wird in diese RedMadRobot-Darstellung interpretiert.

Und dies ist die zweite Maske - nur eine Eingabemaske für etwas. Es wird in eine solche Darstellung umgewandelt.
