Inspiriert von dem Vortrag präsentiert dieser Artikel einen Ansatz zur Vereinfachung des Erstellungsprozesses von Operatoren für Kubernetes und zeigt Ihnen, wie Sie mit minimalem Aufwand eigene Operatoren mit einem Shell-Operator erstellen können.

Wir präsentieren das Video mit dem Bericht (~ 23 Minuten auf Englisch, viel informativer als der Artikel) und dem Hauptauszug daraus in Textform. Gehen!
Bei Flant optimieren und automatisieren wir ständig alles. Heute werden wir über ein weiteres spannendes Konzept sprechen. Lernen Sie Cloud-native Shell-Skripte kennen !
Beginnen wir jedoch mit dem Kontext, in dem all dies geschieht - Kubernetes.
Kubernetes API und Controller
API in Kubernetes kann als eine Art Dateiserver mit Verzeichnissen für jeden Objekttyp dargestellt werden. Objekte (Ressourcen) auf diesem Server werden durch YAML-Dateien dargestellt. Darüber hinaus verfügt der Server über eine grundlegende API, mit der drei Aufgaben ausgeführt werden können:
- Holen Sie sich eine Ressource nach Art und Namen.
- Ändern Sie die Ressource (in diesem Fall speichert der Server nur "richtige" Objekte - alle falsch geformten oder für andere Verzeichnisse bestimmten Objekte werden verworfen).
- ( / ).
Somit fungiert Kubernetes als eine Art Dateiserver (für YAML-Manifeste) mit drei grundlegenden Methoden (ja, tatsächlich gibt es andere, aber wir werden sie vorerst weglassen).

Das Problem ist, dass der Server nur Informationen speichern kann. Damit es funktioniert, benötigen Sie einen Controller - das zweitwichtigste und grundlegendste Konzept in der Kubernetes-Welt.
Es gibt zwei Haupttypen von Controllern. Der erste nimmt Informationen von Kubernetes, verarbeitet sie gemäß der verschachtelten Logik und gibt sie an K8s zurück. Der zweite bezieht Informationen von Kubernetes, ändert jedoch im Gegensatz zum ersten Typ den Status einiger externer Ressourcen.
Schauen wir uns den Prozess zum Erstellen einer Bereitstellung in Kubernetes genauer an:
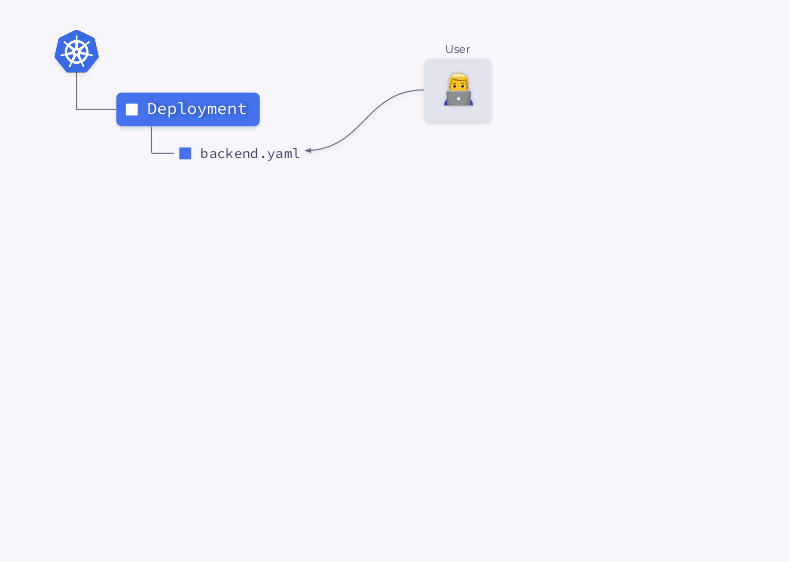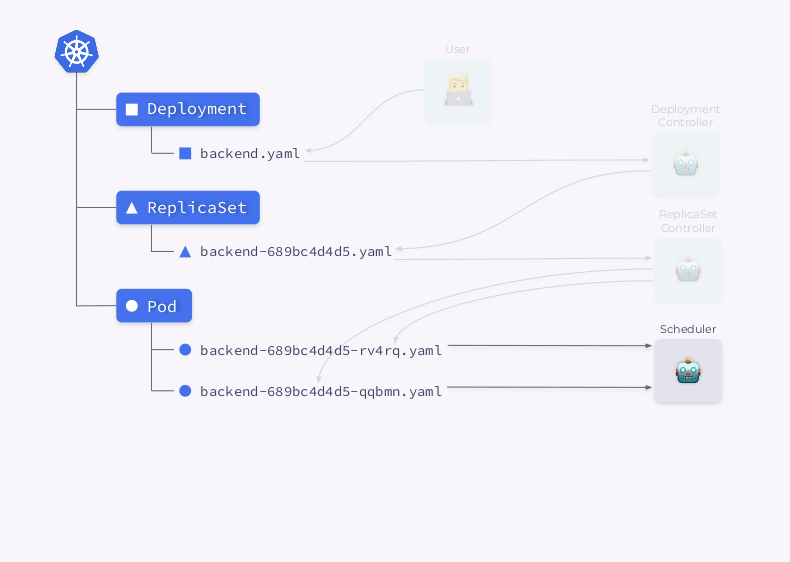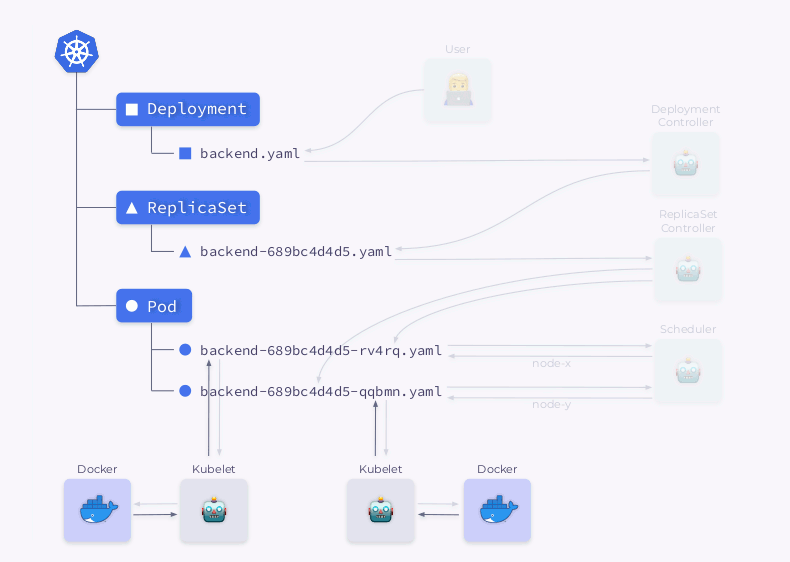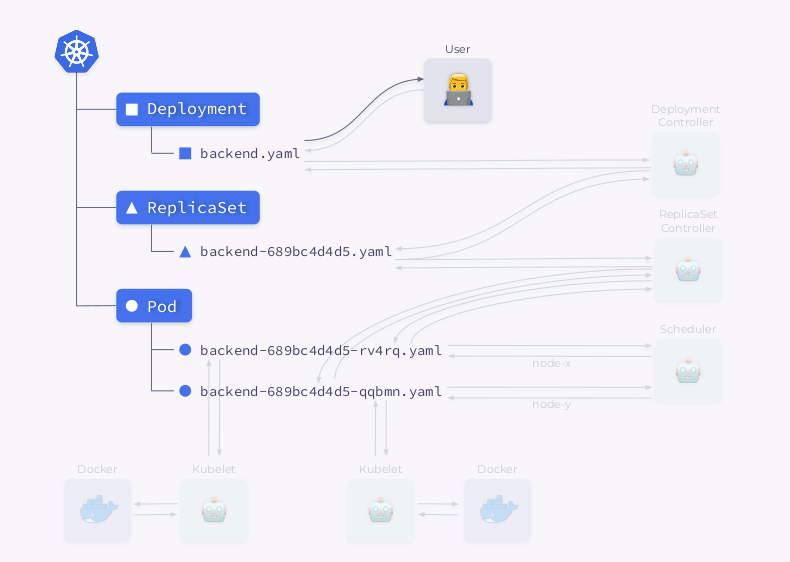
- Der Deployment Controller (enthalten in
kube-controller-manager) empfängt Informationen zur Bereitstellung und erstellt ein ReplicaSet. - ReplicaSet erstellt basierend auf diesen Informationen zwei Replikate (zwei Pods), diese Pods sind jedoch noch nicht geplant.
- Der Scheduler plant Pods und fügt ihren YAMLs Knoteninformationen hinzu.
- Kubelets nehmen Änderungen an einer externen Ressource vor (z. B. Docker).
Dann wird diese ganze Sequenz in umgekehrter Reihenfolge wiederholt: kubelet überprüft die Container, berechnet den Status des Pods und sendet ihn zurück. Der ReplicaSet-Controller erhält den Status und aktualisiert den Status des Replikatsatzes. Dasselbe passiert mit dem Deployment Controller, und der Benutzer erhält schließlich einen aktualisierten (aktuellen) Status.
Shell-Operator
Es stellt sich heraus, dass Kubernetes auf der Zusammenarbeit verschiedener Controller basiert (Kubernetes-Betreiber sind auch Controller). Es stellt sich die Frage, wie Sie mit minimalem Aufwand einen eigenen Operator erstellen können. Und hier kommt der von uns entwickelte Shell-Operator zur Rettung . Systemadministratoren können mit vertrauten Methoden ihre eigenen Anweisungen erstellen.

Einfaches Beispiel: Geheimnisse kopieren
Schauen wir uns ein einfaches Beispiel an.
Angenommen, wir haben einen Kubernetes-Cluster. Es hat einen Namespace
defaultmit einem Geheimnis mysecret. Darüber hinaus gibt es weitere Namespaces im Cluster. Einige von ihnen haben ein spezielles Etikett. Unser Ziel ist es, Secret in Namespaces mit einem Label zu kopieren.
Die Aufgabe wird durch die Tatsache erschwert, dass möglicherweise neue Namespaces im Cluster angezeigt werden und einige von ihnen möglicherweise diese Bezeichnung haben. Andererseits muss beim Löschen eines Etiketts auch Secret gelöscht werden. Zusätzlich zu allem kann sich auch das Geheimnis selbst ändern: In diesem Fall muss das neue Geheimnis in alle Namespaces mit Beschriftungen kopiert werden. Wenn Secret versehentlich in einem Namespace gelöscht wird, sollte unser Operator es sofort wiederherstellen.
Nachdem die Aufgabe formuliert wurde, ist es Zeit, sie mit dem Shell-Operator zu implementieren. Aber zuerst lohnt es sich, ein paar Worte über den Shell-Operator selbst zu sagen.
Wie der Shell-Operator funktioniert
Wie andere Workloads in Kubernetes wird der Shell-Operator in seinem Pod ausgeführt. Dieser Pod
/hooksenthält ausführbare Dateien im Verzeichnis . Dies können Skripte in Bash, Python, Ruby usw. sein. Wir nennen diese ausführbaren Dateien Hooks .

Der Shell-Operator abonniert Kubernetes-Ereignisse und löst diese Hooks als Reaktion auf alle Ereignisse aus, die wir benötigen.

Woher weiß der Shell-Operator, welcher Hook wann ausgeführt werden soll? Der Punkt ist, dass jeder Haken zwei Stufen hat. Beim Start führt der Shell-Operator alle Hooks mit einem Argument aus
--config- dies ist die Konfigurationsphase. Und danach werden die Hooks auf normale Weise gestartet - als Reaktion auf die Ereignisse, mit denen sie verbunden sind. Im letzteren Fall empfängt der Hook den Bindungskontext) - Daten im JSON-Format, auf die wir weiter unten näher eingehen werden.
Den Operator in Bash machen
Wir sind jetzt bereit für die Implementierung. Dazu müssen wir zwei Funktionen schreiben (wir empfehlen übrigens die Bibliothek shell_lib , die das Schreiben von Hooks in Bash erheblich vereinfacht):
- Die erste wird für die Konfigurationsphase benötigt - sie zeigt den Bindungskontext an.
- Die zweite enthält die Hauptlogik des Hooks.
#!/bin/bash
source /shell_lib.sh
function __config__() {
cat << EOF
configVersion: v1
# BINDING CONFIGURATION
EOF
}
function __main__() {
# THE LOGIC
}
hook::run "$@"
Der nächste Schritt besteht darin, zu entscheiden, welche Objekte wir benötigen. In unserem Fall müssen wir verfolgen:
- geheime Quelle für Änderungen;
- alle Namespaces im Cluster, damit Sie wissen, an welche von ihnen das Label angehängt ist;
- Zielgeheimnisse, um sicherzustellen, dass sie alle mit dem Quellgeheimnis synchron sind.
Abonnieren Sie eine geheime Quelle
Die Bindungskonfiguration ist für ihn einfach genug. Wir geben an, dass wir an Secret mit einem Namen
mysecretim Namespace interessiert sind default:

function __config__() {
cat << EOF
configVersion: v1
kubernetes:
- name: src_secret
apiVersion: v1
kind: Secret
nameSelector:
matchNames:
- mysecret
namespace:
nameSelector:
matchNames: ["default"]
group: main
EOF
Infolgedessen wird der Hook ausgeführt, wenn sich das Quellgeheimnis (
src_secret) ändert und den folgenden Bindungskontext erhält:

Wie Sie sehen können, enthält er den Namen und das gesamte Objekt.
Namespaces im Auge behalten
Jetzt müssen Sie Namespaces abonnieren. Dazu geben wir die folgende Bindungskonfiguration an:
- name: namespaces
group: main
apiVersion: v1
kind: Namespace
jqFilter: |
{
namespace: .metadata.name,
hasLabel: (
.metadata.labels // {} |
contains({"secret": "yes"})
)
}
group: main
keepFullObjectsInMemory: false
Wie Sie sehen können, wurde in der Konfiguration ein neues Feld mit dem Namen jqFilter angezeigt. Wie der Name schon sagt,
jqFilterfiltert es alle unnötigen Informationen heraus und erstellt ein neues JSON-Objekt mit den Feldern, die für uns von Interesse sind. Ein Hook mit dieser Konfiguration erhält den folgenden Bindungskontext:
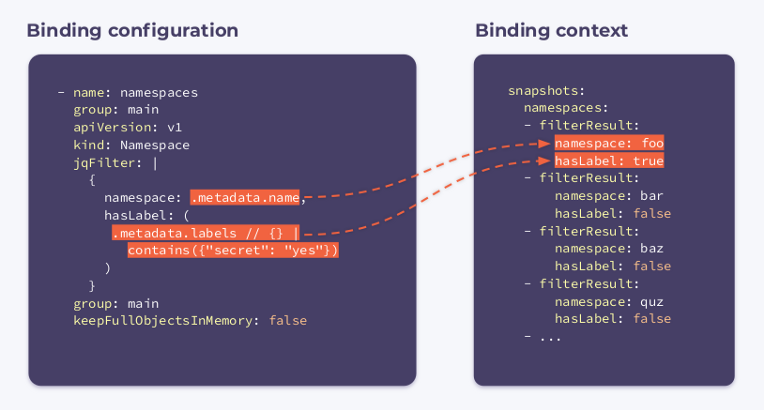
Er enthält ein Array
filterResultsfür jeden Namespace im Cluster. Eine boolesche Variable, die hasLabelangibt, ob die Bezeichnung an den angegebenen Namespace angehängt ist. Der Selektor keepFullObjectsInMemory: falsegibt an, dass keine vollständigen Objekte gespeichert werden müssen.
Geheimnisse-Ziele verfolgen
Wir abonnieren alle Geheimnisse, die eine Anmerkung haben
managed-secret: "yes"(dies sind unsere Ziele dst_secrets):
- name: dst_secrets
apiVersion: v1
kind: Secret
labelSelector:
matchLabels:
managed-secret: "yes"
jqFilter: |
{
"namespace":
.metadata.namespace,
"resourceVersion":
.metadata.annotations.resourceVersion
}
group: main
keepFullObjectsInMemory: false
In diesem Fall
jqFilterwerden alle Informationen mit Ausnahme des Namespace und des Parameters herausgefiltert resourceVersion. Der letzte Parameter wurde beim Erstellen des Geheimnisses an die Anmerkung übergeben: Sie können Versionen von Geheimnissen vergleichen und auf dem neuesten Stand halten.
Ein auf diese Weise konfigurierter Hook empfängt bei Ausführung die drei oben beschriebenen Bindungskontexte. Stellen Sie sich diese als eine Art Momentaufnahme des Clusters vor.

Basierend auf all diesen Informationen kann ein grundlegender Algorithmus entwickelt werden. Es iteriert über alle Namespaces und:
- falls
hasLabelrelevanttruefür den aktuellen Namespace:- vergleicht das globale Geheimnis mit dem lokalen:
- wenn sie gleich sind, tut es nichts;
- wenn sie sich unterscheiden, ausführen
kubectl replaceodercreate;
- vergleicht das globale Geheimnis mit dem lokalen:
- falls
hasLabelrelevantfalsefür den aktuellen Namespace:
- stellt sicher, dass sich Secret nicht im angegebenen Namespace befindet:
- Wenn lokales Geheimnis vorhanden ist, löschen Sie es mit
kubectl delete; - Wenn kein lokales Geheimnis gefunden wird, tut es nichts.
- Wenn lokales Geheimnis vorhanden ist, löschen Sie es mit
- stellt sicher, dass sich Secret nicht im angegebenen Namespace befindet:

Sie können die Algorithmusimplementierung in Bash in unserem Repository mit Beispielen herunterladen .
Auf diese Weise konnten wir einen einfachen Kubernetes-Controller mit 35 Zeilen YAML-Konfigurationen und ungefähr der gleichen Menge Bash-Code erstellen! Die Aufgabe des Shell-Operators besteht darin, sie miteinander zu verbinden.
Das Kopieren von Geheimnissen ist jedoch nicht der einzige Anwendungsbereich des Dienstprogramms. Hier sind einige weitere Beispiele, um zu zeigen, wozu er fähig ist.
Beispiel 1: Änderungen an ConfigMap vornehmen
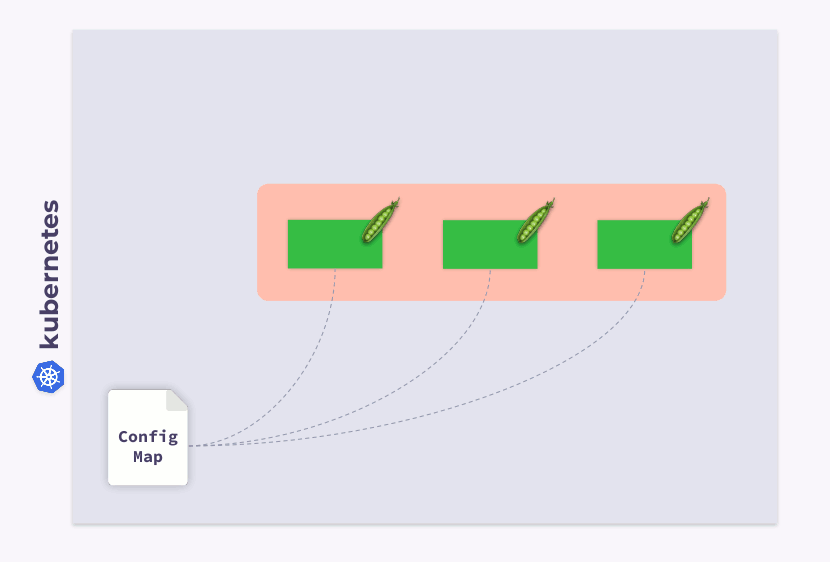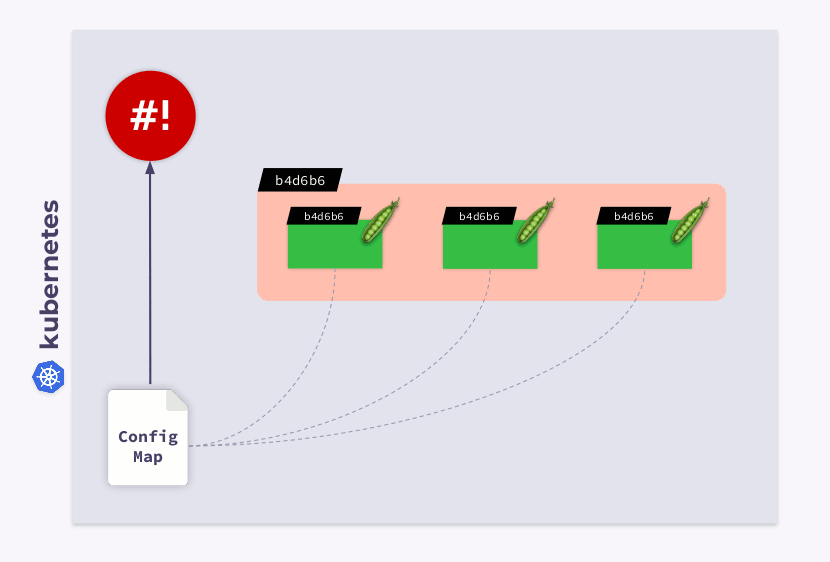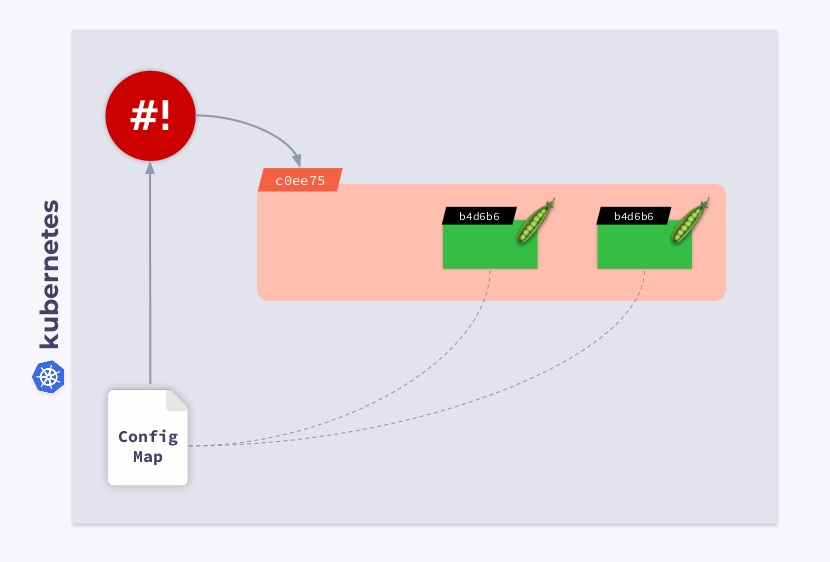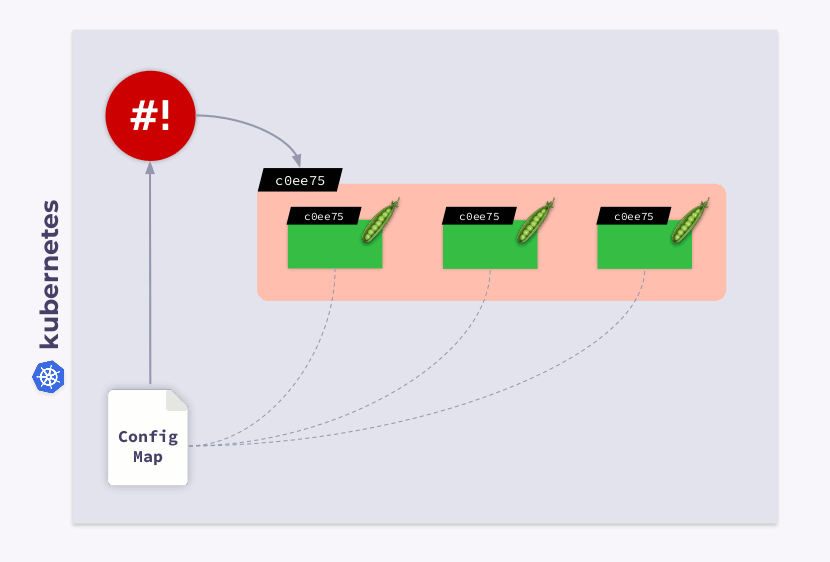
Werfen wir einen Blick auf eine Bereitstellung mit drei Pods. Pods verwenden ConfigMap, um einige Konfigurationen zu speichern. Als die Pods gestartet wurden, befand sich ConfigMap in einem bestimmten Zustand (nennen wir es v.1). Dementsprechend verwenden alle Pods diese spezielle Version von ConfigMap.
Angenommen, ConfigMap hat sich geändert (v.2). Pods verwenden jedoch die alte Version von ConfigMap (v.1):
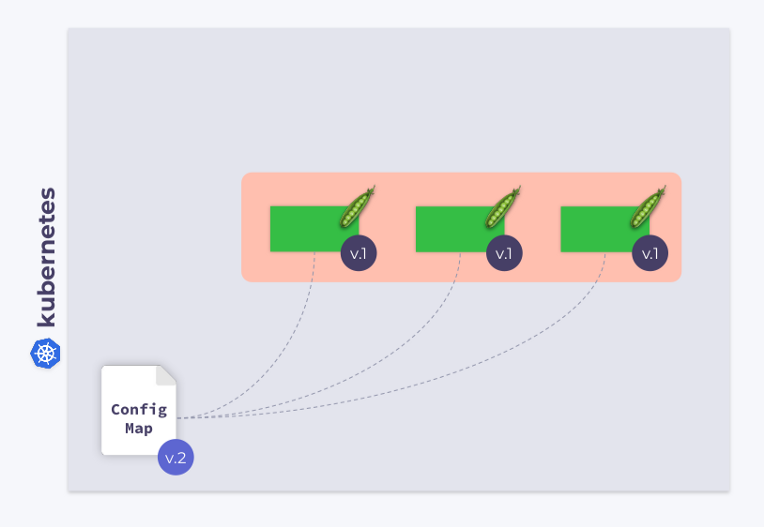
Wie kann ich sie auf die neue ConfigMap (v.2) migrieren lassen? Die Antwort ist einfach: Vorlage verwenden. Fügen wir dem Abschnitt zur
templateBereitstellungskonfiguration eine Prüfsummenanmerkung hinzu :

Infolgedessen wird diese Prüfsumme in allen Pods registriert und ist dieselbe wie in der Bereitstellung. Jetzt müssen Sie nur noch die Anmerkung aktualisieren, wenn sich ConfigMap ändert. Und der Shell-Operator ist in diesem Fall praktisch. Sie müssen lediglich einen Hook programmieren , der ConfigMap abonniert und die Prüfsumme aktualisiert .
Wenn der Benutzer Änderungen an der ConfigMap vornimmt, bemerkt der Shell-Operator diese und berechnet die Prüfsumme neu. Dann kommt die Magie von Kubernetes ins Spiel: Der Orchestrator wird den Pod töten, einen neuen erstellen, darauf warten, dass er wird
Ready, und zum nächsten übergehen. Infolgedessen wird die Bereitstellung synchronisiert und auf die neue Version von ConfigMap migriert.
Beispiel 2: Arbeiten mit benutzerdefinierten Ressourcendefinitionen
Wie Sie wissen, können Sie mit Kubernetes benutzerdefinierte Objekttypen (Arten) erstellen. Zum Beispiel können Sie Art erstellen
MysqlDatabase. Angenommen, dieser Typ hat zwei Metadatenparameter: nameundnamespace.
apiVersion: example.com/v1alpha1
kind: MysqlDatabase
metadata:
name: foo
namespace: bar
Wir haben einen Kubernetes-Cluster mit verschiedenen Namespaces, in dem wir MySQL-Datenbanken erstellen können. In diesem Fall kann der Shell-Operator verwendet werden, um Ressourcen zu verfolgen
MysqlDatabase, sie mit dem MySQL-Server zu verbinden und die gewünschten und beobachteten Zustände des Clusters zu synchronisieren.

Beispiel 3: Überwachen eines Clusternetzwerks
Wie Sie wissen, ist die Verwendung von Ping die einfachste Möglichkeit, ein Netzwerk zu überwachen. In diesem Beispiel zeigen wir, wie eine solche Überwachung mit dem Shell-Operator implementiert wird.
Zunächst müssen Sie die Knoten abonnieren. Der Shell-Operator benötigt den Namen und die IP-Adresse jedes Knotens. Mit ihrer Hilfe werden diese Knoten gepingt.
configVersion: v1
kubernetes:
- name: nodes
apiVersion: v1
kind: Node
jqFilter: |
{
name: .metadata.name,
ip: (
.status.addresses[] |
select(.type == "InternalIP") |
.address
)
}
group: main
keepFullObjectsInMemory: false
executeHookOnEvent: []
schedule:
- name: every_minute
group: main
crontab: "* * * * *"
Der Parameter
executeHookOnEvent: []verhindert das Starten des Hooks als Reaktion auf ein Ereignis (dh als Reaktion auf Änderungen, Hinzufügungen, Löschungen von Knoten). Es wird jedoch nach einem Zeitplan ausgeführt (und die Hostliste aktualisiert) - jede Minute, wie es das Feld vorschreibt schedule.
Nun stellt sich die Frage, wie genau wir über Probleme wie Paketverlust Bescheid wissen. Werfen wir einen Blick auf den Code:
function __main__() {
for i in $(seq 0 "$(context::jq -r '(.snapshots.nodes | length) - 1')"); do
node_name="$(context::jq -r '.snapshots.nodes['"$i"'].filterResult.name')"
node_ip="$(context::jq -r '.snapshots.nodes['"$i"'].filterResult.ip')"
packets_lost=0
if ! ping -c 1 "$node_ip" -t 1 ; then
packets_lost=1
fi
cat >> "$METRICS_PATH" <<END
{
"name": "node_packets_lost",
"add": $packets_lost,
"labels": {
"node": "$node_name"
}
}
END
done
}
Wir durchlaufen die Liste der Knoten, erhalten deren Namen und IP-Adressen, pingen und senden die Ergebnisse an Prometheus. Der Shell-Operator kann Metriken nach Prometheus exportieren und in einer Datei speichern, die sich gemäß dem in der Umgebungsvariablen angegebenen Pfad befindet
$METRICS_PATH.
Auf diese Weise können Sie einen Operator für die einfache Netzwerküberwachung in einem Cluster ausführen.
Warteschlangenmechanismus
Dieser Artikel wäre unvollständig, ohne einen anderen wichtigen Mechanismus zu beschreiben, der in den Shell-Operator integriert ist. Stellen Sie sich vor, es führt einen Hook als Reaktion auf ein Ereignis im Cluster aus.
- Was passiert, wenn gleichzeitig ein anderes Ereignis im Cluster auftritt ?
- Startet der Shell-Operator eine weitere Instanz des Hooks?
- Was aber, wenn beispielsweise fünf Ereignisse sofort im Cluster auftreten?
- Wird der Shell-Operator sie parallel behandeln?
- Was ist mit verbrauchten Ressourcen wie Speicher und CPU?
Glücklicherweise verfügt der Shell-Operator über einen integrierten Warteschlangenmechanismus. Alle Ereignisse werden nacheinander in die Warteschlange gestellt und verarbeitet.
Lassen Sie uns dies anhand von Beispielen veranschaulichen. Nehmen wir an, wir haben zwei Haken. Das erste Ereignis geht an den ersten Haken. Nach Abschluss der Verarbeitung rückt die Warteschlange vor. Die nächsten drei Ereignisse werden an den zweiten Hook umgeleitet - sie werden aus der Warteschlange entfernt und in einem "Stapel" in die Warteschlange eingespeist. Das heißt, der Hook empfängt ein Array von Ereignissen - oder genauer gesagt ein Array von Bindungskontexten.
Diese Ereignisse können auch zu einem großen Ereignis kombiniert werden . Dafür ist ein Parameter
groupin der Bindungskonfiguration verantwortlich .

Sie können eine beliebige Anzahl von Warteschlangen / Hooks und deren verschiedenen Kombinationen erstellen. Beispielsweise kann eine Warteschlange mit zwei Hooks arbeiten oder umgekehrt.
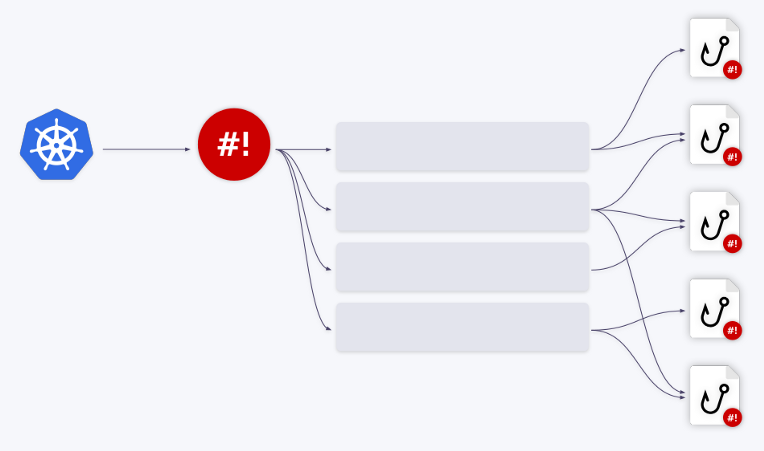
Sie müssen lediglich das Feld
queuein der Bindungskonfiguration entsprechend anpassen . Wenn kein Warteschlangenname angegeben wird, wird der Hook in der Standardwarteschlange ( default) ausgeführt. Mit diesem Warteschlangenmechanismus können Sie alle Ressourcenverwaltungsprobleme bei der Arbeit mit Hooks vollständig lösen.
Fazit
Wir haben darüber gesprochen, was ein Shell-Operator ist, haben gezeigt, wie er zum schnellen und mühelosen Erstellen von Kubernetes-Operatoren verwendet werden kann, und einige Beispiele für seine Verwendung gegeben.
Detaillierte Informationen zum Shell-Operator sowie eine Kurzanleitung zur Verwendung finden Sie im entsprechenden Repository auf GitHub . Zögern Sie nicht, uns bei Fragen zu kontaktieren: Sie können diese in einer speziellen Telegrammgruppe (auf Russisch) oder in diesem Forum (auf Englisch) diskutieren .
Und wenn es Ihnen gefallen hat, freuen wir uns immer über neue Ausgaben / PR / Stars auf GitHub, wo Sie übrigens weitere interessante Projekte finden können . Unter diesen ist der Addon-Operator hervorzuheben , der der ältere Bruder des Shell-Operators ist... Dieses Dienstprogramm verwendet Helm-Diagramme zum Installieren von Add-Ons, kann Aktualisierungen bereitstellen und verschiedene Diagrammparameter / -werte überwachen, steuert den Diagramminstallationsprozess und kann sie auch als Reaktion auf Ereignisse im Cluster ändern.

Videos und Folien
Video von der Aufführung (~ 23 Minuten):
Präsentation des Berichts:
PS
Lesen Sie auch in unserem Blog:
- " Einfache Erstellung von Kubernetes-Operatoren mit einem Shell-Operator: Projektfortschritt in einem Jahr ";
- „ Einführung des Shell-Operators: Das Erstellen von Operatoren für Kubernetes ist jetzt noch einfacher “;
- „ Ist es einfach und bequem, einen Kubernetes-Cluster vorzubereiten? Wir kündigen Addon-Operator an ";
- " Erweiterung und Ergänzung von Kubernetes" (Rückblick und Video des Berichts) .