Einführung
Dieser Artikel ist eine Zusammenstellung eines anderen Artikels . Darin möchte ich mich auf Tools für die Arbeit mit Big Data konzentrieren, die sich auf die Datenanalyse konzentrieren.
Angenommen, Sie haben die Rohdaten akzeptiert, verarbeitet und können sie jetzt weiter verwenden.
Es gibt viele Tools zum Bearbeiten von Daten, von denen jedes seine eigenen Vor- und Nachteile hat. Die meisten sind OLAP-orientiert, einige sind jedoch auch OLTP-optimiert. Einige von ihnen verwenden Standardformate und konzentrieren sich nur auf die Ausführung von Abfragen, andere verwenden ihr eigenes Format oder ihren eigenen Speicher, um die verarbeiteten Daten an die Quelle zu übertragen und so die Leistung zu verbessern. Einige sind für die Speicherung von Daten mithilfe bestimmter Schemata wie Stern oder Schneeflocke optimiert, andere sind flexibler. Zusammenfassend haben wir folgende Gegensätze:
- Data Warehouse vs. Lake
- Hadoop vs. Offline-Speicher
- OLAP gegen OLTP
- Abfrage-Engine versus OLAP-Mechanismen
Wir werden uns auch Tools zur Datenverarbeitung ansehen, mit denen Abfragen ausgeführt werden können.
Datenverarbeitungswerkzeuge
Die meisten der genannten Tools können eine Verbindung zu einem Metadatenserver wie Hive herstellen und Abfragen ausführen, Ansichten erstellen usw. Dies wird häufig verwendet, um zusätzliche (verbesserte) Berichtsebenen zu erstellen.
Spark SQL bietet eine Möglichkeit, SQL-Abfragen nahtlos mit Spark-Programmen zu mischen, sodass Sie DataFrame-APIs mit SQL mischen können. Es verfügt über eine Hive-Integration und eine Standard-JDBC- oder ODBC-Verbindung, sodass Sie Tableau, Looker oder ein beliebiges BI-Tool über Spark mit Ihren Daten verbinden können.

Apache Flinkbietet auch SQL API. Die SQL-Unterstützung von Flink basiert auf Apache Calcite, das den SQL-Standard implementiert. Es lässt sich auch über HiveCatalog in Hive integrieren. Beispielsweise können Benutzer ihre Kafka- oder ElasticSearch-Tabellen mithilfe des HiveCatalog im Hive Metastore speichern und später in SQL-Abfragen wiederverwenden.
Kafka bietet auch SQL-Funktionen. Im Allgemeinen bieten die meisten Datenverarbeitungstools SQL-Schnittstellen.
Abfragetools
Diese Art von Tool konzentriert sich auf eine einheitliche Abfrage an verschiedene Datenquellen in verschiedenen Formaten. Die Idee ist, Abfragen mithilfe von SQL an Ihren Datensee weiterzuleiten, als wäre es eine reguläre relationale Datenbank, obwohl sie einige Einschränkungen aufweist. Einige dieser Tools können auch NoSQL-Datenbanken und vieles mehr abfragen. Diese Tools bieten eine JDBC-Schnittstelle zu externen Tools wie Tableau oder Looker, um eine sichere Verbindung zu Ihrem Data Lake herzustellen. Abfragetools sind die langsamste Option, bieten jedoch die größte Flexibilität.
Apache Pig: eines der ersten Tools neben Hive. Hat eine andere Sprache als SQL. Eine Besonderheit der von Pig erstellten Programme besteht darin, dass sich ihre Struktur für eine signifikante Parallelisierung eignet, die es ihnen wiederum ermöglicht, sehr große Datenmengen zu verarbeiten. Aus diesem Grund ist es im Vergleich zu modernen SQL-basierten Systemen immer noch nicht veraltet.
Presto: Eine Open Source Plattform von Facebook. Es ist eine verteilte SQL-Abfrage-Engine zum Ausführen interaktiver analytischer Abfragen für Datenquellen beliebiger Größe. Mit Presto können Sie Daten überall abfragen, einschließlich Hive, Cassandra, relationalen Datenbanken und Dateisystemen. Es kann große Datenmengen in Sekunden abfragen. Presto ist unabhängig von Hadoop, lässt sich jedoch in die meisten seiner Tools, insbesondere Hive, integrieren, um SQL-Abfragen auszuführen.
Apache Drill: Bietet eine schemafreie SQL-Abfrage-Engine für Hadoop, NoSQL und sogar Cloud-Speicher. Es hängt nicht von Hadoop ab, aber es hat viele Integrationen mit Ökosystem-Tools wie Hive. Eine einzelne Abfrage kann Daten aus mehreren Speichern kombinieren und für jeden einzelne Optimierungen durchführen. Das ist sehr gut, weil ermöglicht es Analysten, Daten als Tabelle zu behandeln, selbst wenn sie die Datei tatsächlich lesen. Drill unterstützt vollständig Standard-SQL. Geschäftsanwender, Analysten und Datenwissenschaftler können Standard-Business-Intelligence-Tools wie Tableau, Qlik und Excel verwenden, um mithilfe von Drill JDBC- und ODBC-Treibern mit nicht relationalen Datenspeichern zu interagieren. Außerdem,Entwickler können den einfachen REST-API-Drill in ihren benutzerdefinierten Anwendungen verwenden, um schöne Visualisierungen zu erstellen.
OLTP-Datenbanken
Obwohl Hadoop für OLAP optimiert ist, gibt es immer noch Situationen, in denen Sie OLTP-Abfragen für eine interaktive Anwendung ausführen möchten.
HBase verfügt aufgrund seines Designs über sehr eingeschränkte ACID-Eigenschaften, da es maßstabsgetreu erstellt wurde und keine sofort einsatzbereiten ACID-Funktionen bietet. Es kann jedoch für einige OLTP-Szenarien verwendet werden.
Apache Phoenix basiert auf HBase und bietet eine Möglichkeit, OTLP-Abfragen im gesamten Hadoop-Ökosystem durchzuführen. Apache Phoenix ist vollständig in andere Hadoop-Produkte wie Spark, Hive, Pig, Flume und Map Reduce integriert. Es kann auch Metadaten speichern, Tabellenerstellung unterstützen und inkrementelle Versionsänderungen mithilfe von DDL-Befehlen ändern. Es funktioniert ziemlich schnell, schneller als mit Drill oder anderen
Mechanismus der Anfragen.
Sie können jede große Datenbank außerhalb des Hadoop-Ökosystems wie Cassandra, YugaByteDB, ScyllaDB für OTLP verwenden.
Schließlich ist es sehr häufig, dass schnelle Datenbanken jeglicher Art wie MongoDB oder MySQL eine langsamere Teilmenge von Daten aufweisen, normalerweise die aktuellsten. Die oben genannten Abfragemechanismen können Daten zwischen langsamer und schneller Speicherung in einer einzigen Abfrage kombinieren.
Verteilte Indizierung
Diese Tools bieten Möglichkeiten zum Speichern und Abrufen unstrukturierter Textdaten und befinden sich außerhalb des Hadoop-Ökosystems, da zum Speichern der Daten spezielle Strukturen erforderlich sind. Die Idee ist, einen invertierten Index zu verwenden, um schnelle Suchen durchzuführen. Zusätzlich zur Textsuche kann diese Technologie für eine Vielzahl von Zwecken verwendet werden, z. B. zum Speichern von Protokollen, Ereignissen usw. Es gibt zwei Hauptoptionen:
Solr: Dies ist eine beliebte, sehr schnelle Open-Source-Unternehmenssuchplattform, die auf Apache Lucene basiert. Solr ist ein robustes, skalierbares und ausfallsicheres Tool, das verteilte Indizierungs-, Replikations- und Lastausgleichsabfragen, automatisches Failover und Wiederherstellung, zentralisierte Konfiguration und mehr bietet. Es eignet sich hervorragend für die Textsuche, aber seine Anwendungsfälle sind im Vergleich zu ElasticSearch begrenzt.
ElasticSearch: Es ist auch ein sehr beliebter verteilter Index, hat sich jedoch zu einem eigenen Ökosystem entwickelt, das viele Anwendungsfälle wie APM, Suche, Textspeicherung, Analyse, Dashboards, maschinelles Lernen und mehr umfasst. Es ist definitiv ein Tool, das Sie entweder für DevOps oder für die Datenpipeline in Ihrer Toolbox haben sollten, da es sehr vielseitig ist. Es kann auch Videos und Bilder speichern und suchen.
ElasticSearchkann als schnelle Speicherschicht für Ihren Datensee für erweiterte Suchfunktionen verwendet werden. Wenn Sie Ihre Daten in einer großen Schlüsselwertdatenbank wie HBase oder Cassandra speichern, die aufgrund fehlender Verbindungen nur sehr eingeschränkte Suchfunktionen bietet, können Sie ElasticSearch vor sie stellen, um Abfragen auszuführen, IDs zurückzugeben und dann Führen Sie eine schnelle Suche in Ihrer Datenbank durch.
Es kann auch für Analysen verwendet werden. Sie können Ihre Daten exportieren, indizieren und dann mit Kibana abfragenDurch das Erstellen von Dashboards, Berichten und mehr können Sie Histogramme und komplexe Aggregationen hinzufügen und sogar Algorithmen für maschinelles Lernen zusätzlich zu Ihren Daten ausführen. Das ElasticSearch-Ökosystem ist riesig und es lohnt sich, es zu erkunden.
OLAP-Datenbanken
Hier sehen wir uns Datenbanken an, die auch einen Metadatenspeicher für Abfrageschemata bereitstellen können. Im Vergleich zu Abfrageausführungssystemen bieten diese Tools auch Datenspeicherung und können auf bestimmte Speicherschemata (Sternschema) angewendet werden. Diese Tools verwenden die SQL-Syntax. Spark oder andere Plattformen können mit ihnen interagieren.
Apache Bienenstock: Wir haben Hive bereits als zentrales Schema-Repository für Spark und andere Tools besprochen, damit diese SQL verwenden können. Hive kann jedoch auch Daten speichern, sodass Sie sie als Repository verwenden können. Er kann auf HDFS oder HBase zugreifen. Auf Anfrage von Hive werden Apache Tez, Apache Spark oder MapReduce verwendet, was viel schneller als Tez oder Spark ist. Es hat auch eine prozedurale Sprache namens HPL-SQL. Hive ist ein äußerst beliebter Metadatenspeicher für Spark SQL.
Apache Impala: Es handelt sich um eine native Analysedatenbank für Hadoop, mit der Sie Daten speichern und effizient abfragen können. Sie kann sich mit Hive verbinden, um mithilfe von Hcatalog Metadaten abzurufen. Impala bietet eine geringe Latenz und eine hohe Parallelität für Business Intelligence- und Analytics-Abfragen in Hadoop (das nicht von gepackten Plattformen wie Apache Hive bereitgestellt wird). Impala lässt sich auch in Umgebungen mit mehreren Benutzern linear skalieren. Dies ist eine bessere Abfragealternative als Hive. Impala ist zur Authentifizierung in die proprietäre Hadoop- und Kerberos-Sicherheit integriert, sodass Sie den Datenzugriff sicher verwalten können. Es verwendet HBase und HDFS zur Datenspeicherung.

Apache Tajo: Dies ist ein weiteres Data Warehouse für Hadoop. Tajo wurde entwickelt, um Ad-hoc-Abfragen mit geringer Latenz und Skalierbarkeit, Online-Aggregation und ETL für große Datenmengen auszuführen, die in HDFS und anderen Datenquellen gespeichert sind. Es unterstützt die Integration in den Hive Metastore, um auf allgemeine Schemas zuzugreifen. Es hat auch viele Abfrageoptimierungen, ist skalierbar, fehlertolerant und bietet eine JDBC-Schnittstelle.
Apache Kylin: Dies ist ein neues verteiltes analytisches Data Warehouse. Kylin ist extrem schnell und kann daher als Ergänzung zu anderen Datenbanken wie Hive für Anwendungsfälle verwendet werden, bei denen die Leistung von entscheidender Bedeutung ist, z. B. Dashboards oder interaktive Berichte. Es ist wahrscheinlich das beste OLAP-Data-Warehouse, aber schwierig zu verwenden. Ein weiteres Problem besteht darin, dass aufgrund der hohen Dehnung mehr Speicherplatz benötigt wird. Die Idee ist, dass Sie, wenn die Abfrage-Engines oder Hive nicht schnell genug sind, einen "Cube" in Kylin erstellen können, einer OLAP-optimierten mehrdimensionalen Tabelle mit vorberechneten Daten
Werte, die Sie über Dashboards oder interaktive Berichte abfragen können. Es kann Würfel direkt aus Spark und sogar in Echtzeit von Kafka aus erstellen.
OLAP-Tools
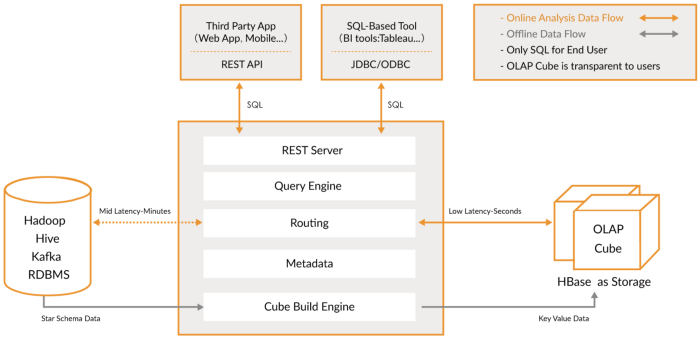
In diese Kategorie füge ich neuere Engines ein, die eine Weiterentwicklung früherer OLAP-Datenbanken darstellen, die mehr Funktionalität bieten und eine umfassende Analyseplattform schaffen. Tatsächlich sind sie eine Mischung aus den beiden vorherigen Kategorien, mit denen Ihre OLAP-Datenbanken indiziert werden. Sie leben außerhalb der Hadoop-Plattform, sind jedoch eng integriert. In diesem Fall überspringen Sie normalerweise den Verarbeitungsschritt und verwenden diese Tools direkt.
Sie versuchen, das Problem der einheitlichen Abfrage von Echtzeitdaten und historischen Daten zu lösen, sodass Sie sofort Echtzeitdaten abfragen können, sobald diese verfügbar sind, sowie historische Daten mit geringer Latenz, um interaktive Anwendungen und Dashboards zu erstellen. Mit diesen Tools können in vielen Fällen Rohdaten mit geringer oder keiner ELT-Transformation, aber mit hoher Leistung abgefragt werden, die besser sind als bei herkömmlichen OLAP-Datenbanken.
Gemeinsam ist ihnen, dass sie eine einheitliche Ansicht von Daten, Live- und Batch-Datenerfassung, verteilter Indizierung, nativem Datenformat, SQL-Unterstützung, JDBC-Schnittstelle, Unterstützung für heiße und kalte Daten, Mehrfachintegrationen und Metadatenspeicherung bieten.
Apache Druid: Dies ist die bekannteste Echtzeit-OLAP-Engine. Es konzentriert sich auf Zeitreihendaten, kann jedoch für alle Daten verwendet werden. Es verwendet ein eigenes Spaltenformat, das Daten stark komprimieren kann, und verfügt über zahlreiche integrierte Optimierungen wie invertierte Indizes, Textcodierung, automatisch reduzierte Daten und mehr. Daten werden in Echtzeit mit Tranquility oder Kafka geladen, die eine sehr geringe Latenz aufweisen. Sie werden in einem schreiboptimierten Zeichenfolgenformat im Speicher gespeichert. Sobald sie eintreffen, können sie wie die zuvor heruntergeladenen Daten abgefragt werden. Der Hintergrundprozess ist dafür verantwortlich, Daten asynchron in ein Deep-Storage-System wie HDFS zu verschieben. Wenn Daten in einen tiefen Speicher verschoben werden, werden sie in kleinere Blöcke aufgeteilt.zeitlich getrennte, als Segmente bezeichnete Segmente, die für Abfragen mit geringer Latenz gut optimiert sind. Dieses Segment verfügt über einen Zeitstempel für mehrere Dimensionen, die Sie zum Filtern und Aggregieren verwenden können, sowie über Metriken, bei denen es sich um vorberechnete Zustände handelt. Beim Burst-Empfang werden Daten direkt in Segmenten gespeichert. Apache Druid unterstützt das Schlucken durch Drücken und Ziehen sowie die Integration in Hive, Spark und sogar NiFi. Es kann den Hive-Metadatenspeicher verwenden und unterstützt Hive-SQL-Abfragen, die dann in von Druid verwendete JSON-Abfragen konvertiert werden. Die Hive-Integration unterstützt JDBC, sodass Sie jedes BI-Tool anschließen können. Es hat auch ein eigenes Metadaten-Repository, normalerweise wird MySQL dafür verwendet.Es kann große Datenmengen aufnehmen und skaliert sehr gut. Das Hauptproblem besteht darin, dass es viele Komponenten enthält und schwierig zu verwalten und bereitzustellen ist.
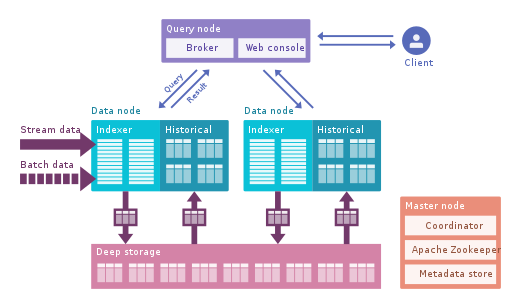
Apache Pinot : Dies ist eine neuere Open-Source-Druiden-Alternative von LinkedIn. Im Vergleich zu Druid bietet es dank des Startree-Index, der eine teilweise Vorberechnung durchführt, eine geringere Latenz, sodass es für benutzerzentrierte Anwendungen verwendet werden kann (es wurde zum Abrufen von LinkedIn-Feeds verwendet). Es wird ein sortierter Index anstelle eines invertierten Index verwendet, was schneller ist. Es hat eine erweiterbare Plugin-Architektur und viele Integrationen, unterstützt jedoch Hive nicht. Es integriert auch die Stapel- und Echtzeitverarbeitung, bietet schnelles Laden, intelligenten Index und speichert Daten in Segmenten. Die Bereitstellung ist im Vergleich zu Druid einfacher und schneller, sieht aber im Moment etwas unreif aus.
ClickHouse: Diese in C ++ geschriebene Engine bietet eine unglaubliche Leistung für OLAP-Abfragen, insbesondere für Aggregate. Es ist wie eine relationale Datenbank, sodass Sie die Daten einfach modellieren können. Es ist sehr einfach einzurichten und hat viele Integrationen.
Lesen Sie diesen Artikel, in dem die 3 Motoren im Detail verglichen werden.
Beginnen Sie klein, indem Sie Ihre Daten untersuchen, bevor Sie eine Entscheidung treffen. Diese neuen Mechanismen sind sehr leistungsfähig, aber schwierig zu verwenden. Wenn Sie stundenlang warten können, verwenden Sie die Stapelverarbeitung und eine Datenbank wie Hive oder Tajo. Verwenden Sie dann Kylin, um OLAP-Abfragen zu beschleunigen und interaktiver zu gestalten. Wenn dies nicht ausreicht und Sie noch weniger Latenz und Echtzeitdaten benötigen, ziehen Sie OLAP-Engines in Betracht. Druide eignen sich besser für Echtzeitanalysen. Kaileen konzentriert sich mehr auf OLAP-Fälle. Druid hat eine gute Integration mit Kafka als Live-Streaming. Kylin empfängt Daten von Hive oder Kafka in Chargen, obwohl ein Live-Empfang geplant ist.
Endlich Greenplum Ist eine weitere OLAP-Engine, die sich mehr auf künstliche Intelligenz konzentriert.
Datenvisualisierung
Es gibt verschiedene kommerzielle Tools zur Visualisierung wie Qlik, Looker oder Tableau.
Wenn Sie Open Source bevorzugen, schauen Sie in Richtung SuperSet. Es ist ein großartiges Tool, das alle genannten Tools unterstützt, einen großartigen Editor hat und sehr schnell ist. Es verwendet SQLAlchemy, um Unterstützung für viele Datenbanken bereitzustellen.
Andere interessante Tools sind Metabase oder Falcon .
Fazit
Es gibt eine Vielzahl von Tools, mit denen Daten bearbeitet werden können, von flexiblen Abfrage-Engines wie Presto bis hin zu Hochleistungsspeicher wie Kylin. Es gibt keine einheitliche Lösung. Ich rate Ihnen, die Daten zu recherchieren und klein anzufangen. Abfrage-Engines sind aufgrund ihrer Flexibilität ein guter Ausgangspunkt. Für verschiedene Anwendungsfälle müssen Sie möglicherweise zusätzliche Tools hinzufügen, um das gewünschte Servicelevel zu erreichen.
Achten Sie besonders auf neue Tools wie Druid oder Pinot, mit denen Sie auf einfache Weise große Datenmengen mit sehr geringer Latenz analysieren und so die Lücke zwischen OLTP und OLAP hinsichtlich der Leistung schließen können. Sie könnten versucht sein, über die Verarbeitung, die Vorberechnung von Aggregaten und dergleichen nachzudenken, aber ziehen Sie diese Tools in Betracht, wenn Sie Ihre Arbeit vereinfachen möchten.