
Hallo!
Mein Name ist Nikita und ich beaufsichtige die Entwicklung mehrerer Projekte bei DomClick. Heute möchte ich das Thema "lustige Bilder" in der RabbitMQ-Welt fortsetzen. In seinem Artikel betrachtete Alexey Kazakov ein so mächtiges Werkzeug wie verzögerte Warteschlangen und verschiedene Implementierungen der Wiederholungsstrategie. Heute werden wir darüber sprechen, wie Sie mit RabbitMQ regelmäßige Aufgaben planen können.
Warum mussten wir unser eigenes Fahrrad entwickeln und warum haben wir Sellerie und andere Tools für das Aufgabenmanagement aufgegeben? Tatsache ist, dass sie nicht unseren Aufgaben und Anforderungen an die Fehlertoleranz entsprachen, die in unserem Unternehmen recht streng sind.
Beim Wechsel zu Docker und Kubernetes haben viele Entwickler Probleme, regelmäßige Aufgaben zu organisieren, Kronen werden mit einem Tamburin auf den Markt gebracht und die Steuerung des Prozesses lässt zu wünschen übrig. Und dann gibt es tagsüber Probleme mit Spitzenlasten.
Meine Aufgabe war es, im Projekt ein zuverlässiges System für die Verarbeitung periodischer Aufgaben zu implementieren, das leicht skalierbar und fehlertolerant ist. Unser Projekt ist in Python, daher war es logisch zu sehen, wie Sellerie zu uns passt. Dies ist ein gutes Tool, aber dabei sind wir häufig auf Probleme mit Zuverlässigkeit, Skalierbarkeit und nahtloser Freigabe gestoßen. Ein Pod - eine Prozessgruppe. Wenn Sie Sellerie skalieren, müssen Sie die Ressourcen eines Pods erhöhen, da keine Synchronisation zwischen den Pods erfolgt. Dies bedeutet, dass die Verarbeitung von Aufgaben, wenn auch nur vorübergehend, gestoppt wird. Und wenn die Aufgaben auch langfristig sind, haben Sie bereits erraten, wie schwierig es ist, sie zu verwalten. Der zweite offensichtliche Nachteil: Standardmäßig wird Asynchronität nicht unterstützt, und für uns ist dies wichtig, da Aufgaben hauptsächlich E / A-Vorgänge enthalten und Sellerie auf Threads ausgeführt wird.
Zu diesem Zeitpunkt (2018) fanden wir kein geeignetes fertiges Werkzeug und begannen, unser eigenes zu entwickeln. Auf der Grundlage der Funktionalität der verzögerten Ausführung von Aufgaben und des Dead Letter Exchange haben wir beschlossen, ein System für die Verarbeitung periodischer Aufgaben zu erstellen. Das Konzept sah ungefähr so aus:
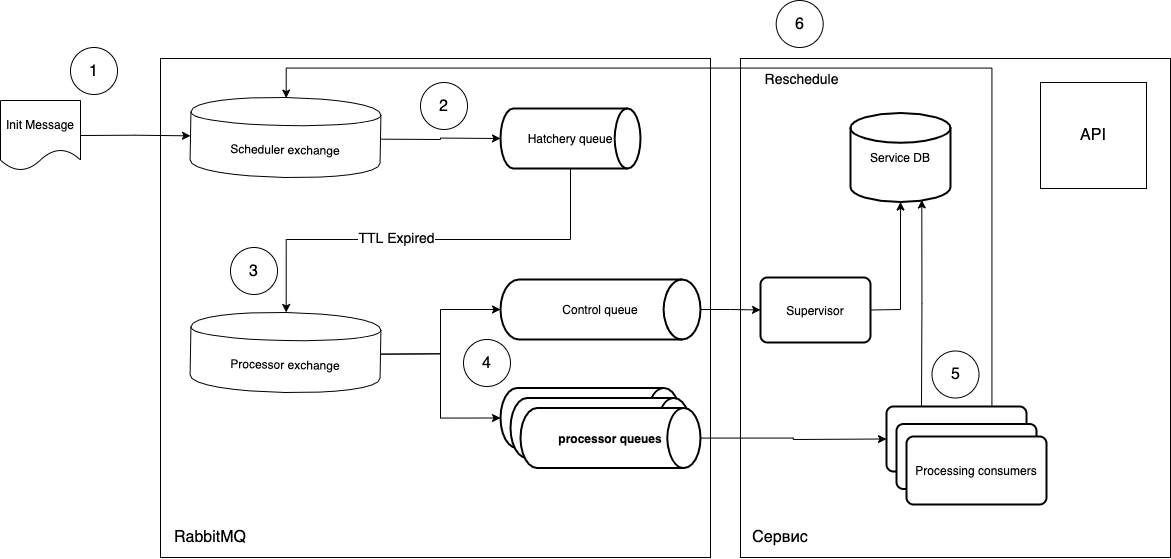
Ich werde versuchen zu erklären, was was ist.
- Aufgaben werden in Form einer Nachricht an die Scheduler-Vermittlungsstelle gesendet.
- Die
routing_keySoftware gelangt in die erforderliche Hatchery-Warteschlange, die einen Parameter enthältmessage_ttl, sowie in die Verbindung mit dem Prozessoraustausch als Deal Letter Exchange. Die "ausgereifte" Warteschlange ist nicht mit der Art der Aufgaben verknüpft, sondern spielt nur die Rolle eines "Timers". Das heißt, Sie können so viele Warteschlangen erstellen, wie Sie benötigen, und sie verwaltenrouting_key. - Da die Warteschlange keine Listener hat, werden die Nachrichten nach dem "Reifen" in der Warteschlange an den Prozessoraustausch gesendet.
- Dann nimmt der freie Verbraucher (verarbeitender Verbraucher) die Nachricht auf und führt sie aus. Nach der Ausführung wird der Zyklus bei Bedarf wiederholt.
Was ist der Vorteil eines solchen Systems?
- Die schrittweise Ausführung, dh eine neue Aufgabe, wird nicht verarbeitet, wenn die vorherige nicht abgeschlossen wurde.
- Mit einem einzigen Zuhörer (Verbraucher) können Sie sowohl universelle als auch spezialisierte Mitarbeiter erstellen. Skaliert durch einfaches Erhöhen der Anzahl der benötigten Pods.
- Stellen Sie neue Aufgaben bereit, ohne die Arbeit der aktuellen zu stören. Es reicht aus, die Listener-Pods sanft zu aktualisieren und die entsprechende Nachricht an die Warteschlange zu senden. Das heißt, Sie können Pods mit einem neuen Code auslösen, der sich mit neuen Nachrichten befasst, und die aktuellen Prozesse werden in den alten Pods weitergeführt. Dies gibt uns ein nahtloses Update.
- Sie können asynchronen Code und jede Infrastruktur verwenden, während Sie stapelunabhängig sind.
- Sie können die Ausführung von Aufgaben in dem nativen Kontrolle
ack/ Niveaureject, und auch eine zusätzliche optionale Warteschlange (Queue Steuer) erhalten , die den Lebenszyklus von Aufgaben verfolgen kann.
Die Schaltung erwies sich als recht einfach, wir haben schnell einen funktionierenden Prototyp erstellt. Und der Code ist wunderschön. Es reicht aus, die Rückruffunktion mit einem einfachen Dekorator zu markieren, der den Nachrichtenlebenszyklus steuert.
def rmq_scheduler(routing_key_for_delay_queue, routing_key_for_processing_queue):
def decorator(func):
@wraps(func)
async def wrapper(channel, body, envelope, properties):
try:
res = await func(channel, body, envelope, properties)
await channel.publish(
payload=body,
exchange_name='',
routing_key=routing_key_for_delay_queue,
)
await channel.basic_client_ack(envelope.delivery_tag)
return res
except Exception as e:
log_error(e)
redelivered_count = get_count_of_redelivery_attempts(properties)
if redelivered_count <= 3:
await resend_msg(
channel=channel,
body=body,
properties=properties,
routing_key=routing_key_for_processing_queue)
else:
async with app.natalya_db_engine.acquire() as conn:
async with conn.begin():
await channel.publish(
payload=body,
exchange_name='',
routing_key=routing_key_for_delay_queue,
)
await channel.basic_client_ack(envelope.delivery_tag)
return wrapper
return decorator
Jetzt verwenden wir dieses Schema, um nur periodische sequentielle Aufgaben auszuführen. Es kann jedoch auch verwendet werden, wenn es wichtig ist, die Ausführung einer Aufgabe zu einem bestimmten Zeitpunkt zu starten, ohne die Zeit auf die Ausführung selbst zu verschieben. Dazu reicht es aus, die Aufgabe neu zu planen, nachdem die Nachricht den Supervisor erreicht hat.
Dieser Ansatz hat zwar zusätzliche Gemeinkosten. Sie müssen verstehen, dass im Falle eines Fehlers die Nachricht in die Warteschlange zurückkehrt, ein anderer Mitarbeiter sie aufnimmt und sofort mit der Ausführung beginnt. Daher müssen Sie die Fehlerbehandlung nach dem Grad der Kritikalität trennen und im Voraus überlegen, was mit der Nachricht im Falle dieses oder jenes Fehlers zu tun ist.
Möglichkeiten:
- Der Fehler wird sich von selbst beheben (z. B. handelt es sich um einen Systemfehler): Fehlerbehandlung senden
noackund wiederholen. - Geschäftslogikfehler: Sie müssen den Zyklus unterbrechen - senden
ack. - Der Fehler von Punkt 1 wird zu oft wiederholt: Wir vergiften
rejectund signalisieren den Entwicklern. Hier gibt es Optionen. Sie können eine Deal-Letter-Warteschlange für die zu speichernden Nachrichten erstellen, um die Nachricht nach dem Parsen zurückzugeben, oder Sie können die Wiederholungstechnik verwenden (angebenmessage_ttl).
Dekorateur Beispiel:
def auto_ack_or_nack(log_message):
def decorator(func):
@wraps(func)
async def wrapper(channel, body, envelope, properties):
try:
res = await func(channel, body, envelope, properties)
await channel.basic_client_ack(envelope.delivery_tag)
return res
except Exception as e:
await channel.basic_client_nack(envelope.delivery_tag, requeue=False)
log_error(log_message, exception=e)
return wrapper
return decorator
Dieses Programm arbeitet seit einem halben Jahr mit uns zusammen, ist sehr zuverlässig und erfordert praktisch keine Aufmerksamkeit. Der Anwendungsabsturz unterbricht den Scheduler nicht und verzögert die Ausführung von Aufgaben nur geringfügig.
Es gibt keine Pluspunkte ohne Minuspunkte. Dieses Schema weist auch eine kritische Sicherheitsanfälligkeit auf. Wenn RabbitMQ etwas passiert ist und die Nachrichten verschwunden sind, müssen Sie manuell nachsehen, was verloren gegangen ist, und die Schleife erneut starten. Dies ist jedoch eine äußerst unwahrscheinliche Situation, in der Sie zuletzt über diesen Dienst nachdenken müssen :)
PS Wenn Ihnen das Thema der Planung periodischer Aufgaben interessant erscheint, werde ich Ihnen im nächsten Artikel ausführlicher erläutern, wie wir die Erstellung von Warteschlangen automatisieren, sowie über Supervisor.
Links: